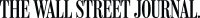「這(左手)是改變世界的Hopper,而這(右手)是Blackwell。」
(然後黃仁勳在台上安慰明顯小了一號的前代AI晶片,說,「Hopper沒關係的」,引來哄堂大笑)
")
科技媒體《WIRED》上個月以〈輝達硬體正在吞噬世界〉(Nvidia Hardware Is Eating the World)為題,報導Nvidia如何靠當初起家的GPU(圖形處理器),從X世代遊戲顯卡的主要供應商,一躍成為人工智慧時代最重要的運算動力供應者。擁有超級算力的Nvidia GPU甚至被《WIRED》看好,未來十年將繼續在AI領域獨占鰲頭。時隔不到一個月,黃仁勳竟又拿出了Hopper GPU的下一代產品—無論算力與能耗都大有進展的Blackwell,觀看直播的外國網友再次驚嘆「Nvidia eats world」!
穿著招牌皮衣的黃仁勳在GTC大會的主題演說中坦言,通用運算已經失去動力,但當前AI模型的參數量仍在瘋狂成長,以OpenAI的GPT-4為例,動輒處理數十億token、參數上看1.8兆。因此黃仁勳說,「我們需要更大的模型,我們需要更大的GPU」。當AI模型仍在大步邁進,輝達發表了比市場瘋搶的H100還要更火熱的Blackwell,這也把八年來的AI算力進展推上了千倍之譜。擁有2080億個電晶體的Blackwell,就是為了在數兆參數上建構和運行生成式AI而來,也難怪黃仁勳要當眾安慰無論個頭與實力都矮了Blackwell一截的Hopper。
")
黃仁勳強調Blackwell是目前最強大的晶片,也是輝達首個採用多晶片封裝設計的GPU。兩塊小晶片之間的連網速度高達10TBps,黃仁勳表示,Blackwell沒有記憶體局部性問題或快取問題,CUDA(Compute Unified Device Architecture,統一計算架構)也將其視為單一GPU。Blackwell配備192GB、速度達到8Gbps的HBM3E記憶體,AI算力達到20 petaflops ,前代H100的4 petaflops完全被拋在腦後。雖然黃仁勳自己也將Blackwell稱為晶片,但他也說Blackwell不是晶片名、而是平台的名字。採用Blackwell架構的GPU除了B200,還有整合了Grace CPU與兩個B200 GPU的GB200。高效整合的多die晶片,讓輝達在製程升級速度減慢的狀況下,仍有辦法大幅推升算力。