WO2024145935A1 - Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium - Google Patents
Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium Download PDFInfo
- Publication number
- WO2024145935A1 WO2024145935A1 PCT/CN2023/071072 CN2023071072W WO2024145935A1 WO 2024145935 A1 WO2024145935 A1 WO 2024145935A1 CN 2023071072 W CN2023071072 W CN 2023071072W WO 2024145935 A1 WO2024145935 A1 WO 2024145935A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- node
- prediction
- current
- nodes
- information
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 373
- 238000003860 storage Methods 0.000 title claims abstract description 23
- 238000012545 processing Methods 0.000 claims description 39
- 230000015654 memory Effects 0.000 claims description 32
- 238000004590 computer program Methods 0.000 claims description 26
- 238000005457 optimization Methods 0.000 abstract 1
- 230000000875 corresponding effect Effects 0.000 description 516
- 230000008569 process Effects 0.000 description 115
- 238000010586 diagram Methods 0.000 description 54
- 230000009466 transformation Effects 0.000 description 29
- 238000013139 quantization Methods 0.000 description 24
- 230000006835 compression Effects 0.000 description 19
- 238000007906 compression Methods 0.000 description 19
- 238000000638 solvent extraction Methods 0.000 description 13
- 230000006870 function Effects 0.000 description 12
- 238000004364 calculation method Methods 0.000 description 11
- 238000004422 calculation algorithm Methods 0.000 description 10
- 238000004891 communication Methods 0.000 description 9
- 238000006243 chemical reaction Methods 0.000 description 8
- 238000005516 engineering process Methods 0.000 description 7
- 238000012935 Averaging Methods 0.000 description 6
- 230000005540 biological transmission Effects 0.000 description 6
- 101100233916 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) KAR5 gene Proteins 0.000 description 5
- 238000009826 distribution Methods 0.000 description 5
- 238000012812 general test Methods 0.000 description 5
- 238000010276 construction Methods 0.000 description 4
- 238000005192 partition Methods 0.000 description 4
- 238000005070 sampling Methods 0.000 description 4
- 230000001360 synchronised effect Effects 0.000 description 4
- 101100012902 Saccharomyces cerevisiae (strain ATCC 204508 / S288c) FIG2 gene Proteins 0.000 description 3
- 230000008878 coupling Effects 0.000 description 3
- 238000010168 coupling process Methods 0.000 description 3
- 238000005859 coupling reaction Methods 0.000 description 3
- 238000013500 data storage Methods 0.000 description 3
- 210000000056 organ Anatomy 0.000 description 3
- 238000007781 pre-processing Methods 0.000 description 3
- 239000007787 solid Substances 0.000 description 3
- 235000014347 soups Nutrition 0.000 description 3
- 230000003068 static effect Effects 0.000 description 3
- 230000000007 visual effect Effects 0.000 description 3
- 101150116295 CAT2 gene Proteins 0.000 description 2
- 101100326920 Caenorhabditis elegans ctl-1 gene Proteins 0.000 description 2
- 101100342039 Halobacterium salinarum (strain ATCC 29341 / DSM 671 / R1) kdpQ gene Proteins 0.000 description 2
- 101100126846 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) katG gene Proteins 0.000 description 2
- 101150019148 Slc7a3 gene Proteins 0.000 description 2
- 230000003044 adaptive effect Effects 0.000 description 2
- 238000004458 analytical method Methods 0.000 description 2
- 239000003086 colorant Substances 0.000 description 2
- 238000002591 computed tomography Methods 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000000694 effects Effects 0.000 description 2
- 238000005259 measurement Methods 0.000 description 2
- 238000012986 modification Methods 0.000 description 2
- 230000004048 modification Effects 0.000 description 2
- 230000003287 optical effect Effects 0.000 description 2
- 238000012797 qualification Methods 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- NAWXUBYGYWOOIX-SFHVURJKSA-N (2s)-2-[[4-[2-(2,4-diaminoquinazolin-6-yl)ethyl]benzoyl]amino]-4-methylidenepentanedioic acid Chemical compound C1=CC2=NC(N)=NC(N)=C2C=C1CCC1=CC=C(C(=O)N[C@@H](CC(=C)C(O)=O)C(O)=O)C=C1 NAWXUBYGYWOOIX-SFHVURJKSA-N 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 241000023320 Luma <angiosperm> Species 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000011960 computer-aided design Methods 0.000 description 1
- 238000013523 data management Methods 0.000 description 1
- 230000006837 decompression Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 238000007689 inspection Methods 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000001788 irregular Effects 0.000 description 1
- 239000004973 liquid crystal related substance Substances 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- 238000004519 manufacturing process Methods 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- OSWPMRLSEDHDFF-UHFFFAOYSA-N methyl salicylate Chemical compound COC(=O)C1=CC=CC=C1O OSWPMRLSEDHDFF-UHFFFAOYSA-N 0.000 description 1
- 239000013307 optical fiber Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 230000008447 perception Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 238000002310 reflectometry Methods 0.000 description 1
- 239000004065 semiconductor Substances 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
Images










































Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/50—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding
- H04N19/597—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using predictive coding specially adapted for multi-view video sequence encoding
Definitions
- FIG2 is a schematic diagram of six viewing angles of a point cloud image
- FIG3 is a schematic block diagram of a point cloud encoding and decoding system according to an embodiment of the present application.
- FIG6E is a schematic diagram of predictive coding of the X or Y axis
- FIG8A is a schematic diagram of an encoding framework of AVS
- FIG8B is a schematic diagram of a decoding framework of AVS
- FIG9D is a schematic diagram of 18 neighboring blocks and their Morton sequence numbers used by the current block to be encoded
- FIG11 is a schematic diagram of octree partitioning
- FIG20 is a schematic block diagram of an electronic device provided in an embodiment of the present application.
- Point cloud data is a specific record form of point cloud.
- Points in the point cloud may include the location information of the point and the attribute information of the point.
- the location information of the point may be the three-dimensional coordinate information of the point.
- the location information of the point may also be called the geometric information of the point.
- the attribute information of the point may include color information, reflectance information, normal vector information, etc.
- Color information reflects the color of an object, and reflectance information reflects the surface material of an object.
- the color information may be information in any color space.
- the color information may be (RGB).
- the color information may be information about brightness and chromaticity (YcbCr, YUV).
- Point clouds are divided into the following types according to the time series of the data:
- the third type of dynamic point cloud acquisition the device that acquires the point cloud is moving.
- Point clouds can be divided into two categories according to their uses:
- Category 1 Machine perception point cloud, which can be used in autonomous navigation systems, real-time inspection systems, geographic information systems, visual sorting robots, disaster relief robots, etc.
- Category 2 Point cloud perceived by the human eye, which can be used in point cloud application scenarios such as digital cultural heritage, free viewpoint broadcasting, 3D immersive communication, and 3D immersive interaction.
- the above point cloud acquisition technology reduces the cost and time of point cloud data acquisition and improves the accuracy of data.
- the change in the point cloud data acquisition method makes it possible to acquire a large amount of point cloud data.
- the processing of massive 3D point cloud data encounters bottlenecks of storage space and transmission bandwidth.
- a point cloud video with a frame rate of 30fps frames per second
- the number of points in each point cloud frame is 700,000
- each point has coordinate information xyz (float) and color information RGB (uchar).
- the data volume of a 10s point cloud video is approximately 0.7 million X (4ByteX3+1ByteX3)
- X 30fpsX10s 3.15GB
- the YUV sampling format is 4:2:0
- the frame rate is 24fps.
- FIG3 is a schematic block diagram of a point cloud encoding and decoding system involved in an embodiment of the present application. It should be noted that FIG3 is only an example, and the point cloud encoding and decoding system of the embodiment of the present application includes but is not limited to that shown in FIG3.
- the point cloud encoding and decoding system 100 includes an encoding device 110 and a decoding device 120.
- the encoding device is used to encode (which can be understood as compression) the point cloud data to generate a code stream, and transmit the code stream to the decoding device.
- the decoding device decodes the code stream generated by the encoding device to obtain decoded point cloud data.
- the encoding device 110 of the embodiment of the present application can be understood as a device with a point cloud encoding function
- the decoding device 120 can be understood as a device with a point cloud decoding function, that is, the embodiment of the present application includes a wider range of devices for the encoding device 110 and the decoding device 120, such as smartphones, desktop computers, mobile computing devices, notebook (e.g., laptop) computers, tablet computers, set-top boxes, televisions, cameras, display devices, digital media players, point cloud game consoles, vehicle-mounted computers, etc.
- the encoding device 110 may transmit the encoded point cloud data (such as a code stream) to the decoding device 120 via the channel 130.
- the channel 130 may include one or more media and/or devices capable of transmitting the encoded point cloud data from the encoding device 110 to the decoding device 120.
- the channel 130 includes one or more communication media that enable the encoding device 110 to transmit the encoded point cloud data directly to the decoding device 120 in real time.
- the encoding device 110 can modulate the encoded point cloud data according to the communication standard and transmit the modulated point cloud data to the decoding device 120.
- the communication medium includes a wireless communication medium, such as a radio frequency spectrum, and optionally, the communication medium may also include a wired communication medium, such as one or more physical transmission lines.
- the channel 130 includes a storage medium, which can store the point cloud data encoded by the encoding device 110.
- the storage medium includes a variety of locally accessible data storage media, such as optical disks, DVDs, flash memories, etc.
- the decoding device 120 can obtain the encoded point cloud data from the storage medium.
- the channel 130 may include a storage server that can store the point cloud data encoded by the encoding device 110.
- the decoding device 120 can download the stored encoded point cloud data from the storage server.
- the storage server can store the encoded point cloud data and transmit the encoded point cloud data to the decoding device 120, such as a web server (e.g., for a website), a file transfer protocol (FTP) server, etc.
- FTP file transfer protocol
- the encoding device 110 includes a point cloud encoder 112 and an output interface 113.
- the output interface 113 may include a modulator/demodulator (modem) and/or a transmitter.
- the encoding device 110 may further include a point cloud source 111 in addition to the point cloud encoder 112 and the input interface 113 .
- the point cloud source 111 may include at least one of a point cloud acquisition device (e.g., a scanner), a point cloud archive, a point cloud input interface, and a computer graphics system, wherein the point cloud input interface is used to receive point cloud data from a point cloud content provider, and the computer graphics system is used to generate point cloud data.
- a point cloud acquisition device e.g., a scanner
- a point cloud archive e.g., a point cloud archive
- a point cloud input interface e.g., a point cloud input interface
- the computer graphics system is used to generate point cloud data.
- the point cloud encoder 112 encodes the point cloud data from the point cloud source 111 to generate a code stream.
- the point cloud encoder 112 transmits the encoded point cloud data directly to the decoding device 120 via the output interface 113.
- the encoded point cloud data can also be stored in a storage medium or a storage server for subsequent reading by the decoding device 120.
- the decoding device 120 includes an input interface 121 and a point cloud decoder 122 .
- the decoding device 120 may further include a display device 123 in addition to the input interface 121 and the point cloud decoder 122 .
- the input interface 121 includes a receiver and/or a modem.
- the input interface 121 can receive the encoded point cloud data through the channel 130 .
- the point cloud decoder 122 is used to decode the encoded point cloud data to obtain decoded point cloud data, and transmit the decoded point cloud data to the display device 123.
- the decoded point cloud data is displayed on the display device 123.
- the display device 123 may be integrated with the decoding device 120 or may be external to the decoding device 120.
- the display device 123 may include a variety of display devices, such as a liquid crystal display (LCD), a plasma display, an organic light emitting diode (OLED) display, or other types of display devices.
- the current point cloud encoder can adopt two point cloud compression coding technology routes proposed by the International Standards Organization Moving Picture Experts Group (MPEG), namely Video-based Point Cloud Compression (VPCC) and Geometry-based Point Cloud Compression (GPCC).
- MPEG International Standards Organization Moving Picture Experts Group
- VPCC Video-based Point Cloud Compression
- GPCC Geometry-based Point Cloud Compression
- VPCC projects the three-dimensional point cloud into two dimensions and uses the existing two-dimensional coding tools to encode the projected two-dimensional image.
- GPCC uses a hierarchical structure to divide the point cloud into multiple units step by step, and encodes the entire point cloud by encoding the division process.
- the following uses the GPCC encoding and decoding framework as an example to explain the point cloud encoder and point cloud decoder applicable to the embodiments of the present application.
- FIG. 4A is a schematic block diagram of a point cloud encoder provided in an embodiment of the present application.
- the points in the point cloud can include the location information of the points and the attribute information of the points. Therefore, the encoding of the points in the point cloud mainly includes location encoding and attribute encoding.
- the location information of the points in the point cloud is also called geometric information, and the corresponding location encoding of the points in the point cloud can also be called geometric encoding.
- the process of position coding includes: preprocessing the points in the point cloud, such as coordinate transformation, quantization, and removal of duplicate points; then, geometric coding the preprocessed point cloud, such as constructing an octree, or constructing a prediction tree, and geometric coding based on the constructed octree or prediction tree to form a geometric code stream.
- geometric coding such as constructing an octree, or constructing a prediction tree
- geometric coding based on the constructed octree or prediction tree to form a geometric code stream.
- the position information of each point in the point cloud data is reconstructed to obtain the reconstructed value of the position information of each point.
- the attribute encoding process includes: given the reconstruction information of the input point cloud position information and the original value of the attribute information, selecting one of the three prediction modes for point cloud prediction, quantizing the predicted result, and performing arithmetic coding to form an attribute code stream.
- the coordinate conversion unit 201 can be used to convert the world coordinates of the point in the point cloud into relative coordinates. For example, the geometric coordinates of the point are respectively subtracted from the minimum value of the xyz coordinate axis, which is equivalent to a DC removal operation, so as to realize the conversion of the coordinates of the point in the point cloud from the world coordinates to the relative coordinates.
- the octree division unit 203 may use an octree encoding method to encode the position information of the quantized points.
- the point cloud is divided in the form of an octree, so that the position of the point can correspond to the position of the octree one by one, and the position of the point in the octree is counted and its flag is recorded as 1 to perform geometric encoding.
- the geometric reconstruction unit 204 can perform position reconstruction based on the position information output by the octree division unit 203 or the intersection points fitted by the surface fitting unit 206 to obtain the reconstructed value of the position information of each point in the point cloud data.
- the position reconstruction can be performed based on the position information output by the prediction tree construction unit 207 to obtain the reconstructed value of the position information of each point in the point cloud data.
- the arithmetic coding unit 205 can use entropy coding to perform arithmetic coding on the position information output by the octree analysis unit 203 or the intersection points fitted by the surface fitting unit 206, or the geometric prediction residual values output by the prediction tree construction unit 207 to generate a geometric code stream; the geometric code stream can also be called a geometry bitstream.
- Attribute encoding can be achieved through the following units:
- Transform colors a color conversion (Transform colors) unit 210
- a recoloring (Transfer attributes) unit 211 a Region Adaptive Hierarchical Transform (RAHT) unit 212, a Generate LOD (Generate LOD) unit 213, a lifting (lifting transform) unit 214, a Quantize coefficients (Quantize coefficients) unit 215 and an arithmetic coding unit 216.
- RAHT Region Adaptive Hierarchical Transform
- point cloud encoder 200 may include more, fewer, or different functional components than those shown in FIG. 4A .
- the recoloring unit 211 recolors the color information using the reconstructed geometric information so that the uncoded attribute information corresponds to the reconstructed geometric information.
- any transformation unit can be selected to transform the points in the point cloud.
- the transformation unit may include: RAHT transformation 212 and lifting (lifting transform) unit 214. Among them, the lifting transformation depends on generating a level of detail (LOD).
- LOD level of detail
- the process of generating LOD by the LOD generating unit includes: obtaining the Euclidean distance between points according to the position information of the points in the point cloud; and dividing the points into different detail expression layers according to the Euclidean distance.
- the Euclidean distances can be sorted and the Euclidean distances in different ranges can be divided into different detail expression layers. For example, a point can be randomly selected as the first detail expression layer. Then the Euclidean distances between the remaining points and the point are calculated, and the points whose Euclidean distances meet the first threshold requirement are classified as the second detail expression layer.
- the arithmetic coding unit 216 may use zero run length coding to perform entropy coding on the residual value of the attribute information of the point to obtain an attribute code stream.
- the attribute code stream may be bit stream information.
- Figure 4B is a schematic block diagram of a point cloud decoder provided in an embodiment of the present application.
- the decoder 300 can obtain the point cloud code stream from the encoding device, and obtain the position information and attribute information of the points in the point cloud by parsing the code.
- the decoding of the point cloud includes position decoding and attribute decoding.
- the process of position decoding includes: performing arithmetic decoding on the geometric code stream; merging after building the octree, reconstructing the position information of the point to obtain the reconstructed information of the point position information; performing coordinate transformation on the reconstructed information of the point position information to obtain the point position information.
- the point position information can also be called the geometric information of the point.
- the attribute decoding process includes: obtaining the residual value of the attribute information of the point in the point cloud by parsing the attribute code stream; obtaining the residual value of the attribute information of the point after dequantization by dequantizing the residual value of the attribute information of the point; based on the reconstruction information of the point position information obtained in the position decoding process, selecting one of the following RAHT inverse transform and lifting inverse transform to predict the point cloud to obtain the predicted value, and adding the predicted value to the residual value to obtain the reconstructed value of the attribute information of the point; performing color space inverse conversion on the reconstructed value of the attribute information of the point to obtain the decoded point cloud.
- Figure 5I is the predictive coding of the plane position information of the laser radar point cloud.
- the plane position of the current node is predicted by using the laser radar acquisition parameters, and the position is quantized into four intervals by using the position where the current node intersects with the laser ray, and finally used as the context of the plane position of the current node.
- the specific calculation process is as follows: Assuming that the coordinates of the laser radar are (x Lidar , y Lidar , z Lidar ), and the geometric coordinates of the current point are (x, y, z), first calculate the vertical tangent value tan ⁇ of the current point relative to the laser radar. The calculation process is shown in formula (6):
- the octree-based geometric information coding mode only has an efficient compression rate for points with correlation in space.
- the use of the direct coding model (DCM) can greatly reduce the complexity.
- the use of DCM is not indicated by the flag information, but is inferred by the parent node and neighbor information of the current node. There are three ways to determine whether the current node is eligible for DCM coding, as shown in Figure 6A:
- the current node has no sibling child nodes, that is, the parent node of the current node has only one child node, and the parent node of the parent node of the current node has only two occupied child nodes, that is, the current node has at most one neighbor node.
- the number of points numPoints of the current node is first encoded, and the number of points of the current node is encoded according to different DirectModes, including the following methods:
- the coordinate information of the points contained in the current node is encoded.
- the following will introduce the lidar point cloud and the human eye point cloud separately.
- the priority coded coordinate axis dirextAxis will be obtained by using the geometric coordinates of the points. It should be noted that the currently compared coordinate axes only include the x and y axes, not the z axis. Assuming that the geometric coordinates of the current node are nodePos, the priority coded coordinate axis is determined by the method shown in formula (8):
- the axis with the smaller node coordinate geometric position is used as the coordinate axis dirextAxis for priority encoding.
- the geometry information of the dirextAxis coordinate axis of the priority coding is first encoded as follows, assuming that the bit depth of the geometry to be encoded corresponding to the priority coding axis is nodeSizeLog2, and assuming that the coordinates of the two points are pointPos[0] and pointPos[1] respectively:
- the priority coded coordinate axis dirextAxis will be obtained by using the geometric coordinates of the points. Assuming that the geometric coordinates of the current node are nodePos, the priority coded coordinate axis is determined by the method shown in formula (9):
- the geometry information of the dirextAxis coordinate axis of the priority coding is first encoded as follows, assuming that the bit depth of the geometry to be encoded corresponding to the priority coding axis is nodeSizeLog2, and assuming that the coordinates of the two points are pointPos[0] and pointPos[1] respectively:
- the geometric coordinate information of the current node can be predicted, so as to further improve the efficiency of the geometric information encoding of the point cloud.
- the geometric information nodePos of the current node is first used to obtain a directly encoded main axis direction, and then the geometric information of the encoded direction is used to predict the geometric information of another dimension.
- the axis direction of the direct encoding is directAxis
- the bit depth to be encoded in the direct encoding is nodeSizeLog2
- the LaserIdx corresponding to the current point i.e. pointLaserIdx in Figure 6B
- the LaserIdx of the current node i.e. nodeLaserIdx
- the LaserIdx of the node i.e. nodeLaserIdx
- the LaserIdx of the node or point is as follows:
- the number of rotation points numPoints of each Laser can be obtained, which represents the number of points obtained when each laser ray rotates one circle.
- the rotation angular velocity deltaPhi of each Laser can then be calculated using the number of rotation points of each Laser, as shown in formula (11):
- Z_pred is used to predict the geometric information of the current point in the Z-axis direction to obtain the prediction residual Z_res, and finally Z_res is encoded.
- G-PCC currently introduces a plane coding mode. In the process of geometric division, it will determine whether the child nodes of the current node are in the same plane. If the child nodes of the current node meet the conditions of the same plane, the child nodes of the current node will be represented by the plane.
- the decoding end follows the order of breadth-first traversal. Before decoding the placeholder information of each node, it will first use the reconstructed geometric information to determine whether the current node is to be plane decoded or IDCM decoded. If the current node meets the conditions for plane decoding, the plane identification and plane position information of the current node will be decoded first, and then the placeholder information of the current node will be decoded based on the plane information; if the current node meets the conditions for IDCM decoding, it will first decode whether the current node is a real IDCM node.
- the placeholder information of the current node will be decoded.
- the current node has no sibling child nodes, that is, the parent node of the current node has only one child node, and the parent node of the parent node of the current node has only two occupied child nodes, that is, the current node has at most one neighbor node.
- the coordinate information of the points contained in the current node is decoded.
- the following will introduce the lidar point cloud and the human eye point cloud separately.
- the decoding end reconstructs the prediction tree structure by continuously parsing the code stream, and then obtains the geometric position prediction residual information and quantization parameters of each prediction node through parsing, and dequantizes the prediction residual to restore the reconstructed geometric position information of each node, and finally completes the geometric reconstruction of the decoding end.
- FIG8A is a schematic diagram of the encoding framework of AVS
- FIG8B is a schematic diagram of the decoding framework of AVS.
- the geometric information is firstly transformed into coordinates so that all point clouds are contained in a bounding box.
- the preprocessing process includes quantization and removal of duplicate points. Quantization mainly plays a role in scaling. Due to the quantization rounding, the geometric information of some points is the same, and whether to remove duplicate points is determined according to the parameters.
- the bounding box is divided in the order of breadth-first traversal (octree/quadtree/binary tree), and the placeholder code of each node is encoded.
- the bounding box is divided into sub-cubes in sequence, and the non-empty (containing points in the point cloud) sub-cubes are divided until the leaf nodes obtained by the division are 1x1x1 unit cubes, and then the division is stopped. Then, in the case of geometric lossless coding, the number of points contained in the leaf nodes is encoded, and finally the encoding of the geometric octree is completed to generate a binary code stream.
- Model 1 below includes the sub-layer neighbor prediction of the current point and the neighbor prediction of the current point layer.
- the neighbor information that can be obtained when encoding the child node of the current point includes the neighbor child nodes in the three directions of left, front and bottom.
- the context model of the child node layer is designed as follows: For the child node layer to be encoded, find the occupancy of the three coplanar, three colinear, and one co-point nodes in the left, front and bottom direction of the same layer as the child node to be encoded, and the node in the negative direction of the dimension with the shortest node side length, which is two node side lengths away from the current child node to be encoded.
- the reference node selected by each child node is shown in Figure 9A.
- the dotted box node is the current node
- the gray node is the current child node to be encoded
- the solid box node is the reference node selected by each child node.
- the occupancy of the 3 coplanar nodes, 3 colinear nodes, and the node at the negative direction of the dimension with the shortest node side length and two node side lengths away from the current sub-node to be encoded is considered in detail.
- There are 2 possibilities for the common neighbor: occupied or unoccupied. A separate context is assigned to the case where the common neighbor node is occupied. If the common neighbor is also unoccupied, the occupancy of the neighbors at the current node layer to be described next is considered. That is, the neighbors at the sub-node layer to be encoded correspond to a total of 127 + 2-1 128 contexts.
- the occupancy of the four groups of neighbors in the current node layer as shown in Figure 9B is considered, where the dotted frame node is the current node and the solid frame node is the neighbor node.
- This method uses a two-layer context reference relationship configuration, as shown in formula (21), the first layer is the occupancy of the encoded adjacent blocks of the parent node of the current sub-block to be encoded (i.e., ctxIdxParent), and the second layer is the occupancy of the adjacent encoded blocks at the same depth as the current sub-block to be encoded (i.e., ctxIdxChild).
- the ctxIdxChild of the second layer is as shown in formula (22), where Ci1 represents the sub-block with the current sub-block. Occupancy of the three coded sub-blocks with a distance of 1.
- the sum of the number of Morton code bits to be encoded for the points in the current block is greater than twice the number of directions that have not reached the minimum side length.
- this flag can be inferred to be False and not encoded. If the parent block of the current block already allows the use of isolated point coding mode, and the current block is the only child node of the parent block, then the current block must not contain isolated points. Therefore, under this condition, the bits for encoding the flag can be omitted.
- the attribute prediction of the sorted point cloud is performed using a differential method, and finally the prediction residual is quantized and entropy encoded to generate a binary code stream.
- the attribute transformation process is as follows: first, wavelet transform is performed on the point cloud attributes and the transform coefficients are quantized; secondly, the attribute reconstruction value is obtained through inverse quantization and inverse wavelet transform; then the difference between the original attribute and the attribute reconstruction value is calculated to obtain the attribute residual and quantize it; finally, the quantized transform coefficients and attribute residuals are entropy encoded to generate a binary code stream.
- Condition 3 The geometric position is lossless, and the attributes are limitedly lossy
- the general test sequences include five categories: Cat1A, Cat1B, Cat1C, Cat2-frame and Cat3.
- Cat1A and Cat2-frame point clouds only contain reflectance attribute information
- Cat1B and Cat3 point clouds only contain color attribute information
- Cat1B point cloud contains both color and reflectance attribute information.
- the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, the Morton order, the Hilbert order, etc.).
- the entire point cloud is divided into several small groups with a maximum length of Y (such as 2).
- the prediction algorithm is used to obtain the attribute prediction value.
- the attribute residual is obtained according to the attribute value and the attribute prediction value.
- the attribute residual is transformed by DCT in small groups to generate transformation coefficients.
- the transformation coefficients are quantized to generate quantized transformation coefficients.
- the quantized transformation coefficients of the entire point cloud are encoded.
- the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, Morton order, Hilbert order, etc.).
- the entire point cloud is divided into several small groups with a maximum length of Y (such as 2), and the quantized transformation coefficients of the entire point cloud are obtained by decoding.
- the prediction algorithm is used to obtain the attribute prediction value, and then the quantized transformation coefficients are dequantized and inversely transformed in groups.
- the attribute reconstruction value is obtained based on the attribute prediction value and the dequantized and inversely transformed coefficients.
- the encoder When directly encoding the current node, the encoder encodes the position information of the midpoint of the current node after determining that the current node is eligible for direct encoding and decoding. However, when encoding the geometric information of the midpoint of the current node, inter-frame information is not considered, thereby reducing the encoding and decoding performance of the point cloud.
- the point cloud includes geometric information and attribute information
- the decoding of the point cloud includes geometric decoding and attribute decoding.
- the embodiment of the present application relates to geometric decoding of point clouds.
- the geometric information of the point cloud is also referred to as the position information of the point cloud. Therefore, the geometric decoding of the point cloud is also referred to as the position decoding of the point cloud.
- the placeholder information of each layer is encoded layer by layer until the voxel-level leaf nodes of the last layer are encoded. That is to say, in octree encoding, the point cloud is divided through the octree, and finally the points in the point cloud are divided into the voxel-level leaf nodes of the octree.
- the encoding of the point cloud is achieved by encoding the entire octree.
- the decoding end first decodes the geometric code stream of the point cloud to obtain the placeholder information of the root node of the octree of the point cloud, and based on the placeholder information of the root node, determines the child nodes included in the root node, that is, the nodes included in the second layer of the octree. Then, the geometric code stream is decoded to obtain the placeholder information of each node in the second layer, and based on the placeholder information of each node, determines the nodes included in the third layer of the octree, and so on.
- S101-A2 Determine N prediction nodes of the current node based on at least one prediction node of the current node in K prediction reference frames.
- S101-A12 for the i-th domain node among the M domain nodes, determine the corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M;
- the decoding end determines the corresponding nodes of the M domain nodes in the kth prediction reference frame as at least one prediction node of the current node in the kth prediction reference frame.
- the M domain nodes each have a corresponding node in the kth prediction reference frame, and then there are M corresponding nodes, and these M corresponding nodes are determined as the prediction nodes of the current node in the kth prediction reference frame, and there are M prediction nodes in total.
- Method 1 Determine a node in the k-th prediction reference frame that has the same division depth as the i-th node as the corresponding node of the i-th node.
- the decoding end determines the first sequence number of the i-th node in the child nodes included in the parent node; the child node with the first sequence number in the child nodes of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
- the i-th node is the second child node of the i-th parent node, and the first sequence number is 2.
- the second child node of the i-th matching node can be determined as the corresponding node of the i-th node.
- the process of the encoder directly encoding the current node includes: determining whether the current node is qualified for direct encoding, and if it is determined that the current node is qualified for direct decoding, setting IDCMEligible to true. Next, determining whether the number of points included in the current node is less than a preset threshold, and if it is less than the preset threshold, determining to encode the current node in a direct encoding manner, that is, directly encoding the number of points of the current node and the geometric information of the midpoint of the current node.
- multiple context models for example, Q context models, are set for the decoding process of the coordinate information.
- the embodiment of the present application does not limit the specific number of context models corresponding to the coordinate information, as long as Q is greater than 1. That is to say, in an embodiment of the present application, at least one optimal context model is selected from two context models to predict and decode the coordinate information of the current point in the current node, so as to improve the decoding efficiency of the coordinate information of the current point.
- the coordinate information corresponds to multiple context models as shown in Table 4:
- the geometric decoding information of the prediction node can be understood as any information involved in the geometric decoding process of the prediction node, such as the number of points included in the prediction node, the placeholder information of the prediction node, the decoding method of the prediction node, the geometric information of the midpoint of the prediction node, etc.
- the geometric decoding information of the prediction node includes direct decoding information of the prediction node and/or coordinate information of a point in the prediction node, wherein the direct decoding information of the prediction node is used to indicate whether the prediction node meets the conditions for decoding in a direct decoding manner.
- step S102-A1 includes the following step S102-A1:
- S102-A1 Determine a first context index based on direct decoding information of the N prediction nodes, and/or determine a second context index based on coordinate information of midpoints of the N prediction nodes.
- the decoding end can determine the first context index based on the direct decoding information of the N prediction nodes, and/or determine the second context index based on the position information of the midpoint of the N prediction nodes, and then select the final context model from the preset multiple context models based on the first context index and/or the second context index.
- the process of determining the context model may be to determine a first context index based on the direct decoding information of N prediction nodes, and then based on the first context index, select a final context model from a plurality of preset context models to decode the coordinate information of the current point.
- the decoding end selects the final context model from the context models shown in Table 4 based on the first context index.
- the process of determining the context model may be to determine the second context index based on the coordinate information of the midpoints of N prediction nodes, and then based on the second context index, select the final context model from the preset multiple context models to decode the coordinate information of the current point.
- the process of determining the context model may be to determine a first context index based on the direct decoding information of N prediction nodes, and then determine a second context index based on the first context index and the coordinate information of the midpoint of the N prediction nodes, and then select a final context model from a plurality of preset context models based on the second context index, the first context index and the second context index to decode the coordinate information of the current point.
- Second context index 1 Second context index 2 Second context index 3 ... First context index 1 Context Model 11 Context Model 12 Context Model 13 ... First context index 2 Context Model 21 Context Model 22 Context Model 23 ... First context index 3 Context Model 31 Context Model 32 Context Model 33 ... ... ... ... ... ... ...
- the decoding end determines the first context index based on the direct decoding information of the N prediction nodes, and determines the second context index based on the coordinate information of the midpoints of the N prediction nodes, and then checks the above table 5 to obtain the final context model. For example, the decoding end determines that the first context index is the first context index 2 based on the direct decoding information of the N prediction nodes, and determines that the second context index is the second context index 3 based on the coordinate information of the midpoints of the N prediction nodes. In this way, by checking Table 5, the final context model can be obtained as context model 23, and then the decoding end uses context model 23 to decode the coordinate information of the current point.
- the decoding end determines the first context index in the following ways, but is not limited to:
- Method 1 the above S102-A1 includes the following steps S102-A1-11 and S102-A1-12:
- a first value corresponding to the prediction node is determined based on direct decoding information of the prediction node, and finally a first context index is determined based on the first values corresponding to the N prediction nodes.
- the following describes the process of determining the first value corresponding to the prediction node.
- the direct decoding information of the prediction node is used to indicate whether the prediction node meets the conditions for decoding in the direct decoding manner.
- the embodiment of the present application does not limit the specific content of the direct decoding information.
- the direct decoding information includes the number of points included in the prediction node. In this way, the first value corresponding to the prediction node can be determined based on the number of points included in the prediction node.
- the first value corresponding to the prediction node when the number of points included in the prediction node is greater than or equal to 2, the first value corresponding to the prediction node is determined to be 1, and if the number of points included in the prediction node is less than 2, the first value corresponding to the prediction node is determined to be 0.
- the first value corresponding to the prediction node when the number of points included in the prediction node is greater than or equal to 1, the first value corresponding to the prediction node is determined to be 1, and if the number of points included in the prediction node is less than 1, the first value corresponding to the prediction node is determined to be 0.
- the direct decoding information of the prediction node includes the direct decoding mode of the prediction node.
- the above S102-A1-11 includes: numbering the direct decoding mode of the prediction node and determining the first value corresponding to the prediction node.
- the decoding end After the decoding end determines the first values corresponding to the N prediction nodes based on the above steps, it determines the first context index based on the first values corresponding to the N prediction nodes.
- determining the first context index based on the first values corresponding to the N prediction nodes includes at least the following implementation methods:
- S102-A1-12 includes the following steps S102-A1-121 to S102-A1-123:
- a weight i.e., the first weight
- the first numerical values corresponding to each prediction node can be weighted based on the first weight of each prediction node, and then the first context index can be determined based on the final weighted result, thereby improving the accuracy of determining the first context index based on the geometric decoding information of the N prediction nodes.
- the first weight of the predicted node 1 is 1; if domain node 1 is a colinear node of the current node, the first weight of the predicted node 1 is a preset weight. If domain node 1 is a common node of the current node, the first weight of predicted node 1 is the preset weight
- the first weight of predicted node 1 is If domain node 1 is a collinear node of the current node, the first weight of predicted node 1 is the preset weight If domain node 1 is a common node of the current node, the first weight of predicted node 1 is the preset weight
- the weight is normalized, and the normalized weight is used as the final first weight of the prediction node.
- Method 2 if K is greater than 1, determine the second weighted prediction value corresponding to each of the K prediction reference frames, and then determine the first context index based on the second weighted prediction values corresponding to the K prediction reference frames.
- the above S102-A1 includes the following steps S102-A1-21 to S102-A1-23:
- the current node includes at least one prediction node in the jth prediction reference frame, so that the first value of the at least one prediction node is determined based on the direct decoding information of the at least one prediction node in the jth prediction reference frame.
- the j-th prediction reference frame includes two prediction nodes of the current node, which are respectively recorded as prediction node 1 and prediction node 2, and then the first value of prediction node 1 is determined based on the direct decoding information of prediction node 1, and the first value of prediction node 2 is determined based on the direct decoding information of prediction node 2.
- the process of determining the first value corresponding to the prediction node based on the direct decoding information of the prediction node can refer to the description of the above embodiment, and the first value corresponding to the prediction node is determined based on the direct decoding mode of the prediction node, for example, the number (0, 1 or 2) of the direct decoding mode of the prediction node is determined as the first value corresponding to the prediction node.
- the decoding end After the decoding end determines the first value of at least one prediction node included in the j-th prediction reference frame, it determines the first weight corresponding to the at least one prediction node, and weightedly processes the first value corresponding to the at least one prediction node based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
- the process of determining the first weight may refer to the description of the above embodiment and will not be repeated here.
- the above introduces the process of determining the second weighted prediction value corresponding to the j-th prediction reference frame among the K prediction reference frames.
- the second weighted prediction values corresponding to other prediction reference frames among the K prediction reference frames are determined in accordance with the method corresponding to the j-th prediction reference frame.
- the decoding end After the decoding end determines the second weighted prediction value corresponding to each of the K prediction reference frames, it executes the above step S102-A1-23.
- the present application does not limit the specific method of determining the first context index based on the second weighted prediction value corresponding to K prediction reference frames.
- the decoding end first determines the second weight corresponding to each of the K prediction reference frames.
- the embodiment of the present application does not limit the determination of the second weight corresponding to each of the K prediction reference frames.
- S102-A1-31 for any prediction node among the N prediction nodes, select a first point corresponding to the current point of the current node from the points included in the prediction node;
- the encoder if the encoder selects the first point corresponding to the current point from the points included in the prediction node based on the rate-distortion cost (or approximate cost), the encoder writes the identification information of the first point in the prediction node into the bitstream, so that the decoder obtains the first point in the prediction node by decoding the bitstream.
- weighted averaging is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame.
- the decoding end After the decoding end determines the second weighted point corresponding to each of the K predicted reference frames, it executes the above step S102-A1-321-23.
- the third weighted point is obtained by weighting the first point in the prediction node in each prediction reference frame, wherein the value of each bit of the first point after the prediction node has only two results, which is 0 or 1. Therefore, in some embodiments, the value of each bit of the first weighted point obtained by weighting the first point in the N prediction nodes is also 0 or 1. In this way, when the i-th bit of the current point on the i-th coordinate axis is decoded, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined based on the value of the i-th bit of the third weighted point on the i-th coordinate axis.
- the decoding end determines the context model corresponding to the i-th bit on the i-th coordinate axis based on the first context index and/or the second context index corresponding to the i-th bit on the i-th coordinate axis, and uses the context model to predict and decode the value of the i-th bit of the current point on the i-th coordinate axis.
- the decoding end determines the first context index and/or the second context index based on the above steps, it determines the context model based on the first context index and/or the second context index, and uses the context model to decode the coordinate information of the current point.
- the DCM mode information of the prediction node is PredDCMode
- the number of points contained in the prediction node is PredNumPoints
- the geometric information of the first point in the prediction node is predPointPos.
- the decoder uses the IDCM mode of the prediction node and the geometric information of the point in the prediction node to predict and decode the geometric information of the current point, that is, the geometric decoding information of the prediction node used by the decoder includes the following two types:
- Modes include PredDCMode(0,1).
- ctx1 is the first context index
- ctx2 is the second context index
- the above takes the decoding end as an example to introduce in detail the point cloud decoding method provided in the embodiment of the present application.
- the following takes the encoding end as an example to introduce the point cloud encoding method provided in the embodiment of the present application.
- Fig. 17 is a schematic diagram of a point cloud coding method according to an embodiment of the present application.
- the point cloud coding method according to the embodiment of the present application can be implemented by the point cloud coding device shown in Fig. 3 or Fig. 4A or Fig. 8A.
- the current node is the node to be encoded in the current frame to be encoded.
- the geometric information of the point cloud is also referred to as the position information of the point cloud, and therefore, the geometric encoding of the point cloud is also referred to as the position encoding of the point cloud.
- the placeholder information of each layer is encoded layer by layer until the voxel-level leaf nodes of the last layer are encoded. That is to say, in octree encoding, the point cloud is divided through the octree, and finally the points in the point cloud are divided into the voxel-level leaf nodes of the octree.
- the encoding of the point cloud is achieved by encoding the entire octree.
- the encoding end first determines whether the node is qualified for direct encoding. If the node is qualified for direct encoding, it determines whether the number of points of the node is less than or equal to a preset threshold. If the number of points of the node is less than or equal to the preset threshold, it determines that the node can be encoded using direct encoding. Then, the number of points included in the node and the geometric information of each point are encoded into the bitstream.
- the encoding end predictively encodes the position information of the midpoint of the current node based on the inter-frame information corresponding to the current node, thereby improving the encoding efficiency and encoding performance of the point cloud.
- the current frame to be encoded is a point cloud frame.
- the current frame to be encoded is also referred to as the current frame or the current point cloud frame or the current point cloud frame to be encoded.
- the current node can be understood as any non-leaf node in the current frame to be encoded.
- the current node is not a leaf node in the octree corresponding to the current frame to be encoded, that is, the current node is an arbitrary middle node of the octree, and the current node is not a non-empty node, that is, it includes at least 1 point.
- the encoder when encoding the current node in the current frame to be encoded, the encoder first determines the prediction reference frame of the current frame to be encoded, and determines N prediction nodes of the current node in the prediction reference frame. For example, FIG12 shows a prediction node of the current node in the prediction reference frame.
- the embodiment of the present application does not limit the number of prediction reference frames of the current frame to be encoded, for example, the current frame to be encoded has one prediction reference frame, or the current frame to be encoded has multiple prediction reference frames. At the same time, the embodiment of the present application does not limit the number N of prediction nodes of the current node, which is determined according to actual needs.
- the embodiment of the present application does not limit the specific method of determining the prediction reference frame of the current frame to be encoded.
- one or several encoded frames before the current frame to be encoded are determined as prediction reference frames for the current frame to be encoded.
- the inter-frame reference frame of the P frame includes the previous frame of the P frame (ie, the forward frame). Therefore, the previous frame of the current frame to be encoded (ie, the forward frame) can be determined as the prediction reference frame of the current frame to be encoded.
- the inter-frame reference frames of the B frame include the previous frame of the P frame (i.e., the forward frame) and the next frame of the P frame (i.e., the backward frame). Therefore, the previous frame of the current frame to be encoded (i.e., the forward frame) can be determined as the predicted reference frame of the current frame to be encoded.
- one or several encoded frames following the current frame to be encoded are determined as prediction reference frames of the current frame to be encoded.
- the frame following the current frame to be encoded may be determined as a prediction reference frame of the current frame to be encoded.
- one or several encoded frames before the current frame to be encoded, and one or several encoded frames after the current frame to be encoded are determined as prediction reference frames of the current frame to be encoded.
- the previous frame and the next frame of the current frame to be encoded may be determined as prediction reference frames of the current frame to be encoded.
- the current frame to be encoded has two prediction reference frames.
- the encoder selects at least one prediction reference frame from the K prediction reference frames based on the placeholder information of the node in the current frame to be encoded and the placeholder information of the node in each of the K prediction reference frames, and then searches for the prediction node of the current node in the at least one prediction reference frame. For example, at least one prediction reference frame whose placeholder information of the node is closest to the placeholder information of the node in the current frame to be encoded is selected from the K prediction reference frames, and then searches for the prediction node of the current node in the at least one prediction reference frame.
- the encoder may determine N prediction nodes of the current node through the following steps S201-A1 and S201-A2:
- S201-A1 for a k-th prediction reference frame among K prediction reference frames, determining at least one prediction node of a current node in the k-th prediction reference frame, where k is a positive integer less than or equal to K, and K is a positive integer;
- S201-A2 Determine N prediction nodes of the current node based on at least one prediction node of the current node in K prediction reference frames.
- the encoding end determines at least one prediction node of the current node from each of the K prediction reference frames, and finally summarizes at least one prediction node in each of the K prediction reference frames to obtain N prediction nodes of the current node.
- the process of the encoding end determining at least one prediction point of the current node in each of the K prediction reference frames is the same.
- the kth prediction reference frame among the K prediction reference frames is taken as an example for explanation.
- the embodiment of the present application does not limit the specific manner in which the encoder determines at least one prediction node of the current node in the kth prediction reference frame.
- Method 1 In the kth prediction reference frame, a prediction node of the current node is determined. For example, a node in the kth prediction reference frame having the same division depth as the current node is determined as the prediction node of the current node.
- node 1 is determined as a prediction node of the current node in the kth prediction reference frame.
- the node 1 determined above and at least one domain node of node 1 in the kth prediction reference frame are determined as the prediction nodes of the current node in the kth prediction reference frame.
- determining at least one prediction node of the current node in the kth prediction reference frame includes the following steps S201-A11 to S201-A13:
- S201-A13 Determine at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame.
- the encoder before determining at least one prediction node of the current node in the kth prediction reference frame, the encoder first determines M domain nodes of the current node in the current frame to be encoded, and the M domain nodes include the current node itself.
- the M domain nodes of the current node include at least one domain node among the domain nodes that are coplanar, colinear, and co-pointed with the current node in the current frame to be encoded. As shown in FIG13 , the current node includes 6 coplanar nodes, 12 colinear nodes, and 8 co-pointed nodes.
- the M domain nodes of the current node may include other nodes within the reference neighborhood in addition to at least one domain node in the current frame to be encoded that is coplanar, colinear, and co-point with the current node. This embodiment of the present application does not impose any restrictions on this.
- the encoding end determines the M domain nodes of the current node in the current frame to be encoded, and then determines the corresponding node of each of the M domain nodes in the kth prediction reference frame, and then determines at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame.
- At least one corresponding node is selected from the corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame. For example, at least one corresponding node whose placeholder information has the smallest difference with the placeholder information of the current node is selected from the corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame.
- At least one prediction node of the current node in K prediction reference frames is determined as N prediction nodes of the current node.
- the encoder determines the corresponding node of the i-th node in the k-th prediction reference frame in at least the following ways:
- a node whose placeholder information in the k-th prediction reference frame has the smallest difference with the placeholder information of the i-th parent node is determined as a matching node of the i-th parent node in the k-th prediction reference frame.
- the encoder determines the first sequence number of the i-th node in the child nodes included in the parent node; the child node with the first sequence number in the child nodes of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
- the i-th node is the second child node of the i-th parent node, and the first sequence number is 2.
- the second child node of the i-th matching node can be determined as the corresponding node of the i-th node.
- the embodiment of the present application refers to the relevant information between frames when predicting the position information of the midpoint of the current node based on the correlation between adjacent frames of the point cloud.
- the WeChat information of the midpoint of the current node is predictively encoded based on the geometric encoding information of the midpoints of the N predicted nodes of the current node, thereby improving the encoding efficiency and encoding performance of the point cloud.
- the encoding end determines the first context index in the following ways, but is not limited to:
- the following describes the process of determining the first value corresponding to the prediction node.
- the encoder After determining the first values corresponding to the N prediction nodes based on the above steps, the encoder determines a first context index based on the first values corresponding to the N prediction nodes.
- Method 1 Determine the average value of the sum of the first numerical values corresponding to the N prediction nodes as the first context index.
- S202-A1-12 includes the following steps S202-A1-121 to S202-A1-123:
- the first weight corresponding to each prediction node in the above-mentioned N prediction nodes is a preset value.
- the above-mentioned N prediction nodes are determined based on the M domain nodes of the current node. Assuming that prediction node 1 is the prediction node corresponding to domain node 1, if domain node 1 is a coplanar node of the current node, the first weight of prediction node 1 is the preset weight 1, if domain node 1 is a colinear node of the current node, the first weight of prediction node 1 is the preset weight 2, and if domain node 1 is a co-point node of the current node, the first weight of prediction node 1 is the preset weight 3.
- a first weight corresponding to the prediction node is determined based on the distance between the domain node corresponding to the prediction node and the current node. For example, the smaller the distance between the domain node and the current node, the stronger the inter-frame correlation between the prediction node corresponding to the domain node and the current node, and thus the greater the first weight of the prediction node.
- the weight is normalized, and the normalized weight is used as the final first weight of the prediction node.
- the embodiment of the present application does not limit the specific method of obtaining the first weighted prediction value by weighting the first numerical values corresponding to N prediction nodes based on the first weight.
- a weighted average is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value.
- the first context index is determined based on the first weighted prediction value, that is, the above S202-A1-123 includes at least the following examples:
- Example 1 Determine the first weighted prediction value as the first context index.
- Example 2 Determine the weighted prediction value range in which the first weighted prediction value is located, and determine the index corresponding to the range as the first context index.
- the current node includes at least one prediction node in the jth prediction reference frame, so that the first value of the at least one prediction node is determined based on the direct encoding information of the at least one prediction node in the jth prediction reference frame.
- the encoding end After the encoding end determines the first value of at least one prediction node included in the j-th prediction reference frame, it determines the first weight corresponding to the at least one prediction node, and weightedly processes the first value corresponding to the at least one prediction node based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
- a weighted average is performed on the first values corresponding to the prediction nodes in the j-th prediction reference frame to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
- a weighted sum is performed on the first numerical values corresponding to the prediction nodes in the j-th prediction reference frame to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
- the process of determining the first weight may refer to the description of the above embodiment and will not be repeated here.
- the above introduces the process of determining the second weighted prediction value corresponding to the j-th prediction reference frame among the K prediction reference frames.
- the second weighted prediction values corresponding to other prediction reference frames among the K prediction reference frames are determined in accordance with the method corresponding to the j-th prediction reference frame.
- the encoding end determines the second weighted prediction value corresponding to each of the K prediction reference frames, it executes the above step S202-A1-23.
- the present application does not limit the specific method of determining the first context index based on the second weighted prediction value corresponding to K prediction reference frames.
- the encoding end determines second weights corresponding to K prediction reference frames, and performs weighted processing on second weighted prediction values corresponding to the K prediction reference frames based on the second weights to obtain a first context index.
- the second weight corresponding to each of the K prediction reference frames is a preset value.
- the K prediction reference frames are forward frames and/or backward frames of the current frame to be encoded. Assuming that prediction reference frame 1 is the forward frame of the current frame to be encoded, the second weight corresponding to prediction reference frame 1 is the preset weight 1. If prediction reference frame 1 is the backward frame of the current frame to be encoded, the second weight corresponding to prediction reference frame 1 is the preset weight 2.
- the second weight corresponding to the predicted reference frame is determined.
- each point cloud includes time information, and the time information may be the time when the point cloud acquisition device acquires the point cloud of the frame. Based on this, if the time difference between the predicted reference frame and the current frame to be encoded is smaller, the inter-frame correlation between the predicted reference frame and the current frame to be encoded is stronger, and thus the second weight corresponding to the predicted reference frame is larger. For example, the inverse of the time difference between the predicted reference frame and the current frame to be encoded can be determined as the second weight corresponding to the predicted reference frame.
- weighted processing is performed on the second weighted prediction values respectively corresponding to the K prediction reference frames based on the second weight to obtain a first context index.
- the second weighted prediction values corresponding to the K prediction reference frames are weighted summed to obtain the first context index.
- the following introduces the process of determining the second context index at the encoding end.
- a point is selected from the multiple points to determine the second context index.
- the above S202-A1 includes the following steps S202-A1-31 and S202-A1-32:
- S202-A1-32. Determine a second context index based on the coordinate information of the first point included in the N prediction nodes.
- the encoder if the encoder selects the first point corresponding to the current point from the points included in the prediction node based on the rate-distortion cost (or approximate cost), the encoder writes the identification information of the first point in the prediction node into the bitstream, so that the encoder obtains the first point in the prediction node by encoding the bitstream.
- the encoder determines the first point corresponding to the current point in each prediction node based on the above method, and then executes the above step S202-A1-32.
- the encoding end encodes the coordinate information of the current point on different coordinate axes respectively. Based on, the above S202-A1-32 includes the following step S202-A1-321:
- S202-A1-321 Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis.
- the above-mentioned i-th coordinate axis can be the X-axis, the Y-axis or the Z-axis, and this embodiment of the present application does not limit this.
- the encoding end determines the second context index corresponding to the Y-axis based on the coordinate information of the first point on the Y-axis included in the N prediction nodes, and based on the first context index and/or the second context index corresponding to the Y-axis, selects the context model corresponding to the Y-axis from multiple context models, and then uses the context model corresponding to the Y-axis to predict and encode the coordinate information of the current point on the Y-axis to obtain the Y coordinate value of the current point.
- the implementation methods of the above S202-A1-321 include but are not limited to the following:
- Method 1 weight the first points included in the N prediction nodes, and determine the second context index corresponding to the i-th coordinate axis based on the weighted coordinate information.
- the above S202-A1-321 includes the following steps S202-A1-321-11 to S202-A1-321-13:
- a weight that is, the first weight, can be determined for each of the N prediction nodes.
- the coordinate information of the first point included in each prediction node can be weighted to obtain a first weighted point, and then the second context index corresponding to the i-th coordinate axis can be determined based on the coordinate information of the first weighted point on the i-th coordinate axis, thereby improving the accuracy of encoding the current point based on the geometric encoding information of the N prediction nodes.
- the encoder After the encoder determines the first weight corresponding to each of the N prediction nodes, the encoder performs weighted processing on the coordinate information of the first point included in the N prediction nodes based on the first weight to obtain a first weighted point.
- the embodiment of the present application does not limit the specific method of obtaining the first weighted point by weighted processing the coordinate information of the first point included in the N prediction nodes based on the first weight.
- each of the K prediction reference frames is considered separately. Specifically, the coordinate information of the first point in the prediction node of each prediction reference frame in the K prediction reference frames is determined, and the second weighted point corresponding to each prediction reference frame is determined, and then based on the coordinate information of the second weighted point corresponding to each prediction reference frame, the second context index corresponding to the i-th coordinate axis is determined, and the second context index is accurately predicted, thereby improving the coding efficiency of the point cloud.
- the determination unit 11 is specifically used to determine the first serial number of the i-th node among the child nodes included in the parent node; and determine the child node with the first serial number among the child nodes of the i-th matching node as the corresponding node of the i-th node in the k-th prediction reference frame.
- the determination unit 11 is specifically configured to determine corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame.
- the prediction unit 12 is specifically configured to determine a first weight corresponding to the prediction node based on a distance between a domain node corresponding to the prediction node and the current node.
- the current frame to be encoded includes K prediction reference frames
- the determination unit 21 is specifically used to determine at least one prediction node of the current node in the kth prediction reference frame among the K prediction reference frames, where k is a positive integer less than or equal to K, and K is a positive integer; based on at least one prediction node of the current node in the K prediction reference frames, determine N prediction nodes of the current node.
- the determination unit 21 is specifically configured to determine at least one prediction node of the current node in the K prediction reference frames as N prediction nodes of the current node.
- the encoding unit 22 is specifically used to determine the index of the context model based on the geometric encoding information of the N prediction nodes; determine the context model based on the index of the context model; and use the context model to predict and encode the coordinate information of the current point in the current node.
- the encoding unit 22 is specifically used to select, for any prediction node among the N prediction nodes, a first point corresponding to the current point in the current node from the points included in the prediction node; and determine the second context index based on the coordinate information of the first point included in the N prediction nodes.
- the encoding unit 22 is specifically used to determine the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis, where the i-th coordinate axis is the X-coordinate axis, the Y-coordinate axis or the Z-coordinate axis; based on the first context index and/or the second context index corresponding to the i-th coordinate axis, select the context model corresponding to the i-th coordinate axis from the multiple context models; and use the context model corresponding to the i-th coordinate axis to predict and encode the coordinate information of the current point on the i-th coordinate axis.
- the encoding unit 22 is specifically used to determine a first weight corresponding to the prediction node; based on the first weight, weighted processing is performed on the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point; based on the coordinate information of the first weighted point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined.
- the encoding unit 22 is specifically used to determine, for the j-th prediction reference frame among the K prediction reference frames, a first weight corresponding to a prediction node in the j-th prediction reference frame; based on the first weight, weighted processing is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K; based on the second weighted points corresponding to the K prediction reference frames, a second context index corresponding to the i-th coordinate axis is determined.
- the encoding unit 22 is specifically used to determine a second weight corresponding to the K predicted reference frames; based on the second weight, weighted processing is performed on the coordinate information of the second weighted point corresponding to the K predicted reference frames to obtain a third weighted point; based on the coordinate information of the third weighted point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined.
- the encoding unit 22 is specifically configured to determine a second weight corresponding to the predicted reference frame based on a time difference between the predicted reference frame and the current frame to be encoded.
- the device embodiment and the method embodiment may correspond to each other, and similar descriptions may refer to the method embodiment. To avoid repetition, it will not be repeated here.
- the point cloud coding device 20 shown in Figure 19 may correspond to the corresponding subject in the point cloud coding method of the embodiment of the present application, and the aforementioned and other operations and/or functions of each unit in the point cloud coding device 20 are respectively for implementing the corresponding processes in the point cloud coding method. For the sake of brevity, they will not be repeated here.
- the functional unit can be implemented in hardware form, can be implemented by instructions in software form, and can also be implemented by a combination of hardware and software units.
- the steps of the method embodiment in the embodiment of the present application can be completed by the hardware integrated logic circuit and/or software form instructions in the processor, and the steps of the method disclosed in the embodiment of the present application can be directly embodied as a hardware decoding processor to perform, or a combination of hardware and software units in the decoding processor to perform.
- FIG. 20 is a schematic block diagram of an electronic device provided in an embodiment of the present application.
- the memory 33 and the processor 32, the memory 33 is used to store the computer program 34 and transmit the program code 34 to the processor 32.
- the processor 32 can call and run the computer program 34 from the memory 33 to implement the method in the embodiment of the present application.
- the processor 32 may include but is not limited to:
- the memory 33 includes but is not limited to:
- Non-volatile memory can be read-only memory (ROM), programmable read-only memory (PROM), erasable programmable read-only memory (EPROM), electrically erasable programmable read-only memory (EEPROM) or flash memory.
- the volatile memory can be random access memory (RAM), which is used as an external cache.
- RAM random access memory
- SRAM static RAM
- DRAM dynamic RAM
- SDRAM synchronous DRAM
- DDR SDRAM double data rate synchronous dynamic random access memory
- ESDRAM enhanced synchronous dynamic random access memory
- SLDRAM synchronous link DRAM
- Direct Rambus RAM Direct Rambus RAM, DR RAM
- the computer program 34 may be divided into one or more units, which are stored in the memory 33 and executed by the processor 32 to complete the method provided by the present application.
- the one or more units may be a series of computer program instruction segments capable of completing specific functions, and the instruction segments are used to describe the execution process of the computer program 34 in the electronic device 30.
- the electronic device 30 may further include:
- the transceiver 33 may be connected to the processor 32 or the memory 33 .
- the processor 32 may control the transceiver 33 to communicate with other devices, specifically, to send information or data to other devices, or to receive information or data sent by other devices.
- the transceiver 33 may include a transmitter and a receiver.
- the transceiver 33 may further include an antenna, and the number of antennas may be one or more.
- the point cloud encoding and decoding system 40 may include: a point cloud encoder 41 and a point cloud decoder 42, wherein the point cloud encoder 41 is used to execute the point cloud encoding method involved in the embodiment of the present application, and the point cloud decoder 42 is used to execute the point cloud decoding method involved in the embodiment of the present application.
- the computer program product includes one or more computer instructions.
- the computer can be a general-purpose computer, a special-purpose computer, a computer network, or other programmable devices.
- the computer instructions can be stored in a computer-readable storage medium, or transmitted from one computer-readable storage medium to another computer-readable storage medium.
- the computer instructions can be transmitted from a website site, computer, server or data center by wired (e.g., coaxial cable, optical fiber, digital subscriber line (digital subscriber line, DSL)) or wireless (e.g., infrared, wireless, microwave, etc.) mode to another website site, computer, server or data center.
- the computer-readable storage medium can be any available medium that a computer can access or a data storage device such as a server or data center that includes one or more available media integrations.
- the available medium can be a magnetic medium (e.g., a floppy disk, a hard disk, a magnetic tape), an optical medium (e.g., a digital video disc (DVD)), or a semiconductor medium (e.g., a solid state disk (SSD)), etc.
- a magnetic medium e.g., a floppy disk, a hard disk, a magnetic tape
- an optical medium e.g., a digital video disc (DVD)
- DVD digital video disc
- SSD solid state disk
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
Abstract
The present application provides a point cloud encoding method and apparatus, a point cloud decoding method and apparatus, a device, and a storage medium. The point cloud encoding/decoding method comprises: determining N prediction nodes of a current node in a prediction reference frame of a current frame to be encoded/decoded, and performing predictive encoding/decoding on coordinate information of points in the current node on the basis of geometry encoding/decoding information of points in the N prediction nodes. That is to say, in embodiments of the present application, a node is subjected to direct encoding/decoding DCM for optimization, the time-domain correlation between the adjacent frames is considered, and geometry information of the prediction nodes in the prediction reference frame is used to perform predictive encoding/decoding on geometry information of points in a node to be subjected to IDCM (i.e., the current node); the time-domain correlation between the adjacent frames is considered, so that the encoding/decoding efficiency of the geometry information of a point cloud is further improved.
Description
本申请涉及点云技术领域,尤其涉及一种点云编解码方法、装置、设备及存储介质。The present application relates to the field of point cloud technology, and in particular to a point cloud encoding and decoding method, device, equipment and storage medium.
通过采集设备对物体表面进行采集,形成点云数据,点云数据包括几十万甚至更多的点。在视频制作过程中,将点云数据以点云媒体文件的形式在点云编码设备和点云解码设备之间传输。但是,如此庞大的点给传输带来了挑战,因此,点云编码设备需要对点云数据进行压缩后传输。The surface of the object is collected by the acquisition device to form point cloud data, which includes hundreds of thousands or even more points. In the video production process, the point cloud data is transmitted between the point cloud encoding device and the point cloud decoding device in the form of point cloud media files. However, such a large number of points brings challenges to transmission, so the point cloud encoding device needs to compress the point cloud data before transmission.
点云的压缩也称为点云的编码,在点云编码过程中,对于在几何空间中处于孤立位置的点来说,使用推断直接编码方式(Infer Direct Mode Coding,简称IDCM)可以大大降低复杂度。在采用直接编码方式对当前节点进行编解码时,对当前节点中点的几何信息进行直接编码。但是,目前对当前节点中点的几何信息进行编码时,没有考虑帧间信息,进而降低点云的编解码性能。Point cloud compression is also called point cloud encoding. In the point cloud encoding process, for points that are isolated in the geometric space, the use of infer direct coding (IDCM) can greatly reduce the complexity. When the direct coding method is used to encode and decode the current node, the geometric information of the point in the current node is directly encoded. However, when encoding the geometric information of the point in the current node, the inter-frame information is not considered, which reduces the encoding and decoding performance of the point cloud.
发明内容Summary of the invention
本申请实施例提供了一种点云编解码方法、装置、设备及存储介质,对节点中点的几何信息进行编码时,考虑了帧间信息,进而提升点云的编解码性能。The embodiments of the present application provide a point cloud encoding and decoding method, apparatus, device and storage medium, which take into account inter-frame information when encoding the geometric information of the node midpoint, thereby improving the encoding and decoding performance of the point cloud.
第一方面,本申请实施例提供一种点云解码方法,包括:In a first aspect, an embodiment of the present application provides a point cloud decoding method, comprising:
在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待解码帧中的待解码节点,所述N为正整数;In a prediction reference frame of a current frame to be decoded, determining N prediction nodes of a current node, wherein the current node is a node to be decoded in the current frame to be decoded, and N is a positive integer;
基于所述N个预测节点的几何解码信息,对所述当前节点中点的坐标信息进行预测解码。Based on the geometric decoding information of the N predicted nodes, the coordinate information of the midpoint of the current node is predicted and decoded.
第二方面,本申请提供了一种点云编码方法,包括:In a second aspect, the present application provides a point cloud encoding method, comprising:
在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待编码帧中的待编码节点,所述N为正整数;In a prediction reference frame of a current frame to be encoded, determining N prediction nodes of a current node, wherein the current node is a node to be encoded in the current frame to be encoded, and N is a positive integer;
基于所述N个预测节点的几何编码信息,对所述当前节点中点的坐标信息进行预测编码。Based on the geometric coding information of the N predicted nodes, the coordinate information of the midpoint of the current node is predicted and coded.
第三方面,本申请提供了一种点云解码装置,用于执行上述第一方面或其各实现方式中的方法。具体地,该装置包括用于执行上述第一方面或其各实现方式中的方法的功能单元。In a third aspect, the present application provides a point cloud decoding device for executing the method in the first aspect or its respective implementations. Specifically, the device includes a functional unit for executing the method in the first aspect or its respective implementations.
第四方面,本申请提供了一种点云编码装置,用于执行上述第二方面或其各实现方式中的方法。具体地,该装置包括用于执行上述第二方面或其各实现方式中的方法的功能单元。In a fourth aspect, the present application provides a point cloud encoding device for executing the method in the second aspect or its respective implementations. Specifically, the device includes a functional unit for executing the method in the second aspect or its respective implementations.
第五方面,提供了一种点云解码器,包括处理器和存储器。该存储器用于存储计算机程序,该处理器用于调用并运行该存储器中存储的计算机程序,以执行上述第一方面或其各实现方式中的方法。In a fifth aspect, a point cloud decoder is provided, comprising a processor and a memory. The memory is used to store a computer program, and the processor is used to call and run the computer program stored in the memory to execute the method in the first aspect or its implementation manners.
第六方面,提供了一种点云编码器,包括处理器和存储器。该存储器用于存储计算机程序,该处理器用于调用并运行该存储器中存储的计算机程序,以执行上述第二方面或其各实现方式中的方法。In a sixth aspect, a point cloud encoder is provided, comprising a processor and a memory. The memory is used to store a computer program, and the processor is used to call and run the computer program stored in the memory to execute the method in the second aspect or its respective implementations.
第七方面,提供了一种点云编解码系统,包括点云编码器和点云解码器。点云解码器用于执行上述第一方面或其各实现方式中的方法,点云编码器用于执行上述第二方面或其各实现方式中的方法。In a seventh aspect, a point cloud encoding and decoding system is provided, comprising a point cloud encoder and a point cloud decoder. The point cloud decoder is used to execute the method in the first aspect or its respective implementations, and the point cloud encoder is used to execute the method in the second aspect or its respective implementations.
第八方面,提供了一种芯片,用于实现上述第一方面至第二方面中的任一方面或其各实现方式中的方法。具体地,该芯片包括:处理器,用于从存储器中调用并运行计算机程序,使得安装有该芯片的设备执行如上述第一方面至第二方面中的任一方面或其各实现方式中的方法。In an eighth aspect, a chip is provided for implementing the method in any one of the first to second aspects or their respective implementations. Specifically, the chip includes: a processor for calling and running a computer program from a memory, so that a device equipped with the chip executes the method in any one of the first to second aspects or their respective implementations.
第九方面,提供了一种计算机可读存储介质,用于存储计算机程序,该计算机程序使得计算机执行上述第一方面至第二方面中的任一方面或其各实现方式中的方法。In a ninth aspect, a computer-readable storage medium is provided for storing a computer program, wherein the computer program enables a computer to execute the method of any one of the first to second aspects or any of their implementations.
第十方面,提供了一种计算机程序产品,包括计算机程序指令,该计算机程序指令使得计算机执行上述第一方面至第二方面中的任一方面或其各实现方式中的方法。In a tenth aspect, a computer program product is provided, comprising computer program instructions, which enable a computer to execute the method in any one of the first to second aspects or their respective implementations.
第十一方面,提供了一种计算机程序,当其在计算机上运行时,使得计算机执行上述第一方面至第二方面中的任一方面或其各实现方式中的方法。In an eleventh aspect, a computer program is provided, which, when executed on a computer, enables the computer to execute the method in any one of the first to second aspects or in each of their implementations.
第十二方面,提供了一种码流,码流是基于上述第二方面的方法生成的,可选的,上述码流包括第一参数和第二参数中的至少一个。In a twelfth aspect, a code stream is provided, which is generated based on the method of the second aspect. Optionally, the code stream includes at least one of the first parameter and the second parameter.
基于以上技术方案,在对当前编解码帧中的当前节点进行解码时,在当前待编解码帧的预测参考帧中,确定当前节点的N个预测节点,基于这N个预测节点中点的几何编解码信息,对当前节点中点的坐标信息进行预测编解码。也就是说,本申请实施例对节点进行DCM直接编解码时进行优化,通过考虑相邻帧之间时域上的相关性,利用预测参考帧中预测节点的几何信息对待节点IDCM节点(即当前节点)中点的几何信息进行预测编解码,通过考虑相邻帧之间时域相关性来进一步提升点云的几何信息编解码效率。Based on the above technical solution, when decoding the current node in the current coded frame, in the predicted reference frame of the current frame to be coded, the N predicted nodes of the current node are determined, and based on the geometric coding and decoding information of the midpoints of the N predicted nodes, the coordinate information of the midpoint of the current node is predicted and coded. In other words, the embodiment of the present application optimizes the node when performing DCM direct coding and decoding, and predicts and codes the geometric information of the midpoint of the IDCM node (i.e., the current node) of the to-be-coded node by considering the correlation in the time domain between adjacent frames, and further improves the coding and decoding efficiency of the geometric information of the point cloud by considering the correlation in the time domain between adjacent frames.
图1A为点云示意图;FIG1A is a schematic diagram of a point cloud;
图1B为点云局部放大图;Figure 1B is a partial enlarged view of the point cloud;
图2为点云图像的六个观看角度示意图;FIG2 is a schematic diagram of six viewing angles of a point cloud image;
图3为本申请实施例涉及的一种点云编解码系统的示意性框图;FIG3 is a schematic block diagram of a point cloud encoding and decoding system according to an embodiment of the present application;
图4A是本申请实施例提供的点云编码器的示意性框图;FIG4A is a schematic block diagram of a point cloud encoder provided in an embodiment of the present application;
图4B是本申请实施例提供的点云解码器的示意性框图;FIG4B is a schematic block diagram of a point cloud decoder provided in an embodiment of the present application;
图5A为一种平面示意图;FIG5A is a schematic plan view;
图5B为节点编码顺序示意图;FIG5B is a schematic diagram of node coding sequence;
图5C为平面标识示意图;FIG5C is a schematic diagram of a plane logo;
图5D为兄弟姐妹节点示意图;FIG5D is a schematic diagram of a sibling node;
图5E为激光雷达与节点的相交示意图;FIG5E is a schematic diagram of the intersection of a laser radar and a node;
图5F为处于相同划分深度相同坐标的邻域节点示意图;FIG5F is a schematic diagram of neighborhood nodes at the same division depth and the same coordinates;
图5G为当节点位于父节点低平面位置时邻域节点示意图;FIG5G is a schematic diagram of a neighboring node when the node is located at a lower plane position of the parent node;
图5H为当节点位于父节点高平面位置时邻域节点示意图;FIG5H is a schematic diagram of a neighboring node when the node is located at a high plane position of the parent node;
图5I为激光雷达点云平面位置信息的预测编码示意图;FIG5I is a schematic diagram of predictive coding of planar position information of a laser radar point cloud;
图6A为IDCM编码示意图;FIG6A is a schematic diagram of IDCM encoding;
图6B为旋转激光雷达获取的点云的坐标转换示意图;FIG6B is a schematic diagram of coordinate transformation of a point cloud acquired by a rotating laser radar;
图6C为X或Y轴方向的预测编码示意图;FIG6C is a schematic diagram of predictive coding in the X or Y axis direction;
图6D为通过水平方位角来进行预测X或者Y平面的角度示意图;FIG6D is a schematic diagram showing the angle of the X or Y plane predicted by the horizontal azimuth angle;
图6E为X或Y轴的预测编码示意图;FIG6E is a schematic diagram of predictive coding of the X or Y axis;
图7A至图7C为基于三角面片的几何信息编码示意图;7A to 7C are schematic diagrams of geometric information encoding based on triangular facets;
图8A为AVS的编码框架示意图;FIG8A is a schematic diagram of an encoding framework of AVS;
图8B为AVS的解码框架示意图;FIG8B is a schematic diagram of a decoding framework of AVS;
图9A为各子节点选取的参考节点示意图;FIG9A is a schematic diagram of reference nodes selected by each sub-node;
图9B为当前节点的4组参考邻居节点示意图;FIG9B is a schematic diagram of four groups of reference neighbor nodes of the current node;
图9C为子块分别对应6个相邻父块的示意图;FIG9C is a schematic diagram showing that sub-blocks correspond to 6 adjacent parent blocks respectively;
图9D为当前待编码块利用到的周围18个相邻块及其莫顿序编号示意图;FIG9D is a schematic diagram of 18 neighboring blocks and their Morton sequence numbers used by the current block to be encoded;
图9E为简化预测树示意图;FIG9E is a simplified prediction tree diagram;
图10为本申请一实施例提供的点云解码方法流程示意图;FIG10 is a schematic diagram of a point cloud decoding method flow chart provided in an embodiment of the present application;
图11为一种八叉树划分示意图;FIG11 is a schematic diagram of octree partitioning;
图12为预测节点的一种示意图;FIG12 is a schematic diagram of a prediction node;
图13为领域节点的一种示意图;FIG13 is a schematic diagram of a domain node;
图14为领域节点的对应节点示意图;FIG14 is a schematic diagram of corresponding nodes of a domain node;
图15A为当前节点在一个预测参考帧中的预测节点的示意图;FIG15A is a schematic diagram of a prediction node of a current node in a prediction reference frame;
图15B为当前节点在两个预测参考帧中的预测节点的示意图;FIG15B is a schematic diagram of the prediction nodes of the current node in two prediction reference frames;
图16A为一种IDCM编码示意图;FIG16A is a schematic diagram of IDCM encoding;
图16B为一种IDCM解码示意图;FIG16B is a schematic diagram of IDCM decoding;
图17为本申请一实施例提供的点云编码方法流程示意图;FIG17 is a schematic diagram of a point cloud encoding method flow chart provided by an embodiment of the present application;
图18是本申请实施例提供的点云解码装置的示意性框图;FIG18 is a schematic block diagram of a point cloud decoding device provided in an embodiment of the present application;
图19是本申请实施例提供的点云编码装置的示意性框图;FIG19 is a schematic block diagram of a point cloud encoding device provided in an embodiment of the present application;
图20是本申请实施例提供的电子设备的示意性框图;FIG20 is a schematic block diagram of an electronic device provided in an embodiment of the present application;
图21是本申请实施例提供的点云编解码系统的示意性框图。Figure 21 is a schematic block diagram of the point cloud encoding and decoding system provided in an embodiment of the present application.
本申请可应用于点云上采样技术领域,例如可以应用于点云压缩技术领域。The present application can be applied to the field of point cloud upsampling technology, for example, can be applied to the field of point cloud compression technology.
为了便于理解本申请的实施例,首先对本申请实施例涉及到的相关概念进行如下简单介绍:In order to facilitate understanding of the embodiments of the present application, the relevant concepts involved in the embodiments of the present application are briefly introduced as follows:
点云(Point Cloud)是指空间中一组无规则分布的、表达三维物体或三维场景的空间结构及表面属性的离散点集。图1A为三维点云图像示意图,图1B为图1A的局部放大图,由图1A和图1B可知,点云表面是由分布稠密的点所组成的。Point cloud refers to a set of irregularly distributed discrete points in space that express the spatial structure and surface properties of a three-dimensional object or three-dimensional scene. Figure 1A is a schematic diagram of a three-dimensional point cloud image, and Figure 1B is a partial enlarged view of Figure 1A. It can be seen from Figures 1A and 1B that the point cloud surface is composed of densely distributed points.
二维图像在每一个像素点均有信息表达,分布规则,因此不需要额外记录其位置信息;然而点云中的点在三维空间中的分布具有随机性和不规则性,因此需要记录每一个点在空间中的位置,才能完整地表达一幅点云。与二维图像类似,采集过程中每一个位置均有对应的属性信息。Two-dimensional images have information expressed at each pixel point, and the distribution is regular, so there is no need to record its position information; however, the distribution of points in the point cloud in three-dimensional space is random and irregular, so it is necessary to record the position of each point in space to fully express a point cloud. Similar to two-dimensional images, each position has corresponding attribute information during the acquisition process.
点云数据(Point Cloud Data)是点云的具体记录形式,点云中的点可以包括点的位置信息和点的属性信息。例如,点的位置信息可以是点的三维坐标信息。点的位置信息也可称为点的几何信息。例如,点的属性信息可包括颜色信息、反射率信息、法向量信息等等。颜色信息反映物体的色彩,反射率(reflectance)信息反映物体的表面材质。所述颜色信息可以是任意一种色彩空间上的信息。例如,所述颜色信息可以是(RGB)。再如,所述颜色信息可以是于亮度色度(YcbCr,YUV)信息。例如,Y表示明亮度(Luma),Cb(U)表示蓝色色差,Cr(V)表示红色,U和V表示为色度(Chroma)用于描述色差信息。例如,根据激光测量原理得到的点云,所述点云中的点可以包括点的三维坐标信息和点的激光反射强度(reflectance)。再如,根据摄影测量原理得到的点云,所述点云中的点可以可包括点的三维坐标信息和点的颜色信息。再如,结合激光测量和摄影测量原理得到点云,所述点云中的点可以可包括点的三维坐标信息、点的激光反射强度(reflectance)和点的颜色信息。如图2示出了一幅点云图像,其中,图2示出了点云图像的六个观看角度,表1示出了由文件头信息部分和数据部分组成的点云数据存储格式:Point cloud data is a specific record form of point cloud. Points in the point cloud may include the location information of the point and the attribute information of the point. For example, the location information of the point may be the three-dimensional coordinate information of the point. The location information of the point may also be called the geometric information of the point. For example, the attribute information of the point may include color information, reflectance information, normal vector information, etc. Color information reflects the color of an object, and reflectance information reflects the surface material of an object. The color information may be information in any color space. For example, the color information may be (RGB). For another example, the color information may be information about brightness and chromaticity (YcbCr, YUV). For example, Y represents brightness (Luma), Cb (U) represents blue color difference, Cr (V) represents red, and U and V represent chromaticity (Chroma) for describing color difference information. For example, according to the point cloud obtained by the laser measurement principle, the points in the point cloud may include the three-dimensional coordinate information of the point and the laser reflection intensity (reflectance) of the point. For another example, according to the point cloud obtained by the photogrammetry principle, the points in the point cloud may include the three-dimensional coordinate information of the point and the color information of the point. For another example, a point cloud is obtained by combining the principles of laser measurement and photogrammetry. The points in the point cloud may include the three-dimensional coordinate information of the point, the laser reflection intensity (reflectance) of the point, and the color information of the point. FIG2 shows a point cloud image, where FIG2 shows six viewing angles of the point cloud image. Table 1 shows the point cloud data storage format composed of a file header information part and a data part:
表1Table 1

表1中,头信息包含了数据格式、数据表示类型、点云总点数、以及点云所表示的内容,例如,本例中的点云为“.ply”格式,由ASCII码表示,总点数为207242,每个点具有三维位置信息XYZ和三维颜色信息RGB。In Table 1, the header information includes the data format, data representation type, the total number of point cloud points, and the content represented by the point cloud. For example, the point cloud in this example is in the ".ply" format, represented by ASCII code, with a total number of 207242 points, and each point has three-dimensional position information XYZ and three-dimensional color information RGB.
点云可以灵活方便地表达三维物体或场景的空间结构及表面属性,并且由于点云通过直接对真实物体采样获得,在保证精度的前提下能提供极强的真实感,因而应用广泛,其范围包括虚拟现实游戏、计算机辅助设计、地理信息系统、自动导航系统、数字文化遗产、自由视点广播、三维沉浸远程呈现、生物组织器官三维重建等。Point clouds can flexibly and conveniently express the spatial structure and surface properties of three-dimensional objects or scenes. Point clouds are obtained by directly sampling real objects, so they can provide a strong sense of reality while ensuring accuracy. Therefore, they are widely used, including virtual reality games, computer-aided design, geographic information systems, automatic navigation systems, digital cultural heritage, free viewpoint broadcasting, three-dimensional immersive remote presentation, and three-dimensional reconstruction of biological tissues and organs.
点云数据的获取途径可以包括但不限于以下至少一种:(1)计算机设备生成。计算机设备可以根据虚拟三维物体及虚拟三维场景的生成点云数据。(2)3D(3-Dimension,三维)激光扫描获取。通过3D激光扫描可以获取静态现实世界三维物体或三维场景的点云数据,每秒可以获取百万级点云数据;(3)3D摄影测量获取。通过3D摄影设备(即一组摄像机或具有多个镜头和传感器的摄像机设备)对现实世界的视觉场景进行采集以获取现实世界的视觉场景的点云数据,通过3D摄影可以获得动态现实世界三维物体或三维场景的点云数据。(4)通过医学设备获取生物组织器官的点云数据。在医学领域可以通过磁共振成像(Magnetic Resonance Imaging,MRI)、电子计算机断层扫描(Computed Tomography,CT)、电磁定位信息等医学设备获取生物组织器官的点云数据。Point cloud data can be obtained by at least one of the following ways: (1) computer equipment generation. Computer equipment can generate point cloud data based on virtual three-dimensional objects and virtual three-dimensional scenes. (2) 3D (3-Dimension) laser scanning acquisition. 3D laser scanning can be used to obtain point cloud data of static real-world three-dimensional objects or three-dimensional scenes, and millions of point cloud data can be obtained per second; (3) 3D photogrammetry acquisition. The visual scene of the real world is collected by 3D photography equipment (i.e., a group of cameras or camera equipment with multiple lenses and sensors) to obtain point cloud data of the visual scene of the real world. 3D photography can be used to obtain point cloud data of dynamic real-world three-dimensional objects or three-dimensional scenes. (4) Point cloud data of biological tissues and organs can be obtained by medical equipment. In the medical field, point cloud data of biological tissues and organs can be obtained by medical equipment such as magnetic resonance imaging (MRI), computed tomography (CT), and electromagnetic positioning information.
点云可以按获取的途径分为:密集型点云和稀疏性点云。Point clouds can be divided into dense point clouds and sparse point clouds according to the way they are acquired.
点云按照数据的时序类型划分为:Point clouds are divided into the following types according to the time series of the data:
第一类静态点云:即物体是静止的,获取点云的设备也是静止的;The first type of static point cloud: the object is stationary, and the device that obtains the point cloud is also stationary;
第二类动态点云:物体是运动的,但获取点云的设备是静止的;The second type of dynamic point cloud: the object is moving, but the device that obtains the point cloud is stationary;
第三类动态获取点云:获取点云的设备是运动的。The third type of dynamic point cloud acquisition: the device that acquires the point cloud is moving.
按点云的用途分为两大类:Point clouds can be divided into two categories according to their uses:
类别一:机器感知点云,其可以用于自主导航系统、实时巡检系统、地理信息系统、视觉分拣机器人、抢险救灾机器人等场景;Category 1: Machine perception point cloud, which can be used in autonomous navigation systems, real-time inspection systems, geographic information systems, visual sorting robots, disaster relief robots, etc.
类别二:人眼感知点云,其可以用于数字文化遗产、自由视点广播、三维沉浸通信、三维沉浸交互等点云应用场景。Category 2: Point cloud perceived by the human eye, which can be used in point cloud application scenarios such as digital cultural heritage, free viewpoint broadcasting, 3D immersive communication, and 3D immersive interaction.
上述点云获取技术降低了点云数据获取成本和时间周期,提高了数据的精度。点云数据获取方式的变革,使大量点云数据的获取成为可能,伴随着应用需求的增长,海量3D点云数据的处理遭遇存储空间和传输带宽限制的瓶颈。The above point cloud acquisition technology reduces the cost and time of point cloud data acquisition and improves the accuracy of data. The change in the point cloud data acquisition method makes it possible to acquire a large amount of point cloud data. With the growth of application demand, the processing of massive 3D point cloud data encounters bottlenecks of storage space and transmission bandwidth.
以帧率为30fps(帧每秒)的点云视频为例,每帧点云的点数为70万,每个点具有坐标信息xyz(float)和颜色信息RGB(uchar),则10s点云视频的数据量大约为0.7millionX(4ByteX3+1ByteX3)X30fpsX10s=3.15GB,而YUV采样格式为4:2:0,帧率为24fps的1280X720二维视频,其10s的数据量约为1280X720X12bitX24framesX10s≈0.33GB,10s的两视角3D视频的数据量约为0.33X2=0.66GB。由此可见,点云视频的数据量远超过相同时长的二维视频和三维视频的数据量。因此,为更好地实现数据管理,节省服务器存储空间,降低服务器与客户端之间的传输流量及传输时间,点云压缩成为促进点云产业发展的关键问题。Taking a point cloud video with a frame rate of 30fps (frames per second) as an example, the number of points in each point cloud frame is 700,000, and each point has coordinate information xyz (float) and color information RGB (uchar). The data volume of a 10s point cloud video is approximately 0.7 million X (4ByteX3+1ByteX3) X 30fpsX10s = 3.15GB, while the YUV sampling format is 4:2:0, and the frame rate is 24fps. The data volume of a 1280X720 two-dimensional video in 10s is approximately 1280X720X12bitX24framesX10s≈0.33GB, and the data volume of a 10s two-view 3D video is approximately 0.33X2 = 0.66GB. It can be seen that the data volume of a point cloud video far exceeds that of a two-dimensional video and a three-dimensional video of the same length. Therefore, in order to better realize data management, save server storage space, and reduce the transmission traffic and transmission time between the server and the client, point cloud compression has become a key issue in promoting the development of the point cloud industry.
下面对点云编解码的相关知识进行介绍。The following is an introduction to the relevant knowledge of point cloud encoding and decoding.
图3为本申请实施例涉及的一种点云编解码系统的示意性框图。需要说明的是,图3只是一种示例,本申请实施例的点云编解码系统包括但不限于图3所示。如图3所示,该点云编解码系统100包含编码设备110和解码设备120。其中编码设备用于对点云数据进行编码(可以理解成压缩)产生码流,并将码流传输给解码设备。解码设备对编码设备编码产生的码流进行解码,得到解码后的点云数据。FIG3 is a schematic block diagram of a point cloud encoding and decoding system involved in an embodiment of the present application. It should be noted that FIG3 is only an example, and the point cloud encoding and decoding system of the embodiment of the present application includes but is not limited to that shown in FIG3. As shown in FIG3, the point cloud encoding and decoding system 100 includes an encoding device 110 and a decoding device 120. The encoding device is used to encode (which can be understood as compression) the point cloud data to generate a code stream, and transmit the code stream to the decoding device. The decoding device decodes the code stream generated by the encoding device to obtain decoded point cloud data.
本申请实施例的编码设备110可以理解为具有点云编码功能的设备,解码设备120可以理解为具有点云解码功能的设备,即本申请实施例对编码设备110和解码设备120包括更广泛的装置,例如包含智能手机、台式计算机、移动计算装置、笔记本(例如,膝上型)计算机、平板计算机、机顶盒、电视、相机、显示装置、数字媒体播放器、点云游戏控制台、车载计算机等。The encoding device 110 of the embodiment of the present application can be understood as a device with a point cloud encoding function, and the decoding device 120 can be understood as a device with a point cloud decoding function, that is, the embodiment of the present application includes a wider range of devices for the encoding device 110 and the decoding device 120, such as smartphones, desktop computers, mobile computing devices, notebook (e.g., laptop) computers, tablet computers, set-top boxes, televisions, cameras, display devices, digital media players, point cloud game consoles, vehicle-mounted computers, etc.
在一些实施例中,编码设备110可以经由信道130将编码后的点云数据(如码流)传输给解码设备120。信道130可以包括能够将编码后的点云数据从编码设备110传输到解码设备120的一个或多个媒体和/或装置。In some embodiments, the encoding device 110 may transmit the encoded point cloud data (such as a code stream) to the decoding device 120 via the channel 130. The channel 130 may include one or more media and/or devices capable of transmitting the encoded point cloud data from the encoding device 110 to the decoding device 120.
在一个实例中,信道130包括使编码设备110能够实时地将编码后的点云数据直接发射到解码设备120的一个或多个通信媒体。在此实例中,编码设备110可根据通信标准来调制编码后的点云数据,且将调制后的点云数据发射到解码设备120。其中通信媒体包含无线通信媒体,例如射频频谱,可选的,通信媒体还可以包含有线通信媒体,例如一根或多根物理传输线。In one example, the channel 130 includes one or more communication media that enable the encoding device 110 to transmit the encoded point cloud data directly to the decoding device 120 in real time. In this example, the encoding device 110 can modulate the encoded point cloud data according to the communication standard and transmit the modulated point cloud data to the decoding device 120. The communication medium includes a wireless communication medium, such as a radio frequency spectrum, and optionally, the communication medium may also include a wired communication medium, such as one or more physical transmission lines.
在另一实例中,信道130包括存储介质,该存储介质可以存储编码设备110编码后的点云数据。存储介质包含多种本地存取式数据存储介质,例如光盘、DVD、快闪存储器等。在该实例中,解码设备120可从该存储介质中获取编码后的点云数据。In another example, the channel 130 includes a storage medium, which can store the point cloud data encoded by the encoding device 110. The storage medium includes a variety of locally accessible data storage media, such as optical disks, DVDs, flash memories, etc. In this example, the decoding device 120 can obtain the encoded point cloud data from the storage medium.
在另一实例中,信道130可包含存储服务器,该存储服务器可以存储编码设备110编码后的点云数据。在此实例中,解码设备120可以从该存储服务器中下载存储的编码后的点云数据。可选的,该存储服务器可以存储编码后的点云数据且可以将该编码后的点云数据发射到解码设备120,例如web服务器(例如,用于网站)、文件传送协议(FTP)服务器等。In another example, the channel 130 may include a storage server that can store the point cloud data encoded by the encoding device 110. In this example, the decoding device 120 can download the stored encoded point cloud data from the storage server. Optionally, the storage server can store the encoded point cloud data and transmit the encoded point cloud data to the decoding device 120, such as a web server (e.g., for a website), a file transfer protocol (FTP) server, etc.
一些实施例中,编码设备110包含点云编码器112及输出接口113。其中,输出接口113可以包含调制器/解调器(调制解调器)和/或发射器。In some embodiments, the encoding device 110 includes a point cloud encoder 112 and an output interface 113. The output interface 113 may include a modulator/demodulator (modem) and/or a transmitter.
在一些实施例中,编码设备110除了包括点云编码器112和输入接口113外,还可以包括点云源111。In some embodiments, the encoding device 110 may further include a point cloud source 111 in addition to the point cloud encoder 112 and the input interface 113 .
点云源111可包含点云采集装置(例如,扫描仪)、点云存档、点云输入接口、计算机图形系统中的至少一个,其中,点云输入接口用于从点云内容提供者处接收点云数据,计算机图形系统用于产生点云数据。The point cloud source 111 may include at least one of a point cloud acquisition device (e.g., a scanner), a point cloud archive, a point cloud input interface, and a computer graphics system, wherein the point cloud input interface is used to receive point cloud data from a point cloud content provider, and the computer graphics system is used to generate point cloud data.
点云编码器112对来自点云源111的点云数据进行编码,产生码流。点云编码器112经由输出接口113将编码后的点云数据直接传输到解码设备120。编码后的点云数据还可存储于存储介质或存储服务器上,以供解码设备120后续读取。The point cloud encoder 112 encodes the point cloud data from the point cloud source 111 to generate a code stream. The point cloud encoder 112 transmits the encoded point cloud data directly to the decoding device 120 via the output interface 113. The encoded point cloud data can also be stored in a storage medium or a storage server for subsequent reading by the decoding device 120.
在一些实施例中,解码设备120包含输入接口121和点云解码器122。In some embodiments, the decoding device 120 includes an input interface 121 and a point cloud decoder 122 .
在一些实施例中,解码设备120除包括输入接口121和点云解码器122外,还可以包括显示装置123。In some embodiments, the decoding device 120 may further include a display device 123 in addition to the input interface 121 and the point cloud decoder 122 .
其中,输入接口121包含接收器及/或调制解调器。输入接口121可通过信道130接收编码后的点云数据。The input interface 121 includes a receiver and/or a modem. The input interface 121 can receive the encoded point cloud data through the channel 130 .
点云解码器122用于对编码后的点云数据进行解码,得到解码后的点云数据,并将解码后的点云数据传输至显示装置123。The point cloud decoder 122 is used to decode the encoded point cloud data to obtain decoded point cloud data, and transmit the decoded point cloud data to the display device 123.
显示装置123显示解码后的点云数据。显示装置123可与解码设备120整合或在解码设备120外部。显示装置123可包括多种显示装置,例如液晶显示器(LCD)、等离子体显示器、有机发光二极管(OLED)显示器或其它类型的显示装置。The decoded point cloud data is displayed on the display device 123. The display device 123 may be integrated with the decoding device 120 or may be external to the decoding device 120. The display device 123 may include a variety of display devices, such as a liquid crystal display (LCD), a plasma display, an organic light emitting diode (OLED) display, or other types of display devices.
此外,图3仅为实例,本申请实施例的技术方案不限于图3,例如本申请的技术还可以应用于单侧的点云编码或单侧的点云解码。In addition, Figure 3 is only an example, and the technical solution of the embodiment of the present application is not limited to Figure 3. For example, the technology of the present application can also be applied to unilateral point cloud encoding or unilateral point cloud decoding.
目前的点云编码器可以采用国际标准组织运动图像专家组(Moving Picture Experts Group,MPEG)提出了两种点云压缩编码技术路线,分别是基于投影的点云压缩(Video-based Point Cloud Compression,VPCC)和基于几何的点云压缩(Geometry-based Point Cloud Compression,GPCC)。VPCC通过将三维点云投影到二维,利用现有的二维编码工具对投影后的二维图像进行编码,GPCC利用层级化的结构将点云逐级划分为多个单元,通过编码记录划分过程编码整个点云。The current point cloud encoder can adopt two point cloud compression coding technology routes proposed by the International Standards Organization Moving Picture Experts Group (MPEG), namely Video-based Point Cloud Compression (VPCC) and Geometry-based Point Cloud Compression (GPCC). VPCC projects the three-dimensional point cloud into two dimensions and uses the existing two-dimensional coding tools to encode the projected two-dimensional image. GPCC uses a hierarchical structure to divide the point cloud into multiple units step by step, and encodes the entire point cloud by encoding the division process.
下面以GPCC编解码框架为例,对本申请实施例可适用的点云编码器和点云解码器进行说明。The following uses the GPCC encoding and decoding framework as an example to explain the point cloud encoder and point cloud decoder applicable to the embodiments of the present application.
图4A是本申请实施例提供的点云编码器的示意性框图。FIG. 4A is a schematic block diagram of a point cloud encoder provided in an embodiment of the present application.
由上述可知点云中的点可以包括点的位置信息和点的属性信息,因此,点云中的点的编码主要包括位置编码和属性编码。在一些示例中点云中点的位置信息又称为几何信息,对应的点云中点的位置编码也可以称为几何编码。From the above, we can know that the points in the point cloud can include the location information of the points and the attribute information of the points. Therefore, the encoding of the points in the point cloud mainly includes location encoding and attribute encoding. In some examples, the location information of the points in the point cloud is also called geometric information, and the corresponding location encoding of the points in the point cloud can also be called geometric encoding.
在GPCC编码框架中,点云的几何信息和对应的属性信息是分开编码的。In the GPCC coding framework, the geometric information of the point cloud and the corresponding attribute information are encoded separately.
如下图4A所示,目前G-PCC的几何编解码可分为基于八叉树的几何编解码和基于预测树的几何编解码。As shown in FIG. 4A below, the current geometric coding and decoding of G-PCC can be divided into octree-based geometric coding and decoding and prediction tree-based geometric coding and decoding.
位置编码的过程包括:对点云中的点进行预处理,例如坐标变换、量化和移除重复点等;接着,对预处理后的点云进行几何编码,例如构建八叉树,或构建预测树,基于构建的八叉树或预测树进行几何编码形成几何码流。同时,基于构建的八叉树或预测树输出的位置信息,对点云数据中各点的位置信息进行重建,得到各点的位置信息的重建值。The process of position coding includes: preprocessing the points in the point cloud, such as coordinate transformation, quantization, and removal of duplicate points; then, geometric coding the preprocessed point cloud, such as constructing an octree, or constructing a prediction tree, and geometric coding based on the constructed octree or prediction tree to form a geometric code stream. At the same time, based on the position information output by the constructed octree or prediction tree, the position information of each point in the point cloud data is reconstructed to obtain the reconstructed value of the position information of each point.
属性编码过程包括:通过给定输入点云的位置信息的重建信息和属性信息的原始值,选择三种预测模式的一种进行点云预测,对预测后的结果进行量化,并进行算术编码形成属性码流。The attribute encoding process includes: given the reconstruction information of the input point cloud position information and the original value of the attribute information, selecting one of the three prediction modes for point cloud prediction, quantizing the predicted result, and performing arithmetic coding to form an attribute code stream.
如图4A所示,位置编码可通过以下单元实现:As shown in Figure 4A, position encoding can be achieved by the following units:
坐标转换(Tanmsform coordinates)单元201、体素(Voxelize)单元202、八叉树划分(Analyze octree)单元203、几何重建(Reconstruct geometry)单元204、算术编码(Arithmetic enconde)单元205、表面拟合单元(Analyze surface approximation)206和预测树构建单元207。Coordinate transformation (Tanmsform coordinates) unit 201, voxel (Voxelize) unit 202, octree partition (Analyze octree) unit 203, geometry reconstruction (Reconstruct geometry) unit 204, arithmetic encoding (Arithmetic enconde) unit 205, surface fitting unit (Analyze surface approximation) 206 and prediction tree construction unit 207.
坐标转换单元201可用于将点云中点的世界坐标变换为相对坐标。例如,点的几何坐标分别减去xyz坐标轴的最小值,相当于去直流操作,以实现将点云中的点的坐标从世界坐标转换为相对坐标。The coordinate conversion unit 201 can be used to convert the world coordinates of the point in the point cloud into relative coordinates. For example, the geometric coordinates of the point are respectively subtracted from the minimum value of the xyz coordinate axis, which is equivalent to a DC removal operation, so as to realize the conversion of the coordinates of the point in the point cloud from the world coordinates to the relative coordinates.
体素(Voxelize)单元202也称为量化和移除重复点(Quantize and remove points)单元,可通过量化减少坐标的数目;量化后原先不同的点可能被赋予相同的坐标,基于此,可通过去重操作将重复的点删除;例如,具有相同量化位置和不同属性信息的多个云可通过属性转换合并到一个云中。在本申请的一些实施例中,体素单元202为可选的单元模块。The voxel unit 202 is also called a quantize and remove points unit, which can reduce the number of coordinates by quantization; after quantization, originally different points may be assigned the same coordinates, based on which, duplicate points can be deleted by deduplication operation; for example, multiple clouds with the same quantized position and different attribute information can be merged into one cloud by attribute conversion. In some embodiments of the present application, the voxel unit 202 is an optional unit module.
八叉树划分单元203可利用八叉树(octree)编码方式,编码量化的点的位置信息。例如,将点云按照八叉树的形式进行划分,由此,点的位置可以和八叉树的位置一一对应,通过统计八叉树中有点的位置,并将其标识(flag)记为1,以进行几何编码。The octree division unit 203 may use an octree encoding method to encode the position information of the quantized points. For example, the point cloud is divided in the form of an octree, so that the position of the point can correspond to the position of the octree one by one, and the position of the point in the octree is counted and its flag is recorded as 1 to perform geometric encoding.
在一些实施例中,在基于三角面片集(trianglesoup,trisoup)的几何信息编码过程中,同样也要通过八叉树划分单元203对点云进行八叉树划分,但区别于基于八叉树的几何信息编码,该trisoup不需要将点云逐级划分到边长为1X1X1的单位立方体,而是划分到block(子块)边长为W时停止划分,基于每个block中点云的分布所形成的表面,得到该表面与block的十二条边所产生的至多十二个vertex(交点),通过表面拟合单元206对交点进行表面拟合,对拟合后的交点进行几何编码。In some embodiments, in the process of geometric information encoding based on triangle soup (trisoup), the point cloud is also divided into octrees by the octree division unit 203. However, different from the geometric information encoding based on the octree, the trisoup does not need to divide the point cloud into unit cubes with a side length of 1X1X1 step by step, but stops dividing when the block (sub-block) has a side length of W. Based on the surface formed by the distribution of the point cloud in each block, at most twelve vertices (intersections) generated by the surface and the twelve edges of the block are obtained, and the intersections are surface fitted by the surface fitting unit 206, and the fitted intersections are geometrically encoded.
预测树构建单元207可利用预测树编码方式,编码量化的点的位置信息。例如,将点云按照预测树的形式进行划分,由此,点的位置可以和预测树中节点的位置一一对应,通过统计预测树中有点的位置,通过选取不同的预测模式 对节点的几何位置信息进行预测得到预测残差,并且利用量化参数对几何预测残差进行量化。最终通过不断迭代,对预测树节点位置信息的预测残差、预测树结构以及量化参数等进行编码,生成二进制码流。The prediction tree construction unit 207 can use the prediction tree encoding method to encode the position information of the quantized points. For example, the point cloud is divided in the form of a prediction tree, so that the position of the point can correspond to the position of the node in the prediction tree one by one. By counting the positions of the points in the prediction tree, different prediction modes are selected to predict the geometric position information of the node to obtain the prediction residual, and the geometric prediction residual is quantized using the quantization parameter. Finally, through continuous iteration, the prediction residual of the prediction tree node position information, the prediction tree structure and the quantization parameter are encoded to generate a binary code stream.
几何重建单元204可以基于八叉树划分单元203输出的位置信息或表面拟合单元206拟合后的交点进行位置重建,得到点云数据中各点的位置信息的重建值。或者,基于预测树构建单元207输出的位置信息进行位置重建,得到点云数据中各点的位置信息的重建值。The geometric reconstruction unit 204 can perform position reconstruction based on the position information output by the octree division unit 203 or the intersection points fitted by the surface fitting unit 206 to obtain the reconstructed value of the position information of each point in the point cloud data. Alternatively, the position reconstruction can be performed based on the position information output by the prediction tree construction unit 207 to obtain the reconstructed value of the position information of each point in the point cloud data.
算术编码单元205可以采用熵编码方式对八叉树分析单元203输出的位置信息或对表面拟合单元206拟合后的交点,或者预测树构建单元207输出的几何预测残差值进行算术编码,生成几何码流;几何码流也可称为几何比特流(geometry bitstream)。The arithmetic coding unit 205 can use entropy coding to perform arithmetic coding on the position information output by the octree analysis unit 203 or the intersection points fitted by the surface fitting unit 206, or the geometric prediction residual values output by the prediction tree construction unit 207 to generate a geometric code stream; the geometric code stream can also be called a geometry bitstream.
属性编码可通过以下单元实现:Attribute encoding can be achieved through the following units:
颜色转换(Transform colors)单元210、重着色(Transfer attributes)单元211、区域自适应分层变换(Region Adaptive Hierarchical Transform,RAHT)单元212、生成LOD(Generate LOD)单元213以及提升(lifting transform)单元214、量化系数(Quantize coefficients)单元215以及算术编码单元216。A color conversion (Transform colors) unit 210, a recoloring (Transfer attributes) unit 211, a Region Adaptive Hierarchical Transform (RAHT) unit 212, a Generate LOD (Generate LOD) unit 213, a lifting (lifting transform) unit 214, a Quantize coefficients (Quantize coefficients) unit 215 and an arithmetic coding unit 216.
需要说明的是,点云编码器200可包含比图4A更多、更少或不同的功能组件。It should be noted that the point cloud encoder 200 may include more, fewer, or different functional components than those shown in FIG. 4A .
颜色转换单元210可用于将点云中点的RGB色彩空间变换为YCbCr格式或其他格式。The color conversion unit 210 may be used to convert the RGB color space of the points in the point cloud into a YCbCr format or other formats.
重着色单元211利用重建的几何信息,对颜色信息进行重新着色,使得未编码的属性信息与重建的几何信息对应起来。The recoloring unit 211 recolors the color information using the reconstructed geometric information so that the uncoded attribute information corresponds to the reconstructed geometric information.
经过重着色单元211转换得到点的属性信息的原始值后,可选择任一种变换单元,对点云中的点进行变换。变换单元可包括:RAHT变换212和提升(lifting transform)单元214。其中,提升变化依赖生成细节层(level of detail,LOD)。After the original value of the attribute information of the point is converted by the recoloring unit 211, any transformation unit can be selected to transform the points in the point cloud. The transformation unit may include: RAHT transformation 212 and lifting (lifting transform) unit 214. Among them, the lifting transformation depends on generating a level of detail (LOD).
RAHT变换和提升变换中的任一项可以理解为用于对点云中点的属性信息进行预测,以得到点的属性信息的预测值,进而基于点的属性信息的预测值得到点的属性信息的残差值。例如,点的属性信息的残差值可以是点的属性信息的原始值减去点的属性信息的预测值。Any of the RAHT transformation and the lifting transformation can be understood as being used to predict the attribute information of a point in a point cloud to obtain a predicted value of the attribute information of the point, and then obtain a residual value of the attribute information of the point based on the predicted value of the attribute information of the point. For example, the residual value of the attribute information of the point can be the original value of the attribute information of the point minus the predicted value of the attribute information of the point.
在本申请的一实施例中,生成LOD单元生成LOD的过程包括:根据点云中点的位置信息,获取点与点之间的欧式距离;根据欧式距离,将点分为不同的细节表达层。在一个实施例中,可以将欧式距离进行排序后,将不同范围的欧式距离划分为不同的细节表达层。例如,可以随机挑选一个点,作为第一细节表达层。然后计算剩余点与该点的欧式距离,并将欧式距离符合第一阈值要求的点,归为第二细节表达层。获取第二细节表达层中点的质心,计算除第一、第二细节表达层以外的点与该质心的欧式距离,并将欧式距离符合第二阈值的点,归为第三细节表达层。以此类推,将所有的点都归到细节表达层中。通过调整欧式距离的阈值,可以使得每层LOD层的点的数量是递增的。应理解,LOD划分的方式还可以采用其它方式,本申请对此不进行限制。In one embodiment of the present application, the process of generating LOD by the LOD generating unit includes: obtaining the Euclidean distance between points according to the position information of the points in the point cloud; and dividing the points into different detail expression layers according to the Euclidean distance. In one embodiment, the Euclidean distances can be sorted and the Euclidean distances in different ranges can be divided into different detail expression layers. For example, a point can be randomly selected as the first detail expression layer. Then the Euclidean distances between the remaining points and the point are calculated, and the points whose Euclidean distances meet the first threshold requirement are classified as the second detail expression layer. The centroid of the points in the second detail expression layer is obtained, and the Euclidean distances between the points other than the first and second detail expression layers and the centroid are calculated, and the points whose Euclidean distances meet the second threshold are classified as the third detail expression layer. By analogy, all points are classified into the detail expression layer. By adjusting the threshold of the Euclidean distance, the number of points in each LOD layer can be increased. It should be understood that the LOD division method can also be adopted in other ways, and the present application does not limit this.
需要说明的是,可以直接将点云划分为一个或多个细节表达层,也可以先将点云划分为多个点云切块(slice),再将每一个点云切块划分为一个或多个LOD层。It should be noted that the point cloud may be directly divided into one or more detail expression layers, or the point cloud may be first divided into a plurality of point cloud slices, and then each point cloud slice may be divided into one or more LOD layers.
例如,可将点云划分为多个点云切块,每个点云切块的点的个数可以在55万-110万之间。每个点云切块可看成单独的点云。每个点云切块又可以划分为多个细节表达层,每个细节表达层包括多个点。在一个实施例中,可根据点与点之间的欧式距离,进行细节表达层的划分。For example, the point cloud can be divided into multiple point cloud blocks, and the number of points in each point cloud block can be between 550,000 and 1.1 million. Each point cloud block can be regarded as a separate point cloud. Each point cloud block can be divided into multiple detail expression layers, and each detail expression layer includes multiple points. In one embodiment, the detail expression layer can be divided according to the Euclidean distance between points.
量化单元215可用于量化点的属性信息的残差值。例如,若量化单元215和RAHT变换单元212相连,则量化单元215可用于量化RAHT变换单元212输出的点的属性信息的残差值。The quantization unit 215 may be used to quantize the residual value of the attribute information of the point. For example, if the quantization unit 215 is connected to the RAHT transformation unit 212, the quantization unit 215 may be used to quantize the residual value of the attribute information of the point output by the RAHT transformation unit 212.
算术编码单元216可使用零行程编码(Zero run length coding)对点的属性信息的残差值进行熵编码,以得到属性码流。所述属性码流可以是比特流信息。The arithmetic coding unit 216 may use zero run length coding to perform entropy coding on the residual value of the attribute information of the point to obtain an attribute code stream. The attribute code stream may be bit stream information.
图4B是本申请实施例提供的点云解码器的示意性框图。Figure 4B is a schematic block diagram of a point cloud decoder provided in an embodiment of the present application.
如图4B所示,解码器300可以从编码设备获取点云码流,通过解析码得到点云中的点的位置信息和属性信息。点云的解码包括位置解码和属性解码。As shown in Fig. 4B, the decoder 300 can obtain the point cloud code stream from the encoding device, and obtain the position information and attribute information of the points in the point cloud by parsing the code. The decoding of the point cloud includes position decoding and attribute decoding.
位置解码的过程包括:对几何码流进行算术解码;构建八叉树后进行合并,对点的位置信息进行重建,以得到点的位置信息的重建信息;对点的位置信息的重建信息进行坐标变换,得到点的位置信息。点的位置信息也可称为点的几何信息。The process of position decoding includes: performing arithmetic decoding on the geometric code stream; merging after building the octree, reconstructing the position information of the point to obtain the reconstructed information of the point position information; performing coordinate transformation on the reconstructed information of the point position information to obtain the point position information. The point position information can also be called the geometric information of the point.
属性解码过程包括:通过解析属性码流,获取点云中点的属性信息的残差值;通过对点的属性信息的残差值进行反量化,得到反量化后的点的属性信息的残差值;基于位置解码过程中获取的点的位置信息的重建信息,选择如下RAHT逆变换和提升逆变换中的一种进行点云预测,得到预测值,预测值与残差值相加得到点的属性信息的重建值;对点的属性信息的重建值进行颜色空间逆转换,以得到解码点云。The attribute decoding process includes: obtaining the residual value of the attribute information of the point in the point cloud by parsing the attribute code stream; obtaining the residual value of the attribute information of the point after dequantization by dequantizing the residual value of the attribute information of the point; based on the reconstruction information of the point position information obtained in the position decoding process, selecting one of the following RAHT inverse transform and lifting inverse transform to predict the point cloud to obtain the predicted value, and adding the predicted value to the residual value to obtain the reconstructed value of the attribute information of the point; performing color space inverse conversion on the reconstructed value of the attribute information of the point to obtain the decoded point cloud.
如图4B所示,位置解码可通过以下单元实现:As shown in FIG4B , position decoding can be achieved by the following units:
算数解码单元301、八叉树重构(synthesize octree)单元302、表面重构单元(Synthesize suface approximation)303、几何重建(Reconstruct geometry)单元304、坐标系反变换(inverse transform coordinates)单元305和预测树重建单元306。 Arithmetic decoding unit 301, octree reconstruction (synthesize octree) unit 302, surface reconstruction unit (Synthesize suface approximation) 303, geometry reconstruction (Reconstruct geometry) unit 304, inverse transform coordinates (inverse transform coordinates) unit 305 and prediction tree reconstruction unit 306.
属性编码可通过以下单元实现:Attribute encoding can be achieved through the following units:
算数解码单元310、反量化(inverse quantize)单元311、RAHT逆变换单元312、生成LOD(Generate LOD)单元313、提升逆变换(Inverse lifting)单元314以及颜色反变换(inverse trasform colors)单元315。 Arithmetic decoding unit 310, inverse quantize unit 311, RAHT inverse transform unit 312, generate LOD unit 313, inverse lifting unit 314 and inverse trasform colors unit 315.
需要说明的是,解压缩是压缩的逆过程,类似的,解码器300中的各个单元的功能可参见编码器200中相应的单元的功能。另外,点云解码器300可包含比图4B更多、更少或不同的功能组件。It should be noted that decompression is the inverse process of compression. Similarly, the functions of each unit in the decoder 300 can refer to the functions of the corresponding units in the encoder 200. In addition, the point cloud decoder 300 may include more, fewer or different functional components than those in FIG. 4B.
例如,解码器300可根据点云中点与点之间的欧式距离将点云划分为多个LOD;然后,依次对LOD中点的属性 信息进行解码;例如,计算零行程编码技术中零的数量(zero_cnt),以基于zero_cnt对残差进行解码;接着,解码框架200可基于解码出的残差值进行反量化,并基于反量化后的残差值与当前点的预测值相加得到该点云的重建值,直到解码完所有的点云。当前点将会作为后续LOD中点的最邻近点,并利用当前点的重建值对后续点的属性信息进行预测。For example, the decoder 300 may divide the point cloud into multiple LODs according to the Euclidean distance between points in the point cloud; then, the attribute information of the points in the LODs is decoded in sequence; for example, the number of zeros (zero_cnt) in the zero-run encoding technique is calculated to decode the residual based on zero_cnt; then, the decoding framework 200 may perform inverse quantization based on the decoded residual value, and obtain the reconstruction value of the point cloud based on the addition of the inverse quantized residual value and the predicted value of the current point, until all point clouds are decoded. The current point will be used as the nearest point of the subsequent LOD point, and the attribute information of the subsequent point will be predicted using the reconstruction value of the current point.
上述是基于GPCC编解码框架下的点云编解码器的基本流程,随着技术的发展,该框架或流程的一些模块或步骤可能会被优化,本申请适用于该基于GPCC编解码框架下的点云编解码器的基本流程,但不限于该框架及流程。The above is the basic process of the point cloud codec based on the GPCC codec framework. With the development of technology, some modules or steps of the framework or process may be optimized. This application is applicable to the basic process of the point cloud codec based on the GPCC codec framework, but is not limited to the framework and process.
下面对基于八叉树的几何编码和基于预测树的几何编码进行介绍。The following introduces octree-based geometric coding and prediction tree-based geometric coding.
基于八叉树的几何编码包括:首先对几何信息进行坐标转换,使点云全都包含在一个bounding box(包围盒)中。然后再进行量化,这一步量化主要起到缩放的作用,由于量化取整,使得一部分点的几何信息相同,根据参数来决定是否移除重复点,量化和移除重复点这一过程又被称为体素化过程。接下来,按照广度优先遍历的顺序不断对bounding box进行树划分(八叉树/四叉树/二叉树),对每个节点的占位码进行编码。在一种隐式几何的划分方式中,首先计算点云的包围盒
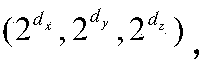 假设,该d
x>d
y>d
z包围盒对应为一个长方体。在几何划分时,首先会基于x轴一直进行二叉树划分,得到两个子节点;直到满足d
x=d
y>d
z条件时,才会基于x和y轴一直进行四叉树划分,得到四个子节点;当最终满足d
x=d
y=d
z条件时,会一直进行八叉树划分,直到划分得到的叶子结点为1x1x1的单位立方体时停止划分,对叶子结点中的点进行编码,生成二进制码流。在基于二叉树/四叉树/八叉树划分的过程中,引入两个参数:K、M。参数K指示在进行八叉树划分之前二叉树/四叉树划分的最多次数;参数M用来指示在进行二叉树/四叉树划分时对应的最小块边长为2
M。同时K和M必须满足条件:假设d
max=max(d
x,d
y,d
z),d
min=min(d
x,d
y,d
z),参数K满足:K>=d
max-d
min;参数M满足:M>=d
min。参数K与M之所以满足上述的条件,是因为目前G-PCC在几何隐式划分的过程中,划分方式的优先级为二叉树、四叉树和八叉树,当节点块大小不满足二叉树/四叉树的条件时,才会对节点一直进行八叉树的划分,直到划分到叶子节点最小单位1X1X1。
Octree-based geometric encoding includes: first, coordinate transformation of geometric information so that all point clouds are contained in a bounding box. Then quantization is performed. This step of quantization mainly plays a role of scaling. Due to quantization rounding, the geometric information of some points is the same. Whether to remove duplicate points is determined based on parameters. The process of quantization and removal of duplicate points is also called voxelization. Next, the bounding box is continuously divided into trees (octree/quadtree/binary tree) in the order of breadth-first traversal, and the placeholder code of each node is encoded. In an implicit geometric division method, the bounding box of the point cloud is first calculated. Assume that the bounding box of dx > dy > dz corresponds to a cuboid. During geometric partitioning, binary tree partitioning will be performed based on the x-axis to obtain two child nodes. When the condition of dx = dy > dz is met, quadtree partitioning will be performed based on the x-axis and y-axis to obtain four child nodes. When the condition of dx = dy = dz is finally met, octree partitioning will be performed until the leaf node obtained by partitioning is a 1x1x1 unit cube. The partitioning will be stopped, and the points in the leaf node will be encoded to generate a binary code stream. In the process of binary tree/quadtree/octree partitioning, two parameters are introduced: K and M. Parameter K indicates the maximum number of binary tree/quadtree partitioning before octree partitioning; parameter M is used to indicate that the minimum block side length corresponding to binary tree/quadtree partitioning is 2M . At the same time, K and M must meet the following conditions: Assuming d max = max(d x , dy , d z ), d min = min(d x , dy , d z ), parameter K satisfies: K>=d max -d min ; parameter M satisfies: M>=d min . The reason why parameters K and M meet the above conditions is that in the process of geometric implicit partitioning of G-PCC, the priority of partitioning is binary tree, quadtree and octree. When the node block size does not meet the conditions of binary tree/quadtree, the node will be partitioned into octree until it is partitioned into the smallest unit of leaf node 1X1X1.
假设,该d
x>d
y>d
z包围盒对应为一个长方体。在几何划分时,首先会基于x轴一直进行二叉树划分,得到两个子节点;直到满足d
x=d
y>d
z条件时,才会基于x和y轴一直进行四叉树划分,得到四个子节点;当最终满足d
x=d
y=d
z条件时,会一直进行八叉树划分,直到划分得到的叶子结点为1x1x1的单位立方体时停止划分,对叶子结点中的点进行编码,生成二进制码流。在基于二叉树/四叉树/八叉树划分的过程中,引入两个参数:K、M。参数K指示在进行八叉树划分之前二叉树/四叉树划分的最多次数;参数M用来指示在进行二叉树/四叉树划分时对应的最小块边长为2
M。同时K和M必须满足条件:假设d
max=max(d
x,d
y,d
z),d
min=min(d
x,d
y,d
z),参数K满足:K>=d
max-d
min;参数M满足:M>=d
min。参数K与M之所以满足上述的条件,是因为目前G-PCC在几何隐式划分的过程中,划分方式的优先级为二叉树、四叉树和八叉树,当节点块大小不满足二叉树/四叉树的条件时,才会对节点一直进行八叉树的划分,直到划分到叶子节点最小单位1X1X1。
Octree-based geometric encoding includes: first, coordinate transformation of geometric information so that all point clouds are contained in a bounding box. Then quantization is performed. This step of quantization mainly plays a role of scaling. Due to quantization rounding, the geometric information of some points is the same. Whether to remove duplicate points is determined based on parameters. The process of quantization and removal of duplicate points is also called voxelization. Next, the bounding box is continuously divided into trees (octree/quadtree/binary tree) in the order of breadth-first traversal, and the placeholder code of each node is encoded. In an implicit geometric division method, the bounding box of the point cloud is first calculated. Assume that the bounding box of dx > dy > dz corresponds to a cuboid. During geometric partitioning, binary tree partitioning will be performed based on the x-axis to obtain two child nodes. When the condition of dx = dy > dz is met, quadtree partitioning will be performed based on the x-axis and y-axis to obtain four child nodes. When the condition of dx = dy = dz is finally met, octree partitioning will be performed until the leaf node obtained by partitioning is a 1x1x1 unit cube. The partitioning will be stopped, and the points in the leaf node will be encoded to generate a binary code stream. In the process of binary tree/quadtree/octree partitioning, two parameters are introduced: K and M. Parameter K indicates the maximum number of binary tree/quadtree partitioning before octree partitioning; parameter M is used to indicate that the minimum block side length corresponding to binary tree/quadtree partitioning is 2M . At the same time, K and M must meet the following conditions: Assuming d max = max(d x , dy , d z ), d min = min(d x , dy , d z ), parameter K satisfies: K>=d max -d min ; parameter M satisfies: M>=d min . The reason why parameters K and M meet the above conditions is that in the process of geometric implicit partitioning of G-PCC, the priority of partitioning is binary tree, quadtree and octree. When the node block size does not meet the conditions of binary tree/quadtree, the node will be partitioned into octree until it is partitioned into the smallest unit of leaf node 1X1X1.
基于八叉树的几何信息编码模式可以通过利用空间中相邻点之间的相关性来对点云的几何信息进行有效的编码,但是对于一些较为平坦的节点或者具有平面特性的节点,通过利用平面编码可以进一步提升点云几何信息的编码效率。The octree-based geometric information encoding mode can effectively encode the geometric information of the point cloud by utilizing the correlation between adjacent points in space. However, for some relatively flat nodes or nodes with planar characteristics, the encoding efficiency of the point cloud geometric information can be further improved by using plane coding.
示例性的,如图5A所示,(a)系列属于Z轴方向的低平面位置,(b)轴系列属于Z轴方向的高平面位置。以(a)为例子,可以看到当前节点中被占据的四个子节点都位于当前节点在Z轴方向的低平面位置,那么可以认为当前节点属于一个Z平面并且在Z轴方向是一个低平面。同样的,(b)表示的是当前节点中被占据的子节点位于当前节点在Z轴方向的高平面位置。For example, as shown in FIG5A , the (a) series belongs to the low plane position in the Z-axis direction, and the (b) series belongs to the high plane position in the Z-axis direction. Taking (a) as an example, it can be seen that the four occupied subnodes in the current node are all located in the low plane position of the current node in the Z-axis direction, so it can be considered that the current node belongs to a Z plane and is a low plane in the Z-axis direction. Similarly, (b) indicates that the occupied subnodes in the current node are located in the high plane position of the current node in the Z-axis direction.
下面以(a)为例,对八叉树编码和平面编码效率进行比较。如图5B所示,对图1中的(a)采用八叉树编码方式,那么当前节点的占位信息表示为:11001100。但是如果采用平面编码方式,首先需要编码一个标识符表示当前节点在Z轴方向是一个平面,其次如果当前节点在Z轴方向是一个平面,需要对当前节点的平面位置进行表示。其次仅仅需要对Z轴方向的低平面节点占位信息进行编码(即0246四个子节点的占位信息),因此基于平面编码方式对当前节点进行编码,仅仅需要编码6个bit,相比原本的八叉树编码可以减少2个bit的表示。基于此分析,平面编码相比八叉树编码具有较为明显的编码效率。因此,对于一个被占据的节点,如果在某一个维度上采用平面编码方式进行编码,则如图5C所示,首先需要对当前节点在该维度上的平面标识(planarMode)和平面位置(PlanePos)信息进行表示,其次基于当前节点的平面信息来对当前节点的占位信息进行编码。需要注意的是:PlaneMode
i(i=0,1,2):0代表当前节点在i轴方向不是一个平面,当节点在i轴方向是一个平面时,PlanePosition
i:0代表当前节点在i轴方向是一个平面,并且平面位置为低平面,1表示当前节点在i轴方向上是一个高平面。示例性的,i=0表示X轴,i=1表示Y轴,i=2表示Z轴。
Taking (a) as an example, the efficiency of octree coding and plane coding is compared. As shown in Figure 5B, if the octree coding method is used for (a) in Figure 1, the placeholder information of the current node is represented as: 11001100. However, if the plane coding method is used, first, an identifier needs to be encoded to indicate that the current node is a plane in the Z-axis direction. Secondly, if the current node is a plane in the Z-axis direction, the plane position of the current node needs to be represented. Secondly, only the placeholder information of the low plane node in the Z-axis direction needs to be encoded (that is, the placeholder information of the four child nodes 0246). Therefore, based on the plane coding method, only 6 bits need to be encoded to encode the current node, which can reduce the representation of 2 bits compared to the original octree coding. Based on this analysis, plane coding has a more obvious coding efficiency than octree coding. Therefore, for an occupied node, if a plane encoding method is used for encoding in a certain dimension, as shown in FIG5C , firstly, the plane identification (planarMode) and plane position (PlanePos) information of the current node in the dimension need to be represented, and secondly, the occupancy information of the current node is encoded based on the plane information of the current node. It should be noted that: PlaneMode i (i=0,1,2): 0 represents that the current node is not a plane in the i-axis direction. When the node is a plane in the i-axis direction, PlanePosition i : 0 represents that the current node is a plane in the i-axis direction, and the plane position is a low plane, and 1 represents that the current node is a high plane in the i-axis direction. Exemplarily, i=0 represents the X-axis, i=1 represents the Y-axis, and i=2 represents the Z-axis.
下面将详细介绍一下当前G-PCC标准中,判断一个节点是否满足平面编码的条件以及当节点满足平面编码条件时,对节点平面标识和平面位置信息的预测编码。The following is a detailed introduction to the current G-PCC standard for determining whether a node meets the plane coding conditions and predictive coding of the node plane identification and plane position information when the node meets the plane coding conditions.
当前G-PCC中存在3种判断节点是否满足平面编码的判断条件,下面逐一进行介绍:Currently, there are three types of judgment conditions in G-PCC to determine whether a node meets the plane coding criteria. The following describes them one by one:
第1种:根据节点在每个维度上的平面概率进行判断。The first type: judge based on the plane probability of the node in each dimension.
首先确定当前节点的局部区域密度(local_node_density),以及当前节点在每个维度上的概率Prob(i)。First, determine the local area density (local_node_density) of the current node and the probability Prob(i) of the current node in each dimension.
当节点的局部区域密度小于阈值Th(Th=3)时,利用当前节点在三维上的平面概率Prob(i)和阈值Th0、Th1和Th2进行比较,其中Th0<Th1<Th2(Th0=0.6,Th1=0.77,Th2=0.88)。下面利用Eligible
i(i=0,1,2)表示每个维度上是否启动平面编码,其中Eligible
i的判断过程如公式(1)所示,例如若Eligible
i>=threshold则表示第i维度上启动平面编码:
When the local area density of the node is less than the threshold Th (Th = 3), the plane probability Prob (i) of the current node in three dimensions is compared with the thresholds Th0, Th1 and Th2, where Th0 < Th1 < Th2 (Th0 = 0.6, Th1 = 0.77, Th2 = 0.88). Eligible i (i = 0, 1, 2) is used below to indicate whether plane coding is enabled in each dimension, where the judgment process of Eligible i is shown in formula (1). For example, if Eligible i > = threshold, it means that plane coding is enabled in the i-th dimension:
Eligible
i=Prob(i)>=threshold (1)
Eligible i = Prob(i)> = threshold (1)
需要注意的是threshold是进行自适应变化的,例如:当Prob(0)>Prob(1)>Prob(2)时,则threshold取值如公式(2)所示:It should be noted that the threshold is adaptively changed. For example, when Prob(0)>Prob(1)>Prob(2), the threshold value is as shown in formula (2):
Eligible
0=Prob(0)>=Th0
Eligible 0 = Prob(0) > = Th0
Eligible
1=Prob(1)>=Th1
Eligible 1 = Prob(1) > = Th1
Eligible
2=Prob(2)>=Th2 (2)
Eligible 2 = Prob(2) > = Th2 (2)
下面介绍local_node_density的更新过程以及Prob(i)的更新。The following describes the update process of local_node_density and the update of Prob(i).
在一种示例中,Prob(i)通过如下公式(3)进行更新:In one example, Prob(i) is updated by the following formula (3):
Prob(i)
new=(Lx Prob(i)+δ(coded node))/L+1 (3)
Prob(i) new = (L x Prob(i) + δ(coded node)) / L + 1 (3)
其中,L=255,当coded node节点是一个平面时,则为1否则为0。Where L=255, when the coded node is a plane, it is 1, otherwise it is 0.
在一种示例中,local_node_density通过如下公式(4)进行更新:In one example, local_node_density is updated by the following formula (4):
local_node_density
new=local_node_density+4*numSiblings (4)
local_node_density new = local_node_density + 4*numSiblings (4)
其中,local_node_density初始化为4,numSiblings为节点的兄弟姐妹节点数目,如图5D所示,当前节点为左侧 节点,右侧节点为当前节点的兄弟姐妹节点,则当前节点的兄弟姐妹节点数目为5(包括自身)。Among them, local_node_density is initialized to 4, numSiblings is the number of siblings of the node, as shown in Figure 5D, the current node is the left node, the right node is the sibling of the current node, then the number of siblings of the current node is 5 (including itself).
第2种:根据当前层的点云密度来判断当前层节点是否满足平面编码。The second method: Determine whether the current layer nodes meet the plane coding requirements based on the point cloud density of the current layer.
利用当前层中点的密度来判断是否对当前层的节点进行平面编码。假设当前待编码点云的点数为pointCount,经过IDCM编码已经重建出的点数为numPointCountRecon,又因为八叉树是基于广度优先遍历的顺序进行编码,因此可以得到当前层待编码的节点数目假设为nodeCount,则假设通过planarEligibleKOctreeDepth表示当前层是否启动平面编码。其中,planarEligibleKOctreeDepth的判断过程如公式(5)所示:The density of the points in the current layer is used to determine whether to perform plane coding on the nodes in the current layer. Assuming that the number of points in the current point cloud to be coded is pointCount, the number of points reconstructed after IDCM coding is numPointCountRecon, and because the octree is coded in the order of breadth-first traversal, the number of nodes to be coded in the current layer can be obtained as nodeCount. It is assumed that planarEligibleKOctreeDepth is used to indicate whether the current layer starts plane coding. The judgment process of planarEligibleKOctreeDepth is shown in formula (5):
planarEligibleKOctreeDepth=(pointCount-numPointCountRecon)<nodeCount*1.3 (5)planarEligibleKOctreeDepth=(pointCount-numPointCountRecon)<nodeCount*1.3 (5)
当planarEligibleKOctreeDepth为true时,则当前层中的所有节点都进行平面编码;否则不进行平面编码,仅仅采用八叉树编码。When planarEligibleKOctreeDepth is true, all nodes in the current layer are plane coded; otherwise, no plane coding is performed and only octree coding is used.
第3种:根据激光雷达点云的采集参数来判断当前节点是否满足平面编码。The third method is to determine whether the current node meets the plane coding requirements based on the acquisition parameters of the lidar point cloud.
如图5E所示,可以看到上方大的正方体节点同时被两个Laser穿过,因此当前节点在Z轴垂直方向上不是一个平面,下方小的正方体节点足够小到不能同时被两个节点同时穿过,因此有可能是一个平面。因此,可以基于当前节点对应的Laser个数,判断当前节点是否满足平面编码。As shown in Figure 5E, it can be seen that the large cube node on the top is traversed by two lasers at the same time, so the current node is not a plane in the vertical direction of the Z axis, and the small cube node on the bottom is small enough that it cannot be traversed by two nodes at the same time, so it may be a plane. Therefore, based on the number of lasers corresponding to the current node, it can be judged whether the current node meets the plane coding.
下面将介绍目前针对满足平面编码条件的节点,平面标识信息和平面位置信息的预测编码。The following will introduce the predictive coding of plane identification information and plane position information for nodes that currently meet the plane coding conditions.
一、平面标识信息的预测编码1. Predictive Coding of Plane Marking Information
目前采用三个上下文对平面标识信息进行编码,即各个维度上的平面表示分开进行设计上下文。Currently, three contexts are used to encode the plane identification information, that is, the plane representation in each dimension is separately designed in context.
下面对非激光雷达点云和激光雷达点云的平面位置信息的编码进行分别介绍。The encoding of the planar position information of non-lidar point clouds and lidar point clouds is introduced separately below.
一)、非激光雷达点云平面位置信息的编码1) Coding of non-lidar point cloud planar position information
1、平面位置信息的预测编码。1. Predictive coding of planar position information.
平面位置信息基于如下信息进行预测编码:The plane position information is predictively coded based on the following information:
(1)利用邻域节点占位信息进行预测得到当前节点的平面位置信息为三元素:预测为低平面、预测为高平面和无法预测;(1) Using the occupancy information of neighboring nodes, the plane position information of the current node is predicted to be three elements: predicted as a low plane, predicted as a high plane, and unpredictable;
(2)与当前节点在相同的划分深度以及相同的坐标下的节点与当前节点之间的空间距离“近”和“远”;(2) The spatial distance between the nodes at the same partition depth and the same coordinates as the current node and the current node is “close” or “far”;
(3)与当前节点在相同的划分深度以及相同的坐标下的节点平面位置;(3) The plane position of the node at the same partition depth and the same coordinates as the current node;
(4)坐标维度(i=0,1,2)。(4) Coordinate dimension (i=0, 1, 2).
如图5F所示,当前待编码节点为左侧节点,则在相同的八叉树划分深度等级下,以及相同的垂直坐标下查找邻域节点为右侧节点,判断两个节点之间的距离为“近”和“远”,并且参考节点的平面位置。As shown in Figure 5F, the current node to be encoded is the left node, then the neighboring node is searched for as the right node at the same octree partition depth level and the same vertical coordinate, the distance between the two nodes is judged as "near" and "far", and the plane position of the reference node is used.
在一种示例中,如图5G所示,黑色节点为当前节点,若当前节点位于父节点的低平面时,通过如下方式,确定当前节点的平面位置:In one example, as shown in FIG5G , the black node is the current node. If the current node is located at the lower plane of the parent node, the plane position of the current node is determined in the following manner:
a)、如果斜划线节点的子节点4到7中有任何一个被占用,而所有点状节点都未被占用,则极有可能当前节点中存在一个平面,且该平面位置较低。a) If any of the child nodes 4 to 7 of the oblique line node is occupied, and all the dot nodes are not occupied, it is very likely that there is a plane in the current node, and the plane is at a lower position.
b)、如果斜划线节点的子节点4到7都未被占用,而任何点状节点被占用,则极有可能在当前节点中存在一个平面,且该平面位置较高。b) If the child nodes 4 to 7 of the oblique line node are not occupied, and any dot node is occupied, it is very likely that there is a plane in the current node, and the plane is at a higher position.
c)、如果斜划线节点的子节点4到7均为空节点,点状节点均为空节点,则无法推断平面位置,故标记为未知。c) If the child nodes 4 to 7 of the oblique line node are all empty nodes and the dot nodes are all empty nodes, the plane position cannot be inferred and is therefore marked as unknown.
如果斜划线节点的子节点4到7中有任何一个被占用,而点状节点中有任何一个被占用,则无法推断出平面位置,因此将其标记为未知。If any of the children 4 to 7 of the dashed node are occupied and any of the dotted nodes are occupied, the plane position cannot be inferred and is therefore marked as unknown.
在另一种示例中,如图5H所示,黑色节点为当前节点,若当节点处于父节点高平面位置时,则通过如下方式,确定当前节点的平面位置:In another example, as shown in FIG5H , the black node is the current node. If the node is at a high plane position of the parent node, the plane position of the current node is determined in the following manner:
a)、如果点状节点的子节点4到7中有任何一个节点被占用,而斜划线节点未被占用,则极有可能在当前节点中存在一个平面,且平面位置较低。a) If any of the child nodes 4 to 7 of the dot node is occupied, and the dashed node is not occupied, it is very likely that there is a plane in the current node, and the plane position is lower.
b)、如果点状节点的子节点4~7均未被占用,而斜划线节点被占用,则极有可能在当前节点中存在平面,且平面位置较高。b) If the child nodes 4 to 7 of the dot node are not occupied, but the oblique line node is occupied, it is very likely that there is a plane in the current node, and the plane position is relatively high.
c)、如果点状节点的子节点4~7都是未被占用的,而斜划线节点是未被占用的,无法推断平面位置,因此标记为未知。c) If the child nodes 4 to 7 of the dot node are all unoccupied, and the slash node is unoccupied, the plane position cannot be inferred, so it is marked as unknown.
d)、如果点状节点的子节点4-7中有一个被占用,而斜划线节点被占用,无法推断平面位置,因此标记为未知。d) If one of the child nodes 4-7 of the dot node is occupied, and the slash node is occupied, the plane position cannot be inferred and is therefore marked as unknown.
二)、激光雷达点云平面位置信息的编码2) Coding of planar position information of laser radar point cloud
图5I为激光雷达点云平面位置信息的预测编码,通过利用激光雷达采集参数来预测当前节点的平面位置,通过利用当前节点与激光射线相交的位置来将位置量化为四个区间,最终作为当前节点平面位置的上下文。具体计算过程如下:假设激光雷达的坐标为(x
Lidar,y
Lidar,z
Lidar),当前点的几何坐标为(x,y,z),则首先计算当前点相对于激光雷达的垂直正切值tanθ,计算过程如公式(6)所示:
Figure 5I is the predictive coding of the plane position information of the laser radar point cloud. The plane position of the current node is predicted by using the laser radar acquisition parameters, and the position is quantized into four intervals by using the position where the current node intersects with the laser ray, and finally used as the context of the plane position of the current node. The specific calculation process is as follows: Assuming that the coordinates of the laser radar are (x Lidar , y Lidar , z Lidar ), and the geometric coordinates of the current point are (x, y, z), first calculate the vertical tangent value tanθ of the current point relative to the laser radar. The calculation process is shown in formula (6):
又因为每个Laser会相对于激光雷达有一定偏移角度,因此会计算当前节点相对于Laser的相对正切值tanθ
corr,L,具体计算过程如公式(7)所示:
Since each laser has a certain offset angle relative to the laser radar, the relative tangent value tanθ corr,L of the current node relative to the laser is calculated. The specific calculation process is shown in formula (7):
最终会利用当前节点的修正正切值来对当前节点的平面位置进行预测,具体如下,假设当前节点下边界的正切值为tan(θ底部),上边界的正切值为tan(θ顶部),根据tanθ
corr,L将平面位置量化为4个量化区间,即平面位置的上下文。
Finally, the corrected tangent value of the current node is used to predict the plane position of the current node. Specifically, assuming that the tangent value of the lower boundary of the current node is tan(θ bottom ), and the tangent value of the upper boundary is tan(θ top ), the plane position is quantized into 4 quantization intervals according to tanθ corr,L , which is the context of the plane position.
但基于八叉树的几何信息编码模式仅对空间中具有相关性的点有高效的压缩速率,而对于在几何空间中处于孤立位置的点来说,使用直接编码模式(Direct Coding Model,简称DCM)可以大大降低复杂度。对于八叉树中的所有节点,DCM的使用不是通过标志位信息来表示的,而是通过当前节点父节点和邻居信息来进行推断得到。判断当前节点 是否具有DCM编码资格的方式有三种,如图6A所示:However, the octree-based geometric information coding mode only has an efficient compression rate for points with correlation in space. For points in isolated positions in the geometric space, the use of the direct coding model (DCM) can greatly reduce the complexity. For all nodes in the octree, the use of DCM is not indicated by the flag information, but is inferred by the parent node and neighbor information of the current node. There are three ways to determine whether the current node is eligible for DCM coding, as shown in Figure 6A:
(1)当前节点没有兄弟姐妹子节点,即当前节点的父节点只有一个孩子节点,同时当前节点父节点的父节点仅有两个被占据子节点,即当前节点最多只有一个邻居节点。(1) The current node has no sibling child nodes, that is, the parent node of the current node has only one child node, and the parent node of the parent node of the current node has only two occupied child nodes, that is, the current node has at most one neighbor node.
(2)当前节点的父节点仅有当前节点一个占据子节点,同时与当前节点共用一个面的六个邻居节点也都属于空节点。(2) The parent node of the current node has only one child node, the current node. At the same time, the six neighbor nodes that share a face with the current node are also empty nodes.
(3)当前节点的兄弟姐妹节点数目大于1。(3) The number of sibling nodes of the current node is greater than 1.
如果当前节点不具有DCM编码资格将对其进行八叉树划分,若具有DCM编码资格将进一步判断该节点中包含的点数,当点数小于阈值2时,则对该节点进行DCM编码,否则将继续进行八叉树划分。当应用DCM编码模式时,首先需要编码当前节点是否是一个真正的孤立点,即IDCM_flag,当IDCM_flag为true时,则当前节点采用DCM编码,否则仍然采用八叉树编码。当前节点满足DCM编码时,需要编码当前节点的DCM编码模式,目前存在两种DCM模式,分别是:1:仅仅只有一个点存在(或者是多个点,但是属于重复点);2:含有两个点。最后需要编码每个点的几何信息,假设节点的边长为2
d时,对该节点几何坐标的每一个分量进行编码时需要d比特,该比特信息直接被编进码流中。这里需要注意的是,在对激光雷达点云进行编码时,通过利用激光雷达采集参数来对三个维度的坐标信息进行预测编码,从而可以进一步提升几何信息的编码效率。
If the current node does not have the DCM coding qualification, it will be divided into octrees. If it has the DCM coding qualification, the number of points contained in the node will be further determined. When the number of points is less than the threshold 2, the node will be DCM-encoded, otherwise the octree division will continue. When the DCM coding mode is applied, it is first necessary to encode whether the current node is a true isolated point, that is, IDCM_flag. When IDCM_flag is true, the current node is encoded using DCM, otherwise it is still encoded using octrees. When the current node meets the DCM coding requirements, it is necessary to encode the DCM coding mode of the current node. There are currently two DCM modes: 1: only one point exists (or multiple points, but they are repeated points); 2: contains two points. Finally, it is necessary to encode the geometric information of each point. Assuming that the side length of the node is 2d , d bits are required to encode each component of the geometric coordinates of the node, and the bit information is directly encoded into the bit stream. It should be noted here that when encoding the lidar point cloud, the three-dimensional coordinate information is predictively encoded by using the lidar acquisition parameters, so as to further improve the coding efficiency of the geometric information.
接下来对IDCM编码的过程进行详细的介绍:Next, the IDCM encoding process is introduced in detail:
当前节点满足直接编码模式(DCM)时,首先编码当前节点的点数目numPoints,根据不同的DirectMode来对当前节点的点数目进行编码,具体包括如下方式:When the current node satisfies the direct coding mode (DCM), the number of points numPoints of the current node is first encoded, and the number of points of the current node is encoded according to different DirectModes, including the following methods:
1、如果当前节点不满足DCM节点的要求,则直接退出,(即点数大于2个点,并且不是重复点)。1. If the current node does not meet the requirements of the DCM node, exit directly (that is, the number of points is greater than 2 points and is not a duplicate point).
2、当前节点含有的点数numPonts小于等于2,则编码过程如下:2. If the number of points numPonts in the current node is less than or equal to 2, the encoding process is as follows:
1)、首先编码当前节点的numPonts是否大于1;1) First, encode whether the numPonts of the current node is greater than 1;
2)、如果当前节点只有一个点并且几何编码环境为几何无损编码,则需要编码当前节点的第二个点不是重复点。2) If the current node has only one point and the geometry coding environment is geometry lossless coding, it is necessary to encode that the second point of the current node is not a duplicate point.
3、当前节点含有的点数numPonts大于2,则编码过程如下:3. If the number of points numPonts contained in the current node is greater than 2, the encoding process is as follows:
1)、首先编码当前节点的numPonts小于等于1;1) First, encode the numPonts of the current node to be less than or equal to 1;
2)、其次编码当前节点的第二个点是一个重复点,其次编码当前节点的重复点数目是否大于1,当重复点数目大于1时,需要对剩余的重复点数目进行指数哥伦布解码。2) Secondly, encode whether the second point of the current node is a repeated point, and then encode whether the number of repeated points of the current node is greater than 1. When the number of repeated points is greater than 1, it is necessary to perform exponential Columbus decoding on the remaining number of repeated points.
在编码完当前节点的点数目之后,对当前节点中包含点的坐标信息进行编码。下面将分别对激光雷达点云和面向人眼点云分开介绍。After encoding the number of points in the current node, the coordinate information of the points contained in the current node is encoded. The following will introduce the lidar point cloud and the human eye point cloud separately.
面向人眼点云Point cloud for human eyes
1)、如果当前节点中仅仅只含有一个点,则会对点的三个维度方向的几何信息进行直接编码(Bypass coding)。1) If the current node contains only one point, the geometric information of the point in three dimensions will be directly encoded (Bypass coding).
2)、如果当前节点中含有两个点,则会首先通过利用点的几何坐标得到优先编码的坐标轴dirextAxis,这里需要注意的是,目前比较的坐标轴只包含x和y轴,不包含z轴。假设当前节点的几何坐标为nodePos,则采用如公式(8)所示的方式,确定优先编码的坐标轴:2) If the current node contains two points, the priority coded coordinate axis dirextAxis will be obtained by using the geometric coordinates of the points. It should be noted that the currently compared coordinate axes only include the x and y axes, not the z axis. Assuming that the geometric coordinates of the current node are nodePos, the priority coded coordinate axis is determined by the method shown in formula (8):
dirextAxis=!(nodePos[0]<nodePos[1]) (8)dirextAxis=! (nodePos[0]<nodePos[1]) (8)
也就是将节点坐标几何位置小的轴作为优先编码的坐标轴dirextAxis。That is to say, the axis with the smaller node coordinate geometric position is used as the coordinate axis dirextAxis for priority encoding.
其次按照如下方式首先对优先编码的坐标轴dirextAxis几何信息进行编码,假设优先编码的轴对应的待编码几何bit深度为nodeSizeLog2,并假设两个点的坐标分别为pointPos[0]和pointPos[1]:Secondly, the geometry information of the dirextAxis coordinate axis of the priority coding is first encoded as follows, assuming that the bit depth of the geometry to be encoded corresponding to the priority coding axis is nodeSizeLog2, and assuming that the coordinates of the two points are pointPos[0] and pointPos[1] respectively:

在编码完优先编码轴dirextAxis之后,再对当前点的几何坐标进行直接编码。假设每个点的剩余编码bit深度为nodeSizeLog2,则具体编码过程如下:After encoding the priority encoding axis dirextAxis, the geometric coordinates of the current point are directly encoded. Assuming that the remaining encoding bit depth of each point is nodeSizeLog2, the specific encoding process is as follows:
for(int axisIdx=0;axisIdx<3;++axisIdx)for(int axisIdx=0;axisIdx<3;++axisIdx)
for(int mask=(1<<nodeSizeLog2[axisIdx])>>1;mask;mask>>1)for(int mask=(1<<nodeSizeLog2[axisIdx])>>1;mask;mask>>1)
encodePosBit(!!(pointPos[axisIdx]&mask));encodePosBit(!!(pointPos[axisIdx]&mask));
面向激光雷达点云For LiDAR point clouds
1)、如果当前节点中含有两个点,则会首先通过利用点的几何坐标得到优先编码的坐标轴dirextAxis,假设当前节点的几何坐标为nodePos,则采用如公式(9)所示的方式,确定优先编码的坐标轴:1) If the current node contains two points, the priority coded coordinate axis dirextAxis will be obtained by using the geometric coordinates of the points. Assuming that the geometric coordinates of the current node are nodePos, the priority coded coordinate axis is determined by the method shown in formula (9):
dirextAxis=!(nodePos[0]<nodePos[1]) (9)dirextAxis=! (nodePos[0]<nodePos[1]) (9)
也就是将节点坐标几何位置小的轴作为优先编码的坐标轴dirextAxis,这里需要注意的是,目前比较的坐标轴只包含x和y轴,不包含z轴。That is to say, the axis with the smaller node coordinate geometric position is used as the coordinate axis dirextAxis for priority encoding. It should be noted here that the currently compared coordinate axes only include the x and y axes, but not the z axis.
其次按照如下方式首先对优先编码的坐标轴dirextAxis几何信息进行编码,假设优先编码的轴对应的待编码几何bit深度为nodeSizeLog2,并假设两个点的坐标分别为pointPos[0]和pointPos[1]:Secondly, the geometry information of the dirextAxis coordinate axis of the priority coding is first encoded as follows, assuming that the bit depth of the geometry to be encoded corresponding to the priority coding axis is nodeSizeLog2, and assuming that the coordinates of the two points are pointPos[0] and pointPos[1] respectively:

在编码完优先编码轴dirextAxis之后,再对当前点的几何坐标进行编码。After encoding the priority encoding axis dirextAxis, the geometric coordinates of the current point are encoded.
由于激光雷达点云可以得到激光雷达点云的采集参数,通过利用可以预测当前节点的几何坐标信息,从而可以进一步提升点云的几何信息编码效率。同样的首先利用当前节点的几何信息nodePos得到一个直接编码的主轴方向,其次利用已经完成编码的方向的几何信息来对另外一个维度的几何信息进行预测编码。同样假设直接编码的轴方向是directAxis,并且假设直接编码中的待编码bit深度为nodeSizeLog2,则编码方式如下:Since the laser radar point cloud can obtain the acquisition parameters of the laser radar point cloud, the geometric coordinate information of the current node can be predicted, so as to further improve the efficiency of the geometric information encoding of the point cloud. Similarly, the geometric information nodePos of the current node is first used to obtain a directly encoded main axis direction, and then the geometric information of the encoded direction is used to predict the geometric information of another dimension. Also, assuming that the axis direction of the direct encoding is directAxis, and assuming that the bit depth to be encoded in the direct encoding is nodeSizeLog2, the encoding method is as follows:
for(int mask=(1<<nodeSizeLog2)>>1;mask;mask>>1)for(int mask=(1<<nodeSizeLog2)>>1;mask;mask>>1)
encodePosBit(!!(pointPos[directAxis]&mask));encodePosBit(!!(pointPos[directAxis]&mask));
这里需要注意的是,在这里会将directAxis方向的几何精度信息全部编码。It should be noted here that all geometric accuracy information in the directAxis direction will be encoded here.
在编码完directAxis坐标方向的所有精度之后,会首先计算当前点所对应的LaserIdx,即图6B中的pointLaserIdx号,并且计算当前节点的LaserIdx,即nodeLaserIdx。其次会利用节点的LaserIdx即nodeLaserIdx来对点的LaserIdx即pointLaserIdx进行预测编码,其中节点或者点的LaserIdx的计算方式如下:After encoding all the precision of the directAxis coordinate direction, the LaserIdx corresponding to the current point, i.e. pointLaserIdx in Figure 6B, will be calculated first, and the LaserIdx of the current node, i.e. nodeLaserIdx, will be calculated. Then the LaserIdx of the node, i.e. nodeLaserIdx, will be used to predictively encode the LaserIdx of the point, i.e. pointLaserIdx. The calculation method of the LaserIdx of the node or point is as follows:
假设点的几何坐标为pointPos,激光射线的起始坐标为LidarOrigin,并且假设Laser的数目为LaserNum,每个Laser的正切值为tanθ
i,每个Laser在垂直方向上的偏移位置为Z
i,则:
Assume that the geometric coordinates of the point are pointPos, the starting coordinates of the laser ray are LidarOrigin, and the number of Lasers is LaserNum, the tangent value of each Laser is tanθ i , and the offset position of each Laser in the vertical direction is Zi , then:

在计算得到当前点的LaserIdx之后,首先会利用当前节点的LaserIdx对点的pointLaserIdx进行预测编码。在编码完当前点的LaserIdx之后,对当前点三个维度的几何信息利用激光雷达的采集参数进行预测编码。After calculating the LaserIdx of the current point, the LaserIdx of the current node is first used to predict the pointLaserIdx of the point. After encoding the LaserIdx of the current point, the three-dimensional geometric information of the current point is predictively encoded using the acquisition parameters of the laser radar.
具体算法如图6C所示,首先利用当前点对应的LaserIdx得到对应的水平方位角的预测值,即
 其次利用当前点对应的节点几何信息得到节点对应的水平方位角度
其次利用当前点对应的节点几何信息得到节点对应的水平方位角度
 其中,水平方位角
其中,水平方位角
 与节点几何信息之间的计算方式如公式(10)所示,假设节点的几何坐标为nodePos:
The specific algorithm is shown in FIG6C . First, the LaserIdx corresponding to the current point is used to obtain the corresponding predicted value of the horizontal azimuth angle, that is, Secondly, the node geometry information corresponding to the current point is used to obtain the horizontal azimuth angle corresponding to the node Among them, the horizontal azimuth The calculation method between the node geometry information is shown in formula (10), assuming that the geometry coordinates of the node are nodePos:
与节点几何信息之间的计算方式如公式(10)所示,假设节点的几何坐标为nodePos:
The specific algorithm is shown in FIG6C . First, the LaserIdx corresponding to the current point is used to obtain the corresponding predicted value of the horizontal azimuth angle, that is, Secondly, the node geometry information corresponding to the current point is used to obtain the horizontal azimuth angle corresponding to the node Among them, the horizontal azimuth The calculation method between the node geometry information is shown in formula (10), assuming that the geometry coordinates of the node are nodePos:
通过利用激光雷达的采集参数,可以得到每个Laser的旋转点数numPoints,即代表每个激光射线旋转一圈得到的点数,则可以利用每个Laser的旋转点数计算得到每个Laser的旋转角速度deltaPhi,如公式(11)所示:By using the acquisition parameters of the laser radar, the number of rotation points numPoints of each Laser can be obtained, which represents the number of points obtained when each laser ray rotates one circle. The rotation angular velocity deltaPhi of each Laser can then be calculated using the number of rotation points of each Laser, as shown in formula (11):
如图6D所示,利用节点的水平方位角
 以及当前点对应的Laser前一个编码点的水平方位角
以及当前点对应的Laser前一个编码点的水平方位角
 计算得到当前点对应的水平方位角预测值
计算得到当前点对应的水平方位角预测值
 具体计算公式如公式(12)所示:
As shown in FIG6D , using the horizontal azimuth angle of the node And the horizontal azimuth of the previous Laser code point corresponding to the current point Calculate the predicted horizontal azimuth angle corresponding to the current point The specific calculation formula is shown in formula (12):
具体计算公式如公式(12)所示:
As shown in FIG6D , using the horizontal azimuth angle of the node And the horizontal azimuth of the previous Laser code point corresponding to the current point Calculate the predicted horizontal azimuth angle corresponding to the current point The specific calculation formula is shown in formula (12):
最终,如图6E所示,通过利用水平方位角的预测值
 以及当前节点的低平面水平方位角
以及当前节点的低平面水平方位角
 和高平面的水平方位角
和高平面的水平方位角
 来对当前节点的几何信息进行预测编码。具体如下所示:
Finally, as shown in FIG6E , by using the predicted value of the horizontal azimuth and the low plane horizontal azimuth of the current node and the horizontal azimuth of the high plane To predict the geometric information of the current node. The details are as follows:
来对当前节点的几何信息进行预测编码。具体如下所示:
Finally, as shown in FIG6E , by using the predicted value of the horizontal azimuth and the low plane horizontal azimuth of the current node and the horizontal azimuth of the high plane To predict the geometric information of the current node. The details are as follows:

在编码完点的LaserIdx之后,会利用当前点所对应的LaserIdx对当前点的Z轴方向进行预测编码,即当前通过利用当前点的x和y信息计算得到柱面坐标系的深度信息radius,其次利用当前点的激光LaserIdx得到当前点的正切值以及垂直方向的便宜,则可以得到当前点的Z轴方向的预测值即Z_pred:After encoding the LaserIdx of the point, the LaserIdx corresponding to the current point will be used to predict the Z-axis direction of the current point. That is, the depth information radius of the cylindrical coordinate system is calculated by using the x and y information of the current point. Then, the tangent value of the current point and the vertical value are obtained by using the laser LaserIdx of the current point. Then, the predicted value of the Z-axis direction of the current point, namely Z_pred, can be obtained:
最终利用Z_pred对当前点的Z轴方向的几何信息进行预测编码得到预测残差Z_res,最终对Z_res进行编码。Finally, Z_pred is used to predict the geometric information of the current point in the Z-axis direction to obtain the prediction residual Z_res, and finally Z_res is encoded.
需要注意的是,在节点划分到叶子节点时,在几何无损编码的情况下,需要对叶子节点中的重复点数目进行编码。最终对所有节点的占位信息进行编码,生成二进制码流。另外G-PCC目前引入了一种平面编码模式,在对几何进行划分的过程中,会判断当前节点的子节点是否处于同一平面,如果当前节点的子节点满足同一平面的条件,会用该平面对当前节点的子节点进行表示。It should be noted that when nodes are divided into leaf nodes, in the case of geometric lossless coding, the number of repeated points in the leaf nodes needs to be encoded. Finally, the placeholder information of all nodes is encoded to generate a binary code stream. In addition, G-PCC currently introduces a plane coding mode. In the process of geometric division, it will determine whether the child nodes of the current node are in the same plane. If the child nodes of the current node meet the conditions of the same plane, the child nodes of the current node will be represented by the plane.
在基于八叉树的几何解码,解码端按照广度优先遍历的顺序,在对每个节点的占位信息解码之前,首先会利用已经重建得到的几何信息来判断当前节点是否进行平面解码或者IDCM解码,如果当前节点满足平面解码的条件,则会首先对当前节点的平面标识和平面位置信息进行解码,其次基于平面信息来对当前节点的占位信息进行解码;如果当前节点满足IDCM解码的条件,则会首先解码当前节点是否是一个真正的IDCM节点,如果是一个真正的IDCM解码,则会继续解析当前节点的DCM解码模式,其次可以得到当前DCM节点中的点数目,最后对每个点的几何信息进行解码。对于既不满足平面解码也不满足DCM解码的节点,会对当前节点的占位信息进行解码。通过按照这样的方式不断解析得到每个节点的占位码,并且依次不断划分节点,直至划分得到1X1X1的单位立方体时停止划分,解析得到每个叶子节点中包含的点数,最终恢复得到几何重构点云信息。In the octree-based geometric decoding, the decoding end follows the order of breadth-first traversal. Before decoding the placeholder information of each node, it will first use the reconstructed geometric information to determine whether the current node is to be plane decoded or IDCM decoded. If the current node meets the conditions for plane decoding, the plane identification and plane position information of the current node will be decoded first, and then the placeholder information of the current node will be decoded based on the plane information; if the current node meets the conditions for IDCM decoding, it will first decode whether the current node is a real IDCM node. If it is a real IDCM decoding, it will continue to parse the DCM decoding mode of the current node, and then the number of points in the current DCM node can be obtained, and finally the geometric information of each point will be decoded. For nodes that do not meet neither plane decoding nor DCM decoding, the placeholder information of the current node will be decoded. By continuously parsing in this way, the placeholder code of each node is obtained, and the nodes are continuously divided in turn until the division is stopped when the unit cube of 1X1X1 is obtained, the number of points contained in each leaf node is obtained by parsing, and finally the geometric reconstructed point cloud information is restored.
下面对IDCM解码的过程进行详细的介绍:The following is a detailed introduction to the IDCM decoding process:
与编码同样的处理,首先利用先验信息来决定节点是否启动IDCM,即IDCM的启动条件如下:The same process as encoding, first use the prior information to decide whether the node starts IDCM, that is, the starting conditions of IDCM are as follows:
(1)当前节点没有兄弟姐妹子节点,即当前节点的父节点只有一个孩子节点,同时当前节点父节点的父节点仅有两个被占据子节点,即当前节点最多只有一个邻居节点。(1) The current node has no sibling child nodes, that is, the parent node of the current node has only one child node, and the parent node of the parent node of the current node has only two occupied child nodes, that is, the current node has at most one neighbor node.
(2)当前节点的父节点仅有当前节点一个占据子节点,同时与当前节点共用一个面的六个邻居节点也都属于空节点。(2) The parent node of the current node has only one child node, the current node. At the same time, the six neighbor nodes that share a face with the current node are also empty nodes.
(3)当前节点的兄弟姐妹节点数目大于1。(3) The number of sibling nodes of the current node is greater than 1.
当节点满足DCM编码的条件时,首先解码当前节点是否是一个真正的DCM节点,即IDCM_flag,当IDCM_flag为true时,则当前节点采用DCM编码,否则仍然采用八叉树编码。When a node meets the conditions for DCM encoding, first decode whether the current node is a real DCM node, that is, IDCM_flag. When IDCM_flag is true, the current node adopts DCM encoding, otherwise it still adopts octree encoding.
其次解码当前节点的点数目numPoints,具体的解码方式如下所示:Secondly, decode the number of points numPoints of the current node. The specific decoding method is as follows:
1)、首先解码当前节点的numPonts是否大于1;1) First, decode whether the numPonts of the current node is greater than 1;
2)、如果解码得到当前节点的numPonts大于1,则继续解码第二个点是否是一个重复点,如果第二个点不是重复点,则这里可以隐性推断出满足DCM模式的第二种,只含有两个点;2) If the numPonts of the current node obtained by decoding is greater than 1, continue decoding to see if the second point is a duplicate point. If the second point is not a duplicate point, it can be implicitly inferred that the second type that satisfies the DCM mode contains only two points.
3)、如果解码得到当前节点的numPonts小于等于1,则继续解码第二个点是否是一个重复点,如果第二个点不是重复点,则这里可以隐性推断出满足DCM模式的第二种,只含有一个点;如果解码得到第二个点是一个重复点,则可以推断出满足DCM模式的第三种,含有多个点,但是都是重复点,则继续解码重复点的数目是否大于1(熵解码),如果大于1,则继续解码剩余重复点的数目(利用指数哥伦布进行解码)。3) If the numPonts of the current node obtained by decoding is less than or equal to 1, continue to decode whether the second point is a repeated point. If the second point is not a repeated point, it can be implicitly inferred that the second type that satisfies the DCM mode contains only one point; if the second point obtained by decoding is a repeated point, it can be inferred that the third type that satisfies the DCM mode contains multiple points, but they are all repeated points, then continue to decode whether the number of repeated points is greater than 1 (entropy decoding). If it is greater than 1, continue to decode the number of remaining repeated points (decoding using exponential Columbus).
如果当前节点不满足DCM节点的要求,即点数大于2个点,并且不是重复点,则直接退出。If the current node does not meet the requirements of the DCM node, that is, the number of points is greater than 2 points and it is not a duplicate point, exit directly.
在解码完当前节点的点数目之后,对当前节点中包含点的坐标信息进行解码。下面将分别对激光雷达点云和面向人眼点云分开介绍。After decoding the number of points in the current node, the coordinate information of the points contained in the current node is decoded. The following will introduce the lidar point cloud and the human eye point cloud separately.
面向人眼点云Point cloud for human eyes
1)、如果当前节点中仅仅只含有一个点,则会对点的三个维度方向的几何信息进行直接解码(Bypass coding);1) If the current node contains only one point, the geometric information of the point in three dimensions will be directly decoded (Bypass coding);
2)、如果当前节点中含有两个点,则会首先通过利用点的几何坐标得到优先解码的坐标轴dirextAxis,这里需要注意的是,目前比较的坐标轴只包含x和y轴,不包含z轴。假设当前节点的几何坐标为nodePos,则采用如公式(13)所示的方式,确定优先编码的坐标轴:2) If the current node contains two points, the priority decoding coordinate axis dirextAxis will be obtained by using the geometric coordinates of the points. It should be noted that the coordinate axes currently compared only include the x and y axes, not the z axis. Assuming that the geometric coordinates of the current node are nodePos, the method shown in formula (13) is used to determine the priority encoding coordinate axis:
dirextAxis=!(nodePos[0]<nodePos[1]) (13)dirextAxis=! (nodePos[0]<nodePos[1]) (13)
也就是说,将节点坐标几何位置小的轴作为优先解码的坐标轴dirextAxis。That is to say, the axis with the smaller node coordinate geometric position is used as the coordinate axis dirextAxis for priority decoding.
其次按照如下方式首先对优先解码的坐标轴dirextAxis几何信息进行解码,假设优先解码的轴对应的待解码几何bit深度为nodeSizeLog2,并假设两个点的坐标分别为pointPos[0]和pointPos[1]:Secondly, the geometry information of the dirextAxis coordinate axis to be decoded is first decoded as follows, assuming that the bit depth of the geometry to be decoded corresponding to the axis to be decoded is nodeSizeLog2, and assuming that the coordinates of the two points are pointPos[0] and pointPos[1] respectively:

在解码完优先解码轴dirextAxis之后,在对当前点的几何坐标进行直接解码。假设每个点的剩余编码bit深度为nodeSizeLog2,则具体解码过程如下,假设点的坐标信息为pointPos:After decoding the priority decoding axis dirextAxis, the geometric coordinates of the current point are directly decoded. Assuming that the remaining encoding bit depth of each point is nodeSizeLog2, the specific decoding process is as follows, assuming that the coordinate information of the point is pointPos:

面向激光雷达点云For LiDAR point clouds
1)、如果当前节点中含有两个点,则会首先通过利用点的几何坐标得到优先解码的坐标轴dirextAxis,假设当前节点的几何坐标为nodePos,则采用如公式(14)所示的方式,确定优先编码的坐标轴:1) If the current node contains two points, the priority decoding coordinate axis dirextAxis will be obtained by using the geometric coordinates of the points. Assuming that the geometric coordinates of the current node are nodePos, the priority encoding coordinate axis is determined by the method shown in formula (14):
dirextAxis=!(nodePos[0]<nodePos[1]) (14)dirextAxis=! (nodePos[0]<nodePos[1]) (14)
也就是说,将节点坐标几何位置小的轴作为优先解码的坐标轴dirextAxis,这里需要注意的是,目前比较的坐标轴只包含x和y轴,不包含z轴。That is to say, the axis with the smaller node coordinate geometric position is used as the coordinate axis dirextAxis for priority decoding. It should be noted here that the currently compared coordinate axes only include the x and y axes, but not the z axis.
其次按照如下方式首先对优先编码的坐标轴dirextAxis几何信息进行解码,假设优先解码的轴对应的待编码几何bit深度为nodeSizeLog2,并假设两个点的坐标分别为pointPos[0]和pointPos[1]:Secondly, the geometry information of the dirextAxis coordinate axis that is encoded first is decoded as follows, assuming that the bit depth of the geometry to be encoded corresponding to the axis that is decoded first is nodeSizeLog2, and assuming that the coordinates of the two points are pointPos[0] and pointPos[1] respectively:

在解码完优先解码轴dirextAxis之后,再对当前点的几何坐标进行解码。After decoding the priority decoding axis dirextAxis, the geometric coordinates of the current point are decoded.
同样的,首先利用当前节点的几何信息nodePos得到一个直接解码的主轴方向,其次利用已经完成解码的方向的几何信息来对另外一个维度的几何信息进行解码。同样假设直接解码的轴方向是directAxis,并且假设直接解码中的待解码bit深度为nodeSizeLog2,则解码方式如下:Similarly, first use the current node's geometry information nodePos to get a direct decoding main axis direction, and then use the geometry information of the decoded direction to decode the geometry information of another dimension. Also assuming that the axis direction of direct decoding is directAxis, and assuming that the bit depth to be decoded in direct decoding is nodeSizeLog2, the decoding method is as follows:

这里需要注意的是,在这里会将directAxis方向的几何精度信息全部解码。It should be noted here that all geometric accuracy information in the directAxis direction will be decoded here.
在解码完directAxis坐标方向的所有精度之后,会首先计算当前节点的LaserIdx,即nodeLaserIdx,其次会利用节点的LaserIdx即nodeLaserIdx来对点的LaserIdx即pointLaserIdx进行预测解码,其中节点或者点的LaserIdx的计算方式跟编码端相同。最终对当前点的LaserIdx与节点的LaserIdx预测残差信息进行解码得到ResLaserIdx,则计算公式如公式15所示:After decoding all the precisions of the directAxis coordinate direction, the LaserIdx of the current node, i.e., nodeLaserIdx, is calculated first. Then, the LaserIdx of the node, i.e., nodeLaserIdx, is used to predict and decode the LaserIdx of the point, i.e., pointLaserIdx. The calculation method of the LaserIdx of the node or point is the same as that of the encoder. Finally, the LaserIdx of the current point and the predicted residual information of the LaserIdx of the node are decoded to obtain ResLaserIdx. The calculation formula is shown in Formula 15:
PointLaserIdx=nodeLaserIdx+ResLaserIdx (15)PointLaserIdx=nodeLaserIdx+ResLaserIdx (15)
在解码完当前点的LaserIdx之后,对当前点三个维度的几何信息利用激光雷达的采集参数进行预测解码。After decoding the LaserIdx of the current point, the three-dimensional geometric information of the current point is predicted and decoded using the acquisition parameters of the laser radar.
具体的,如图6B所示,首先利用当前点对应的LaserIdx得到对应的水平方位角的预测值,即
 其次利用当前点对应的节点几何信息得到节点对应的水平方位角度
其次利用当前点对应的节点几何信息得到节点对应的水平方位角度
 其中,假设节点的几何坐标为nodePos,水平方位角
其中,假设节点的几何坐标为nodePos,水平方位角
 与节点几何信息之间的计算方式如公式(16)所示:
Specifically, as shown in FIG6B , the LaserIdx corresponding to the current point is first used to obtain the corresponding predicted value of the horizontal azimuth, that is, Secondly, the node geometry information corresponding to the current point is used to obtain the horizontal azimuth angle corresponding to the node Among them, it is assumed that the geometric coordinates of the node are nodePos, and the horizontal azimuth is The calculation method between the node geometry information is shown in formula (16):
与节点几何信息之间的计算方式如公式(16)所示:
Specifically, as shown in FIG6B , the LaserIdx corresponding to the current point is first used to obtain the corresponding predicted value of the horizontal azimuth, that is, Secondly, the node geometry information corresponding to the current point is used to obtain the horizontal azimuth angle corresponding to the node Among them, it is assumed that the geometric coordinates of the node are nodePos, and the horizontal azimuth is The calculation method between the node geometry information is shown in formula (16):
通过利用激光雷达的采集参数,可以得到每个Laser的旋转点数numPoints,即代表每个激光射线旋转一圈得到的点数,则可以利用每个Laser的旋转点数计算得到每个Laser的旋转角速度deltaPhi,如公式(17)所示:By using the acquisition parameters of the laser radar, the number of rotation points numPoints of each Laser can be obtained, which represents the number of points obtained when each laser ray rotates one circle. The rotation angular velocity deltaPhi of each Laser can then be calculated using the number of rotation points of each Laser, as shown in formula (17):
接着,如图6D所示,利用节点的水平方位角
 以及当前点对应的Laser前一个编码点的水平方位角
以及当前点对应的Laser前一个编码点的水平方位角
 计算得到当前点对应的水平方位角预测值
计算得到当前点对应的水平方位角预测值
 水平方位角的预测值。计算方式如公式(18)所示:
Next, as shown in FIG6D , the horizontal azimuth angle of the node is used And the horizontal azimuth of the previous Laser code point corresponding to the current point Calculate the predicted horizontal azimuth angle corresponding to the current point The predicted value of the horizontal azimuth angle. The calculation method is shown in formula (18):
水平方位角的预测值。计算方式如公式(18)所示:
Next, as shown in FIG6D , the horizontal azimuth angle of the node is used And the horizontal azimuth of the previous Laser code point corresponding to the current point Calculate the predicted horizontal azimuth angle corresponding to the current point The predicted value of the horizontal azimuth angle. The calculation method is shown in formula (18):
最终通过利用水平方位角的预测值
 以及当前节点的低平面水平方位角
以及当前节点的低平面水平方位角
 和高平面的水平方位角
和高平面的水平方位角
 来 对当前节点的几何信息进行预测编码。具体如下所示:
Finally, by using the predicted value of the horizontal azimuth and the low plane horizontal azimuth of the current node and the horizontal azimuth of the high plane To predict the geometric information of the current node. The details are as follows:
来 对当前节点的几何信息进行预测编码。具体如下所示:
Finally, by using the predicted value of the horizontal azimuth and the low plane horizontal azimuth of the current node and the horizontal azimuth of the high plane To predict the geometric information of the current node. The details are as follows:

在解码完点的LaserIdx之后,会利用当前点所对应的LaserIdx对当前点的Z轴方向进行预测解码,即当前通过利用当前点的x和y信息计算得到柱面坐标系的深度信息radius,其次利用当前点的激光LaserIdx得到当前点的正切值以及垂直方向的偏移量,则可以得到当前点的Z轴方向的预测值即Z_pred:After decoding the LaserIdx of the point, the Z-axis direction of the current point will be predicted and decoded using the LaserIdx corresponding to the current point. That is, the depth information radius of the cylindrical coordinate system is calculated by using the x and y information of the current point. Then, the tangent value of the current point and the vertical offset are obtained using the laser LaserIdx of the current point. Then, the predicted value of the Z-axis direction of the current point, namely Z_pred, can be obtained:

最终利用解码得到的Z_res和Z_pred来重建恢复得到当前点Z轴方向的几何信息。Finally, the decoded Z_res and Z_pred are used to reconstruct and restore the geometric information of the current point in the Z-axis direction.
在基于trisoup(triangle soup,三角面片集)的几何信息编码框架中,同样也要先进行几何划分,但区别于基于二叉树/四叉树/八叉树的几何信息编码,该方法不需要将点云逐级划分到边长为1x1x1的单位立方体,而是划分到block(子块)边长为W时停止划分,基于每个block中点云的分布所形成的表面,得到该表面与block的十二条边所产生的至多十二个vertex(交点)。依次编码每个block的vertex坐标,生成二进制码流。In the geometric information coding framework based on trisoup (triangle soup, triangle patch set), geometric division must also be performed first, but different from the geometric information coding based on binary tree/quadtree/octree, this method does not need to divide the point cloud into unit cubes with a side length of 1x1x1 step by step, but stops dividing when the block (sub-block) has a side length of W. Based on the surface formed by the distribution of the point cloud in each block, at most twelve vertices (intersection points) generated by the surface and the twelve edges of the block are obtained. The vertex coordinates of each block are encoded in turn to generate a binary code stream.
基于trisoup的点云几何信息重建,在解码端进行点云几何信息重建时,首先解码vertex坐标用于完成三角面片重建,该过程如图7A至图7C所示。图7A所示的block中存在3个vertex(v1,v2,v3),利用这3个vertex按照一定顺序所构成的三角面片集被称为triangle soup,即trisoup,如图7B所示。之后,在该三角面片集上进行采样,将得到的采样点作为该block内的重建点云,如图7C所示。When reconstructing the geometric information of the point cloud based on trisoup, the vertex coordinates are first decoded to complete the reconstruction of the triangle facets at the decoding end. The process is shown in Figures 7A to 7C. There are three vertices (v1, v2, v3) in the block shown in Figure 7A. The triangle facet set formed by these three vertices in a certain order is called triangle soup, i.e., trisoup, as shown in Figure 7B. After that, sampling is performed on the triangle facet set, and the obtained sampling points are used as the reconstructed point cloud in the block, as shown in Figure 7C.
基于预测树的几何编码包括:首先对输入点云进行排序,目前采用的排序方法包括无序、莫顿序、方位角序和径向距离序。在编码端通过利用两种不同的方式建立预测树结构,其中包括:KD-Tree(高时延慢速模式)和利用激光雷达标定信息,将每个点划分到不同的Laser上,按照不同的Laser建立预测结构(低时延快速模式)。接下来基于预测树的结构,遍历预测树中的每个节点,通过选取不同的预测模式对节点的几何位置信息进行预测得到预测残差,并且利用量化参数对几何预测残差进行量化。最终通过不断迭代,对预测树节点位置信息的预测残差、预测树结构以及量化参数等进行编码,生成二进制码流。The geometric coding based on the prediction tree includes: first, sorting the input point cloud. The currently used sorting methods include unordered, Morton order, azimuth order and radial distance order. At the encoding end, the prediction tree structure is established by using two different methods, including: KD-Tree (high-latency slow mode) and using the laser radar calibration information to divide each point into different Lasers, and establish a prediction structure according to different Lasers (low-latency fast mode). Next, based on the structure of the prediction tree, traverse each node in the prediction tree, predict the geometric position information of the node by selecting different prediction modes to obtain the prediction residual, and quantize the geometric prediction residual using the quantization parameter. Finally, through continuous iteration, the prediction residual of the prediction tree node position information, the prediction tree structure and the quantization parameters are encoded to generate a binary code stream.
基于预测树的几何解码,解码端通过不断解析码流,重构预测树结构,其次通过解析得到每个预测节点的几何位置预测残差信息以及量化参数,并且对预测残差进行反量化,恢复得到每个节点的重构几何位置信息,最终完成解码端的几何重构。Based on the geometric decoding of the prediction tree, the decoding end reconstructs the prediction tree structure by continuously parsing the bit stream, and then obtains the geometric position prediction residual information and quantization parameters of each prediction node through parsing, and dequantizes the prediction residual to recover the reconstructed geometric position information of each node, and finally completes the geometric reconstruction of the decoding end.
几何编码完成后,对几何信息进行重建。目前,属性编码主要针对颜色信息进行。首先,将颜色信息从RGB颜色空间转换到YUV颜色空间。然后,利用重建的几何信息对点云重新着色,使得未编码的属性信息与重建的几何信息对应起来。在颜色信息编码中,主要有两种变换方法,一是依赖于LOD(Level of Detail,细节层次)划分的基于距离的提升变换,二是直接进行RAHT(Region Adaptive Hierarchal Transform,区域自适应分层变换)变换,这两种方法都会将颜色信息从空间域转换到频域,通过变换得到高频系数和低频系数,最后对系数进行量化并编码,生成二进制码流。After the geometric encoding is completed, the geometric information is reconstructed. At present, attribute encoding is mainly performed on color information. First, the color information is converted from the RGB color space to the YUV color space. Then, the point cloud is recolored using the reconstructed geometric information so that the unencoded attribute information corresponds to the reconstructed geometric information. In color information encoding, there are two main transformation methods. One is the distance-based lifting transformation that relies on LOD (Level of Detail) division, and the other is to directly perform RAHT (Region Adaptive Hierarchal Transform) transformation. Both methods will convert color information from the spatial domain to the frequency domain, obtain high-frequency coefficients and low-frequency coefficients through transformation, and finally quantize and encode the coefficients to generate a binary code stream.
在利用几何信息来对属性信息进行预测时,可以利用莫顿码进行最近邻居搜索,点云中每点对应的莫顿码可以由该点的几何坐标得到。计算莫顿码的具体方法描述如下所示,对于每一个分量用d比特二进制数表示的三维坐标,其三个分量可以表示为公式(19):When using geometric information to predict attribute information, Morton codes can be used to search for nearest neighbors. The Morton code corresponding to each point in the point cloud can be obtained from the geometric coordinates of the point. The specific method for calculating the Morton code is described as follows. For each component of the three-dimensional coordinate represented by a d-bit binary number, its three components can be expressed as formula (19):
其中,
 分别是x,y,z的最高位
分别是x,y,z的最高位
 到最低位
到最低位
 对应的二进制数值。莫顿码M是对x,y,z从最高位开始,依次交叉排列
对应的二进制数值。莫顿码M是对x,y,z从最高位开始,依次交叉排列
 到最低位,M的计算公式如下公式(20)所示:
in, The highest bits of x, y, and z are To the lowest position The corresponding binary value. The Morton code M is x, y, z, starting from the highest bit, arranged in sequence To the lowest bit, the calculation formula of M is shown in the following formula (20):
到最低位,M的计算公式如下公式(20)所示:
in, The highest bits of x, y, and z are To the lowest position The corresponding binary value. The Morton code M is x, y, z, starting from the highest bit, arranged in sequence To the lowest bit, the calculation formula of M is shown in the following formula (20):
其中,
 分别是M的最高位
分别是M的最高位
 到最低位
到最低位
 的值。在得到点云中每个点的莫顿码M后,将点云中的点按莫顿码由小到大的顺序进行排列,并将每个点的权值w设为1。
in, The highest bit of M To the lowest position After obtaining the Morton code M of each point in the point cloud, the points in the point cloud are arranged in order from small to large Morton codes, and the weight w of each point is set to 1.
的值。在得到点云中每个点的莫顿码M后,将点云中的点按莫顿码由小到大的顺序进行排列,并将每个点的权值w设为1。
in, The highest bit of M To the lowest position After obtaining the Morton code M of each point in the point cloud, the points in the point cloud are arranged in order from small to large Morton codes, and the weight w of each point is set to 1.
GPCC的通用测试条件共4种:There are 4 general test conditions for GPCC:
条件1:几何位置有限度有损、属性有损;Condition 1: The geometric position is limitedly lossy and the attributes are lossy;
条件2:几何位置无损、属性有损;Condition 2: The geometric position is lossless, but the attributes are lossy;
条件3:几何位置无损、属性有限度有损;Condition 3: The geometric position is lossless, and the attributes are limitedly lossy;
条件4:几何位置无损、属性无损。Condition 4: The geometric position and attributes are lossless.
通用测试序列包括Cat1A,Cat1B,Cat3-fused,Cat3-frame共四类,其中Cat2-frame点云只包含反射率属性信息,Cat1A、Cat1B点云只包含颜色属性信息,Cat3-fused点云同时包含颜色和反射率属性信息。The general test sequences include Cat1A, Cat1B, Cat3-fused, and Cat3-frame. The Cat2-frame point cloud only contains reflectance attribute information, the Cat1A and Cat1B point clouds only contain color attribute information, and the Cat3-fused point cloud contains both color and reflectance attribute information.
GPCC的技术路线共2种,以几何压缩所采用的算法进行区分,分为八叉树编码分支和预测树编码分支。There are two technical routes of GPCC, which are distinguished by the algorithm used for geometric compression, and are divided into octree coding branch and prediction tree coding branch.
其中,八叉树编码分支中,在编码端,将包围盒依次划分得到子立方体,对非空的(包含点云中的点)的子立方体继续进行划分,直到划分得到的叶子结点为1X1X1的单位立方体时停止划分,在几何无损编码情况下,需要对叶子节点中所包含的点数进行编码,最终完成几何八叉树的编码,生成二进制码流。在解码端,解码端按照广度优先遍历的顺序,通过不断解析得到每个节点的占位码,并且依次不断划分节点,直至划分得到1x1x1的单位立方体时停止划分,在几何无损解码的情况下,需要解析得到每个叶子节点中包含的点数,最终恢复得到几何重构点云信息。Among them, in the octree coding branch, at the encoding end, the bounding box is divided into sub-cubes in sequence, and the non-empty (containing points in the point cloud) sub-cubes are continued to be divided until the leaf node obtained by division is a 1X1X1 unit cube. In the case of geometric lossless coding, it is necessary to encode the number of points contained in the leaf node, and finally complete the encoding of the geometric octree to generate a binary code stream. At the decoding end, the decoding end obtains the placeholder code of each node by continuous parsing in the order of breadth-first traversal, and continuously divides the nodes in sequence until the division is a 1x1x1 unit cube. In the case of geometric lossless decoding, it is necessary to parse the number of points contained in each leaf node, and finally restore the geometric reconstructed point cloud information.
预测树编码分支中,在编码端通过利用两种不同的方式建立预测树结构,其中包括:KD-Tree(高时延慢速模式)和利用激光雷达标定信息,将每个点划分到不同的Laser上,按照不同的Laser建立预测结构(低时延快速模式)。接下来基于预测树的结构,遍历预测树中的每个节点,通过选取不同的预测模式对节点的几何位置信息进行预测得到预测残差,并且利用量化参数对几何预测残差进行量化。最终通过不断迭代,对预测树节点位置信息的预测残差、预测树结构以及量化参数等进行编码,生成二进制码流。在解码端,解码端通过不断解析码流,重构预测树结构,其次通过解析得到每个预测节点的几何位置预测残差信息以及量化参数,并且对预测残差进行反量化,恢复得到每个节点的重构几何位置信息,最终完成解码端的几何重构。In the prediction tree coding branch, the prediction tree structure is established at the encoding end by using two different methods, including: KD-Tree (high-latency slow mode) and using the laser radar calibration information to divide each point into different lasers and establish a prediction structure according to different lasers (low-latency fast mode). Next, based on the structure of the prediction tree, each node in the prediction tree is traversed, and the geometric position information of the node is predicted by selecting different prediction modes to obtain the prediction residual, and the geometric prediction residual is quantized using the quantization parameter. Finally, through continuous iteration, the prediction residual of the prediction tree node position information, the prediction tree structure, and the quantization parameters are encoded to generate a binary code stream. At the decoding end, the decoding end reconstructs the prediction tree structure by continuously parsing the code stream, and then obtains the geometric position prediction residual information and quantization parameters of each prediction node through parsing, and dequantizes the prediction residual to restore the reconstructed geometric position information of each node, and finally completes the geometric reconstruction of the decoding end.
下面对AVS编解码框架进行介绍。The AVS encoding and decoding framework is introduced below.
在点云AVS编码器框架中,点云的几何信息和每点所对应的属性信息是分开编码的。In the point cloud AVS encoder framework, the geometric information of the point cloud and the attribute information corresponding to each point are encoded separately.
图8A为AVS的编码框架示意图,图8B为AVS的解码框架示意图。如图8A所示,首先对几何信息进行坐标转换,使点云全都包含在一个bounding box(包围盒)中。在预处理过程之前,会根据参数配置来决定是否要将整个点云序列划分成多个slice(点云片),对于每个划分的slice将其视为单个独立点云串行处理。预处理过程包含量化和移除重复点。量化主要起到缩放的作用,由于量化取整,使得一部分点的几何信息相同,根据参数来决定是否移除重复点。接下来,按照广度优先遍历的顺序对bounding box进行划分(八叉树/四叉树/二叉树),对每个节点的占位码进行编码。FIG8A is a schematic diagram of the encoding framework of AVS, and FIG8B is a schematic diagram of the decoding framework of AVS. As shown in FIG8A, the geometric information is firstly transformed into coordinates so that all point clouds are contained in a bounding box. Before the preprocessing process, it is determined whether to divide the entire point cloud sequence into multiple slices according to the parameter configuration, and each divided slice is treated as a single independent point cloud serial processing. The preprocessing process includes quantization and removal of duplicate points. Quantization mainly plays a role in scaling. Due to the quantization rounding, the geometric information of some points is the same, and whether to remove duplicate points is determined according to the parameters. Next, the bounding box is divided in the order of breadth-first traversal (octree/quadtree/binary tree), and the placeholder code of each node is encoded.
如图8B所示,在基于八叉树的几何编码框架中,将包围盒依次划分得到子立方体,对非空的(包含点云中的点)的子立方体继续进行划分,直到划分得到的叶子结点为1x1x1的单位立方体时停止划分,其次在几何无损编码的情况下,对叶子节点中所包含的点数进行编码,最终完成几何八叉树的编码,生成二进制码流。在基于八叉树的几何解码过程中,解码端按照广度优先遍历的顺序,通过不断解析得到每个节点的占位码,并且依次不断划分节点,直至划分得到1x1x1的单位立方体时停止划分,解析得到每个叶子节点中包含的点数,最终恢复得到几何重构点云信息。As shown in FIG8B , in the octree-based geometric coding framework, the bounding box is divided into sub-cubes in sequence, and the non-empty (containing points in the point cloud) sub-cubes are divided until the leaf nodes obtained by the division are 1x1x1 unit cubes, and then the division is stopped. Then, in the case of geometric lossless coding, the number of points contained in the leaf nodes is encoded, and finally the encoding of the geometric octree is completed to generate a binary code stream. In the octree-based geometric decoding process, the decoding end obtains the placeholder code of each node by continuously parsing in the order of breadth-first traversal, and continuously divides the nodes in sequence until the division is stopped when the 1x1x1 unit cube is obtained, and the number of points contained in each leaf node is parsed to finally restore the geometric reconstructed point cloud information.
目前的AVS几何编码中,存在两种编码方式,一种是八叉树编码,另外一种是预测树编码。There are two encoding methods in the current AVS geometric coding, one is octree coding and the other is prediction tree coding.
八叉树编码:如果采用八叉树编码,则存在两种上下文编码模型,上下文模型一用于cat1-A和cat2点云序列;上下文模型二用于cat1-B和cat3序列。Octree coding: If octree coding is used, there are two context coding models. Context model one is used for cat1-A and cat2 point cloud sequences; context model two is used for cat1-B and cat3 sequences.
下面对下文模型一进行介绍。The following is an introduction to Model 1.
下文模型一包括当前点的子层邻居预测以及当前点层的邻居预测。 Model 1 below includes the sub-layer neighbor prediction of the current point and the neighbor prediction of the current point layer.
1)当前点的子层邻居预测1) Sub-layer neighbor prediction of the current point
在八叉树广度优先遍历的划分方式下,编码当前点的子节点时能够获得的邻居信息包括左前下三个方向的邻居子节点。子节点层的上下文模型设计如下:对于待编码子节点层,查找与待编码子节点同层的左前下方向3个共面、3个共线、1个共点节点以及节点边长最短的维度上负方向距离当前待编码子节点两个节点边长处的节点的占位情况。以X维度上的节点边长最短为例,各子节点选择的参考节点如图9A所示。其中虚线框节点为当前节点,灰色节点为当前待编码子节点,实线框节点为各子节点选取的参考节点。Under the octree breadth-first traversal division method, the neighbor information that can be obtained when encoding the child node of the current point includes the neighbor child nodes in the three directions of left, front and bottom. The context model of the child node layer is designed as follows: For the child node layer to be encoded, find the occupancy of the three coplanar, three colinear, and one co-point nodes in the left, front and bottom direction of the same layer as the child node to be encoded, and the node in the negative direction of the dimension with the shortest node side length, which is two node side lengths away from the current child node to be encoded. Taking the node with the shortest side length in the X dimension as an example, the reference node selected by each child node is shown in Figure 9A. The dotted box node is the current node, the gray node is the current child node to be encoded, and the solid box node is the reference node selected by each child node.
其中3个共面、3个共线节点以及节点边长最短的维度上负方向距离当前待编码子节点两个节点边长处的节点的占位情况详细考虑,这7个节点的占位情况共有2
7=128种情况。如果不全为不占据,则共有2
7-1=127种情况,为每种情况分配1个上下文;若这7个节点全为不占据,则考虑共点邻居节点占位情况。该共点邻居有2种可能:占据或不占据。为该共点邻居节点被占据的情况单独分配1个上下文,若该共点邻居也为不占据,则考虑接下来要讲述的当前节点层邻居的占位情况。即待编码子节点层邻居一共对应127+2-1=128个上下文。
Among them, the occupancy of the 3 coplanar nodes, 3 colinear nodes, and the node at the negative direction of the dimension with the shortest node side length and two node side lengths away from the current sub-node to be encoded is considered in detail. There are 2 7 = 128 cases for the occupancy of these 7 nodes. If not all are unoccupied, there are 2 7 -1 = 127 cases, and 1 context is assigned to each case; if all of these 7 nodes are unoccupied, the occupancy of the common neighbor nodes is considered. There are 2 possibilities for the common neighbor: occupied or unoccupied. A separate context is assigned to the case where the common neighbor node is occupied. If the common neighbor is also unoccupied, the occupancy of the neighbors at the current node layer to be described next is considered. That is, the neighbors at the sub-node layer to be encoded correspond to a total of 127 + 2-1 = 128 contexts.
2)当前节点层的邻居预测2) Neighbor prediction of the current node layer
如果待编码子节点的8个同层参考节点都未被占据,则考虑如图9B所示的当前节点层的四组邻居的占位情况。其中虚线框节点为当前节点,实线边框为邻居节点。If the eight reference nodes in the same layer of the subnode to be encoded are not occupied, the occupancy of the four groups of neighbors in the current node layer as shown in Figure 9B is considered, where the dotted frame node is the current node and the solid frame node is the neighbor node.
对于当前节点层,按照以下步骤确定上下文:For the current node layer, the context is determined as follows:
1.首先考虑当前节点的右上后3个共面邻居。当前节点右上后共面的3个邻居的占位情况共有2
3=8种可能,为不全为不占据的情况各分配一个上下文,再考虑待编码子节点位于当前节点的位置,则该组邻居节点共提供(8-1)×8=56个上下文。如果当前点的右上后3个共面的邻居都不占据,那么继续考虑当前节点层其余三组邻居
1. First consider the three coplanar neighbors to the upper right of the current node. There are 2 3 = 8 possible occupancy situations of the three coplanar neighbors to the upper right of the current node. For the cases where all of them are not occupied, a context is assigned to each. Considering that the child node to be encoded is located at the position of the current node, this group of neighbor nodes provides a total of (8-1) × 8 = 56 contexts. If the three coplanar neighbors to the upper right of the current point are not occupied, then continue to consider the remaining three groups of neighbors at the current node layer.
2.考虑最近被占据的节点与当前节点的距离。2. Consider the distance between the most recently occupied node and the current node.
具体的邻居节点分布与距离的对应关系如表2所示。The specific correspondence between neighbor node distribution and distance is shown in Table 2.
表2 当前节点层占位情况与距离的对应关系Table 2 Correspondence between the current node layer occupancy and distance
| 当前节点层占位情况Current node layer occupancy | 距离distance |
| 左前下共面邻居占据或右上后共线邻居占据The left front and bottom coplanar neighbors occupy or the right top and back colinear neighbors occupy | 11 |
| 左前下共面邻居、右上后共线邻居都不占据且左前下共线邻居占据The left front and bottom coplanar neighbors and the right top and back collinear neighbors are not occupied, and the left front and bottom collinear neighbors are occupied | 22 |
| 当前节点层的四组邻居都不占据None of the four neighbor groups at the current node level are occupied | 33 |
由表2可得,距离共有3个取值。为这3个取值情况各分配1个上下文,再考虑待编码子节点位于当前节点的位置情况,共3×8=24个上下文。From Table 2, we can see that the distance has 3 values. One context is assigned to each of the 3 values, and considering the position of the sub-node to be encoded at the current node, there are 3×8=24 contexts in total.
至此,本套上下文模型总共分配了128+56+24=208个上下文。So far, this set of context models has allocated a total of 128+56+24=208 contexts.
下面对上下文模型二进行介绍。The following is an introduction to context model 2.
该方法使用双层上下文参考关系配置,如式(21)所示,第一层是与当前待编码子块父节点已编码相邻块的占用情况(即ctxIdxParent),第二层是与当前待编码子块同一深度下的相邻已编码块的占用情况(即ctxIdxChild)。This method uses a two-layer context reference relationship configuration, as shown in formula (21), the first layer is the occupancy of the encoded adjacent blocks of the parent node of the current sub-block to be encoded (i.e., ctxIdxParent), and the second layer is the occupancy of the adjacent encoded blocks at the same depth as the current sub-block to be encoded (i.e., ctxIdxChild).
首先,对于每一个待编码子块,第二层的ctxIdxChild如式(22)所示,C
i
1表示与当前子块
 距离为1的3个已编码子块的占用情况。
First, for each sub-block to be encoded, the ctxIdxChild of the second layer is as shown in formula (22), where Ci1 represents the sub-block with the current sub-block. Occupancy of the three coded sub-blocks with a distance of 1.
距离为1的3个已编码子块的占用情况。
First, for each sub-block to be encoded, the ctxIdxChild of the second layer is as shown in formula (22), where Ci1 represents the sub-block with the current sub-block. Occupancy of the three coded sub-blocks with a distance of 1.
idx=LUT[ctxIdxParent][ctxIdxChild] (21)idx=LUT[ctxIdxParent][ctxIdxChild] (21)
其次,第一层的ctxIdxParent,对于不同子块的相对位置,通过查表方式寻找与其共面和共线的相邻父块,并通过其占用情况根据式(23)计算得到ctxIdxParent。图9C为子块分别对应6个相邻父块的示意图,如图9C所示,每个子图显示了第i个子块找到的6个相邻父块的相对位置关系,其中包含3个共面父块(P
i,0,P
i,1,P
i,2)和3个共线父块(P
i,3,P
i,4,P
i,5)。每个子块和相邻父块位置关系通过表2方式获取,表2中的数字对应图6中的莫顿序号,该方式考虑了不同子块位置以及几何上的中心旋转对称性。图9D为当前待编码块利用到的周围18个相邻块及其莫顿序编号示意图,从图9D可以看出,以当前块为中心,该方法拥有更大的感受野,可以利用周围已编码的最多18个相邻父块。式(3)中采用的方式是3个共面父块占用情况的排列组合以及3个共线父块占用的个数加和。
Secondly, for the first layer ctxIdxParent, for the relative positions of different sub-blocks, the adjacent parent blocks that are coplanar and colinear with them are found by table lookup, and the ctxIdxParent is calculated according to the occupancy status according to formula (23). Figure 9C is a schematic diagram of sub-blocks corresponding to 6 adjacent parent blocks. As shown in Figure 9C, each sub-graph shows the relative position relationship of the 6 adjacent parent blocks found by the i-th sub-block, including 3 coplanar parent blocks (P i,0 ,P i,1 ,P i,2 ) and 3 colinear parent blocks (P i,3 ,P i,4 ,P i,5 ). The position relationship between each sub-block and the adjacent parent block is obtained by Table 2. The numbers in Table 2 correspond to the Morton numbers in Figure 6. This method takes into account the different sub-block positions and the geometric center rotation symmetry. FIG9D is a schematic diagram of the 18 neighboring blocks and their Morton sequence numbers used by the current block to be encoded. It can be seen from FIG9D that, with the current block as the center, this method has a larger receptive field and can use up to 18 neighboring parent blocks that have been encoded around it. The method used in formula (3) is the combination of the occupancy of the three coplanar parent blocks and the sum of the number of occupancy of the three colinear parent blocks.
因此,该方法中使用的上下文数量最多为2
3×2
5=256个。
Therefore, the number of contexts used in this method is at most 2 3 ×2 5 =256.
表3 为子块i和其相邻父块j的关系,表格中的数字对应图9D中的莫顿序编号。Table 3 shows the relationship between child block i and its adjacent parent block j. The numbers in the table correspond to the Morton sequence numbers in Figure 9D.
表3table 3

预测树编码:如果采用预测树编码,首先在编码端利用点云的几何信息进行莫顿码排序,其次利用KD-Tree对点云的几何信息进行预测编码,类似一个单链结构通过利用父节点来对子节点的几何信息进行预测编码。如图9E所示,预测树采用单链结构:除了唯一的叶节点外,每个树节点只有一个子节点。除了根节点由缺省值预测外,其他节点由其父节点提供几何预测值。Prediction tree coding: If prediction tree coding is used, first, the geometric information of the point cloud is used at the encoding end to perform Morton code sorting, and then the geometric information of the point cloud is predicted and encoded using KD-Tree, which is similar to a single chain structure that predicts and encodes the geometric information of the child node by using the parent node. As shown in Figure 9E, the prediction tree adopts a single chain structure: except for the only leaf node, each tree node has only one child node. Except for the root node, which is predicted by the default value, other nodes are provided with geometric prediction values by their parent nodes.
在进行多叉树几何编码过程中,当当前块同时满足下列三个条件时生效孤立点直接编码模式:During the multitree geometry coding process, the isolated point direct coding mode is effective when the current block satisfies the following three conditions at the same time:
1.几何头信息中孤立点直接编码模式标识符为1;1. The isolated point direct coding mode identifier in the geometry header information is 1;
2.当前块内仅含有一个点云数据点;2. The current block contains only one point cloud data point;
3.当前块内的点的待编码莫顿码位数之和大于未到达最小边长方向的数目的二倍。3. The sum of the number of Morton code bits to be encoded for the points in the current block is greater than twice the number of directions that have not reached the minimum side length.
当上述三个条件均成立时进入该分支。引入一个flag标识位表示当前节点是否使用孤立点编码模式,该flag使用一个context进行熵编码。如果flag为True,则使用孤立点模式,直接编码该点的几何坐标,同时结束八叉树划分。如果flag为False,则编码占用码,并继续八叉树划分。This branch is entered when all three conditions above are met. A flag is introduced to indicate whether the current node uses the isolated point coding mode. The flag uses a context for entropy coding. If the flag is True, the isolated point mode is used to directly encode the geometric coordinates of the point, and the octree division is terminated. If the flag is False, the occupancy code is encoded and the octree division continues.
在特定情况下,该flag可以推断为False而不用编码。如果当前块的父块已经可以允许使用孤立点编码模式,并且当前块是父块的唯一个子节点,那么当前块中一定不包含孤立点。因此,在这种条件下可以省去编码flag的比特。In certain cases, this flag can be inferred to be False and not encoded. If the parent block of the current block already allows the use of isolated point coding mode, and the current block is the only child node of the parent block, then the current block must not contain isolated points. Therefore, under this condition, the bits for encoding the flag can be omitted.
在编码了flag标识位之后,由于当前块内仅含有一个点云点,则直接编码该点云点几何坐标对应莫顿码的未编码的比特。具体的编码过程如下:After encoding the flag bit, since the current block contains only one point cloud point, the uncoded bits of the Morton code corresponding to the geometric coordinates of the point cloud point are directly encoded. The specific encoding process is as follows:
假设点的剩余编码bit深度为nodeSizeLog2,则具体编码过程如下:Assuming that the remaining encoding bit depth of the point is nodeSizeLog2, the specific encoding process is as follows:
for(int axisIdx=0;axisIdx<3;++axisIdx)for(int axisIdx=0;axisIdx<3;++axisIdx)
for(int mask=(1<<nodeSizeLog2[axisIdx])>>1;mask;mask>>1)for(int mask=(1<<nodeSizeLog2[axisIdx])>>1;mask;mask>>1)
encodePosBit(!!(pointPos[axisIdx]&mask));encodePosBit(!!(pointPos[axisIdx]&mask));
几何编码完成后,对几何信息进行重建。目前,属性编码主要针对颜色、反射率信息进行。如图8A所示,编码端首先判断是否进行颜色空间的转换,若进行颜色空间转换,则将颜色信息从RGB颜色空间转换到YUV颜色空间。然后,利用原始点云对重建点云进行重着色,使得未编码的属性信息与重建的几何信息对应起来。在颜色信息编码中分为两个模块:属性预测与属性变换。属性预测过程如下:首先对点云进行重排序,然后进行差分预测。其中重排序的方法有两种:莫顿重排序和Hilbert重排序。对于cat1A序列与cat2序列,对其进行Hilbert重排序;对于cat1B序列与cat3序列,对其进行莫顿重排序。对排序之后的点云使用差分方式进行属性预测,最后对预测残差进行量化并熵编码,生成二进制码流。属性变换过程如下:首先对点云属性做小波变换,对变换系数做量化;其次通过逆量化、逆小波变换得到属性重建值;然后计算原始属性和属性重建值的差得到属性残差并对其量化;最后将量化后的变换系数和属性残差进行熵编码,生成二进制码流。After the geometric encoding is completed, the geometric information is reconstructed. At present, attribute encoding is mainly performed on color and reflectivity information. As shown in Figure 8A, the encoding end first determines whether to perform color space conversion. If color space conversion is performed, the color information is converted from RGB color space to YUV color space. Then, the reconstructed point cloud is recolored using the original point cloud so that the unencoded attribute information corresponds to the reconstructed geometric information. In color information encoding, it is divided into two modules: attribute prediction and attribute transformation. The attribute prediction process is as follows: first, the point cloud is reordered, and then differential prediction is performed. There are two reordering methods: Morton reordering and Hilbert reordering. For cat1A sequence and cat2 sequence, Hilbert reordering is performed on them; for cat1B sequence and cat3 sequence, Morton reordering is performed on them. The attribute prediction of the sorted point cloud is performed using a differential method, and finally the prediction residual is quantized and entropy encoded to generate a binary code stream. The attribute transformation process is as follows: first, wavelet transform is performed on the point cloud attributes and the transform coefficients are quantized; secondly, the attribute reconstruction value is obtained through inverse quantization and inverse wavelet transform; then the difference between the original attribute and the attribute reconstruction value is calculated to obtain the attribute residual and quantize it; finally, the quantized transform coefficients and attribute residuals are entropy encoded to generate a binary code stream.
下面对AVS PCC的通用测试条件进行介绍。The general test conditions of AVS PCC are introduced below.
AVS的通用测试条件共4种:There are 4 general test conditions for AVS:
条件1:几何位置有限度有损、属性有损;Condition 1: The geometric position is limitedly lossy and the attributes are lossy;
条件2:几何位置无损、属性有损;Condition 2: The geometric position is lossless, but the attributes are lossy;
条件3:几何位置无损、属性有限度有损;Condition 3: The geometric position is lossless, and the attributes are limitedly lossy;
条件4:几何位置无损、属性无损。Condition 4: The geometric position and attributes are lossless.
通用测试序列包括Cat1A,Cat1B,Cat1C,Cat2-frame和Cat3共五类,其中Cat1A、Cat2-frame点云只包含反射率属性信息,Cat1B、Cat3点云只包含颜色属性信息,Cat1B点云同时包含颜色和反射率属性信息。The general test sequences include five categories: Cat1A, Cat1B, Cat1C, Cat2-frame and Cat3. Cat1A and Cat2-frame point clouds only contain reflectance attribute information, Cat1B and Cat3 point clouds only contain color attribute information, and Cat1B point cloud contains both color and reflectance attribute information.
技术路线:共2种,以属性压缩所采用的算法进行区分。Technical routes: There are 2 types in total, distinguished by the algorithm used for attribute compression.
技术路线1:预测分支,属性压缩采用基于帧内预测的方法:Technical route 1: prediction branch, attribute compression adopts the method based on intra-frame prediction:
在编码端,按照一定的顺序(点云原始采集顺序、莫顿顺序、希尔伯特顺序等)处理点云中的点,先采用预测算法得到属性预测值,根据属性值和属性预测值得到属性残差,然后对属性残差进行量化,生成量化残差,最后对量化残差进行编码;At the encoding end, the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, the Morton order, the Hilbert order, etc.), and the prediction algorithm is first used to obtain the attribute prediction value, and the attribute residual is obtained according to the attribute value and the attribute prediction value. Then, the attribute residual is quantized to generate a quantized residual, and finally the quantized residual is encoded;
在解码端,按照一定的顺序(点云原始采集顺序、莫顿顺序、希尔伯特顺序等)处理点云中的点,先采用预测算法得到属性预测值,然后解码获取量化残差,再对量化残差进行反量化,最后根据属性预测值和反量化后的残差,获得属性重建值。At the decoding end, the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, Morton order, Hilbert order, etc.). The prediction algorithm is first used to obtain the attribute prediction value, and then the decoding is performed to obtain the quantized residual. The quantized residual is then dequantized, and finally the attribute reconstruction value is obtained based on the attribute prediction value and the dequantized residual.
技术路线2:预测变换分支—资源受限,属性压缩采用基于帧内预测和DCT变换的方法,在编码量化后的变换系数时,有最大点数X(如4096)的限制,即最多每X点为一组进行编码:Technical route 2: Prediction transform branch - limited resources, attribute compression uses a method based on intra-frame prediction and DCT transform. When encoding the quantized transform coefficients, there is a maximum point number X (such as 4096), that is, at most every X points are encoded as a group:
在编码端,按照一定的顺序(点云原始采集顺序、莫顿顺序、希尔伯特顺序等)处理点云中的点,先将整个点云分成长度最大为Y(如2)的若干小组,然后将这若干个小组组合成若干个大组(每个大组中的点数不超过X,如4096),然后采用预测算法得到属性预测值,根据属性值和属性预测值得到属性残差,以小组为单位对属性残差进行DCT变换,生成变换系数,再对变换系数进行量化,生成量化后的变换系数,最后以大组为单位对量化后的变换系数进行编码;At the encoding end, the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, the Morton order, the Hilbert order, etc.), and the entire point cloud is first divided into several small groups with a maximum length of Y (such as 2), and then these small groups are combined into several large groups (the number of points in each large group does not exceed X, such as 4096), and then the prediction algorithm is used to obtain the attribute prediction value, and the attribute residual is obtained according to the attribute value and the attribute prediction value. The attribute residual is transformed by DCT in small groups to generate transformation coefficients, and then the transformation coefficients are quantized to generate quantized transformation coefficients, and finally the quantized transformation coefficients are encoded in large groups;
在解码端,按照一定的顺序(点云原始采集顺序、莫顿顺序、希尔伯特顺序等)处理点云中的点,先将整个点云分成长度最大为Y(如2)的若干小组,然后将这若干个小组组合成若干个大组(每个大组中的点数不超过X,如4096),以大组为单位解码获取量化后的变换系数,然后采用预测算法得到属性预测值,再以小组为单位对量化后的变换系数进行反量化、反变换,最后根据属性预测值和反量化、反变换后的系数,获得属性重建值。At the decoding end, the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, Morton order, Hilbert order, etc.). First, the entire point cloud is divided into several small groups with a maximum length of Y (such as 2), and then these small groups are combined into several large groups (the number of points in each large group does not exceed X, such as 4096). The quantized transform coefficients are decoded in large groups, and then the prediction algorithm is used to obtain the attribute prediction value. The quantized transform coefficients are dequantized and inversely transformed in small groups. Finally, the attribute reconstruction value is obtained based on the attribute prediction value and the dequantized and inversely transformed coefficients.
技术路线3:预测变换分支—资源不受限,属性压缩采用基于帧内预测和DCT变换的方法,在编码量化后的变换系数时,没有最大点数X的限制,即所有系数一起进行编码:Technical route 3: Prediction transform branch - resources are not limited. Attribute compression adopts a method based on intra-frame prediction and DCT transform. When encoding the quantized transform coefficients, there is no limit on the maximum number of points X, that is, all coefficients are encoded together:
在编码端,按照一定的顺序(点云原始采集顺序、莫顿顺序、希尔伯特顺序等)处理点云中的点,先将整个点云分成长度最大为Y(如2)的若干小组,然后采用预测算法得到属性预测值,根据属性值和属性预测值得到属性残差,以小组为单位对属性残差进行DCT变换,生成变换系数,再对变换系数进行量化,生成量化后的变换系数,最后对整个点云的量化后的变换系数进行编码;At the encoding end, the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, the Morton order, the Hilbert order, etc.). First, the entire point cloud is divided into several small groups with a maximum length of Y (such as 2). Then, the prediction algorithm is used to obtain the attribute prediction value. The attribute residual is obtained according to the attribute value and the attribute prediction value. The attribute residual is transformed by DCT in small groups to generate transformation coefficients. The transformation coefficients are quantized to generate quantized transformation coefficients. Finally, the quantized transformation coefficients of the entire point cloud are encoded.
在解码端,按照一定的顺序(点云原始采集顺序、莫顿顺序、希尔伯特顺序等)处理点云中的点,先将整个点云分成长度最大为Y(如2)的若干小组,解码获取整个点云的量化后的变换系数,然后采用预测算法得到属性预测值,再以小组为单位对量化后的变换系数进行反量化、反变换,最后根据属性预测值和反量化、反变换后的系数,获得属性重建值。At the decoding end, the points in the point cloud are processed in a certain order (the original acquisition order of the point cloud, Morton order, Hilbert order, etc.). First, the entire point cloud is divided into several small groups with a maximum length of Y (such as 2), and the quantized transformation coefficients of the entire point cloud are obtained by decoding. Then, the prediction algorithm is used to obtain the attribute prediction value, and then the quantized transformation coefficients are dequantized and inversely transformed in groups. Finally, the attribute reconstruction value is obtained based on the attribute prediction value and the dequantized and inversely transformed coefficients.
技术路线4:多层变换分支,属性压缩采用基于多层小波变换的方法:Technical route 4: Multi-layer transformation branch, attribute compression adopts a method based on multi-layer wavelet transform:
在编码端,对整个点云进行多层小波变换,生成变换系数,然后对变换系数进行量化,生成量化后的变换系数,最后对整个点云的量化后的变换系数进行编码;At the encoding end, the entire point cloud is subjected to multi-layer wavelet transform to generate transform coefficients, which are then quantized to generate quantized transform coefficients, and finally the quantized transform coefficients of the entire point cloud are encoded;
在解码端,解码获取整个点云的量化后的变换系数,然后对量化后的变换系数进行反量化、反变换,获得属性重建值。At the decoding end, decoding obtains the quantized transform coefficients of the entire point cloud, and then dequantizes and inversely transforms the quantized transform coefficients to obtain attribute reconstruction values.
在对当前节点进行直接编码时,编码端在确定当前节点具备直接编解码的资格后,对当前节点中点的位置信息进行编码。但是,目前对当前节点中点的几何信息进行编码时,没有考虑帧间信息,进而降低点云的编解码性能。When directly encoding the current node, the encoder encodes the position information of the midpoint of the current node after determining that the current node is eligible for direct encoding and decoding. However, when encoding the geometric information of the midpoint of the current node, inter-frame information is not considered, thereby reducing the encoding and decoding performance of the point cloud.
为了解决上述技术问题,本申请实施例在对当前解码帧中的当前节点进行编解码时,在当前待编解码帧的预测参考帧中,确定当前节点的N个预测节点,基于这N个预测节点中点的几何编解码信息,对当前节点中点的坐标信息进行预测编解码。也就是说,本申请实施例对节点进行DCM直接编解码时进行优化,通过考虑相邻帧之间时域上的相关性,利用预测参考帧中预测节点的几何信息对待节点IDCM节点(即当前节点)中点的几何信息进行预测编解码,通过考虑相邻帧之间时域相关性来进一步提升点云的几何信息编解码效率。In order to solve the above technical problems, when encoding and decoding the current node in the current decoding frame, the embodiment of the present application determines N predicted nodes of the current node in the predicted reference frame of the current frame to be encoded and decoded, and predicts and decodes the coordinate information of the midpoint of the current node based on the geometric encoding and decoding information of the midpoints of the N predicted nodes. In other words, the embodiment of the present application optimizes the node when performing DCM direct encoding and decoding, and predicts and decodes the geometric information of the midpoint of the IDCM node (i.e., the current node) of the to-be-encoded node by considering the correlation in the time domain between adjacent frames, and further improves the efficiency of geometric information encoding and decoding of the point cloud by considering the correlation in the time domain between adjacent frames.
下面结合具体的实施例,对本申请实施例涉及的点云编解码方法进行介绍。The point cloud encoding and decoding method involved in the embodiments of the present application is introduced below in conjunction with specific embodiments.
首先,以解码端为例,对本申请实施例提供的点云解码方法进行介绍。First, taking the decoding end as an example, the point cloud decoding method provided in the embodiment of the present application is introduced.
图10为本申请一实施例提供的点云解码方法流程示意图。本申请实施例的点云解码方法可以由上述图3或图4B或8B所示的点云解码设备或点云解码器完成。Fig. 10 is a schematic diagram of a point cloud decoding method according to an embodiment of the present application. The point cloud decoding method according to the embodiment of the present application can be implemented by the point cloud decoding device or point cloud decoder shown in Fig. 3 or Fig. 4B or Fig. 8B.
如图10所示,本申请实施例的点云解码方法包括:As shown in FIG10 , the point cloud decoding method of the embodiment of the present application includes:
S101、在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点。S101 . Determine N prediction nodes of a current node in a prediction reference frame of a current frame to be decoded.
其中,当前节点为当前待解码帧中的待解码节点。The current node is the node to be decoded in the current frame to be decoded.
由上述可知,点云包括几何信息和属性信息,对点云的解码包括几何解码和属性解码。本申请实施例涉及点云的几何解码。As can be seen from the above, the point cloud includes geometric information and attribute information, and the decoding of the point cloud includes geometric decoding and attribute decoding. The embodiment of the present application relates to geometric decoding of point clouds.
在一些实施例中,点云的几何信息也称为点云的位置信息,因此,点云的几何解码也称为点云的位置解码。In some embodiments, the geometric information of the point cloud is also referred to as the position information of the point cloud. Therefore, the geometric decoding of the point cloud is also referred to as the position decoding of the point cloud.
在基于八叉树的编码方式中,编码端基于点云的几何信息,构建点云的八叉树结构,如图11所示,使用最小长方体包围点云,首先对该包围盒进行八叉树划分,得到8个节点,对这8个节点中被占用的节点,即包括点的节点继续进行八叉树划分,以此类推,直到划分到体素级别位置,例如划分到1X1X1的正方体为止。这样划分得到的点云八叉树结构包括多层节点组成,例如包括N层,在编码时,逐层编码每一层的占位信息,直到编码完最后一层的体素级别的叶子节点为止。也就是说,在八叉树编码中,将点云通八叉树划分,最终将点云中的点划分到八叉树的体素级的叶子节点中,通过对整个八叉树进行编码,实现对点云的编码。In the octree-based encoding method, the encoding end constructs the octree structure of the point cloud based on the geometric information of the point cloud. As shown in Figure 11, the point cloud is enclosed by the smallest cuboid. The enclosing box is first divided into octrees to obtain 8 nodes. The occupied nodes among the 8 nodes, that is, the nodes including the points, continue to be divided into octrees, and so on, until the division is to the voxel level, for example, to a 1X1X1 cube. The point cloud octree structure obtained by such division includes multiple layers of nodes, for example, N layers. When encoding, the placeholder information of each layer is encoded layer by layer until the voxel-level leaf nodes of the last layer are encoded. That is to say, in octree encoding, the point cloud is divided through the octree, and finally the points in the point cloud are divided into the voxel-level leaf nodes of the octree. The encoding of the point cloud is achieved by encoding the entire octree.
对应的,解码端,首先解码点云的几何码流,得到该点云的八叉树的根节点的占位信息,并基于该根节点的占位信息,确定出该根节点所包括的子节点,即八叉树的第2层包括的节点。接着,解码几何码流,得到第2层中的各节点的占位信息,并基于各节点的占位信息,确定出八叉树的第3层所包括的节点,依次类推。Correspondingly, the decoding end first decodes the geometric code stream of the point cloud to obtain the placeholder information of the root node of the octree of the point cloud, and based on the placeholder information of the root node, determines the child nodes included in the root node, that is, the nodes included in the second layer of the octree. Then, the geometric code stream is decoded to obtain the placeholder information of each node in the second layer, and based on the placeholder information of each node, determines the nodes included in the third layer of the octree, and so on.
但基于八叉树的几何信息编码模式对空间中具有相关性的点有高效的压缩速率,而对于在几何空间中处于孤立位置的点来说,使用直接编码方式可以大大降低复杂度,提升编解码效率。However, the octree-based geometric information encoding mode has an efficient compression rate for correlated points in space, and for points in isolated positions in the geometric space, the use of direct encoding can greatly reduce the complexity and improve the encoding and decoding efficiency.
由于直接编码方式是对节点所包括的点的几何信息直接进行编码,若节点所包括的点数较多时,采用直接编码方式时压缩效果差。因此,对于八叉树中的节点,在进行直接编码之前,首先判断该节点是否可以采用直接编码方式。若判断该节点可以采用直接编码方式进行编码时,则采用直接编码方式对该节点所包括的点的几何信息进行直接编码。若判断该节点不可以采用直接编码方式进行编码时,则继续采用八叉树方式对该节点进行划分。Since the direct encoding method directly encodes the geometric information of the points included in the node, if the number of points included in the node is large, the compression effect is poor when the direct encoding method is used. Therefore, for the nodes in the octree, before direct encoding, first determine whether the node can be encoded using the direct encoding method. If it is determined that the node can be encoded using the direct encoding method, the direct encoding method is used to directly encode the geometric information of the points included in the node. If it is determined that the node cannot be encoded using the direct encoding method, the octree method is continued to be used to divide the node.
具体的,编码端首先判断节点是否具备直接编码的资格,若该节点具备直接编码的资格后,判断节点的点数是否小于或等于预设阈值,若节点的点数小于或等于预设阈值,则确定该节点可以采用直接编码方式进行解码。接着,将该节点所包括的点数,以及各点的几何信息编入码流。对应的,解码端在确定该节点具备直接解码的资格后,解码码流,得到该节点的点数,以及各点的几何信息,实现该节点的几何解码。Specifically, the encoding end first determines whether the node is qualified for direct encoding. If the node is qualified for direct encoding, it determines whether the number of points of the node is less than or equal to the preset threshold. If the number of points of the node is less than or equal to the preset threshold, it is determined that the node can be decoded by direct encoding. Then, the number of points included in the node and the geometric information of each point are encoded into the bitstream. Correspondingly, after determining that the node is qualified for direct decoding, the decoding end decodes the bitstream, obtains the number of points of the node and the geometric information of each point, and implements geometric decoding of the node.
目前在对当前节点中点的位置信息进行预测编码时,未考虑帧间信息,使得点云的编码性能低。Currently, when predictive coding is performed on the position information of the midpoint of the current node, inter-frame information is not considered, resulting in low coding performance of the point cloud.
为了解决上述问题,本申请实施例中,解码端基于当前节点对应的帧间信息,对当前节点中点的位置信息进行预测解码,进而提升点云的解码效率和解码性能。In order to solve the above problems, in an embodiment of the present application, the decoding end predicts and decodes the position information of the midpoint of the current node based on the inter-frame information corresponding to the current node, thereby improving the decoding efficiency and decoding performance of the point cloud.
具体的,解码端首先在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点。Specifically, the decoding end first determines N prediction nodes of the current node in the prediction reference frame of the current frame to be decoded.
需要说明的是,当前待解码帧为一个点云帧,在一些实施例中,当前待解码帧也称为当前帧或当前点云帧或当前待解码的点云帧等。当前节点可以理解为当前待解码帧中的任意一个非叶子节点的非空节点。也就是说,当前节点不是当前待解码帧对应的八叉树中的叶子节点,即当前节点为八叉树的中间任意节点,且该当前节点不是非空节点,即至少包括1个点。It should be noted that the current frame to be decoded is a point cloud frame. In some embodiments, the current frame to be decoded is also referred to as the current frame or the current point cloud frame or the point cloud frame to be decoded. The current node can be understood as any non-leaf node in the current frame to be decoded. In other words, the current node is not a leaf node in the octree corresponding to the current frame to be decoded, that is, the current node is any middle node of the octree, and the current node is not a non-empty node, that is, it includes at least 1 point.
在本申请实施例中,解码端在解码当前待解码帧中的当前节点时,首先确定当前待解码帧的预测参考帧,并在预测参考帧中,确定当前节点的N个预测节点。例如图12示出了当前节点在预测参考帧中的一个预测节点。In the embodiment of the present application, when decoding the current node in the current frame to be decoded, the decoding end first determines the prediction reference frame of the current frame to be decoded, and determines N prediction nodes of the current node in the prediction reference frame. For example, FIG12 shows a prediction node of the current node in the prediction reference frame.
需要说明的是,本申请实施例对当前待解码帧的预测参考帧的个数不做限制,例如,当前待解码帧具有一个预测参考帧,或者当前待解码帧具有多个预测参考帧。同时,本申请实施例对当前节点的预测节点的个数N也不做限制,具体根据实际需要确定。It should be noted that the embodiment of the present application does not limit the number of prediction reference frames of the current frame to be decoded. For example, the current frame to be decoded has one prediction reference frame, or the current frame to be decoded has multiple prediction reference frames. At the same time, the embodiment of the present application does not limit the number N of prediction nodes of the current node, which is determined according to actual needs.
本申请实施例对确定当前待解码帧的预测参考帧的具体方式也不做限制。The embodiment of the present application does not limit the specific method of determining the prediction reference frame of the current frame to be decoded.
在一些实施例中,将当前待解码帧的前一个或前几个已解码帧,确定为该当前待解码帧的预测参考帧。In some embodiments, one or several decoded frames before the current frame to be decoded are determined as prediction reference frames of the current frame to be decoded.
例如,若当前待解码帧为P帧,P帧在帧间参考帧包括P帧的前一帧(即前向帧),因此,可以将当前待解码帧的前一帧(即前向帧),确定为当前待解码帧的预测参考帧。For example, if the current frame to be decoded is a P frame, the inter-frame reference frame of the P frame includes the previous frame of the P frame (ie, the forward frame). Therefore, the previous frame of the current frame to be decoded (ie, the forward frame) can be determined as the predicted reference frame of the current frame to be decoded.
再例如,若当前待解码帧为B帧,B帧的帧间参考帧包括P帧的前一帧(即前向帧)和P帧的后一帧(即后向帧),因此,可以将当前待解码帧的前一帧(即前向帧),确定为当前待解码帧的预测参考帧。For another example, if the current frame to be decoded is a B frame, the inter-frame reference frames of the B frame include the previous frame of the P frame (i.e., the forward frame) and the next frame of the P frame (i.e., the backward frame). Therefore, the previous frame of the current frame to be decoded (i.e., the forward frame) can be determined as the predicted reference frame of the current frame to be decoded.
在一些实施例中,将当前待解码帧的后一个或后几个已解码帧,确定为该当前待解码帧的预测参考帧。In some embodiments, one or several decoded frames following the current frame to be decoded are determined as prediction reference frames of the current frame to be decoded.
例如,若当前待解码帧为B帧,则可以将当前待解码帧的后一帧,确定为当前待解码帧的预测参考帧。For example, if the current frame to be decoded is a B frame, the frame following the current frame to be decoded may be determined as a prediction reference frame of the current frame to be decoded.
在一些实施例中,将当前待解码帧的前一个或前几个已解码帧,以及当前待解码帧的后一个或后几个已解码帧,确定为该当前待解码帧的预测参考帧。In some embodiments, one or several decoded frames before the current frame to be decoded, and one or several decoded frames after the current frame to be decoded, are determined as prediction reference frames of the current frame to be decoded.
例如,若当前待解码帧为B帧,则可以将当前待解码帧的前一帧和后一帧,确定为当前待解码帧的预测参考帧,此时,当前待解码帧具有2个预测参考帧。For example, if the current frame to be decoded is a B frame, the previous frame and the next frame of the current frame to be decoded may be determined as prediction reference frames of the current frame to be decoded. In this case, the current frame to be decoded has two prediction reference frames.
下面以当前待解码帧包括K个预测参考帧为例,对上述S101-A中在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点的具体过程进行介绍。Taking the current frame to be decoded including K prediction reference frames as an example, the specific process of determining N prediction nodes of the current node in the prediction reference frame of the current frame to be decoded in S101-A above is introduced.
在一些实施例中,解码端基于当前待解码帧中节点的占位信息,以及K个预测参考帧中每一个预测参考帧中节点的占位信息,从K个预测参考帧中选出至少一个预测参考帧,进而在该至少一个预测参考帧中,查找当前节点的预测节点。例如,从K个预测参考帧中,选出节点的占位信息与当前待解码帧的节点的占位信息最相近的至少一个预测参考帧,进而在这至少一个预测参考帧中,查找当前节点的预测节点。In some embodiments, the decoding end selects at least one prediction reference frame from the K prediction reference frames based on the placeholder information of the node in the current frame to be decoded and the placeholder information of the node in each of the K prediction reference frames, and then searches for the prediction node of the current node in the at least one prediction reference frame. For example, at least one prediction reference frame whose placeholder information of the node is closest to the placeholder information of the node in the current frame to be decoded is selected from the K prediction reference frames, and then searches for the prediction node of the current node in the at least one prediction reference frame.
在一些实施例中,解码端可以通过如下S101-A1和S101-A2的步骤,确定当前节点的N个预测节点:In some embodiments, the decoding end may determine N predicted nodes of the current node through the following steps S101-A1 and S101-A2:
S101-A1、针对K个预测参考帧中的第k个预测参考帧,确定当前节点在第k个预测参考帧中的至少一个预测节点,k为小于或等于K的正整数,K为正整数;S101-A1, for a k-th prediction reference frame among K prediction reference frames, determining at least one prediction node of a current node in the k-th prediction reference frame, where k is a positive integer less than or equal to K, and K is a positive integer;
S101-A2、基于当前节点在K个预测参考帧中的至少一个预测节点,确定当前节点的N个预测节点。S101-A2. Determine N prediction nodes of the current node based on at least one prediction node of the current node in K prediction reference frames.
在该实施例中,解码端从K个预测参考帧中的每一个预测参考帧中,确定出当前节点的至少一个预测节点,最后将K个预测参考帧中各预测参考帧中的至少一个预测节点进行汇总,得到当前节点的N个预测节点。In this embodiment, the decoding end determines at least one prediction node of the current node from each of the K prediction reference frames, and finally summarizes at least one prediction node in each of the K prediction reference frames to obtain N prediction nodes of the current node.
其中,解码端确定当前节点在K个预测参考帧中每一个预测参考帧中的至少一个预测点的过程相同,为了便于描述,在此以K个预测参考帧中的第k个预测参考帧为例进行说明。Among them, the process of the decoding end determining at least one prediction point of the current node in each of the K prediction reference frames is the same. For the convenience of description, the kth prediction reference frame among the K prediction reference frames is taken as an example for explanation.
下面对上述S101-A1中确定当前节点在第k个预测参考帧中的至少一个预测节点的具体过程进行介绍。The specific process of determining at least one prediction node of the current node in the kth prediction reference frame in the above S101-A1 is introduced below.
本申请实施例对解码端确定当前节点在第k个预测参考帧中的至少一个预测节点的具体方式不做限制。The embodiment of the present application does not limit the specific manner in which the decoding end determines at least one prediction node of the current node in the kth prediction reference frame.
方式一,在第k个预测参考帧中,确定出当前节点的一个预测节点。例如,将第k个预测参考帧中与当前节点的划分深度相同的一个节点,确定为当前节点的预测节点。Method 1: In the kth prediction reference frame, a prediction node of the current node is determined. For example, a node in the kth prediction reference frame having the same division depth as the current node is determined as the prediction node of the current node.
举例说明,假设当前节点位于当前待解码帧的八叉树的第3层,这样可以获取第k个预测参考帧中位于八叉树第3层的各节点,进而从这些节点中,确定出当前节点的预测节点。For example, assuming that the current node is located at the third layer of the octree of the current frame to be decoded, the nodes located at the third layer of the octree in the kth prediction reference frame can be obtained, and then the prediction node of the current node can be determined from these nodes.
在一种示例中,若当前节点在第k个预测参考帧中的预测节点的个数为1个时,则可以将第k个预测参考帧与当前节点处于相同划分深度的这些点中,选出占位信息与当前节点的占位信息差异最小的一个节点,记为节点1,将该节点1确定为当前节点在第k个预测参考帧中的一个预测节点。In one example, if the number of prediction nodes of the current node in the kth prediction reference frame is 1, then among the points at which the kth prediction reference frame and the current node are at the same division depth, a node whose occupancy information is the smallest different from that of the current node can be selected, recorded as node 1, and node 1 is determined as a prediction node of the current node in the kth prediction reference frame.
在另一种示例中,若当前节点在第k个预测参考帧中的预测节点的个数大于1时,则将上述确定的节点1,以及节点1在第k个预测参考帧中的至少一个领域节点,例如与节点1共面、共线、共点等的至少一个领域节点,确定为当前节点在第k个预测参考帧中的预测节点。In another example, if the number of prediction nodes of the current node in the kth prediction reference frame is greater than 1, the node 1 determined above and at least one domain node of node 1 in the kth prediction reference frame, such as at least one domain node that is coplanar, colinear, or co-point with node 1, are determined as the prediction nodes of the current node in the kth prediction reference frame.
方式二,上述S101-A1中确定当前节点在第k个预测参考帧中的至少一个预测节点,包括如下S101-A11至S101-A13的步骤: Mode 2, in the above S101-A1, determining at least one prediction node of the current node in the kth prediction reference frame includes the following steps S101-A11 to S101-A13:
S101-A11、在当前待解码帧中,确定当前节点的M个领域节点,M个领域节点中包括当前节点,M为正整数;S101-A11, in the current frame to be decoded, determine M domain nodes of the current node, the M domain nodes include the current node, and M is a positive integer;
S101-A12、针对M个领域节点中的第i个领域节点,确定第i个领域节点在第k个预测参考帧中的对应节点,i为小于或等于M的正整数;S101-A12, for the i-th domain node among the M domain nodes, determine the corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M;
S101-A13、基于M个领域节点在第k个预测参考帧中的对应节点,确定当前节点在第k个预测参考帧中的至少一个预测节点。S101-A13. Determine at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame.
在该实现方式中,解码端在确定当前节点在第k个预测参考帧中的至少一个预测节点之前,首先在当前待解码帧中确定当前节点的M个领域节点,该M个领域节点中包括当前节点自身。In this implementation, before determining at least one prediction node of the current node in the kth prediction reference frame, the decoding end first determines M domain nodes of the current node in the current frame to be decoded, and the M domain nodes include the current node itself.
需要说明的是,在本申请实施例中,对当前节点的M个领域节点的具体确定方式不做限制。It should be noted that in the embodiment of the present application, there is no limitation on the specific method of determining the M domain nodes of the current node.
在一种示例中,当前节点的M个领域节点包括当前待解码帧中,与当前节点共面、共线和共点的领域节点中的至少一个领域节点。如图13所示,当前节点包括6个共面的节点、12个共线的节点和8个共点的节点。In one example, the M domain nodes of the current node include at least one domain node among the domain nodes that are coplanar, colinear, and co-pointed with the current node in the current frame to be decoded. As shown in FIG13 , the current node includes 6 coplanar nodes, 12 colinear nodes, and 8 co-pointed nodes.
在另一种示例中,当前节点的M个领域节点中除了包括当前待解码帧中,与当前节点共面、共线和共点的领域节点中的至少一个领域节点外,还可以包括参考邻域范围内的其他节点,本申请实施例对此不做限制。In another example, the M domain nodes of the current node may include other nodes within the reference neighborhood in addition to at least one domain node in the current frame to be decoded that is coplanar, colinear, and co-point with the current node. This embodiment of the present application does not impose any restrictions on this.
解码端基于上述步骤,在当前待解码帧中确定出当前节点的M个领域节点后,确定出M个领域节点中每一个领域节点在第k个预测参考帧中的对应节点,进而基于M个领域节点在第k个预测参考帧中的对应节点,确定当前节点在第k个预测参考帧中的至少一个预测节点。Based on the above steps, the decoding end determines the M domain nodes of the current node in the current frame to be decoded, and then determines the corresponding node of each of the M domain nodes in the kth prediction reference frame, and then determines at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame.
本申请实施例对S101-A13的具体实现方式不做限制。The embodiment of the present application does not limit the specific implementation method of S101-A13.
在一种可能的实现方式中,从M个领域节点在第k个预测参考帧中的对应节点中,筛选出至少一个对应节点,作为当前节点在第k个预测参考帧中的至少一个预测节点。例如,从M个领域节点在第k个预测参考帧中的对应节点中,筛选出占位信息与当前节点的占位信息差异最小的至少一个对应节点,作为当前节点在第k个预测参考帧中的至少一个预测节点。其中,确定对应节点的占位信息与当前节点的占位信息的差异的方式可以参照上述占位信息的差异的确定过程,例如将对应节点的占位信息与当前节点的占位信息进行异或运算,将异或运算结果作为该对应节点的占位信息与当前节点的占位信息之间的差异。In a possible implementation, at least one corresponding node is selected from the corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame. For example, at least one corresponding node whose placeholder information has the smallest difference with the placeholder information of the current node is selected from the corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame. The method of determining the difference between the placeholder information of the corresponding node and the placeholder information of the current node can refer to the above-mentioned process of determining the difference in placeholder information, for example, performing an XOR operation on the placeholder information of the corresponding node and the placeholder information of the current node, and using the XOR operation result as the difference between the placeholder information of the corresponding node and the placeholder information of the current node.
在另一种可能的实现方式中,解码端将M个领域节点在第k个预测参考帧中的对应节点,确定为当前节点在第k个预测参考帧中的至少一个预测节点。例如,M个领域节点分别在第k个预测参考帧中具有一个对应节点,进而有M个对应节点,将这M个对应节点确定为当前节点在第k个预测参考帧中的预测节点,共有M个预测节点。In another possible implementation, the decoding end determines the corresponding nodes of the M domain nodes in the kth prediction reference frame as at least one prediction node of the current node in the kth prediction reference frame. For example, the M domain nodes each have a corresponding node in the kth prediction reference frame, and then there are M corresponding nodes, and these M corresponding nodes are determined as the prediction nodes of the current node in the kth prediction reference frame, and there are M prediction nodes in total.
上面对确定当前节点在第k个预测参考帧中的至少一个预测节点的过程进行介绍。这样,解码端可以采用与上述相同的方式,确定出当前节点在K个预测参考帧中每一个预测参考帧中的至少一个预测节点。The above describes the process of determining at least one prediction node of the current node in the kth prediction reference frame. In this way, the decoding end can use the same method as above to determine at least one prediction node of the current node in each of the K prediction reference frames.
例如,若当前待解码帧为P帧时,K个预测参考帧包括当前待解码帧的前向帧。此时,解码端基于上述步骤,可以确定出当前节点在前向帧中的至少一个预测节点。示例性的,如图15A所示,假设当前节点包括3个领域节点,分别记为节点11、节点12(为当前节点)和节点13,这3个领域节点在前向帧中分别对应一个对应节点,分别记为节点21、节点22和节点23,进而将节点21、节点22和节点23确定为当前节点在前向帧中的3个预测节点,或者从节点21、节点22和节点23中选出1或2个节点确定为当前节点在前向帧中的1个或2个预测节点。For example, if the current frame to be decoded is a P frame, the K predicted reference frames include the forward frame of the current frame to be decoded. At this point, the decoding end can determine at least one predicted node of the current node in the forward frame based on the above steps. Exemplarily, as shown in FIG15A , it is assumed that the current node includes three domain nodes, which are respectively recorded as node 11, node 12 (current node) and node 13. These three domain nodes correspond to a corresponding node in the forward frame, respectively recorded as node 21, node 22 and node 23, and then node 21, node 22 and node 23 are determined as the three predicted nodes of the current node in the forward frame, or 1 or 2 nodes are selected from node 21, node 22 and node 23 to be determined as 1 or 2 predicted nodes of the current node in the forward frame.
再例如,若当前待解码帧为B帧时,K个预测参考帧包括当前待解码帧的前向帧和后向帧。此时,解码端基于上述步骤,可以确定出当前节点在前向帧中的至少一个预测节点,以及当前节点在后向帧中的至少一个预测节点。示例性的,如图15B所示,假设当前节点包括3个领域节点,分别记为节点11、节点12和节点13,这3个领域节点在前向帧中分别对应一个对应节点记为节点21、节点22和节点23,这3个领域节点在后向帧中分别对应一个对应节点记为节点41、节点42和节点43。这样解码端可以将节点21、节点22和节点23确定为当前节点在前向帧中的3个预测节点,或者从节点21、节点22和节点23中选出1或2个节点确定为当前节点在前向帧中的1个或2个预测节点。同理,解码端可以将节点41、节点42和节点43确定为当前节点在后向帧中的3个预测节点,或者从节点41、节点42和节点43中选出1或2个节点确定为当前节点在后向帧中的1个或2个预测节点。For another example, if the current frame to be decoded is a B frame, the K prediction reference frames include the forward frame and the backward frame of the current frame to be decoded. At this time, the decoding end can determine at least one prediction node of the current node in the forward frame, and at least one prediction node of the current node in the backward frame based on the above steps. Exemplarily, as shown in FIG15B, it is assumed that the current node includes three domain nodes, which are respectively recorded as nodes 11, 12, and 13. These three domain nodes correspond to a corresponding node in the forward frame, which are recorded as nodes 21, 22, and 23, respectively. These three domain nodes correspond to a corresponding node in the backward frame, which are recorded as nodes 41, 42, and 43. In this way, the decoding end can determine nodes 21, 22, and 23 as the three prediction nodes of the current node in the forward frame, or select 1 or 2 nodes from nodes 21, 22, and 23 to determine as 1 or 2 prediction nodes of the current node in the forward frame. Similarly, the decoding end can determine node 41, node 42 and node 43 as three prediction nodes of the current node in the backward frame, or select one or two nodes from node 41, node 42 and node 43 as one or two prediction nodes of the current node in the backward frame.
解码端确定出当前节点在K个预测参考帧中每一个预测参考帧中的至少一个预测节点后,执行上述S101-B的步骤,即基于当前节点在K个预测参考帧中的至少一个预测节点,确定当前节点的N个预测节点。After the decoding end determines at least one prediction node of the current node in each of the K prediction reference frames, it executes the above step S101-B, that is, based on at least one prediction node of the current node in the K prediction reference frames, determines N prediction nodes of the current node.
在一种示例中,将当前节点在K个预测参考帧中的至少一个预测节点,确定为当前节点的N个预测节点。In an example, at least one prediction node of the current node in K prediction reference frames is determined as N prediction nodes of the current node.
例如,K=2,即K个预测参考帧包括第一个预测参考帧和第二个预测参考帧。假设当前节点在第一个预测参考帧中有2个预测节点,当前节点在第二个预测参考帧中有3个预测节点,这样可以确定当前节点具有5个预测节点,此时N=5。For example, K=2, that is, the K prediction reference frames include the first prediction reference frame and the second prediction reference frame. Assuming that the current node has 2 prediction nodes in the first prediction reference frame and the current node has 3 prediction nodes in the second prediction reference frame, it can be determined that the current node has 5 prediction nodes, and N=5 at this time.
在另一种示例中,从当前节点在K个预测参考帧中的至少一个预测节点中,筛选出当前节点的N个预测节点。In another example, N prediction nodes of the current node are screened out from at least one prediction node of the current node in K prediction reference frames.
继续参照上述示例,假设K=2,即K个预测参考帧包括第一个预测参考帧和第二个预测参考帧。假设当前节点在第一个预测参考帧中有2个预测节点,当前节点在第二个预测参考帧中有3个预测节点。从这5个预测节点中,选出3个预测节点作为当前节点的最终预测节点。例如,从这5个预测节点中,选出占位信息与当前节点的占位信息差异最小的3个预测节点,确定为当前节点的最终预测节点。Continuing with the above example, assume that K=2, that is, the K prediction reference frames include the first prediction reference frame and the second prediction reference frame. Assume that the current node has 2 prediction nodes in the first prediction reference frame, and the current node has 3 prediction nodes in the second prediction reference frame. From these 5 prediction nodes, select 3 prediction nodes as the final prediction nodes of the current node. For example, from these 5 prediction nodes, select the 3 prediction nodes whose placeholder information has the smallest difference with the placeholder information of the current node, and determine them as the final prediction nodes of the current node.
在该方式二中,解码端在当前待解码帧中确定出当前节点的M个领域节点后,在第k个预测参考帧中,确定出这M个领域节点中每一个领域节点的对应节点,进而基于M个领域节点中每一个领域节点的对应节点,确定当前节点在该第k个预测参考帧中的至少一个预测点。In the second method, after the decoding end determines the M domain nodes of the current node in the current frame to be decoded, it determines the corresponding node of each of the M domain nodes in the kth prediction reference frame, and then determines at least one prediction point of the current node in the kth prediction reference frame based on the corresponding node of each of the M domain nodes.
方式三,上述S101-A1中确定当前节点在第k个预测参考帧中的至少一个预测节点,包括如下S101-B11至S101-B13的步骤: Mode 3, in the above S101-A1, determining at least one prediction node of the current node in the kth prediction reference frame includes the following steps S101-B11 to S101-B13:
S101-B11、确定当前节点在第k个预测参考帧中的对应节点;S101-B11, determining a corresponding node of the current node in the kth prediction reference frame;
S101-B12、确定对应节点的至少一个领域节点;S101-B12, determining at least one domain node of the corresponding node;
S101-B13、将至少一个领域节点,确定为当前节点在第k个预测参考帧中的至少一个预测节点。S101-B13. Determine at least one domain node as at least one prediction node of the current node in the kth prediction reference frame.
在该方式3中,针对K个预测参考帧中的每一个预测参考帧,解码端首先在各预测参考帧中确定该当前节点的对应节点。例如,确定当前节点在预测参考帧1中的对应节点1,确定当前节点在预测参考帧2中的对应节点2。接着,解码端确定各对应节点的至少一个领域节点。例如,在预测参考帧1中确定对应节点1的至少一个领域节点,以及在预测参考帧2中确定对应节点2的至少一个领域节点。这样可以将对应节点1在预测参考帧1中的至少一个领域节点,确定为当前节点在预测参考帧1中的至少一个预测节点,将对应节点2在预测参考帧2中的至少一个领域节点,确定为当前节点在预测参考帧2中的至少一个预测节点。In this method 3, for each of the K prediction reference frames, the decoding end first determines the corresponding node of the current node in each prediction reference frame. For example, the corresponding node 1 of the current node in the prediction reference frame 1 is determined, and the corresponding node 2 of the current node in the prediction reference frame 2 is determined. Next, the decoding end determines at least one domain node of each corresponding node. For example, at least one domain node of the corresponding node 1 is determined in the prediction reference frame 1, and at least one domain node of the corresponding node 2 is determined in the prediction reference frame 2. In this way, at least one domain node of the corresponding node 1 in the prediction reference frame 1 can be determined as at least one prediction node of the current node in the prediction reference frame 1, and at least one domain node of the corresponding node 2 in the prediction reference frame 2 can be determined as at least one prediction node of the current node in the prediction reference frame 2.
方式二的S101-A12中确定第i个领域节点在第k个预测参考帧中的对应节点,与上述方式三的S101-B11中确定当前节点在第k个预测参考帧中的对应节点的过程基本相同。为了便于描述,将上述第i个领域节点和当前节点记为第i个节点,下面对确定第i个节点在第k个预测参考帧中的对应节点的具体过程进行介绍。The process of determining the corresponding node of the i-th domain node in the k-th prediction reference frame in S101-A12 of the second method is basically the same as the process of determining the corresponding node of the current node in the k-th prediction reference frame in S101-B11 of the above-mentioned third method. For the convenience of description, the above-mentioned i-th domain node and the current node are recorded as the i-th node, and the specific process of determining the corresponding node of the i-th node in the k-th prediction reference frame is introduced below.
解码端确定第i个节点在第k个预测参考帧中的对应节点至少包括如下几种方式:The decoding end determines the corresponding node of the i-th node in the k-th prediction reference frame in at least the following ways:
方式1,将第k个预测参考帧中与第i个节点的划分深度相同的一个节点,确定为第i个节点的对应节点。Method 1: Determine a node in the k-th prediction reference frame that has the same division depth as the i-th node as the corresponding node of the i-th node.
举例说明,假设第i个节点位于当前待解码帧的八叉树的第3层,这样可以获取第k个预测参考帧中位于八叉树第3层的各节点,进而从这些节点中,确定出第i个节点的对应节点。例如,将第k个预测参考帧与第i个节点处于相同划分深度的这些点中,选出占位信息与第i个节点的占位信息差异最小的一个节点,确定为第i个节点在第k个预测参考帧中的对应节点。For example, assuming that the i-th node is located at the third layer of the octree of the current frame to be decoded, the nodes located at the third layer of the octree in the k-th prediction reference frame can be obtained, and then the corresponding node of the i-th node can be determined from these nodes. For example, among the points where the k-th prediction reference frame and the i-th node are at the same division depth, a node whose placeholder information has the smallest difference with the placeholder information of the i-th node is selected and determined as the corresponding node of the i-th node in the k-th prediction reference frame.
方式2、上述S101-A12和S101-B11包括如下步骤:Mode 2: The above S101-A12 and S101-B11 include the following steps:
S101-A121、在当前待解码帧中,确定第i个节点的父节点,作为第i个父节点;S101-A121, in the current frame to be decoded, determine the parent node of the i-th node as the i-th parent node;
S101-A122、确定第i个父节点在第k个预测参考帧中的匹配节点,作为第i个匹配节点;S101-A122, determining a matching node of the i-th parent node in the k-th prediction reference frame as the i-th matching node;
S101-A123、将i个匹配节点的子节点中的一个子节点,确定为第i个节点在第k个预测参考帧中的对应节点。S101-A123, determine one of the child nodes of the i matching nodes as the corresponding node of the i-th node in the k-th prediction reference frame.
在该方式2中,对于第i个节点,解码端在当前待解码帧中,确定该第i个节点的父节点,进而在第k个预测参考帧中,确定第i个预测领域节点的父节点的匹配节点。为了便于描述,将第i个节点的父节点记为第i个父节点,将第i个节点的父节点在第k个预测参考帧中的匹配节点,确定为第i个匹配节点。接着,将第i个匹配节点的子节点的一个子节点,确定为第i个节点在第k个预测参考帧中的对应节点,实现对第i个节点在第k个预测参考帧中的对应节点的准确确定。In the method 2, for the i-th node, the decoding end determines the parent node of the i-th node in the current frame to be decoded, and then determines the matching node of the parent node of the i-th prediction domain node in the k-th prediction reference frame. For the convenience of description, the parent node of the i-th node is recorded as the i-th parent node, and the matching node of the parent node of the i-th node in the k-th prediction reference frame is determined as the i-th matching node. Then, a child node of the child node of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame, thereby accurately determining the corresponding node of the i-th node in the k-th prediction reference frame.
下面对上述S101-A122中确定第i个父节点在第k个预测参考帧中的匹配节点的具体过程进行介绍。The specific process of determining the matching node of the i-th parent node in the k-th prediction reference frame in the above S101-A122 is introduced below.
本申请实施例对解码端确定第i个父节点在第k个预测参考帧中的匹配节点的具体方式不做限制。The embodiment of the present application does not limit the specific manner in which the decoding end determines the matching node of the i-th parent node in the k-th prediction reference frame.
在一些实施例中,确定第i个父节点在当前待解码帧中的划分深度,例如第i个父节点在当前待解码帧的八叉树的第2层。这样,解码端可以将第k个预测参考帧中与第i个父节点的划分深度相同的各节点中的一个节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。例如将第k个预测参考帧中处于第2层的各节点中的一个节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。In some embodiments, the division depth of the i-th parent node in the current frame to be decoded is determined, for example, the i-th parent node is in the second layer of the octree of the current frame to be decoded. In this way, the decoding end can determine one of the nodes in the k-th prediction reference frame that have the same division depth as the i-th parent node as the matching node of the i-th parent node in the k-th prediction reference frame. For example, one of the nodes in the second layer in the k-th prediction reference frame is determined as the matching node of the i-th parent node in the k-th prediction reference frame.
在一些实施例中,解码端基于第i个父节点的占位信息,确定第i个父节点在第k个预测参考帧中的匹配节点。具体的,由于当前待解码帧中的第i个父节点的占位信息已解码,且第k个预测参考帧中的各节点的占位信息也已解码。这样,解码端可以基于第i个父节点的占位信息,在第k个预测参考帧中查找该第i个父节点的匹配节点。In some embodiments, the decoding end determines the matching node of the i-th parent node in the k-th prediction reference frame based on the placeholder information of the i-th parent node. Specifically, since the placeholder information of the i-th parent node in the current frame to be decoded has been decoded, and the placeholder information of each node in the k-th prediction reference frame has also been decoded, the decoding end can search for the matching node of the i-th parent node in the k-th prediction reference frame based on the placeholder information of the i-th parent node.
例如,将第k个预测参考帧中,占位信息与第i个父节点的占位信息之间的差异最小的节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。For example, a node whose placeholder information in the k-th prediction reference frame has the smallest difference with the placeholder information of the i-th parent node is determined as a matching node of the i-th parent node in the k-th prediction reference frame.
举例说明,假设第i个父节点的占位信息为11001101,在第k个预测参考帧中查询占位信息与占位信息11001101差异最小的节点。具体是,解码端将第i个父节点的占位信息,与第k个预测参考帧中的每一个节点的占位信息进行异或运算,将第k个预测参考帧中的异或运算结果最小的一个节点,确定为第i个父节点在第k个预测参考帧中匹配节点。For example, assuming that the placeholder information of the i-th parent node is 11001101, the node whose placeholder information is the smallest different from the placeholder information 11001101 is searched in the k-th prediction reference frame. Specifically, the decoding end performs an XOR operation on the placeholder information of the i-th parent node and the placeholder information of each node in the k-th prediction reference frame, and determines the node with the smallest XOR operation result in the k-th prediction reference frame as the matching node of the i-th parent node in the k-th prediction reference frame.
示例性的,假设第k个预测参考帧中的节点1的占位信息为10001101,将11001101与10001101进行异或运算,其中11001101的第1位与10001101的第1位均为1,因此,两者的第1位的异或运算结果为0,11001101的第2位与10001111的第2位不相同,因此,两者的第2位的异或运算结果为1,依次类推,得到11001101与10001111的异或运算结果为0+1+0+0+0+0+1+0=2。参照该方式,解码端可以确定出第i个父节点的占位信息与第k个预测参考帧中每一个节点的占位信息的异或运算结果,进而将第k个预测参考帧中,与第i个父节点的占位信息的异或运算最小的节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。For example, assuming that the occupancy information of node 1 in the kth predicted reference frame is 10001101, 11001101 and 10001101 are XORed, where the first bit of 11001101 and the first bit of 10001101 are both 1, so the XOR result of the first bit of the two is 0, the second bit of 11001101 is different from the second bit of 10001111, so the XOR result of the second bit of the two is 1, and so on, the XOR result of 11001101 and 10001111 is 0+1+0+0+0+0+1+0=2. According to this method, the decoding end can determine the XOR operation result of the occupancy information of the i-th parent node and the occupancy information of each node in the k-th prediction reference frame, and then determine the node in the k-th prediction reference frame with the smallest XOR operation with the occupancy information of the i-th parent node as the matching node of the i-th parent node in the k-th prediction reference frame.
基于上述步骤,解码端可以确定出第i个父节点在第k个预测参考帧中的匹配节点。为了便于描述,将该匹配节 点记为第i个匹配节点。Based on the above steps, the decoding end can determine the matching node of the i-th parent node in the k-th prediction reference frame. For the convenience of description, this matching node is recorded as the i-th matching node.
接着,解码端将该第i个匹配节点的子节点中的一个子节点,确定为第i个领域节点在第k个预测参考帧中的对应节点。Next, the decoding end determines one of the child nodes of the i-th matching node as the corresponding node of the i-th domain node in the k-th prediction reference frame.
例如,解码端将该第i个匹配节点所包括的子节点中的一个默认子节点,确定为第i个节点在第k个预测参考帧中的对应节点。假设,将第i个匹配节点的第1个子节点,确定为第i个节点在第k个预测参考帧中的对应节点。For example, the decoding end determines a default child node among the child nodes included in the i-th matching node as the corresponding node of the i-th node in the k-th prediction reference frame. Assume that the first child node of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
再例如,解码端确定第i个节点在父节点所包括的子节点中的第一序号;将第i个匹配节点的子节点中序号为第一序号的子节点,确定为第i个节点在第k个预测参考帧中的对应节点。示例性的,如图14所示,第i个节点为第i个父节点的第2个子节点,此时第一序号为2。这样可以将第i个匹配节点的第2个子节点,确定为第i个节点的对应节点。For another example, the decoding end determines the first sequence number of the i-th node in the child nodes included in the parent node; the child node with the first sequence number in the child nodes of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame. Exemplarily, as shown in FIG14, the i-th node is the second child node of the i-th parent node, and the first sequence number is 2. In this way, the second child node of the i-th matching node can be determined as the corresponding node of the i-th node.
上面对确定M个领域节点中第i个领域节点,在第k个预测参考帧中的对应节点,以及确定当前节点在第k个预测参考帧中的对应节点的确定过程进行介绍。这样,解码端可以采用方式二或方式三的方式,确定出当前节点在预测参考帧中的N个预测节点。The above describes the process of determining the corresponding node of the i-th domain node in the M domain nodes in the k-th prediction reference frame, and determining the corresponding node of the current node in the k-th prediction reference frame. In this way, the decoding end can use the second or third method to determine the N prediction nodes of the current node in the prediction reference frame.
解码端基于上述步骤,在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点后,执行如下S102的步骤。Based on the above steps, the decoding end determines N prediction nodes of the current node in the prediction reference frame of the current frame to be decoded, and then performs the following step S102.
S102、基于N个预测节点中点的几何解码信息,对当前节点中点的位置信息进行预测解码。S102. Based on the geometric decoding information of the midpoints of the N predicted nodes, predict and decode the position information of the midpoint of the current node.
由于点云的相邻帧之间的相关性,本申请实施例基于点云的相邻帧之间的相关性,在对当前节点中点的位置信息进行预测编码时,参照了帧间的相关信息。具体是基于当前节点的N个预测节点中点的几何解码信息,对当前节点中点的微信信息进行预测编码,从而提升点云的编解码效率和编解码性能。Due to the correlation between adjacent frames of the point cloud, the embodiment of the present application refers to the relevant information between frames when predicting the position information of the midpoint of the current node based on the correlation between adjacent frames of the point cloud. Specifically, the WeChat information of the midpoint of the current node is predictively encoded based on the geometric decoding information of the midpoints of the N predicted nodes of the current node, thereby improving the encoding and decoding efficiency and encoding and decoding performance of the point cloud.
在一种示例中,如图16A所示,编码端对当前节点进行直接编码的过程包括:判断当前节点是否具备直接编码资格,若确定当前节点具备直接解码资格时,则将IDCMEligible置为真。接着,判断当前节点所包括的点数是否小于预设阈值,若小于预设阈值,则确定采用直接编码方式对当前节点进行编码,即对当前节点的点数,以及当前节点中点的几何信息进行直接编码。In one example, as shown in FIG16A , the process of the encoder directly encoding the current node includes: determining whether the current node is qualified for direct encoding, and if it is determined that the current node is qualified for direct decoding, setting IDCMEligible to true. Next, determining whether the number of points included in the current node is less than a preset threshold, and if it is less than the preset threshold, determining to encode the current node in a direct encoding manner, that is, directly encoding the number of points of the current node and the geometric information of the midpoint of the current node.
对应的,解码端在对当前节点进行解码时,如图16B所示,解码端首先判断当前节点是否具备直接解码的资格,若解码端确定当前节点具备直接解码资格后,将IDCMEligible置为真。接着,解码当前节点中点的几何信息。Correspondingly, when the decoding end decodes the current node, as shown in FIG16B , the decoding end first determines whether the current node is eligible for direct decoding, and if the decoding end determines that the current node is eligible for direct decoding, it sets IDCMEligible to true. Next, the geometric information of the midpoint of the current node is decoded.
需要说明的是,本申请实施例中,基于N个预测节点的几何解码信息,对当前节点中点的坐标信息进行预测解码,可以理解为将N个预测节点的几何解码信息作为上下文,对当前节点中点的坐标信息进行预测解码。例如,解码端基于N个预测节点的几何解码信息,确定上下文模型的索引,进而基于该上下文模型的索引,从预设的多个上下文模型中,确定出目标上下文模型,并使用该上下文模型,对当前节点中点的坐标信息进行预测解码。It should be noted that, in the embodiment of the present application, predictive decoding of the coordinate information of the midpoint of the current node is performed based on the geometric decoding information of the N predicted nodes, which can be understood as using the geometric decoding information of the N predicted nodes as context to predictively decode the coordinate information of the midpoint of the current node. For example, the decoding end determines the index of the context model based on the geometric decoding information of the N predicted nodes, and then determines the target context model from the preset multiple context models based on the index of the context model, and uses the context model to predictively decode the coordinate information of the midpoint of the current node.
本申请实施例中,基于N个预测节点的几何解码信息,对当前节点中各点的坐标信息进行预测解码的过程基本相同,为了便于描述,在此以对当前节点中的当前点的坐标信息进行预测解码为例进行说明。In an embodiment of the present application, based on the geometric decoding information of N predicted nodes, the process of predicting and decoding the coordinate information of each point in the current node is basically the same. For the sake of ease of description, the predicting and decoding of the coordinate information of the current point in the current node is taken as an example to illustrate.
在一些实施例中,上述S102包括如下步骤:In some embodiments, the above S102 includes the following steps:
S102-A、基于N个预测节点的几何解码信息,确定上下文模型的索引;S102-A, determining an index of a context model based on geometric decoding information of N prediction nodes;
S102-B、基于上下文模型的索引,确定上下文模型;S102-B, determining a context model based on an index of the context model;
S102-C、使用上下文模型,对当前节点中的当前点的坐标信息进行预测解码。S102-C. Use the context model to predict and decode the coordinate information of the current point in the current node.
在本申请实施例中,为坐标信息的解码过程设置多个上下文模型,例如Q个上下文模型,本申请实施例对坐标信息对应的上下文模型的具体个数不做限制,只要保证Q大于1即可。也就是说,在本申请实施例中,至少从2个上下文模型中选择一个最优的上下文模型,对当前节点中的当前点的坐标信息进行预测解码,以提高对当前点的坐标信息的解码效率。In an embodiment of the present application, multiple context models, for example, Q context models, are set for the decoding process of the coordinate information. The embodiment of the present application does not limit the specific number of context models corresponding to the coordinate information, as long as Q is greater than 1. That is to say, in an embodiment of the present application, at least one optimal context model is selected from two context models to predict and decode the coordinate information of the current point in the current node, so as to improve the decoding efficiency of the coordinate information of the current point.
示例性的,坐标信息对应多个上下文模型如表4所示:Exemplarily, the coordinate information corresponds to multiple context models as shown in Table 4:
|
索引 | 上下文模型Context Model | |
| 00 |
上下文模型A |
|
| 11 | 上下文模型BContext Model B | |
| ……… | ……… |
这样,解码端基于N个预测节点的几何解码信息,确定上下文模型的索引。接着,基于该上下文模型的索引,从表4对应的上下文模型中,选出一个上下文模型对当前节点中的当前点的坐标信息进行预测解码。In this way, the decoding end determines the index of the context model based on the geometric decoding information of the N prediction nodes. Then, based on the index of the context model, a context model is selected from the context models corresponding to Table 4 to predict and decode the coordinate information of the current point in the current node.
本申请实施例中预测节点的几何解码信息可以理解为预测节点的几何解码过程中所涉及的任意信息。例如包括预测节点所包括的点数、预测节点的占位信息、预测节点的解码方式、预测节点中点的几何信息等等。In the embodiment of the present application, the geometric decoding information of the prediction node can be understood as any information involved in the geometric decoding process of the prediction node, such as the number of points included in the prediction node, the placeholder information of the prediction node, the decoding method of the prediction node, the geometric information of the midpoint of the prediction node, etc.
在一些实施例中,预测节点的几何解码信息包括预测节点的直接解码信息和/或预测节点中点的坐标信息,其中,预测节点的直接解码信息用于指示预测节点是否满足直接解码方式进行解码的条件。In some embodiments, the geometric decoding information of the prediction node includes direct decoding information of the prediction node and/or coordinate information of a point in the prediction node, wherein the direct decoding information of the prediction node is used to indicate whether the prediction node meets the conditions for decoding in a direct decoding manner.
基于此,上述S102-A包括如下S102-A1的步骤:Based on this, the above S102-A includes the following step S102-A1:
S102-A1、基于N个预测节点的直接解码信息,确定第一上下文索引,和/或基于N个预测节点中点的坐标信息,确定第二上下文索引。S102-A1. Determine a first context index based on direct decoding information of the N prediction nodes, and/or determine a second context index based on coordinate information of midpoints of the N prediction nodes.
对应的,上述S102-B包括如下步骤S102-B的步骤:Correspondingly, the above S102-B includes the following steps S102-B:
S102-B1、基于第一上下文索引和/或第二上下文索引,从预设的多个上下文模型中,选出上下文模型。S102-B1. Select a context model from a plurality of preset context models based on the first context index and/or the second context index.
在该实施例中,若预测节点的几何解码信息包括预测节点的直接解码信息和/或预测节点中点的坐标信息时,则解码端可以基于N个预测节点的直接解码信息,确定第一上下文索引,和/或基于N个预测节点中点的位置信息,确定第二上下文索引,进而基于第一上下文索引和/或第二上下文索引,从预设的多个上下文模型中,选出最终的上下文模 型。In this embodiment, if the geometric decoding information of the prediction node includes direct decoding information of the prediction node and/or coordinate information of the midpoint of the prediction node, the decoding end can determine the first context index based on the direct decoding information of the N prediction nodes, and/or determine the second context index based on the position information of the midpoint of the N prediction nodes, and then select the final context model from the preset multiple context models based on the first context index and/or the second context index.
由此可知,在该实施例中,解码端确定上下文模型的方式包括但不限于如下几种方式:It can be seen that in this embodiment, the decoding end determines the context model in the following ways, including but not limited to:
在一种可能的实现方式中,若预测节点的几何解码信息包括预测节点的直接解码信息时,则确定上下文模型的过程可以是,基于N个预测节点的直接解码信息,确定第一上下文索引,进而基于第一上下文索引,从预设的多个上下文模型中,选出最终的上下文模型对当前点的坐标信息进行解码。In one possible implementation, if the geometric decoding information of the prediction node includes direct decoding information of the prediction node, the process of determining the context model may be to determine a first context index based on the direct decoding information of N prediction nodes, and then based on the first context index, select a final context model from a plurality of preset context models to decode the coordinate information of the current point.
例如,解码端基于第一上下文索引,从表4所示的上下文模型中,选出最终的上下文模型。For example, the decoding end selects the final context model from the context models shown in Table 4 based on the first context index.
在另一种可能的实现方式中,若预测节点的几何解码信息包括预测节点中点的坐标信息时,则确定上下文模型的过程可以是,基于N个预测节点中点的坐标信息,确定第二上下文索引,进而基于第二上下文索引,从预设的多个上下文模型中,选出最终的上下文模型对当前点的坐标信息进行解码。In another possible implementation, if the geometric decoding information of the prediction node includes the coordinate information of the midpoint of the prediction node, the process of determining the context model may be to determine the second context index based on the coordinate information of the midpoints of N prediction nodes, and then based on the second context index, select the final context model from the preset multiple context models to decode the coordinate information of the current point.
例如,解码端基于第二上下文索引,从表4所示的上下文模型中,选出最终的上下文模型。For example, the decoding end selects the final context model from the context models shown in Table 4 based on the second context index.
在另一种可能的实现方式中,若预测节点的几何解码信息包括预测节点的直接解码信息和预测节点中点的坐标信息时,则确定上下文模型的过程可以是,基于N个预测节点的直接解码信息,确定第一上下文索引,进而基于第一上下文索引,基于N个预测节点中点的坐标信息,确定第二上下文索引,进而基于第二上下文索引,基于第一上下文索引和第二上下文索引,从预设的多个上下文模型中,选出最终的上下文模型对当前点的坐标信息进行解码。In another possible implementation, if the geometric decoding information of the prediction node includes direct decoding information of the prediction node and coordinate information of the midpoint of the prediction node, the process of determining the context model may be to determine a first context index based on the direct decoding information of N prediction nodes, and then determine a second context index based on the first context index and the coordinate information of the midpoint of the N prediction nodes, and then select a final context model from a plurality of preset context models based on the second context index, the first context index and the second context index to decode the coordinate information of the current point.
示例性的,第一上下文索引、第二上下文索引和上下文模型的对应关系如表5所示:Exemplarily, the correspondence between the first context index, the second context index and the context model is shown in Table 5:
表5table 5
|
第二上下文索引1 |
第二上下文索引2 |
第二上下文索引3 |
……… | |
|
第一上下文索引1 |
上下文模型11 |
上下文模型12 |
上下文模型13 |
……… |
|
第一上下文索引2 |
上下文模型21 |
上下文模型22 |
上下文模型23 |
……… |
|
第一上下文索引3 |
上下文模型31 |
上下文模型32Context Model 32 |
上下文模型33 |
……… |
| ……… | ……… | ……… | ……… | ……… |
在该方式3中,解码端基于N个预测节点的直接解码信息,确定出第一上下文索引,以及基于N个预测节点中点的坐标信息,确定出第二上下文索引后,查上述表5,得到最终的上下文文模型。例如,解码端基于N个预测节点的直接解码信息,确定出第一上下文索引为第一上下文索引2,基于N个预测节点中点的坐标信息,确定出第二上下文索引为第二上下文索引3,这样查表5,可以得到最终的上下文模型为上下文模型23,进而解码端使用上下文模型23对当前点的坐标信息进行解码。In this mode 3, the decoding end determines the first context index based on the direct decoding information of the N prediction nodes, and determines the second context index based on the coordinate information of the midpoints of the N prediction nodes, and then checks the above table 5 to obtain the final context model. For example, the decoding end determines that the first context index is the first context index 2 based on the direct decoding information of the N prediction nodes, and determines that the second context index is the second context index 3 based on the coordinate information of the midpoints of the N prediction nodes. In this way, by checking Table 5, the final context model can be obtained as context model 23, and then the decoding end uses context model 23 to decode the coordinate information of the current point.
下面对S102-A1中基于N个预测节点的直接解码信息,确定第一上下文索引的具体过程进行介绍。The specific process of determining the first context index based on the direct decoding information of the N prediction nodes in S102-A1 is introduced below.
本申请实施例中,解码端确定第一上下文索引的方式包括但不限于如下几种:In the embodiment of the present application, the decoding end determines the first context index in the following ways, but is not limited to:
方式一,上述S102-A1包括如下S102-A1-11和S102-A1-12的步骤:Method 1: the above S102-A1 includes the following steps S102-A1-11 and S102-A1-12:
S102-A1-11、针对N个预测节点中的任一预测节点,基于预测节点的直接解码信息,确定预测节点对应的第一数值。S102-A1-11. For any prediction node among the N prediction nodes, determine a first value corresponding to the prediction node based on direct decoding information of the prediction node.
在该方式中,针对N个预测节点中的每一个预测节点,基于该预测节点的直接解码信息,确定该预测节点对应的第一数值,最后基于N个预测节点对应的第一数值,确定第一上下文索引。In this manner, for each of the N prediction nodes, a first value corresponding to the prediction node is determined based on direct decoding information of the prediction node, and finally a first context index is determined based on the first values corresponding to the N prediction nodes.
下面对确定预测节点对应的第一数值的过程进行介绍。The following describes the process of determining the first value corresponding to the prediction node.
由上述可知,预测节点的直接解码信息用于指示该预测节点是否满足直接解码方式进行解码的条件。本申请实施例对直接解码信息的具体内容不做限制。As can be seen from the above, the direct decoding information of the prediction node is used to indicate whether the prediction node meets the conditions for decoding in the direct decoding manner. The embodiment of the present application does not limit the specific content of the direct decoding information.
在一些实施例中,直接解码信息包括预测节点所包括的点数。这样,可以基于预测节点所包括的点数,确定预测节点对应的第一数值。In some embodiments, the direct decoding information includes the number of points included in the prediction node. In this way, the first value corresponding to the prediction node can be determined based on the number of points included in the prediction node.
在一种示例中,在GPCC框架下,预测节点所包括的点数大于或等于2时,则确定预测节点对应的第一数值为1,若预测节点所包括的点数小于2时,则确定预测节点对应的第一数值为0。在AVS框架下,预测节点所包括的点数大于或等于1时,则确定预测节点对应的第一数值为1,若预测节点所包括的点数小于1时,则确定预测节点对应的第一数值为0。In one example, in the GPCC framework, when the number of points included in the prediction node is greater than or equal to 2, the first value corresponding to the prediction node is determined to be 1, and if the number of points included in the prediction node is less than 2, the first value corresponding to the prediction node is determined to be 0. In the AVS framework, when the number of points included in the prediction node is greater than or equal to 1, the first value corresponding to the prediction node is determined to be 1, and if the number of points included in the prediction node is less than 1, the first value corresponding to the prediction node is determined to be 0.
在另一种示例中,将预测节点所包括的点数,确定为该预测节点对应的第一数值,例如该预测节点包括2个点时,则确定该预测节点对应的第一数值为2。In another example, the number of points included in the prediction node is determined as the first value corresponding to the prediction node. For example, when the prediction node includes 2 points, the first value corresponding to the prediction node is determined to be 2.
在一些实施例中,预测节点的直接解码信息包括预测节点的直接解码模式,此时,上述S102-A1-11包括:将预测节点的直接解码模式的编号,确定预测节点对应的第一数值。In some embodiments, the direct decoding information of the prediction node includes the direct decoding mode of the prediction node. In this case, the above S102-A1-11 includes: numbering the direct decoding mode of the prediction node and determining the first value corresponding to the prediction node.
例如,在GPCC框架下,若预测节点的直接解码模式为模式0时,则确定该预测节点对应的第一数值为0。若预测节点的直接解码模式为模式1时,则确定该预测节点对应的第一数值为1。若预测节点的直接解码模式为模式2时,则确定该预测节点对应的第一数值为2。For example, in the GPCC framework, if the direct decoding mode of the prediction node is mode 0, the first value corresponding to the prediction node is determined to be 0. If the direct decoding mode of the prediction node is mode 1, the first value corresponding to the prediction node is determined to be 1. If the direct decoding mode of the prediction node is mode 2, the first value corresponding to the prediction node is determined to be 2.
再例如,在AVS框架下,若预测节点的直接解码模式为模式0时,则确定该预测节点对应的第一数值为0。若预测节点的直接解码模式为模式1时,则确定该预测节点对应的第一数值为1。For another example, in the AVS framework, if the direct decoding mode of the prediction node is mode 0, the first value corresponding to the prediction node is determined to be 0. If the direct decoding mode of the prediction node is mode 1, the first value corresponding to the prediction node is determined to be 1.
基于上述步骤,解码端确定出N个预测节点中每一个预测节点对应的第一数值后,执行如下S102-A1-12的步骤。Based on the above steps, after the decoding end determines the first value corresponding to each of the N prediction nodes, the following step S102-A1-12 is executed.
S102-A1-12、基于N个预测节点对应的第一数值,确定第一上下文索引。S102-A1-12. Determine a first context index based on first numerical values corresponding to the N prediction nodes.
解码端基于上述步骤,确定出N个预测节点对应的第一数值后,基于N个预测节点对应的第一数值,确定第一上下文索引。After the decoding end determines the first values corresponding to the N prediction nodes based on the above steps, it determines the first context index based on the first values corresponding to the N prediction nodes.
其中,基于N个预测节点对应的第一数值,确定第一上下文索引至少包括如下实现方式:Wherein, determining the first context index based on the first values corresponding to the N prediction nodes includes at least the following implementation methods:
方式1,将N个预测节点对应的第一数值之和的平均值,确定为第一上下文索引。Method 1: Determine the average value of the sum of the first numerical values corresponding to the N prediction nodes as the first context index.
方式2,S102-A1-12包括如下S102-A1-121至S102-A1-123的步骤: Mode 2, S102-A1-12 includes the following steps S102-A1-121 to S102-A1-123:
S102-A1-121、确定预测节点对应的第一权重;S102-A1-121, determine a first weight corresponding to the prediction node;
S102-A1-122、基于第一权重,对N个预测节点对应的第一数值进行加权处理,得到第一加权预测值;S102-A1-122, based on the first weight, weighting the first values corresponding to the N prediction nodes to obtain a first weighted prediction value;
S102-A1-123、基于第一加权预测值,确定第一上下文索引。S102-A1-123. Determine a first context index based on the first weighted prediction value.
在该方式2中,若当前节点包括多个预测节点,即N个预测节点时,在基于N个预测节点对应的第一数值确定第一上下文索引时,可以为N个预测节点中的每一个预测节点确定一个权重,即第一权重,这样可以基于各预测节点的第一权重,对各预测节点对应的第一数值进行加权处理,进而根据最终的加权结果,确定第一上下文索引,从而提高了基于N个预测节点的几何解码信息,确定第一上下文索引的准确性。In method 2, if the current node includes multiple prediction nodes, i.e., N prediction nodes, when determining the first context index based on the first numerical values corresponding to the N prediction nodes, a weight, i.e., the first weight, can be determined for each of the N prediction nodes. In this way, the first numerical values corresponding to each prediction node can be weighted based on the first weight of each prediction node, and then the first context index can be determined based on the final weighted result, thereby improving the accuracy of determining the first context index based on the geometric decoding information of the N prediction nodes.
本申请实施例对确定N个预测节点分别对应的第一权重不做限制。The embodiment of the present application does not limit the determination of the first weights corresponding to the N prediction nodes.
在一些实施例中,上述N个预测节点中各预测节点对应的第一权重为预设值。由上述可知,上述N个预测节点是基于当前节点的M个领域节点确定的,假设预测节点1为领域节点1对应的预测节点,若领域节点1为当前节点的共面节点时,则预测节点1的第一权重为预设权重1,若领域节点1为当前节点的共线节点时,则预测节点1的第一权重为预设权重2,若领域节点1为当前节点的共点节点时,则预测节点1的第一权重为预设权重3。In some embodiments, the first weight corresponding to each prediction node in the above-mentioned N prediction nodes is a preset value. As can be seen from the above, the above-mentioned N prediction nodes are determined based on the M domain nodes of the current node. Assuming that prediction node 1 is the prediction node corresponding to domain node 1, if domain node 1 is a coplanar node of the current node, the first weight of prediction node 1 is the preset weight 1, if domain node 1 is a colinear node of the current node, the first weight of prediction node 1 is the preset weight 2, and if domain node 1 is a co-point node of the current node, the first weight of prediction node 1 is the preset weight 3.
在一些实施例中,对于N个预测节点中的每一个预测节点,基于该预测节点对应的领域节点与当前节点之间的距离,确定该预测节点对应的第一权重。例如,领域节点与当前节点之间的距离越小,则该领域节点对应的预测节点与当前节点的帧间相关性越强,进而该预测节点的第一权重越大。In some embodiments, for each of the N prediction nodes, a first weight corresponding to the prediction node is determined based on the distance between the domain node corresponding to the prediction node and the current node. For example, the smaller the distance between the domain node and the current node, the stronger the inter-frame correlation between the prediction node corresponding to the domain node and the current node, and thus the greater the first weight of the prediction node.
举例说明,以N个预测节点中的预测节点1为例,假设预测节点1为当前节点的M个领域节点中领域节点1在预测参考帧中的对应点,这样可以基于领域节点1与当前节点之间的距离,确定预测节点1的第一权重。例如,将领域节点1与当前节点之间的距离的倒数,确定为预测节点1的第一权重。For example, taking prediction node 1 among N prediction nodes as an example, assuming that prediction node 1 is the corresponding point of domain node 1 among M domain nodes of the current node in the prediction reference frame, the first weight of prediction node 1 can be determined based on the distance between domain node 1 and the current node. For example, the inverse of the distance between domain node 1 and the current node is determined as the first weight of prediction node 1.
在一种示例中,若领域节点1为当前节点的共面节点时,则预测节点1的第一权重为1,若领域节点1为当前节点的共线节点时,则预测节点1的第一权重为预设权重
 若领域节点1为当前节点的共点节点时,则预测节点1的第一权重为预设权重
若领域节点1为当前节点的共点节点时,则预测节点1的第一权重为预设权重
 In one example, if
In one example, if domain node 1 is a coplanar node of the current node, the first weight of the predicted node 1 is 1; if domain node 1 is a colinear node of the current node, the first weight of the predicted node 1 is a preset weight. If domain node 1 is a common node of the current node, the first weight of predicted node 1 is the preset weight
在一种示例中,若领域节点1为当前节点的共面节点时,则预测节点1的第一权重为
 若领域节点1为当前节点的共线节点时,则预测节点1的第一权重为预设权重
若领域节点1为当前节点的共线节点时,则预测节点1的第一权重为预设权重
 若领域节点1为当前节点的共点节点时,则预测节点1的第一权重为预设权重
若领域节点1为当前节点的共点节点时,则预测节点1的第一权重为预设权重
 In one example, if
In one example, if domain node 1 is a coplanar node of the current node, the first weight of predicted node 1 is If domain node 1 is a collinear node of the current node, the first weight of predicted node 1 is the preset weight If domain node 1 is a common node of the current node, the first weight of predicted node 1 is the preset weight
在一些实施例中,基于上述步骤,确定出N个预测节点中各预测节点对应的权重后,对该权重进行归一化处理,将归一化处理后的权重作出预测节点的最终第一权重。In some embodiments, based on the above steps, after the weight corresponding to each prediction node in the N prediction nodes is determined, the weight is normalized, and the normalized weight is used as the final first weight of the prediction node.
本申请实施例对基于第一权重,对N个预测节点对应的第一数值进行加权处理,得到第一加权预测值的具体方式不做限制。The embodiment of the present application does not limit the specific method of obtaining the first weighted prediction value by weighting the first numerical values corresponding to N prediction nodes based on the first weight.
在一种示例中,基于第一权重,对N个预测节点对应的第一数值进行加权平均,得到第一加权预测值。In one example, based on the first weight, a weighted average is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value.
在另一种示例中,基于第一权重,对N个预测节点对应的第一数值进行加权求和,得到第一加权预测值。In another example, based on the first weight, a weighted sum is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value.
基于方式步骤,确定出第一加权预测值后,基于该第一加权预测值,确定第一上下文索引,即上述S102-A1-123至少包括如下几种示例:After determining the first weighted prediction value based on the method steps, the first context index is determined based on the first weighted prediction value, that is, the above S102-A1-123 includes at least the following examples:
示例1,将第一加权预测值,确定为第一上下文索引。Example 1: Determine the first weighted prediction value as the first context index.
示例2,确定第一加权预测值所在加权预测值范围,将该范围对应的索引,确定为第一上下文索引。Example 2: Determine the weighted prediction value range in which the first weighted prediction value is located, and determine the index corresponding to the range as the first context index.
上述以解码端对N个预测节点进行加权处理,得到第一上下文索引的过程进行介绍。The above is an introduction to the process in which the decoding end performs weighted processing on N prediction nodes to obtain the first context index.
在一些实施例中,解码端还可以采用如下方式二,确定第一上下文索引。In some embodiments, the decoding end may also adopt the following method 2 to determine the first context index.
方式二、若K大于1时,确定K个预测参考帧中每一个预测参考帧对应的第二加权预测值,进而基于K个预测参考帧分别对应的第二加权预测值,确定第一上下文索引。此时,上述S102-A1包括如下S102-A1-21至S102-A1-23的步骤:Method 2: if K is greater than 1, determine the second weighted prediction value corresponding to each of the K prediction reference frames, and then determine the first context index based on the second weighted prediction values corresponding to the K prediction reference frames. At this time, the above S102-A1 includes the following steps S102-A1-21 to S102-A1-23:
S102-A1-21、针对K个预测参考帧中的第j个预测参考帧,基于当前节点在第j个预测参考帧中的预测节点的直接解码信息,确定第j个预测参考帧中的预测节点对应的第一数值,j为小于或等于K的正整数;S102-A1-21. For a j-th prediction reference frame among the K prediction reference frames, determine a first value corresponding to the prediction node in the j-th prediction reference frame based on direct decoding information of the prediction node of the current node in the j-th prediction reference frame, where j is a positive integer less than or equal to K.
S102-A1-22、确定预测节点对应的第一权重,并基于第一权重对第j个预测参考帧中的预测节点对应的第一数值进行加权处理,得到第j个预测参考帧对应的第二加权预测值;S102-A1-22, determining a first weight corresponding to the prediction node, and performing weighted processing on the first value corresponding to the prediction node in the j-th prediction reference frame based on the first weight, to obtain a second weighted prediction value corresponding to the j-th prediction reference frame;
S102-A1-23、基于K个预测参考帧对应的第二加权预测值,确定第一上下文索引。S102-A1-23. Determine a first context index based on second weighted prediction values corresponding to K prediction reference frames.
在该方式二中,在确定第一上下文索引时,对这K个预测参考帧中的每一个预测参考帧作为单独的上下文信息分别进行考虑。具体是,确定K个预测参考帧中每一个预测参考帧所包括的预测节点的直接解码信息,确定每一个预测参考帧对应的第二加权预测值,进而基于每一个预测参考帧对应的第二加权预测值,确定第一上下文索引,实现第一上下文索引的准确选择,进而提升点云的解码效率。In the second method, when determining the first context index, each of the K prediction reference frames is considered as separate context information. Specifically, the direct decoding information of the prediction node included in each of the K prediction reference frames is determined, and the second weighted prediction value corresponding to each prediction reference frame is determined, and then based on the second weighted prediction value corresponding to each prediction reference frame, the first context index is determined to achieve accurate selection of the first context index, thereby improving the decoding efficiency of the point cloud.
本申请实施例中,解码端确定K个预测参考帧中每一个预测参考帧对应的第二加权预测值的具体方式相同,为了便于描述,在此以K个预测参考帧中的第j个预测参考帧为例进行说明。In the embodiment of the present application, the specific method in which the decoding end determines the second weighted prediction value corresponding to each of the K prediction reference frames is the same. For the sake of ease of description, the jth prediction reference frame among the K prediction reference frames is taken as an example for explanation.
在本申请实施例中,当前节点在第j个预测参考帧中包括至少一个预测节点,这样基于该第j个预测参考帧中的这至少一个预测节点的直接解码信息,确定这至少一个预测节点的第一数值。In an embodiment of the present application, the current node includes at least one prediction node in the jth prediction reference frame, so that the first value of the at least one prediction node is determined based on the direct decoding information of the at least one prediction node in the jth prediction reference frame.
举例说明,第j个预测参考帧中包括当前节点的2个预测节点,分别记为预测节点1和预测节点2,进而基于预测节点1的直接解码信息,确定预测节点1的第一数值,基于预测节点2的直接解码信息,确定预测节点2的第一数值。其中,基于预测节点的直接解码信息,确定预测节点对应的第一数值的过程可以参照上述实施例的描述,示例性的基于预测节点的直接解码模式,确定预测节点对应的第一数值,例如,将预测节点的直接解码模式的编号(0、1或2)确定为该预测节点对应的第一数值。For example, the j-th prediction reference frame includes two prediction nodes of the current node, which are respectively recorded as prediction node 1 and prediction node 2, and then the first value of prediction node 1 is determined based on the direct decoding information of prediction node 1, and the first value of prediction node 2 is determined based on the direct decoding information of prediction node 2. The process of determining the first value corresponding to the prediction node based on the direct decoding information of the prediction node can refer to the description of the above embodiment, and the first value corresponding to the prediction node is determined based on the direct decoding mode of the prediction node, for example, the number (0, 1 or 2) of the direct decoding mode of the prediction node is determined as the first value corresponding to the prediction node.
解码端确定出第j个预测参考帧所包括的至少一个预测节点的第一数值后,确定这至少一个预测节点分别对应的 第一权重,并基于第一权重对这至少一个预测节点对应的第一数值进行加权处理,得到第j个预测参考帧对应的第二加权预测值。After the decoding end determines the first value of at least one prediction node included in the j-th prediction reference frame, it determines the first weight corresponding to the at least one prediction node, and weightedly processes the first value corresponding to the at least one prediction node based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
在一种示例中,基于第一权重,对第j个预测参考帧中的预测节点对应的第一数值进行加权平均,得到第j个预测参考帧对应的第二加权预测值。In one example, based on the first weight, a weighted average is performed on the first values corresponding to the prediction nodes in the j-th prediction reference frame to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
在另一种示例中,基于第一权重,对第j个预测参考帧中的预测节点对应的第一数值进行加权求和,得到第j个预测参考帧对应的第二加权预测值。In another example, based on the first weight, a weighted sum is performed on the first numerical values corresponding to the prediction nodes in the j-th prediction reference frame to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
其中,第一权重的确定过程可以参照上述实施例的描述,在此不再赘述。The process of determining the first weight may refer to the description of the above embodiment and will not be repeated here.
上述对确定K个预测参考帧中第j个预测参考帧对应的第二加权预测值的过程进行介绍,K个预测参考帧中其他预测参考帧对应的第二加权预测值参照上述第j个预测参考帧对应的方式进行确定。The above introduces the process of determining the second weighted prediction value corresponding to the j-th prediction reference frame among the K prediction reference frames. The second weighted prediction values corresponding to other prediction reference frames among the K prediction reference frames are determined in accordance with the method corresponding to the j-th prediction reference frame.
解码端确定出K个预测参考帧中每一个预测参考帧对应的第二加权预测值后,执行上述S102-A1-23的步骤。After the decoding end determines the second weighted prediction value corresponding to each of the K prediction reference frames, it executes the above step S102-A1-23.
本申请实施对基于K个预测参考帧对应的第二加权预测值,确定第一上下文索引的具体方式不做限制。The present application does not limit the specific method of determining the first context index based on the second weighted prediction value corresponding to K prediction reference frames.
在一些实施例中,解码端将K个预测参考帧对应的第二加权预测值的平均值,确定为第一上下文索引。In some embodiments, the decoding end determines an average value of the second weighted prediction values corresponding to the K prediction reference frames as the first context index.
在一些实施例中,解码端确定K个预测参考帧对应的第二权重,并基于第二权重对K个预测参考帧对应的第二加权预测值进行加权处理,得到第一上下文索引。In some embodiments, the decoding end determines second weights corresponding to K predicted reference frames, and performs weighted processing on second weighted prediction values corresponding to the K predicted reference frames based on the second weights to obtain a first context index.
在该实施例中,解码端首先确定K个预测参考帧中每一个预测参考帧对应的第二权重。本申请实施例对确定K个预测参考帧中每一个预测参考帧对应的第二权重不做限制。In this embodiment, the decoding end first determines the second weight corresponding to each of the K prediction reference frames. The embodiment of the present application does not limit the determination of the second weight corresponding to each of the K prediction reference frames.
在一些实施例中,上述K个预测参考帧中每一个预测参考帧对应的第二权重为预设值。由上述可知,上述K个预测参考帧为当前待解码帧的前向帧和/或后向帧。假设预测参考帧1为当前待解码帧的前向帧时,则预测参考帧1对应的第二权重为预设权重1,若预测参考帧1为当前待解码帧的后向帧时,则预测参考帧1对应的第二权重为预设权重2。In some embodiments, the second weight corresponding to each of the K predicted reference frames is a preset value. As can be seen from the above, the K predicted reference frames are forward frames and/or backward frames of the current frame to be decoded. Assuming that predicted reference frame 1 is the forward frame of the current frame to be decoded, the second weight corresponding to predicted reference frame 1 is the preset weight 1. If predicted reference frame 1 is the backward frame of the current frame to be decoded, the second weight corresponding to predicted reference frame 1 is the preset weight 2.
在一些实施例中,基于预测参考帧与当前待解码帧的时间差距,确定预测参考帧对应的第二权重。在本申请实施例中,每一张点云包括时间信息,该时间信息可以为点云采集设备采集该帧点云时的时间。基于此,若预测参考帧与当前待解码帧的时间差距越小,则该预测参考帧与当前待解码帧的帧间相关性越强,进而该预测参考帧对应的第二权重越大。例如,可以将预测参考帧与当前待解码帧的时间差距的倒数确定为该预测参考帧对应的第二权重。In some embodiments, based on the time difference between the predicted reference frame and the current frame to be decoded, the second weight corresponding to the predicted reference frame is determined. In an embodiment of the present application, each point cloud includes time information, and the time information may be the time when the point cloud acquisition device acquires the point cloud of the frame. Based on this, if the time difference between the predicted reference frame and the current frame to be decoded is smaller, the inter-frame correlation between the predicted reference frame and the current frame to be decoded is stronger, and thus the second weight corresponding to the predicted reference frame is larger. For example, the inverse of the time difference between the predicted reference frame and the current frame to be decoded can be determined as the second weight corresponding to the predicted reference frame.
确定出K个预测参考帧中每一个预测参考帧对应的第二权重后,基于第二权重对K个预测参考帧分别对应的第二加权预测值进行加权处理,得到第一上下文索引。After determining the second weight corresponding to each of the K prediction reference frames, weighted processing is performed on the second weighted prediction values respectively corresponding to the K prediction reference frames based on the second weight to obtain a first context index.
举例说明,假设K=2,例如当前待解码帧包括2个预测参考帧,这2个预测参考帧包括当前待解码帧的前向帧和后向帧,假设前向帧对应的第二权重为W1、后向帧对应的第二权重为W2,这样基于W1和W2,对前向帧对应的第二加权预测值和后向帧对应的第二加权预测值进行加权,得到第一上下文索引。For example, assuming K=2, for example, the current frame to be decoded includes 2 prediction reference frames, and these 2 prediction reference frames include the forward frame and backward frame of the current frame to be decoded. Assuming that the second weight corresponding to the forward frame is W1, and the second weight corresponding to the backward frame is W2, based on W1 and W2, the second weighted prediction value corresponding to the forward frame and the second weighted prediction value corresponding to the backward frame are weighted to obtain the first context index.
在一种示例中,基于第二权重,对K个预测参考帧分别对应的第二加权预测值进行加权平均,得到第一上下文索引。In one example, based on the second weight, weighted averaging is performed on the second weighted prediction values corresponding to the K prediction reference frames to obtain the first context index.
在另一种示例中,基于第二权重,对K个预测参考帧分别对应的第二加权预测值进行加权求和,得到第一上下文索引。In another example, based on the second weight, the second weighted prediction values corresponding to the K prediction reference frames are weighted summed to obtain the first context index.
上文对解码端确定第一上下文索引的过程进行介绍。The above describes the process of determining the first context index at the decoding end.
下面对解码端确定第二上下文索引的过程进行介绍。The following introduces the process of determining the second context index at the decoding end.
由上述确定预测节点的过程可知,N个预测节点中的每一个预测节点包括一个点或多个点,若N个预测节点中各预测节点包括一个点时,则使用各预测节点所包括的一个点,确定第二上下文索引。From the above process of determining the prediction node, it can be seen that each of the N prediction nodes includes one point or multiple points. If each of the N prediction nodes includes one point, the second context index is determined using one point included in each prediction node.
在一些实施例中,若预测节点中包括多个点时,则从这多个点中选择一个点来确定第二上下文索引。此时,上述S102-A1包括如下S102-A1-31和S102-A1-32的步骤:In some embodiments, if the prediction node includes multiple points, a point is selected from the multiple points to determine the second context index. In this case, the above S102-A1 includes the following steps S102-A1-31 and S102-A1-32:
S102-A1-31、对于N个预测节点中的任一预测节点,从预测节点所包括的点中,选出当前节点的当前点对应的第一点;S102-A1-31, for any prediction node among the N prediction nodes, select a first point corresponding to the current point of the current node from the points included in the prediction node;
S102-A1-32、基于N个预测节点所包括的第一点的坐标信息,确定第二上下文索引。S102-A1-32. Determine a second context index based on the coordinate information of the first point included in the N prediction nodes.
举例说明,假设N个预测节点包括预测节点1和预测节点2,其中预测节点1中包括点1和点2,预测节点2包括点3、点4和点5,则从预测节点1所包括的点1和点2中选出一个点作为第一点,从预测节点2所包括的点3、点4和点5中选出一个点作为第一点。这样可以基于预测节点1中的第一点和预测节点2中的第一点的几何信息,确定当前点的几何信息。For example, assuming that N prediction nodes include prediction node 1 and prediction node 2, where prediction node 1 includes point 1 and point 2, and prediction node 2 includes point 3, point 4, and point 5, then one point is selected as the first point from point 1 and point 2 included in prediction node 1, and one point is selected as the first point from point 3, point 4, and point 5 included in prediction node 2. In this way, the geometric information of the current point can be determined based on the geometric information of the first point in prediction node 1 and the first point in prediction node 2.
本申请实施例对从预测节点所包括的点中,选出当前节点的当前点对应的第一点的具体方式不做限制。The embodiment of the present application does not limit the specific method of selecting the first point corresponding to the current point of the current node from the points included in the prediction node.
在一种可能的实现方式中,将预测节点中与当前点的顺序一致的点,确定为当前点对应的第一点。举例说明,假设当前点为当前节点中的第2个点,这样可以将预测节点1中的点2确定为当前点对应的第一点,将预测节点2中的点4确定为当前点对应的第一点。再例如,若预测节点只包括一个点时,则将预测节点所包括的该点确定为当前点对应的第一点。In a possible implementation, the points in the prediction node that are in the same order as the current point are determined as the first point corresponding to the current point. For example, assuming that the current point is the second point in the current node, point 2 in prediction node 1 can be determined as the first point corresponding to the current point, and point 4 in prediction node 2 can be determined as the first point corresponding to the current point. For another example, if the prediction node includes only one point, the point included in the prediction node is determined as the first point corresponding to the current point.
在一种可能的实现方式中,若编码端基于率失真代价(或近似代价),从预测节点所包括的点中,选出当前点对应的第一点时,编码端将预测节点中的第一点的标识信息写入码流,这样解码端通过解码码流,得到预测节点中的第一点。In one possible implementation, if the encoder selects the first point corresponding to the current point from the points included in the prediction node based on the rate-distortion cost (or approximate cost), the encoder writes the identification information of the first point in the prediction node into the bitstream, so that the decoder obtains the first point in the prediction node by decoding the bitstream.
解码端对于N个预测节点中的每一个预测节点,基于上述方法,确定出各预测节点中当前点对应的第一点,进而执行上述S102-A1-32的步骤。For each of the N prediction nodes, the decoding end determines the first point corresponding to the current point in each prediction node based on the above method, and then executes the above step S102-A1-32.
在本申请实施例中,解码端对当前点在不同坐标轴上的坐标信息进行分别编码,基于,则上述S102-A1-32包括如下S102-A1-321的步骤:In the embodiment of the present application, the decoding end encodes the coordinate information of the current point on different coordinate axes respectively. Based on, the above S102-A1-32 includes the following step S102-A1-321:
S102-A1-321、基于N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。S102-A1-321. Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis.
上述第i个坐标轴可以是X轴、Y轴或Z轴,本申请实施例对此不做限制。The above-mentioned i-th coordinate axis can be the X-axis, the Y-axis or the Z-axis, and this embodiment of the present application does not limit this.
在一些实施例中,若上述点云为激光雷达点云则,则由上述可知,第i个坐标轴为X轴或Y轴。In some embodiments, if the above point cloud is a lidar point cloud, then it can be seen from the above that the i-th coordinate axis is the X-axis or the Y-axis.
在一些实施例中,若上述点云为面向人眼点云时,则由上述可知,第i个坐标轴可以为X轴、Y轴或Z轴中的任意一个坐标轴。In some embodiments, if the point cloud is a point cloud facing the human eye, it can be known from the above that the i-th coordinate axis can be any one of the X-axis, Y-axis or Z-axis.
在本申请实施例中,解码端对当前点在第i个坐标轴上的坐标信息进行解码时,则基于N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。这样可以基于第一上下文索引和/或第i个坐标轴对应的第二上下文索引,从多个上下文模型中,选出第i个坐标轴对应的上下文模型,进而使用第i个坐标轴对应的上下文模型,对当前点在第i个坐标轴上的坐标信息进行预测解码。例如,解码端基于N个预测节点所包括的第一点在X轴上的坐标信息,确定X轴对应的第二上下文索引,并基于第一上下文索引和/或X轴对应的第二上下文索引,从多个上下文模型中,选出X轴对应的上下文模型,进而使用X轴对应的上下文模型,对当前点在X轴上的坐标信息进行预测解码,得到当前点的X坐标值。再例如,解码端基于N个预测节点所包括的第一点在Y轴上的坐标信息,确定Y轴对应的第二上下文索引,并基于第一上下文索引和/或Y轴对应的第二上下文索引,从多个上下文模型中,选出Y轴对应的上下文模型,进而使用Y轴对应的上下文模型,对当前点在Y轴上的坐标信息进行预测解码,得到当前点的Y坐标值。In an embodiment of the present application, when the decoding end decodes the coordinate information of the current point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined based on the coordinate information of the first point on the i-th coordinate axis included in the N prediction nodes. In this way, the context model corresponding to the i-th coordinate axis can be selected from multiple context models based on the first context index and/or the second context index corresponding to the i-th coordinate axis, and then the context model corresponding to the i-th coordinate axis is used to predict and decode the coordinate information of the current point on the i-th coordinate axis. For example, the decoding end determines the second context index corresponding to the X-axis based on the coordinate information of the first point on the X-axis included in the N prediction nodes, and selects the context model corresponding to the X-axis from multiple context models based on the first context index and/or the second context index corresponding to the X-axis, and then uses the context model corresponding to the X-axis to predict and decode the coordinate information of the current point on the X-axis to obtain the X coordinate value of the current point. For another example, the decoding end determines the second context index corresponding to the Y-axis based on the coordinate information of the first point on the Y-axis included in the N prediction nodes, and based on the first context index and/or the second context index corresponding to the Y-axis, selects the context model corresponding to the Y-axis from multiple context models, and then uses the context model corresponding to the Y-axis to predict and decode the coordinate information of the current point on the Y-axis to obtain the Y coordinate value of the current point.
下面对解码端基于N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引的过程进行介绍。The following introduces a process of determining the second context index corresponding to the i-th coordinate axis at the decoding end based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis.
本申请实施例中,上述S102-A1-321的实现方式包括但不限于如下几种:In the embodiment of the present application, the implementation methods of the above S102-A1-321 include but are not limited to the following:
方式一,对N个预测节点所包括的第一点进行加权,基于加权后的坐标信息,确定第i个坐标轴对应的第二上下文索引。此时,上述S102-A1-321包括如下S102-A1-321-11至S102-A1-321-13的步骤:Method 1: weight the first points included in the N prediction nodes, and determine the second context index corresponding to the i-th coordinate axis based on the weighted coordinate information. At this time, the above S102-A1-321 includes the following steps S102-A1-321-11 to S102-A1-321-13:
S102-A1-321-11、确定预测节点对应的第一权重;S102-A1-321-11, determine a first weight corresponding to the prediction node;
S102-A1-321-12、基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点;S102-A1-321-12, based on the first weight, weighting the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point;
S102-A1-321-13、基于第一加权点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。S102-A1-321-13. Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the first weighted point on the i-th coordinate axis.
在该方式一中,若当前节点包括多个预测节点,即N个预测节点时,在基于N个预测节点所包括的第一点的坐标信息,确定第i个坐标轴对应的第二上下文索引时,可以为N个预测节点中的每一个预测节点确定一个权重,即第一权重。这样可以基于各预测节点的第一权重,对各预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点,进而根据第一加权点在第i个坐标轴上坐标信息,确定第i个坐标轴对应的第二上下文索引,从而提高了基于N个预测节点的几何解码信息,对当前点进行解码的准确性。In the first mode, if the current node includes multiple prediction nodes, that is, N prediction nodes, when determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes, a weight, that is, the first weight, can be determined for each of the N prediction nodes. In this way, based on the first weight of each prediction node, the coordinate information of the first point included in each prediction node can be weighted to obtain a first weighted point, and then the second context index corresponding to the i-th coordinate axis can be determined based on the coordinate information of the first weighted point on the i-th coordinate axis, thereby improving the accuracy of decoding the current point based on the geometric decoding information of the N prediction nodes.
本申请实施例对确定N个预测节点分别对应的第一权重的过程可以参照上述实施例的描述,在此不再赘述。The process of determining the first weights corresponding to the N prediction nodes respectively in the embodiment of the present application can refer to the description of the above embodiment, which will not be repeated here.
解码端确定出N个预测节点中每一个预测节点对应的第一权重后,基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点。After the decoding end determines the first weight corresponding to each of the N prediction nodes, based on the first weight, the coordinate information of the first point included in the N prediction nodes is weighted to obtain a first weighted point.
本申请实施例对基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点的具体方式不做限制。The embodiment of the present application does not limit the specific method of obtaining the first weighted point by weighted processing the coordinate information of the first point included in the N prediction nodes based on the first weight.
在一种示例中,基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权平均,得到第一加权点。In one example, based on the first weight, the coordinate information of the first point included in the N prediction nodes is weighted averaged to obtain a first weighted point.
基于方式步骤,确定出第一加权点后,基于第一加权点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。Based on the method steps, after the first weighted point is determined, the second context index corresponding to the i-th coordinate axis is determined based on the coordinate information of the first weighted point on the i-th coordinate axis.
由上述可知,第一加权点是对N个预测节点中的第一点进行加权得到,其中预测节点后的第一点的各bit位的取值只有2种结果,为0或1。因此,在一些实施例中,对N个预测节点中的第一点进行加权得到的第一加权点的各bit位的取值也为0或1。这样,对当前点在第i个坐标轴上的第i个bit位进行解码时,则基于第一加权点在第i个坐标轴上的第i个bit位的取值,确定第i个坐标轴上的第i个bit位对应的第二上下文索引。例如,若第一加权点在第i个坐标轴上的第i个bit位的取值为0,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为0。再例如,若第一加权点在第i个坐标轴上的第i个bit位的取值为1,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为1。最后,解码端基于第一上下文索引和/或第i个坐标轴上的第i个bit位对应的第二上下文索引,确定第i个坐标轴上的第i个bit位对应的上下文模型,并使用该上下文模型对当前点在第i个坐标轴上的第i个bit位的值进行预测解码。As can be seen from the above, the first weighted point is obtained by weighting the first point in the N prediction nodes, wherein the values of each bit of the first point after the prediction node have only two results, which are 0 or 1. Therefore, in some embodiments, the values of each bit of the first weighted point obtained by weighting the first point in the N prediction nodes are also 0 or 1. In this way, when decoding the i-th bit of the current point on the i-th coordinate axis, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined based on the value of the i-th bit of the first weighted point on the i-th coordinate axis. For example, if the value of the i-th bit of the first weighted point on the i-th coordinate axis is 0, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 0. For another example, if the value of the i-th bit of the first weighted point on the i-th coordinate axis is 1, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 1. Finally, the decoding end determines the context model corresponding to the i-th bit on the i-th coordinate axis based on the first context index and/or the second context index corresponding to the i-th bit on the i-th coordinate axis, and uses the context model to predict and decode the value of the i-th bit of the current point on the i-th coordinate axis.
解码端除了基于上述方式一确定出第二上下文索引后,还可以通过如下方式二,确定出第二上下文索引。In addition to determining the second context index based on the above-mentioned method 1, the decoding end may also determine the second context index through the following method 2.
方式二,若K大于1时,则对K个预测参考帧中每一个预测参考帧中的预测节点所包括的第一点进行加权,基于加权后的坐标信息,确定第i个坐标轴对应的第二上下文索引。此时,上述S102-B包括如下S102-B21至S102-B23的步骤::Method 2: if K is greater than 1, weight the first point included in the prediction node in each of the K prediction reference frames, and determine the second context index corresponding to the i-th coordinate axis based on the weighted coordinate information. At this time, the above S102-B includes the following steps S102-B21 to S102-B23:
S102-A1-321-21、针对K个预测参考帧中的第j个预测参考帧,确定第j个预测参考帧中预测节点对应的第一权重;S102-A1-321-21. For a j-th prediction reference frame among the K prediction reference frames, determine a first weight corresponding to a prediction node in the j-th prediction reference frame;
S102-A1-321-22、基于第一权重,对第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到第j个预测参考帧对应的第二加权点,j为小于或等于K的正整数;S102-A1-321-22, based on the first weight, weighting the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K;
S102-A1-321-23、基于K个预测参考帧对应的第二加权点,确定第i个坐标轴对应的第二上下文索引。S102-A1-321-23. Determine a second context index corresponding to the i-th coordinate axis based on the second weighted points corresponding to the K predicted reference frames.
在该方式二中,在确定当前点的几何信息时,对这K个预测参考帧中的每一个预测参考帧分别进行考虑。具体是,确定K个预测参考帧中每一个预测参考帧的预测节点中的第一点的坐标信息,确定每一个预测参考帧对应的第二加权点,进而基于每一个预测参考帧对应的第二加权点的坐标信息,确定第i个坐标轴对应的第二上下文索引,实现第二上下文索引的准确预测,进而提升点云的解码效率。In the second method, when determining the geometric information of the current point, each of the K prediction reference frames is considered separately. Specifically, the coordinate information of the first point in the prediction node of each of the K prediction reference frames is determined, and the second weighted point corresponding to each prediction reference frame is determined, and then based on the coordinate information of the second weighted point corresponding to each prediction reference frame, the second context index corresponding to the i-th coordinate axis is determined, and the second context index is accurately predicted, thereby improving the decoding efficiency of the point cloud.
本申请实施例中,解码端确定K个预测参考帧中每一个预测参考帧对应的第二加权点的具体方式相同,为了便于描述,在此以K个预测参考帧中的第j个预测参考帧为例进行说明。In the embodiment of the present application, the specific method in which the decoding end determines the second weighted point corresponding to each of the K prediction reference frames is the same. For ease of description, the jth prediction reference frame among the K prediction reference frames is used as an example for illustration.
在本申请实施例中,当前节点在第j个预测参考帧中包括至少一个预测节点,这样基于该第j个预测参考帧中的这至少一个预测节点所包括的第一点的坐标信息,确定该第j个预测参考帧对应的第二加权点。In an embodiment of the present application, the current node includes at least one prediction node in the jth prediction reference frame, so that based on the coordinate information of the first point included in the at least one prediction node in the jth prediction reference frame, the second weighted point corresponding to the jth prediction reference frame is determined.
举例说明,第j个预测参考帧中包括当前节点的2个预测节点,分别记为预测节点1和预测节点2,进而对预测节点1所包括的第一点的几何信息和预测节点2所包括的第一点的坐标信息进行加权处理,得到第j个预测参考帧对应的第二加权点。For example, the j-th prediction reference frame includes two prediction nodes of the current node, which are respectively recorded as prediction node 1 and prediction node 2, and then the geometric information of the first point included in prediction node 1 and the coordinate information of the first point included in prediction node 2 are weighted to obtain the second weighted point corresponding to the j-th prediction reference frame.
解码端对第j个预测参考帧中的预测节点所包括的第一点的几何信息进行加权处理之前,首先需要确定出第j个预测参考帧中各预测节点对应的第一权重。其中,第一权重的确定过程可以参照上述实施例的描述,在此不再赘述。Before the decoder performs weighted processing on the geometric information of the first point included in the prediction node in the jth prediction reference frame, it is necessary to first determine the first weight corresponding to each prediction node in the jth prediction reference frame. The process of determining the first weight can refer to the description of the above embodiment and will not be repeated here.
接着,解码端基于第一权重,对第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到第j个预测参考帧对应的第二加权点。Next, the decoding end performs weighted processing on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame based on the first weight, to obtain a second weighted point corresponding to the j-th prediction reference frame.
在一种示例中,基于第一权重,对第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权平均,得到第j个预测参考帧对应的第二加权点。In one example, based on the first weight, weighted averaging is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame.
上述对确定K个预测参考帧中第j个预测参考帧对应的第二加权点的过程进行介绍,K个预测参考帧中其他预测参考帧对应的第二加权点可以参照上述第j个预测参考帧对应的方式进行确定。The above introduces the process of determining the second weighted point corresponding to the j-th prediction reference frame among the K prediction reference frames. The second weighted points corresponding to other prediction reference frames among the K prediction reference frames can be determined by referring to the method corresponding to the j-th prediction reference frame.
解码端确定出K个预测参考帧中每一个预测参考帧对应的第二加权点后,执行上述S102-A1-321-23的步骤。After the decoding end determines the second weighted point corresponding to each of the K predicted reference frames, it executes the above step S102-A1-321-23.
本申请实施对基于K个预测参考帧对应的第二加权点,确定第i个坐标轴对应的第二上下文索引的具体方式不做限制。The present application does not limit the specific method of determining the second context index corresponding to the i-th coordinate axis based on the second weighted points corresponding to the K prediction reference frames.
在一些实施例中,解码端确定K个预测参考帧对应的第二加权点在第i个坐标轴上的坐标信息的平均值,基于该平均值,确定第i个坐标轴对应的第二上下文索引。In some embodiments, the decoding end determines an average value of coordinate information of second weighted points corresponding to K predicted reference frames on the i-th coordinate axis, and determines a second context index corresponding to the i-th coordinate axis based on the average value.
在一些实施例中,上述S102-A1-321-23包括如下S102-A1-321-231至S102-A1-321-233的步骤:In some embodiments, the above S102-A1-321-23 includes the following steps S102-A1-321-231 to S102-A1-321-233:
S102-A1-321-231、确定K个预测参考帧对应的第二权重;S102-A1-321-231, determine second weights corresponding to K prediction reference frames;
S102-B232、基于第二权重对K个预测参考帧对应的第二加权点的几何信息进行加权处理,得到第三加权点;S102-B232, weighting the geometric information of the second weighted points corresponding to the K prediction reference frames based on the second weight to obtain a third weighted point;
S102-B233、基于第三加权点在所述第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。S102-B233. Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the third weighted point on the i-th coordinate axis.
在该实施例中,解码端可以参照上述实施例的方法,确定K个预测参考帧中每一个预测参考帧对应的第二权重。接着,基于第二权重对K个预测参考帧分别对应的第二加权点的坐标信息进行加权处理,得到第三加权点。In this embodiment, the decoding end can refer to the method of the above embodiment to determine the second weight corresponding to each of the K prediction reference frames. Then, based on the second weight, the coordinate information of the second weighted points corresponding to the K prediction reference frames is weighted to obtain a third weighted point.
举例说明,假设K=2,例如当前待解码帧包括2个预测参考帧,这2个预测参考帧包括当前待解码帧的前向帧和后向帧,假设前向帧对应的第二权重为W1、后向帧对应的第二权重为W2,这样基于W1和W2,对前向帧对应的第二加权点的几何信息和后向帧对应的第二加权点的几何信息进行加权,得到第三加权点的几何信息。For example, assuming K=2, for example, the current frame to be decoded includes 2 prediction reference frames, and these 2 prediction reference frames include the forward frame and backward frame of the current frame to be decoded. Assume that the second weight corresponding to the forward frame is W1, and the second weight corresponding to the backward frame is W2. Based on W1 and W2, the geometric information of the second weighted point corresponding to the forward frame and the geometric information of the second weighted point corresponding to the backward frame are weighted to obtain the geometric information of the third weighted point.
在一种示例中,基于第二权重,对K个预测参考帧分别对应的第二加权点的几何信息进行加权平均,得到第三加权点的坐标信息。In one example, based on the second weight, weighted averaging is performed on the geometric information of the second weighted points respectively corresponding to the K prediction reference frames to obtain coordinate information of the third weighted point.
解码端基于上述步骤,确定出第三加权点的几何信息后,基于第三加权点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。After determining the geometric information of the third weighted point based on the above steps, the decoding end determines the second context index corresponding to the i-th coordinate axis based on the coordinate information of the third weighted point on the i-th coordinate axis.
由上述可知,第三加权点是各预测参考帧中的预测节点中的第一点进行加权得到,其中预测节点后的第一点的各bit位的取值只有2种结果,为0或1。因此,在一些实施例中,对N个预测节点中的第一点进行加权得到的第一加权点的各bit位的取值也为0或1。这样,对当前点在第i个坐标轴上的第i个bit位进行解码时,则基于第三加权点在第i个坐标轴上的第i个bit位的取值,确定第i个坐标轴上的第i个bit位对应的第二上下文索引。例如,若第三加权点在第i个坐标轴上的第i个bit位的取值为0,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为0。再例如,若第三加权点在第i个坐标轴上的第i个bit位的取值为1,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为1。最后,解码端基于第一上下文索引和/或第i个坐标轴上的第i个bit位对应的第二上下文索引,确定第i个坐标轴上的第i个bit位对应的上下文模型,并使用该上下文模型对当前点在第i个坐标轴上的第i个bit位的值进行预测解码。As can be seen from the above, the third weighted point is obtained by weighting the first point in the prediction node in each prediction reference frame, wherein the value of each bit of the first point after the prediction node has only two results, which is 0 or 1. Therefore, in some embodiments, the value of each bit of the first weighted point obtained by weighting the first point in the N prediction nodes is also 0 or 1. In this way, when the i-th bit of the current point on the i-th coordinate axis is decoded, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined based on the value of the i-th bit of the third weighted point on the i-th coordinate axis. For example, if the value of the i-th bit of the third weighted point on the i-th coordinate axis is 0, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 0. For another example, if the value of the i-th bit of the third weighted point on the i-th coordinate axis is 1, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 1. Finally, the decoding end determines the context model corresponding to the i-th bit on the i-th coordinate axis based on the first context index and/or the second context index corresponding to the i-th bit on the i-th coordinate axis, and uses the context model to predict and decode the value of the i-th bit of the current point on the i-th coordinate axis.
解码端基于上述步骤,确定出第一上下文索引和/或第二上下文索引后,基于第一上下文索引和/或第二上下文索引,确定上下文模型,并使用该上下文模型对当前点的坐标信息进行解码。After the decoding end determines the first context index and/or the second context index based on the above steps, it determines the context model based on the first context index and/or the second context index, and uses the context model to decode the coordinate information of the current point.
在一种示例中,假设预测节点的DCM模式信息为PredDCMode,并且预测节点中含有的点数为PredNumPoints,假设预测节点中第一点的几何信息为predPointPos。假设,解码端利用预测节点的IDCM模式以及预测节点中点的几何信息来对当前点的几何信息进行预测解码,即解码端使用的预测节点的几何解码信息包含如下两种:In an example, assuming that the DCM mode information of the prediction node is PredDCMode, and the number of points contained in the prediction node is PredNumPoints, and assuming that the geometric information of the first point in the prediction node is predPointPos. Assume that the decoder uses the IDCM mode of the prediction node and the geometric information of the point in the prediction node to predict and decode the geometric information of the current point, that is, the geometric decoding information of the prediction node used by the decoder includes the following two types:
1)预测节点的IDCM模式;1) IDCM mode of the prediction node;
2)预测节点中点(即第一点)的几何信息,即预测节点中点对应精度上的bit信息(0或者1)。2) The geometric information of the midpoint of the prediction node (i.e., the first point), that is, the bit information (0 or 1) corresponding to the accuracy of the midpoint of the prediction node.
例如,在GPCC框架下,预测节点的IDCM模式包括PredDCMode(0,1,2)。在AVS框架下,预测节点的IDCMFor example, in the GPCC framework, the IDCM mode of the prediction node includes PredDCMode(0,1,2). In the AVS framework, the IDCM of the prediction node
模式包括PredDCMode(0,1)。Modes include PredDCMode(0,1).
假设当前节点中点的数目为numPoints,并且每个点的几何信息为PointPos,待编码的bit精度深度为nodeSizeLog2,则对当前节点中的每个点的几何信息解码过程如下:Assuming that the number of points in the current node is numPoints, and the geometric information of each point is PointPos, and the bit precision depth to be encoded is nodeSizeLog2, the decoding process of the geometric information of each point in the current node is as follows:


则通过上述解码过程,可以得到当前节点中每一个点的几何信息。其中,ctx1为第一上下文索引,ctx2为第二上下文索引。Through the above decoding process, the geometric information of each point in the current node can be obtained. Wherein, ctx1 is the first context index, and ctx2 is the second context index.
本申请实施例提供的点云解码方法,在对当前解码帧中的当前节点进行解码时,在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点,基于这N个预测节点中点的几何解码信息,对当前节点中点的坐标信息进行预测解码。也就是说,本申请实施例对节点进行DCM直接解码时进行优化,通过考虑相邻帧之间时域上的相关性,利用预测参考帧中预测节点的几何信息对待节点IDCM节点(即当前节点)中点的几何信息进行预测解码,通过考虑相邻帧之间时域相关性来进一步提升点云的几何信息解码效率。The point cloud decoding method provided by the embodiment of the present application, when decoding the current node in the current decoding frame, determines N predicted nodes of the current node in the predicted reference frame of the current frame to be decoded, and predicts and decodes the coordinate information of the midpoint of the current node based on the geometric decoding information of the midpoints of these N predicted nodes. In other words, the embodiment of the present application optimizes the direct DCM decoding of the node, and predicts and decodes the geometric information of the midpoint of the IDCM node (i.e., the current node) of the to-be-decoded node by considering the correlation in the time domain between adjacent frames, and further improves the efficiency of geometric information decoding of the point cloud by considering the correlation in the time domain between adjacent frames.
上文以解码端为例,对本申请实施例提供的点云解码方法进行详细介绍,下面以编码端为例,对本申请实施例提供的点云编码方法进行介绍。The above takes the decoding end as an example to introduce in detail the point cloud decoding method provided in the embodiment of the present application. The following takes the encoding end as an example to introduce the point cloud encoding method provided in the embodiment of the present application.
图17为本申请一实施例提供的点云编码方法流程示意图。本申请实施例的点云编码方法可以由上述图3或图4A或图8A所示的点云编码设备完成。Fig. 17 is a schematic diagram of a point cloud coding method according to an embodiment of the present application. The point cloud coding method according to the embodiment of the present application can be implemented by the point cloud coding device shown in Fig. 3 or Fig. 4A or Fig. 8A.
如图17所示,本申请实施例的点云编码方法包括:As shown in FIG. 17 , the point cloud encoding method of the embodiment of the present application includes:
S201、在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点。S201. Determine N prediction nodes of a current node in a prediction reference frame of a current frame to be encoded.
其中,当前节点为当前待编码帧中的待编码节点。The current node is the node to be encoded in the current frame to be encoded.
由上述可知,点云包括几何信息和属性信息,对点云的编码包括几何编码和属性编码。本申请实施例涉及点云的几何编码。As can be seen from the above, the point cloud includes geometric information and attribute information, and the encoding of the point cloud includes geometric encoding and attribute encoding. The embodiment of the present application relates to geometric encoding of point clouds.
在一些实施例中,点云的几何信息也称为点云的位置信息,因此,点云的几何编码也称为点云的位置编码。In some embodiments, the geometric information of the point cloud is also referred to as the position information of the point cloud, and therefore, the geometric encoding of the point cloud is also referred to as the position encoding of the point cloud.
在基于八叉树的编码方式中,编码端基于点云的几何信息,构建点云的八叉树结构,如图11所示,使用最小长方体包围点云,首先对该包围盒进行八叉树划分,得到8个节点,对这8个节点中被占用的节点,即包括点的节点继续进行八叉树划分,以此类推,直到划分到体素级别位置,例如划分到1X1X1的正方体为止。这样划分得到的点云八叉树结构包括多层节点组成,例如包括N层,在编码时,逐层编码每一层的占位信息,直到编码完最后一层的体素级别的叶子节点为止。也就是说,在八叉树编码中,将点云通八叉树划分,最终将点云中的点划分到八叉树的体素级的叶子节点中,通过对整个八叉树进行编码,实现对点云的编码。In the octree-based encoding method, the encoding end constructs the octree structure of the point cloud based on the geometric information of the point cloud. As shown in Figure 11, the point cloud is enclosed by the smallest cuboid. The enclosing box is first divided into octrees to obtain 8 nodes. The occupied nodes among the 8 nodes, that is, the nodes including the points, continue to be divided into octrees, and so on, until the division is to the voxel level, for example, to a 1X1X1 cube. The point cloud octree structure obtained by such division includes multiple layers of nodes, for example, N layers. When encoding, the placeholder information of each layer is encoded layer by layer until the voxel-level leaf nodes of the last layer are encoded. That is to say, in octree encoding, the point cloud is divided through the octree, and finally the points in the point cloud are divided into the voxel-level leaf nodes of the octree. The encoding of the point cloud is achieved by encoding the entire octree.
但基于八叉树的几何信息编码模式对空间中具有相关性的点有高效的压缩速率,而对于在几何空间中处于孤立位置的点来说,使用直接编码方式可以大大降低复杂度,提升编编码效率。However, the octree-based geometric information encoding mode has an efficient compression rate for correlated points in space, and for points in isolated positions in the geometric space, the use of direct encoding can greatly reduce complexity and improve encoding efficiency.
由于直接编码方式是对节点所包括的点的几何信息直接进行编码,若节点所包括的点数较多时,采用直接编码方式时压缩效果差。因此,对于八叉树中的节点,在进行直接编码之前,首先判断该节点是否可以采用直接编码方式。若判断该节点可以采用直接编码方式进行编码时,则采用直接编码方式对该节点所包括的点的几何信息进行直接编码。若判断该节点不可以采用直接编码方式进行编码时,则继续采用八叉树方式对该节点进行划分。Since the direct encoding method directly encodes the geometric information of the points included in the node, if the number of points included in the node is large, the compression effect is poor when the direct encoding method is used. Therefore, for the nodes in the octree, before direct encoding, first determine whether the node can be encoded using the direct encoding method. If it is determined that the node can be encoded using the direct encoding method, the direct encoding method is used to directly encode the geometric information of the points included in the node. If it is determined that the node cannot be encoded using the direct encoding method, the octree method is continued to be used to divide the node.
具体的,编码端首先判断节点是否具备直接编码的资格,若该节点具备直接编码的资格后,判断节点的点数是否小于或等于预设阈值,若节点的点数小于或等于预设阈值,则确定该节点可以采用直接编码方式进行编码。接着,将该节点所包括的点数,以及各点的几何信息编入码流。Specifically, the encoding end first determines whether the node is qualified for direct encoding. If the node is qualified for direct encoding, it determines whether the number of points of the node is less than or equal to a preset threshold. If the number of points of the node is less than or equal to the preset threshold, it determines that the node can be encoded using direct encoding. Then, the number of points included in the node and the geometric information of each point are encoded into the bitstream.
目前在对当前节点中点的位置信息进行预测编码时,未考虑帧间信息,使得点云的编码性能低。Currently, when predictive coding is performed on the position information of the midpoint of the current node, inter-frame information is not considered, resulting in low coding performance of the point cloud.
为了解决上述问题,本申请实施例中,编码端基于当前节点对应的帧间信息,对当前节点中点的位置信息进行预测编码,进而提升点云的编码效率和编码性能。In order to solve the above problems, in an embodiment of the present application, the encoding end predictively encodes the position information of the midpoint of the current node based on the inter-frame information corresponding to the current node, thereby improving the encoding efficiency and encoding performance of the point cloud.
具体的,编码端首先在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点。Specifically, the encoder first determines N prediction nodes of the current node in the prediction reference frame of the current frame to be encoded.
需要说明的是,当前待编码帧为一个点云帧,在一些实施例中,当前待编码帧也称为当前帧或当前点云帧或当前待编码的点云帧等。当前节点可以理解为当前待编码帧中的任意一个非叶子节点的非空节点。也就是说,当前节点不是当前待编码帧对应的八叉树中的叶子节点,即当前节点为八叉树的中间任意节点,且该当前节点不是非空节点,即至少包括1个点。It should be noted that the current frame to be encoded is a point cloud frame. In some embodiments, the current frame to be encoded is also referred to as the current frame or the current point cloud frame or the current point cloud frame to be encoded. The current node can be understood as any non-leaf node in the current frame to be encoded. In other words, the current node is not a leaf node in the octree corresponding to the current frame to be encoded, that is, the current node is an arbitrary middle node of the octree, and the current node is not a non-empty node, that is, it includes at least 1 point.
在本申请实施例中,编码端在编码当前待编码帧中的当前节点时,首先确定当前待编码帧的预测参考帧,并在预测参考帧中,确定当前节点的N个预测节点。例如图12示出了当前节点在预测参考帧中的一个预测节点。In the embodiment of the present application, when encoding the current node in the current frame to be encoded, the encoder first determines the prediction reference frame of the current frame to be encoded, and determines N prediction nodes of the current node in the prediction reference frame. For example, FIG12 shows a prediction node of the current node in the prediction reference frame.
需要说明的是,本申请实施例对当前待编码帧的预测参考帧的个数不做限制,例如,当前待编码帧具有一个预测参考帧,或者当前待编码帧具有多个预测参考帧。同时,本申请实施例对当前节点的预测节点的个数N也不做限制,具体根据实际需要确定。It should be noted that the embodiment of the present application does not limit the number of prediction reference frames of the current frame to be encoded, for example, the current frame to be encoded has one prediction reference frame, or the current frame to be encoded has multiple prediction reference frames. At the same time, the embodiment of the present application does not limit the number N of prediction nodes of the current node, which is determined according to actual needs.
本申请实施例对确定当前待编码帧的预测参考帧的具体方式也不做限制。The embodiment of the present application does not limit the specific method of determining the prediction reference frame of the current frame to be encoded.
在一些实施例中,将当前待编码帧的前一个或前几个已编码帧,确定为该当前待编码帧的预测参考帧。In some embodiments, one or several encoded frames before the current frame to be encoded are determined as prediction reference frames for the current frame to be encoded.
例如,若当前待编码帧为P帧,P帧在帧间参考帧包括P帧的前一帧(即前向帧),因此,可以将当前待编码帧的前一帧(即前向帧),确定为当前待编码帧的预测参考帧。For example, if the current frame to be encoded is a P frame, the inter-frame reference frame of the P frame includes the previous frame of the P frame (ie, the forward frame). Therefore, the previous frame of the current frame to be encoded (ie, the forward frame) can be determined as the prediction reference frame of the current frame to be encoded.
再例如,若当前待编码帧为B帧,B帧的帧间参考帧包括P帧的前一帧(即前向帧)和P帧的后一帧(即后向帧),因此,可以将当前待编码帧的前一帧(即前向帧),确定为当前待编码帧的预测参考帧。For another example, if the current frame to be encoded is a B frame, the inter-frame reference frames of the B frame include the previous frame of the P frame (i.e., the forward frame) and the next frame of the P frame (i.e., the backward frame). Therefore, the previous frame of the current frame to be encoded (i.e., the forward frame) can be determined as the predicted reference frame of the current frame to be encoded.
在一些实施例中,将当前待编码帧的后一个或后几个已编码帧,确定为该当前待编码帧的预测参考帧。In some embodiments, one or several encoded frames following the current frame to be encoded are determined as prediction reference frames of the current frame to be encoded.
例如,若当前待编码帧为B帧,则可以将当前待编码帧的后一帧,确定为当前待编码帧的预测参考帧。For example, if the current frame to be encoded is a B frame, the frame following the current frame to be encoded may be determined as a prediction reference frame of the current frame to be encoded.
在一些实施例中,将当前待编码帧的前一个或前几个已编码帧,以及当前待编码帧的后一个或后几个已编码帧,确定为该当前待编码帧的预测参考帧。In some embodiments, one or several encoded frames before the current frame to be encoded, and one or several encoded frames after the current frame to be encoded, are determined as prediction reference frames of the current frame to be encoded.
例如,若当前待编码帧为B帧,则可以将当前待编码帧的前一帧和后一帧,确定为当前待编码帧的预测参考帧,此时,当前待编码帧具有2个预测参考帧。For example, if the current frame to be encoded is a B frame, the previous frame and the next frame of the current frame to be encoded may be determined as prediction reference frames of the current frame to be encoded. In this case, the current frame to be encoded has two prediction reference frames.
下面以当前待编码帧包括K个预测参考帧为例,对上述S201-A中在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点的具体过程进行介绍。Taking the current frame to be encoded including K prediction reference frames as an example, the specific process of determining N prediction nodes of the current node in the prediction reference frame of the current frame to be encoded in S201-A above is introduced.
在一些实施例中,编码端基于当前待编码帧中节点的占位信息,以及K个预测参考帧中每一个预测参考帧中节点的占位信息,从K个预测参考帧中选出至少一个预测参考帧,进而在该至少一个预测参考帧中,查找当前节点的预测节点。例如,从K个预测参考帧中,选出节点的占位信息与当前待编码帧的节点的占位信息最相近的至少一个预测参考帧,进而在这至少一个预测参考帧中,查找当前节点的预测节点。In some embodiments, the encoder selects at least one prediction reference frame from the K prediction reference frames based on the placeholder information of the node in the current frame to be encoded and the placeholder information of the node in each of the K prediction reference frames, and then searches for the prediction node of the current node in the at least one prediction reference frame. For example, at least one prediction reference frame whose placeholder information of the node is closest to the placeholder information of the node in the current frame to be encoded is selected from the K prediction reference frames, and then searches for the prediction node of the current node in the at least one prediction reference frame.
在一些实施例中,编码端可以通过如下S201-A1和S201-A2的步骤,确定当前节点的N个预测节点:In some embodiments, the encoder may determine N prediction nodes of the current node through the following steps S201-A1 and S201-A2:
S201-A1、针对K个预测参考帧中的第k个预测参考帧,确定当前节点在第k个预测参考帧中的至少一个预测节点,k为小于或等于K的正整数,K为正整数;S201-A1, for a k-th prediction reference frame among K prediction reference frames, determining at least one prediction node of a current node in the k-th prediction reference frame, where k is a positive integer less than or equal to K, and K is a positive integer;
S201-A2、基于当前节点在K个预测参考帧中的至少一个预测节点,确定当前节点的N个预测节点。S201-A2: Determine N prediction nodes of the current node based on at least one prediction node of the current node in K prediction reference frames.
在该实施例中,编码端从K个预测参考帧中的每一个预测参考帧中,确定出当前节点的至少一个预测节点,最后将K个预测参考帧中各预测参考帧中的至少一个预测节点进行汇总,得到当前节点的N个预测节点。In this embodiment, the encoding end determines at least one prediction node of the current node from each of the K prediction reference frames, and finally summarizes at least one prediction node in each of the K prediction reference frames to obtain N prediction nodes of the current node.
其中,编码端确定当前节点在K个预测参考帧中每一个预测参考帧中的至少一个预测点的过程相同,为了便于描述,在此以K个预测参考帧中的第k个预测参考帧为例进行说明。Among them, the process of the encoding end determining at least one prediction point of the current node in each of the K prediction reference frames is the same. For the sake of ease of description, the kth prediction reference frame among the K prediction reference frames is taken as an example for explanation.
下面对上述S201-A1中确定当前节点在第k个预测参考帧中的至少一个预测节点的具体过程进行介绍。The specific process of determining at least one prediction node of the current node in the kth prediction reference frame in the above S201-A1 is introduced below.
本申请实施例对编码端确定当前节点在第k个预测参考帧中的至少一个预测节点的具体方式不做限制。The embodiment of the present application does not limit the specific manner in which the encoder determines at least one prediction node of the current node in the kth prediction reference frame.
方式一,在第k个预测参考帧中,确定出当前节点的一个预测节点。例如,将第k个预测参考帧中与当前节点的划分深度相同的一个节点,确定为当前节点的预测节点。Method 1: In the kth prediction reference frame, a prediction node of the current node is determined. For example, a node in the kth prediction reference frame having the same division depth as the current node is determined as the prediction node of the current node.
在一种示例中,若当前节点在第k个预测参考帧中的预测节点的个数为1个时,则可以将第k个预测参考帧与当前节点处于相同划分深度的这些点中,选出占位信息与当前节点的占位信息差异最小的一个节点,记为节点1,将该节点1确定为当前节点在第k个预测参考帧中的一个预测节点。In one example, if the number of prediction nodes of the current node in the kth prediction reference frame is 1, then among the points at which the kth prediction reference frame and the current node are at the same division depth, a node whose occupancy information is the smallest different from that of the current node can be selected, recorded as node 1, and node 1 is determined as a prediction node of the current node in the kth prediction reference frame.
在另一种示例中,若当前节点在第k个预测参考帧中的预测节点的个数大于1时,则将上述确定的节点1,以及节点1在第k个预测参考帧中的至少一个领域节点,例如与节点1共面、共线、共点等的至少一个领域节点,确定为当前节点在第k个预测参考帧中的预测节点。In another example, if the number of prediction nodes of the current node in the kth prediction reference frame is greater than 1, the node 1 determined above and at least one domain node of node 1 in the kth prediction reference frame, such as at least one domain node that is coplanar, colinear, or co-point with node 1, are determined as the prediction nodes of the current node in the kth prediction reference frame.
方式二,上述S201-A1中确定当前节点在第k个预测参考帧中的至少一个预测节点,包括如下S201-A11至S201-A13的步骤: Mode 2, in the above S201-A1, determining at least one prediction node of the current node in the kth prediction reference frame includes the following steps S201-A11 to S201-A13:
S201-A11、在当前待编码帧中,确定当前节点的M个领域节点,M个领域节点中包括当前节点,M为正整数;S201-A11, in the current frame to be encoded, determine M domain nodes of the current node, the M domain nodes include the current node, and M is a positive integer;
S201-A12、针对M个领域节点中的第i个领域节点,确定第i个领域节点在第k个预测参考帧中的对应节点,i为小于或等于M的正整数;S201-A12, for the i-th domain node among the M domain nodes, determine the corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M;
S201-A13、基于M个领域节点在第k个预测参考帧中的对应节点,确定当前节点在第k个预测参考帧中的至少一个预测节点。S201-A13. Determine at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame.
在该实现方式中,编码端在确定当前节点在第k个预测参考帧中的至少一个预测节点之前,首先在当前待编码帧中确定当前节点的M个领域节点,该M个领域节点中包括当前节点自身。In this implementation, before determining at least one prediction node of the current node in the kth prediction reference frame, the encoder first determines M domain nodes of the current node in the current frame to be encoded, and the M domain nodes include the current node itself.
需要说明的是,在本申请实施例中,对当前节点的M个领域节点的具体确定方式不做限制。It should be noted that in the embodiment of the present application, there is no limitation on the specific method of determining the M domain nodes of the current node.
在一种示例中,当前节点的M个领域节点包括当前待编码帧中,与当前节点共面、共线和共点的领域节点中的至少一个领域节点。如图13所示,当前节点包括6个共面的节点、12个共线的节点和8个共点的节点。In one example, the M domain nodes of the current node include at least one domain node among the domain nodes that are coplanar, colinear, and co-pointed with the current node in the current frame to be encoded. As shown in FIG13 , the current node includes 6 coplanar nodes, 12 colinear nodes, and 8 co-pointed nodes.
在另一种示例中,当前节点的M个领域节点中除了包括当前待编码帧中,与当前节点共面、共线和共点的领域节点中的至少一个领域节点外,还可以包括参考邻域范围内的其他节点,本申请实施例对此不做限制。In another example, the M domain nodes of the current node may include other nodes within the reference neighborhood in addition to at least one domain node in the current frame to be encoded that is coplanar, colinear, and co-point with the current node. This embodiment of the present application does not impose any restrictions on this.
编码端基于上述步骤,在当前待编码帧中确定出当前节点的M个领域节点后,确定出M个领域节点中每一个领域节点在第k个预测参考帧中的对应节点,进而基于M个领域节点在第k个预测参考帧中的对应节点,确定当前节点在第k个预测参考帧中的至少一个预测节点。Based on the above steps, the encoding end determines the M domain nodes of the current node in the current frame to be encoded, and then determines the corresponding node of each of the M domain nodes in the kth prediction reference frame, and then determines at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame.
本申请实施例对S201-A13的具体实现方式不做限制。The embodiment of the present application does not limit the specific implementation method of S201-A13.
在一种可能的实现方式中,从M个领域节点在第k个预测参考帧中的对应节点中,筛选出至少一个对应节点,作为当前节点在第k个预测参考帧中的至少一个预测节点。例如,从M个领域节点在第k个预测参考帧中的对应节点中,筛选出占位信息与当前节点的占位信息差异最小的至少一个对应节点,作为当前节点在第k个预测参考帧中的至少一个预测节点。其中,确定对应节点的占位信息与当前节点的占位信息的差异的方式可以参照上述占位信息的差异的确定过程,例如将对应节点的占位信息与当前节点的占位信息进行异或运算,将异或运算结果作为该对应节点的占位信息与当前节点的占位信息之间的差异。In a possible implementation, at least one corresponding node is selected from the corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame. For example, at least one corresponding node whose placeholder information has the smallest difference with the placeholder information of the current node is selected from the corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame. The method of determining the difference between the placeholder information of the corresponding node and the placeholder information of the current node can refer to the above-mentioned process of determining the difference in placeholder information, for example, performing an XOR operation on the placeholder information of the corresponding node and the placeholder information of the current node, and using the XOR operation result as the difference between the placeholder information of the corresponding node and the placeholder information of the current node.
在另一种可能的实现方式中,编码端将M个领域节点在第k个预测参考帧中的对应节点,确定为当前节点在第k个预测参考帧中的至少一个预测节点。例如,M个领域节点分别在第k个预测参考帧中具有一个对应节点,进而有M个对应节点,将这M个对应节点确定为当前节点在第k个预测参考帧中的预测节点,共有M个预测节点。In another possible implementation, the encoder determines the corresponding nodes of the M domain nodes in the kth prediction reference frame as at least one prediction node of the current node in the kth prediction reference frame. For example, the M domain nodes each have a corresponding node in the kth prediction reference frame, and thus there are M corresponding nodes. The M corresponding nodes are determined as the prediction nodes of the current node in the kth prediction reference frame, and there are M prediction nodes in total.
上面对确定当前节点在第k个预测参考帧中的至少一个预测节点的过程进行介绍。这样,编码端可以采用与上述相同的方式,确定出当前节点在K个预测参考帧中每一个预测参考帧中的至少一个预测节点。The above describes the process of determining at least one prediction node of the current node in the kth prediction reference frame. In this way, the encoder can use the same method as above to determine at least one prediction node of the current node in each of the K prediction reference frames.
编码端确定出当前节点在K个预测参考帧中每一个预测参考帧中的至少一个预测节点后,执行上述S201-B的步骤,即基于当前节点在K个预测参考帧中的至少一个预测节点,确定当前节点的N个预测节点。After the encoder determines at least one prediction node of the current node in each of the K prediction reference frames, it executes the above step S201-B, that is, determines N prediction nodes of the current node based on at least one prediction node of the current node in the K prediction reference frames.
在一种示例中,将当前节点在K个预测参考帧中的至少一个预测节点,确定为当前节点的N个预测节点。In an example, at least one prediction node of the current node in K prediction reference frames is determined as N prediction nodes of the current node.
例如,K=2,即K个预测参考帧包括第一个预测参考帧和第二个预测参考帧。假设当前节点在第一个预测参考帧中有2个预测节点,当前节点在第二个预测参考帧中有3个预测节点,这样可以确定当前节点具有5个预测节点,此时N=5。For example, K=2, that is, the K prediction reference frames include the first prediction reference frame and the second prediction reference frame. Assuming that the current node has 2 prediction nodes in the first prediction reference frame and the current node has 3 prediction nodes in the second prediction reference frame, it can be determined that the current node has 5 prediction nodes, and N=5 at this time.
在另一种示例中,从当前节点在K个预测参考帧中的至少一个预测节点中,筛选出当前节点的N个预测节点。In another example, N prediction nodes of the current node are screened out from at least one prediction node of the current node in K prediction reference frames.
继续参照上述示例,假设K=2,即K个预测参考帧包括第一个预测参考帧和第二个预测参考帧。假设当前节点在第一个预测参考帧中有2个预测节点,当前节点在第二个预测参考帧中有3个预测节点。从这5个预测节点中,选出3个预测节点作为当前节点的最终预测节点。例如,从这5个预测节点中,选出占位信息与当前节点的占位信息差异最小的3个预测节点,确定为当前节点的最终预测节点。Continuing with the above example, assume that K=2, that is, the K prediction reference frames include the first prediction reference frame and the second prediction reference frame. Assume that the current node has 2 prediction nodes in the first prediction reference frame, and the current node has 3 prediction nodes in the second prediction reference frame. From these 5 prediction nodes, select 3 prediction nodes as the final prediction nodes of the current node. For example, from these 5 prediction nodes, select the 3 prediction nodes whose placeholder information has the smallest difference with the placeholder information of the current node, and determine them as the final prediction nodes of the current node.
在该方式二中,编码端在当前待编码帧中确定出当前节点的M个领域节点后,在第k个预测参考帧中,确定出这M个领域节点中每一个领域节点的对应节点,进而基于M个领域节点中每一个领域节点的对应节点,确定当前节点在该第k个预测参考帧中的至少一个预测点。In the second method, after the encoding end determines the M domain nodes of the current node in the current frame to be encoded, it determines the corresponding node of each of the M domain nodes in the kth prediction reference frame, and then determines at least one prediction point of the current node in the kth prediction reference frame based on the corresponding node of each of the M domain nodes.
方式三,上述S201-A1中确定当前节点在第k个预测参考帧中的至少一个预测节点,包括如下S201-B11至S201-B13的步骤: Mode 3, in the above S201-A1, determining at least one prediction node of the current node in the kth prediction reference frame includes the following steps S201-B11 to S201-B13:
S201-B11、确定当前节点在第k个预测参考帧中的对应节点;S201-B11, determining the corresponding node of the current node in the kth prediction reference frame;
S201-B12、确定对应节点的至少一个领域节点;S201-B12, determining at least one domain node of the corresponding node;
S201-B13、将至少一个领域节点,确定为当前节点在第k个预测参考帧中的至少一个预测节点。S201-B13. Determine at least one domain node as at least one prediction node of the current node in the kth prediction reference frame.
在该方式3中,针对K个预测参考帧中的每一个预测参考帧,编码端首先在各预测参考帧中确定该当前节点的对应节点。例如,确定当前节点在预测参考帧1中的对应节点1,确定当前节点在预测参考帧2中的对应节点2。接着,编码端确定各对应节点的至少一个领域节点。例如,在预测参考帧1中确定对应节点1的至少一个领域节点,以及在预测参考帧2中确定对应节点2的至少一个领域节点。这样可以将对应节点1在预测参考帧1中的至少一个领域节点,确定为当前节点在预测参考帧1中的至少一个预测节点,将对应节点2在预测参考帧2中的至少一个领域节点,确定为当前节点在预测参考帧2中的至少一个预测节点。In this method 3, for each of the K prediction reference frames, the encoder first determines the corresponding node of the current node in each prediction reference frame. For example, the corresponding node 1 of the current node in the prediction reference frame 1 is determined, and the corresponding node 2 of the current node in the prediction reference frame 2 is determined. Next, the encoder determines at least one domain node of each corresponding node. For example, at least one domain node of the corresponding node 1 is determined in the prediction reference frame 1, and at least one domain node of the corresponding node 2 is determined in the prediction reference frame 2. In this way, at least one domain node of the corresponding node 1 in the prediction reference frame 1 can be determined as at least one prediction node of the current node in the prediction reference frame 1, and at least one domain node of the corresponding node 2 in the prediction reference frame 2 can be determined as at least one prediction node of the current node in the prediction reference frame 2.
方式二的S201-A12中确定第i个领域节点在第k个预测参考帧中的对应节点,与上述方式三的S201-B11中确定当前节点在第k个预测参考帧中的对应节点的过程基本相同。为了便于描述,将上述第i个领域节点和当前节点记为第i个节点,下面对确定第i个节点在第k个预测参考帧中的对应节点的具体过程进行介绍。The process of determining the corresponding node of the i-th domain node in the k-th prediction reference frame in S201-A12 of the second method is basically the same as the process of determining the corresponding node of the current node in the k-th prediction reference frame in S201-B11 of the above-mentioned third method. For the convenience of description, the above-mentioned i-th domain node and the current node are recorded as the i-th node, and the specific process of determining the corresponding node of the i-th node in the k-th prediction reference frame is introduced below.
编码端确定第i个节点在第k个预测参考帧中的对应节点至少包括如下几种方式:The encoder determines the corresponding node of the i-th node in the k-th prediction reference frame in at least the following ways:
方式1,将第k个预测参考帧中与第i个节点的划分深度相同的一个节点,确定为第i个节点的对应节点。Method 1: Determine a node in the k-th prediction reference frame that has the same division depth as the i-th node as the corresponding node of the i-th node.
方式2、上述S201-A12和S201-B11包括如下步骤:Mode 2: The above S201-A12 and S201-B11 include the following steps:
S201-A121、在当前待编码帧中,确定第i个节点的父节点,作为第i个父节点;S201-A121, in the current frame to be encoded, determine the parent node of the i-th node as the i-th parent node;
S201-A122、确定第i个父节点在第k个预测参考帧中的匹配节点,作为第i个匹配节点;S201-A122, determining a matching node of the i-th parent node in the k-th prediction reference frame as the i-th matching node;
S201-A123、将i个匹配节点的子节点中的一个子节点,确定为第i个节点在第k个预测参考帧中的对应节点。S201-A123. Determine one of the child nodes of the i matching nodes as the corresponding node of the i-th node in the k-th prediction reference frame.
在该方式2中,对于第i个节点,编码端在当前待编码帧中,确定该第i个节点的父节点,进而在第k个预测参考帧中,确定第i个预测领域节点的父节点的匹配节点。为了便于描述,将第i个节点的父节点记为第i个父节点,将第i个节点的父节点在第k个预测参考帧中的匹配节点,确定为第i个匹配节点。接着,将第i个匹配节点的子节点的一个子节点,确定为第i个节点在第k个预测参考帧中的对应节点,实现对第i个节点在第k个预测参考帧中的对应节点的准确确定。In the method 2, for the i-th node, the encoding end determines the parent node of the i-th node in the current frame to be encoded, and then determines the matching node of the parent node of the i-th prediction domain node in the k-th prediction reference frame. For the convenience of description, the parent node of the i-th node is recorded as the i-th parent node, and the matching node of the parent node of the i-th node in the k-th prediction reference frame is determined as the i-th matching node. Then, a child node of the child node of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame, thereby accurately determining the corresponding node of the i-th node in the k-th prediction reference frame.
下面对上述S201-A122中确定第i个父节点在第k个预测参考帧中的匹配节点的具体过程进行介绍。The specific process of determining the matching node of the i-th parent node in the k-th prediction reference frame in the above S201-A122 is introduced below.
本申请实施例对编码端确定第i个父节点在第k个预测参考帧中的匹配节点的具体方式不做限制。The embodiment of the present application does not limit the specific manner in which the encoder determines the matching node of the i-th parent node in the k-th prediction reference frame.
在一些实施例中,确定第i个父节点在当前待编码帧中的划分深度,例如第i个父节点在当前待编码帧的八叉树的第2层。这样,编码端可以将第k个预测参考帧中与第i个父节点的划分深度相同的各节点中的一个节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。例如将第k个预测参考帧中处于第2层的各节点中的一个节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。In some embodiments, the division depth of the i-th parent node in the current frame to be encoded is determined, for example, the i-th parent node is in the second layer of the octree of the current frame to be encoded. In this way, the encoder can determine one of the nodes in the k-th prediction reference frame that have the same division depth as the i-th parent node as the matching node of the i-th parent node in the k-th prediction reference frame. For example, one of the nodes in the second layer in the k-th prediction reference frame is determined as the matching node of the i-th parent node in the k-th prediction reference frame.
在一些实施例中,编码端基于第i个父节点的占位信息,确定第i个父节点在第k个预测参考帧中的匹配节点。具体的,由于当前待编码帧中的第i个父节点的占位信息已编码,且第k个预测参考帧中的各节点的占位信息也已编码。这样,编码端可以基于第i个父节点的占位信息,在第k个预测参考帧中查找该第i个父节点的匹配节点。In some embodiments, the encoder determines the matching node of the i-th parent node in the k-th prediction reference frame based on the placeholder information of the i-th parent node. Specifically, since the placeholder information of the i-th parent node in the current frame to be encoded has been encoded, and the placeholder information of each node in the k-th prediction reference frame has also been encoded, the encoder can search for the matching node of the i-th parent node in the k-th prediction reference frame based on the placeholder information of the i-th parent node.
例如,将第k个预测参考帧中,占位信息与第i个父节点的占位信息之间的差异最小的节点,确定为第i个父节点在第k个预测参考帧中的匹配节点。For example, a node whose placeholder information in the k-th prediction reference frame has the smallest difference with the placeholder information of the i-th parent node is determined as a matching node of the i-th parent node in the k-th prediction reference frame.
举例说明,假设第i个父节点的占位信息为11001101,在第k个预测参考帧中查询占位信息与占位信息11001101差异最小的节点。具体是,编码端将第i个父节点的占位信息,与第k个预测参考帧中的每一个节点的占位信息进行异或运算,将第k个预测参考帧中的异或运算结果最小的一个节点,确定为第i个父节点在第k个预测参考帧中匹配节点。For example, assuming that the placeholder information of the i-th parent node is 11001101, the node whose placeholder information is the smallest different from the placeholder information 11001101 is searched in the k-th prediction reference frame. Specifically, the encoder performs an XOR operation on the placeholder information of the i-th parent node and the placeholder information of each node in the k-th prediction reference frame, and determines the node with the smallest XOR operation result in the k-th prediction reference frame as the matching node of the i-th parent node in the k-th prediction reference frame.
基于上述步骤,编码端可以确定出第i个父节点在第k个预测参考帧中的匹配节点。为了便于描述,将该匹配节点记为第i个匹配节点。Based on the above steps, the encoder can determine the matching node of the i-th parent node in the k-th prediction reference frame. For ease of description, the matching node is recorded as the i-th matching node.
接着,编码端将该第i个匹配节点的子节点中的一个子节点,确定为第i个领域节点在第k个预测参考帧中的对应节点。Next, the encoder determines one of the child nodes of the i-th matching node as the corresponding node of the i-th domain node in the k-th prediction reference frame.
例如,编码端将该第i个匹配节点所包括的子节点中的一个默认子节点,确定为第i个节点在第k个预测参考帧中的对应节点。假设,将第i个匹配节点的第1个子节点,确定为第i个节点在第k个预测参考帧中的对应节点。For example, the encoder determines a default child node among the child nodes included in the i-th matching node as the corresponding node of the i-th node in the k-th prediction reference frame. Assume that the first child node of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
再例如,编码端确定第i个节点在父节点所包括的子节点中的第一序号;将第i个匹配节点的子节点中序号为第 一序号的子节点,确定为第i个节点在第k个预测参考帧中的对应节点。示例性的,如图14所示,第i个节点为第i个父节点的第2个子节点,此时第一序号为2。这样可以将第i个匹配节点的第2个子节点,确定为第i个节点的对应节点。For another example, the encoder determines the first sequence number of the i-th node in the child nodes included in the parent node; the child node with the first sequence number in the child nodes of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame. Exemplarily, as shown in FIG14, the i-th node is the second child node of the i-th parent node, and the first sequence number is 2. In this way, the second child node of the i-th matching node can be determined as the corresponding node of the i-th node.
上面对确定M个领域节点中第i个领域节点,在第k个预测参考帧中的对应节点,以及确定当前节点在第k个预测参考帧中的对应节点的确定过程进行介绍。这样,编码端可以采用方式二或方式三的方式,确定出当前节点在预测参考帧中的N个预测节点。The above describes the process of determining the corresponding node of the i-th domain node in the M domain nodes in the k-th prediction reference frame, and determining the corresponding node of the current node in the k-th prediction reference frame. In this way, the encoder can use the second or third method to determine the N prediction nodes of the current node in the prediction reference frame.
编码端基于上述步骤,在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点后,执行如下S202的步骤。Based on the above steps, the encoder determines N prediction nodes of the current node in the prediction reference frame of the current frame to be encoded, and then performs the following step S202.
S202、基于N个预测节点中点的几何编码信息,对当前节点中点的位置信息进行预测编码。S202. Based on the geometric coding information of the midpoints of the N predicted nodes, predictive coding is performed on the position information of the midpoint of the current node.
由于点云的相邻帧之间的相关性,本申请实施例基于点云的相邻帧之间的相关性,在对当前节点中点的位置信息进行预测编码时,参照了帧间的相关信息。具体是基于当前节点的N个预测节点中点的几何编码信息,对当前节点中点的微信信息进行预测编码,从而提升点云的编编码效率和编编码性能。Due to the correlation between adjacent frames of the point cloud, the embodiment of the present application refers to the relevant information between frames when predicting the position information of the midpoint of the current node based on the correlation between adjacent frames of the point cloud. Specifically, the WeChat information of the midpoint of the current node is predictively encoded based on the geometric encoding information of the midpoints of the N predicted nodes of the current node, thereby improving the encoding efficiency and encoding performance of the point cloud.
需要说明的是,本申请实施例中,基于N个预测节点的几何编码信息,对当前节点中点的坐标信息进行预测编码,可以理解为将N个预测节点的几何编码信息作为上下文,对当前节点中点的坐标信息进行预测编码。例如,编码端基于N个预测节点的几何编码信息,确定上下文模型的索引,进而基于该上下文模型的索引,从预设的多个上下文模型中,确定出目标上下文模型,并使用该上下文模型,对当前节点中点的坐标信息进行预测编码。It should be noted that, in the embodiment of the present application, the coordinate information of the midpoint of the current node is predictively encoded based on the geometric encoding information of the N prediction nodes, which can be understood as using the geometric encoding information of the N prediction nodes as context to predictively encode the coordinate information of the midpoint of the current node. For example, the encoding end determines the index of the context model based on the geometric encoding information of the N prediction nodes, and then determines the target context model from the preset multiple context models based on the index of the context model, and uses the context model to predictively encode the coordinate information of the midpoint of the current node.
本申请实施例中,基于N个预测节点的几何编码信息,对当前节点中各点的坐标信息进行预测编码的过程基本相同,为了便于描述,在此以对当前节点中的当前点的坐标信息进行预测编码为例进行说明。In an embodiment of the present application, based on the geometric coding information of N prediction nodes, the process of predictive coding the coordinate information of each point in the current node is basically the same. For the sake of ease of description, the predictive coding of the coordinate information of the current point in the current node is taken as an example to illustrate.
在一些实施例中,上述S202包括如下步骤:In some embodiments, the above S202 includes the following steps:
S202-A、基于N个预测节点的几何编码信息,确定上下文模型的索引;S202-A, determining the index of the context model based on the geometric coding information of the N prediction nodes;
S202-B、基于上下文模型的索引,确定上下文模型;S202-B, determining a context model based on an index of the context model;
S202-C、使用上下文模型,对当前节点中的当前点的坐标信息进行预测编码。S202-C. Use the context model to predictively encode the coordinate information of the current point in the current node.
在本申请实施例中,为坐标信息的编码过程设置多个上下文模型,例如Q个上下文模型,本申请实施例对坐标信息对应的上下文模型的具体个数不做限制,只要保证Q大于1即可。也就是说,在本申请实施例中,至少从2个上下文模型中选择一个最优的上下文模型,对当前节点中的当前点的坐标信息进行预测编码,以提高对当前点的坐标信息的编码效率。In the embodiment of the present application, multiple context models are set for the encoding process of the coordinate information, for example, Q context models. The embodiment of the present application does not limit the specific number of context models corresponding to the coordinate information, as long as Q is greater than 1. That is to say, in the embodiment of the present application, at least one optimal context model is selected from two context models, and the coordinate information of the current point in the current node is predictively encoded to improve the encoding efficiency of the coordinate information of the current point.
本申请实施例中预测节点的几何编码信息可以理解为预测节点的几何编码过程中所涉及的任意信息。例如包括预测节点所包括的点数、预测节点的占位信息、预测节点的编码方式、预测节点中点的几何信息等等。In the embodiment of the present application, the geometric coding information of the prediction node can be understood as any information involved in the geometric coding process of the prediction node, such as the number of points included in the prediction node, the placeholder information of the prediction node, the coding method of the prediction node, the geometric information of the midpoint of the prediction node, etc.
在一些实施例中,预测节点的几何编码信息包括预测节点的直接编码信息和/或预测节点中点的坐标信息,其中,预测节点的直接编码信息用于指示预测节点是否满足直接编码方式进行编码的条件。In some embodiments, the geometric coding information of the prediction node includes direct coding information of the prediction node and/or coordinate information of a midpoint of the prediction node, wherein the direct coding information of the prediction node is used to indicate whether the prediction node meets the conditions for encoding in a direct coding manner.
基于此,上述S202-A包括如下S202-A1的步骤:Based on this, the above S202-A includes the following step S202-A1:
S202-A1、基于N个预测节点的直接编码信息,确定第一上下文索引,和/或基于N个预测节点中点的坐标信息,确定第二上下文索引。S202-A1. Determine a first context index based on direct encoding information of the N prediction nodes, and/or determine a second context index based on coordinate information of midpoints of the N prediction nodes.
对应的,上述S202-B包括如下步骤S202-B的步骤:Correspondingly, the above S202-B includes the following steps S202-B:
S202-B1、基于第一上下文索引和/或第二上下文索引,从预设的多个上下文模型中,选出上下文模型。S202-B1. Select a context model from a plurality of preset context models based on the first context index and/or the second context index.
在该实施例中,若预测节点的几何编码信息包括预测节点的直接编码信息和/或预测节点中点的坐标信息时,则编码端可以基于N个预测节点的直接编码信息,确定第一上下文索引,和/或基于N个预测节点中点的位置信息,确定第二上下文索引,进而基于第一上下文索引和/或第二上下文索引,从预设的多个上下文模型中,选出最终的上下文模型。In this embodiment, if the geometric coding information of the prediction node includes the direct coding information of the prediction node and/or the coordinate information of the midpoint of the prediction node, the encoding end can determine the first context index based on the direct coding information of the N prediction nodes, and/or determine the second context index based on the position information of the midpoint of the N prediction nodes, and then select the final context model from the preset multiple context models based on the first context index and/or the second context index.
由此可知,在该实施例中,编码端确定上下文模型的方式包括但不限于如下几种方式:It can be seen that in this embodiment, the encoding end determines the context model in the following ways, including but not limited to:
在一种可能的实现方式中,若预测节点的几何编码信息包括预测节点的直接编码信息时,则确定上下文模型的过程可以是,基于N个预测节点的直接编码信息,确定第一上下文索引,进而基于第一上下文索引,从预设的多个上下文模型中,选出最终的上下文模型对当前点的坐标信息进行编码。In one possible implementation, if the geometric coding information of the prediction node includes direct coding information of the prediction node, the process of determining the context model may be to determine a first context index based on the direct coding information of N prediction nodes, and then based on the first context index, select a final context model from a plurality of preset context models to encode the coordinate information of the current point.
例如,编码端基于第一上下文索引,从表4所示的上下文模型中,选出最终的上下文模型。For example, the encoder selects the final context model from the context models shown in Table 4 based on the first context index.
在另一种可能的实现方式中,若预测节点的几何编码信息包括预测节点中点的坐标信息时,则确定上下文模型的过程可以是,基于N个预测节点中点的坐标信息,确定第二上下文索引,进而基于第二上下文索引,从预设的多个上下文模型中,选出最终的上下文模型对当前点的坐标信息进行编码。In another possible implementation, if the geometric coding information of the prediction node includes the coordinate information of the midpoint of the prediction node, the process of determining the context model may be to determine the second context index based on the coordinate information of the midpoints of N prediction nodes, and then based on the second context index, select the final context model from the preset multiple context models to encode the coordinate information of the current point.
例如,编码端基于第二上下文索引,从表4所示的上下文模型中,选出最终的上下文模型。For example, the encoder selects the final context model from the context models shown in Table 4 based on the second context index.
在另一种可能的实现方式中,若预测节点的几何编码信息包括预测节点的直接编码信息和预测节点中点的坐标信息时,则确定上下文模型的过程可以是,基于N个预测节点的直接编码信息,确定第一上下文索引,进而基于第一上下文索引,基于N个预测节点中点的坐标信息,确定第二上下文索引,进而基于第二上下文索引,基于第一上下文索引和第二上下文索引,从预设的多个上下文模型中,选出最终的上下文模型对当前点的坐标信息进行编码。In another possible implementation, if the geometric coding information of the prediction node includes the direct coding information of the prediction node and the coordinate information of the midpoint of the prediction node, the process of determining the context model may be to determine a first context index based on the direct coding information of N prediction nodes, and then determine a second context index based on the first context index and the coordinate information of the midpoint of the N prediction nodes, and then select a final context model from a plurality of preset context models based on the second context index, the first context index and the second context index to encode the coordinate information of the current point.
示例性的,第一上下文索引、第二上下文索引和上下文模型的对应关系如表5所示。Exemplarily, the correspondence between the first context index, the second context index and the context model is shown in Table 5.
在该方式3中,编码端基于N个预测节点的直接编码信息,确定出第一上下文索引,以及基于N个预测节点中点的坐标信息,确定出第二上下文索引后,查上述表5,得到最终的上下文文模型。例如,编码端基于N个预测节点的直接编码信息,确定出第一上下文索引为第一上下文索引2,基于N个预测节点中点的坐标信息,确定出第二上下文索引为第二上下文索引3,这样查表5,可以得到最终的上下文模型为上下文模型23,进而编码端使用上下文模型23对当前点的坐标信息进行编码。In this mode 3, the encoder determines the first context index based on the direct coding information of the N prediction nodes, and determines the second context index based on the coordinate information of the midpoints of the N prediction nodes, and then checks the above table 5 to obtain the final context model. For example, the encoder determines that the first context index is the first context index 2 based on the direct coding information of the N prediction nodes, and determines that the second context index is the second context index 3 based on the coordinate information of the midpoints of the N prediction nodes. By checking Table 5, the final context model can be obtained as context model 23, and then the encoder uses context model 23 to encode the coordinate information of the current point.
下面对S202-A1中基于N个预测节点的直接编码信息,确定第一上下文索引的具体过程进行介绍。The specific process of determining the first context index based on the direct encoding information of the N prediction nodes in S202-A1 is introduced below.
本申请实施例中,编码端确定第一上下文索引的方式包括但不限于如下几种:In the embodiment of the present application, the encoding end determines the first context index in the following ways, but is not limited to:
方式一,上述S202-A1包括如下S202-A1-11和S202-A1-12的步骤:Method 1: the above S202-A1 includes the following steps S202-A1-11 and S202-A1-12:
S202-A1-11、针对N个预测节点中的任一预测节点,基于预测节点的直接编码信息,确定预测节点对应的第一数值。S202-A1-11. For any prediction node among the N prediction nodes, determine a first numerical value corresponding to the prediction node based on direct encoding information of the prediction node.
在该方式中,针对N个预测节点中的每一个预测节点,基于该预测节点的直接编码信息,确定该预测节点对应的第一数值,最后基于N个预测节点对应的第一数值,确定第一上下文索引。In this manner, for each of the N prediction nodes, a first numerical value corresponding to the prediction node is determined based on direct encoding information of the prediction node, and finally a first context index is determined based on the first numerical values corresponding to the N prediction nodes.
下面对确定预测节点对应的第一数值的过程进行介绍。The following describes the process of determining the first value corresponding to the prediction node.
由上述可知,预测节点的直接编码信息用于指示该预测节点是否满足直接编码方式进行编码的条件。本申请实施例对直接编码信息的具体内容不做限制。As can be seen from the above, the direct coding information of the prediction node is used to indicate whether the prediction node meets the conditions for encoding in the direct coding manner. The embodiment of the present application does not limit the specific content of the direct coding information.
在一些实施例中,直接编码信息包括预测节点所包括的点数。这样,可以基于预测节点所包括的点数,确定预测节点对应的第一数值。In some embodiments, the direct encoding information includes the number of points included in the prediction node. In this way, the first value corresponding to the prediction node can be determined based on the number of points included in the prediction node.
在一种示例中,在GPCC框架下,预测节点所包括的点数大于或等于2时,则确定预测节点对应的第一数值为1,若预测节点所包括的点数小于2时,则确定预测节点对应的第一数值为0。在AVS框架下,预测节点所包括的点数大于或等于1时,则确定预测节点对应的第一数值为1,若预测节点所包括的点数小于1时,则确定预测节点对应的第一数值为0。In one example, in the GPCC framework, when the number of points included in the prediction node is greater than or equal to 2, the first value corresponding to the prediction node is determined to be 1, and if the number of points included in the prediction node is less than 2, the first value corresponding to the prediction node is determined to be 0. In the AVS framework, when the number of points included in the prediction node is greater than or equal to 1, the first value corresponding to the prediction node is determined to be 1, and if the number of points included in the prediction node is less than 1, the first value corresponding to the prediction node is determined to be 0.
在另一种示例中,将预测节点所包括的点数,确定为该预测节点对应的第一数值,例如该预测节点包括2个点时,则确定该预测节点对应的第一数值为2。In another example, the number of points included in the prediction node is determined as the first value corresponding to the prediction node. For example, when the prediction node includes 2 points, the first value corresponding to the prediction node is determined to be 2.
在一些实施例中,预测节点的直接编码信息包括预测节点的直接编码模式,此时,上述S202-A1-11包括:将预测节点的直接编码模式的编号,确定预测节点对应的第一数值。In some embodiments, the direct encoding information of the prediction node includes the direct encoding mode of the prediction node. In this case, the above S202-A1-11 includes: numbering the direct encoding mode of the prediction node to determine the first value corresponding to the prediction node.
例如,在GPCC框架下,若预测节点的直接编码模式为模式0时,则确定该预测节点对应的第一数值为0。若预测节点的直接编码模式为模式1时,则确定该预测节点对应的第一数值为1。若预测节点的直接编码模式为模式2时,则确定该预测节点对应的第一数值为2。For example, in the GPCC framework, if the direct encoding mode of the prediction node is mode 0, the first value corresponding to the prediction node is determined to be 0. If the direct encoding mode of the prediction node is mode 1, the first value corresponding to the prediction node is determined to be 1. If the direct encoding mode of the prediction node is mode 2, the first value corresponding to the prediction node is determined to be 2.
再例如,在AVS框架下,若预测节点的直接解码模式为模式0时,则确定该预测节点对应的第一数值为0。若预测节点的直接解码模式为模式1时,则确定该预测节点对应的第一数值为1。For another example, in the AVS framework, if the direct decoding mode of the prediction node is mode 0, the first value corresponding to the prediction node is determined to be 0. If the direct decoding mode of the prediction node is mode 1, the first value corresponding to the prediction node is determined to be 1.
基于上述步骤,编码端确定出N个预测节点中每一个预测节点对应的第一数值后,执行如下S202-A1-12的步骤。Based on the above steps, after the encoder determines the first value corresponding to each of the N prediction nodes, it executes the following step S202-A1-12.
S202-A1-12、基于N个预测节点对应的第一数值,确定第一上下文索引。S202-A1-12. Determine a first context index based on first numerical values corresponding to the N prediction nodes.
编码端基于上述步骤,确定出N个预测节点对应的第一数值后,基于N个预测节点对应的第一数值,确定第一上下文索引。After determining the first values corresponding to the N prediction nodes based on the above steps, the encoder determines a first context index based on the first values corresponding to the N prediction nodes.
其中,基于N个预测节点对应的第一数值,确定第一上下文索引至少包括如下实现方式:Wherein, determining the first context index based on the first values corresponding to the N prediction nodes includes at least the following implementation methods:
方式1,将N个预测节点对应的第一数值之和的平均值,确定为第一上下文索引。Method 1: Determine the average value of the sum of the first numerical values corresponding to the N prediction nodes as the first context index.
方式2,S202-A1-12包括如下S202-A1-121至S202-A1-123的步骤: Mode 2, S202-A1-12 includes the following steps S202-A1-121 to S202-A1-123:
S202-A1-121、确定预测节点对应的第一权重;S202-A1-121, determine a first weight corresponding to the prediction node;
S202-A1-122、基于第一权重,对N个预测节点对应的第一数值进行加权处理,得到第一加权预测值;S202-A1-122, based on the first weight, weighting the first values corresponding to the N prediction nodes to obtain a first weighted prediction value;
S202-A1-123、基于第一加权预测值,确定第一上下文索引。S202-A1-123. Determine a first context index based on the first weighted prediction value.
在该方式2中,若当前节点包括多个预测节点,即N个预测节点时,在基于N个预测节点对应的第一数值确定第一上下文索引时,可以为N个预测节点中的每一个预测节点确定一个权重,即第一权重,这样可以基于各预测节点的第一权重,对各预测节点对应的第一数值进行加权处理,进而根据最终的加权结果,确定第一上下文索引,从而提高了基于N个预测节点的几何编码信息,确定第一上下文索引的准确性。In method 2, if the current node includes multiple prediction nodes, i.e., N prediction nodes, when determining the first context index based on the first numerical values corresponding to the N prediction nodes, a weight, i.e., the first weight, can be determined for each of the N prediction nodes. In this way, the first numerical values corresponding to each prediction node can be weighted based on the first weight of each prediction node, and then the first context index can be determined based on the final weighted result, thereby improving the accuracy of determining the first context index based on the geometric coding information of the N prediction nodes.
本申请实施例对确定N个预测节点分别对应的第一权重不做限制。The embodiment of the present application does not limit the determination of the first weights corresponding to the N prediction nodes.
在一些实施例中,上述N个预测节点中各预测节点对应的第一权重为预设值。由上述可知,上述N个预测节点是基于当前节点的M个领域节点确定的,假设预测节点1为领域节点1对应的预测节点,若领域节点1为当前节点的共面节点时,则预测节点1的第一权重为预设权重1,若领域节点1为当前节点的共线节点时,则预测节点1的第一权重为预设权重2,若领域节点1为当前节点的共点节点时,则预测节点1的第一权重为预设权重3。In some embodiments, the first weight corresponding to each prediction node in the above-mentioned N prediction nodes is a preset value. As can be seen from the above, the above-mentioned N prediction nodes are determined based on the M domain nodes of the current node. Assuming that prediction node 1 is the prediction node corresponding to domain node 1, if domain node 1 is a coplanar node of the current node, the first weight of prediction node 1 is the preset weight 1, if domain node 1 is a colinear node of the current node, the first weight of prediction node 1 is the preset weight 2, and if domain node 1 is a co-point node of the current node, the first weight of prediction node 1 is the preset weight 3.
在一些实施例中,对于N个预测节点中的每一个预测节点,基于该预测节点对应的领域节点与当前节点之间的距离,确定该预测节点对应的第一权重。例如,领域节点与当前节点之间的距离越小,则该领域节点对应的预测节点与当前节点的帧间相关性越强,进而该预测节点的第一权重越大。In some embodiments, for each of the N prediction nodes, a first weight corresponding to the prediction node is determined based on the distance between the domain node corresponding to the prediction node and the current node. For example, the smaller the distance between the domain node and the current node, the stronger the inter-frame correlation between the prediction node corresponding to the domain node and the current node, and thus the greater the first weight of the prediction node.
在一些实施例中,基于上述步骤,确定出N个预测节点中各预测节点对应的权重后,对该权重进行归一化处理,将归一化处理后的权重作出预测节点的最终第一权重。In some embodiments, based on the above steps, after the weight corresponding to each prediction node in the N prediction nodes is determined, the weight is normalized, and the normalized weight is used as the final first weight of the prediction node.
本申请实施例对基于第一权重,对N个预测节点对应的第一数值进行加权处理,得到第一加权预测值的具体方式不做限制。The embodiment of the present application does not limit the specific method of obtaining the first weighted prediction value by weighting the first numerical values corresponding to N prediction nodes based on the first weight.
在一种示例中,基于第一权重,对N个预测节点对应的第一数值进行加权平均,得到第一加权预测值。In one example, based on the first weight, a weighted average is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value.
在另一种示例中,基于第一权重,对N个预测节点对应的第一数值进行加权求和,得到第一加权预测值。In another example, based on the first weight, a weighted sum is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value.
基于方式步骤,确定出第一加权预测值后,基于该第一加权预测值,确定第一上下文索引,即上述S202-A1-123至少包括如下几种示例:After determining the first weighted prediction value based on the method steps, the first context index is determined based on the first weighted prediction value, that is, the above S202-A1-123 includes at least the following examples:
示例1,将第一加权预测值,确定为第一上下文索引。Example 1: Determine the first weighted prediction value as the first context index.
示例2,确定第一加权预测值所在加权预测值范围,将该范围对应的索引,确定为第一上下文索引。Example 2: Determine the weighted prediction value range in which the first weighted prediction value is located, and determine the index corresponding to the range as the first context index.
上述以编码端对N个预测节点进行加权处理,得到第一上下文索引的过程进行介绍。The above is an introduction to the process in which the encoder performs weighted processing on N prediction nodes to obtain the first context index.
在一些实施例中,编码端还可以采用如下方式二,确定第一上下文索引。In some embodiments, the encoding end may also adopt the following method 2 to determine the first context index.
方式二、若K大于1时,确定K个预测参考帧中每一个预测参考帧对应的第二加权预测值,进而基于K个预测参考帧分别对应的第二加权预测值,确定第一上下文索引。此时,上述S202-A1包括如下S202-A1-21至S202-A1-23的步骤:Method 2: if K is greater than 1, determine the second weighted prediction value corresponding to each of the K prediction reference frames, and then determine the first context index based on the second weighted prediction values corresponding to the K prediction reference frames. At this time, the above S202-A1 includes the following steps S202-A1-21 to S202-A1-23:
S202-A1-21、针对K个预测参考帧中的第j个预测参考帧,基于当前节点在第j个预测参考帧中的预测节点的直接编码信息,确定第j个预测参考帧中的预测节点对应的第一数值,j为小于或等于K的正整数;S202-A1-21. For a j-th prediction reference frame among the K prediction reference frames, determine a first value corresponding to the prediction node in the j-th prediction reference frame based on direct encoding information of the prediction node of the current node in the j-th prediction reference frame, where j is a positive integer less than or equal to K.
S202-A1-22、确定预测节点对应的第一权重,并基于第一权重对第j个预测参考帧中的预测节点对应的第一数值进行加权处理,得到第j个预测参考帧对应的第二加权预测值;S202-A1-22, determining a first weight corresponding to the prediction node, and performing weighted processing on the first value corresponding to the prediction node in the j-th prediction reference frame based on the first weight, to obtain a second weighted prediction value corresponding to the j-th prediction reference frame;
S202-A1-23、基于K个预测参考帧对应的第二加权预测值,确定第一上下文索引。S202-A1-23. Determine a first context index based on the second weighted prediction values corresponding to the K prediction reference frames.
在该方式二中,在确定第一上下文索引时,对这K个预测参考帧中的每一个预测参考帧作为单独的上下文信息分别进行考虑。具体是,确定K个预测参考帧中每一个预测参考帧所包括的预测节点的直接编码信息,确定每一个预测参考帧对应的第二加权预测值,进而基于每一个预测参考帧对应的第二加权预测值,确定第一上下文索引,实现第一上下文索引的准确选择,进而提升点云的编码效率。In the second method, when determining the first context index, each of the K prediction reference frames is considered as separate context information. Specifically, the direct coding information of the prediction node included in each of the K prediction reference frames is determined, and the second weighted prediction value corresponding to each prediction reference frame is determined, and then based on the second weighted prediction value corresponding to each prediction reference frame, the first context index is determined to achieve accurate selection of the first context index, thereby improving the coding efficiency of the point cloud.
本申请实施例中,编码端确定K个预测参考帧中每一个预测参考帧对应的第二加权预测值的具体方式相同,为了便于描述,在此以K个预测参考帧中的第j个预测参考帧为例进行说明。In the embodiment of the present application, the specific method in which the encoding end determines the second weighted prediction value corresponding to each of the K prediction reference frames is the same. For the sake of ease of description, the jth prediction reference frame among the K prediction reference frames is used as an example for illustration.
在本申请实施例中,当前节点在第j个预测参考帧中包括至少一个预测节点,这样基于该第j个预测参考帧中的这至少一个预测节点的直接编码信息,确定这至少一个预测节点的第一数值。In an embodiment of the present application, the current node includes at least one prediction node in the jth prediction reference frame, so that the first value of the at least one prediction node is determined based on the direct encoding information of the at least one prediction node in the jth prediction reference frame.
举例说明,第j个预测参考帧中包括当前节点的2个预测节点,分别记为预测节点1和预测节点2,进而基于预测节点1的直接编码信息,确定预测节点1的第一数值,基于预测节点2的直接编码信息,确定预测节点2的第一数值。其中,基于预测节点的直接编码信息,确定预测节点对应的第一数值的过程可以参照上述实施例的描述,示例性的基于预测节点的直接编码模式,确定预测节点对应的第一数值,例如,将预测节点的直接编码模式的编号(0、1或2)确定为该预测节点对应的第一数值。For example, the j-th prediction reference frame includes two prediction nodes of the current node, which are respectively recorded as prediction node 1 and prediction node 2, and then the first value of prediction node 1 is determined based on the direct coding information of prediction node 1, and the first value of prediction node 2 is determined based on the direct coding information of prediction node 2. The process of determining the first value corresponding to the prediction node based on the direct coding information of the prediction node can refer to the description of the above embodiment, and the first value corresponding to the prediction node is determined based on the direct coding mode of the prediction node, for example, the number (0, 1 or 2) of the direct coding mode of the prediction node is determined as the first value corresponding to the prediction node.
编码端确定出第j个预测参考帧所包括的至少一个预测节点的第一数值后,确定这至少一个预测节点分别对应的第一权重,并基于第一权重对这至少一个预测节点对应的第一数值进行加权处理,得到第j个预测参考帧对应的第二加权预测值。After the encoding end determines the first value of at least one prediction node included in the j-th prediction reference frame, it determines the first weight corresponding to the at least one prediction node, and weightedly processes the first value corresponding to the at least one prediction node based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
在一种示例中,基于第一权重,对第j个预测参考帧中的预测节点对应的第一数值进行加权平均,得到第j个预测参考帧对应的第二加权预测值。In one example, based on the first weight, a weighted average is performed on the first values corresponding to the prediction nodes in the j-th prediction reference frame to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
在另一种示例中,基于第一权重,对第j个预测参考帧中的预测节点对应的第一数值进行加权求和,得到第j个预测参考帧对应的第二加权预测值。In another example, based on the first weight, a weighted sum is performed on the first numerical values corresponding to the prediction nodes in the j-th prediction reference frame to obtain a second weighted prediction value corresponding to the j-th prediction reference frame.
其中,第一权重的确定过程可以参照上述实施例的描述,在此不再赘述。The process of determining the first weight may refer to the description of the above embodiment and will not be repeated here.
上述对确定K个预测参考帧中第j个预测参考帧对应的第二加权预测值的过程进行介绍,K个预测参考帧中其他预测参考帧对应的第二加权预测值参照上述第j个预测参考帧对应的方式进行确定。The above introduces the process of determining the second weighted prediction value corresponding to the j-th prediction reference frame among the K prediction reference frames. The second weighted prediction values corresponding to other prediction reference frames among the K prediction reference frames are determined in accordance with the method corresponding to the j-th prediction reference frame.
编码端确定出K个预测参考帧中每一个预测参考帧对应的第二加权预测值后,执行上述S202-A1-23的步骤。After the encoding end determines the second weighted prediction value corresponding to each of the K prediction reference frames, it executes the above step S202-A1-23.
本申请实施对基于K个预测参考帧对应的第二加权预测值,确定第一上下文索引的具体方式不做限制。The present application does not limit the specific method of determining the first context index based on the second weighted prediction value corresponding to K prediction reference frames.
在一些实施例中,编码端将K个预测参考帧对应的第二加权预测值的平均值,确定为第一上下文索引。In some embodiments, the encoding end determines an average value of the second weighted prediction values corresponding to the K prediction reference frames as the first context index.
在一些实施例中,编码端确定K个预测参考帧对应的第二权重,并基于第二权重对K个预测参考帧对应的第二加权预测值进行加权处理,得到第一上下文索引。In some embodiments, the encoding end determines second weights corresponding to K prediction reference frames, and performs weighted processing on second weighted prediction values corresponding to the K prediction reference frames based on the second weights to obtain a first context index.
在该实施例中,编码端首先确定K个预测参考帧中每一个预测参考帧对应的第二权重。本申请实施例对确定K个预测参考帧中每一个预测参考帧对应的第二权重不做限制。In this embodiment, the encoding end first determines the second weight corresponding to each of the K prediction reference frames. The embodiment of the present application does not limit the determination of the second weight corresponding to each of the K prediction reference frames.
在一些实施例中,上述K个预测参考帧中每一个预测参考帧对应的第二权重为预设值。由上述可知,上述K个预测参考帧为当前待编码帧的前向帧和/或后向帧。假设预测参考帧1为当前待编码帧的前向帧时,则预测参考帧1对应的第二权重为预设权重1,若预测参考帧1为当前待编码帧的后向帧时,则预测参考帧1对应的第二权重为预设权重2。In some embodiments, the second weight corresponding to each of the K prediction reference frames is a preset value. As can be seen from the above, the K prediction reference frames are forward frames and/or backward frames of the current frame to be encoded. Assuming that prediction reference frame 1 is the forward frame of the current frame to be encoded, the second weight corresponding to prediction reference frame 1 is the preset weight 1. If prediction reference frame 1 is the backward frame of the current frame to be encoded, the second weight corresponding to prediction reference frame 1 is the preset weight 2.
在一些实施例中,基于预测参考帧与当前待编码帧的时间差距,确定预测参考帧对应的第二权重。在本申请实施例中,每一张点云包括时间信息,该时间信息可以为点云采集设备采集该帧点云时的时间。基于此,若预测参考帧与当前待编码帧的时间差距越小,则该预测参考帧与当前待编码帧的帧间相关性越强,进而该预测参考帧对应的第二权重越大。例如,可以将预测参考帧与当前待编码帧的时间差距的倒数确定为该预测参考帧对应的第二权重。In some embodiments, based on the time difference between the predicted reference frame and the current frame to be encoded, the second weight corresponding to the predicted reference frame is determined. In an embodiment of the present application, each point cloud includes time information, and the time information may be the time when the point cloud acquisition device acquires the point cloud of the frame. Based on this, if the time difference between the predicted reference frame and the current frame to be encoded is smaller, the inter-frame correlation between the predicted reference frame and the current frame to be encoded is stronger, and thus the second weight corresponding to the predicted reference frame is larger. For example, the inverse of the time difference between the predicted reference frame and the current frame to be encoded can be determined as the second weight corresponding to the predicted reference frame.
确定出K个预测参考帧中每一个预测参考帧对应的第二权重后,基于第二权重对K个预测参考帧分别对应的第二加权预测值进行加权处理,得到第一上下文索引。After determining the second weight corresponding to each of the K prediction reference frames, weighted processing is performed on the second weighted prediction values respectively corresponding to the K prediction reference frames based on the second weight to obtain a first context index.
举例说明,假设K=2,例如当前待编码帧包括2个预测参考帧,这2个预测参考帧包括当前待编码帧的前向帧和后向帧,假设前向帧对应的第二权重为W1、后向帧对应的第二权重为W2,这样基于W1和W2,对前向帧对应的第二加权预测值和后向帧对应的第二加权预测值进行加权,得到第一上下文索引。For example, assuming K=2, for example, the current frame to be encoded includes 2 prediction reference frames, and these 2 prediction reference frames include the forward frame and the backward frame of the current frame to be encoded. Assuming that the second weight corresponding to the forward frame is W1, and the second weight corresponding to the backward frame is W2, based on W1 and W2, the second weighted prediction value corresponding to the forward frame and the second weighted prediction value corresponding to the backward frame are weighted to obtain the first context index.
在一种示例中,基于第二权重,对K个预测参考帧分别对应的第二加权预测值进行加权平均,得到第一上下文索引。In one example, based on the second weight, weighted averaging is performed on the second weighted prediction values corresponding to the K prediction reference frames to obtain the first context index.
在另一种示例中,基于第二权重,对K个预测参考帧分别对应的第二加权预测值进行加权求和,得到第一上下文索引。In another example, based on the second weight, the second weighted prediction values corresponding to the K prediction reference frames are weighted summed to obtain the first context index.
上文对编码端确定第一上下文索引的过程进行介绍。The above describes the process of determining the first context index at the encoding end.
下面对编码端确定第二上下文索引的过程进行介绍。The following introduces the process of determining the second context index at the encoding end.
由上述确定预测节点的过程可知,N个预测节点中的每一个预测节点包括一个点或多个点,若N个预测节点中各预测节点包括一个点时,则使用各预测节点所包括的一个点,确定第二上下文索引。From the above process of determining the prediction node, it can be seen that each of the N prediction nodes includes one point or multiple points. If each of the N prediction nodes includes one point, the second context index is determined using one point included in each prediction node.
在一些实施例中,若预测节点中包括多个点时,则从这多个点中选择一个点来确定第二上下文索引。此时,上述S202-A1包括如下S202-A1-31和S202-A1-32的步骤:In some embodiments, if the prediction node includes multiple points, a point is selected from the multiple points to determine the second context index. At this time, the above S202-A1 includes the following steps S202-A1-31 and S202-A1-32:
S202-A1-31、对于N个预测节点中的任一预测节点,从预测节点所包括的点中,选出当前节点的当前点对应的第一点;S202-A1-31, for any prediction node among the N prediction nodes, select a first point corresponding to the current point of the current node from the points included in the prediction node;
S202-A1-32、基于N个预测节点所包括的第一点的坐标信息,确定第二上下文索引。S202-A1-32. Determine a second context index based on the coordinate information of the first point included in the N prediction nodes.
举例说明,假设N个预测节点包括预测节点1和预测节点2,其中预测节点1中包括点1和点2,预测节点2包括点3、点4和点5,则从预测节点1所包括的点1和点2中选出一个点作为第一点,从预测节点2所包括的点3、点4和点5中选出一个点作为第一点。这样可以基于预测节点1中的第一点和预测节点2中的第一点的几何信息,确定当前点的几何信息。For example, assuming that N prediction nodes include prediction node 1 and prediction node 2, where prediction node 1 includes point 1 and point 2, and prediction node 2 includes point 3, point 4, and point 5, then one point is selected as the first point from point 1 and point 2 included in prediction node 1, and one point is selected as the first point from point 3, point 4, and point 5 included in prediction node 2. In this way, the geometric information of the current point can be determined based on the geometric information of the first point in prediction node 1 and the first point in prediction node 2.
本申请实施例对从预测节点所包括的点中,选出当前节点的当前点对应的第一点的具体方式不做限制。The embodiment of the present application does not limit the specific method of selecting the first point corresponding to the current point of the current node from the points included in the prediction node.
在一种可能的实现方式中,将预测节点中与当前点的顺序一致的点,确定为当前点对应的第一点。举例说明,假设当前点为当前节点中的第2个点,这样可以将预测节点1中的点2确定为当前点对应的第一点,将预测节点2中的点4确定为当前点对应的第一点。再例如,若预测节点只包括一个点时,则将预测节点所包括的该点确定为当前点对应的第一点。In a possible implementation, the points in the prediction node that are in the same order as the current point are determined as the first point corresponding to the current point. For example, assuming that the current point is the second point in the current node, point 2 in prediction node 1 can be determined as the first point corresponding to the current point, and point 4 in prediction node 2 can be determined as the first point corresponding to the current point. For another example, if the prediction node includes only one point, the point included in the prediction node is determined as the first point corresponding to the current point.
在一种可能的实现方式中,若编码端基于率失真代价(或近似代价),从预测节点所包括的点中,选出当前点对应的第一点时,编码端将预测节点中的第一点的标识信息写入码流,这样编码端通过编码码流,得到预测节点中的第一点。In one possible implementation, if the encoder selects the first point corresponding to the current point from the points included in the prediction node based on the rate-distortion cost (or approximate cost), the encoder writes the identification information of the first point in the prediction node into the bitstream, so that the encoder obtains the first point in the prediction node by encoding the bitstream.
编码端对于N个预测节点中的每一个预测节点,基于上述方法,确定出各预测节点中当前点对应的第一点,进而执行上述S202-A1-32的步骤。For each of the N prediction nodes, the encoder determines the first point corresponding to the current point in each prediction node based on the above method, and then executes the above step S202-A1-32.
在本申请实施例中,编码端对当前点在不同坐标轴上的坐标信息进行分别编码,基于,则上述S202-A1-32包括如下S202-A1-321的步骤:In the embodiment of the present application, the encoding end encodes the coordinate information of the current point on different coordinate axes respectively. Based on, the above S202-A1-32 includes the following step S202-A1-321:
S202-A1-321、基于N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。S202-A1-321. Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis.
上述第i个坐标轴可以是X轴、Y轴或Z轴,本申请实施例对此不做限制。The above-mentioned i-th coordinate axis can be the X-axis, the Y-axis or the Z-axis, and this embodiment of the present application does not limit this.
在本申请实施例中,编码端对当前点在第i个坐标轴上的坐标信息进行编码时,则基于N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。这样可以基于第一上下文索引和/或第i个坐标轴对应的第二上下文索引,从多个上下文模型中,选出第i个坐标轴对应的上下文模型,进而使用第i个坐标轴对应的上下文模型,对当前点在第i个坐标轴上的坐标信息进行预测编码。例如,编码端基于N个预测节点所包括的第一点在X轴上的坐标信息,确定X轴对应的第二上下文索引,并基于第一上下文索引和/或X轴对应的第二上下文索引,从多个上下文模型中,选出X轴对应的上下文模型,进而使用X轴对应的上下文模型,对当前点在X轴上的坐标信息进行预测编码,得到当前点的X坐标值。再例如,编码端基于N个预测节点所包括的第一点在Y轴上的坐标信息,确定Y轴对应的第二上下文索引,并基于第一上下文索引和/或Y轴对应的第二上下文索引,从多个上下文模型中,选出Y轴对应的上下文模型,进而使用Y轴对应的上下文模型,对当前点在Y轴上的坐标信息进行预测编码,得到当前点的Y坐标值。In an embodiment of the present application, when the encoding end encodes the coordinate information of the current point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined based on the coordinate information of the first point on the i-th coordinate axis included in the N prediction nodes. In this way, the context model corresponding to the i-th coordinate axis can be selected from multiple context models based on the first context index and/or the second context index corresponding to the i-th coordinate axis, and then the context model corresponding to the i-th coordinate axis is used to predict the coordinate information of the current point on the i-th coordinate axis. For example, the encoding end determines the second context index corresponding to the X-axis based on the coordinate information of the first point on the X-axis included in the N prediction nodes, and selects the context model corresponding to the X-axis from multiple context models based on the first context index and/or the second context index corresponding to the X-axis, and then uses the context model corresponding to the X-axis to predict the coordinate information of the current point on the X-axis to obtain the X coordinate value of the current point. For another example, the encoding end determines the second context index corresponding to the Y-axis based on the coordinate information of the first point on the Y-axis included in the N prediction nodes, and based on the first context index and/or the second context index corresponding to the Y-axis, selects the context model corresponding to the Y-axis from multiple context models, and then uses the context model corresponding to the Y-axis to predict and encode the coordinate information of the current point on the Y-axis to obtain the Y coordinate value of the current point.
下面对编码端基于N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引的过程进行介绍。The following introduces a process in which the encoder determines the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis.
本申请实施例中,上述S202-A1-321的实现方式包括但不限于如下几种:In the embodiment of the present application, the implementation methods of the above S202-A1-321 include but are not limited to the following:
方式一,对N个预测节点所包括的第一点进行加权,基于加权后的坐标信息,确定第i个坐标轴对应的第二上下文索引。此时,上述S202-A1-321包括如下S202-A1-321-11至S202-A1-321-13的步骤:Method 1: weight the first points included in the N prediction nodes, and determine the second context index corresponding to the i-th coordinate axis based on the weighted coordinate information. At this time, the above S202-A1-321 includes the following steps S202-A1-321-11 to S202-A1-321-13:
S202-A1-321-11、确定预测节点对应的第一权重;S202-A1-321-11. Determine a first weight corresponding to the prediction node;
S202-A1-321-12、基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点;S202-A1-321-12, based on the first weight, weighting the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point;
S202-A1-321-13、基于第一加权点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。S202-A1-321-13. Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the first weighted point on the i-th coordinate axis.
在该方式一中,若当前节点包括多个预测节点,即N个预测节点时,在基于N个预测节点所包括的第一点的坐标信息,确定第i个坐标轴对应的第二上下文索引时,可以为N个预测节点中的每一个预测节点确定一个权重,即第一权重。这样可以基于各预测节点的第一权重,对各预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点,进而根据第一加权点在第i个坐标轴上坐标信息,确定第i个坐标轴对应的第二上下文索引,从而提高了基于N个预测节点的几何编码信息,对当前点进行编码的准确性。In the first mode, if the current node includes multiple prediction nodes, that is, N prediction nodes, when determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes, a weight, that is, the first weight, can be determined for each of the N prediction nodes. In this way, based on the first weight of each prediction node, the coordinate information of the first point included in each prediction node can be weighted to obtain a first weighted point, and then the second context index corresponding to the i-th coordinate axis can be determined based on the coordinate information of the first weighted point on the i-th coordinate axis, thereby improving the accuracy of encoding the current point based on the geometric encoding information of the N prediction nodes.
本申请实施例对确定N个预测节点分别对应的第一权重的过程可以参照上述实施例的描述,在此不再赘述。The process of determining the first weights corresponding to the N prediction nodes respectively in the embodiment of the present application can refer to the description of the above embodiment, which will not be repeated here.
编码端确定出N个预测节点中每一个预测节点对应的第一权重后,基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点。After the encoder determines the first weight corresponding to each of the N prediction nodes, the encoder performs weighted processing on the coordinate information of the first point included in the N prediction nodes based on the first weight to obtain a first weighted point.
本申请实施例对基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点的具体方式不做限制。The embodiment of the present application does not limit the specific method of obtaining the first weighted point by weighted processing the coordinate information of the first point included in the N prediction nodes based on the first weight.
在一种示例中,基于第一权重,对N个预测节点所包括的第一点的坐标信息进行加权平均,得到第一加权点。In one example, based on the first weight, the coordinate information of the first point included in the N prediction nodes is weighted averaged to obtain a first weighted point.
基于方式步骤,确定出第一加权点后,基于第一加权点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。Based on the method steps, after the first weighted point is determined, the second context index corresponding to the i-th coordinate axis is determined based on the coordinate information of the first weighted point on the i-th coordinate axis.
由上述可知,第一加权点是对N个预测节点中的第一点进行加权得到,其中预测节点后的第一点的各bit位的取值只有2种结果,为0或1。因此,在一些实施例中,对N个预测节点中的第一点进行加权得到的第一加权点的各bit 位的取值也为0或1。这样,对当前点在第i个坐标轴上的第i个bit位进行编码时,则基于第一加权点在第i个坐标轴上的第i个bit位的取值,确定第i个坐标轴上的第i个bit位对应的第二上下文索引。例如,若第一加权点在第i个坐标轴上的第i个bit位的取值为0,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为0。再例如,若第一加权点在第i个坐标轴上的第i个bit位的取值为1,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为1。最后,编码端基于第一上下文索引和/或第i个坐标轴上的第i个bit位对应的第二上下文索引,确定第i个坐标轴上的第i个bit位对应的上下文模型,并使用该上下文模型对当前点在第i个坐标轴上的第i个bit位的值进行预测编码。As can be seen from the above, the first weighted point is obtained by weighting the first point in the N prediction nodes, wherein the values of each bit of the first point after the prediction node have only two results, which are 0 or 1. Therefore, in some embodiments, the values of each bit of the first weighted point obtained by weighting the first point in the N prediction nodes are also 0 or 1. In this way, when the i-th bit of the current point on the i-th coordinate axis is encoded, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined based on the value of the i-th bit of the first weighted point on the i-th coordinate axis. For example, if the value of the i-th bit of the first weighted point on the i-th coordinate axis is 0, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 0. For another example, if the value of the i-th bit of the first weighted point on the i-th coordinate axis is 1, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 1. Finally, the encoding end determines the context model corresponding to the i-th bit on the i-th coordinate axis based on the first context index and/or the second context index corresponding to the i-th bit on the i-th coordinate axis, and uses the context model to predict the value of the i-th bit of the current point on the i-th coordinate axis.
编码端除了基于上述方式一确定出第二上下文索引后,还可以通过如下方式二,确定出第二上下文索引。In addition to determining the second context index based on the above-mentioned method 1, the encoder may also determine the second context index through the following method 2.
方式二,若K大于1时,则对K个预测参考帧中每一个预测参考帧中的预测节点所包括的第一点进行加权,基于加权后的坐标信息,确定第i个坐标轴对应的第二上下文索引。此时,上述S202-B包括如下S202-B21至S202-B23的步骤::Method 2: if K is greater than 1, weight the first point included in the prediction node in each of the K prediction reference frames, and determine the second context index corresponding to the i-th coordinate axis based on the weighted coordinate information. At this time, the above S202-B includes the following steps S202-B21 to S202-B23:
S202-A1-321-21、针对K个预测参考帧中的第j个预测参考帧,确定第j个预测参考帧中预测节点对应的第一权重;S202-A1-321-21. For a j-th prediction reference frame among the K prediction reference frames, determine a first weight corresponding to a prediction node in the j-th prediction reference frame;
S202-A1-321-22、基于第一权重,对第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到第j个预测参考帧对应的第二加权点,j为小于或等于K的正整数;S202-A1-321-22, based on the first weight, weighting the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K;
S202-A1-321-23、基于K个预测参考帧对应的第二加权点,确定第i个坐标轴对应的第二上下文索引。S202-A1-321-23. Determine a second context index corresponding to the i-th coordinate axis based on the second weighted points corresponding to the K predicted reference frames.
在该方式二中,在确定当前点的几何信息时,对这K个预测参考帧中的每一个预测参考帧分别进行考虑。具体是,确定K个预测参考帧中每一个预测参考帧的预测节点中的第一点的坐标信息,确定每一个预测参考帧对应的第二加权点,进而基于每一个预测参考帧对应的第二加权点的坐标信息,确定第i个坐标轴对应的第二上下文索引,实现第二上下文索引的准确预测,进而提升点云的编码效率。In the second method, when determining the geometric information of the current point, each of the K prediction reference frames is considered separately. Specifically, the coordinate information of the first point in the prediction node of each prediction reference frame in the K prediction reference frames is determined, and the second weighted point corresponding to each prediction reference frame is determined, and then based on the coordinate information of the second weighted point corresponding to each prediction reference frame, the second context index corresponding to the i-th coordinate axis is determined, and the second context index is accurately predicted, thereby improving the coding efficiency of the point cloud.
本申请实施例中,编码端确定K个预测参考帧中每一个预测参考帧对应的第二加权点的具体方式相同,为了便于描述,在此以K个预测参考帧中的第j个预测参考帧为例进行说明。In the embodiment of the present application, the specific method in which the encoding end determines the second weighted point corresponding to each of the K prediction reference frames is the same. For ease of description, the jth prediction reference frame among the K prediction reference frames is used as an example for illustration.
在本申请实施例中,当前节点在第j个预测参考帧中包括至少一个预测节点,这样基于该第j个预测参考帧中的这至少一个预测节点所包括的第一点的坐标信息,确定该第j个预测参考帧对应的第二加权点。In an embodiment of the present application, the current node includes at least one prediction node in the jth prediction reference frame, so that based on the coordinate information of the first point included in the at least one prediction node in the jth prediction reference frame, the second weighted point corresponding to the jth prediction reference frame is determined.
举例说明,第j个预测参考帧中包括当前节点的2个预测节点,分别记为预测节点1和预测节点2,进而对预测节点1所包括的第一点的几何信息和预测节点2所包括的第一点的坐标信息进行加权处理,得到第j个预测参考帧对应的第二加权点。For example, the j-th prediction reference frame includes two prediction nodes of the current node, which are respectively recorded as prediction node 1 and prediction node 2, and then the geometric information of the first point included in prediction node 1 and the coordinate information of the first point included in prediction node 2 are weighted to obtain the second weighted point corresponding to the j-th prediction reference frame.
编码端对第j个预测参考帧中的预测节点所包括的第一点的几何信息进行加权处理之前,首先需要确定出第j个预测参考帧中各预测节点对应的第一权重。其中,第一权重的确定过程可以参照上述实施例的描述,在此不再赘述。Before the encoder performs weighted processing on the geometric information of the first point included in the prediction node in the jth prediction reference frame, it is necessary to first determine the first weight corresponding to each prediction node in the jth prediction reference frame. The process of determining the first weight can refer to the description of the above embodiment and will not be repeated here.
接着,编码端基于第一权重,对第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到第j个预测参考帧对应的第二加权点。Next, the encoder performs weighted processing on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame based on the first weight to obtain a second weighted point corresponding to the j-th prediction reference frame.
在一种示例中,基于第一权重,对第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权平均,得到第j个预测参考帧对应的第二加权点。In one example, based on the first weight, weighted averaging is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame.
上述对确定K个预测参考帧中第j个预测参考帧对应的第二加权点的过程进行介绍,K个预测参考帧中其他预测参考帧对应的第二加权点可以参照上述第j个预测参考帧对应的方式进行确定。The above introduces the process of determining the second weighted point corresponding to the j-th prediction reference frame among the K prediction reference frames. The second weighted points corresponding to other prediction reference frames among the K prediction reference frames can be determined by referring to the method corresponding to the j-th prediction reference frame.
编码端确定出K个预测参考帧中每一个预测参考帧对应的第二加权点后,执行上述S202-A1-321-23的步骤。After the encoding end determines the second weighted point corresponding to each of the K predicted reference frames, it executes the above-mentioned step S202-A1-321-23.
本申请实施对基于K个预测参考帧对应的第二加权点,确定第i个坐标轴对应的第二上下文索引的具体方式不做限制。The present application does not limit the specific method of determining the second context index corresponding to the i-th coordinate axis based on the second weighted points corresponding to the K prediction reference frames.
在一些实施例中,编码端确定K个预测参考帧对应的第二加权点在第i个坐标轴上的坐标信息的平均值,基于该平均值,确定第i个坐标轴对应的第二上下文索引。In some embodiments, the encoding end determines an average value of coordinate information of second weighted points corresponding to K predicted reference frames on the i-th coordinate axis, and determines a second context index corresponding to the i-th coordinate axis based on the average value.
在一些实施例中,上述S202-A1-321-23包括如下S202-A1-321-231至S202-A1-321-233的步骤:In some embodiments, the above S202-A1-321-23 includes the following steps S202-A1-321-231 to S202-A1-321-233:
S202-A1-321-231、确定K个预测参考帧对应的第二权重;S202-A1-321-231, determine second weights corresponding to K prediction reference frames;
S202-B232、基于第二权重对K个预测参考帧对应的第二加权点的几何信息进行加权处理,得到第三加权点;S202-B232, weighting the geometric information of the second weighted points corresponding to the K prediction reference frames based on the second weight to obtain a third weighted point;
S202-B233、基于第三加权点在所述第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。S202-B233. Determine a second context index corresponding to the i-th coordinate axis based on the coordinate information of the third weighted point on the i-th coordinate axis.
在该实施例中,编码端可以参照上述实施例的方法,确定K个预测参考帧中每一个预测参考帧对应的第二权重。接着,基于第二权重对K个预测参考帧分别对应的第二加权点的坐标信息进行加权处理,得到第三加权点。In this embodiment, the encoding end may refer to the method of the above embodiment to determine the second weight corresponding to each of the K prediction reference frames. Then, based on the second weight, weighted processing is performed on the coordinate information of the second weighted points corresponding to the K prediction reference frames to obtain a third weighted point.
举例说明,假设K=2,例如当前待编码帧包括2个预测参考帧,这2个预测参考帧包括当前待编码帧的前向帧和后向帧,假设前向帧对应的第二权重为W1、后向帧对应的第二权重为W2,这样基于W1和W2,对前向帧对应的第二加权点的几何信息和后向帧对应的第二加权点的几何信息进行加权,得到第三加权点的几何信息。For example, assuming K=2, for example, the current frame to be encoded includes 2 prediction reference frames, and these 2 prediction reference frames include the forward frame and backward frame of the current frame to be encoded. Assuming that the second weight corresponding to the forward frame is W1, and the second weight corresponding to the backward frame is W2, based on W1 and W2, the geometric information of the second weighted point corresponding to the forward frame and the geometric information of the second weighted point corresponding to the backward frame are weighted to obtain the geometric information of the third weighted point.
在一种示例中,基于第二权重,对K个预测参考帧分别对应的第二加权点的几何信息进行加权平均,得到第三加权点的坐标信息。In one example, based on the second weight, weighted averaging is performed on the geometric information of the second weighted points respectively corresponding to the K prediction reference frames to obtain coordinate information of the third weighted point.
编码端基于上述步骤,确定出第三加权点的几何信息后,基于第三加权点在第i个坐标轴上的坐标信息,确定第i个坐标轴对应的第二上下文索引。After determining the geometric information of the third weighted point based on the above steps, the encoder determines the second context index corresponding to the i-th coordinate axis based on the coordinate information of the third weighted point on the i-th coordinate axis.
由上述可知,第三加权点是各预测参考帧中的预测节点中的第一点进行加权得到,其中预测节点后的第一点的各bit位的取值只有2种结果,为0或1。因此,在一些实施例中,对N个预测节点中的第一点进行加权得到的第一加权点的各bit位的取值也为0或1。这样,对当前点在第i个坐标轴上的第i个bit位进行编码时,则基于第三加权点在第i个坐标轴上的第i个bit位的取值,确定第i个坐标轴上的第i个bit位对应的第二上下文索引。例如,若第三加权点在第i个坐标轴上的第i个bit位的取值为0,则确定第i个坐标轴上的第i个bit位对应的第二上下文索引为0。再例如,若第三加权点在第i个坐标轴上的第i个bit位的取值为1,则确定第i个坐标轴上的第i个bit位对应的第二上下 文索引为1。最后,编码端基于第一上下文索引和/或第i个坐标轴上的第i个bit位对应的第二上下文索引,确定第i个坐标轴上的第i个bit位对应的上下文模型,并使用该上下文模型对当前点在第i个坐标轴上的第i个bit位的值进行预测编码。As can be seen from the above, the third weighted point is obtained by weighting the first point in the prediction node in each prediction reference frame, wherein the value of each bit of the first point after the prediction node has only two results, which is 0 or 1. Therefore, in some embodiments, the value of each bit of the first weighted point obtained by weighting the first point in the N prediction nodes is also 0 or 1. In this way, when the i-th bit of the current point on the i-th coordinate axis is encoded, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined based on the value of the i-th bit of the third weighted point on the i-th coordinate axis. For example, if the value of the i-th bit of the third weighted point on the i-th coordinate axis is 0, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 0. For another example, if the value of the i-th bit of the third weighted point on the i-th coordinate axis is 1, the second context index corresponding to the i-th bit on the i-th coordinate axis is determined to be 1. Finally, the encoding end determines the context model corresponding to the i-th bit on the i-th coordinate axis based on the first context index and/or the second context index corresponding to the i-th bit on the i-th coordinate axis, and uses the context model to predict the value of the i-th bit of the current point on the i-th coordinate axis.
编码端基于上述步骤,确定出第一上下文索引和/或第二上下文索引后,基于第一上下文索引和/或第二上下文索引,确定上下文模型,并使用该上下文模型对当前点的坐标信息进行编码。After the encoding end determines the first context index and/or the second context index based on the above steps, it determines the context model based on the first context index and/or the second context index, and uses the context model to encode the coordinate information of the current point.
在一种示例中,假设预测节点的DCM模式信息为PredDCMode,并且预测节点中含有的点数为PredNumPoints,假设预测节点中第一点的几何信息为predPointPos。假设,编码端利用预测节点的IDCM模式以及预测节点中点的几何信息来对当前点的几何信息进行预测编码,即编码端使用的预测节点的几何编码信息包含如下两种:In an example, assuming that the DCM mode information of the prediction node is PredDCMode, and the number of points contained in the prediction node is PredNumPoints, and assuming that the geometric information of the first point in the prediction node is predPointPos. Assume that the encoder uses the IDCM mode of the prediction node and the geometric information of the point in the prediction node to predict the geometric information of the current point, that is, the geometric coding information of the prediction node used by the encoder includes the following two types:
1)预测节点的IDCM模式;1) IDCM mode of the prediction node;
2)预测节点中点(即第一点)的几何信息,即预测节点中点对应精度上的bit信息(0或者1)。2) The geometric information of the midpoint of the prediction node (i.e., the first point), that is, the bit information (0 or 1) corresponding to the precision of the midpoint of the prediction node.
例如,在GPCC框架下,预测节点的IDCM模式包括PredDCMode(0,1,2)。在AVS框架下,预测节点的IDCM模式包括PredDCMode(0,1)。For example, in the GPCC framework, the IDCM mode of the prediction node includes PredDCMode(0,1,2). In the AVS framework, the IDCM mode of the prediction node includes PredDCMode(0,1).
假设当前节点中点的数目为numPoints,并且每个点的几何信息为PointPos,待编码的bit精度深度为nodeSizeLog2,则对当前节点中的每个点的几何信息编码过程如下:Assuming that the number of points in the current node is numPoints, and the geometric information of each point is PointPos, and the bit precision depth to be encoded is nodeSizeLog2, the geometric information encoding process of each point in the current node is as follows:

则通过上述编码过程,可以得到当前节点中每一个点的几何信息。其中,ctx1为第一上下文索引,ctx2为第二上下文索引。Through the above encoding process, the geometric information of each point in the current node can be obtained. Among them, ctx1 is the first context index, and ctx2 is the second context index.
本申请实施例提供的点云编码方法,在对当前编码帧中的当前节点进行编码时,在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点,基于这N个预测节点中点的几何编码信息,对当前节点中点的坐标信息进行预测编码。也就是说,本申请实施例对节点进行DCM直接编码时进行优化,通过考虑相邻帧之间时域上的相关性,利用预测参考帧中预测节点的几何信息对待节点IDCM节点(即当前节点)中点的几何信息进行预测编码,通过考虑相邻帧之间时域相关性来进一步提升点云的几何信息编码效率。The point cloud encoding method provided by the embodiment of the present application, when encoding the current node in the current encoding frame, determines N predicted nodes of the current node in the predicted reference frame of the current frame to be encoded, and predictively encodes the coordinate information of the midpoint of the current node based on the geometric encoding information of the midpoints of these N predicted nodes. In other words, the embodiment of the present application optimizes the direct DCM encoding of the node, and predictively encodes the geometric information of the midpoint of the IDCM node (i.e., the current node) of the to-be-encoded node by considering the correlation in the time domain between adjacent frames, using the geometric information of the predicted node in the predicted reference frame, and further improves the efficiency of the geometric information encoding of the point cloud by considering the correlation in the time domain between adjacent frames.
应理解,图10至图17仅为本申请的示例,不应理解为对本申请的限制。It should be understood that Figures 10 to 17 are merely examples of the present application and should not be construed as limitations to the present application.
以上结合附图详细描述了本申请的优选实施方式,但是,本申请并不限于上述实施方式中的具体细节,在本申请的技术构思范围内,可以对本申请的技术方案进行多种简单变型,这些简单变型均属于本申请的保护范围。例如,在上述具体实施方式中所描述的各个具体技术特征,在不矛盾的情况下,可以通过任何合适的方式进行组合,为了避免不必要的重复,本申请对各种可能的组合方式不再另行说明。又例如,本申请的各种不同的实施方式之间也可以进行任意组合,只要其不违背本申请的思想,其同样应当视为本申请所公开的内容。The preferred embodiments of the present application are described in detail above in conjunction with the accompanying drawings. However, the present application is not limited to the specific details in the above embodiments. Within the technical concept of the present application, the technical solution of the present application can be subjected to a variety of simple modifications, and these simple modifications all belong to the protection scope of the present application. For example, the various specific technical features described in the above specific embodiments can be combined in any suitable manner without contradiction. In order to avoid unnecessary repetition, the present application will not further explain various possible combinations. For another example, the various different embodiments of the present application can also be arbitrarily combined, as long as they do not violate the ideas of the present application, they should also be regarded as the contents disclosed in the present application.
还应理解,在本申请的各种方法实施例中,上述各过程的序号的大小并不意味着执行顺序的先后,各过程的执行顺序应以其功能和内在逻辑确定,而不应对本申请实施例的实施过程构成任何限定。另外,本申请实施例中,术语“和/或”,仅仅是一种描述关联对象的关联关系,表示可以存在三种关系。具体地,A和/或B可以表示:单独存在A,同时存在A和B,单独存在B这三种情况。另外,本文中字符“/”,一般表示前后关联对象是一种“或”的关系。It should also be understood that in the various method embodiments of the present application, the size of the sequence number of each process does not mean the order of execution, and the execution order of each process should be determined by its function and internal logic, and should not constitute any limitation on the implementation process of the embodiment of the present application. In addition, in the embodiment of the present application, the term "and/or" is merely a description of the association relationship of associated objects, indicating that three relationships may exist. Specifically, A and/or B can represent: A exists alone, A and B exist at the same time, and B exists alone. In addition, the character "/" in this article generally indicates that the objects associated before and after are in an "or" relationship.
上文结合图10至图17,详细描述了本申请的方法实施例,下文结合图18至图19,详细描述本申请的装置实施例。The above text, in combination with Figures 10 to 17 , describes in detail a method embodiment of the present application. The following text, in combination with Figures 18 to 19 , describes in detail a device embodiment of the present application.
图18是本申请实施例提供的点云解码装置的示意性框图。Figure 18 is a schematic block diagram of the point cloud decoding device provided in an embodiment of the present application.
如图18所示,该点云解码装置10可以包括:As shown in FIG. 18 , the point cloud decoding device 10 may include:
确定单元11,用于在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待解码帧中的待解码节点,所述N为正整数;A determination unit 11 is used to determine N prediction nodes of a current node in a prediction reference frame of a current frame to be decoded, wherein the current node is a node to be decoded in the current frame to be decoded, and N is a positive integer;
解码单元12,用于基于所述N个预测节点的几何解码信息,对所述当前节点中点的坐标信息进行预测解码。The decoding unit 12 is used to predict and decode the coordinate information of the midpoint of the current node based on the geometric decoding information of the N predicted nodes.
在一些实施例中,所述当前待解码帧包括K个预测参考帧,确定单元11,具体用于针对所述K个预测参考帧中的第k个预测参考帧,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,所述k为小于或等于K的正整数,所述K为正整数;基于所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定所述当前节点的N个预测节点。In some embodiments, the current frame to be decoded includes K prediction reference frames, and the determination unit 11 is specifically used to determine at least one prediction node of the current node in the kth prediction reference frame among the K prediction reference frames, where k is a positive integer less than or equal to K, and K is a positive integer; based on at least one prediction node of the current node in the K prediction reference frames, determine N prediction nodes of the current node.
在一些实施例中,确定单元11,具体用于在所述当前待解码帧中,确定所述当前节点的M个领域节点,所述M个领域节点中包括所述当前节点,所述M为正整数;针对所述M个领域节点中的第i个领域节点,确定所述第i个领域节点在所述第k个预测参考帧中的对应节点,所述i为小于或等于M的正整数;基于所述M个领域节点在所述第k个预测参考帧中的对应节点,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点。In some embodiments, the determination unit 11 is specifically used to determine M domain nodes of the current node in the current frame to be decoded, where the M domain nodes include the current node, and M is a positive integer; for the i-th domain node among the M domain nodes, determine the corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M; based on the corresponding nodes of the M domain nodes in the k-th prediction reference frame, determine at least one prediction node of the current node in the k-th prediction reference frame.
在一些实施例中,确定单元11,具体用于确定所述当前节点在所述第k个预测参考帧中的对应节点;确定所述对应节点的至少一个领域节点;将所述至少一个领域节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。In some embodiments, the determination unit 11 is specifically used to determine the corresponding node of the current node in the kth prediction reference frame; determine at least one domain node of the corresponding node; and determine the at least one domain node as at least one prediction node of the current node in the kth prediction reference frame.
在一些实施例中,确定单元11,具体用于在所述当前待解码帧中,确定第i个节点的父节点,作为第i个父节点,所述第i个节点为所述第i个领域节点或者为所述当前节点;确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,作为第i个匹配节点;将所述i个匹配节点的子节点中的一个子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。In some embodiments, the determination unit 11 is specifically used to determine the parent node of the i-th node in the current frame to be decoded, as the i-th parent node, the i-th node being the i-th domain node or the current node; determine the matching node of the i-th parent node in the k-th prediction reference frame as the i-th matching node; and determine one of the child nodes of the i-matching node as the corresponding node of the i-th node in the k-th prediction reference frame.
在一些实施例中,确定单元11,具体用于基于所述第i个父节点的占位信息,确定所述第i个父节点在所述第k个预测参考帧中的匹配节点。In some embodiments, the determination unit 11 is specifically configured to determine a matching node of the i-th parent node in the k-th prediction reference frame based on the placeholder information of the i-th parent node.
在一些实施例中,确定单元11,具体用于将所述第k个预测参考帧中,占位信息与所述第i个父节点的占位信息之间的差异最小的节点,确定为所述第i个父节点在所述第k个预测参考帧中的匹配节点。In some embodiments, the determination unit 11 is specifically used to determine the node whose occupancy information in the kth prediction reference frame has the smallest difference with the occupancy information of the i-th parent node as the matching node of the i-th parent node in the k-th prediction reference frame.
在一些实施例中,确定单元11,具体用于确定所述第i个节点在所述父节点所包括的子节点中的第一序号;将所述第i个匹配节点的子节点中序号为第一序号的子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。In some embodiments, the determination unit 11 is specifically used to determine the first serial number of the i-th node among the child nodes included in the parent node; and determine the child node with the first serial number among the child nodes of the i-th matching node as the corresponding node of the i-th node in the k-th prediction reference frame.
在一些实施例中,确定单元11,具体用于将所述M个领域节点在所述第k个预测参考帧中的对应节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。In some embodiments, the determination unit 11 is specifically configured to determine corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame.
在一些实施例中,确定单元11,具体用于将所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定为所述当前节点的N个预测节点。In some embodiments, the determination unit 11 is specifically configured to determine at least one prediction node of the current node in the K prediction reference frames as N prediction nodes of the current node.
在一些实施例中,若所述当前待解码帧为P帧,则所述K个预测参考帧包括所述当前待解码帧的前向帧。In some embodiments, if the current frame to be decoded is a P frame, the K prediction reference frames include a forward frame of the current frame to be decoded.
在一些实施例中,若所述当前待解码帧为B帧,则所述K个预测参考帧包括所述当前待解码帧的前向帧和后向帧。In some embodiments, if the current frame to be decoded is a B frame, the K prediction reference frames include a forward frame and a backward frame of the current frame to be decoded.
在一些实施例中,预测单元12,具体用于基于所述N个预测节点的几何解码信息,确定上下文模型的索引;基于所述上下文模型的索引,确定所述上下文模型;使用所述上下文模型,对所述当前节点中的当前点的坐标信息进行预测解码。In some embodiments, the prediction unit 12 is specifically used to determine the index of the context model based on the geometric decoding information of the N prediction nodes; determine the context model based on the index of the context model; and use the context model to predict and decode the coordinate information of the current point in the current node.
在一些实施例中,所述预测节点的几何解码信息包括所述预测节点的直接解码信息和/或所述预测节点中点的位置信息,所述直接解码信息用于指示所述预测节点是否满足直接解码方式进行解码的条件,预测单元12,具体用于基于所述N个预测节点的直接解码信息,确定第一上下文索引,和/或基于所述N个预测节点中点的坐标信息,确定第二上下文索引;基于所述第一上下文索引和/或所述第二上下文索引,从预设的多个上下文模型中,选出所述上下文模型。In some embodiments, the geometric decoding information of the prediction node includes direct decoding information of the prediction node and/or position information of the midpoint of the prediction node, and the direct decoding information is used to indicate whether the prediction node meets the conditions for decoding by direct decoding. The prediction unit 12 is specifically used to determine a first context index based on the direct decoding information of the N prediction nodes, and/or determine a second context index based on the coordinate information of the midpoint of the N prediction nodes; based on the first context index and/or the second context index, select the context model from a plurality of preset context models.
在一些实施例中,预测单元12,具体用于针对所述N个预测节点中的任一预测节点,基于所述预测节点的直接解码信息,确定所述预测节点对应的第一数值;基于所述N个预测节点对应的第一数值,确定所述第一上下文索引。In some embodiments, the prediction unit 12 is specifically used to determine, for any prediction node among the N prediction nodes, a first numerical value corresponding to the prediction node based on direct decoding information of the prediction node; and determine the first context index based on the first numerical values corresponding to the N prediction nodes.
在一些实施例中,预测单元12,具体用于将所述预测节点的直接解码模式的编号,确定所述预测节点对应的第一数值。In some embodiments, the prediction unit 12 is specifically configured to determine the first value corresponding to the prediction node by using the number of the direct decoding mode of the prediction node.
在一些实施例中,预测单元12,具体用于确定所述预测节点对应的第一权重;基于所述第一权重,对所述N个预测节点对应的第一数值进行加权处理,得到第一加权预测值;基于所述第一加权预测值,确定所述第一上下文索引。In some embodiments, the prediction unit 12 is specifically used to determine a first weight corresponding to the prediction node; based on the first weight, weighted processing is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value; based on the first weighted prediction value, the first context index is determined.
在一些实施例中,预测单元12,具体用于针对所述K个预测参考帧中的第j个预测参考帧,基于所述当前节点在所述第j个预测参考帧中的预测节点的直接解码信息,确定所述第j个预测参考帧中的预测节点对应的第一数值,所述j为小于或等于K的正整数;确定所述预测节点对应的第一权重,并基于所述第一权重对所述第j个预测参考帧中的预测节点对应的第一数值进行加权处理,得到所述第j个预测参考帧对应的第二加权预测值;基于所述K个预测参考帧对应的第二加权预测值,确定所述第一上下文索引。In some embodiments, the prediction unit 12 is specifically used to determine, for the j-th prediction reference frame among the K prediction reference frames, a first numerical value corresponding to the prediction node in the j-th prediction reference frame based on direct decoding information of the prediction node of the current node in the j-th prediction reference frame, where j is a positive integer less than or equal to K; determine a first weight corresponding to the prediction node, and weightedly process the first numerical value corresponding to the prediction node in the j-th prediction reference frame based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame; and determine the first context index based on the second weighted prediction values corresponding to the K prediction reference frames.
在一些实施例中,预测单元12,具体用于确定所述K个预测参考帧对应的第二权重;基于所述第二权重对所述K个预测参考帧分别对应的第二加权预测值进行加权处理,得到所述第一上下文索引。In some embodiments, the prediction unit 12 is specifically used to determine second weights corresponding to the K prediction reference frames; based on the second weights, weighted processing is performed on second weighted prediction values corresponding to the K prediction reference frames respectively to obtain the first context index.
在一些实施例中,预测单元12,具体用于对于所述N个预测节点中的任一预测节点,从所述预测节点所包括的点中,选出所述当前节点中的当前点对应的第一点;基于所述N个预测节点所包括的第一点的坐标信息,确定所述第二上下文索引。In some embodiments, the prediction unit 12 is specifically used to select, for any prediction node among the N prediction nodes, a first point corresponding to the current point in the current node from the points included in the prediction node; and determine the second context index based on the coordinate information of the first point included in the N prediction nodes.
在一些实施例中,预测单元12,具体用于基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,所述第i个坐标轴为X坐标轴、Y坐标轴或Z坐标轴;基于所述第一上下文索引和/或所述第i个坐标轴对应的第二上下文索引,从所述多个上下文模型中,选出所述第i个坐标轴对应的上下文模型;使用所述第i个坐标轴对应的上下文模型,对所述当前点在所述第i个坐标轴上的坐标信息进行预测解码。In some embodiments, the prediction unit 12 is specifically used to determine the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis, where the i-th coordinate axis is the X-coordinate axis, the Y-coordinate axis or the Z-coordinate axis; based on the first context index and/or the second context index corresponding to the i-th coordinate axis, select the context model corresponding to the i-th coordinate axis from the multiple context models; and use the context model corresponding to the i-th coordinate axis to predict and decode the coordinate information of the current point on the i-th coordinate axis.
在一些实施例中,预测单元12,具体用于确定所述预测节点对应的第一权重;基于所述第一权重,对所述N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点;基于所述第一加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。In some embodiments, the prediction unit 12 is specifically used to determine a first weight corresponding to the prediction node; based on the first weight, weighted processing is performed on the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point; based on the coordinate information of the first weighted point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined.
在一些实施例中,若所述K大于1时,则预测单元12,具体用于基于针对所述K个预测参考帧中的第j个预测参考帧,确定所述第j个预测参考帧中预测节点对应的第一权重;基于所述第一权重,对所述第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到所述第j个预测参考帧对应的第二加权点,所述j为小于或等于K的正整数;基于所述K个预测参考帧对应的第二加权点,确定所述第i个坐标轴对应的第二上下文索引。In some embodiments, if K is greater than 1, the prediction unit 12 is specifically used to determine a first weight corresponding to a prediction node in the j-th prediction reference frame based on the j-th prediction reference frame among the K prediction reference frames; based on the first weight, weighted processing is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K; based on the second weighted points corresponding to the K prediction reference frames, a second context index corresponding to the i-th coordinate axis is determined.
在一些实施例中,预测单元12,具体用于基于确定所述K个预测参考帧对应的第二权重;基于所述第二权重对所述K个预测参考帧对应的第二加权点的坐标信息进行加权处理,得到第三加权点;基于所述第三加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。In some embodiments, the prediction unit 12 is specifically used to determine the second weights corresponding to the K prediction reference frames; based on the second weights, weighted processing is performed on the coordinate information of the second weighted points corresponding to the K prediction reference frames to obtain a third weighted point; based on the coordinate information of the third weighted point on the i-th coordinate axis, determine the second context index corresponding to the i-th coordinate axis.
在一些实施例中,预测单元12,具体用于基于所述预测节点对应的领域节点与所述当前节点之间的距离,确定所述预测节点对应的第一权重。In some embodiments, the prediction unit 12 is specifically configured to determine a first weight corresponding to the prediction node based on a distance between a domain node corresponding to the prediction node and the current node.
在一些实施例中,预测单元12,具体用于基于所述预测参考帧与所述当前待解码帧之间的时间差距,确定所述预 测参考帧对应的第二权重。In some embodiments, the prediction unit 12 is specifically used to determine the second weight corresponding to the predicted reference frame based on the time difference between the predicted reference frame and the current frame to be decoded.
应理解,装置实施例与方法实施例可以相互对应,类似的描述可以参照方法实施例。为避免重复,此处不再赘述。具体地,图18所示的点云解码装置10可以对应于执行本申请实施例的点云解码方法中的相应主体,并且点云解码装置10中的各个单元的前述和其它操作和/或功能分别为了实现点云解码方法中的相应流程,为了简洁,在此不再赘述。It should be understood that the device embodiment and the method embodiment may correspond to each other, and similar descriptions may refer to the method embodiment. To avoid repetition, no further description is given here. Specifically, the point cloud decoding device 10 shown in FIG. 18 may correspond to the corresponding subject in the point cloud decoding method of the embodiment of the present application, and the aforementioned and other operations and/or functions of each unit in the point cloud decoding device 10 are respectively for implementing the corresponding processes in the point cloud decoding method, and for the sake of brevity, no further description is given here.
图19是本申请实施例提供的点云编码装置的示意性框图。Figure 19 is a schematic block diagram of the point cloud encoding device provided in an embodiment of the present application.
如图19所示,点云编码装置20包括:As shown in FIG. 19 , the point cloud encoding device 20 includes:
确定单元21,具体用于在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待编码帧中的待编码节点,所述N为正整数;The determination unit 21 is specifically configured to determine N prediction nodes of a current node in a prediction reference frame of a current frame to be encoded, wherein the current node is a node to be encoded in the current frame to be encoded, and N is a positive integer;
编码单元22,用于基于所述N个预测节点的几何编码信息,对所述当前节点中点的坐标信息进行预测编码。The encoding unit 22 is used to perform predictive encoding on the coordinate information of the midpoint of the current node based on the geometric encoding information of the N predicted nodes.
在一些实施例中,所述当前待编码帧包括K个预测参考帧,确定单元21,具体用于针对所述K个预测参考帧中的第k个预测参考帧,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,所述k为小于或等于K的正整数,所述K为正整数;基于所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定所述当前节点的N个预测节点。In some embodiments, the current frame to be encoded includes K prediction reference frames, and the determination unit 21 is specifically used to determine at least one prediction node of the current node in the kth prediction reference frame among the K prediction reference frames, where k is a positive integer less than or equal to K, and K is a positive integer; based on at least one prediction node of the current node in the K prediction reference frames, determine N prediction nodes of the current node.
在一些实施例中,确定单元21,具体用于在所述当前待编码帧中,确定所述当前节点的M个领域节点,所述M个领域节点中包括所述当前节点,所述M为正整数;针对所述M个领域节点中的第i个领域节点,确定所述第i个领域节点在所述第k个预测参考帧中的对应节点,所述i为小于或等于M的正整数;基于所述M个领域节点在所述第k个预测参考帧中的对应节点,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点。In some embodiments, the determination unit 21 is specifically used to determine M domain nodes of the current node in the current frame to be encoded, where the M domain nodes include the current node, and M is a positive integer; for the i-th domain node among the M domain nodes, determine the corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M; based on the corresponding nodes of the M domain nodes in the k-th prediction reference frame, determine at least one prediction node of the current node in the k-th prediction reference frame.
在一些实施例中,确定单元21,具体用于确定所述当前节点在所述第k个预测参考帧中的对应节点;确定所述对应节点的至少一个领域节点;将所述至少一个领域节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。In some embodiments, the determination unit 21 is specifically used to determine the corresponding node of the current node in the kth prediction reference frame; determine at least one domain node of the corresponding node; and determine the at least one domain node as at least one prediction node of the current node in the kth prediction reference frame.
在一些实施例中,确定单元21,具体用于在所述当前待编码帧中,确定第i个节点的父节点,作为第i个父节点,所述第i个节点为所述第i个领域节点或者为所述当前节点;确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,作为第i个匹配节点;将所述i个匹配节点的子节点中的一个子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。In some embodiments, the determination unit 21 is specifically used to determine the parent node of the i-th node in the current frame to be encoded, as the i-th parent node, the i-th node being the i-th domain node or the current node; determine the matching node of the i-th parent node in the k-th prediction reference frame as the i-th matching node; and determine one of the child nodes of the i-matching node as the corresponding node of the i-th node in the k-th prediction reference frame.
在一些实施例中,确定单元21,具体用于基于所述第i个父节点的占位信息,确定所述第i个父节点在所述第k个预测参考帧中的匹配节点。In some embodiments, the determination unit 21 is specifically configured to determine a matching node of the i-th parent node in the k-th prediction reference frame based on the placeholder information of the i-th parent node.
在一些实施例中,确定单元21,具体用于将所述第k个预测参考帧中,占位信息与所述第i个父节点的占位信息之间的差异最小的节点,确定为所述第i个父节点在所述第k个预测参考帧中的匹配节点。In some embodiments, the determination unit 21 is specifically configured to determine the node whose placeholder information in the kth prediction reference frame has the smallest difference with the placeholder information of the i-th parent node as the matching node of the i-th parent node in the k-th prediction reference frame.
在一些实施例中,确定单元21,具体用于确定所述第i个节点在所述父节点所包括的子节点中的第一序号;将所述第i个匹配节点的子节点中序号为第一序号的子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。In some embodiments, the determination unit 21 is specifically used to determine the first serial number of the i-th node among the child nodes included in the parent node; and determine the child node with the first serial number among the child nodes of the i-th matching node as the corresponding node of the i-th node in the k-th prediction reference frame.
在一些实施例中,确定单元21,具体用于将所述M个领域节点在所述第k个预测参考帧中的对应节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。In some embodiments, the determination unit 21 is specifically configured to determine corresponding nodes of the M domain nodes in the k-th prediction reference frame as at least one prediction node of the current node in the k-th prediction reference frame.
在一些实施例中,确定单元21,具体用于将所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定为所述当前节点的N个预测节点。In some embodiments, the determination unit 21 is specifically configured to determine at least one prediction node of the current node in the K prediction reference frames as N prediction nodes of the current node.
在一些实施例中,若所述当前待编码帧为P帧,则所述K个预测参考帧包括所述当前待编码帧的前向帧。In some embodiments, if the current frame to be encoded is a P frame, the K prediction reference frames include a forward frame of the current frame to be encoded.
在一些实施例中,若所述当前待编码帧为B帧,则所述K个预测参考帧包括所述当前待编码帧的前向帧和后向帧。In some embodiments, if the current frame to be encoded is a B frame, the K prediction reference frames include a forward frame and a backward frame of the current frame to be encoded.
在一些实施例中,编码单元22,具体用于基于所述N个预测节点的几何编码信息,确定上下文模型的索引;基于所述上下文模型的索引,确定所述上下文模型;使用所述上下文模型,对所述当前节点中的当前点的坐标信息进行预测编码。In some embodiments, the encoding unit 22 is specifically used to determine the index of the context model based on the geometric encoding information of the N prediction nodes; determine the context model based on the index of the context model; and use the context model to predict and encode the coordinate information of the current point in the current node.
在一些实施例中,所述预测节点的几何编码信息包括所述预测节点的直接编码信息和/或所述预测节点中点的位置信息,所述直接编码信息用于指示所述预测节点是否满足直接编码方式进行编码的条件,编码单元22,具体用于基于所述N个预测节点的直接编码信息,确定第一上下文索引,和/或基于所述N个预测节点中点的坐标信息,确定第二上下文索引;基于所述第一上下文索引和/或所述第二上下文索引,从预设的多个上下文模型中,选出所述上下文模型。In some embodiments, the geometric coding information of the prediction node includes direct coding information of the prediction node and/or position information of the midpoint of the prediction node, and the direct coding information is used to indicate whether the prediction node meets the conditions for encoding in a direct coding manner. The encoding unit 22 is specifically used to determine a first context index based on the direct coding information of the N prediction nodes, and/or determine a second context index based on the coordinate information of the midpoints of the N prediction nodes; based on the first context index and/or the second context index, select the context model from a plurality of preset context models.
在一些实施例中,编码单元22,具体用于针对所述N个预测节点中的任一预测节点,基于所述预测节点的直接编码信息,确定所述预测节点对应的第一数值;基于所述N个预测节点对应的第一数值,确定所述第一上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine, for any prediction node among the N prediction nodes, a first numerical value corresponding to the prediction node based on direct encoding information of the prediction node; and determine the first context index based on the first numerical values corresponding to the N prediction nodes.
在一些实施例中,所述直接编码信息包括所述预测节点的直接编码模式,编码单元22,具体用于将所述预测节点的直接编码模式的编号,确定所述预测节点对应的第一数值。In some embodiments, the direct encoding information includes a direct encoding mode of the prediction node, and the encoding unit 22 is specifically configured to determine a first value corresponding to the prediction node by serializing the direct encoding mode of the prediction node.
在一些实施例中,编码单元22,具体用于确定所述预测节点对应的第一权重;基于所述第一权重,对所述N个预测节点对应的第一数值进行加权处理,得到第一加权预测值;基于所述第一加权预测值,确定所述第一上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine a first weight corresponding to the prediction node; based on the first weight, weighted processing is performed on the first numerical values corresponding to the N prediction nodes to obtain a first weighted prediction value; based on the first weighted prediction value, the first context index is determined.
在一些实施例中,编码单元22,具体用于针对所述K个预测参考帧中的第j个预测参考帧,基于所述当前节点在所述第j个预测参考帧中的预测节点的直接编码信息,确定所述第j个预测参考帧中的预测节点对应的第一数值,所述j为小于或等于K的正整数;确定所述预测节点对应的第一权重,并基于所述第一权重对所述第j个预测参考帧中的预测节点对应的第一数值进行加权处理,得到所述第j个预测参考帧对应的第二加权预测值;基于所述K个预测参考帧对应的第二加权预测值,确定所述第一上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine, for the j-th prediction reference frame among the K prediction reference frames, a first numerical value corresponding to the prediction node in the j-th prediction reference frame based on direct encoding information of the prediction node of the current node in the j-th prediction reference frame, where j is a positive integer less than or equal to K; determine a first weight corresponding to the prediction node, and weightedly process the first numerical value corresponding to the prediction node in the j-th prediction reference frame based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame; and determine the first context index based on the second weighted prediction values corresponding to the K prediction reference frames.
在一些实施例中,编码单元22,具体用于确定所述K个预测参考帧对应的第二权重;基于所述第二权重对所述K个预测参考帧分别对应的第二加权预测值进行加权处理,得到所述第一上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine the second weights corresponding to the K prediction reference frames; based on the second weights, weighted processing is performed on the second weighted prediction values corresponding to the K prediction reference frames respectively to obtain the first context index.
在一些实施例中,编码单元22,具体用于对于所述N个预测节点中的任一预测节点,从所述预测节点所包括的点中,选出所述当前节点中的当前点对应的第一点;基于所述N个预测节点所包括的第一点的坐标信息,确定所述第二上下文索引。In some embodiments, the encoding unit 22 is specifically used to select, for any prediction node among the N prediction nodes, a first point corresponding to the current point in the current node from the points included in the prediction node; and determine the second context index based on the coordinate information of the first point included in the N prediction nodes.
在一些实施例中,编码单元22,具体用于基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,所述第i个坐标轴为X坐标轴、Y坐标轴或Z坐标轴;基于所述第一上下文索引和/或所述第i个坐标轴对应的第二上下文索引,从所述多个上下文模型中,选出所述第i个坐标轴对应的上下文模型;使用所述第i个坐标轴对应的上下文模型,对所述当前点在所述第i个坐标轴上的坐标信息进行预测编码。In some embodiments, the encoding unit 22 is specifically used to determine the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis, where the i-th coordinate axis is the X-coordinate axis, the Y-coordinate axis or the Z-coordinate axis; based on the first context index and/or the second context index corresponding to the i-th coordinate axis, select the context model corresponding to the i-th coordinate axis from the multiple context models; and use the context model corresponding to the i-th coordinate axis to predict and encode the coordinate information of the current point on the i-th coordinate axis.
在一些实施例中,编码单元22,具体用于确定所述预测节点对应的第一权重;基于所述第一权重,对所述N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点;基于所述第一加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine a first weight corresponding to the prediction node; based on the first weight, weighted processing is performed on the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point; based on the coordinate information of the first weighted point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined.
在一些实施例中,编码单元22,具体用于针对所述K个预测参考帧中的第j个预测参考帧,确定所述第j个预测参考帧中预测节点对应的第一权重;基于所述第一权重,对所述第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到所述第j个预测参考帧对应的第二加权点,所述j为小于或等于K的正整数;基于所述K个预测参考帧对应的第二加权点,确定所述第i个坐标轴对应的第二上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine, for the j-th prediction reference frame among the K prediction reference frames, a first weight corresponding to a prediction node in the j-th prediction reference frame; based on the first weight, weighted processing is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K; based on the second weighted points corresponding to the K prediction reference frames, a second context index corresponding to the i-th coordinate axis is determined.
在一些实施例中,编码单元22,具体用于确定所述K个预测参考帧对应的第二权重;基于所述第二权重对所述K个预测参考帧对应的第二加权点的坐标信息进行加权处理,得到第三加权点;基于所述第三加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。In some embodiments, the encoding unit 22 is specifically used to determine a second weight corresponding to the K predicted reference frames; based on the second weight, weighted processing is performed on the coordinate information of the second weighted point corresponding to the K predicted reference frames to obtain a third weighted point; based on the coordinate information of the third weighted point on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis is determined.
在一些实施例中,编码单元22,具体用于基于所述预测节点对应的领域节点与所述当前节点之间的距离,确定所述预测节点对应的第一权重。In some embodiments, the encoding unit 22 is specifically configured to determine a first weight corresponding to the prediction node based on a distance between a domain node corresponding to the prediction node and the current node.
在一些实施例中,编码单元22,具体用于基于所述预测参考帧与所述当前待编码帧之间的时间差距,确定所述预测参考帧对应的第二权重。In some embodiments, the encoding unit 22 is specifically configured to determine a second weight corresponding to the predicted reference frame based on a time difference between the predicted reference frame and the current frame to be encoded.
应理解,装置实施例与方法实施例可以相互对应,类似的描述可以参照方法实施例。为避免重复,此处不再赘述。具体地,图19所示的点云编码装置20可以对应于执行本申请实施例的点云编码方法中的相应主体,并且点云编码装置20中的各个单元的前述和其它操作和/或功能分别为了实现点云编码方法中的相应流程,为了简洁,在此不再赘述。It should be understood that the device embodiment and the method embodiment may correspond to each other, and similar descriptions may refer to the method embodiment. To avoid repetition, it will not be repeated here. Specifically, the point cloud coding device 20 shown in Figure 19 may correspond to the corresponding subject in the point cloud coding method of the embodiment of the present application, and the aforementioned and other operations and/or functions of each unit in the point cloud coding device 20 are respectively for implementing the corresponding processes in the point cloud coding method. For the sake of brevity, they will not be repeated here.
上文中结合附图从功能单元的角度描述了本申请实施例的装置和系统。应理解,该功能单元可以通过硬件形式实现,也可以通过软件形式的指令实现,还可以通过硬件和软件单元组合实现。具体地,本申请实施例中的方法实施例的各步骤可以通过处理器中的硬件的集成逻辑电路和/或软件形式的指令完成,结合本申请实施例公开的方法的步骤可以直接体现为硬件译码处理器执行完成,或者用译码处理器中的硬件及软件单元组合执行完成。可选地,软件单元可以位于随机存储器,闪存、只读存储器、可编程只读存储器、电可擦写可编程存储器、寄存器等本领域的成熟的存储介质中。该存储介质位于存储器,处理器读取存储器中的信息,结合其硬件完成上述方法实施例中的步骤。The above describes the device and system of the embodiment of the present application from the perspective of the functional unit in conjunction with the accompanying drawings. It should be understood that the functional unit can be implemented in hardware form, can be implemented by instructions in software form, and can also be implemented by a combination of hardware and software units. Specifically, the steps of the method embodiment in the embodiment of the present application can be completed by the hardware integrated logic circuit and/or software form instructions in the processor, and the steps of the method disclosed in the embodiment of the present application can be directly embodied as a hardware decoding processor to perform, or a combination of hardware and software units in the decoding processor to perform. Optionally, the software unit can be located in a mature storage medium in the field such as a random access memory, a flash memory, a read-only memory, a programmable read-only memory, an electrically erasable programmable memory, a register, etc. The storage medium is located in a memory, and the processor reads the information in the memory, and completes the steps in the above method embodiment in conjunction with its hardware.
图20是本申请实施例提供的电子设备的示意性框图。FIG. 20 is a schematic block diagram of an electronic device provided in an embodiment of the present application.
如图20所示,该电子设备30可以为本申请实施例所述的点云解码设备,或者点云编码设备,该电子设备30可包括:As shown in FIG. 20 , the electronic device 30 may be a point cloud decoding device or a point cloud encoding device as described in the embodiment of the present application, and the electronic device 30 may include:
存储器33和处理器32,该存储器33用于存储计算机程序34,并将该程序代码34传输给该处理器32。换言之,该处理器32可以从存储器33中调用并运行计算机程序34,以实现本申请实施例中的方法。The memory 33 and the processor 32, the memory 33 is used to store the computer program 34 and transmit the program code 34 to the processor 32. In other words, the processor 32 can call and run the computer program 34 from the memory 33 to implement the method in the embodiment of the present application.
例如,该处理器32可用于根据该计算机程序34中的指令执行上述方法200中的步骤。For example, the processor 32 may be configured to execute the steps in the method 200 according to the instructions in the computer program 34 .
在本申请的一些实施例中,该处理器32可以包括但不限于:In some embodiments of the present application, the processor 32 may include but is not limited to:
通用处理器、数字信号处理器(Digital Signal Processor,DSP)、专用集成电路(Application Specific Integrated Circuit,ASIC)、现场可编程门阵列(Field Programmable Gate Array,FPGA)或者其他可编程逻辑器件、分立门或者晶体管逻辑器件、分立硬件组件等等。General-purpose processor, digital signal processor (DSP), application-specific integrated circuit (ASIC), field programmable gate array (FPGA) or other programmable logic devices, discrete gate or transistor logic devices, discrete hardware components, etc.
在本申请的一些实施例中,该存储器33包括但不限于:In some embodiments of the present application, the memory 33 includes but is not limited to:
易失性存储器和/或非易失性存储器。其中,非易失性存储器可以是只读存储器(Read-Only Memory,ROM)、可编程只读存储器(Programmable ROM,PROM)、可擦除可编程只读存储器(Erasable PROM,EPROM)、电可擦除可编程只读存储器(Electrically EPROM,EEPROM)或闪存。易失性存储器可以是随机存取存储器(Random Access Memory,RAM),其用作外部高速缓存。通过示例性但不是限制性说明,许多形式的RAM可用,例如静态随机存取存储器(Static RAM,SRAM)、动态随机存取存储器(Dynamic RAM,DRAM)、同步动态随机存取存储器(Synchronous DRAM,SDRAM)、双倍数据速率同步动态随机存取存储器(Double Data Rate SDRAM,DDR SDRAM)、增强型同步动态随机存取存储器(Enhanced SDRAM,ESDRAM)、同步连接动态随机存取存储器(synch link DRAM,SLDRAM)和直接内存总线随机存取存储器(Direct Rambus RAM,DR RAM)。Volatile memory and/or non-volatile memory. Among them, the non-volatile memory can be read-only memory (ROM), programmable read-only memory (PROM), erasable programmable read-only memory (EPROM), electrically erasable programmable read-only memory (EEPROM) or flash memory. The volatile memory can be random access memory (RAM), which is used as an external cache. By way of example and not limitation, many forms of RAM are available, such as static RAM (SRAM), dynamic RAM (DRAM), synchronous DRAM (SDRAM), double data rate synchronous dynamic random access memory (DDR SDRAM), enhanced synchronous dynamic random access memory (ESDRAM), synchronous link DRAM (SLDRAM) and direct RAM bus random access memory (Direct Rambus RAM, DR RAM).
在本申请的一些实施例中,该计算机程序34可以被分割成一个或多个单元,该一个或者多个单元被存储在该存储器33中,并由该处理器32执行,以完成本申请提供的方法。该一个或多个单元可以是能够完成特定功能的一系列计算机程序指令段,该指令段用于描述该计算机程序34在该电子设备30中的执行过程。In some embodiments of the present application, the computer program 34 may be divided into one or more units, which are stored in the memory 33 and executed by the processor 32 to complete the method provided by the present application. The one or more units may be a series of computer program instruction segments capable of completing specific functions, and the instruction segments are used to describe the execution process of the computer program 34 in the electronic device 30.
如图20所示,该电子设备30还可包括:As shown in FIG. 20 , the electronic device 30 may further include:
收发器33,该收发器33可连接至该处理器32或存储器33。The transceiver 33 may be connected to the processor 32 or the memory 33 .
其中,处理器32可以控制该收发器33与其他设备进行通信,具体地,可以向其他设备发送信息或数据,或接收其他设备发送的信息或数据。收发器33可以包括发射机和接收机。收发器33还可以进一步包括天线,天线的数量可以为一个或多个。The processor 32 may control the transceiver 33 to communicate with other devices, specifically, to send information or data to other devices, or to receive information or data sent by other devices. The transceiver 33 may include a transmitter and a receiver. The transceiver 33 may further include an antenna, and the number of antennas may be one or more.
应当理解,该电子设备30中的各个组件通过总线系统相连,其中,总线系统除包括数据总线之外,还包括电源总 线、控制总线和状态信号总线。It should be understood that the various components in the electronic device 30 are connected via a bus system, wherein the bus system includes not only a data bus but also a power bus, a control bus and a status signal bus.
图21是本申请实施例提供的点云编解码系统的示意性框图。Figure 21 is a schematic block diagram of the point cloud encoding and decoding system provided in an embodiment of the present application.
如图21所示,该点云编解码系统40可包括:点云编码器41和点云解码器42,其中点云编码器41用于执行本申请实施例涉及的点云编码方法,点云解码器42用于执行本申请实施例涉及的点云解码方法。As shown in Figure 21, the point cloud encoding and decoding system 40 may include: a point cloud encoder 41 and a point cloud decoder 42, wherein the point cloud encoder 41 is used to execute the point cloud encoding method involved in the embodiment of the present application, and the point cloud decoder 42 is used to execute the point cloud decoding method involved in the embodiment of the present application.
本申请还提供了一种码流,该码流是根据上述编码方法生成的。The present application also provides a code stream, which is generated according to the above encoding method.
本申请还提供了一种计算机存储介质,其上存储有计算机程序,该计算机程序被计算机执行时使得该计算机能够执行上述方法实施例的方法。或者说,本申请实施例还提供一种包含指令的计算机程序产品,该指令被计算机执行时使得计算机执行上述方法实施例的方法。The present application also provides a computer storage medium on which a computer program is stored, and when the computer program is executed by a computer, the computer can perform the method of the above method embodiment. In other words, the present application embodiment also provides a computer program product containing instructions, and when the instructions are executed by a computer, the computer can perform the method of the above method embodiment.
当使用软件实现时,可以全部或部分地以计算机程序产品的形式实现。该计算机程序产品包括一个或多个计算机指令。在计算机上加载和执行该计算机程序指令时,全部或部分地产生按照本申请实施例该的流程或功能。该计算机可以是通用计算机、专用计算机、计算机网络、或者其他可编程装置。该计算机指令可以存储在计算机可读存储介质中,或者从一个计算机可读存储介质向另一个计算机可读存储介质传输,例如,该计算机指令可以从一个网站站点、计算机、服务器或数据中心通过有线(例如同轴电缆、光纤、数字用户线(digital subscriber line,DSL))或无线(例如红外、无线、微波等)方式向另一个网站站点、计算机、服务器或数据中心进行传输。该计算机可读存储介质可以是计算机能够存取的任何可用介质或者是包含一个或多个可用介质集成的服务器、数据中心等数据存储设备。该可用介质可以是磁性介质(例如,软盘、硬盘、磁带)、光介质(例如数字点云光盘(digital video disc,DVD))、或者半导体介质(例如固态硬盘(solid state disk,SSD))等。When software is used for implementation, it can be implemented in whole or in part in the form of a computer program product. The computer program product includes one or more computer instructions. When the computer program instructions are loaded and executed on a computer, the process or function according to the embodiment of the present application is generated in whole or in part. The computer can be a general-purpose computer, a special-purpose computer, a computer network, or other programmable devices. The computer instructions can be stored in a computer-readable storage medium, or transmitted from one computer-readable storage medium to another computer-readable storage medium. For example, the computer instructions can be transmitted from a website site, computer, server or data center by wired (e.g., coaxial cable, optical fiber, digital subscriber line (digital subscriber line, DSL)) or wireless (e.g., infrared, wireless, microwave, etc.) mode to another website site, computer, server or data center. The computer-readable storage medium can be any available medium that a computer can access or a data storage device such as a server or data center that includes one or more available media integrations. The available medium can be a magnetic medium (e.g., a floppy disk, a hard disk, a magnetic tape), an optical medium (e.g., a digital video disc (DVD)), or a semiconductor medium (e.g., a solid state disk (SSD)), etc.
本领域普通技术人员可以意识到,结合本文中所公开的实施例描述的各示例的单元及算法步骤,能够以电子硬件、或者计算机软件和电子硬件的结合来实现。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束条件。专业技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本申请的范围。Those of ordinary skill in the art will appreciate that the units and algorithm steps of each example described in conjunction with the embodiments disclosed herein can be implemented in electronic hardware, or a combination of computer software and electronic hardware. Whether these functions are performed in hardware or software depends on the specific application and design constraints of the technical solution. Professional and technical personnel can use different methods to implement the described functions for each specific application, but such implementation should not be considered to be beyond the scope of this application.
在本申请所提供的几个实施例中,应该理解到,所揭露的系统、装置和方法,可以通过其它的方式实现。例如,以上所描述的装置实施例仅仅是示意性的,例如,该单元的划分,仅仅为一种逻辑功能划分,实际实现时可以有另外的划分方式,例如多个单元或组件可以结合或者可以集成到另一个系统,或一些特征可以忽略,或不执行。另一点,所显示或讨论的相互之间的耦合或直接耦合或通信连接可以是通过一些接口,装置或单元的间接耦合或通信连接,可以是电性,机械或其它的形式。In the several embodiments provided in the present application, it should be understood that the disclosed systems, devices and methods can be implemented in other ways. For example, the device embodiments described above are only schematic. For example, the division of the unit is only a logical function division. There may be other division methods in actual implementation, such as multiple units or components can be combined or integrated into another system, or some features can be ignored or not executed. Another point is that the mutual coupling or direct coupling or communication connection shown or discussed can be through some interfaces, indirect coupling or communication connection of devices or units, which can be electrical, mechanical or other forms.
作为分离部件说明的单元可以是或者也可以不是物理上分开的,作为单元显示的部件可以是或者也可以不是物理单元,即可以位于一个地方,或者也可以分布到多个网络单元上。可以根据实际的需要选择其中的部分或者全部单元来实现本实施例方案的目的。例如,在本申请各个实施例中的各功能单元可以集成在一个处理单元中,也可以是各个单元单独物理存在,也可以两个或两个以上单元集成在一个单元中。The units described as separate components may or may not be physically separated, and the components displayed as units may or may not be physical units, that is, they may be located in one place, or they may be distributed on multiple network units. Some or all of the units may be selected according to actual needs to achieve the purpose of the scheme of this embodiment. For example, each functional unit in each embodiment of the present application may be integrated into a processing unit, or each unit may exist physically separately, or two or more units may be integrated into one unit.
以上内容,仅为本申请的具体实施方式,但本申请的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本申请揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本申请的保护范围之内。因此,本申请的保护范围应以该权利要求的保护范围为准。The above contents are only specific implementation methods of the present application, but the protection scope of the present application is not limited thereto. Any technician familiar with the technical field can easily think of changes or substitutions within the technical scope disclosed in the present application, which should be included in the protection scope of the present application. Therefore, the protection scope of the present application should be based on the protection scope of the claims.
Claims (56)
- 一种点云解码方法,其特征在于,包括:A point cloud decoding method, characterized by comprising:在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待解码帧中的待解码节点,所述N为正整数;In a prediction reference frame of a current frame to be decoded, determining N prediction nodes of a current node, wherein the current node is a node to be decoded in the current frame to be decoded, and N is a positive integer;基于所述N个预测节点的几何解码信息,对所述当前节点中点的坐标信息进行预测解码。Based on the geometric decoding information of the N predicted nodes, the coordinate information of the midpoint of the current node is predicted and decoded.
- 根据权利要求1所述的方法,其特征在于,所述当前待解码帧包括K个预测参考帧,所述在当前待解码帧的预测参考帧中,确定所述当前节点的N个预测节点,包括:The method according to claim 1, characterized in that the current frame to be decoded includes K prediction reference frames, and determining N prediction nodes of the current node in the prediction reference frame of the current frame to be decoded comprises:针对所述K个预测参考帧中的第k个预测参考帧,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,所述k为小于或等于K的正整数,所述K为正整数;For a k-th prediction reference frame among the K prediction reference frames, determining at least one prediction node of the current node in the k-th prediction reference frame, where k is a positive integer less than or equal to K, and K is a positive integer;基于所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定所述当前节点的N个预测节点。Based on at least one prediction node of the current node in the K prediction reference frames, N prediction nodes of the current node are determined.
- 根据权利要求2所述的方法,其特征在于,所述确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,包括:The method according to claim 2, characterized in that the determining of at least one prediction node of the current node in the k-th prediction reference frame comprises:在所述当前待解码帧中,确定所述当前节点的M个领域节点,所述M个领域节点中包括所述当前节点,所述M为正整数;In the current frame to be decoded, determine M domain nodes of the current node, the M domain nodes include the current node, and M is a positive integer;针对所述M个领域节点中的第i个领域节点,确定所述第i个领域节点在所述第k个预测参考帧中的对应节点,所述i为小于或等于M的正整数;For an i-th domain node among the M domain nodes, determine a corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M;基于所述M个领域节点在所述第k个预测参考帧中的对应节点,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点。Based on the corresponding nodes of the M domain nodes in the k-th prediction reference frame, at least one prediction node of the current node in the k-th prediction reference frame is determined.
- 根据权利要求2所述的方法,其特征在于,所述确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,包括:The method according to claim 2, characterized in that the determining of at least one prediction node of the current node in the k-th prediction reference frame comprises:确定所述当前节点在所述第k个预测参考帧中的对应节点;Determine a corresponding node of the current node in the k-th prediction reference frame;确定所述对应节点的至少一个领域节点;Determining at least one domain node of the corresponding node;将所述至少一个领域节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。The at least one domain node is determined as at least one prediction node of the current node in the k-th prediction reference frame.
- 根据权利要求3或4所述的方法,其特征在于,所述方法还包括:The method according to claim 3 or 4, characterized in that the method further comprises:在所述当前待解码帧中,确定第i个节点的父节点,作为第i个父节点,所述第i个节点为所述第i个领域节点或者为所述当前节点;In the current frame to be decoded, determine the parent node of the ith node as the ith parent node, the ith node being the ith domain node or the current node;确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,作为第i个匹配节点;Determine a matching node of the i-th parent node in the k-th prediction reference frame as the i-th matching node;将所述i个匹配节点的子节点中的一个子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。One of the child nodes of the i matching nodes is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
- 根据权利要求5所述的方法,其特征在于,所述确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,包括:The method according to claim 5, characterized in that the determining the matching node of the i-th parent node in the k-th prediction reference frame comprises:基于所述第i个父节点的占位信息,确定所述第i个父节点在所述第k个预测参考帧中的匹配节点。Based on the placeholder information of the i-th parent node, a matching node of the i-th parent node in the k-th prediction reference frame is determined.
- 根据权利要求6所述的方法,其特征在于,所述基于所述第i个父节点的占位信息,确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,包括:The method according to claim 6, characterized in that the determining, based on the placeholder information of the i-th parent node, a matching node of the i-th parent node in the k-th prediction reference frame comprises:将所述第k个预测参考帧中,占位信息与所述第i个父节点的占位信息之间的差异最小的节点,确定为所述第i个父节点在所述第k个预测参考帧中的匹配节点。A node whose placeholder information in the k-th prediction reference frame has the smallest difference with the placeholder information of the i-th parent node is determined as a matching node of the i-th parent node in the k-th prediction reference frame.
- 根据权利要求5所述的方法,其特征在于,所述将所述i个匹配节点的子节点中的一个子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点,包括:The method according to claim 5, characterized in that the step of determining one of the child nodes of the i matching nodes as the corresponding node of the i-th node in the k-th prediction reference frame comprises:确定所述第i个节点在所述父节点所包括的子节点中的第一序号;Determine the first sequence number of the i-th node among the child nodes included in the parent node;将所述第i个匹配节点的子节点中序号为第一序号的子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。The child node with the first sequence number among the child nodes of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
- 根据权利要求3所述的方法,其特征在于,所述基于所述M个领域节点在所述第k个预测参考帧中的对应节点,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,包括:The method according to claim 3, characterized in that the determining at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame comprises:将所述M个领域节点在所述第k个预测参考帧中的对应节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。The corresponding nodes of the M domain nodes in the k-th prediction reference frame are determined as at least one prediction node of the current node in the k-th prediction reference frame.
- 根据权利要求2所述的方法,其特征在于,所述基于所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定所述当前节点的N个预测节点,包括:The method according to claim 2, characterized in that the determining the N prediction nodes of the current node based on at least one prediction node of the current node in the K prediction reference frames comprises:将所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定为所述当前节点的N个预测节点。At least one prediction node of the current node in the K prediction reference frames is determined as N prediction nodes of the current node.
- 根据权利要求2所述的方法,其特征在于,若所述当前待解码帧为P帧,则所述K个预测参考帧包括所述当前待解码帧的前向帧。The method according to claim 2 is characterized in that if the current frame to be decoded is a P frame, the K prediction reference frames include a forward frame of the current frame to be decoded.
- 根据权利要求2所述的方法,其特征在于,若所述当前待解码帧为B帧,则所述K个预测参考帧包括所述当前待解码帧的前向帧和后向帧。The method according to claim 2 is characterized in that, if the current frame to be decoded is a B frame, the K prediction reference frames include a forward frame and a backward frame of the current frame to be decoded.
- 根据权利要求2-12任一项所述的方法,其特征在于,所述基于所述N个预测节点的几何解码信息,对所述当前节点中点的坐标信息进行预测解码,包括:The method according to any one of claims 2 to 12, characterized in that the predictive decoding of the coordinate information of the midpoint of the current node based on the geometric decoding information of the N predicted nodes comprises:基于所述N个预测节点的几何解码信息,确定上下文模型的索引;Determining an index of a context model based on the geometric decoding information of the N prediction nodes;基于所述上下文模型的索引,确定所述上下文模型;Determining the context model based on the index of the context model;使用所述上下文模型,对所述当前节点中的当前点的坐标信息进行预测解码。Using the context model, the coordinate information of the current point in the current node is predicted and decoded.
- 根据权利要求13所述的方法,其特征在于,所述预测节点的几何解码信息包括所述预测节点的直接解码信息和/或所述预测节点中点的位置信息,所述直接解码信息用于指示所述预测节点是否满足直接解码方式进行解码的条件, 所述基于所述N个预测节点的几何解码信息,确定上下文模型的索引,包括:The method according to claim 13 is characterized in that the geometric decoding information of the prediction node includes direct decoding information of the prediction node and/or position information of a midpoint of the prediction node, and the direct decoding information is used to indicate whether the prediction node satisfies a condition for decoding in a direct decoding manner, and determining the index of the context model based on the geometric decoding information of the N prediction nodes comprises:基于所述N个预测节点的直接解码信息,确定第一上下文索引,和/或基于所述N个预测节点中点的坐标信息,确定第二上下文索引;Determine a first context index based on direct decoding information of the N prediction nodes, and/or determine a second context index based on coordinate information of midpoints of the N prediction nodes;所述基于所述上下文模型的索引,选择所述上下文模型,包括:The selecting the context model based on the index of the context model comprises:基于所述第一上下文索引和/或所述第二上下文索引,从预设的多个上下文模型中,选出所述上下文模型。Based on the first context index and/or the second context index, the context model is selected from a plurality of preset context models.
- 根据权利要求14所述的方法,其特征在于,所述基于所述N个预测节点的直接解码信息,确定第一上下文索引,包括:The method according to claim 14, characterized in that the determining the first context index based on the direct decoding information of the N prediction nodes comprises:针对所述N个预测节点中的任一预测节点,基于所述预测节点的直接解码信息,确定所述预测节点对应的第一数值;For any prediction node among the N prediction nodes, determining a first value corresponding to the prediction node based on direct decoding information of the prediction node;基于所述N个预测节点对应的第一数值,确定所述第一上下文索引。The first context index is determined based on first values corresponding to the N prediction nodes.
- 根据权利要求15所述的方法,其特征在于,所述直接解码信息包括所述预测节点的直接解码模式,所述基于所述预测节点的直接解码信息,确定所述预测节点对应的第一数值,包括:The method according to claim 15, characterized in that the direct decoding information includes a direct decoding mode of the prediction node, and determining the first value corresponding to the prediction node based on the direct decoding information of the prediction node comprises:将所述预测节点的直接解码模式的编号,确定所述预测节点对应的第一数值。The direct decoding mode number of the prediction node is used to determine a first value corresponding to the prediction node.
- 根据权利要求15所述的方法,其特征在于,所述基于所述N个预测节点对应的第一数值,确定所述第一上下文索引,包括:The method according to claim 15, characterized in that the determining the first context index based on the first values corresponding to the N prediction nodes comprises:确定所述预测节点对应的第一权重;Determining a first weight corresponding to the prediction node;基于所述第一权重,对所述N个预测节点对应的第一数值进行加权处理,得到第一加权预测值;Based on the first weight, weighting the first values corresponding to the N prediction nodes to obtain a first weighted prediction value;基于所述第一加权预测值,确定所述第一上下文索引。Based on the first weighted prediction value, the first context index is determined.
- 根据权利要求14所述的方法,其特征在于,若所述K大于1时,则所述基于所述N个预测节点的直接解码信息,确定第一上下文索引,包括:The method according to claim 14, characterized in that, if the K is greater than 1, the determining the first context index based on the direct decoding information of the N prediction nodes comprises:针对所述K个预测参考帧中的第j个预测参考帧,基于所述当前节点在所述第j个预测参考帧中的预测节点的直接解码信息,确定所述第j个预测参考帧中的预测节点对应的第一数值,所述j为小于或等于K的正整数;For a j-th prediction reference frame among the K prediction reference frames, determining a first value corresponding to the prediction node in the j-th prediction reference frame based on direct decoding information of the prediction node of the current node in the j-th prediction reference frame, where j is a positive integer less than or equal to K;确定所述预测节点对应的第一权重,并基于所述第一权重对所述第j个预测参考帧中的预测节点对应的第一数值进行加权处理,得到所述第j个预测参考帧对应的第二加权预测值;Determine a first weight corresponding to the prediction node, and perform weighted processing on a first value corresponding to the prediction node in the j-th prediction reference frame based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame;基于所述K个预测参考帧对应的第二加权预测值,确定所述第一上下文索引。The first context index is determined based on second weighted prediction values corresponding to the K prediction reference frames.
- 根据权利要求18所述的方法,其特征在于,所述基于所述K个预测参考帧对应的第二加权预测值,确定所述第一上下文索引,包括:The method according to claim 18, characterized in that the determining the first context index based on the second weighted prediction values corresponding to the K prediction reference frames comprises:确定所述K个预测参考帧对应的第二权重;Determine second weights corresponding to the K prediction reference frames;基于所述第二权重对所述K个预测参考帧分别对应的第二加权预测值进行加权处理,得到所述第一上下文索引。Based on the second weight, weighted processing is performed on the second weighted prediction values respectively corresponding to the K prediction reference frames to obtain the first context index.
- 根据权利要求14所述的方法,其特征在于,所述基于所述N个预测节点中点的坐标信息,确定第二上下文索引,包括:The method according to claim 14, characterized in that the determining the second context index based on the coordinate information of the midpoints of the N prediction nodes comprises:对于所述N个预测节点中的任一预测节点,从所述预测节点所包括的点中,选出所述当前节点中的当前点对应的第一点;For any prediction node among the N prediction nodes, selecting a first point corresponding to a current point in the current node from the points included in the prediction node;基于所述N个预测节点所包括的第一点的坐标信息,确定所述第二上下文索引。The second context index is determined based on coordinate information of a first point included in the N prediction nodes.
- 根据权利要求20所述的方法,其特征在于,所述基于所述N个预测节点所包括的第一点的坐标信息,确定所述第二上下文索引,包括:The method according to claim 20, characterized in that the determining the second context index based on the coordinate information of the first point included in the N prediction nodes comprises:基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,所述第i个坐标轴为X坐标轴、Y坐标轴或Z坐标轴;Determine, based on coordinate information of a first point included in the N prediction nodes on an i-th coordinate axis, a second context index corresponding to the i-th coordinate axis, where the i-th coordinate axis is an X-coordinate axis, a Y-coordinate axis, or a Z-coordinate axis;所述基于所述第一上下文索引和/或所述第二上下文索引,从预设的多个上下文模型中,选出所述上下文模型,包括:The selecting the context model from a plurality of preset context models based on the first context index and/or the second context index includes:基于所述第一上下文索引和/或所述第i个坐标轴对应的第二上下文索引,从所述多个上下文模型中,选出所述第i个坐标轴对应的上下文模型;Based on the first context index and/or the second context index corresponding to the i-th coordinate axis, selecting a context model corresponding to the i-th coordinate axis from the multiple context models;所述使用所述上下文模型,对所述当前节点中的当前点的坐标信息进行预测解码,包括:The using the context model to predict and decode the coordinate information of the current point in the current node includes:使用所述第i个坐标轴对应的上下文模型,对所述当前点在所述第i个坐标轴上的坐标信息进行预测解码。Use the context model corresponding to the i-th coordinate axis to predict and decode the coordinate information of the current point on the i-th coordinate axis.
- 根据权利要求21所述的方法,其特征在于,所述基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,包括:The method according to claim 21, characterized in that the determining, based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis, the second context index corresponding to the i-th coordinate axis comprises:确定所述预测节点对应的第一权重;Determining a first weight corresponding to the prediction node;基于所述第一权重,对所述N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点;Based on the first weight, weighted processing is performed on the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point;基于所述第一加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。Based on the coordinate information of the first weighted point on the i-th coordinate axis, a second context index corresponding to the i-th coordinate axis is determined.
- 根据权利要求21所述的方法,其特征在于,若所述K大于1时,则所述基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,包括:The method according to claim 21, characterized in that if K is greater than 1, determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis includes:针对所述K个预测参考帧中的第j个预测参考帧,确定所述第j个预测参考帧中预测节点对应的第一权重;For a j-th prediction reference frame among the K prediction reference frames, determining a first weight corresponding to a prediction node in the j-th prediction reference frame;基于所述第一权重,对所述第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到所述第j个预测参考帧对应的第二加权点,所述j为小于或等于K的正整数;Based on the first weight, weighted processing is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K;基于所述K个预测参考帧对应的第二加权点,确定所述第i个坐标轴对应的第二上下文索引。Based on the second weighted points corresponding to the K prediction reference frames, a second context index corresponding to the i-th coordinate axis is determined.
- 根据权利要求23所述的方法,其特征在于,所述基于所述K个预测参考帧对应的第二加权点的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,包括:The method according to claim 23, characterized in that the determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the second weighted points corresponding to the K prediction reference frames comprises:确定所述K个预测参考帧对应的第二权重;Determine second weights corresponding to the K prediction reference frames;基于所述第二权重对所述K个预测参考帧对应的第二加权点的坐标信息进行加权处理,得到第三加权点;performing weighted processing on the coordinate information of the second weighted points corresponding to the K prediction reference frames based on the second weight to obtain a third weighted point;基于所述第三加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。Based on the coordinate information of the third weighted point on the i-th coordinate axis, a second context index corresponding to the i-th coordinate axis is determined.
- 根据权利要求17、18、22或23所述的方法,其特征在于,确定所述预测节点对应的第一权重,包括:The method according to claim 17, 18, 22 or 23, characterized in that determining the first weight corresponding to the prediction node comprises:基于所述预测节点对应的领域节点与所述当前节点之间的距离,确定所述预测节点对应的第一权重。Based on the distance between the domain node corresponding to the prediction node and the current node, a first weight corresponding to the prediction node is determined.
- 根据权利要求19或24所述的方法,其特征在于,所述确定所述K个预测参考帧对应的第二权重,包括:The method according to claim 19 or 24, characterized in that the determining the second weights corresponding to the K prediction reference frames comprises:基于所述预测参考帧与所述当前待解码帧之间的时间差距,确定所述预测参考帧对应的第二权重。Based on the time difference between the predicted reference frame and the current frame to be decoded, a second weight corresponding to the predicted reference frame is determined.
- 一种点云编码方法,其特征在于,包括:A point cloud encoding method, characterized by comprising:在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待编码帧中的待编码节点,所述N为正整数;In a prediction reference frame of a current frame to be encoded, determining N prediction nodes of a current node, wherein the current node is a node to be encoded in the current frame to be encoded, and N is a positive integer;基于所述N个预测节点的几何编码信息,对所述当前节点中点的坐标信息进行预测编码。Based on the geometric coding information of the N predicted nodes, the coordinate information of the midpoint of the current node is predicted and coded.
- 根据权利要求27所述的方法,其特征在于,所述当前待编码帧包括K个预测参考帧,所述在当前待编码帧的预测参考帧中,确定所述当前节点的N个预测节点,包括:The method according to claim 27, characterized in that the current frame to be encoded includes K prediction reference frames, and determining N prediction nodes of the current node in the prediction reference frame of the current frame to be encoded comprises:针对所述K个预测参考帧中的第k个预测参考帧,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,所述k为小于或等于K的正整数,所述K为正整数;For a k-th prediction reference frame among the K prediction reference frames, determining at least one prediction node of the current node in the k-th prediction reference frame, where k is a positive integer less than or equal to K, and K is a positive integer;基于所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定所述当前节点的N个预测节点。Based on at least one prediction node of the current node in the K prediction reference frames, N prediction nodes of the current node are determined.
- 根据权利要求28所述的方法,其特征在于,所述确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,包括:The method according to claim 28, characterized in that the determining of at least one prediction node of the current node in the k-th prediction reference frame comprises:在所述当前待编码帧中,确定所述当前节点的M个领域节点,所述M个领域节点中包括所述当前节点,所述M为正整数;In the current frame to be encoded, determine M domain nodes of the current node, the M domain nodes include the current node, and M is a positive integer;针对所述M个领域节点中的第i个领域节点,确定所述第i个领域节点在所述第k个预测参考帧中的对应节点,所述i为小于或等于M的正整数;For an i-th domain node among the M domain nodes, determine a corresponding node of the i-th domain node in the k-th prediction reference frame, where i is a positive integer less than or equal to M;基于所述M个领域节点在所述第k个预测参考帧中的对应节点,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点。Based on the corresponding nodes of the M domain nodes in the k-th prediction reference frame, at least one prediction node of the current node in the k-th prediction reference frame is determined.
- 根据权利要求28所述的方法,其特征在于,所述确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,包括:The method according to claim 28, characterized in that the determining of at least one prediction node of the current node in the k-th prediction reference frame comprises:确定所述当前节点在所述第k个预测参考帧中的对应节点;Determine a corresponding node of the current node in the k-th prediction reference frame;确定所述对应节点的至少一个领域节点;Determining at least one domain node of the corresponding node;将所述至少一个领域节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。The at least one domain node is determined as at least one prediction node of the current node in the k-th prediction reference frame.
- 根据权利要求29或30所述的方法,其特征在于,所述方法还包括:The method according to claim 29 or 30, characterized in that the method further comprises:在所述当前待编码帧中,确定第i个节点的父节点,作为第i个父节点,所述第i个节点为所述第i个领域节点或者为所述当前节点;In the current frame to be encoded, determine the parent node of the ith node as the ith parent node, the ith node being the ith domain node or the current node;确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,作为第i个匹配节点;Determine a matching node of the i-th parent node in the k-th prediction reference frame as the i-th matching node;将所述i个匹配节点的子节点中的一个子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。One of the child nodes of the i matching nodes is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
- 根据权利要求31所述的方法,其特征在于,所述确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,包括:The method according to claim 31, characterized in that the determining the matching node of the i-th parent node in the k-th prediction reference frame comprises:基于所述第i个父节点的占位信息,确定所述第i个父节点在所述第k个预测参考帧中的匹配节点。Based on the placeholder information of the i-th parent node, a matching node of the i-th parent node in the k-th prediction reference frame is determined.
- 根据权利要求32所述的方法,其特征在于,所述基于所述第i个父节点的占位信息,确定所述第i个父节点在所述第k个预测参考帧中的匹配节点,包括:The method according to claim 32, characterized in that the determining, based on the placeholder information of the i-th parent node, a matching node of the i-th parent node in the k-th prediction reference frame comprises:将所述第k个预测参考帧中,占位信息与所述第i个父节点的占位信息之间的差异最小的节点,确定为所述第i个父节点在所述第k个预测参考帧中的匹配节点。A node whose placeholder information in the k-th prediction reference frame has the smallest difference with the placeholder information of the i-th parent node is determined as a matching node of the i-th parent node in the k-th prediction reference frame.
- 根据权利要求31所述的方法,其特征在于,所述将所述i个匹配节点的子节点中的一个子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点,包括:The method according to claim 31, characterized in that the step of determining one of the child nodes of the i matching nodes as the corresponding node of the i-th node in the k-th prediction reference frame comprises:确定所述第i个节点在所述父节点所包括的子节点中的第一序号;Determine the first sequence number of the i-th node among the child nodes included in the parent node;将所述第i个匹配节点的子节点中序号为第一序号的子节点,确定为所述第i个节点在所述第k个预测参考帧中的对应节点。The child node with the first sequence number among the child nodes of the i-th matching node is determined as the corresponding node of the i-th node in the k-th prediction reference frame.
- 根据权利要求29所述的方法,其特征在于,所述基于所述M个领域节点在所述第k个预测参考帧中的对应节点,确定所述当前节点在所述第k个预测参考帧中的至少一个预测节点,包括:The method according to claim 29, characterized in that the determining at least one prediction node of the current node in the kth prediction reference frame based on the corresponding nodes of the M domain nodes in the kth prediction reference frame comprises:将所述M个领域节点在所述第k个预测参考帧中的对应节点,确定为所述当前节点在所述第k个预测参考帧中的至少一个预测节点。The corresponding nodes of the M domain nodes in the k-th prediction reference frame are determined as at least one prediction node of the current node in the k-th prediction reference frame.
- 根据权利要求28所述的方法,其特征在于,所述基于所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定所述当前节点的N个预测节点,包括:The method according to claim 28, characterized in that the determining the N prediction nodes of the current node based on at least one prediction node of the current node in the K prediction reference frames comprises:将所述当前节点在所述K个预测参考帧中的至少一个预测节点,确定为所述当前节点的N个预测节点。At least one prediction node of the current node in the K prediction reference frames is determined as N prediction nodes of the current node.
- 根据权利要求28所述的方法,其特征在于,若所述当前待编码帧为P帧,则所述K个预测参考帧包括所述当前待编码帧的前向帧。The method according to claim 28 is characterized in that if the current frame to be encoded is a P frame, the K prediction reference frames include a forward frame of the current frame to be encoded.
- 根据权利要求28所述的方法,其特征在于,若所述当前待编码帧为B帧,则所述K个预测参考帧包括所述当前待编码帧的前向帧和后向帧。The method according to claim 28 is characterized in that if the current frame to be encoded is a B frame, the K prediction reference frames include a forward frame and a backward frame of the current frame to be encoded.
- 根据权利要求28-38任一项所述的方法,其特征在于,所述基于所述N个预测节点的几何编码信息,对所述当前节点中点的坐标信息进行预测编码,包括:The method according to any one of claims 28 to 38, characterized in that the predictive coding of the coordinate information of the midpoint of the current node based on the geometric coding information of the N predicted nodes comprises:基于所述N个预测节点的几何编码信息,确定上下文模型的索引;Determining an index of a context model based on the geometric coding information of the N prediction nodes;基于所述上下文模型的索引,确定所述上下文模型;Determining the context model based on the index of the context model;使用所述上下文模型,对所述当前节点中的当前点的坐标信息进行预测编码。Using the context model, the coordinate information of the current point in the current node is predictively encoded.
- 根据权利要求39所述的方法,其特征在于,所述预测节点的几何编码信息包括所述预测节点的直接编码信息和/或所述预测节点中点的位置信息,所述直接编码信息用于指示所述预测节点是否满足直接编码方式进行编码的条件,所述基于所述N个预测节点的几何编码信息,确定上下文模型的索引,包括:The method according to claim 39 is characterized in that the geometric coding information of the prediction node includes direct coding information of the prediction node and/or position information of a midpoint of the prediction node, the direct coding information is used to indicate whether the prediction node satisfies a condition for encoding in a direct coding manner, and the determining the index of the context model based on the geometric coding information of the N prediction nodes comprises:基于所述N个预测节点的直接编码信息,确定第一上下文索引,和/或基于所述N个预测节点中点的坐标信息,确定第二上下文索引;Determine a first context index based on direct encoding information of the N prediction nodes, and/or determine a second context index based on coordinate information of midpoints of the N prediction nodes;所述基于所述上下文模型的索引,选择所述上下文模型,包括:The selecting the context model based on the index of the context model comprises:基于所述第一上下文索引和/或所述第二上下文索引,从预设的多个上下文模型中,选出所述上下文模型。Based on the first context index and/or the second context index, the context model is selected from a plurality of preset context models.
- 根据权利要求40所述的方法,其特征在于,所述基于所述N个预测节点的直接编码信息,确定第一上下文索引,包括:The method according to claim 40, characterized in that the determining the first context index based on the direct encoding information of the N prediction nodes comprises:针对所述N个预测节点中的任一预测节点,基于所述预测节点的直接编码信息,确定所述预测节点对应的第一数值;For any prediction node among the N prediction nodes, determining a first value corresponding to the prediction node based on direct encoding information of the prediction node;基于所述N个预测节点对应的第一数值,确定所述第一上下文索引。The first context index is determined based on first values corresponding to the N prediction nodes.
- 根据权利要求41所述的方法,其特征在于,所述直接编码信息包括所述预测节点的直接编码模式,所述基于所述预测节点的直接编码信息,确定所述预测节点对应的第一数值,包括:The method according to claim 41, characterized in that the direct encoding information includes a direct encoding mode of the prediction node, and determining the first value corresponding to the prediction node based on the direct encoding information of the prediction node comprises:将所述预测节点的直接编码模式的编号,确定所述预测节点对应的第一数值。The direct coding mode number of the prediction node is used to determine a first value corresponding to the prediction node.
- 根据权利要求41所述的方法,其特征在于,所述基于所述N个预测节点对应的第一数值,确定所述第一上下文索引,包括:The method according to claim 41, characterized in that the determining the first context index based on the first values corresponding to the N prediction nodes comprises:确定所述预测节点对应的第一权重;Determining a first weight corresponding to the prediction node;基于所述第一权重,对所述N个预测节点对应的第一数值进行加权处理,得到第一加权预测值;Based on the first weight, weighting the first values corresponding to the N prediction nodes to obtain a first weighted prediction value;基于所述第一加权预测值,确定所述第一上下文索引。Based on the first weighted prediction value, the first context index is determined.
- 根据权利要求40所述的方法,其特征在于,若所述K大于1时,则所述基于所述N个预测节点的直接编码信息,确定第一上下文索引,包括:The method according to claim 40, characterized in that if the K is greater than 1, then the determining the first context index based on the direct encoding information of the N prediction nodes comprises:针对所述K个预测参考帧中的第j个预测参考帧,基于所述当前节点在所述第j个预测参考帧中的预测节点的直接编码信息,确定所述第j个预测参考帧中的预测节点对应的第一数值,所述j为小于或等于K的正整数;For a j-th prediction reference frame among the K prediction reference frames, determining a first value corresponding to the prediction node in the j-th prediction reference frame based on direct encoding information of the prediction node of the current node in the j-th prediction reference frame, where j is a positive integer less than or equal to K;确定所述预测节点对应的第一权重,并基于所述第一权重对所述第j个预测参考帧中的预测节点对应的第一数值进行加权处理,得到所述第j个预测参考帧对应的第二加权预测值;Determine a first weight corresponding to the prediction node, and perform weighted processing on a first value corresponding to the prediction node in the j-th prediction reference frame based on the first weight to obtain a second weighted prediction value corresponding to the j-th prediction reference frame;基于所述K个预测参考帧对应的第二加权预测值,确定所述第一上下文索引。The first context index is determined based on second weighted prediction values corresponding to the K prediction reference frames.
- 根据权利要求44所述的方法,其特征在于,所述基于所述K个预测参考帧对应的第二加权预测值,确定所述第一上下文索引,包括:The method according to claim 44, characterized in that the determining the first context index based on the second weighted prediction values corresponding to the K prediction reference frames comprises:确定所述K个预测参考帧对应的第二权重;Determine second weights corresponding to the K prediction reference frames;基于所述第二权重对所述K个预测参考帧分别对应的第二加权预测值进行加权处理,得到所述第一上下文索引。Based on the second weight, weighted processing is performed on the second weighted prediction values respectively corresponding to the K prediction reference frames to obtain the first context index.
- 根据权利要求40所述的方法,其特征在于,所述基于所述N个预测节点中点的坐标信息,确定第二上下文索引,包括:The method according to claim 40, characterized in that the determining the second context index based on the coordinate information of the midpoints of the N prediction nodes comprises:对于所述N个预测节点中的任一预测节点,从所述预测节点所包括的点中,选出所述当前节点中的当前点对应的第一点;For any prediction node among the N prediction nodes, selecting a first point corresponding to a current point in the current node from the points included in the prediction node;基于所述N个预测节点所包括的第一点的坐标信息,确定所述第二上下文索引。The second context index is determined based on coordinate information of a first point included in the N prediction nodes.
- 根据权利要求46所述的方法,其特征在于,所述基于所述N个预测节点所包括的第一点的坐标信息,确定所述第二上下文索引,包括:The method according to claim 46, characterized in that the determining the second context index based on the coordinate information of the first point included in the N prediction nodes comprises:基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,所述第i个坐标轴为X坐标轴、Y坐标轴或Z坐标轴;Determine, based on coordinate information of a first point included in the N prediction nodes on an i-th coordinate axis, a second context index corresponding to the i-th coordinate axis, where the i-th coordinate axis is an X-coordinate axis, a Y-coordinate axis, or a Z-coordinate axis;所述基于所述第一上下文索引和/或所述第二上下文索引,从预设的多个上下文模型中,选出所述上下文模型,包括:The selecting the context model from a plurality of preset context models based on the first context index and/or the second context index includes:基于所述第一上下文索引和/或所述第i个坐标轴对应的第二上下文索引,从所述多个上下文模型中,选出所述第i个坐标轴对应的上下文模型;Based on the first context index and/or the second context index corresponding to the i-th coordinate axis, selecting a context model corresponding to the i-th coordinate axis from the multiple context models;所述使用所述上下文模型,对所述当前节点中的当前点的坐标信息进行预测编码,包括:The using the context model to predictively encode the coordinate information of the current point in the current node includes:使用所述第i个坐标轴对应的上下文模型,对所述当前点在所述第i个坐标轴上的坐标信息进行预测编码。The context model corresponding to the i-th coordinate axis is used to predictively encode the coordinate information of the current point on the i-th coordinate axis.
- 根据权利要求47所述的方法,其特征在于,所述基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,包括:The method according to claim 47, characterized in that the determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis comprises:确定所述预测节点对应的第一权重;Determining a first weight corresponding to the prediction node;基于所述第一权重,对所述N个预测节点所包括的第一点的坐标信息进行加权处理,得到第一加权点;Based on the first weight, weighted processing is performed on the coordinate information of the first point included in the N prediction nodes to obtain a first weighted point;基于所述第一加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。Based on the coordinate information of the first weighted point on the i-th coordinate axis, a second context index corresponding to the i-th coordinate axis is determined.
- 根据权利要求47所述的方法,其特征在于,若所述K大于1时,则所述基于所述N个预测节点所包括的第一点在第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引,包括:The method according to claim 47, characterized in that if K is greater than 1, determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the first point included in the N prediction nodes on the i-th coordinate axis includes:针对所述K个预测参考帧中的第j个预测参考帧,确定所述第j个预测参考帧中预测节点对应的第一权重;For a j-th prediction reference frame among the K prediction reference frames, determining a first weight corresponding to a prediction node in the j-th prediction reference frame;基于所述第一权重,对所述第j个预测参考帧中的预测节点所包括的第一点的坐标信息进行加权处理,得到所述第j个预测参考帧对应的第二加权点,所述j为小于或等于K的正整数;Based on the first weight, weighted processing is performed on the coordinate information of the first point included in the prediction node in the j-th prediction reference frame to obtain a second weighted point corresponding to the j-th prediction reference frame, where j is a positive integer less than or equal to K;基于所述K个预测参考帧对应的第二加权点,确定所述第i个坐标轴对应的第二上下文索引。Based on the second weighted points corresponding to the K prediction reference frames, a second context index corresponding to the i-th coordinate axis is determined.
- 根据权利要求49所述的方法,其特征在于,所述基于所述K个预测参考帧对应的第二加权点的坐标信息, 确定所述第i个坐标轴对应的第二上下文索引,包括:The method according to claim 49, characterized in that the determining the second context index corresponding to the i-th coordinate axis based on the coordinate information of the second weighted points corresponding to the K prediction reference frames comprises:确定所述K个预测参考帧对应的第二权重;Determine second weights corresponding to the K prediction reference frames;基于所述第二权重对所述K个预测参考帧对应的第二加权点的坐标信息进行加权处理,得到第三加权点;performing weighted processing on the coordinate information of the second weighted points corresponding to the K prediction reference frames based on the second weight to obtain a third weighted point;基于所述第三加权点在所述第i个坐标轴上的坐标信息,确定所述第i个坐标轴对应的第二上下文索引。Based on the coordinate information of the third weighted point on the i-th coordinate axis, a second context index corresponding to the i-th coordinate axis is determined.
- 根据权利要求43、44、48或49所述的方法,其特征在于,确定所述预测节点对应的第一权重,包括:The method according to claim 43, 44, 48 or 49, characterized in that determining the first weight corresponding to the prediction node comprises:基于所述预测节点对应的领域节点与所述当前节点之间的距离,确定所述预测节点对应的第一权重。Based on the distance between the domain node corresponding to the prediction node and the current node, a first weight corresponding to the prediction node is determined.
- 根据权利要求45或50所述的方法,其特征在于,所述确定所述K个预测参考帧对应的第二权重,包括:The method according to claim 45 or 50, characterized in that the determining the second weights corresponding to the K prediction reference frames comprises:基于所述预测参考帧与所述当前待编码帧之间的时间差距,确定所述预测参考帧对应的第二权重。Based on the time difference between the predicted reference frame and the current frame to be encoded, a second weight corresponding to the predicted reference frame is determined.
- 一种点云解码装置,其特征在于,包括:A point cloud decoding device, characterized by comprising:确定单元,用于在当前待解码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待解码帧中的待解码节点,所述N为正整数;A determination unit, configured to determine N prediction nodes of a current node in a prediction reference frame of a current frame to be decoded, wherein the current node is a node to be decoded in the current frame to be decoded, and N is a positive integer;解码单元,用于基于所述N个预测节点的几何解码信息,对所述当前节点中点的坐标信息进行预测解码。A decoding unit is used to predict and decode the coordinate information of the midpoint of the current node based on the geometric decoding information of the N predicted nodes.
- 一种点云编码装置,其特征在于,包括:A point cloud encoding device, characterized by comprising:确定单元,具体用于在当前待编码帧的预测参考帧中,确定当前节点的N个预测节点,所述当前节点为所述当前待编码帧中的待编码节点,所述N为正整数;A determination unit, specifically configured to determine N prediction nodes of a current node in a prediction reference frame of a current frame to be encoded, wherein the current node is a node to be encoded in the current frame to be encoded, and N is a positive integer;编码单元,用于基于所述N个预测节点的几何编码信息,对所述当前节点中点的坐标信息进行预测编码。The encoding unit is used to predict the coordinate information of the midpoint of the current node based on the geometric encoding information of the N prediction nodes.
- 一种电子设备,其特征在于,包括:处理器和存储器;An electronic device, characterized in that it comprises: a processor and a memory;所述存储器用于存储计算机程序;The memory is used to store computer programs;所述处理器用于调用并运行所述存储器中存储的计算机程序,以执行如权利要求1至26或27至52任一项所述的方法。The processor is used to call and run the computer program stored in the memory to perform the method according to any one of claims 1 to 26 or 27 to 52.
- 一种计算机可读存储介质,其特征在于,用于存储计算机程序,所述计算机程序使得计算机执行如权利要求1至26或27至52任一项所述的方法。A computer-readable storage medium, characterized in that it is used to store a computer program, wherein the computer program enables a computer to execute the method according to any one of claims 1 to 26 or 27 to 52.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2023/071072 WO2024145935A1 (en) | 2023-01-06 | 2023-01-06 | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/CN2023/071072 WO2024145935A1 (en) | 2023-01-06 | 2023-01-06 | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| WO2024145935A1 true WO2024145935A1 (en) | 2024-07-11 |
Family
ID=91803377
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/CN2023/071072 WO2024145935A1 (en) | 2023-01-06 | 2023-01-06 | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2024145935A1 (en) |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN112565764A (en) * | 2020-12-03 | 2021-03-26 | 西安电子科技大学 | Point cloud geometric information interframe coding and decoding method |
| CN114095735A (en) * | 2020-08-24 | 2022-02-25 | 北京大学深圳研究生院 | Point cloud geometric inter-frame prediction method based on block motion estimation and motion compensation |
| CN114143556A (en) * | 2021-12-28 | 2022-03-04 | 苏州联视泰电子信息技术有限公司 | Interframe coding and decoding method for compressing three-dimensional sonar point cloud data |
| CN115471627A (en) * | 2021-06-11 | 2022-12-13 | 维沃移动通信有限公司 | Point cloud geometric information encoding processing method, point cloud geometric information decoding processing method and related equipment |
| WO2022257145A1 (en) * | 2021-06-11 | 2022-12-15 | Oppo广东移动通信有限公司 | Point cloud attribute prediction method and apparatus, and codec |
-
2023
- 2023-01-06 WO PCT/CN2023/071072 patent/WO2024145935A1/en unknown
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN114095735A (en) * | 2020-08-24 | 2022-02-25 | 北京大学深圳研究生院 | Point cloud geometric inter-frame prediction method based on block motion estimation and motion compensation |
| CN112565764A (en) * | 2020-12-03 | 2021-03-26 | 西安电子科技大学 | Point cloud geometric information interframe coding and decoding method |
| CN115471627A (en) * | 2021-06-11 | 2022-12-13 | 维沃移动通信有限公司 | Point cloud geometric information encoding processing method, point cloud geometric information decoding processing method and related equipment |
| WO2022257145A1 (en) * | 2021-06-11 | 2022-12-15 | Oppo广东移动通信有限公司 | Point cloud attribute prediction method and apparatus, and codec |
| CN114143556A (en) * | 2021-12-28 | 2022-03-04 | 苏州联视泰电子信息技术有限公司 | Interframe coding and decoding method for compressing three-dimensional sonar point cloud data |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| WO2023024840A1 (en) | Point cloud encoding and decoding methods, encoder, decoder and storage medium | |
| US11910017B2 (en) | Method for predicting point cloud attribute, encoder, decoder, and storage medium | |
| TW202249488A (en) | Point cloud attribute prediction method and apparatus, and codec | |
| WO2024065269A1 (en) | Point cloud encoding and decoding method and apparatus, device, and storage medium | |
| US12113963B2 (en) | Method and apparatus for selecting neighbor point in point cloud, encoder, and decoder | |
| WO2024145935A1 (en) | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium | |
| WO2024145913A1 (en) | Point cloud encoding and decoding method and apparatus, device, and storage medium | |
| WO2024145912A1 (en) | Point cloud coding method and apparatus, point cloud decoding method and apparatus, device, and storage medium | |
| WO2024145934A1 (en) | Point cloud coding/decoding method and apparatus, and device and storage medium | |
| WO2024145933A1 (en) | Point cloud coding method and apparatus, point cloud decoding method and apparatus, and devices and storage medium | |
| WO2024178632A9 (en) | Point cloud coding method and apparatus, point cloud decoding method and apparatus, and device and storage medium | |
| WO2024207463A1 (en) | Point cloud encoding/decoding method and apparatus, and device and storage medium | |
| WO2024145911A1 (en) | Point cloud encoding/decoding method and apparatus, device and storage medium | |
| WO2024212114A1 (en) | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device, and storage medium | |
| WO2024212113A1 (en) | Point cloud encoding and decoding method and apparatus, device and storage medium | |
| WO2024197680A1 (en) | Point cloud coding method and apparatus, point cloud decoding method and apparatus, device, and storage medium | |
| WO2024065270A1 (en) | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, devices, and storage medium | |
| WO2024065271A1 (en) | Point cloud encoding/decoding method and apparatus, and device and storage medium | |
| WO2024065272A1 (en) | Point cloud coding method and apparatus, point cloud decoding method and apparatus, and device and storage medium | |
| WO2024026712A1 (en) | Point cloud coding method and apparatus, point cloud decoding method and apparatus, and device and storage medium | |
| WO2024221458A1 (en) | Point cloud encoding/decoding method and apparatus, device, and storage medium | |
| WO2023024842A1 (en) | Point cloud encoding/decoding method, apparatus and device, and storage medium | |
| WO2024011381A1 (en) | Point cloud encoding method and apparatus, point cloud decoding method and apparatus, device and storage medium | |
| WO2022257150A1 (en) | Point cloud encoding and decoding methods and apparatus, point cloud codec, and storage medium | |
| WO2024216476A1 (en) | Encoding/decoding method, encoder, decoder, code stream, and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 23914092 Country of ref document: EP Kind code of ref document: A1 |