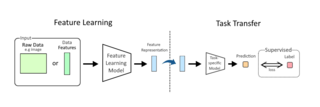
In machine learning, feature learning or representation learning is a set of techniques that allows a system to automatically discover the representations needed for feature detection or classification from raw data. This replaces manual feature engineering and allows a machine to both learn the features and use them to perform a specific task.
In natural language processing, a word embedding is a representation of a word. The embedding is used in text analysis. Typically, the representation is a real-valued vector that encodes the meaning of the word in such a way that the words that are closer in the vector space are expected to be similar in meaning. Word embeddings can be obtained using language modeling and feature learning techniques, where words or phrases from the vocabulary are mapped to vectors of real numbers.
Multimodal learning, in the context of machine learning, is a type of deep learning using multiple modalities of data, such as text, audio, or images.
Word2vec is a technique in natural language processing (NLP) for obtaining vector representations of words. These vectors capture information about the meaning of the word based on the surrounding words. The word2vec algorithm estimates these representations by modeling text in a large corpus. Once trained, such a model can detect synonymous words or suggest additional words for a partial sentence. Word2vec was developed by Tomáš Mikolov and colleagues at Google and published in 2013.
Neural machine translation (NMT) is an approach to machine translation that uses an artificial neural network to predict the likelihood of a sequence of words, typically modeling entire sentences in a single integrated model.
Paraphrase or paraphrasing in computational linguistics is the natural language processing task of detecting and generating paraphrases. Applications of paraphrasing are varied including information retrieval, question answering, text summarization, and plagiarism detection. Paraphrasing is also useful in the evaluation of machine translation, as well as semantic parsing and generation of new samples to expand existing corpora.
In natural language processing, a sentence embedding refers to a numeric representation of a sentence in the form of a vector of real numbers which encodes meaningful semantic information.
Spark NLP is an open-source text processing library for advanced natural language processing for the Python, Java and Scala programming languages. The library is built on top of Apache Spark and its Spark ML library.

A transformer is a deep learning architecture developed by researchers at Google and based on the multi-head attention mechanism, proposed in the 2017 paper "Attention Is All You Need". Text is converted to numerical representations called tokens, and each token is converted into a vector via lookup from a word embedding table. At each layer, each token is then contextualized within the scope of the context window with other (unmasked) tokens via a parallel multi-head attention mechanism, allowing the signal for key tokens to be amplified and less important tokens to be diminished.

Seq2seq is a family of machine learning approaches used for natural language processing. Applications include language translation, image captioning, conversational models, and text summarization. Seq2seq uses sequence transformation: it turns one sequence into another sequence.

ELMo is a word embedding method for representing a sequence of words as a corresponding sequence of vectors. It was created by researchers at the Allen Institute for Artificial Intelligence, and University of Washington and first released in February, 2018. It is a bidirectional LSTM which takes character-level as inputs and produces word-level embeddings.

Attention is a machine learning method that determines the relative importance of each component in a sequence relative to the other components in that sequence. In natural language processing, importance is represented by "soft" weights assigned to each word in a sentence. More generally, attention encodes vectors called token embeddings across a fixed-width sequence that can range from tens to millions of tokens in size.

Contrastive Language-Image Pre-training (CLIP) is a technique for training a pair of neural network models, one for image understanding and one for text understanding, using a contrastive objective. This method has enabled broad applications across multiple domains, including cross-modal retrieval, text-to-image generation, aesthetic ranking, and image captioning.

A vision transformer (ViT) is a transformer designed for computer vision. A ViT decomposes an input image into a series of patches, serializes each patch into a vector, and maps it to a smaller dimension with a single matrix multiplication. These vector embeddings are then processed by a transformer encoder as if they were token embeddings.
Perceiver is a transformer adapted to be able to process non-textual data, such as images, sounds and video, and spatial data. Transformers underlie other notable systems such as BERT and GPT-3, which preceded Perceiver. It adopts an asymmetric attention mechanism to distill inputs into a latent bottleneck, allowing it to learn from large amounts of heterogeneous data. Perceiver matches or outperforms specialized models on classification tasks.
Prompt engineering is the process of structuring an instruction that can be interpreted and understood by a generative artificial intelligence (AI) model. A prompt is natural language text describing the task that an AI should perform: a prompt for a text-to-text language model can be a query such as "what is Fermat's little theorem?", a command such as "write a poem in the style of Edgar Allan Poe about leaves falling", or a longer statement including context, instructions, and conversation history.
A large language model (LLM) is a type of computational model designed for natural language processing tasks such as language generation. As language models, LLMs acquire these abilities by learning statistical relationships from vast amounts of text during a self-supervised and semi-supervised training process.

"Attention Is All You Need" is a 2017 landmark research paper in machine learning authored by eight scientists working at Google. The paper introduced a new deep learning architecture known as the transformer, based on the attention mechanism proposed in 2014 by Bahdanau et al. It is considered a foundational paper in modern artificial intelligence, as the transformer approach has become the main architecture of large language models like those based on GPT. At the time, the focus of the research was on improving Seq2seq techniques for machine translation, but the authors go further in the paper, foreseeing the technique's potential for other tasks like question answering and what is now known as multimodal Generative AI.
T5 is a series of large language models developed by Google AI introduced in 2019. Like the original Transformer model, T5 models are encoder-decoder Transformers, where the encoder processes the input text, and the decoder generates the output text.
The Latent Diffusion Model (LDM) is a diffusion model architecture developed by the CompVis group at LMU Munich.









 Sentiment classification
Sentiment classification Sentence classification
Sentence classification Answering multiple-choice questions
Answering multiple-choice questions







