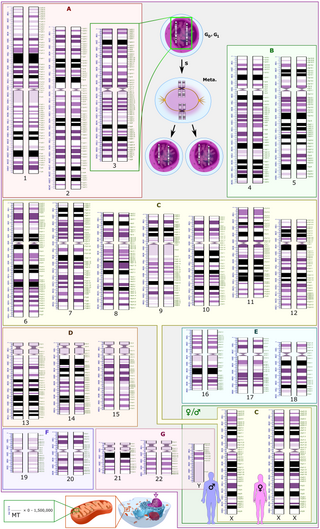
The human genome is a complete set of nucleic acid sequences for humans, encoded as the DNA within each of the 24 distinct chromosomes in the cell nucleus. A small DNA molecule is found within individual mitochondria. These are usually treated separately as the nuclear genome and the mitochondrial genome. Human genomes include both protein-coding DNA sequences and various types of DNA that does not encode proteins. The latter is a diverse category that includes DNA coding for non-translated RNA, such as that for ribosomal RNA, transfer RNA, ribozymes, small nuclear RNAs, and several types of regulatory RNAs. It also includes promoters and their associated gene-regulatory elements, DNA playing structural and replicatory roles, such as scaffolding regions, telomeres, centromeres, and origins of replication, plus large numbers of transposable elements, inserted viral DNA, non-functional pseudogenes and simple, highly repetitive sequences. Introns make up a large percentage of non-coding DNA. Some of this non-coding DNA is non-functional junk DNA, such as pseudogenes, but there is no firm consensus on the total amount of junk DNA.
Genomics is an interdisciplinary field of molecular biology focusing on the structure, function, evolution, mapping, and editing of genomes. A genome is an organism's complete set of DNA, including all of its genes as well as its hierarchical, three-dimensional structural configuration. In contrast to genetics, which refers to the study of individual genes and their roles in inheritance, genomics aims at the collective characterization and quantification of all of an organism's genes, their interrelations and influence on the organism. Genes may direct the production of proteins with the assistance of enzymes and messenger molecules. In turn, proteins make up body structures such as organs and tissues as well as control chemical reactions and carry signals between cells. Genomics also involves the sequencing and analysis of genomes through uses of high throughput DNA sequencing and bioinformatics to assemble and analyze the function and structure of entire genomes. Advances in genomics have triggered a revolution in discovery-based research and systems biology to facilitate understanding of even the most complex biological systems such as the brain.
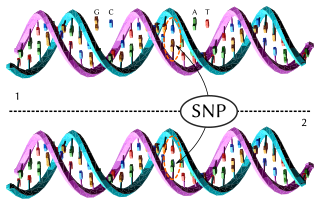
In genetics and bioinformatics, a single-nucleotide polymorphism is a germline substitution of a single nucleotide at a specific position in the genome. Although certain definitions require the substitution to be present in a sufficiently large fraction of the population, many publications do not apply such a frequency threshold.
The International HapMap Project was an organization that aimed to develop a haplotype map (HapMap) of the human genome, to describe the common patterns of human genetic variation. HapMap is used to find genetic variants affecting health, disease and responses to drugs and environmental factors. The information produced by the project is made freely available for research.
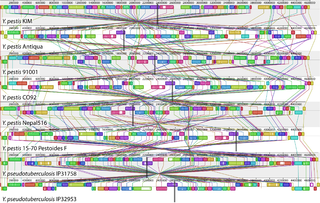
Comparative genomics is a branch of biological research that examines genome sequences across a spectrum of species, spanning from humans and mice to a diverse array of organisms from bacteria to chimpanzees. This large-scale holistic approach compares two or more genomes to discover the similarities and differences between the genomes and to study the biology of the individual genomes. Comparison of whole genome sequences provides a highly detailed view of how organisms are related to each other at the gene level. By comparing whole genome sequences, researchers gain insights into genetic relationships between organisms and study evolutionary changes. The major principle of comparative genomics is that common features of two organisms will often be encoded within the DNA that is evolutionarily conserved between them. Therefore, Comparative genomics provides a powerful tool for studying evolutionary changes among organisms, helping to identify genes that are conserved or common among species, as well as genes that give unique characteristics of each organism. Moreover, these studies can be performed at different levels of the genomes to obtain multiple perspectives about the organisms.

The Wellcome Sanger Institute, previously known as The Sanger Centre and Wellcome Trust Sanger Institute, is a non-profit British genomics and genetics research institute, primarily funded by the Wellcome Trust.
Indel (insertion-deletion) is a molecular biology term for an insertion or deletion of bases in the genome of an organism. Indels ≥ 50 bases in length are classified as structural variants.

Human genetic variation is the genetic differences in and among populations. There may be multiple variants of any given gene in the human population (alleles), a situation called polymorphism.
Human evolutionary genetics studies how one human genome differs from another human genome, the evolutionary past that gave rise to the human genome, and its current effects. Differences between genomes have anthropological, medical, historical and forensic implications and applications. Genetic data can provide important insights into human evolution.
Population genomics is the large-scale comparison of DNA sequences of populations. Population genomics is a neologism that is associated with population genetics. Population genomics studies genome-wide effects to improve our understanding of microevolution so that we may learn the phylogenetic history and demography of a population.
Whole genome sequencing (WGS) is the process of determining the entirety, or nearly the entirety, of the DNA sequence of an organism's genome at a single time. This entails sequencing all of an organism's chromosomal DNA as well as DNA contained in the mitochondria and, for plants, in the chloroplast.
Cancer genome sequencing is the whole genome sequencing of a single, homogeneous or heterogeneous group of cancer cells. It is a biochemical laboratory method for the characterization and identification of the DNA or RNA sequences of cancer cell(s).

Exome sequencing, also known as whole exome sequencing (WES), is a genomic technique for sequencing all of the protein-coding regions of genes in a genome. It consists of two steps: the first step is to select only the subset of DNA that encodes proteins. These regions are known as exons—humans have about 180,000 exons, constituting about 1% of the human genome, or approximately 30 million base pairs. The second step is to sequence the exonic DNA using any high-throughput DNA sequencing technology.

A reference genome is a digital nucleic acid sequence database, assembled by scientists as a representative example of the set of genes in one idealized individual organism of a species. As they are assembled from the sequencing of DNA from a number of individual donors, reference genomes do not accurately represent the set of genes of any single individual organism. Instead, a reference provides a haploid mosaic of different DNA sequences from each donor. For example, one of the most recent human reference genomes, assembly GRCh38/hg38, is derived from >60 genomic clone libraries. There are reference genomes for multiple species of viruses, bacteria, fungus, plants, and animals. Reference genomes are typically used as a guide on which new genomes are built, enabling them to be assembled much more quickly and cheaply than the initial Human Genome Project. Reference genomes can be accessed online at several locations, using dedicated browsers such as Ensembl or UCSC Genome Browser.
Genomic structural variation is the variation in structure of an organism's chromosome, such as deletions, duplications, copy-number variants, insertions, inversions and translocations. Originally, a structure variation affects a sequence length about 1kb to 3Mb, which is larger than SNPs and smaller than chromosome abnormality. However, the operational range of structural variants has widened to include events > 50bp. Some structural variants are associated with genetic diseases, however most are not. Approximately 13% of the human genome is defined as structurally variant in the normal population, and there are at least 240 genes that exist as homozygous deletion polymorphisms in human populations, suggesting these genes are dispensable in humans. While humans carry a median of 3.6 Mbp in SNPs, a median of 8.9 Mbp is affected by structural variation which thus causes most genetic differences between humans in terms of raw sequence data.
In genetics, imputation is the statistical inference of unobserved genotypes. It is achieved by using known haplotypes in a population, for instance from the HapMap or the 1000 Genomes Project in humans, thereby allowing to test for association between a trait of interest and experimentally untyped genetic variants, but whose genotypes have been statistically inferred ("imputed"). Genotype imputation is usually performed on SNPs, the most common kind of genetic variation.
Single nucleotide polymorphism annotation is the process of predicting the effect or function of an individual SNP using SNP annotation tools. In SNP annotation the biological information is extracted, collected and displayed in a clear form amenable to query. SNP functional annotation is typically performed based on the available information on nucleic acid and protein sequences.

Structural variation in the human genome is operationally defined as genomic alterations, varying between individuals, that involve DNA segments larger than 1 kilo base (kb), and could be either microscopic or submicroscopic. This definition distinguishes them from smaller variants that are less than 1 kb in size such as short deletions, insertions, and single nucleotide variants.
ANNOVAR is a bioinformatics software tool for the interpretation and prioritization of single nucleotide variants (SNVs), insertions, deletions, and copy number variants (CNVs) of a given genome.
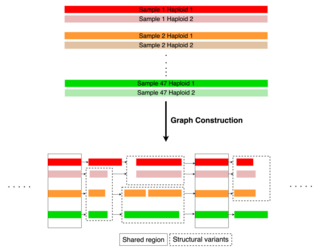
The Human Pangenome Reference is a collection of genomes from a diverse cohort of individuals compiled by the Human Pangenome Reference Consortium (HPRC). This first draft pangenome comprises 47 phased, diploid assemblies from a diverse cohort of individuals and was intended to capture the genetic diversity of the human population. The development of this pangenome seeks to address perceived shortcomings in the current human reference genome by offering a more comprehensive and inclusive resource for genomic research and analysis.


