In computing, multitasking is the concurrent execution of multiple tasks over a certain period of time. New tasks can interrupt already started ones before they finish, instead of waiting for them to end. As a result, a computer executes segments of multiple tasks in an interleaved manner, while the tasks share common processing resources such as central processing units (CPUs) and main memory. Multitasking automatically interrupts the running program, saving its state and loading the saved state of another program and transferring control to it. This "context switch" may be initiated at fixed time intervals, or the running program may be coded to signal to the supervisory software when it can be interrupted.
In computing, a context switch is the process of storing the state of a process or thread, so that it can be restored and resume execution at a later point, and then restoring a different, previously saved, state. This allows multiple processes to share a single central processing unit (CPU), and is an essential feature of a multitasking operating system. In a traditional CPU, each process - a program in execution - utilizes the various CPU registers to store data and hold the current state of the running process. However, in a multitasking operating system, the operating system switches between processes or threads to allow the execution of multiple processes simultaneously. For every switch, the operating system must save the state of the currently running process, followed by loading the next process state, which will run on the CPU. This sequence of operations that stores the state of the running process and the loading of the following running process is called a context switch.
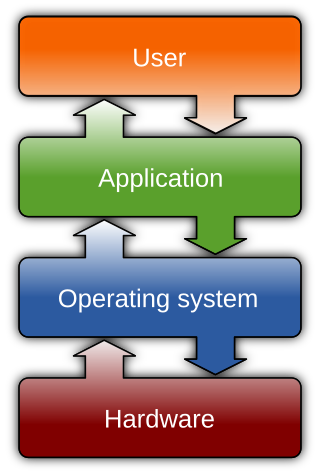
An operating system (OS) is system software that manages computer hardware and software resources, and provides common services for computer programs.

Non-uniform memory access (NUMA) is a computer memory design used in multiprocessing, where the memory access time depends on the memory location relative to the processor. Under NUMA, a processor can access its own local memory faster than non-local memory. The benefits of NUMA are limited to particular workloads, notably on servers where the data is often associated strongly with certain tasks or users.

In computing, a process is the instance of a computer program that is being executed by one or many threads. There are many different process models, some of which are light weight, but almost all processes are rooted in an operating system (OS) process which comprises the program code, assigned system resources, physical and logical access permissions, and data structures to initiate, control and coordinate execution activity. Depending on the OS, a process may be made up of multiple threads of execution that execute instructions concurrently.

In computer science, a thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler, which is typically a part of the operating system. The implementation of threads and processes differs between operating systems. In Modern Operating Systems, Tanenbaum shows that many distinct models of process organization are possible. In many cases, a thread is a component of a process. The multiple threads of a given process may be executed concurrently, sharing resources such as memory, while different processes do not share these resources. In particular, the threads of a process share its executable code and the values of its dynamically allocated variables and non-thread-local global variables at any given time.
In computer science, algorithmic efficiency is a property of an algorithm which relates to the amount of computational resources used by the algorithm. An algorithm must be analyzed to determine its resource usage, and the efficiency of an algorithm can be measured based on the usage of different resources. Algorithmic efficiency can be thought of as analogous to engineering productivity for a repeating or continuous process.

In UNIX computing, the system load is a measure of the amount of computational work that a computer system performs. The load average represents the average system load over a period of time. It conventionally appears in the form of three numbers which represent the system load during the last one-, five-, and fifteen-minute periods.
In computing, scheduling is the action of assigning resources to perform tasks. The resources may be processors, network links or expansion cards. The tasks may be threads, processes or data flows.
In modern computers many processes run at once. Active processes are placed in an array called a run queue, or runqueue. The run queue may contain priority values for each process, which will be used by the scheduler to determine which process to run next. To ensure each program has a fair share of resources, each one is run for some time period (quantum) before it is paused and placed back into the run queue. When a program is stopped to let another run, the program with the highest priority in the run queue is then allowed to execute.
nice is a program found on Unix and Unix-like operating systems such as Linux. It directly maps to a kernel call of the same name. nice is used to invoke a utility or shell script with a particular CPU priority, thus giving the process more or less CPU time than other processes. A niceness of -20 is the lowest niceness, or highest priority. The default niceness for processes is inherited from its parent process and is usually 0.
In computing, preemption is the act of temporarily interrupting an executing task, with the intention of resuming it at a later time. This interrupt is done by an external scheduler with no assistance or cooperation from the task. This preemptive scheduler usually runs in the most privileged protection ring, meaning that interruption and then resumption are considered highly secure actions. Such changes to the currently executing task of a processor are known as context switching.

CPU time is the amount of time for which a central processing unit (CPU) was used for processing instructions of a computer program or operating system, as opposed to elapsed time, which includes for example, waiting for input/output (I/O) operations or entering low-power (idle) mode. The CPU time is measured in clock ticks or seconds. Often, it is useful to measure CPU time as a percentage of the CPU's capacity, which is called the CPU usage. CPU time and CPU usage have two main uses.

The Completely Fair Scheduler (CFS) is a process scheduler that was merged into the 2.6.23 release of the Linux kernel and is the default scheduler of the tasks of the SCHED_NORMAL class. It handles CPU resource allocation for executing processes, and aims to maximize overall CPU utilization while also maximizing interactive performance.
Con Kolivas is an Australian anaesthetist. He has worked as a computer programmer on the Linux kernel and on the development of the cryptographic currency mining software CGMiner. His Linux contributions include patches for the kernel to improve its desktop performance, particularly reducing I/O impact.
A process is a program in execution, and an integral part of any modern-day operating system (OS). The OS must allocate resources to processes, enable processes to share and exchange information, protect the resources of each process from other processes and enable synchronization among processes. To meet these requirements, the OS must maintain a data structure for each process, which describes the state and resource ownership of that process, and which enables the OS to exert control over each process.
The Brain Fuck Scheduler (BFS) is a process scheduler designed for the Linux kernel in August 2009 as an alternative to the Completely Fair Scheduler (CFS) and the O(1) scheduler. BFS was created by an experienced kernel programmer Con Kolivas.

The Slurm Workload Manager, formerly known as Simple Linux Utility for Resource Management (SLURM), or simply Slurm, is a free and open-source job scheduler for Linux and Unix-like kernels, used by many of the world's supercomputers and computer clusters.
SCHED_DEADLINE is a CPU scheduler available in the Linux kernel since version 3.14, based on the Earliest Deadline First (EDF) and Constant Bandwidth Server (CBS) algorithms, supporting resource reservations: each task scheduled under such policy is associated with a budget Q, and a period P, corresponding to a declaration to the kernel that Q time units are required by that task every P time units, on any processor. This makes SCHED_DEADLINE particularly suitable for real-time applications, like multimedia or industrial control, where P corresponds to the minimum time elapsing between subsequent activations of the task, and Q corresponds to the worst-case execution time needed by each activation of the task.
The O(n) scheduler is the scheduler used in the Linux kernel between versions 2.4 and 2.6. Since version 2.6.0, it has been replaced by the O(1) scheduler and in 2.6.23 by the current Completely Fair Scheduler (CFS).
