Information retrieval (IR) in computing and information science is the task of identifying and retrieving information system resources that are relevant to an information need. The information need can be specified in the form of a search query. In the case of document retrieval, queries can be based on full-text or other content-based indexing. Information retrieval is the science of searching for information in a document, searching for documents themselves, and also searching for the metadata that describes data, and for databases of texts, images or sounds.
Question answering (QA) is a computer science discipline within the fields of information retrieval and natural language processing (NLP) that is concerned with building systems that automatically answer questions that are posed by humans in a natural language.
Latent semantic analysis (LSA) is a technique in natural language processing, in particular distributional semantics, of analyzing relationships between a set of documents and the terms they contain by producing a set of concepts related to the documents and terms. LSA assumes that words that are close in meaning will occur in similar pieces of text. A matrix containing word counts per document is constructed from a large piece of text and a mathematical technique called singular value decomposition (SVD) is used to reduce the number of rows while preserving the similarity structure among columns. Documents are then compared by cosine similarity between any two columns. Values close to 1 represent very similar documents while values close to 0 represent very dissimilar documents.
A language model is a probabilistic model of a natural language. In 1980, the first significant statistical language model was proposed, and during the decade IBM performed ‘Shannon-style’ experiments, in which potential sources for language modeling improvement were identified by observing and analyzing the performance of human subjects in predicting or correcting text.
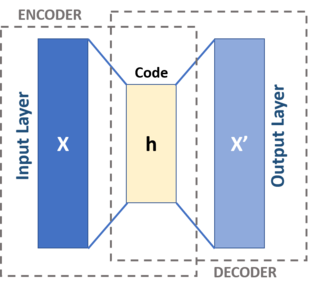
An autoencoder is a type of artificial neural network used to learn efficient codings of unlabeled data. An autoencoder learns two functions: an encoding function that transforms the input data, and a decoding function that recreates the input data from the encoded representation. The autoencoder learns an efficient representation (encoding) for a set of data, typically for dimensionality reduction, to generate lower-dimensional embeddings for subsequent use by other machine learning algorithms.
In statistical classification, the Fisher kernel, named after Ronald Fisher, is a function that measures the similarity of two objects on the basis of sets of measurements for each object and a statistical model. In a classification procedure, the class for a new object can be estimated by minimising, across classes, an average of the Fisher kernel distance from the new object to each known member of the given class.
Query expansion (QE) is the process of reformulating a given query to improve retrieval performance in information retrieval operations, particularly in the context of query understanding. In the context of search engines, query expansion involves evaluating a user's input and expanding the search query to match additional documents. Query expansion involves techniques such as:
Vector space model or term vector model is an algebraic model for representing text documents as vectors such that the distance between vectors represents the relevance between the documents. It is used in information filtering, information retrieval, indexing and relevancy rankings. Its first use was in the SMART Information Retrieval System.
Multimedia information retrieval is a research discipline of computer science that aims at extracting semantic information from multimedia data sources. Data sources include directly perceivable media such as audio, image and video, indirectly perceivable sources such as text, semantic descriptions, biosignals as well as not perceivable sources such as bioinformation, stock prices, etc. The methodology of MMIR can be organized in three groups:
- Methods for the summarization of media content. The result of feature extraction is a description.
- Methods for the filtering of media descriptions
- Methods for the categorization of media descriptions into classes.
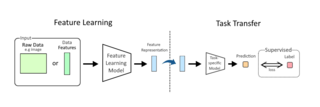
In machine learning (ML), feature learning or representation learning is a set of techniques that allow a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
Multimodal learning is a type of deep learning that integrates and processes multiple types of data, referred to as modalities, such as text, audio, images, or video. This integration allows for a more holistic understanding of complex data, improving model performance in tasks like visual question answering, cross-modal retrieval, text-to-image generation, aesthetic ranking, and image captioning.

Semantic parsing is the task of converting a natural language utterance to a logical form: a machine-understandable representation of its meaning. Semantic parsing can thus be understood as extracting the precise meaning of an utterance. Applications of semantic parsing include machine translation, question answering, ontology induction, automated reasoning, and code generation. The phrase was first used in the 1970s by Yorick Wilks as the basis for machine translation programs working with only semantic representations. Semantic parsing is one of the important tasks in computational linguistics and natural language processing.
Paraphrase or paraphrasing in computational linguistics is the natural language processing task of detecting and generating paraphrases. Applications of paraphrasing are varied including information retrieval, question answering, text summarization, and plagiarism detection. Paraphrasing is also useful in the evaluation of machine translation, as well as semantic parsing and generation of new samples to expand existing corpora.
In natural language processing, a sentence embedding refers to a numeric representation of a sentence in the form of a vector of real numbers which encodes meaningful semantic information.

A transformer is a deep learning architecture developed by researchers at Google and based on the multi-head attention mechanism, proposed in the 2017 paper "Attention Is All You Need". Text is converted to numerical representations called tokens, and each token is converted into a vector via lookup from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism, allowing the signal for key tokens to be amplified and less important tokens to be diminished.
Prompt engineering is the process of structuring an instruction that can be interpreted and understood by a generative artificial intelligence (AI) model. A prompt is natural language text describing the task that an AI should perform. A prompt for a text-to-text language model can be a query such as "what is Fermat's little theorem?", a command such as "write a poem in the style of Edgar Allan Poe about leaves falling", or a longer statement including context, instructions, and conversation history.
A large language model (LLM) is a type of computational model designed for natural language processing tasks such as language generation. As language models, LLMs acquire these abilities by learning statistical relationships from vast amounts of text during a self-supervised and semi-supervised training process.
LangChain is a software framework that helps facilitate the integration of large language models (LLMs) into applications. As a language model integration framework, LangChain's use-cases largely overlap with those of language models in general, including document analysis and summarization, chatbots, and code analysis.
A vector database, vector store or vector search engine is a database that can store vectors along with other data items. Vector databases typically implement one or more Approximate Nearest Neighbor algorithms, so that one can search the database with a query vector to retrieve the closest matching database records.
Learned sparse retrieval or sparse neural search is an approach to Information Retrieval which uses a sparse vector representation of queries and documents. It borrows techniques both from lexical bag-of-words and vector embedding algorithms, and is claimed to perform better than either alone. The best-known sparse neural search systems are SPLADE and its successor SPLADE v2. Others include DeepCT, uniCOIL, EPIC, DeepImpact, TILDE and TILDEv2, Sparta, SPLADE-max, and DistilSPLADE-max.


