Related Research Articles

In computers, case sensitivity defines whether uppercase and lowercase letters are treated as distinct (case-sensitive) or equivalent (case-insensitive). For instance, when users interested in learning about dogs search an e-book, "dog" and "Dog" are of the same significance to them. Thus, they request a case-insensitive search. But when they search an online encyclopedia for information about the United Nations, for example, or something with no ambiguity regarding capitalization and ambiguity between two or more terms cut down by capitalization, they may prefer a case-sensitive search.

Disk partitioning or disk slicing is the creation of one or more regions on secondary storage, so that each region can be managed separately. These regions are called partitions. It is typically the first step of preparing a newly installed disk after a partitioning scheme is chosen for the new disk before any file system is created. The disk stores the information about the partitions' locations and sizes in an area known as the partition table that the operating system reads before any other part of the disk. Each partition then appears to the operating system as a distinct "logical" disk that uses part of the actual disk. System administrators use a program called a partition editor to create, resize, delete, and manipulate the partitions. Partitioning allows the use of different filesystems to be installed for different kinds of files. Separating user data from system data can prevent the system partition from becoming full and rendering the system unusable. Partitioning can also make backing up easier. A disadvantage is that it can be difficult to properly size partitions, resulting in having one partition with too much free space and another nearly totally allocated.
In computer security, an access-control list (ACL) is a list of permissions associated with a system resource. An ACL specifies which users or system processes are granted access to resources, as well as what operations are allowed on given resources. Each entry in a typical ACL specifies a subject and an operation. For instance,
HPFS is a file system created specifically for the OS/2 operating system to improve upon the limitations of the FAT file system. It was written by Gordon Letwin and others at Microsoft and added to OS/2 version 1.2, at that time still a joint undertaking of Microsoft and IBM, and released in 1988.

In computer science, inter-process communication (IPC), also spelled interprocess communication, are the mechanisms provided by an operating system for processes to manage shared data. Typically, applications can use IPC, categorized as clients and servers, where the client requests data and the server responds to client requests. Many applications are both clients and servers, as commonly seen in distributed computing.

In the maintenance of file systems, defragmentation is a process that reduces the degree of fragmentation. It does this by physically organizing the contents of the mass storage device used to store files into the smallest number of contiguous regions. It also attempts to create larger regions of free space using compaction to impede the return of fragmentation. Some defragmentation utilities try to keep smaller files within a single directory together, as they are often accessed in sequence.
Btrieve is a transactional database software product. It is based on Indexed Sequential Access Method (ISAM), which is a way of storing data for fast retrieval. There have been several versions of the product for DOS, Linux, older versions of Microsoft Windows, 32-bit IBM OS/2 and for Novell NetWare.
A temporary file is a file created to store information temporarily, either for a program's intermediate use or for transfer to a permanent file when complete. It may be created by computer programs for a variety of purposes, such as when a program cannot allocate enough memory for its tasks, when the program is working on data bigger than the architecture's address space, or as a primitive form of inter-process communication.
The Installable File System (IFS) is a filesystem API in MS-DOS/PC DOS 4.x, IBM OS/2 and Microsoft Windows that enables the operating system to recognize and load drivers for file systems.
In computing, a file system or filesystem governs file organization and access. A local file system is a capability of an operating system that services the applications running on the same computer. A distributed file system is a protocol that provides file access between networked computers.
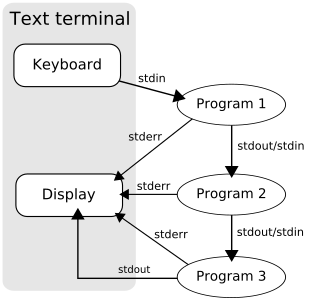
In Unix-like computer operating systems, a pipeline is a mechanism for inter-process communication using message passing. A pipeline is a set of processes chained together by their standard streams, so that the output text of each process (stdout) is passed directly as input (stdin) to the next one. The second process is started as the first process is still executing, and they are executed concurrently.
Microsoft DNS is the name given to the implementation of domain name system services provided in Microsoft Windows operating systems.
In computing, a temporary folder or temporary directory is a directory used to hold temporary files. Many operating systems and some software automatically delete the contents of this directory at bootup or at regular intervals, leaving the directory itself intact.
A file system API is an application programming interface through which a utility or user program requests services of a file system. An operating system may provide abstractions for accessing different file systems transparently.
In computer science, an anonymous pipe is a simplex FIFO communication channel that may be used for one-way interprocess communication (IPC). An implementation is often integrated into the operating system's file IO subsystem. Typically a parent program opens anonymous pipes, and creates a new process that inherits the other ends of the pipes, or creates several new processes and arranges them in a pipeline.
The following tables compare general and technical information for a number of file systems.
An NTFS reparse point is a type of NTFS file system object. It is available with the NTFS v3.0 found in Windows 2000 or later versions. Reparse points provide a way to extend the NTFS filesystem. A reparse point contains a reparse tag and data that are interpreted by a filesystem filter driver identified by the tag. Microsoft includes several default tags including NTFS symbolic links, directory junction points, volume mount points and Unix domain sockets. Also, reparse points are used as placeholders for files moved by Windows 2000's Remote Storage Hierarchical Storage System. They also can act as hard links, but are not limited to pointing to files on the same volume: they can point to directories on any local volume. The feature is inherited to ReFS.
In Unix-like operating systems, a device file, device node, or special file is an interface to a device driver that appears in a file system as if it were an ordinary file. There are also special files in DOS, OS/2, and Windows. These special files allow an application program to interact with a device by using its device driver via standard input/output system calls. Using standard system calls simplifies many programming tasks, and leads to consistent user-space I/O mechanisms regardless of device features and functions.
Strozzi NoSQL is a shell-based relational database management system initialized and developed by Carlo Strozzi that runs under Unix-like operating systems, or others with compatibility layers. Its file name NoSQL merely reflects the fact that it does not express its queries using Structured Query Language; the NoSQL RDBMS is distinct from the circa-2009 general concept of NoSQL databases, which are typically non-relational, unlike the NoSQL RDBMS. Strozzi NoSQL is released under the GNU GPL.
In computing, process substitution is a form of inter-process communication that allows the input or output of a command to appear as a file. The command is substituted in-line, where a file name would normally occur, by the command shell. This allows programs that normally only accept files to directly read from or write to another program.
References
- ↑ "mkfifo, mkfifoat - make a FIFO special file". IEEE Std 1003.1-2017. The Open Group.
- ↑ "mknod, mknodat - make directory, special file, or regular file". IEEE Std 1003.1-2017. The Open Group.
- ↑ "13.2.7 LOAD DATA Statement". MySQL 8.0 Reference Manual. MySQL. Archived from the original on 2020-06-14. Retrieved 2020-05-19.
- ↑ Aidan Van Dyk (2008-03-27). "Re: psql and named pipes". pgsql-hackers. PostgreSQL. Archived from the original on 2022-05-20. Retrieved 2020-05-19.
- ↑ "System.IO.Pipes Namespace". Microsoft Developer Network.
- ↑ "How to connect to SQL Server by using an earlier version of SQL Server". Microsoft. 2019-11-19. Archived from the original on 2020-07-20. Retrieved 2020-05-19.