CN108446741B - Method, system and storage medium for evaluating importance of machine learning hyper-parameter - Google Patents
Method, system and storage medium for evaluating importance of machine learning hyper-parameter Download PDFInfo
- Publication number
- CN108446741B CN108446741B CN201810270934.5A CN201810270934A CN108446741B CN 108446741 B CN108446741 B CN 108446741B CN 201810270934 A CN201810270934 A CN 201810270934A CN 108446741 B CN108446741 B CN 108446741B
- Authority
- CN
- China
- Prior art keywords
- data set
- meta
- parameter
- hyper
- samples
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/21—Design or setup of recognition systems or techniques; Extraction of features in feature space; Blind source separation
- G06F18/217—Validation; Performance evaluation; Active pattern learning techniques
Landscapes
- Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Theoretical Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Artificial Intelligence (AREA)
- Evolutionary Biology (AREA)
- Evolutionary Computation (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
The invention discloses a method, a system and a storage medium for evaluating the importance of machine learning hyper-parameters, which are used for acquiring different data sets in OpenML, extracting meta-features to represent each data set, and collecting data of the performance of a classification algorithm to be evaluated under different hyper-parameter configurations; extracting meta-features to represent a target data set in use, and obtaining an increasing sequence of distances between the target data set and the historical data set by calculating distances between the meta-features; and evaluating the importance of the hyper-parameters by using performance data of different hyper-parameters of the classification algorithm to be evaluated, sequentially executing the proposed Relief and clustering algorithm on the previous m historical data sets close to the target data set according to the ordered sequence of increasing distances between the historical data sets and the target data set, and finally obtaining the automatic parameter adjusting process of ordering and guiding the importance of the hyper-parameters of the classification algorithm to be evaluated. The invention provides certain guidance for the super-parameter adjustment of the classification algorithm black box, thereby achieving the purposes of saving time and improving efficiency.
Description
Technical Field
The invention relates to a method and a system for evaluating the importance of a machine learning hyper-parameter and a storage medium.
Background
Machine learning provides important technical support for data processing and data classification, however, model selection and parameter adjustment are still two major problems troubling users, and thus automatic machine learning systems are produced. The automatic machine learning system achieves the purposes of automatic data preprocessing, automatic algorithm selection and automatic parameter adjustment by utilizing an automatic machine learning algorithm, improves the accuracy of data classification prediction, and simultaneously relieves users from the heavy tasks of algorithm selection and repeated parameter adjustment.
Because the core of the automatic machine learning is automatic Algorithm Selection and automatic super-parameter configuration, the system reduces the machine learning process into an Algorithm Selection and super-parameter optimization (CASH) problem. The CASH problem is that the selection of the algorithm is used as a new super parameter of the root level, and therefore the problems of the selection algorithm and the super parameter value are mapped to the problem of the selection of the super parameter value. By using data preprocessing and feature selection techniques as the hyper-parameters, the system can automatically select data preprocessing and feature selection techniques. The final conclusion of the super-parameter optimization problem can be that the optimal solution can be found through a classical Bayesian optimization algorithm, so that the effect of improving the data classification prediction precision is achieved.
However, the configuration process of the hyper-parameter configuration module of the current automatic machine learning system is completely empirical, or the final result is obtained by repeated iteration to adjust the configuration of a plurality of hyper-parameters one by one, so that the defects are as follows: machine learning time is wasted, computer resources are wasted by repeated iterations, and adjusting the configuration of all hyper-parameters without significant concern wastes time and effort by the user.
Disclosure of Invention
The invention relates to a method, a system and a storage medium for evaluating the importance of machine learning hyper-parameters, aiming at solving the technical problem of accurately evaluating the hyper-parameter importance of a machine learning algorithm and using the same for guiding automatic hyper-parameter configuration and enhancing the interpretability of the hyper-parameter configuration.
As a first aspect of the present invention:
the method for evaluating the importance of the machine learning hyper-parameter comprises the following steps:
step (1): acquiring a plurality of new data sets similar to the target data set type from an open machine learning environment OpenML, and extracting meta-feature vectors for each new data set, so that each new data set is represented by the meta-feature vectors;
collecting data of the performance of a classification algorithm to be evaluated under different hyper-parameter configurations from an open machine learning environment OpenML;
storing the meta-feature vector of each new data set and the performance data corresponding to different hyper-parameter configurations in corresponding historical data sets;
step (2): extracting meta-feature vectors of the target data set to represent the target data set, calculating the distance between the meta-feature vectors of the target data set and the meta-feature vectors of the historical data sets, and obtaining a distance sequence from near to far between the target data set and each historical data set;
and (3): sequentially executing a Relief-Cluster algorithm on the first f historical data sets closest to the target data set: further calculating the average weight of each type of hyper-parameter through the weight of each type of hyper-parameter obtained by a Relief algorithm, and preliminarily obtaining the importance weight sequence of each type of hyper-parameter by utilizing the average weight of each type of hyper-parameter; further verifying the accuracy of the super-parameter importance evaluation by using a clustering algorithm; and finally, obtaining the super-parameter importance ranking of the classification algorithm to be evaluated.
The machine learning super-parameter importance evaluation method comprises the following steps:
and (4): and setting a plurality of parameters with the top importance ranking according to the obtained super-parameter importance ranking of the classification algorithm to be evaluated, and then classifying the data to be classified by using the classification algorithm with the set parameters.
In the step (1), each data set DiIs described as a vector represented by F meta-features
In the step (1), the meta-feature includes: simple meta-features, statistical meta-features and significance meta-features of the data set;
the simple meta-features include: the number of data set samples, the number of features, the number of categories, or the number of missing values;
statistical meta-features of the data set, including: the kurtosis of the mean, variance, or distance vector;
significance meta-features including: performance obtained by running a machine learning algorithm on the data set.
The performance of the classification algorithm to be evaluated in the step (1) under different hyper-parameter configurations comprises the following steps: misclassification rate or RMSE;
in addition, for many common algorithms, the open machine learning environment OpenML already contains very comprehensive performance data, and is suitable for different hyper-parameter configurations on various data sets, namely, collecting a data set DiHyper-parametric configuration theta under classification algorithm to be evaluatediAnd performance yiData of
For the target data set DN'Extracting the meta-feature VN'To represent a target data set and based onThe dissimilar data sets have the principle that the hyper-parameter configuration of the algorithm also has difference, and the distance sequence between the target data set and the historical data set is obtained by utilizing the distance between the meta-feature vectors. Evaluating the importance of the hyper-parameters of the first f historical data sets close to the target data set by using performance data of the algorithm in different hyper-parameters;
measuring target data set D by using distance between meta-feature vectorsN'With historical data set DiA distance d betweenpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn
Wherein, VN'Representing a data set DN'Meta feature vector of (V)iRepresenting a historical data set DiPn denotes the p-norm.
And comparing the distances between the target data set and the meta-feature vectors of the historical data set to obtain an ordering sequence pi (1) of the distances between the historical data set and the target data set from near to far, wherein the ordering sequence pi (1) is
Sequentially executing a Relief-Cluster algorithm on the first f historical data sets close to the target data set according to the sorting queues pi (1) from the historical data set to the target data set from near to far. Firstly, preliminarily evaluating the importance of the hyper-parameter by the average weight of each type of the hyper-parameter obtained by a Relief algorithm, then further verifying the accuracy of the evaluation of the importance of the hyper-parameter by utilizing the r (C) index of the clustering algorithm, repeating the above two steps for m times, selecting the corresponding evaluation result of the importance of the hyper-parameter when the r (C) index is maximum, finally obtaining the ranking of the importance of the hyper-parameter of the classification algorithm to be evaluated, and finally guiding the automatic parameter adjusting process of a target data set in the classification algorithm to be evaluated.
The weight of each type of hyper-parameter obtained by the Relief algorithm comprises the following steps:
setting a threshold according to the size of performance data under different super-parameter configurations, and collecting historical dataDividing performance data corresponding to different medium-sized hyper-parameter configurations into high-performance samples and low-performance samples, and randomly selecting one sample s from the performance data by a Relief algorithmiThen, a distance s is selected from each of the high-performance samples and the low-performance samplesiThe most recent sample;
and siHomogeneous samples sjIs represented by M, with siSamples of different classes sjWeight w of per-class hyperparameter h, denoted by QhUpdating according to equation (1):
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,sim) represents two samples siThe difference from M in the hyperparameter h;
diff(h,siq) represents two samples siThe difference from Q in the hyperparameter h;
two samples siAnd sjThe difference diff (h, s) in the hyperparameter hi,sj) Is defined as:
if the superparameter h is a scalar type superparameter,
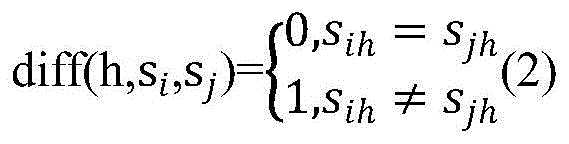
if the hyperparameter h is a numerical hyperparameter,
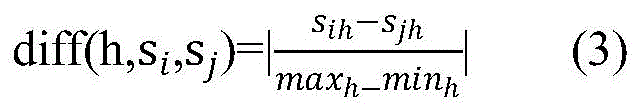
wherein i is not less than 1 and not more than j and not more than m, h is not less than 1 and not more than ph, maxhIs the maximum value of the hyperparameter h in the sample set, minhIs the minimum value of the hyperparameter h in the sample set, m represents the number of samples, each sample contains ph hyperparameters, rt represents the iteration number, and rt represents>1, to avoid the randomness of one sampling; sihIs shown in sample siValue of upper parameter h, sjhIs shown in sample sjThe value of the upper parameter h.
As can be seen from equation (1), the superparameters that contribute greatly to high performance are represented by large differences among different classes and small differences among similar classes, and therefore the weight of the superparameters having the ability to distinguish is a positive value.
In order to avoid the randomness of one-time sampling, rt is performed in an iteration mode for more than 1 time, and importance weight sequencing of each type of super parameter is obtained.
The step of further verifying the accuracy of the hyperparameter importance assessment by using the clustering algorithm comprises the following steps:
sorting the superparameters positioned in the top K classes according to the importance weights of the obtained superparameters of each class, clustering the superparameters positioned in the top K classes, and calculating the importance of the superparameters, wherein a superparameter sample set is assumed to be S, T is the size of the superparameter sample set, K is the number of the classes to which the superparameter samples belong, and pikRepresenting the probability of a sample belonging to class k, CkThe actual class label representing a hyper-parameter sample, C represents a hyper-parameter set, and the importance measure at C, r (C), is expressed as:



wherein F (C) represents the difference between the result of clustering on the hyper-parameter set C and the class label on the whole hyper-parameter sample set, C represents the hyper-parameter set, Fi(C) Denotes the difference, X, between the result of clustering on the hypercameter set C and the class label within each classiA sample set of hyper-parameters representing the ith class.
The higher the value of r (C), the greater the correlation between the clustering result and the actual class label, and the greater the influence of the hyper-parameter set C on the classification. And selecting the corresponding super parameter importance evaluation result when the r (C) index is maximum.
Class labels refer to high performance and low performance labels.
As a second aspect of the present invention,
the machine learning super-parameter importance evaluation system comprises: the computer program product comprises a memory, a processor, and computer instructions stored on the memory and executed on the processor, wherein the computer instructions, when executed by the processor, perform the steps of any of the above methods.
As a third aspect of the present invention,
a computer readable storage medium having computer instructions embodied thereon, which, when executed by a processor, perform the steps of any of the above methods.
The invention has the beneficial effects that:
the invention can accurately evaluate the super-parameter importance of the machine learning algorithm, and is used for guiding the automatic super-parameter configuration and enhancing the interpretability problem of the super-parameter configuration. The super-parameter importance for describing the machine learning algorithm per se provides effective reference and good interpretability for a super-parameter configuration process. The module is used for solving the technical problem of accurately evaluating the super-parameter importance of the machine learning algorithm and using the super-parameter importance to guide automatic super-parameter configuration and enhance the interpretability of the super-parameter configuration.
(1) The method saves resources and time, reduces the search space by providing proper prior knowledge, ensures that the super-parameter configuration process has certain guidance, and gets rid of the state of the prior complete black box.
(2) Meanwhile, the user can intuitively know which type of hyper-parameters has greater influence on the performance of the algorithm.
Drawings
The accompanying drawings, which are incorporated in and constitute a part of this application, illustrate embodiments of the application and, together with the description, serve to explain the application and are not intended to limit the application.
FIG. 1 is a flow chart provided by the present invention;
Detailed Description
It should be noted that the following detailed description is exemplary and is intended to provide further explanation of the disclosure. Unless defined otherwise, all technical and scientific terms used herein have the same meaning as commonly understood by one of ordinary skill in the art to which this application belongs.
The method fully utilizes a plurality of data sets in the open machine learning environment OpenML and performance data of each data set under various algorithms, calculates the distance between a target data set and a historical data set by combining a meta-learning method, obtains the importance sequence of each type of hyper-parameters of a classification algorithm to be evaluated by utilizing a Relief algorithm and a clustering algorithm, and the sequencing result is used for guiding the automatic parameter adjusting process of the target data set in the classification algorithm to be evaluated. The invention provides proper prior knowledge, reduces the search space, ensures that the super-parameter configuration process has certain instructive performance, and gets rid of the state of the prior complete black box; meanwhile, the user can intuitively know which type of hyper-parameters has greater influence on the performance of the algorithm.
As shown in fig. 1, the present invention comprises the steps of:
step A, obtaining different data sets in OpenML, extracting meta-features from each data set, enabling each data set to be represented by the meta-features, and collecting theta of a classification algorithm to be evaluated in different hyper-parametric configurationsiLower performance yi(e.g., misclassification rate or RMSE) of data Storing the meta-feature vector of each data set and performance data corresponding to different super-parameter configurations in a historical data set sample library;
Storing the meta-feature vector of each data set and performance data corresponding to different super-parameter configurations in a historical data set sample library;
the meta-features extracted in step a mainly include three major parts, namely, simple meta-features (for example, the number of samples in the data set, the number of features, the number of categories, the number of missing values, etc.), statistical meta-features of the data set (for example, the average value, the variance, the kurtosis of the distance vector, etc.), and importance meta-features (for example, information about the performance obtained by running a machine learning algorithm on the data set, etc.).
And step B, for the target data set used by the user, extracting meta-features to represent the target data set, and obtaining a distance sequence between the target data set and the historical data set by using the distance between meta-feature vectors on the basis of the principle that the super-parameter configuration of the algorithm used by dissimilar data sets also has difference. For the first f historical data sets which are closer to the target data set, the importance of the super parameters can be evaluated by using performance data of different super parameters of a classification algorithm to be evaluated;
in step B, the distance between the meta feature vectors is used to measure the target data set DN'With historical data set Di(i ═ 1,2, … N), where the distance formula we use the usual p-norm that measures the difference between the feature vectors of the dataset elements: dpn(DN′,Di)=||VN′-Vi||pn. By comparing the distances between the target data set and the meta-feature vectors of the historical data set, the ordered sequence pi (1) of the historical data set and the target data set from near to far can be obtained, wherein the ordered sequence pi (1) is
And step C, sequentially executing the proposed Relief-Cluster algorithm on the first f historical data sets close to the target data set according to the ordered sequence of the distance between the historical data sets and the target data set from near to far. Firstly, preliminarily evaluating the importance of the hyper-parameter by the average weight of each type of the hyper-parameter obtained by a Relief algorithm, then further verifying the accuracy of the evaluation of the importance of the hyper-parameter by utilizing the r (C) index of the clustering algorithm, repeating the two steps for m times, selecting the corresponding evaluation result of the importance of the hyper-parameter when the r (C) index is maximum, and finally obtaining the ranking of the importance of the hyper-parameter of the classification algorithm to be evaluated and then using the ranking for guiding the automatic parameter adjusting process of the target data set in the classification algorithm to be evaluated.
In the present invention, step C specifically includes the following steps:
step C1, setting a threshold according to the size of performance data under different super-parameter configurations to divide the data into a high-performance class and a low-performance class, and randomly selecting a sample s from a super-parameter sample set by a Relief algorithmiThen selecting a distance s from each of the two types of samplesiThe most recent sample. And siSamples of the same kind are denoted by M, andithe samples of different classes are represented by Q, and the weight w of each class of super parameter hhUpdating according to equation (1):
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
in the above formula, two samples siAnd sj(1 ≦ i ≠ j ≦ m) the difference in the hyper-parameter h (1 ≦ h ≦ ph) is defined as:
if the super parameter h is a scalar type super parameter,

if the super parameter h is a numerical super parameter,

therein, maxhAnd minhThe maximum and minimum values of the hyper-parameter h in the sample set, respectively.
As can be seen from equation (1), the hyperparameter with a large contribution to high performance should be represented by a large difference between different categories and a small difference between the same categories, and thus the weight of the hyperparameter with the ability to distinguish should be a positive value. To avoid the randomness of one sample, the above process iterates rt >1 times.
And step C2, according to the importance weight sequence of each type of super-parameter obtained in the previous step, clustering the super-parameters in the top K types, and calculating the feature importance, wherein a super-parameter sample set is assumed to be S, T is the size of the super-parameter sample set, K is the number of the classes to which the super-parameter samples belong, and pikRepresenting the probability of a sample belonging to class k, CkRepresenting the actual class label of the hyper-parameter sample, C represents the hyper-parameter subset, the importance measure at C, r (C), can be expressed as:

wherein F (C) represents the difference between the clustering result on the hyper-parameter set C and the class label on the whole hyper-parameter sample set, C represents the hyper-parameter set, Fi(C) Denotes differences within respective classes, XiA set of hyper-reference samples representing the ith class. The higher the r (C) value is, the greater the correlation degree between the clustering result and the actual class label is, and the greater the influence of the super-parameter set C on the classification is.
And (3) iterating the two steps for m times, selecting the corresponding super-parameter importance ranking when the r (r) and the C (c) are the maximum, and finally converting the obtained super-parameter importance ranking result into an automatic parameter adjusting process for guiding the target data set in a classification algorithm to be evaluated.
The flow chart of the Relief-Cluster algorithm in the invention is as follows:
inputting: hyper-parametric sample set S, hyper-parametric class number hc, sampling/iteration number rt
And (3) outputting: cluster evaluation index r (C), hyperparametric importance weight matrix W

Randomly selecting a sample S from Si;
From and siSelecting and s from samples of the same kindiThe nearest neighbor is marked as M;
from and siSelection of S from heterogeneous samplesiThe nearest neighbor is marked as N;
updating the super-parameter importance weight vector W by adopting a formula (1);
selecting a super parameter set with the size of X;
clustering samples on the hyper-parameter set;
calculating the correlation degree r (C) of the clustering result and the actual result
Selecting corresponding super-parameter importance sequencing when the value is maximum from m r (C);
End
the above description is only a preferred embodiment of the present application and is not intended to limit the present application, and various modifications and changes may be made by those skilled in the art. Any modification, equivalent replacement, improvement and the like made within the spirit and principle of the present application shall be included in the protection scope of the present application.
Claims (18)
1. The classification system of the data to be classified based on the machine learning super-parameter importance evaluation is characterized by comprising the following steps:
a historical data set acquisition module configured to: acquiring a plurality of new data sets similar to the target data set type from an open machine learning environment OpenML, and extracting meta-features from each new data set to enable each new data set to be represented by a meta-feature vector;
collecting data of the performance of a classification algorithm to be evaluated under different hyper-parameter configurations from an open machine learning environment OpenML;
storing the meta-feature vector of each new data set and the performance data corresponding to different hyper-parameter configurations in corresponding historical data sets;
a distance sequence acquisition module configured to: extracting meta-feature vectors of the target data set to represent the target data set, calculating the distance between the meta-feature vectors of the target data set and the meta-feature vectors of the historical data sets, and obtaining a distance sequence from near to far between the target data set and each historical data set;
an output module configured to: sequentially executing a Relief-Cluster algorithm on the first f historical data sets closest to the target data set: further calculating the average weight of each type of hyper-parameter through the weight of each type of hyper-parameter obtained by a Relief algorithm, and preliminarily obtaining the importance weight sequence of each type of hyper-parameter by utilizing the average weight of each type of hyper-parameter; further verifying the accuracy of the super-parameter importance evaluation by using a clustering algorithm; finally, obtaining the super-parameter importance ranking of the classification algorithm to be evaluated;
a classification module configured to: and setting a plurality of parameters with the top importance ranking according to the obtained super-parameter importance ranking of the classification algorithm to be evaluated, and then classifying the data to be classified by using the classification algorithm with the set parameters.
2. The system of claim 1, wherein each data set D in the historical data set acquisition moduleiIs described as a vector represented by F meta-features
3. The system of claim 1, wherein the meta-features in the historical data set acquisition module include: simple meta-features, statistical meta-features and significance meta-features of the data set;
the simple meta-features include: the number of data set samples, the number of features, the number of categories, or the number of missing values;
statistical meta-features of the data set, including: the kurtosis of the mean, variance, or distance vector;
the importance meta-feature comprises: performance obtained by running a machine learning algorithm on the data set.
4. The system of claim 1, wherein the performance of the classification algorithm to be evaluated in the historical data set acquisition module under different hyper-parameter configurations comprises: misclassification rate or RMSE.
5. The system of claim 1, wherein the distance between meta-feature vectors is used to scale the target data set DN+1With historical data set DiA distance d betweenpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn
Wherein, VN′Representing a target data set DN′Meta feature vector of (V)iRepresenting a historical data set DiP represents the p-norm;
and comparing the distances between the target data set and the meta-feature vectors of the historical data set to obtain an ordering sequence pi (1) of the distances between the historical data set and the target data set from near to far.
6. The system of claim 1, wherein,
the weight of each type of hyper-parameter obtained by the Relief algorithm comprises the following steps:
setting a threshold according to the size of performance data under different super-parameter configurations, dividing the performance data corresponding to different super-parameter configurations in a historical data set into high-performance samples and low-performance samples, and randomly selecting a sample s from the performance data by a Relief algorithmiThen, a distance s is selected from each of the high-performance samples and the low-performance samplesiThe most recent sample;
and siHomogeneous samples sjIs represented by M, with siSamples of different classes sjWeight w of per-class hyperparameter h, denoted by QhUpdating according to equation (1):
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,sim) represents two samples siThe difference from M in the hyperparameter h;
diff(h,siq) represents two samples siThe difference from Q in the hyperparameter h;
two samples siAnd sjThe difference diff (h, s) in the hyperparameter hi,sj) Is defined as:
if the superparameter h is a scalar type superparameter,

if the hyperparameter h is a numerical hyperparameter,

wherein i is not less than 1 but not more than j and m is not less than 1 but not more than hph,maxhIs the maximum value of the hyperparameter h in the sample set, minhIs the minimum value of the hyperparameter h in the sample set, m represents the number of samples, each sample contains ph hyperparameters, rt represents the iteration number, rt >1, sihIs shown in sample siValue of upper parameter h, sjhIs shown in sample sjThe value of the upper parameter h.
7. The classification system of the data to be classified based on the machine learning super-parameter importance evaluation is characterized by comprising the following steps: a memory, a processor, and computer instructions stored on the memory and executed on the processor, the computer instructions when executed by the processor performing the steps of:
step (1): acquiring a plurality of new data sets similar to the target data set type from an open machine learning environment OpenML, and extracting meta-features from each new data set to enable each new data set to be represented by a meta-feature vector;
collecting data of the performance of a classification algorithm to be evaluated under different hyper-parameter configurations from an open machine learning environment OpenML;
storing the meta-feature vector of each new data set and the performance data corresponding to different hyper-parameter configurations in corresponding historical data sets;
step (2): extracting meta-feature vectors of the target data set to represent the target data set, calculating the distance between the meta-feature vectors of the target data set and the meta-feature vectors of the historical data sets, and obtaining a distance sequence from near to far between the target data set and each historical data set;
and (3): sequentially executing a Relief-Cluster algorithm on the first f historical data sets closest to the target data set: further calculating the average weight of each type of hyper-parameter through the weight of each type of hyper-parameter obtained by a Relief algorithm, and preliminarily obtaining the importance weight sequence of each type of hyper-parameter by utilizing the average weight of each type of hyper-parameter; further verifying the accuracy of the super-parameter importance evaluation by using a clustering algorithm; finally, obtaining the super-parameter importance ranking of the classification algorithm to be evaluated;
and (4): and setting a plurality of parameters with the top importance ranking according to the obtained super-parameter importance ranking of the classification algorithm to be evaluated, and then classifying the data to be classified by using the classification algorithm with the set parameters.
8. The system of claim 7, wherein in step (1), each data set DiIs described as a vector represented by F meta-features
9. The system of claim 7, wherein in step (1), the meta-features comprise: simple meta-features, statistical meta-features and significance meta-features of the data set;
the simple meta-features include: the number of data set samples, the number of features, the number of categories, or the number of missing values;
statistical meta-features of the data set, including: the kurtosis of the mean, variance, or distance vector;
the importance meta-feature comprises: performance obtained by running a machine learning algorithm on the data set.
10. The system of claim 7, wherein the performance of the classification algorithm to be evaluated in step (1) under different hyper-parameter configurations comprises: misclassification rate or RMSE.
11. The system of claim 7, wherein the distance between meta feature vectors is used to scale the target data set DN+1With historical data set DiA distance d betweenpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn;
Wherein, VN′Representing a target data set DN′Meta feature vector of (V)iRepresenting a historical data set DiP represents the p-norm;
and comparing the distances between the target data set and the meta-features of the historical data set to obtain an ordering sequence pi (1) of the distances between the historical data set and the target data set from near to far.
12. The system of claim 7, wherein,
the weight of each type of hyper-parameter obtained by the Relief algorithm comprises the following steps:
setting a threshold according to the size of performance data under different super-parameter configurations, dividing the performance data corresponding to different super-parameter configurations in a historical data set into high-performance samples and low-performance samples, and randomly selecting a sample s from the performance data by a Relief algorithmiThen, a distance s is selected from each of the high-performance samples and the low-performance samplesiThe most recent sample;
and siHomogeneous samples sjIs represented by M, with siSamples of different classes sjWeight w of per-class hyperparameter h, denoted by QhUpdating according to equation (1):
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,sim) represents two samples siThe difference from M in the hyperparameter h;
diff(h,siq) represents two samples siThe difference from Q in the hyperparameter h;
two samples siAnd sjThe difference diff (h, s) in the hyperparameter hi,sj) Is defined as:
if the superparameter h is a scalar type superparameter,
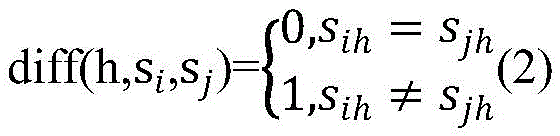
if the hyperparameter h is a numerical hyperparameter,

wherein i is not less than 1 and not more than j and not more than m, h is not less than 1 and not more than ph, maxhIs the maximum value of the hyperparameter h in the sample set, minhIs the minimum value of the hyperparameter h in the sample set, m represents the number of samples, each sample contains ph hyperparameters, rt represents the iteration number, rt >1, sihIs shown in sample siValue of upper parameter h, sjhIs shown in sample sjThe value of the upper parameter h.
13. A computer readable storage medium having computer instructions embodied thereon, said computer instructions when executed by a processor performing the steps of:
step (1): acquiring a plurality of new data sets similar to the target data set type from an open machine learning environment OpenML, and extracting meta-features from each new data set to enable each new data set to be represented by a meta-feature vector;
collecting data of the performance of a classification algorithm to be evaluated under different hyper-parameter configurations from an open machine learning environment OpenML;
storing the meta-feature vector of each new data set and the performance data corresponding to different hyper-parameter configurations in corresponding historical data sets;
step (2): extracting meta-feature vectors of the target data set to represent the target data set, calculating the distance between the meta-feature vectors of the target data set and the meta-feature vectors of the historical data sets, and obtaining a distance sequence from near to far between the target data set and each historical data set;
and (3): sequentially executing a Relief-Cluster algorithm on the first f historical data sets closest to the target data set: further calculating the average weight of each type of hyper-parameter through the weight of each type of hyper-parameter obtained by a Relief algorithm, and preliminarily obtaining the importance weight sequence of each type of hyper-parameter by utilizing the average weight of each type of hyper-parameter; further verifying the accuracy of the super-parameter importance evaluation by using a clustering algorithm; finally, obtaining the super-parameter importance ranking of the classification algorithm to be evaluated;
and (4): and setting a plurality of parameters with the top importance ranking according to the obtained super-parameter importance ranking of the classification algorithm to be evaluated, and then classifying the data to be classified by using the classification algorithm with the set parameters.
14. The medium of claim 13, wherein in step (1), each data set DiIs described as a vector represented by F meta-features
15. The medium of claim 13, wherein in step (1), the meta-feature comprises: simple meta-features, statistical meta-features and significance meta-features of the data set;
the simple meta-features include: the number of data set samples, the number of features, the number of categories, or the number of missing values;
statistical meta-features of the data set, including: the kurtosis of the mean, variance, or distance vector;
the importance meta-feature comprises: performance obtained by running a machine learning algorithm on the data set.
16. The medium of claim 13, wherein the performance of the classification algorithm under evaluation in step (1) under different hyper-parameter configurations comprises: misclassification rate or RMSE.
17. The medium of claim 13, wherein the distance between meta feature vectors is used to scale the target data set DN+1With historical data set DiA distance d betweenpn(DN′,Di):
dpn(DN′,Di)=||VN′-Vi||pn;
Wherein, VN′Representing a target data set DN′Meta feature vector of (V)iRepresenting the number of historiesData set DiP represents the p-norm;
and comparing the distances between the target data set and the meta-feature vectors of the historical data set to obtain an ordering sequence pi (1) of the distances between the historical data set and the target data set from near to far.
18. The medium of claim 13, wherein the weight for each type of hyperparameter obtained by the Relief algorithm comprises:
setting a threshold according to the size of performance data under different super-parameter configurations, dividing the performance data corresponding to different super-parameter configurations in a historical data set into high-performance samples and low-performance samples, and randomly selecting a sample s from the performance data by a Relief algorithmiThen, a distance s is selected from each of the high-performance samples and the low-performance samplesiThe most recent sample;
and siHomogeneous samples sjIs represented by M, with siSamples of different classes sjWeight w of per-class hyperparameter h, denoted by QhUpdating according to equation (1):
wh=wh-diff(h,si,M)/rt+diff(h,si,Q)/rt (1)
diff(h,sim) represents two samples siThe difference from M in the hyperparameter h;
diff(h,siq) represents two samples siThe difference from Q in the hyperparameter h;
two samples siAnd sjThe difference diff (h, s) in the hyperparameter hi,sj) Is defined as:
if the superparameter h is a scalar type superparameter,
if the hyperparameter h is a numerical hyperparameter,

wherein i is not less than 1 and not more than j and not more than m, h is not less than 1 and not more than ph, maxhIs the maximum value of the hyperparameter h in the sample set, minhIs the minimum value of the hyperparameter h in the sample set, m represents the number of samples, each sample contains ph hyperparameters, rt represents the iteration number, rt >1, sihIs shown in sample siValue of upper parameter h, sjhIs shown in sample sjThe value of the upper parameter h.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810270934.5A CN108446741B (en) | 2018-03-29 | 2018-03-29 | Method, system and storage medium for evaluating importance of machine learning hyper-parameter |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN201810270934.5A CN108446741B (en) | 2018-03-29 | 2018-03-29 | Method, system and storage medium for evaluating importance of machine learning hyper-parameter |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN108446741A CN108446741A (en) | 2018-08-24 |
| CN108446741B true CN108446741B (en) | 2020-01-07 |
Family
ID=63197670
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN201810270934.5A Active CN108446741B (en) | 2018-03-29 | 2018-03-29 | Method, system and storage medium for evaluating importance of machine learning hyper-parameter |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN108446741B (en) |
Families Citing this family (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6892424B2 (en) * | 2018-10-09 | 2021-06-23 | 株式会社Preferred Networks | Hyperparameter tuning methods, devices and programs |
| CN109447277B (en) * | 2018-10-19 | 2023-11-10 | 厦门渊亭信息科技有限公司 | Universal machine learning super-ginseng black box optimization method and system |
| CN109460825A (en) * | 2018-10-24 | 2019-03-12 | 阿里巴巴集团控股有限公司 | For constructing the Feature Selection Algorithms, device and equipment of machine learning model |
| CN111160459A (en) * | 2019-12-30 | 2020-05-15 | 上海依图网络科技有限公司 | Device and method for optimizing hyper-parameters |
| CN111260243A (en) * | 2020-02-10 | 2020-06-09 | 京东数字科技控股有限公司 | Risk assessment method, device, equipment and computer readable storage medium |
| CN111401567A (en) * | 2020-03-20 | 2020-07-10 | 厦门渊亭信息科技有限公司 | Universal deep learning hyper-parameter optimization method and device |
| CN111539536B (en) * | 2020-06-19 | 2020-10-23 | 支付宝(杭州)信息技术有限公司 | Method and device for evaluating service model hyper-parameters |
| CN111917648B (en) * | 2020-06-30 | 2021-10-26 | 华南理工大学 | Transmission optimization method for rearrangement of distributed machine learning data in data center |
| CN113760188A (en) * | 2021-07-30 | 2021-12-07 | 浪潮电子信息产业股份有限公司 | Parameter adjusting and selecting method, system and device for distributed storage system |
| CN114490094B (en) * | 2022-04-18 | 2022-07-12 | 北京麟卓信息科技有限公司 | GPU (graphics processing Unit) video memory allocation method and system based on machine learning |
Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105531725A (en) * | 2013-06-28 | 2016-04-27 | D-波系统公司 | Systems and methods for quantum processing of data |
| CN105701509A (en) * | 2016-01-13 | 2016-06-22 | 清华大学 | Image classification method based on cross-type migration active learning |
| CN106295682A (en) * | 2016-08-02 | 2017-01-04 | 厦门美图之家科技有限公司 | A kind of judge the method for the picture quality factor, device and calculating equipment |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN101926646B (en) * | 2003-07-01 | 2012-11-28 | 卡迪尔马格成像公司 | Use of machine learning for classification of magneto cardiograms |
| CN106203432B (en) * | 2016-07-14 | 2020-01-17 | 杭州健培科技有限公司 | Positioning system of region of interest based on convolutional neural network significance map |
-
2018
- 2018-03-29 CN CN201810270934.5A patent/CN108446741B/en active Active
Patent Citations (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN105531725A (en) * | 2013-06-28 | 2016-04-27 | D-波系统公司 | Systems and methods for quantum processing of data |
| CN105701509A (en) * | 2016-01-13 | 2016-06-22 | 清华大学 | Image classification method based on cross-type migration active learning |
| CN106295682A (en) * | 2016-08-02 | 2017-01-04 | 厦门美图之家科技有限公司 | A kind of judge the method for the picture quality factor, device and calculating equipment |
Also Published As
| Publication number | Publication date |
|---|---|
| CN108446741A (en) | 2018-08-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108446741B (en) | Method, system and storage medium for evaluating importance of machine learning hyper-parameter | |
| Azadi et al. | Auxiliary image regularization for deep cnns with noisy labels | |
| US10013636B2 (en) | Image object category recognition method and device | |
| CN107067025B (en) | Text data automatic labeling method based on active learning | |
| JP5521881B2 (en) | Image identification information addition program and image identification information addition device | |
| CN111127364B (en) | Image data enhancement strategy selection method and face recognition image data enhancement method | |
| JP5957629B1 (en) | Method and apparatus for automatically displaying the structural shape of an image for guiding a medical plan | |
| WO2019015246A1 (en) | Image feature acquisition | |
| CN111553127A (en) | Multi-label text data feature selection method and device | |
| JP6897749B2 (en) | Learning methods, learning systems, and learning programs | |
| Wang et al. | An unequal deep learning approach for 3-D point cloud segmentation | |
| CN107451210B (en) | Graph matching query method based on query relaxation result enhancement | |
| CN110516950A (en) | A kind of risk analysis method of entity-oriented parsing task | |
| He et al. | Large-scale dataset pruning with dynamic uncertainty | |
| Ourabah | Large scale data using K-means | |
| Tiruneh et al. | Feature selection for construction organizational competencies impacting performance | |
| CN117763360B (en) | Training set rapid analysis method based on deep neural network and electronic equipment | |
| Jia et al. | Latent task adaptation with large-scale hierarchies | |
| CN111753083A (en) | Complaint report text classification method based on SVM parameter optimization | |
| CN117763316A (en) | High-dimensional data dimension reduction method and dimension reduction system based on machine learning | |
| CN116432835A (en) | Customer loss early warning and attributing method, device, computer equipment and storage medium | |
| Kaur et al. | Measuring accuracy of stock price prediction using machine learning based classifiers | |
| CN112884065A (en) | Deep learning model robust boundary assessment method and device based on support vector machine and application | |
| Huang et al. | TX-Gen: Multi-Objective Optimization for Sparse Counterfactual Explanations for Time-Series Classification | |
| Zhao et al. | Coarse-fine surrogate model driven preference-based multi-objective evolutionary fuzzy clustering algorithm for color image segmentation |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |