
The Heterogeneous Element Processor (HEP) [1] was introduced by Denelcor, Inc. in 1982. The HEP's architect was Burton Smith. The machine was designed to solve fluid dynamics problems for the Ballistic Research Laboratory. [2] A HEP system, as the name implies, was pieced together from many heterogeneous components -- processors, data memory modules, and I/O modules. The components were connected via a switched network.
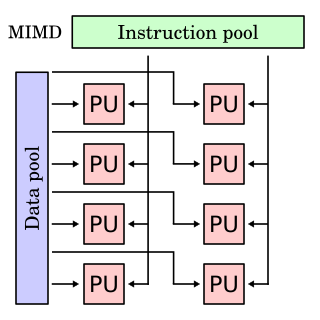
A single processor, called a PEM (Process Execution Module), in a HEP system (up to sixteen PEMs could be connected) was rather unconventional; via a "program status word (PSW) queue" up to fifty processes could be maintained in hardware at once. The largest system ever delivered had 4 PEMs. The eight-stage instruction pipeline allowed instructions from eight different processes to proceed at once. In fact, only one instruction from a given process was allowed to be present in the pipeline at any point in time. Therefore, the full processor throughput of 10 MIPS could only be achieved when eight or more processes were active; no single process could achieve throughput greater than 1.25 MIPS. This type of multithreading processing classifies today the HEP as a barrel processor, while it was described as an MIMD pipelined processor [3] by its designers. The hardware implementation of the HEP PEM was emitter-coupled logic.
Processes were classified as either user-level or supervisor-level. User-level processes could create supervisor-level processes, which were used to manage user-level processes and perform I/O. Processes of the same class were required to be grouped into one of seven user tasks and seven supervisor tasks.
Each processor, in addition to the PSW queue and instruction pipeline, contained instruction memory, 2,048 64-bit general purpose registers and 4,096 constant registers. Constant registers were differentiated by the fact that only supervisor processes could modify their contents. The processors themselves contained no data memory; instead, data memory modules could be separately attached to the switched network.
The HEP memory consisted of completely separate instruction memory (up to 128 MBs) and data memory (up to 1 GB). Users saw 64-bit words, but in reality, data memory words were 72-bit with the extra bits used for state, see next paragraph, parity, tagging, and other uses.
The HEP implemented a type of mutual exclusion in which all registers and locations in data memory had associated "empty" and "full" states. Reading from a location set the state to "empty," while writing to it set the state to "full." A programmer could allow processes to halt after trying to read from an empty location or write to a full location, enforcing critical sections.
The switched network [4] between elements resembled, in many ways, a modern computer network. On the network were sets of nodes, each of which had three links. When a packet arrived at a node, it consulted a routing table and attempted to forward the packet closer to its destination. If a node became congested, any incoming packets were passed on without routing. Packets treated in such a manner had their priority level increased; when several packets vied for a single node, a packet with a higher priority level would be routed before ones with lower priority levels.
Another component of the switched network was the sO System, with its own memory and many individual DEC UNIBUS buses attached for disks and other peripherals. The system also had the ability to save the full/empty bits not normally visible directly. The initial IO System performance was shown to be woefully inadequate due to the high latency in starting the IO operations. Ron Natalie (from BRL) and Burton Smith designed a new system out of spare parts on napkins at a local steakhouse and put it into operation in the course of the ensuing week.
The HEP's primary application programming language was a unique Fortran variant. In time C, Pascal, and SISAL were added. The syntax of data variables using full-empty bits prepended '$' before their name. So 'A' would name a local variable, but $A would be a locking full-empty variable. Application dead-lock was thus possible. Problematic, failure to '$' could introduce unintended numerical inaccuracy.
The first HEP operating system was HEPOS. Mike Muuss was involved in a Unix port for the Ballistic Research Laboratory. HEPOS was not a Unix-like operating system.
Although it was known to have poor cost-performance, the HEP received attention due to what were, at the time, several revolutionary features. The HEP had the performance of a CDC 7600-class computer in the Cray-1 era. HEP systems were leased by the Ballistic Research Laboratory (four PEM system), Los Alamos, [1] the Argonne National Laboratory (single PEM), the National Security Agency and Shoko Ltd (Japan, 1 PEM). Germany's Messerschmitt (three PEMS system) is the only client who bought it. [5] Denelcor also delivered a two PEM system to the University of Georgia in exchange for them providing software assistance (the system had also been offered to the University of Maryland). [6] Messerschmitt was the only client to put the HEP into use for "real" applications; the other clients used it for experimenting with parallel algorithms. The BRL system was used to prepare a movie using the BRL-CAD software as its only real application. Faster and larger designs for HEP-2 and HEP-3 were started but never completed. The architectural concept would later be embodied with the code-name Horizon.
| External image | |
|---|---|








{kind=link}