
A hard disk drive (HDD), hard disk, hard drive, or fixed disk is an electro-mechanical data storage device that stores and retrieves digital data using magnetic storage with one or more rigid rapidly rotating platters coated with magnetic material. The platters are paired with magnetic heads, usually arranged on a moving actuator arm, which read and write data to the platter surfaces. Data is accessed in a random-access manner, meaning that individual blocks of data can be stored and retrieved in any order. HDDs are a type of non-volatile storage, retaining stored data when powered off. Modern HDDs are typically in the form of a small rectangular box.
RAID is a data storage virtualization technology that combines multiple physical disk drive components into one or more logical units for the purposes of data redundancy, performance improvement, or both. This is in contrast to the previous concept of highly reliable mainframe disk drives referred to as "single large expensive disk" (SLED).

The ST-506 and ST-412 were early hard disk drive products introduced by Seagate in 1980 and 1981 respectively, that later became construed as hard disk drive interfaces: the ST-506 disk interface and the ST-412 disk interface. Compared to the ST-506 precursor, the ST-412 implemented a refinement to the seek speed, and increased the drive capacity from 5 MB to 10 MB, but was otherwise highly similar.
Disk formatting is the process of preparing a data storage device such as a hard disk drive, solid-state drive, floppy disk, memory card or USB flash drive for initial use. In some cases, the formatting operation may also create one or more new file systems. The first part of the formatting process that performs basic medium preparation is often referred to as "low-level formatting". Partitioning is the common term for the second part of the process, dividing the device into several sub-devices and, in some cases, writing information to the device allowing an operating system to be booted from it. The third part of the process, usually termed "high-level formatting" most often refers to the process of generating a new file system. In some operating systems all or parts of these three processes can be combined or repeated at different levels and the term "format" is understood to mean an operation in which a new disk medium is fully prepared to store files. Some formatting utilities allow distinguishing between a quick format, which does not erase all existing data and a long option that does erase all existing data.

Mount Rainier (MRW) is a format for writable optical discs which provides the packet writing and defect management. Its goal is the replacement of the floppy disk. It is named after Mount Rainier, a volcano near Seattle, Washington, United States.
dd is a command-line utility for Unix, Plan 9, Inferno, and Unix-like operating systems and beyond, the primary purpose of which is to convert and copy files. On Unix, device drivers for hardware and special device files appear in the file system just like normal files; dd can also read and/or write from/to these files, provided that function is implemented in their respective driver. As a result, dd can be used for tasks such as backing up the boot sector of a hard drive, and obtaining a fixed amount of random data. The dd program can also perform conversions on the data as it is copied, including byte order swapping and conversion to and from the ASCII and EBCDIC text encodings.

Self-Monitoring, Analysis, and Reporting Technology is a monitoring system included in computer hard disk drives (HDDs) and solid-state drives (SSDs). Its a primary function is to detect and report various indicators of drive reliability, or how long a drive can function while anticipating imminent hardware failures.

Data corruption refers to errors in computer data that occur during writing, reading, storage, transmission, or processing, which introduce unintended changes to the original data. Computer, transmission, and storage systems use a number of measures to provide end-to-end data integrity, or lack of errors.
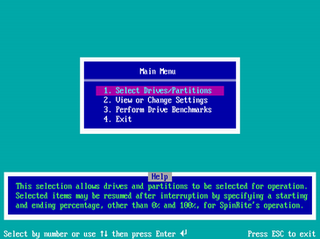
SpinRite is a computer program for scanning RAS Random Access Storage devices such as hard disks, reading and rewriting data to resolve and retrieve data that is unreadable by DOS or Windows. The first version was released in 1987 by Steve Gibson. The current version, 6.1, was released in 2024.

The USB mass storage device class is a set of computing communications protocols, specifically a USB Device Class, defined by the USB Implementers Forum that makes a USB device accessible to a host computing device and enables file transfers between the host and the USB device. To a host, the USB device acts as an external hard drive; the protocol set interfaces with a number of storage devices.
In computing, data recovery is a process of retrieving deleted, inaccessible, lost, corrupted, damaged, or formatted data from secondary storage, removable media or files, when the data stored in them cannot be accessed in a usual way. The data is most often salvaged from storage media such as internal or external hard disk drives (HDDs), solid-state drives (SSDs), USB flash drives, magnetic tapes, CDs, DVDs, RAID subsystems, and other electronic devices. Recovery may be required due to physical damage to the storage devices or logical damage to the file system that prevents it from being mounted by the host operating system (OS).
Data scrubbing is an error correction technique that uses a background task to periodically inspect main memory or storage for errors, then corrects detected errors using redundant data in the form of different checksums or copies of data. Data scrubbing reduces the likelihood that single correctable errors will accumulate, leading to reduced risks of uncorrectable errors.
sync is a standard system call in the Unix operating system, which commits all data from the kernel filesystem buffers to non-volatile storage, i.e., data which has been scheduled for writing via low-level I/O system calls. Higher-level I/O layers such as stdio may maintain separate buffers of their own.

A hard disk drive failure occurs when a hard disk drive malfunctions and the stored information cannot be accessed with a properly configured computer.
In computing, error recovery control (ERC) is a feature of hard disks which allow a system administrator to configure the amount of time a drive's firmware is allowed to spend recovering from a read or write error. Limiting the recovery time allows for improved error handling in hardware or software RAID environments. In some cases, there is a conflict as to whether error handling should be undertaken by the hard drive or by the RAID implementation, which leads to drives being marked as unusable and significant performance degradation, when this could otherwise have been avoided.
badblocks is a Linux utility to check for bad sectors on a disk drive. It can create a text file with list of these sectors that can be used with other programs, like mkfs, so that they are not used in the future and thus do not cause corruption of data. It is part of the e2fsprogs project, and a port is available for BSD operating systems.

A forensic disk controller or hardware write-block device is a specialized type of computer hard disk controller made for the purpose of gaining read-only access to computer hard drives without the risk of damaging the drive's contents. The device is named forensic because its most common application is for use in investigations where a computer hard drive may contain evidence. Such a controller historically has been made in the form of a dongle that fits between a computer and an IDE or SCSI hard drive, but with the advent of USB and SATA, forensic disk controllers supporting these newer technologies have become widespread. Steve Bress and Mark Menz invented hard drive write blocking.
SCSI / ATA Translation (SAT) is a set of standards developed by the T10 subcommittee, defining how to communicate with ATA devices through a SCSI application layer. The standard attempts to be consistent with the SCSI architectural model, the SCSI Primary Commands, and the SCSI Block Commands standards.
A trim command allows an operating system to inform a solid-state drive (SSD) which blocks of data are no longer considered to be "in use" and therefore can be erased internally.
Shingled magnetic recording (SMR) is a magnetic storage data recording technology used in hard disk drives (HDDs) to increase storage density and overall per-drive storage capacity. Conventional hard disk drives record data by writing non-overlapping concentric magnetic tracks, while shingled recording writes new tracks that overlap part of the previously written magnetic track, leaving the previous track narrower and allowing higher track density. Thus, the tracks partially overlap similar to roof shingles. This approach was selected because, if the writing head is made too narrow, it cannot provide the very high fields required in the recording layer of the disk.
