Related Research Articles

MP3 is a coding format for digital audio developed largely by the Fraunhofer Society in Germany under the lead of Karlheinz Brandenburg, with support from other digital scientists in other countries. Originally defined as the third audio format of the MPEG-1 standard, it was retained and further extended—defining additional bit rates and support for more audio channels—as the third audio format of the subsequent MPEG-2 standard. A third version, known as MPEG-2.5—extended to better support lower bit rates—is commonly implemented but is not a recognized standard.

Audio system measurements are a means of quantifying system performance. These measurements are made for several purposes. Designers take measurements so that they can specify the performance of a piece of equipment. Maintenance engineers make them to ensure equipment is still working to specification, or to ensure that the cumulative defects of an audio path are within limits considered acceptable. Audio system measurements often accommodate psychoacoustic principles to measure the system in a way that relates to human hearing.
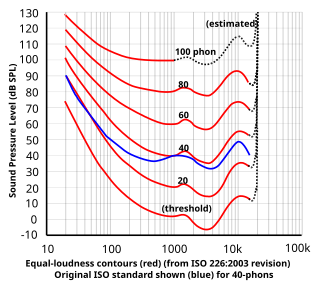
In acoustics, loudness is the subjective perception of sound pressure. More formally, it is defined as the "attribute of auditory sensation in terms of which sounds can be ordered on a scale extending from quiet to loud". The relation of physical attributes of sound to perceived loudness consists of physical, physiological and psychological components. The study of apparent loudness is included in the topic of psychoacoustics and employs methods of psychophysics.
An equal-loudness contour is a measure of sound pressure level, over the frequency spectrum, for which a listener perceives a constant loudness when presented with pure steady tones. The unit of measurement for loudness levels is the phon and is arrived at by reference to equal-loudness contours. By definition, two sine waves of differing frequencies are said to have equal-loudness level measured in phons if they are perceived as equally loud by the average young person without significant hearing impairment.

G.722 is an ITU-T standard 7 kHz wideband audio codec operating at 48, 56 and 64 kbit/s. It was approved by ITU-T in November 1988. Technology of the codec is based on sub-band ADPCM (SB-ADPCM). The corresponding narrow-band codec based on the same technology is G.726.
In data compression and psychoacoustics, transparency is the result of lossy data compression accurate enough that the compressed result is perceptually indistinguishable from the uncompressed input, i.e. perceptually lossless.
Mean opinion score (MOS) is a measure used in the domain of Quality of Experience and telecommunications engineering, representing overall quality of a stimulus or system. It is the arithmetic mean over all individual "values on a predefined scale that a subject assigns to his opinion of the performance of a system quality". Such ratings are usually gathered in a subjective quality evaluation test, but they can also be algorithmically estimated.
Perceptual Speech Quality Measure (PSQM) is a computational and modeling algorithm defined in Recommendation ITU-T P.861 that objectively evaluates and quantifies voice quality of voice-band speech codecs. It may be used to rank the performance of these speech codecs with differing speech input levels, talkers, bit rates and transcodings. P.861 was withdrawn and replaced by Recommendation ITU-T P.862 (PESQ), which contains an improved speech assessment algorithm.
Video quality is a characteristic of a video passed through a video transmission or processing system that describes perceived video degradation. Video processing systems may introduce some amount of distortion or artifacts in the video signal that negatively impact the user's perception of the system. For many stakeholders in video production and distribution, ensuring video quality is an important task.
SINPO, an acronym for Signal, Interference, Noise, Propagation, and Overall, is a Signal Reporting Code used to describe the quality of broadcast and radiotelegraph transmissions. SINPFEMO, an acronym for Signal, Interference, Noise, Propagation, frequency of Fading, dEpth, Modulation, and Overall is used to describe the quality of radiotelephony transmissions. SINPFEMO code consists of the SINPO code plus the addition of three letters to describe additional features of radiotelephony transmissions. These codes are defined by Recommendation ITU-R Sm.1135, SINPO and SINPFEMO codes.
Subjective video quality is video quality as experienced by humans. It is concerned with how video is perceived by a viewer and designates their opinion on a particular video sequence. It is related to the field of Quality of Experience. Measuring subjective video quality is necessary because objective quality assessment algorithms such as PSNR have been shown to correlate poorly with subjective ratings. Subjective ratings may also be used as ground truth to develop new algorithms.
A codec listening test is a scientific study designed to compare two or more lossy audio codecs, usually with respect to perceived fidelity or compression efficiency.
An ABX test is a method of comparing two choices of sensory stimuli to identify detectable differences between them. A subject is presented with two known samples followed by one unknown sample X that is randomly selected from either A or B. The subject is then required to identify X as either A or B. If X cannot be identified reliably with a low p-value in a predetermined number of trials, then the null hypothesis cannot be rejected and it cannot be proven that there is a perceptible difference between A and B.
Perceptual Evaluation of Audio Quality (PEAQ) is a standardized algorithm for objectively measuring perceived audio quality, developed in 1994–1998 by a joint venture of experts within Task Group 6Q of the International Telecommunication Union's Radiocommunication Sector (ITU-R). It was originally released as ITU-R Recommendation BS.1387 in 1998 and last updated in 2023. It utilizes software to simulate perceptual properties of the human ear and then integrates multiple model output variables into a single metric.
Latency refers to a short period of delay between when an audio signal enters a system, and when it emerges. Potential contributors to latency in an audio system include analog-to-digital conversion, buffering, digital signal processing, transmission time, digital-to-analog conversion, and the speed of sound in the transmission medium.
Perceptual Evaluation of Speech Quality (PESQ) is a family of standards comprising a test methodology for automated assessment of the speech quality as experienced by a user of a telephony system. It was standardized as Recommendation ITU-T P.862 in 2001. PESQ is used for objective voice quality testing by phone manufacturers, network equipment vendors and telecom operators. Its usage requires a license. The first edition of PESQ's successor POLQA entered into force in 2011.
Wideband audio, also known as wideband voice or HD voice, is high definition voice quality for telephony audio, contrasted with standard digital telephony "toll quality". It extends the frequency range of audio signals transmitted over telephone lines, resulting in higher quality speech. The range of the human voice extends from 100 Hz to 17 kHz but traditional, voiceband or narrowband telephone calls limit audio frequencies to the range of 300 Hz to 3.4 kHz. Wideband audio relaxes the bandwidth limitation and transmits in the audio frequency range of 50 Hz to 7 kHz. In addition, some wideband codecs may use a higher audio bit depth of 16 bits to encode samples, also resulting in much better voice quality.
Perceptual Objective Listening Quality Analysis (POLQA) was the working title of an ITU-T standard that covers a model to predict speech quality by means of analyzing digital speech signals. The model was standardized as Recommendation ITU-T P.863 in 2011. The second edition of the standard appeared in 2014, and the third, currently in-force edition was adopted in 2018 under the title Perceptual objective listening quality prediction.
High-resolution audio is a term for audio files with greater than 44.1 kHz sample rate or higher than 16-bit audio bit depth. It commonly refers to 96 or 192 kHz sample rates. However, 44.1 kHz/24-bit, 48 kHz/24-bit and 88.2 kHz/24-bit recordings also exist that are labeled HD Audio.
Dolby AC-4 is an audio compression technology developed by Dolby Laboratories. Dolby AC-4 bitstreams can contain audio channels and/or audio objects. Dolby AC-4 has been adopted by the DVB project and standardized by the ETSI.
References
- ↑ ITU-R recommendation BS.1534
- ↑ ITU-R BS.1116 (February 2015). "Methods for the subjective assessment of small impairments in audio systems".
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: numeric names: authors list (link) - 1 2 Schinkel-Bielefeld, N., Lotze, N. and Nagel, F. (May 2013). "Audio quality evaluation by experienced and inexperienced listeners". The Journal of the Acoustical Society of America. 133 (5): 3246. Bibcode:2013ASAJ..133.3246S. doi:10.1121/1.4805210.
{{cite journal}}: CS1 maint: multiple names: authors list (link) - ↑ Rumsey, Francis; Zielinski, Slawomir; Kassier, Rafael; Bech, Søren (2005-05-31). "Relationships between experienced listener ratings of multichannel audio quality and naïve listener preferences". The Journal of the Acoustical Society of America. 117 (6): 3832–3840. Bibcode:2005ASAJ..117.3832R. doi:10.1121/1.1904305. ISSN 0001-4966. PMID 16018485.
- ↑ Gaëtan, Lorho; Guillaume, Le Ray; Nick, Zacharov (2010-06-13). "eGauge—A Measure of Assessor Expertise in Audio Quality Evaluations". Proceedings of the Audio Engineering Society. 38th International Conference on Sound Quality Evaluation.
- ↑ Ekeroot, Jonas; Berg, Jan; Nykänen, Arne (2014-04-25). "Criticality of Audio Stimuli for Listening Tests – Listening Durations During a Ranking Task". 136th Convention of the Audio Engineering Society.
- ↑ Max, Neuendorf; Frederik, Nagel (2011-10-19). "Exploratory Studies on Perceptual Stationarity in Listening Test - Part I: Real World Signals from Custom Listening Tests".
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Frederik, Nagel; Max, Neuendorf (2011-10-19). "Exploratory Studies on Perceptual Stationarity in Listening Test - Part II: Synthetic Signals with Time Varying Artifacts".
{{cite journal}}: Cite journal requires|journal=(help) - ↑ Nadja, Schinkel-Bielefeld (2017-05-11). "Audio Quality Evaluation in MUSHRA Tests–Influences between Loop Setting and a Listeners' Ratings". 142nd Convention of the Audio Engineering Society.
- ↑ ITU-T P.800 (August 1996). "P.800 : Methods for subjective determination of transmission quality".
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: numeric names: authors list (link) - ↑ Nadja, Schinkel-Bielefeld; Zhang, Jiandong; Qin, Yili; Katharina, Leschanowsky, Anna; Fu, Shanshan (2017-05-11). "Is it Harder to Perceive Coding Artifact in Foreign Language Items? – A Study with Mandarin Chinese and German Speaking Listeners".
{{cite journal}}: Cite journal requires|journal=(help)CS1 maint: multiple names: authors list (link) - ↑ Blašková, Lubica; Holub, Jan (2008). "How do Non-native Listeners Perceive Quality of Transmitted Voice?" (PDF). Communications. 10 (4): 11–15. doi:10.26552/com.C.2008.4.11-14. S2CID 196699038.