CN108446741B - 机器学习超参数重要性评估方法、系统及存储介质 - Google Patents
机器学习超参数重要性评估方法、系统及存储介质 Download PDFInfo
- Publication number
- CN108446741B CN108446741B CN201810270934.5A CN201810270934A CN108446741B CN 108446741 B CN108446741 B CN 108446741B CN 201810270934 A CN201810270934 A CN 201810270934A CN 108446741 B CN108446741 B CN 108446741B
- Authority
- CN
- China
- Prior art keywords
- data set
- meta
- parameter
- hyper
- samples
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
本发明公开了机器学习超参数重要性评估方法、系统及存储介质,获取OpenML中不同的数据集,并提取元特征来表示每个数据集,同时收集待评估分类算法在不同超参配置下性能的数据;提取元特征来表示使用的目标数据集,并通过计算元特征之间的距离获得目标数据集与历史数据集之间距离的递增序列;使用待评估分类算法不同超参的性能数据来评估超参重要性,根据历史数据集与目标数据集距离递增的有序序列,对距离目标数据集较近的前m个历史数据集依次执行提出的Relief和聚类算法,最终获得待评估分类算法的超参重要性排序并指导的自动化调参过程。本发明对于分类算法黑盒的超参调整给予一定的指导,从而达到节省时间,提高效率的目的。
Description
技术领域
本发明是机器学习超参数重要性评估方法、系统及存储介质。
背景技术
机器学习为数据处理和数据分类提供了重要的技术支撑,然而模型选择和调参依然是困扰用户的两大难题,于是自动化机器学习系统应运而生。自动化机器学习系统利用自动化机器学习算法达到了自动化数据预处理,自动化选择算法,自动化调参的目的,提高了数据分类预测的准确性,同时将用户从选择算法和反复调参的繁重任务中解脱出来。
由于自动化机器学习的核心是自动化算法选择及自动化超参配置,因此该系统将机器学习过程归约成了算法选择和超参优化(Combined Algorithm Selection andHyper-parameter optimization,CASH)问题。CASH问题即把算法的选择当做根层次的新的超参数,从而将选择算法和超参数值的问题映射到选择超参值的问题。通过将数据预处理和特征选择技术作为超参数,系统可以自动选择数据预处理和特征选择技术。最终归结为的超参优化问题可以通过经典的贝叶斯优化算法找到最优解,从而达到提升数据分类预测精度的效果。
然而目前的自动化机器学习系统的超参配置模块的配置过程全凭经验,或者通过反复迭代得到最后的结果来对若干个超参数的配置进行一一调整,这样存在的缺陷是:浪费机器学习的时间,而且反复迭代也浪费计算机资源,不分重要性地对所有超参数的配置进行调整会浪费用户的时间和精力。
发明内容
本发明是机器学习超参数重要性评估方法、系统及存储介质,所要解决的技术问题是如何准确评估机器学习算法的超参重要性,并将其用于指导自动化超参配置以及增强超参配置的可解释性问题。
作为本发明的第一方面:
机器学习超参数重要性评估方法,包括:
步骤(1):从开放式机器学习环境OpenML中获取与目标数据集类型相似的若干新数据集,并对每个新数据集提取元特征向量,使得每个新数据集都用元特征向量来表示;
从开放式机器学习环境OpenML中收集待评估分类算法在不同超参数配置下性能的数据;
将每个新数据集的元特征向量以及不同超参数配置对应的性能数据存储于对应的历史数据集中;
步骤(2):提取目标数据集的元特征向量来表示目标数据集,计算目标数据集元特征向量与历史数据集元特征向量之间的距离,获得目标数据集与每个历史数据集之间距离由近至远的距离序列;
步骤(3):对距离目标数据集最近的前f个历史数据集依次执行Relief-Cluster算法:通过Relief算法得到的每类超参数的权重,进一步计算每类超参数的平均权重,利用每类超参数的平均权重初步得到每类超参数重要性权重排序;利用聚类算法进一步验证超参数重要性评估的准确性;最后,得到待评估分类算法的超参数重要性排序。
所述机器学习超参数重要性评估方法,包括以下步骤:
步骤(4):根据得到的待评估分类算法的超参数重要性排序,对重要性排序靠前的若干个参数进行设置,然后,利用设置好参数的分类算法对待分类数据进行分类。
所述步骤(1)中,每个数据集Di被描述为由F个元特征表示的向量
所述步骤(1)中,元特征,包括:简单的元特征、数据集的统计元特征和重要性元特征;
所述简单的元特征,包括:数据集样本数量、特征数量、类别数量或缺失值数量;
所述数据集的统计元特征,包括:平均值、方差或距离向量的峰度;
重要性元特征,包括:在数据集上运行机器学习算法获得的性能。
所述步骤(1)中待评估分类算法在不同超参数配置下的性能,包括:错误分类率或者RMSE;
另外,对于许多常见算法,开放式机器学习环境OpenML已经包含了非常全面的性能数据,适用于各种数据集上的不同超参数配置,即收集数据集Di在待评估分类算法下的超参配置θi及性能yi数据
对于目标数据集DN',提取元特征VN'来表示目标数据集,并基于不相似的数据集其使用算法的超参数配置也具有差异这一原则,利用元特征向量之间的距离获得目标数据集与历史数据集之间的距离序列。对距离目标数据集近的前f个历史数据集,使用算法在不同超参数的性能数据来评估超参数重要性;
利用元特征向量之间的距离来衡量目标数据集DN'与历史数据集Di之间的距离dpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn
其中,VN'表示数据集DN'的元特征向量,Vi表示历史数据集Di的元特征向量,pn表示p范数。
通过目标数据集与历史数据集元特征向量之间的距离比较,得到历史数据集与目标数据集距离由近至远的排序序列π(1),...,π(N),其中
根据历史数据集与目标数据集距离由近至远的排序队列π(1),...,π(N),对距离目标数据集较近的前f个历史数据集依次执行Relief-Cluster算法。首先通过Relief算法得到的每类超参的平均权重来初步评估超参重要性,然后利用聚类算法的r(C)指标进一步验证超参重要性评估的准确性,重复以上两步m次,选择r(C)指标最大时对应的超参重要性评估结果,最后得到待评估分类算法的超参重要性排序,转而用于指导目标数据集在待评估分类算法的自动化调参过程。
所述通过Relief算法得到的每类超参数的权重包括:
根据不同超参数配置下的性能数据大小设置阈值,将历史数据集中不同超参数配置对应的性能数据分为高性能样本和低性能样本,Relief算法首先从性能数据中随机选择一个样本si,然后从性能高样本和性能差样本中各选择一个距离si最近的样本;
与si同类的样本sj用M表示,与si不同类的样本sj用Q表示,每类超参数h的权重wh根据公式(1)更新:
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,si,M)表示两个样本si与M在超参数h上的差异;
diff(h,si,Q)表示两个样本si与Q在超参数h上的差异;
两个样本si与sj在超参数h上的差异diff(h,si,sj)定义为:
若超参数h为标量型超参数,
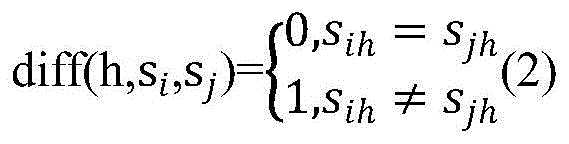
若超参数h为数值型超参数,
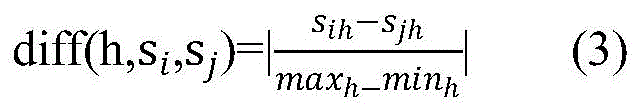
其中,1≤i≠j≤m,1≤h≤ph,maxh为超参数h在样本集中的最大值,minh为超参数h在样本集中的最小值,m表示样本数,每个样本包含ph个超参数,rt表示迭代次数,rt>1,为了避免一次抽样的随机性;sih表示在样本si上超参h的值,sjh表示在样本sj上超参h的值。
由公式(1)可知,对于高性能贡献大的超参数表现为在异类间差异大而在同类间差异小,因此具有区分能力的超参数的权值为正值。
为避免一次抽样的随机性,迭代进行rt>1次,得到每类超参的重要性权重排序。
所述利用聚类算法进一步验证超参数重要性评估的准确性包括:
根据得到的每类超参数的重要性权重排序,对位于前k类的超参数进行聚类,并计算超参数重要性,假设超参数样本集为S,T为超参数样本集合的大小,K为超参数样本所属类的个数,pik表示样本隶属于类k的概率,Ck表示超参数样本的实际类标签,C表示超参数集,则在C的重要性度量r(C)表示为:



其中,F(C)表示在超参数集C上聚类的结果与类标签在整个超参数样本集上的差异,C代表超参数集,Fi(C)表示在超参数集C上聚类的结果与类标签在各个类内的差异,Xi表示第i个类的超参数样本集合。
r(C)值越高,聚类结果与实际类标签之间的相关度越大,超参数集C对分类的影响越大。选择r(C)指标最大时对应的超参重要性评估结果。
类标签是指性能高和性能低的标签。
作为本发明的第二方面,
机器学习超参数重要性评估系统,包括:存储器、处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成上述任一方法所述的步骤。
作为本发明的第三方面,
一种计算机可读存储介质,其上运行有计算机指令,所述计算机指令被处理器运行时,完成上述任一方法所述的步骤。
本发明的有益效果:
本发明可以准确评估机器学习算法的超参重要性,用于指导自动化超参配置以及增强超参配置的可解释性问题。用于描述机器学习算法本身的超参重要性,为超参配置过程提供有效借鉴和良好的可解释性。此模块着重解决的技术问题为如何准确评估机器学习算法的超参重要性,并将其用于指导自动化超参配置以及增强超参配置的可解释性问题。
(1)节约资源,节省时间,通过提供合适的先验知识,缩小搜索空间,使得超参配置过程具有一定的指导性,摆脱以往完全黑盒的状态。
(2)同时可以让用户直观的了解哪类超参数对算法性能影响更大。
附图说明
构成本申请的一部分的说明书附图用来提供对本申请的进一步理解,本申请的示意性实施例及其说明用于解释本申请,并不构成对本申请的不当限定。
图1为本发明提供的流程图;
具体实施方式
应该指出,以下详细说明都是例示性的,旨在对本申请提供进一步的说明。除非另有指明,本文使用的所有技术和科学术语具有与本申请所属技术领域的普通技术人员通常理解的相同含义。
本发明充分利用开放式机器学习环境OpenML中的多个数据集以及其每个数据集在多种算法下的性能数据,结合元学习方法计算目标数据集与历史数据集的距离,并利用Relief算法和聚类算法得到待评估分类算法每类超参数的重要性排序,排序结果转而用于指导目标数据集在待评估分类算法的自动化调参过程。本发明为提供合适的先验知识,缩小搜索空间,使得超参配置过程具有一定的指导性,摆脱以往完全黑盒的状态;同时可以让用户直观的了解哪类超参数对算法性能影响更大。
如图1所示,本发明包括以下步骤:
步骤A、获取OpenML中不同的数据集,并对每个数据集提取元特征,使得每个数据集都可以用元特征来表示,同时收集待评估分类算法在不同超参配置θi下性能yi(例如,错误分类率或者RMSE)的数据 并将每个数据集的元特征向量以及不同超参配置对应的性能数据存储于历史数据集样本库;
并将每个数据集的元特征向量以及不同超参配置对应的性能数据存储于历史数据集样本库;
在步骤A中提取的元特征主要包括:简单的元特征(例如,数据集样本数量,特征数量,类别数量,缺失值数量等)、数据集的统计元特征(例如,平均值,方差,距离向量的峰度等)、重要性元特征(例如在数据集上运行机器学习算法获得的性能等信息)这三大部分。
步骤B、对于我们使用的目标数据集,我们也提取元特征来表示目标数据集,并基于不相似的数据集其使用算法的超参配置也具有差异这一原则,利用元特征向量之间的距离获得目标数据集与历史数据集之间的距离序列。对距离目标数据集较近的前f个历史数据集,我们可以使用待评估分类算法不同超参的性能数据来评估超参重要性;
在步骤B中,利用元特征向量之间的距离来衡量目标数据集DN'与历史数据集Di(i=1,2,…N)之间的距离,其中的距离公式我们使用的是衡量数据集元特征向量之间差异的常用p-范数:dpn(DN′,Di)=||VN′-Vi||pn。通过目标数据集与历史数据集元特征向量之间的距离比较,我们可以得到历史数据集与目标数据集距离由近至远的排序序列π(1),...,π(N),其中
步骤C、根据历史数据集与目标数据集距离由近至远的有序序列,对距离目标数据集较近的前f个历史数据集依次执行我们提出的Relief-Cluster算法。首先通过Relief算法得到的每类超参的平均权重来初步评估超参重要性,然后利用聚类算法的r(C)指标进一步验证超参重要性评估的准确性,重复以上两步m次,选择r(C)指标最大时对应的超参重要性评估结果,最后得到待评估分类算法的超参重要性排序转而用于指导目标数据集在待评估分类算法的自动化调参过程。
在本发明中,步骤C具体包括以下步骤:
步骤C1、我们根据不同超参配置下的性能数据大小设置阈值将数据分为性能高的一类和性能差的一类,Relief算法首先从超参样本集合中随机选择一个样本si,然后从两类样本中各选择一个距离si最近的样本。与si同类的样本用M表示,与si不同类的样本用Q表示,每类超参h的权重wh根据公式(1)更新:
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
上述公式中,两个样本si与sj(1≤i≠j≤m)在超参h(1≤h≤ph)上的差定义为:
若超参h为标量型超参,

若超参h为数值型超参,

其中,maxh和minh分别为超参h在样本集中的最大值和最小值。
由公式(1)可知,对于高性能贡献较大的超参应该表现为在异类间差异较大而在同类间差异较小,因此具有区分能力的超参的权值应为正值。为避免一次抽样的随机性,上述过程迭代进行rt>1次。
步骤C2、根据上步得到的每类超参的重要性权重排序,我们对位于前k类的超参进行聚类,并计算特征重要性,假设超参样本集为S,T为超参样本集合的大小,K为超参样本所属类的个数,pik表示样本隶属于类k的概率,Ck表示超参样本的实际类标号,C表示超参子集,则在C的重要性度量r(C)可以表示为:

其中F(C)表示在超参集C上聚类的结果与类标签在整个超参样本集上的差异,C代表超参子集,Fi(C)表示各个类内的差异,Xi表示第i个类的超参样本集合。r(C)值越高,聚类结果与实际类标签之间的相关度越大,超参集C对分类的影响越大。
对以上两步迭代m次,选取r(C)最大时对应的超参重要性排序,最后将得到的超参重要性排序结果转而用于指导目标数据集在待评估分类算法的自动化调参过程。
本发明中Relief-Cluster算法的流程图:
输入:超参数样本集S,超参数类别数hc,取样/迭代次数rt
输出:聚类评价指标r(C),超参数重要性权重矩阵W

从S中随机选择一个样本si;
从与si同类的样本中选择与si最近的一个近邻,记为M;
从与si异类的样本中选择与si最近的一个近邻,记为N;
采用公式(1)更新超参重要性权重向量W;
选取大小为X的超参子集;
在超参子集上对样本聚类;
计算聚类结果与实际结果的相关度r(C)
从m个r(C)中选取值最大时对应的超参重要性排序;
End
以上所述仅为本申请的优选实施例而已,并不用于限制本申请,对于本领域的技术人员来说,本申请可以有各种更改和变化。凡在本申请的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本申请的保护范围之内。
Claims (18)
1.基于机器学习超参数重要性评估的待分类数据分类系统,其特征是,包括:
历史数据集获取模块,其被配置为:从开放式机器学习环境OpenML中获取与目标数据集类型相似的若干新数据集,并对每个新数据集提取元特征,使得每个新数据集都用元特征向量来表示;
从开放式机器学习环境OpenML中收集待评估分类算法在不同超参数配置下性能的数据;
将每个新数据集的元特征向量以及不同超参数配置对应的性能数据存储于对应的历史数据集中;
距离序列获取模块,其被配置为:提取目标数据集的元特征向量来表示目标数据集,计算目标数据集元特征向量与历史数据集元特征向量之间的距离,获得目标数据集与每个历史数据集之间距离由近至远的距离序列;
输出模块,其被配置为:对距离目标数据集最近的前f个历史数据集依次执行Relief-Cluster算法:通过Relief算法得到的每类超参数的权重,进一步计算每类超参数的平均权重,利用每类超参数的平均权重初步得到每类超参数重要性权重排序;利用聚类算法进一步验证超参数重要性评估的准确性;最后,得到待评估分类算法的超参数重要性排序;
分类模块,其被配置为:根据得到的待评估分类算法的超参数重要性排序,对重要性排序靠前的若干个参数进行设置,然后,利用设置好参数的分类算法对待分类数据进行分类。
2.如权利要求1所述的系统,其特征是,所述历史数据集获取模块中,每个数据集Di被描述为由F个元特征表示的向量
3.如权利要求1所述的系统,其特征是,所述历史数据集获取模块中,元特征,包括:简单的元特征、数据集的统计元特征和重要性元特征;
所述简单的元特征,包括:数据集样本数量、特征数量、类别数量或缺失值数量;
所述数据集的统计元特征,包括:平均值、方差或距离向量的峰度;
所述重要性元特征,包括:在数据集上运行机器学习算法获得的性能。
4.如权利要求1所述的系统,其特征是,所述历史数据集获取模块中待评估分类算法在不同超参数配置下的性能,包括:错误分类率或者RMSE。
5.如权利要求1所述的系统,其特征是,利用元特征向量之间的距离来衡量目标数据集DN+1与历史数据集Di之间的距离dpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn
其中,VN′表示目标数据集DN′的元特征向量,Vi表示历史数据集Di的元特征向量,pn表示p范数;
通过目标数据集与历史数据集元特征向量之间的距离比较,得到历史数据集与目标数据集距离由近至远的排序序列π(1),...,π(N)。
6.如权利要求1所述的系统,其特征是,
所述通过Relief算法得到的每类超参数的权重包括:
根据不同超参数配置下的性能数据大小设置阈值,将历史数据集中不同超参数配置对应的性能数据分为高性能样本和低性能样本,Relief算法首先从性能数据中随机选择一个样本si,然后从性能高样本和性能差样本中各选择一个距离si最近的样本;
与si同类的样本sj用M表示,与si不同类的样本sj用Q表示,每类超参数h的权重wh根据公式(1)更新:
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,si,M)表示两个样本si与M在超参数h上的差异;
diff(h,si,Q)表示两个样本si与Q在超参数h上的差异;
两个样本si与sj在超参数h上的差异diff(h,si,sj)定义为:
若超参数h为标量型超参数,

若超参数h为数值型超参数,

其中,1≤i≠j≤m,1≤h≤ph,maxh为超参数h在样本集中的最大值,minh为超参数h在样本集中的最小值,m表示样本数,每个样本包含ph个超参数,rt表示迭代次数,rt>1,sih表示在样本si上超参h的值,sjh表示在样本sj上超参h的值。
7.基于机器学习超参数重要性评估的待分类数据分类系统,其特征是,包括:存储器、处理器以及存储在存储器上并在处理器上运行的计算机指令,所述计算机指令被处理器运行时,完成以下步骤:
步骤(1):从开放式机器学习环境OpenML中获取与目标数据集类型相似的若干新数据集,并对每个新数据集提取元特征,使得每个新数据集都用元特征向量来表示;
从开放式机器学习环境OpenML中收集待评估分类算法在不同超参数配置下性能的数据;
将每个新数据集的元特征向量以及不同超参数配置对应的性能数据存储于对应的历史数据集中;
步骤(2):提取目标数据集的元特征向量来表示目标数据集,计算目标数据集元特征向量与历史数据集元特征向量之间的距离,获得目标数据集与每个历史数据集之间距离由近至远的距离序列;
步骤(3):对距离目标数据集最近的前f个历史数据集依次执行Relief-Cluster算法:通过Relief算法得到的每类超参数的权重,进一步计算每类超参数的平均权重,利用每类超参数的平均权重初步得到每类超参数重要性权重排序;利用聚类算法进一步验证超参数重要性评估的准确性;最后,得到待评估分类算法的超参数重要性排序;
步骤(4):根据得到的待评估分类算法的超参数重要性排序,对重要性排序靠前的若干个参数进行设置,然后,利用设置好参数的分类算法对待分类数据进行分类。
8.如权利要求7所述的系统,其特征是,所述步骤(1)中,每个数据集Di被描述为由F个元特征表示的向量
9.如权利要求7所述的系统,其特征是,所述步骤(1)中,元特征,包括:简单的元特征、数据集的统计元特征和重要性元特征;
所述简单的元特征,包括:数据集样本数量、特征数量、类别数量或缺失值数量;
所述数据集的统计元特征,包括:平均值、方差或距离向量的峰度;
所述重要性元特征,包括:在数据集上运行机器学习算法获得的性能。
10.如权利要求7所述的系统,其特征是,所述步骤(1)中待评估分类算法在不同超参数配置下的性能,包括:错误分类率或者RMSE。
11.如权利要求7所述的系统,其特征是,利用元特征向量之间的距离来衡量目标数据集DN+1与历史数据集Di之间的距离dpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn;
其中,VN′表示目标数据集DN′的元特征向量,Vi表示历史数据集Di的元特征向量,pn表示p范数;
通过目标数据集与历史数据集元特征之间的距离比较,得到历史数据集与目标数据集距离由近至远的排序序列π(1),...,π(N)。
12.如权利要求7所述的系统,其特征是,
所述通过Relief算法得到的每类超参数的权重包括:
根据不同超参数配置下的性能数据大小设置阈值,将历史数据集中不同超参数配置对应的性能数据分为高性能样本和低性能样本,Relief算法首先从性能数据中随机选择一个样本si,然后从性能高样本和性能差样本中各选择一个距离si最近的样本;
与si同类的样本sj用M表示,与si不同类的样本sj用Q表示,每类超参数h的权重wh根据公式(1)更新:
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,si,M)表示两个样本si与M在超参数h上的差异;
diff(h,si,Q)表示两个样本si与Q在超参数h上的差异;
两个样本si与sj在超参数h上的差异diff(h,si,sj)定义为:
若超参数h为标量型超参数,
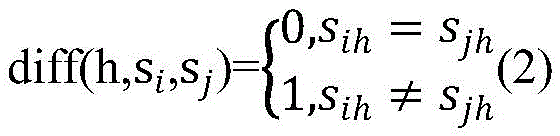
若超参数h为数值型超参数,

其中,1≤i≠j≤m,1≤h≤ph,maxh为超参数h在样本集中的最大值,minh为超参数h在样本集中的最小值,m表示样本数,每个样本包含ph个超参数,rt表示迭代次数,rt>1,sih表示在样本si上超参h的值,sjh表示在样本sj上超参h的值。
13.一种计算机可读存储介质,其特征是,其上运行有计算机指令,所述计算机指令被处理器运行时,完成以下步骤:
步骤(1):从开放式机器学习环境OpenML中获取与目标数据集类型相似的若干新数据集,并对每个新数据集提取元特征,使得每个新数据集都用元特征向量来表示;
从开放式机器学习环境OpenML中收集待评估分类算法在不同超参数配置下性能的数据;
将每个新数据集的元特征向量以及不同超参数配置对应的性能数据存储于对应的历史数据集中;
步骤(2):提取目标数据集的元特征向量来表示目标数据集,计算目标数据集元特征向量与历史数据集元特征向量之间的距离,获得目标数据集与每个历史数据集之间距离由近至远的距离序列;
步骤(3):对距离目标数据集最近的前f个历史数据集依次执行Relief-Cluster算法:通过Relief算法得到的每类超参数的权重,进一步计算每类超参数的平均权重,利用每类超参数的平均权重初步得到每类超参数重要性权重排序;利用聚类算法进一步验证超参数重要性评估的准确性;最后,得到待评估分类算法的超参数重要性排序;
步骤(4):根据得到的待评估分类算法的超参数重要性排序,对重要性排序靠前的若干个参数进行设置,然后,利用设置好参数的分类算法对待分类数据进行分类。
14.如权利要求13所述的介质,其特征是,所述步骤(1)中,每个数据集Di被描述为由F个元特征表示的向量
15.如权利要求13所述的介质,其特征是,所述步骤(1)中,元特征,包括:简单的元特征、数据集的统计元特征和重要性元特征;
所述简单的元特征,包括:数据集样本数量、特征数量、类别数量或缺失值数量;
所述数据集的统计元特征,包括:平均值、方差或距离向量的峰度;
所述重要性元特征,包括:在数据集上运行机器学习算法获得的性能。
16.如权利要求13所述的介质,其特征是,所述步骤(1)中待评估分类算法在不同超参数配置下的性能,包括:错误分类率或者RMSE。
17.如权利要求13所述的介质,其特征是,利用元特征向量之间的距离来衡量目标数据集DN+1与历史数据集Di之间的距离dpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn;
其中,VN′表示目标数据集DN′的元特征向量,Vi表示历史数据集Di的元特征向量,pn表示p范数;
通过目标数据集与历史数据集元特征向量之间的距离比较,得到历史数据集与目标数据集距离由近至远的排序序列π(1),...,π(N)。
18.如权利要求13所述的介质,其特征是,所述通过Relief算法得到的每类超参数的权重包括:
根据不同超参数配置下的性能数据大小设置阈值,将历史数据集中不同超参数配置对应的性能数据分为高性能样本和低性能样本,Relief算法首先从性能数据中随机选择一个样本si,然后从性能高样本和性能差样本中各选择一个距离si最近的样本;
与si同类的样本sj用M表示,与si不同类的样本sj用Q表示,每类超参数h的权重wh根据公式(1)更新:
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,si,M)表示两个样本si与M在超参数h上的差异;
diff(h,si,Q)表示两个样本si与Q在超参数h上的差异;
两个样本si与sj在超参数h上的差异diff(h,si,sj)定义为:
若超参数h为标量型超参数,
若超参数h为数值型超参数,

其中,1≤i≠j≤m,1≤h≤ph,maxh为超参数h在样本集中的最大值,minh为超参数h在样本集中的最小值,m表示样本数,每个样本包含ph个超参数,rt表示迭代次数,rt>1,sih表示在样本si上超参h的值,sjh表示在样本sj上超参h的值。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810270934.5A CN108446741B (zh) | 2018-03-29 | 2018-03-29 | 机器学习超参数重要性评估方法、系统及存储介质 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810270934.5A CN108446741B (zh) | 2018-03-29 | 2018-03-29 | 机器学习超参数重要性评估方法、系统及存储介质 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108446741A CN108446741A (zh) | 2018-08-24 |
| CN108446741B true CN108446741B (zh) | 2020-01-07 |
Family
ID=63197670
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810270934.5A Active CN108446741B (zh) | 2018-03-29 | 2018-03-29 | 机器学习超参数重要性评估方法、系统及存储介质 |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108446741B (zh) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6892424B2 (ja) * | 2018-10-09 | 2021-06-23 | 株式会社Preferred Networks | ハイパーパラメータチューニング方法、装置及びプログラム |
| CN109447277B (zh) * | 2018-10-19 | 2023-11-10 | 厦门渊亭信息科技有限公司 | 一种通用的机器学习超参黑盒优化方法及系统 |
| CN109460825A (zh) * | 2018-10-24 | 2019-03-12 | 阿里巴巴集团控股有限公司 | 用于构建机器学习模型的特征选取方法、装置以及设备 |
| CN111160459A (zh) * | 2019-12-30 | 2020-05-15 | 上海依图网络科技有限公司 | 超参数的优化装置和方法 |
| CN111260243A (zh) * | 2020-02-10 | 2020-06-09 | 京东数字科技控股有限公司 | 风险评估方法、装置、设备及计算机可读存储介质 |
| CN111401567A (zh) * | 2020-03-20 | 2020-07-10 | 厦门渊亭信息科技有限公司 | 一种通用的深度学习超参优化方法及装置 |
| CN111539536B (zh) * | 2020-06-19 | 2020-10-23 | 支付宝(杭州)信息技术有限公司 | 一种评估业务模型超参数的方法和装置 |
| CN111917648B (zh) * | 2020-06-30 | 2021-10-26 | 华南理工大学 | 一种数据中心里分布式机器学习数据重排的传输优化方法 |
| CN113760188A (zh) * | 2021-07-30 | 2021-12-07 | 浪潮电子信息产业股份有限公司 | 一种分布式存储系统的调参选择方法、系统及装置 |
| CN114490094B (zh) * | 2022-04-18 | 2022-07-12 | 北京麟卓信息科技有限公司 | 一种基于机器学习的gpu显存分配方法及系统 |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105531725A (zh) * | 2013-06-28 | 2016-04-27 | D-波系统公司 | 用于对数据进行量子处理的系统和方法 |
| CN105701509A (zh) * | 2016-01-13 | 2016-06-22 | 清华大学 | 一种基于跨类别迁移主动学习的图像分类方法 |
| CN106295682A (zh) * | 2016-08-02 | 2017-01-04 | 厦门美图之家科技有限公司 | 一种判断图片质量因子的方法、装置和计算设备 |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101926646B (zh) * | 2003-07-01 | 2012-11-28 | 卡迪尔马格成像公司 | 使用机器学习来进行心磁图分类 |
| CN106203432B (zh) * | 2016-07-14 | 2020-01-17 | 杭州健培科技有限公司 | 一种基于卷积神经网显著性图谱的感兴趣区域的定位系统 |
-
2018
- 2018-03-29 CN CN201810270934.5A patent/CN108446741B/zh active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105531725A (zh) * | 2013-06-28 | 2016-04-27 | D-波系统公司 | 用于对数据进行量子处理的系统和方法 |
| CN105701509A (zh) * | 2016-01-13 | 2016-06-22 | 清华大学 | 一种基于跨类别迁移主动学习的图像分类方法 |
| CN106295682A (zh) * | 2016-08-02 | 2017-01-04 | 厦门美图之家科技有限公司 | 一种判断图片质量因子的方法、装置和计算设备 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108446741A (zh) | 2018-08-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108446741B (zh) | 机器学习超参数重要性评估方法、系统及存储介质 | |
| Azadi et al. | Auxiliary image regularization for deep cnns with noisy labels | |
| US10013636B2 (en) | Image object category recognition method and device | |
| CN107067025B (zh) | 一种基于主动学习的文本数据自动标注方法 | |
| JP5521881B2 (ja) | 画像識別情報付与プログラム及び画像識別情報付与装置 | |
| CN111127364B (zh) | 图像数据增强策略选择方法及人脸识别图像数据增强方法 | |
| JP5957629B1 (ja) | 診療計画を導くための画像の構造形状を自動的に表示する方法及び装置 | |
| WO2019015246A1 (zh) | 图像特征获取 | |
| CN111553127A (zh) | 一种多标记的文本类数据特征选择方法及装置 | |
| JP6897749B2 (ja) | 学習方法、学習システム、および学習プログラム | |
| Wang et al. | An unequal deep learning approach for 3-D point cloud segmentation | |
| CN107451210B (zh) | 一种基于查询松弛结果增强的图匹配查询方法 | |
| CN110516950A (zh) | 一种面向实体解析任务的风险分析方法 | |
| He et al. | Large-scale dataset pruning with dynamic uncertainty | |
| Ourabah | Large scale data using K-means | |
| Tiruneh et al. | Feature selection for construction organizational competencies impacting performance | |
| CN117763360B (zh) | 基于深度神经网络的训练集快速分析方法及电子设备 | |
| Jia et al. | Latent task adaptation with large-scale hierarchies | |
| CN111753083A (zh) | 一种基于svm参数优化的投诉举报文本分类方法 | |
| CN117763316A (zh) | 一种基于机器学习的高维数据降维方法及降维系统 | |
| CN116432835A (zh) | 客户流失预警归因方法、装置、计算机设备及存储介质 | |
| Kaur et al. | Measuring accuracy of stock price prediction using machine learning based classifiers | |
| CN112884065A (zh) | 一种基于支持向量机的深度学习模型鲁棒边界评估方法、装置和应用 | |
| Huang et al. | TX-Gen: Multi-Objective Optimization for Sparse Counterfactual Explanations for Time-Series Classification | |
| Zhao et al. | Coarse-fine surrogate model driven preference-based multi-objective evolutionary fuzzy clustering algorithm for color image segmentation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |