In computer programming and software design, code refactoring is the process of restructuring existing source code—changing the factoring—without changing its external behavior. Refactoring is intended to improve the design, structure, and/or implementation of the software, while preserving its functionality. Potential advantages of refactoring may include improved code readability and reduced complexity; these can improve the source code's maintainability and create a simpler, cleaner, or more expressive internal architecture or object model to improve extensibility. Another potential goal for refactoring is improved performance; software engineers face an ongoing challenge to write programs that perform faster or use less memory.
Programming style, also known as coding style, refers to the conventions and patterns used in writing source code, resulting in a consistent and readable codebase. These conventions often encompass aspects such as indentation, naming conventions, capitalization, and comments. Consistent programming style is generally considered beneficial for code readability and maintainability, particularly in collaborative environments.
In computing, inline expansion, or inlining, is a manual or compiler optimization that replaces a function call site with the body of the called function. Inline expansion is similar to macro expansion, but occurs during compilation, without changing the source code, while macro expansion occurs prior to compilation, and results in different text that is then processed by the compiler.
Copy-and-paste programming, sometimes referred to as just pasting, is the production of highly repetitive computer programming code, as produced by copy and paste operations. It is primarily a pejorative term; those who use the term are often implying a lack of programming competence and ability to create abstractions. It may also be the result of technology limitations as subroutines or libraries would normally be used instead. However, there are occasions when copy-and-paste programming is considered acceptable or necessary, such as for boilerplate, loop unrolling, languages with limited metaprogramming facilities, or certain programming idioms, and it is supported by some source code editors in the form of snippets.

F# is a general-purpose, high-level, strongly typed, multi-paradigm programming language that encompasses functional, imperative, and object-oriented programming methods. It is most often used as a cross-platform Common Language Infrastructure (CLI) language on .NET, but can also generate JavaScript and graphics processing unit (GPU) code.

D, also known as dlang, is a multi-paradigm system programming language created by Walter Bright at Digital Mars and released in 2001. Andrei Alexandrescu joined the design and development effort in 2007. Though it originated as a re-engineering of C++, D is now a very different language. As it has developed, it has drawn inspiration from other high-level programming languages. Notably, it has been influenced by Java, Python, Ruby, C#, and Eiffel.

The syntax of the C programming language is the set of rules governing writing of software in C. It is designed to allow for programs that are extremely terse, have a close relationship with the resulting object code, and yet provide relatively high-level data abstraction. C was the first widely successful high-level language for portable operating-system development.
MBASIC is the Microsoft BASIC implementation of BASIC for the CP/M operating system. MBASIC is a descendant of the original Altair BASIC interpreters that were among Microsoft's first products. MBASIC was one of the two versions of BASIC bundled with the Osborne 1 computer. The name "MBASIC" is derived from the disk file name MBASIC.COM of the BASIC interpreter.
In mathematics and in computer programming, a variadic function is a function of indefinite arity, i.e., one which accepts a variable number of arguments. Support for variadic functions differs widely among programming languages.

AutoIt is a freeware programming language for Microsoft Windows. In its earliest release, it was primarily intended to create automation scripts for Microsoft Windows programs but has since grown to include enhancements in both programming language design and overall functionality.
Automatic parallelization, also auto parallelization, or autoparallelization refers to converting sequential code into multi-threaded and/or vectorized code in order to use multiple processors simultaneously in a shared-memory multiprocessor (SMP) machine. Fully automatic parallelization of sequential programs is a challenge because it requires complex program analysis and the best approach may depend upon parameter values that are not known at compilation time.
The C and C++ programming languages are closely related but have many significant differences. C++ began as a fork of an early, pre-standardized C, and was designed to be mostly source-and-link compatible with C compilers of the time. Due to this, development tools for the two languages are often integrated into a single product, with the programmer able to specify C or C++ as their source language.
Tacit programming, also called point-free style, is a programming paradigm in which function definitions do not identify the arguments on which they operate. Instead the definitions merely compose other functions, among which are combinators that manipulate the arguments. Tacit programming is of theoretical interest, because the strict use of composition results in programs that are well adapted for equational reasoning. It is also the natural style of certain programming languages, including APL and its derivatives, and concatenative languages such as Forth. The lack of argument naming gives point-free style a reputation of being unnecessarily obscure, hence the epithet "pointless style".
Plagiarism detection or content similarity detection is the process of locating instances of plagiarism or copyright infringement within a work or document. The widespread use of computers and the advent of the Internet have made it easier to plagiarize the work of others.
The syntax and semantics of PHP, a programming language, form a set of rules that define how a PHP program can be written and interpreted.
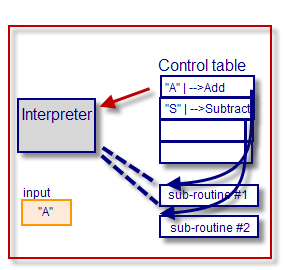
Control tables are tables that control the control flow or play a major part in program control. There are no rigid rules about the structure or content of a control table—its qualifying attribute is its ability to direct control flow in some way through "execution" by a processor or interpreter. The design of such tables is sometimes referred to as table-driven design. In some cases, control tables can be specific implementations of finite-state-machine-based automata-based programming. If there are several hierarchical levels of control table they may behave in a manner equivalent to UML state machines
This article describes the features in the programming language Haskell.
Nemerle is a general-purpose, high-level, statically typed programming language designed for platforms using the Common Language Infrastructure (.NET/Mono). It offers functional, object-oriented, aspect-oriented, reflective and imperative features. It has a simple C#-like syntax and a powerful metaprogramming system.

Dafny is an imperative and functional compiled language that compiles to other programming languages, such as C#, Java, JavaScript, Go and Python. It supports formal specification through preconditions, postconditions, loop invariants, loop variants, termination specifications and read/write framing specifications. The language combines ideas from the functional and imperative paradigms; it includes support for object-oriented programming. Features include generic classes, dynamic allocation, inductive datatypes and a variation of separation logic known as implicit dynamic frames for reasoning about side effects. Dafny was created by Rustan Leino at Microsoft Research after his previous work on developing ESC/Modula-3, ESC/Java, and Spec#.
This glossary of computer science is a list of definitions of terms and concepts used in computer science, its sub-disciplines, and related fields, including terms relevant to software, data science, and computer programming.
