In machine learning, support vector machines are supervised max-margin models with associated learning algorithms that analyze data for classification and regression analysis. Developed at AT&T Bell Laboratories, SVMs are one of the most studied models, being based on statistical learning frameworks of VC theory proposed by Vapnik and Chervonenkis (1974).
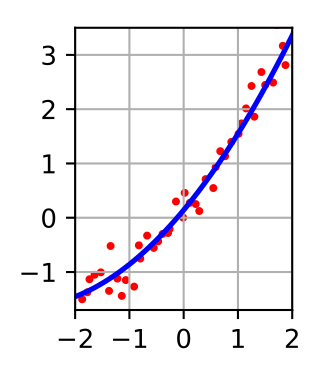
In regression analysis, least squares is a parameter estimation method based on minimizing the sum of the squares of the residuals made in the results of each individual equation.
In statistics, the Gauss–Markov theorem states that the ordinary least squares (OLS) estimator has the lowest sampling variance within the class of linear unbiased estimators, if the errors in the linear regression model are uncorrelated, have equal variances and expectation value of zero. The errors do not need to be normal, nor do they need to be independent and identically distributed. The requirement that the estimator be unbiased cannot be dropped, since biased estimators exist with lower variance. See, for example, the James–Stein estimator, ridge regression, or simply any degenerate estimator.
In mathematics and computing, the Levenberg–Marquardt algorithm, also known as the damped least-squares (DLS) method, is used to solve non-linear least squares problems. These minimization problems arise especially in least squares curve fitting. The LMA interpolates between the Gauss–Newton algorithm (GNA) and the method of gradient descent. The LMA is more robust than the GNA, which means that in many cases it finds a solution even if it starts very far off the final minimum. For well-behaved functions and reasonable starting parameters, the LMA tends to be slower than the GNA. LMA can also be viewed as Gauss–Newton using a trust region approach.
Ridge regression is a method of estimating the coefficients of multiple-regression models in scenarios where the independent variables are highly correlated. It has been used in many fields including econometrics, chemistry, and engineering. Also known as Tikhonov regularization, named for Andrey Tikhonov, it is a method of regularization of ill-posed problems. It is particularly useful to mitigate the problem of multicollinearity in linear regression, which commonly occurs in models with large numbers of parameters. In general, the method provides improved efficiency in parameter estimation problems in exchange for a tolerable amount of bias.

In mathematics, statistics, finance, and computer science, particularly in machine learning and inverse problems, regularization is a process that converts the answer of a problem to a simpler one. It is often used in solving ill-posed problems or to prevent overfitting.
In statistics, Poisson regression is a generalized linear model form of regression analysis used to model count data and contingency tables. Poisson regression assumes the response variable Y has a Poisson distribution, and assumes the logarithm of its expected value can be modeled by a linear combination of unknown parameters. A Poisson regression model is sometimes known as a log-linear model, especially when used to model contingency tables.
In statistics, a generalized additive model (GAM) is a generalized linear model in which the linear response variable depends linearly on unknown smooth functions of some predictor variables, and interest focuses on inference about these smooth functions.
Proportional hazards models are a class of survival models in statistics. Survival models relate the time that passes, before some event occurs, to one or more covariates that may be associated with that quantity of time. In a proportional hazards model, the unique effect of a unit increase in a covariate is multiplicative with respect to the hazard rate. The hazard rate at time is the probability per short time dt that an event will occur between and given that up to time no event has occurred yet. For example, taking a drug may halve one's hazard rate for a stroke occurring, or, changing the material from which a manufactured component is constructed, may double its hazard rate for failure. Other types of survival models such as accelerated failure time models do not exhibit proportional hazards. The accelerated failure time model describes a situation where the biological or mechanical life history of an event is accelerated.
Bayesian linear regression is a type of conditional modeling in which the mean of one variable is described by a linear combination of other variables, with the goal of obtaining the posterior probability of the regression coefficients and ultimately allowing the out-of-sample prediction of the regressandconditional on observed values of the regressors. The simplest and most widely used version of this model is the normal linear model, in which given is distributed Gaussian. In this model, and under a particular choice of prior probabilities for the parameters—so-called conjugate priors—the posterior can be found analytically. With more arbitrarily chosen priors, the posteriors generally have to be approximated.
In statistics, principal component regression (PCR) is a regression analysis technique that is based on principal component analysis (PCA). PCR is a form of reduced rank regression. More specifically, PCR is used for estimating the unknown regression coefficients in a standard linear regression model.
In statistical theory, the field of high-dimensional statistics studies data whose dimension is larger than typically considered in classical multivariate analysis. The area arose owing to the emergence of many modern data sets in which the dimension of the data vectors may be comparable to, or even larger than, the sample size, so that justification for the use of traditional techniques, often based on asymptotic arguments with the dimension held fixed as the sample size increased, was lacking.
In statistics and machine learning, lasso is a regression analysis method that performs both variable selection and regularization in order to enhance the prediction accuracy and interpretability of the resulting statistical model. The lasso method assumes that the coefficients of the linear model are sparse, meaning that few of them are non-zero. It was originally introduced in geophysics, and later by Robert Tibshirani, who coined the term.
Least-squares support-vector machines (LS-SVM) for statistics and in statistical modeling, are least-squares versions of support-vector machines (SVM), which are a set of related supervised learning methods that analyze data and recognize patterns, and which are used for classification and regression analysis. In this version one finds the solution by solving a set of linear equations instead of a convex quadratic programming (QP) problem for classical SVMs. Least-squares SVM classifiers were proposed by Johan Suykens and Joos Vandewalle. LS-SVMs are a class of kernel-based learning methods.
Proximal gradientmethods for learning is an area of research in optimization and statistical learning theory which studies algorithms for a general class of convex regularization problems where the regularization penalty may not be differentiable. One such example is regularization of the form
Multiple kernel learning refers to a set of machine learning methods that use a predefined set of kernels and learn an optimal linear or non-linear combination of kernels as part of the algorithm. Reasons to use multiple kernel learning include a) the ability to select for an optimal kernel and parameters from a larger set of kernels, reducing bias due to kernel selection while allowing for more automated machine learning methods, and b) combining data from different sources that have different notions of similarity and thus require different kernels. Instead of creating a new kernel, multiple kernel algorithms can be used to combine kernels already established for each individual data source.
De-sparsified lasso contributes to construct confidence intervals and statistical tests for single or low-dimensional components of a large parameter vector in high-dimensional model.
In statistics, linear regression is a model that estimates the linear relationship between a scalar response and one or more explanatory variables. A model with exactly one explanatory variable is a simple linear regression; a model with two or more explanatory variables is a multiple linear regression. This term is distinct from multivariate linear regression, which predicts multiple correlated dependent variables rather than a single dependent variable.
Regularized least squares (RLS) is a family of methods for solving the least-squares problem while using regularization to further constrain the resulting solution.
Structured sparsity regularization is a class of methods, and an area of research in statistical learning theory, that extend and generalize sparsity regularization learning methods. Both sparsity and structured sparsity regularization methods seek to exploit the assumption that the output variable to be learned can be described by a reduced number of variables in the input space . Sparsity regularization methods focus on selecting the input variables that best describe the output. Structured sparsity regularization methods generalize and extend sparsity regularization methods, by allowing for optimal selection over structures like groups or networks of input variables in .












