Apache Lucene is a free and open-source search engine software library, originally written in Java by Doug Cutting. It is supported by the Apache Software Foundation and is released under the Apache Software License. Lucene is widely used as a standard foundation for production search applications.

Metabolomics is the scientific study of chemical processes involving metabolites, the small molecule substrates, intermediates, and products of cell metabolism. Specifically, metabolomics is the "systematic study of the unique chemical fingerprints that specific cellular processes leave behind", the study of their small-molecule metabolite profiles. The metabolome represents the complete set of metabolites in a biological cell, tissue, organ, or organism, which are the end products of cellular processes. Messenger RNA (mRNA), gene expression data, and proteomic analyses reveal the set of gene products being produced in the cell, data that represents one aspect of cellular function. Conversely, metabolic profiling can give an instantaneous snapshot of the physiology of that cell, and thus, metabolomics provides a direct "functional readout of the physiological state" of an organism. There are indeed quantifiable correlations between the metabolome and the other cellular ensembles, which can be used to predict metabolite abundances in biological samples from, for example mRNA abundances. One of the ultimate challenges of systems biology is to integrate metabolomics with all other -omics information to provide a better understanding of cellular biology.
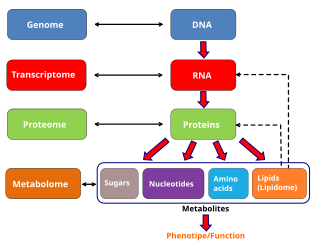
The metabolome refers to the complete set of small-molecule chemicals found within a biological sample. The biological sample can be a cell, a cellular organelle, an organ, a tissue, a tissue extract, a biofluid or an entire organism. The small molecule chemicals found in a given metabolome may include both endogenous metabolites that are naturally produced by an organism as well as exogenous chemicals that are not naturally produced by an organism.
The DrugBank database is a comprehensive, freely accessible, online database containing information on drugs and drug targets created and maintained by the University of Alberta and The Metabolomics Innovation Centre located in Alberta, Canada. As both a bioinformatics and a cheminformatics resource, DrugBank combines detailed drug data with comprehensive drug target information. DrugBank has used content from Wikipedia; Wikipedia also often links to Drugbank, posing potential circular reporting issues.
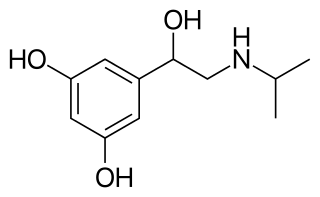
Orciprenaline, also known as metaproterenol, is a bronchodilator used in the treatment of asthma. Orciprenaline is a moderately selective β2 adrenergic receptor agonist that stimulates receptors of the smooth muscle in the lungs, uterus, and vasculature supplying skeletal muscle, with minimal or no effect on α adrenergic receptors. The pharmacologic effects of β adrenergic agonist drugs, such as orciprenaline, are at least in part attributable to stimulation through β adrenergic receptors of intracellular adenylyl cyclase, the enzyme which catalyzes the conversion of ATP to cAMP. Increased cAMP levels are associated with relaxation of bronchial smooth muscle and inhibition of release of mediators of immediate hypersensitivity from many cells, especially from mast cells.

Glycochenodeoxycholic acid is a bile salt formed in the liver from chenodeoxycholic acid and glycine, usually found as the sodium salt. It acts as a detergent to solubilize fats for absorption.
PDBsum is a database that provides an overview of the contents of each 3D macromolecular structure deposited in the Protein Data Bank (PDB).
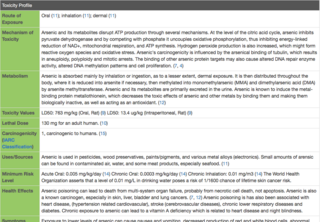
The Toxin and Toxin-Target Database (T3DB), also known as the Toxic Exposome Database, is a freely accessible online database of common substances that are toxic to humans, along with their protein, DNA or organ targets. The database currently houses nearly 3,700 toxic compounds or poisons described by nearly 42,000 synonyms. This list includes various groups of toxins, including common pollutants, pesticides, drugs, food toxins, household and industrial/workplace toxins, cigarette toxins, and uremic toxins. These toxic substances are linked to 2,086 corresponding protein/DNA target records. In total there are 42,433 toxic substance-toxin target associations. Each toxic compound record (ToxCard) in T3DB contains nearly 100 data fields and holds information such as chemical properties and descriptors, mechanisms of action, toxicity or lethal dose values, molecular and cellular interactions, medical information, NMR an MS spectra, and up- and down-regulated genes. This information has been extracted from over 18,000 sources, which include other databases, government documents, books, and scientific literature.
The Small Molecule Pathway Database (SMPDB) is a comprehensive, high-quality, freely accessible, online database containing more than 600 small molecule (i.e. metabolic) pathways found in humans. SMPDB is designed specifically to support pathway elucidation and pathway discovery in metabolomics, transcriptomics, proteomics and systems biology. It is able to do so, in part, by providing colorful, detailed, fully searchable, hyperlinked diagrams of five types of small molecule pathways: 1) general human metabolic pathways; 2) human metabolic disease pathways; 3) human metabolite signaling pathways; 4) drug-action pathways and 5) drug metabolism pathways. SMPDB pathways may be navigated, viewed and zoomed interactively using a Google Maps-like interface. All SMPDB pathways include information on the relevant organs, subcellular compartments, protein cofactors, protein locations, metabolite locations, chemical structures and protein quaternary structures (Fig. 1). Each small molecule in SMPDB is hyperlinked to detailed descriptions contained in the HMDB or DrugBank and each protein or enzyme complex is hyperlinked to UniProt. Additionally, all SMPDB pathways are accompanied with detailed descriptions and references, providing an overview of the pathway, condition or processes depicted in each diagram. Users can browse the SMPDB (Fig. 2) or search its contents by text searching (Fig. 3), sequence searching, or chemical structure searching. More powerful queries are also possible including searching with lists of gene or protein names, drug names, metabolite names, GenBank IDs, Swiss-Prot IDs, Agilent or Affymetrix microarray IDs. These queries will produce lists of matching pathways and highlight the matching molecules on each of the pathway diagrams. Gene, metabolite and protein concentration data can also be visualized through SMPDB's mapping interface.
MetaboAnalyst is a set of online tools for metabolomic data analysis and interpretation, created by members of the Wishart Research Group at the University of Alberta. It was first released in May 2009 and version 2.0 was released in January 2012. MetaboAnalyst provides a variety of analysis methods that have been tailored for metabolomic data. These methods include metabolomic data processing, normalization, multivariate statistical analysis, and data annotation. The current version is focused on biomarker discovery and classification.
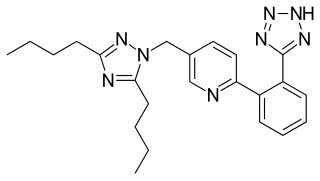
Forasartan, otherwise known as the compound SC-52458, is a nonpeptide angiotensin II receptor antagonist (ARB, AT1 receptor blocker).
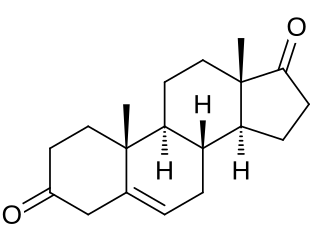
5-Androstenedione, also known as androst-5-ene-3,17-dione, is a prohormone of testosterone. The World Anti-Doping Agency prohibits its use in athletes. In the United States, it is a controlled substance.
The Yeast Metabolome Database (YMDB) is a comprehensive, high-quality, freely accessible, online database of small molecule metabolites found in or produced by Saccharomyces cerevisiae. The YMDB was designed to facilitate yeast metabolomics research, specifically in the areas of general fermentation as well as wine, beer and fermented food analysis. YMDB supports the identification and characterization of yeast metabolites using NMR spectroscopy, GC-MS spectrometry and Liquid chromatography–mass spectrometry. The YMDB contains two kinds of data: 1) chemical data and 2) molecular biology/biochemistry data. The chemical data includes 2027 metabolite structures with detailed metabolite descriptions along with nearly 4000 NMR, GC-MS and LC/MS spectra.
Metabolite Set Enrichment Analysis (MSEA) is a method designed to help metabolomics researchers identify and interpret patterns of metabolite concentration changes in a biologically meaningful way. It is conceptually similar to another widely used tool developed for transcriptomics called Gene Set Enrichment Analysis or GSEA. GSEA uses a collection of predefined gene sets to rank the lists of genes obtained from gene chip studies. By using this “prior knowledge” about gene sets researchers are able to readily identify significant and coordinated changes in gene expression data while at the same time gaining some biological context. MSEA does the same thing by using a collection of predefined metabolite pathways and disease states obtained from the Human Metabolome Database. MSEA is offered as a service both through a stand-alone web server and as part of a larger metabolomics analysis suite called MetaboAnalyst.
Metabolomic Pathway Analysis, shortened to MetPA, is a freely available, user-friendly web server to assist with the identification analysis and visualization of metabolic pathways using metabolomic data. MetPA makes use of advances originally developed for pathway analysis in microarray experiments and applies those principles and concepts to the analysis of metabolic pathways. For input, MetPA expects either a list of compound names or a metabolite concentration table with phenotypic labels. The list of compounds can include common names, HMDB IDs or KEGG IDs with one compound per row. Compound concentration tables must have samples in rows and compounds in columns. MetPA's output is a series of tables indicating which pathways are significantly enriched as well as a variety of graphs or pathway maps illustrating where and how certain pathways were enriched. MetPA's graphical output uses a colorful Google-Maps visualization system that allows simple, intuitive data exploration that lets users employ a computer mouse or track pad to select, drag and place images and to seamlessly zoom in and out. Users can explore MetPA's output using three different views or levels: 1) a metabolome view; 2) a pathway view; 3) a compound view.
FooDB is a freely available, open-access database containing chemical composition data on common, unprocessed foods. It also contains extensive data on flavour and aroma constituents, food additives as well as positive and negative health effects associated with food constituents. The database contains information on more than 28,000 chemicals found in more than 1000 raw or unprocessed food products. The data in FooDB was collected from many sources including textbooks, scientific journals, on-line food composition or nutrient databases, flavour and aroma databases and various on-line metabolomic databases. This literature-derived information has been combined with experimentally derived data measured on thousands of compounds from more than 40 very common food products through the Alberta Food Metabolome Project which is led by David S. Wishart. Users are able to browse through the FooDB data by food source, name, descriptors or function. Chemical structures and molecular weights for compounds in FooDB may be searched via a specialized chemical structure search utility. Users are able to view the content of FooDB using two different “Viewing” options: FoodView, which lists foods by their chemical compounds, or ChemView, which lists chemicals by their food sources. Knowledge about the precise chemical composition of foods can be used to guide public health policies, assist food companies with improved food labelling, help dieticians prepare better dietary plans, support nutraceutical companies with their submissions of health claims and guide consumer choices with regard to food purchases.
The E. coli Metabolome Database (ECMDB) is a freely accessible, online database of small molecule metabolites found in or produced by Escherichia coli. Escherichia coli is perhaps the best studied bacterium on earth and has served as the "model microbe" in microbiology research for more than 60 years. The ECMDB is essentially an E. coli "omics" encyclopedia containing detailed data on the genome, proteome and metabolome of E. coli. ECMDB is part of a suite of organism-specific metabolomics databases that includes DrugBank, HMDB, YMDB and SMPDB. As a metabolomics resource, the ECMDB is designed to facilitate research in the area gut/microbiome metabolomics and environmental metabolomics. The ECMDB contains two kinds of data: 1) chemical data and 2) molecular biology and/or biochemical data. The chemical data includes more than 2700 metabolite structures with detailed metabolite descriptions along with nearly 5000 NMR, GC-MS and LC-MS spectra corresponding to these metabolites. The biochemical data includes nearly 1600 protein sequences and more than 3100 biochemical reactions that are linked to these metabolite entries. Each metabolite entry in the ECMDB contains more than 80 data fields with approximately 65% of the information being devoted to chemical data and the other 35% of the information devoted to enzymatic or biochemical data. Many data fields are hyperlinked to other databases. The ECMDB also has a variety of structure and pathway viewing applets. The ECMDB database offers a number of text, sequence, spectral, chemical structure and relational query searches. These are described in more detail below.
David S. Wishart is a Canadian researcher and a Distinguished University Professor in the Department of Biological Sciences and the Department of Computing Science at the University of Alberta. Wishart also holds cross appointments in the Faculty of Pharmacy and Pharmaceutical Sciences and the Department of Laboratory Medicine and Pathology in the Faculty of Medicine and Dentistry. Additionally, Wishart holds a joint appointment in metabolomics at the Pacific Northwest National Laboratory in Richland, Washington. Wishart is well known for his pioneering contributions to the fields of protein NMR spectroscopy, bioinformatics, cheminformatics and metabolomics. In 2011, Wishart founded the Metabolomics Innovation Centre (TMIC), which is Canada's national metabolomics laboratory.