WO2017137457A1 - Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates - Google Patents
Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates Download PDFInfo
- Publication number
- WO2017137457A1 WO2017137457A1 PCT/EP2017/052790 EP2017052790W WO2017137457A1 WO 2017137457 A1 WO2017137457 A1 WO 2017137457A1 EP 2017052790 W EP2017052790 W EP 2017052790W WO 2017137457 A1 WO2017137457 A1 WO 2017137457A1
- Authority
- WO
- WIPO (PCT)
- Prior art keywords
- group
- groups
- formula
- antibody
- linker
- Prior art date
Links
- 238000000034 method Methods 0.000 title claims abstract description 112
- 229940127121 immunoconjugate Drugs 0.000 title claims abstract description 97
- 231100001274 therapeutic index Toxicity 0.000 title claims abstract description 49
- 230000008685 targeting Effects 0.000 title claims abstract description 29
- 206010028980 Neoplasm Diseases 0.000 title claims description 66
- 230000021615 conjugation Effects 0.000 claims abstract description 214
- 125000000524 functional group Chemical group 0.000 claims abstract description 136
- 150000001875 compounds Chemical class 0.000 claims abstract description 96
- -1 nucleoside mono- Chemical class 0.000 claims abstract description 96
- 238000006243 chemical reaction Methods 0.000 claims abstract description 95
- 235000000346 sugar Nutrition 0.000 claims abstract description 73
- 101001012157 Homo sapiens Receptor tyrosine-protein kinase erbB-2 Proteins 0.000 claims abstract description 41
- 102100030086 Receptor tyrosine-protein kinase erbB-2 Human genes 0.000 claims abstract description 41
- 102000003886 Glycoproteins Human genes 0.000 claims abstract description 37
- 108090000288 Glycoproteins Proteins 0.000 claims abstract description 37
- 239000003054 catalyst Substances 0.000 claims abstract description 32
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical group CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 claims abstract description 27
- 239000002777 nucleoside Substances 0.000 claims abstract description 17
- 239000001177 diphosphate Substances 0.000 claims abstract description 13
- 235000011180 diphosphates Nutrition 0.000 claims abstract description 13
- XPPKVPWEQAFLFU-UHFFFAOYSA-J diphosphate(4-) Chemical compound [O-]P([O-])(=O)OP([O-])([O-])=O XPPKVPWEQAFLFU-UHFFFAOYSA-J 0.000 claims abstract description 10
- 125000005842 heteroatom Chemical group 0.000 claims description 230
- 125000005647 linker group Chemical group 0.000 claims description 165
- 125000003118 aryl group Chemical group 0.000 claims description 128
- 229910052739 hydrogen Inorganic materials 0.000 claims description 117
- 239000001257 hydrogen Substances 0.000 claims description 116
- 125000006850 spacer group Chemical group 0.000 claims description 100
- 229960000575 trastuzumab Drugs 0.000 claims description 95
- 125000000217 alkyl group Chemical group 0.000 claims description 82
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 claims description 65
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 claims description 65
- 150000001413 amino acids Chemical class 0.000 claims description 65
- 150000003839 salts Chemical class 0.000 claims description 65
- 239000012634 fragment Substances 0.000 claims description 60
- 229910052760 oxygen Inorganic materials 0.000 claims description 59
- 125000003710 aryl alkyl group Chemical group 0.000 claims description 58
- 229910052717 sulfur Inorganic materials 0.000 claims description 56
- 102000004169 proteins and genes Human genes 0.000 claims description 53
- 108090000623 proteins and genes Proteins 0.000 claims description 53
- SHZGCJCMOBCMKK-UHFFFAOYSA-N D-mannomethylose Natural products CC1OC(O)C(O)C(O)C1O SHZGCJCMOBCMKK-UHFFFAOYSA-N 0.000 claims description 52
- SHZGCJCMOBCMKK-DHVFOXMCSA-N L-fucopyranose Chemical compound C[C@@H]1OC(O)[C@@H](O)[C@H](O)[C@@H]1O SHZGCJCMOBCMKK-DHVFOXMCSA-N 0.000 claims description 50
- OVRNDRQMDRJTHS-RTRLPJTCSA-N N-acetyl-D-glucosamine Chemical compound CC(=O)N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-RTRLPJTCSA-N 0.000 claims description 36
- 125000001424 substituent group Chemical group 0.000 claims description 34
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 33
- 230000001225 therapeutic effect Effects 0.000 claims description 32
- 125000000753 cycloalkyl group Chemical group 0.000 claims description 25
- 229950006780 n-acetylglucosamine Drugs 0.000 claims description 24
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 21
- IEDXPSOJFSVCKU-HOKPPMCLSA-N [4-[[(2S)-5-(carbamoylamino)-2-[[(2S)-2-[6-(2,5-dioxopyrrolidin-1-yl)hexanoylamino]-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl N-[(2S)-1-[[(2S)-1-[[(3R,4S,5S)-1-[(2S)-2-[(1R,2R)-3-[[(1S,2R)-1-hydroxy-1-phenylpropan-2-yl]amino]-1-methoxy-2-methyl-3-oxopropyl]pyrrolidin-1-yl]-3-methoxy-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]-N-methylcarbamate Chemical compound CC[C@H](C)[C@@H]([C@@H](CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C)[C@@H](O)c1ccccc1)OC)N(C)C(=O)[C@@H](NC(=O)[C@H](C(C)C)N(C)C(=O)OCc1ccc(NC(=O)[C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)CCCCCN2C(=O)CCC2=O)C(C)C)cc1)C(C)C IEDXPSOJFSVCKU-HOKPPMCLSA-N 0.000 claims description 20
- 239000013543 active substance Substances 0.000 claims description 20
- PNNNRSAQSRJVSB-SLPGGIOYSA-N Fucose Natural products C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C=O PNNNRSAQSRJVSB-SLPGGIOYSA-N 0.000 claims description 19
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 claims description 18
- 229910052736 halogen Inorganic materials 0.000 claims description 16
- 150000002367 halogens Chemical group 0.000 claims description 15
- YUOCYTRGANSSRY-UHFFFAOYSA-N pyrrolo[2,3-i][1,2]benzodiazepine Chemical class C1=CN=NC2=C3C=CN=C3C=CC2=C1 YUOCYTRGANSSRY-UHFFFAOYSA-N 0.000 claims description 13
- 125000002355 alkine group Chemical group 0.000 claims description 11
- 231100000599 cytotoxic agent Toxicity 0.000 claims description 11
- 239000002619 cytotoxin Substances 0.000 claims description 11
- MFRNYXJJRJQHNW-DEMKXPNLSA-N (2s)-2-[[(2r,3r)-3-methoxy-3-[(2s)-1-[(3r,4s,5s)-3-methoxy-5-methyl-4-[methyl-[(2s)-3-methyl-2-[[(2s)-3-methyl-2-(methylamino)butanoyl]amino]butanoyl]amino]heptanoyl]pyrrolidin-2-yl]-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 MFRNYXJJRJQHNW-DEMKXPNLSA-N 0.000 claims description 9
- 229940045799 anthracyclines and related substance Drugs 0.000 claims description 9
- 239000000427 antigen Substances 0.000 claims description 8
- 108091007433 antigens Proteins 0.000 claims description 8
- 102000036639 antigens Human genes 0.000 claims description 8
- 125000001153 fluoro group Chemical group F* 0.000 claims description 8
- 229940123237 Taxane Drugs 0.000 claims description 7
- 229960005501 duocarmycin Drugs 0.000 claims description 7
- 229930184221 duocarmycin Natural products 0.000 claims description 7
- 229930184737 tubulysin Natural products 0.000 claims description 7
- OFXYRBJPCXTHMK-SQOUGZDYSA-N (2R,3R,4R,5R)-2-azido-N-(2,2-difluoroacetyl)-3,4,5,6-tetrahydroxyhexanamide Chemical group N(=[N+]=[N-])[C@@H](C(=O)NC(C(F)F)=O)[C@@H](O)[C@@H](O)[C@H](O)CO OFXYRBJPCXTHMK-SQOUGZDYSA-N 0.000 claims description 6
- MDAGZUURIZAVTG-OKMMGKLZSA-N (3R,4R,5R)-N-(2-azidoacetyl)-3,4,5,6-tetrahydroxyhexanamide Chemical group N(=[N+]=[N-])CC(=O)NC(=O)C[C@@H](O)[C@@H](O)[C@H](O)CO MDAGZUURIZAVTG-OKMMGKLZSA-N 0.000 claims description 6
- 102100041003 Glutamate carboxypeptidase 2 Human genes 0.000 claims description 6
- 229940122803 Vinca alkaloid Drugs 0.000 claims description 6
- 102100023144 Zinc transporter ZIP6 Human genes 0.000 claims description 6
- 239000002246 antineoplastic agent Substances 0.000 claims description 6
- 150000004945 aromatic hydrocarbons Chemical group 0.000 claims description 6
- 229940002612 prodrug Drugs 0.000 claims description 6
- 239000000651 prodrug Substances 0.000 claims description 6
- IVRMZWNICZWHMI-UHFFFAOYSA-N azide group Chemical group [N-]=[N+]=[N-] IVRMZWNICZWHMI-UHFFFAOYSA-N 0.000 claims description 5
- 101710112752 Cytotoxin Proteins 0.000 claims description 4
- 102000013128 Endothelin B Receptor Human genes 0.000 claims description 4
- 108010090557 Endothelin B Receptor Proteins 0.000 claims description 4
- 101000892862 Homo sapiens Glutamate carboxypeptidase 2 Proteins 0.000 claims description 4
- 101000874179 Homo sapiens Syndecan-1 Proteins 0.000 claims description 4
- 101000801433 Homo sapiens Trophoblast glycoprotein Proteins 0.000 claims description 4
- 102000003735 Mesothelin Human genes 0.000 claims description 4
- 108090000015 Mesothelin Proteins 0.000 claims description 4
- 102100035721 Syndecan-1 Human genes 0.000 claims description 4
- 102100033579 Trophoblast glycoprotein Human genes 0.000 claims description 4
- 125000004122 cyclic group Chemical group 0.000 claims description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 4
- BLUGYPPOFIHFJS-UUFHNPECSA-N (2s)-n-[(2s)-1-[[(3r,4s,5s)-3-methoxy-1-[(2s)-2-[(1r,2r)-1-methoxy-2-methyl-3-oxo-3-[[(1s)-2-phenyl-1-(1,3-thiazol-2-yl)ethyl]amino]propyl]pyrrolidin-1-yl]-5-methyl-1-oxoheptan-4-yl]-methylamino]-3-methyl-1-oxobutan-2-yl]-3-methyl-2-(methylamino)butanamid Chemical compound CN[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C=1SC=CN=1)CC1=CC=CC=C1 BLUGYPPOFIHFJS-UUFHNPECSA-N 0.000 claims description 3
- 125000001140 1,4-phenylene group Chemical group [H]C1=C([H])C([*:2])=C([H])C([H])=C1[*:1] 0.000 claims description 3
- 208000007934 ACTH-independent macronodular adrenal hyperplasia Diseases 0.000 claims description 3
- 206010005003 Bladder cancer Diseases 0.000 claims description 3
- 206010006187 Breast cancer Diseases 0.000 claims description 3
- 208000026310 Breast neoplasm Diseases 0.000 claims description 3
- 101000851376 Homo sapiens Tumor necrosis factor receptor superfamily member 8 Proteins 0.000 claims description 3
- 206010061902 Pancreatic neoplasm Diseases 0.000 claims description 3
- 208000005718 Stomach Neoplasms Diseases 0.000 claims description 3
- 102100036857 Tumor necrosis factor receptor superfamily member 8 Human genes 0.000 claims description 3
- 208000007097 Urinary Bladder Neoplasms Diseases 0.000 claims description 3
- 229950008579 ertumaxomab Drugs 0.000 claims description 3
- 206010017758 gastric cancer Diseases 0.000 claims description 3
- 208000015486 malignant pancreatic neoplasm Diseases 0.000 claims description 3
- 229950003135 margetuximab Drugs 0.000 claims description 3
- 201000002528 pancreatic cancer Diseases 0.000 claims description 3
- 208000008443 pancreatic carcinoma Diseases 0.000 claims description 3
- 229960002087 pertuzumab Drugs 0.000 claims description 3
- 125000000843 phenylene group Chemical group C1(=C(C=CC=C1)*)* 0.000 claims description 3
- 201000011549 stomach cancer Diseases 0.000 claims description 3
- 201000005112 urinary bladder cancer Diseases 0.000 claims description 3
- BGFTWECWAICPDG-UHFFFAOYSA-N 2-[bis(4-chlorophenyl)methyl]-4-n-[3-[bis(4-chlorophenyl)methyl]-4-(dimethylamino)phenyl]-1-n,1-n-dimethylbenzene-1,4-diamine Chemical compound C1=C(C(C=2C=CC(Cl)=CC=2)C=2C=CC(Cl)=CC=2)C(N(C)C)=CC=C1NC(C=1)=CC=C(N(C)C)C=1C(C=1C=CC(Cl)=CC=1)C1=CC=C(Cl)C=C1 BGFTWECWAICPDG-UHFFFAOYSA-N 0.000 claims description 2
- 231100000729 Amatoxin Toxicity 0.000 claims description 2
- 101001005269 Arabidopsis thaliana Ceramide synthase 1 LOH3 Proteins 0.000 claims description 2
- 101001005312 Arabidopsis thaliana Ceramide synthase LOH1 Proteins 0.000 claims description 2
- 108010008014 B-Cell Maturation Antigen Proteins 0.000 claims description 2
- 102000006942 B-Cell Maturation Antigen Human genes 0.000 claims description 2
- 102100038080 B-cell receptor CD22 Human genes 0.000 claims description 2
- 102100024222 B-lymphocyte antigen CD19 Human genes 0.000 claims description 2
- 108700012439 CA9 Proteins 0.000 claims description 2
- 101150013553 CD40 gene Proteins 0.000 claims description 2
- 102100025221 CD70 antigen Human genes 0.000 claims description 2
- 108050007957 Cadherin Proteins 0.000 claims description 2
- 102000000905 Cadherin Human genes 0.000 claims description 2
- 102100028801 Calsyntenin-1 Human genes 0.000 claims description 2
- 102100024423 Carbonic anhydrase 9 Human genes 0.000 claims description 2
- 102100025475 Carcinoembryonic antigen-related cell adhesion molecule 5 Human genes 0.000 claims description 2
- 102100039496 Choline transporter-like protein 4 Human genes 0.000 claims description 2
- 102100036466 Delta-like protein 3 Human genes 0.000 claims description 2
- 108010055196 EphA2 Receptor Proteins 0.000 claims description 2
- 102100030340 Ephrin type-A receptor 2 Human genes 0.000 claims description 2
- 102100033942 Ephrin-A4 Human genes 0.000 claims description 2
- 108010066687 Epithelial Cell Adhesion Molecule Proteins 0.000 claims description 2
- 102000018651 Epithelial Cell Adhesion Molecule Human genes 0.000 claims description 2
- 102100023600 Fibroblast growth factor receptor 2 Human genes 0.000 claims description 2
- 101710182389 Fibroblast growth factor receptor 2 Proteins 0.000 claims description 2
- 102100027842 Fibroblast growth factor receptor 3 Human genes 0.000 claims description 2
- 101710182396 Fibroblast growth factor receptor 3 Proteins 0.000 claims description 2
- 102100035139 Folate receptor alpha Human genes 0.000 claims description 2
- 108090000369 Glutamate Carboxypeptidase II Proteins 0.000 claims description 2
- 101150112082 Gpnmb gene Proteins 0.000 claims description 2
- 108010078321 Guanylate Cyclase Proteins 0.000 claims description 2
- 102000014469 Guanylate cyclase Human genes 0.000 claims description 2
- 102100030595 HLA class II histocompatibility antigen gamma chain Human genes 0.000 claims description 2
- 101000884305 Homo sapiens B-cell receptor CD22 Proteins 0.000 claims description 2
- 101000980825 Homo sapiens B-lymphocyte antigen CD19 Proteins 0.000 claims description 2
- 101000934356 Homo sapiens CD70 antigen Proteins 0.000 claims description 2
- 101000914324 Homo sapiens Carcinoembryonic antigen-related cell adhesion molecule 5 Proteins 0.000 claims description 2
- 101000928513 Homo sapiens Delta-like protein 3 Proteins 0.000 claims description 2
- 101000925259 Homo sapiens Ephrin-A4 Proteins 0.000 claims description 2
- 101001023230 Homo sapiens Folate receptor alpha Proteins 0.000 claims description 2
- 101001082627 Homo sapiens HLA class II histocompatibility antigen gamma chain Proteins 0.000 claims description 2
- 101000606465 Homo sapiens Inactive tyrosine-protein kinase 7 Proteins 0.000 claims description 2
- 101001046677 Homo sapiens Integrin alpha-V Proteins 0.000 claims description 2
- 101001057504 Homo sapiens Interferon-stimulated gene 20 kDa protein Proteins 0.000 claims description 2
- 101001055144 Homo sapiens Interleukin-2 receptor subunit alpha Proteins 0.000 claims description 2
- 101000777628 Homo sapiens Leukocyte antigen CD37 Proteins 0.000 claims description 2
- 101000628547 Homo sapiens Metalloreductase STEAP1 Proteins 0.000 claims description 2
- 101001133056 Homo sapiens Mucin-1 Proteins 0.000 claims description 2
- 101000623901 Homo sapiens Mucin-16 Proteins 0.000 claims description 2
- 101000934338 Homo sapiens Myeloid cell surface antigen CD33 Proteins 0.000 claims description 2
- 101000581981 Homo sapiens Neural cell adhesion molecule 1 Proteins 0.000 claims description 2
- 101000897042 Homo sapiens Nucleotide pyrophosphatase Proteins 0.000 claims description 2
- 101000633784 Homo sapiens SLAM family member 7 Proteins 0.000 claims description 2
- 101000835984 Homo sapiens SLIT and NTRK-like protein 6 Proteins 0.000 claims description 2
- 101000685848 Homo sapiens Zinc transporter ZIP6 Proteins 0.000 claims description 2
- 102100039813 Inactive tyrosine-protein kinase 7 Human genes 0.000 claims description 2
- 102100022337 Integrin alpha-V Human genes 0.000 claims description 2
- 102100026878 Interleukin-2 receptor subunit alpha Human genes 0.000 claims description 2
- 101150086425 LYPD3 gene Proteins 0.000 claims description 2
- 101150048357 Lamp1 gene Proteins 0.000 claims description 2
- 102100031586 Leukocyte antigen CD37 Human genes 0.000 claims description 2
- 102100026712 Metalloreductase STEAP1 Human genes 0.000 claims description 2
- 102100034256 Mucin-1 Human genes 0.000 claims description 2
- 102100023123 Mucin-16 Human genes 0.000 claims description 2
- 101100369076 Mus musculus Tdgf1 gene Proteins 0.000 claims description 2
- 102100025243 Myeloid cell surface antigen CD33 Human genes 0.000 claims description 2
- 102100035486 Nectin-4 Human genes 0.000 claims description 2
- 101710043865 Nectin-4 Proteins 0.000 claims description 2
- 102100027347 Neural cell adhesion molecule 1 Human genes 0.000 claims description 2
- 102100021969 Nucleotide pyrophosphatase Human genes 0.000 claims description 2
- 108091006938 SLC39A6 Proteins 0.000 claims description 2
- 108091007561 SLC44A4 Proteins 0.000 claims description 2
- 102100025504 SLIT and NTRK-like protein 6 Human genes 0.000 claims description 2
- 101150031731 Slc39a6 gene Proteins 0.000 claims description 2
- 101000668858 Spinacia oleracea 30S ribosomal protein S1, chloroplastic Proteins 0.000 claims description 2
- 101000898746 Streptomyces clavuligerus Clavaminate synthase 1 Proteins 0.000 claims description 2
- 102100040245 Tumor necrosis factor receptor superfamily member 5 Human genes 0.000 claims description 2
- 102100027212 Tumor-associated calcium signal transducer 2 Human genes 0.000 claims description 2
- 101150035873 ZIP6 gene Proteins 0.000 claims description 2
- MXKCYTKUIDTFLY-ZNNSSXPHSA-N alpha-L-Fucp-(1->2)-beta-D-Galp-(1->4)-[alpha-L-Fucp-(1->3)]-beta-D-GlcpNAc-(1->3)-D-Galp Chemical compound O[C@H]1[C@H](O)[C@H](O)[C@H](C)O[C@H]1O[C@H]1[C@H](O[C@H]2[C@@H]([C@@H](NC(C)=O)[C@H](O[C@H]3[C@H]([C@@H](CO)OC(O)[C@@H]3O)O)O[C@@H]2CO)O[C@H]2[C@H]([C@H](O)[C@H](O)[C@H](C)O2)O)O[C@H](CO)[C@H](O)[C@@H]1O MXKCYTKUIDTFLY-ZNNSSXPHSA-N 0.000 claims description 2
- 150000004814 combretastatins Chemical class 0.000 claims description 2
- 229940127276 delta-like ligand 3 Drugs 0.000 claims description 2
- 229930188854 dolastatin Natural products 0.000 claims description 2
- 102000052116 epidermal growth factor receptor activity proteins Human genes 0.000 claims description 2
- 108700015053 epidermal growth factor receptor activity proteins Proteins 0.000 claims description 2
- 229930013356 epothilone Natural products 0.000 claims description 2
- HESCAJZNRMSMJG-KKQRBIROSA-N epothilone A Chemical class C/C([C@@H]1C[C@@H]2O[C@@H]2CCC[C@@H]([C@@H]([C@@H](C)C(=O)C(C)(C)[C@@H](O)CC(=O)O1)O)C)=C\C1=CSC(C)=N1 HESCAJZNRMSMJG-KKQRBIROSA-N 0.000 claims description 2
- 108020005243 folate receptor Proteins 0.000 claims description 2
- 102000006815 folate receptor Human genes 0.000 claims description 2
- 238000003384 imaging method Methods 0.000 claims description 2
- 239000003112 inhibitor Substances 0.000 claims description 2
- 229940043355 kinase inhibitor Drugs 0.000 claims description 2
- 239000002829 mitogen activated protein kinase inhibitor Substances 0.000 claims description 2
- YOHYSYJDKVYCJI-UHFFFAOYSA-N n-[3-[[6-[3-(trifluoromethyl)anilino]pyrimidin-4-yl]amino]phenyl]cyclopropanecarboxamide Chemical compound FC(F)(F)C1=CC=CC(NC=2N=CN=C(NC=3C=C(NC(=O)C4CC4)C=CC=3)C=2)=C1 YOHYSYJDKVYCJI-UHFFFAOYSA-N 0.000 claims description 2
- 239000003757 phosphotransferase inhibitor Substances 0.000 claims description 2
- 230000035755 proliferation Effects 0.000 claims description 2
- 125000001425 triazolyl group Chemical group 0.000 claims description 2
- 150000002431 hydrogen Chemical group 0.000 claims 3
- 102000001760 Notch3 Receptor Human genes 0.000 claims 1
- 108010029756 Notch3 Receptor Proteins 0.000 claims 1
- 229920001481 poly(stearyl methacrylate) Polymers 0.000 claims 1
- 239000000562 conjugate Substances 0.000 description 244
- YMWUJEATGCHHMB-UHFFFAOYSA-N Dichloromethane Chemical compound ClCCl YMWUJEATGCHHMB-UHFFFAOYSA-N 0.000 description 149
- 239000000243 solution Substances 0.000 description 141
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 123
- 125000004435 hydrogen atom Chemical group [H]* 0.000 description 97
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 87
- 239000000047 product Substances 0.000 description 84
- 125000000304 alkynyl group Chemical group 0.000 description 65
- 239000000203 mixture Substances 0.000 description 65
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 64
- 238000002360 preparation method Methods 0.000 description 53
- LOKCTEFSRHRXRJ-UHFFFAOYSA-I dipotassium trisodium dihydrogen phosphate hydrogen phosphate dichloride Chemical compound P(=O)(O)(O)[O-].[K+].P(=O)(O)([O-])[O-].[Na+].[Na+].[Cl-].[K+].[Cl-].[Na+] LOKCTEFSRHRXRJ-UHFFFAOYSA-I 0.000 description 52
- 239000002953 phosphate buffered saline Substances 0.000 description 52
- DNIAPMSPPWPWGF-UHFFFAOYSA-N Propylene glycol Chemical compound CC(O)CO DNIAPMSPPWPWGF-UHFFFAOYSA-N 0.000 description 51
- 235000018102 proteins Nutrition 0.000 description 50
- 239000000523 sample Substances 0.000 description 46
- 125000003342 alkenyl group Chemical group 0.000 description 44
- 230000008569 process Effects 0.000 description 42
- 235000001014 amino acid Nutrition 0.000 description 41
- 229940024606 amino acid Drugs 0.000 description 41
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 38
- 150000004676 glycans Chemical class 0.000 description 38
- 229910001868 water Inorganic materials 0.000 description 35
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 34
- 239000011541 reaction mixture Substances 0.000 description 33
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 33
- 125000002947 alkylene group Chemical group 0.000 description 31
- 125000002496 methyl group Chemical group [H]C([H])([H])* 0.000 description 31
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 30
- 229920001223 polyethylene glycol Polymers 0.000 description 30
- 230000002829 reductive effect Effects 0.000 description 30
- 238000000746 purification Methods 0.000 description 29
- 238000010183 spectrum analysis Methods 0.000 description 28
- 102000004190 Enzymes Human genes 0.000 description 24
- 108090000790 Enzymes Proteins 0.000 description 24
- 230000000295 complement effect Effects 0.000 description 24
- 229940088598 enzyme Drugs 0.000 description 24
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 24
- 125000004450 alkenylene group Chemical group 0.000 description 23
- 125000004419 alkynylene group Chemical group 0.000 description 23
- 238000004458 analytical method Methods 0.000 description 23
- 125000006270 aryl alkenylene group Chemical group 0.000 description 23
- 238000004007 reversed phase HPLC Methods 0.000 description 23
- 125000005724 cycloalkenylene group Chemical group 0.000 description 22
- 238000003786 synthesis reaction Methods 0.000 description 22
- 125000000852 azido group Chemical group *N=[N+]=[N-] 0.000 description 21
- 230000015572 biosynthetic process Effects 0.000 description 21
- 125000004432 carbon atom Chemical group C* 0.000 description 21
- 125000002993 cycloalkylene group Chemical group 0.000 description 21
- STQGQHZAVUOBTE-UHFFFAOYSA-N 7-Cyan-hept-2t-en-4,6-diinsaeure Natural products C1=2C(O)=C3C(=O)C=4C(OC)=CC=CC=4C(=O)C3=C(O)C=2CC(O)(C(C)=O)CC1OC1CC(N)C(O)C(C)O1 STQGQHZAVUOBTE-UHFFFAOYSA-N 0.000 description 20
- 125000004433 nitrogen atom Chemical group N* 0.000 description 19
- IMNFDUFMRHMDMM-UHFFFAOYSA-N N-Heptane Chemical compound CCCCCCC IMNFDUFMRHMDMM-UHFFFAOYSA-N 0.000 description 18
- 229940049595 antibody-drug conjugate Drugs 0.000 description 18
- 238000006352 cycloaddition reaction Methods 0.000 description 18
- 229920001542 oligosaccharide Polymers 0.000 description 18
- 150000002482 oligosaccharides Chemical class 0.000 description 18
- 239000007787 solid Substances 0.000 description 18
- 235000019439 ethyl acetate Nutrition 0.000 description 17
- 229910052757 nitrogen Inorganic materials 0.000 description 17
- 239000012071 phase Substances 0.000 description 17
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 16
- 239000007983 Tris buffer Substances 0.000 description 16
- 238000004440 column chromatography Methods 0.000 description 16
- 125000000392 cycloalkenyl group Chemical group 0.000 description 16
- 239000003814 drug Substances 0.000 description 16
- IWBOPFCKHIJFMS-UHFFFAOYSA-N ethylene glycol bis(2-aminoethyl) ether Chemical compound NCCOCCOCCN IWBOPFCKHIJFMS-UHFFFAOYSA-N 0.000 description 16
- 238000004128 high performance liquid chromatography Methods 0.000 description 16
- 150000002772 monosaccharides Chemical class 0.000 description 16
- NVBFHJWHLNUMCV-UHFFFAOYSA-N sulfamide Chemical compound NS(N)(=O)=O NVBFHJWHLNUMCV-UHFFFAOYSA-N 0.000 description 16
- 102000005744 Glycoside Hydrolases Human genes 0.000 description 15
- 108010031186 Glycoside Hydrolases Proteins 0.000 description 15
- 241001465754 Metazoa Species 0.000 description 15
- 241000699670 Mus sp. Species 0.000 description 15
- 108091034117 Oligonucleotide Proteins 0.000 description 15
- 238000004587 chromatography analysis Methods 0.000 description 15
- 238000006736 Huisgen cycloaddition reaction Methods 0.000 description 14
- 150000001540 azides Chemical class 0.000 description 14
- 229910052799 carbon Inorganic materials 0.000 description 14
- 210000004027 cell Anatomy 0.000 description 14
- 125000000468 ketone group Chemical group 0.000 description 14
- 239000002105 nanoparticle Substances 0.000 description 14
- 239000000377 silicon dioxide Substances 0.000 description 14
- 239000000126 substance Substances 0.000 description 14
- 125000003396 thiol group Chemical group [H]S* 0.000 description 14
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 description 13
- 230000002776 aggregation Effects 0.000 description 13
- 238000004220 aggregation Methods 0.000 description 13
- 125000002915 carbonyl group Chemical group [*:2]C([*:1])=O 0.000 description 13
- ZPWOOKQUDFIEIX-UHFFFAOYSA-N cyclooctyne Chemical compound C1CCCC#CCC1 ZPWOOKQUDFIEIX-UHFFFAOYSA-N 0.000 description 13
- 229940079593 drug Drugs 0.000 description 13
- 125000001495 ethyl group Chemical group [H]C([H])([H])C([H])([H])* 0.000 description 13
- 239000011859 microparticle Substances 0.000 description 13
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 12
- 239000000872 buffer Substances 0.000 description 12
- 201000011510 cancer Diseases 0.000 description 12
- 230000000694 effects Effects 0.000 description 12
- 125000004185 ester group Chemical group 0.000 description 12
- RAXXELZNTBOGNW-UHFFFAOYSA-N imidazole Natural products C1=CNC=N1 RAXXELZNTBOGNW-UHFFFAOYSA-N 0.000 description 12
- 239000012044 organic layer Substances 0.000 description 12
- 229920000642 polymer Polymers 0.000 description 12
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 12
- NXLNNXIXOYSCMB-UHFFFAOYSA-N (4-nitrophenyl) carbonochloridate Chemical compound [O-][N+](=O)C1=CC=C(OC(Cl)=O)C=C1 NXLNNXIXOYSCMB-UHFFFAOYSA-N 0.000 description 11
- 238000005698 Diels-Alder reaction Methods 0.000 description 11
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 11
- 150000001345 alkine derivatives Chemical class 0.000 description 11
- MSWZFWKMSRAUBD-UHFFFAOYSA-N beta-D-galactosamine Natural products NC1C(O)OC(CO)C(O)C1O MSWZFWKMSRAUBD-UHFFFAOYSA-N 0.000 description 11
- 125000005587 carbonate group Chemical group 0.000 description 11
- 150000001993 dienes Chemical class 0.000 description 11
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 11
- 125000004430 oxygen atom Chemical group O* 0.000 description 11
- AOJJSUZBOXZQNB-TZSSRYMLSA-N Doxorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(=O)CO)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 AOJJSUZBOXZQNB-TZSSRYMLSA-N 0.000 description 10
- IAJILQKETJEXLJ-UHFFFAOYSA-N Galacturonsaeure Natural products O=CC(O)C(O)C(O)C(O)C(O)=O IAJILQKETJEXLJ-UHFFFAOYSA-N 0.000 description 10
- 239000011203 carbon fibre reinforced carbon Substances 0.000 description 10
- 238000003818 flash chromatography Methods 0.000 description 10
- 238000007306 functionalization reaction Methods 0.000 description 10
- 230000002209 hydrophobic effect Effects 0.000 description 10
- 125000001449 isopropyl group Chemical group [H]C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 10
- 108020004707 nucleic acids Proteins 0.000 description 10
- 150000007523 nucleic acids Chemical class 0.000 description 10
- 102000039446 nucleic acids Human genes 0.000 description 10
- 229920001184 polypeptide Polymers 0.000 description 10
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 9
- FXHOOIRPVKKKFG-UHFFFAOYSA-N N,N-Dimethylacetamide Chemical compound CN(C)C(C)=O FXHOOIRPVKKKFG-UHFFFAOYSA-N 0.000 description 9
- 150000001336 alkenes Chemical class 0.000 description 9
- 230000037396 body weight Effects 0.000 description 9
- 239000011133 lead Substances 0.000 description 9
- 125000004108 n-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])C([H])([H])* 0.000 description 9
- SQDFHQJTAWCFIB-UHFFFAOYSA-N n-methylidenehydroxylamine Chemical compound ON=C SQDFHQJTAWCFIB-UHFFFAOYSA-N 0.000 description 9
- 125000002914 sec-butyl group Chemical group [H]C([H])([H])C([H])([H])C([H])(*)C([H])([H])[H] 0.000 description 9
- 125000000999 tert-butyl group Chemical group [H]C([H])([H])C(*)(C([H])([H])[H])C([H])([H])[H] 0.000 description 9
- 229960001612 trastuzumab emtansine Drugs 0.000 description 9
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 8
- OAKJQQAXSVQMHS-UHFFFAOYSA-N Hydrazine Chemical compound NN OAKJQQAXSVQMHS-UHFFFAOYSA-N 0.000 description 8
- XYFCBTPGUUZFHI-UHFFFAOYSA-N Phosphine Chemical compound P XYFCBTPGUUZFHI-UHFFFAOYSA-N 0.000 description 8
- 239000002202 Polyethylene glycol Substances 0.000 description 8
- IAJILQKETJEXLJ-QTBDOELSSA-N aldehydo-D-glucuronic acid Chemical compound O=C[C@H](O)[C@@H](O)[C@H](O)[C@H](O)C(O)=O IAJILQKETJEXLJ-QTBDOELSSA-N 0.000 description 8
- 230000004927 fusion Effects 0.000 description 8
- 108020001507 fusion proteins Proteins 0.000 description 8
- 102000037865 fusion proteins Human genes 0.000 description 8
- 229940097043 glucuronic acid Drugs 0.000 description 8
- 239000010410 layer Substances 0.000 description 8
- 238000004519 manufacturing process Methods 0.000 description 8
- 125000004123 n-propyl group Chemical group [H]C([H])([H])C([H])([H])C([H])([H])* 0.000 description 8
- 150000002825 nitriles Chemical class 0.000 description 8
- 150000007855 nitrilimines Chemical class 0.000 description 8
- 229920001451 polypropylene glycol Polymers 0.000 description 8
- 150000003852 triazoles Chemical class 0.000 description 8
- JYEUMXHLPRZUAT-UHFFFAOYSA-N 1,2,3-triazine Chemical group C1=CN=NN=C1 JYEUMXHLPRZUAT-UHFFFAOYSA-N 0.000 description 7
- XCCTYIAWTASOJW-XVFCMESISA-N Uridine-5'-Diphosphate Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(=O)OP(O)(O)=O)O[C@H]1N1C(=O)NC(=O)C=C1 XCCTYIAWTASOJW-XVFCMESISA-N 0.000 description 7
- 125000003277 amino group Chemical group 0.000 description 7
- SQVRNKJHWKZAKO-UHFFFAOYSA-N beta-N-Acetyl-D-neuraminic acid Natural products CC(=O)NC1C(O)CC(O)(C(O)=O)OC1C(O)C(O)CO SQVRNKJHWKZAKO-UHFFFAOYSA-N 0.000 description 7
- 150000001732 carboxylic acid derivatives Chemical class 0.000 description 7
- 125000000522 cyclooctenyl group Chemical class C1(=CCCCCCC1)* 0.000 description 7
- 125000000664 diazo group Chemical group [N-]=[N+]=[*] 0.000 description 7
- 229910052731 fluorine Inorganic materials 0.000 description 7
- 125000001072 heteroaryl group Chemical group 0.000 description 7
- 150000002632 lipids Chemical class 0.000 description 7
- 229920001282 polysaccharide Polymers 0.000 description 7
- 239000005017 polysaccharide Substances 0.000 description 7
- 238000010791 quenching Methods 0.000 description 7
- 229920006395 saturated elastomer Polymers 0.000 description 7
- PECYZEOJVXMISF-UHFFFAOYSA-N 3-aminoalanine Chemical compound [NH3+]CC(N)C([O-])=O PECYZEOJVXMISF-UHFFFAOYSA-N 0.000 description 6
- ZWIADYZPOWUWEW-XVFCMESISA-N CDP Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(=O)OP(O)(O)=O)O1 ZWIADYZPOWUWEW-XVFCMESISA-N 0.000 description 6
- QGWNDRXFNXRZMB-UUOKFMHZSA-N GDP Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(O)=O)[C@@H](O)[C@H]1O QGWNDRXFNXRZMB-UUOKFMHZSA-N 0.000 description 6
- 108060003306 Galactosyltransferase Proteins 0.000 description 6
- 102000030902 Galactosyltransferase Human genes 0.000 description 6
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 6
- 125000000539 amino acid group Chemical group 0.000 description 6
- 239000000611 antibody drug conjugate Substances 0.000 description 6
- 238000013459 approach Methods 0.000 description 6
- 239000008346 aqueous phase Substances 0.000 description 6
- 125000001559 cyclopropyl group Chemical group [H]C1([H])C([H])([H])C1([H])* 0.000 description 6
- 238000003379 elimination reaction Methods 0.000 description 6
- QGWNDRXFNXRZMB-UHFFFAOYSA-N guanidine diphosphate Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(COP(O)(=O)OP(O)(O)=O)C(O)C1O QGWNDRXFNXRZMB-UHFFFAOYSA-N 0.000 description 6
- 229910052740 iodine Inorganic materials 0.000 description 6
- 239000002773 nucleotide Substances 0.000 description 6
- 125000003729 nucleotide group Chemical group 0.000 description 6
- 125000001997 phenyl group Chemical group [H]C1=C([H])C([H])=C(*)C([H])=C1[H] 0.000 description 6
- 102220080600 rs797046116 Human genes 0.000 description 6
- 238000003756 stirring Methods 0.000 description 6
- 125000005247 tetrazinyl group Chemical group N1=NN=NC(=C1)* 0.000 description 6
- 238000005303 weighing Methods 0.000 description 6
- MTCFGRXMJLQNBG-REOHCLBHSA-N (2S)-2-Amino-3-hydroxypropansäure Chemical compound OC[C@H](N)C(O)=O MTCFGRXMJLQNBG-REOHCLBHSA-N 0.000 description 5
- DYLIWHYUXAJDOJ-OWOJBTEDSA-N (e)-4-(6-aminopurin-9-yl)but-2-en-1-ol Chemical compound NC1=NC=NC2=C1N=CN2C\C=C\CO DYLIWHYUXAJDOJ-OWOJBTEDSA-N 0.000 description 5
- WZZBNLYBHUDSHF-DHLKQENFSA-N 1-[(3s,4s)-4-[8-(2-chloro-4-pyrimidin-2-yloxyphenyl)-7-fluoro-2-methylimidazo[4,5-c]quinolin-1-yl]-3-fluoropiperidin-1-yl]-2-hydroxyethanone Chemical compound CC1=NC2=CN=C3C=C(F)C(C=4C(=CC(OC=5N=CC=CN=5)=CC=4)Cl)=CC3=C2N1[C@H]1CCN(C(=O)CO)C[C@@H]1F WZZBNLYBHUDSHF-DHLKQENFSA-N 0.000 description 5
- GIAFURWZWWWBQT-UHFFFAOYSA-N 2-(2-aminoethoxy)ethanol Chemical compound NCCOCCO GIAFURWZWWWBQT-UHFFFAOYSA-N 0.000 description 5
- WQUBEIMCFHCJCO-AWCRTANDSA-N 4-amino-n-{4-[2-(2,6-dimethyl-phenoxy)-acetylamino]-3-hydroxy-1-isobutyl-5-phenyl-pentyl}-benzamide Chemical group C([C@@H]([C@@H](O)C[C@H](CC(C)C)NC(=O)C=1C=C(N)C=CC=1)NC(=O)COC=1C(=CC=CC=1C)C)C1=CC=CC=C1 WQUBEIMCFHCJCO-AWCRTANDSA-N 0.000 description 5
- 108010027164 Amanitins Proteins 0.000 description 5
- 0 CC(C)(C(NS(N(C)*)(=O)=O)=O)OC(C)(C)S Chemical compound CC(C)(C(NS(N(C)*)(=O)=O)=O)OC(C)(C)S 0.000 description 5
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical group [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 5
- 229940126639 Compound 33 Drugs 0.000 description 5
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical group CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 5
- 108010046220 N-Acetylgalactosaminyltransferases Proteins 0.000 description 5
- 102000007524 N-Acetylgalactosaminyltransferases Human genes 0.000 description 5
- PXHVJJICTQNCMI-UHFFFAOYSA-N Nickel Chemical compound [Ni] PXHVJJICTQNCMI-UHFFFAOYSA-N 0.000 description 5
- PNUZDKCDAWUEGK-CYZMBNFOSA-N Sitafloxacin Chemical compound C([C@H]1N)N(C=2C(=C3C(C(C(C(O)=O)=CN3[C@H]3[C@H](C3)F)=O)=CC=2F)Cl)CC11CC1 PNUZDKCDAWUEGK-CYZMBNFOSA-N 0.000 description 5
- 125000002877 alkyl aryl group Chemical group 0.000 description 5
- CIORWBWIBBPXCG-JZTFPUPKSA-N amanitin Chemical compound O=C1N[C@@H](CC(N)=O)C(=O)N2CC(O)C[C@H]2C(=O)N[C@@H](C(C)[C@@H](O)CO)C(=O)N[C@@H](C2)C(=O)NCC(=O)N[C@@H](C(C)CC)C(=O)NCC(=O)N[C@H]1CS(=O)C1=C2C2=CC=C(O)C=C2N1 CIORWBWIBBPXCG-JZTFPUPKSA-N 0.000 description 5
- 150000001412 amines Chemical class 0.000 description 5
- 239000007864 aqueous solution Substances 0.000 description 5
- 229910052794 bromium Inorganic materials 0.000 description 5
- 150000001720 carbohydrates Chemical class 0.000 description 5
- 239000003153 chemical reaction reagent Substances 0.000 description 5
- ODDUNIODPWONQM-UHFFFAOYSA-N chlorosulfonylazaniumylidynemethane Chemical compound ClS(=O)(=O)[N+]#[C-] ODDUNIODPWONQM-UHFFFAOYSA-N 0.000 description 5
- 239000010949 copper Substances 0.000 description 5
- 125000000298 cyclopropenyl group Chemical group [H]C1=C([H])C1([H])* 0.000 description 5
- 230000003247 decreasing effect Effects 0.000 description 5
- 125000002897 diene group Chemical group 0.000 description 5
- ZBCBWPMODOFKDW-UHFFFAOYSA-N diethanolamine Chemical compound OCCNCCO ZBCBWPMODOFKDW-UHFFFAOYSA-N 0.000 description 5
- 230000008030 elimination Effects 0.000 description 5
- 239000005556 hormone Substances 0.000 description 5
- 229940088597 hormone Drugs 0.000 description 5
- 125000002312 hydrocarbylidene group Chemical group 0.000 description 5
- 239000000017 hydrogel Substances 0.000 description 5
- 231100000682 maximum tolerated dose Toxicity 0.000 description 5
- 239000012528 membrane Substances 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 238000006053 organic reaction Methods 0.000 description 5
- 230000009467 reduction Effects 0.000 description 5
- 238000000926 separation method Methods 0.000 description 5
- 150000008163 sugars Chemical class 0.000 description 5
- 150000003573 thiols Chemical class 0.000 description 5
- VIJSPAIQWVPKQZ-BLECARSGSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-acetamido-5-(diaminomethylideneamino)pentanoyl]amino]-4-methylpentanoyl]amino]-4,4-dimethylpentanoyl]amino]-4-methylpentanoyl]amino]propanoyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound NC(=N)NCCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CC(C)(C)C)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCNC(N)=N)NC(C)=O VIJSPAIQWVPKQZ-BLECARSGSA-N 0.000 description 4
- IAKHMKGGTNLKSZ-INIZCTEOSA-N (S)-colchicine Chemical compound C1([C@@H](NC(C)=O)CC2)=CC(=O)C(OC)=CC=C1C1=C2C=C(OC)C(OC)=C1OC IAKHMKGGTNLKSZ-INIZCTEOSA-N 0.000 description 4
- OKKJLVBELUTLKV-MZCSYVLQSA-N Deuterated methanol Chemical compound [2H]OC([2H])([2H])[2H] OKKJLVBELUTLKV-MZCSYVLQSA-N 0.000 description 4
- BCCRXDTUTZHDEU-VKHMYHEASA-N Gly-Ser Chemical compound NCC(=O)N[C@@H](CO)C(O)=O BCCRXDTUTZHDEU-VKHMYHEASA-N 0.000 description 4
- PEEHTFAAVSWFBL-UHFFFAOYSA-N Maleimide Chemical compound O=C1NC(=O)C=C1 PEEHTFAAVSWFBL-UHFFFAOYSA-N 0.000 description 4
- SQVRNKJHWKZAKO-PFQGKNLYSA-N N-acetyl-beta-neuraminic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)O[C@H]1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-PFQGKNLYSA-N 0.000 description 4
- 229920003171 Poly (ethylene oxide) Polymers 0.000 description 4
- MTCFGRXMJLQNBG-UHFFFAOYSA-N Serine Natural products OCC(N)C(O)=O MTCFGRXMJLQNBG-UHFFFAOYSA-N 0.000 description 4
- PPBRXRYQALVLMV-UHFFFAOYSA-N Styrene Chemical compound C=CC1=CC=CC=C1 PPBRXRYQALVLMV-UHFFFAOYSA-N 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- 230000009286 beneficial effect Effects 0.000 description 4
- 125000002619 bicyclic group Chemical group 0.000 description 4
- 239000003795 chemical substances by application Substances 0.000 description 4
- IERHLVCPSMICTF-XVFCMESISA-N cytidine 5'-monophosphate Chemical compound O=C1N=C(N)C=CN1[C@H]1[C@H](O)[C@H](O)[C@@H](COP(O)(O)=O)O1 IERHLVCPSMICTF-XVFCMESISA-N 0.000 description 4
- IERHLVCPSMICTF-UHFFFAOYSA-N cytidine monophosphate Natural products O=C1N=C(N)C=CN1C1C(O)C(O)C(COP(O)(O)=O)O1 IERHLVCPSMICTF-UHFFFAOYSA-N 0.000 description 4
- UJLXYODCHAELLY-XLPZGREQSA-N dTDP Chemical compound O=C1NC(=O)C(C)=CN1[C@@H]1O[C@H](COP(O)(=O)OP(O)(O)=O)[C@@H](O)C1 UJLXYODCHAELLY-XLPZGREQSA-N 0.000 description 4
- 239000000975 dye Substances 0.000 description 4
- 150000002148 esters Chemical class 0.000 description 4
- 229940093476 ethylene glycol Drugs 0.000 description 4
- GNBHRKFJIUUOQI-UHFFFAOYSA-N fluorescein Chemical class O1C(=O)C2=CC=CC=C2C21C1=CC=C(O)C=C1OC1=CC(O)=CC=C21 GNBHRKFJIUUOQI-UHFFFAOYSA-N 0.000 description 4
- 230000014509 gene expression Effects 0.000 description 4
- 239000008103 glucose Substances 0.000 description 4
- 150000004820 halides Chemical group 0.000 description 4
- 125000005439 maleimidyl group Chemical group C1(C=CC(N1*)=O)=O 0.000 description 4
- 150000007522 mineralic acids Chemical class 0.000 description 4
- 125000002950 monocyclic group Chemical group 0.000 description 4
- BTWRPQHFJAFXJR-UHFFFAOYSA-N n-[2-(ethylaminooxy)ethoxy]ethanamine Chemical compound CCNOCCONCC BTWRPQHFJAFXJR-UHFFFAOYSA-N 0.000 description 4
- 150000007524 organic acids Chemical class 0.000 description 4
- 206010033675 panniculitis Diseases 0.000 description 4
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 4
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 4
- 125000004076 pyridyl group Chemical group 0.000 description 4
- 239000010948 rhodium Substances 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 210000004304 subcutaneous tissue Anatomy 0.000 description 4
- 125000000446 sulfanediyl group Chemical group *S* 0.000 description 4
- 125000002128 sulfonyl halide group Chemical group 0.000 description 4
- 239000006228 supernatant Substances 0.000 description 4
- 150000003568 thioethers Chemical class 0.000 description 4
- 239000003643 water by type Substances 0.000 description 4
- 230000003442 weekly effect Effects 0.000 description 4
- YJLIKUSWRSEPSM-WGQQHEPDSA-N (2r,3r,4s,5r)-2-[6-amino-8-[(4-phenylphenyl)methylamino]purin-9-yl]-5-(hydroxymethyl)oxolane-3,4-diol Chemical compound C=1C=C(C=2C=CC=CC=2)C=CC=1CNC1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O YJLIKUSWRSEPSM-WGQQHEPDSA-N 0.000 description 3
- AGGWFDNPHKLBBV-YUMQZZPRSA-N (2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]-5-(carbamoylamino)pentanoic acid Chemical compound CC(C)[C@H](N)C(=O)N[C@H](C(O)=O)CCCNC(N)=O AGGWFDNPHKLBBV-YUMQZZPRSA-N 0.000 description 3
- UDQTXCHQKHIQMH-KYGLGHNPSA-N (3ar,5s,6s,7r,7ar)-5-(difluoromethyl)-2-(ethylamino)-5,6,7,7a-tetrahydro-3ah-pyrano[3,2-d][1,3]thiazole-6,7-diol Chemical compound S1C(NCC)=N[C@H]2[C@@H]1O[C@H](C(F)F)[C@@H](O)[C@@H]2O UDQTXCHQKHIQMH-KYGLGHNPSA-N 0.000 description 3
- MPDDTAJMJCESGV-CTUHWIOQSA-M (3r,5r)-7-[2-(4-fluorophenyl)-5-[methyl-[(1r)-1-phenylethyl]carbamoyl]-4-propan-2-ylpyrazol-3-yl]-3,5-dihydroxyheptanoate Chemical compound C1([C@@H](C)N(C)C(=O)C2=NN(C(CC[C@@H](O)C[C@@H](O)CC([O-])=O)=C2C(C)C)C=2C=CC(F)=CC=2)=CC=CC=C1 MPDDTAJMJCESGV-CTUHWIOQSA-M 0.000 description 3
- YQOLEILXOBUDMU-KRWDZBQOSA-N (4R)-5-[(6-bromo-3-methyl-2-pyrrolidin-1-ylquinoline-4-carbonyl)amino]-4-(2-chlorophenyl)pentanoic acid Chemical compound CC1=C(C2=C(C=CC(=C2)Br)N=C1N3CCCC3)C(=O)NC[C@H](CCC(=O)O)C4=CC=CC=C4Cl YQOLEILXOBUDMU-KRWDZBQOSA-N 0.000 description 3
- 125000006710 (C2-C12) alkenyl group Chemical group 0.000 description 3
- 125000006711 (C2-C12) alkynyl group Chemical group 0.000 description 3
- RYHBNJHYFVUHQT-UHFFFAOYSA-N 1,4-Dioxane Chemical compound C1COCCO1 RYHBNJHYFVUHQT-UHFFFAOYSA-N 0.000 description 3
- VCUXVXLUOHDHKK-UHFFFAOYSA-N 2-(2-aminopyrimidin-4-yl)-4-(2-chloro-4-methoxyphenyl)-1,3-thiazole-5-carboxamide Chemical compound ClC1=CC(OC)=CC=C1C1=C(C(N)=O)SC(C=2N=C(N)N=CC=2)=N1 VCUXVXLUOHDHKK-UHFFFAOYSA-N 0.000 description 3
- PYRKKGOKRMZEIT-UHFFFAOYSA-N 2-[6-(2-cyclopropylethoxy)-9-(2-hydroxy-2-methylpropyl)-1h-phenanthro[9,10-d]imidazol-2-yl]-5-fluorobenzene-1,3-dicarbonitrile Chemical compound C1=C2C3=CC(CC(C)(O)C)=CC=C3C=3NC(C=4C(=CC(F)=CC=4C#N)C#N)=NC=3C2=CC=C1OCCC1CC1 PYRKKGOKRMZEIT-UHFFFAOYSA-N 0.000 description 3
- MSWZFWKMSRAUBD-GASJEMHNSA-N 2-amino-2-deoxy-D-galactopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O MSWZFWKMSRAUBD-GASJEMHNSA-N 0.000 description 3
- HBAQYPYDRFILMT-UHFFFAOYSA-N 8-[3-(1-cyclopropylpyrazol-4-yl)-1H-pyrazolo[4,3-d]pyrimidin-5-yl]-3-methyl-3,8-diazabicyclo[3.2.1]octan-2-one Chemical class C1(CC1)N1N=CC(=C1)C1=NNC2=C1N=C(N=C2)N1C2C(N(CC1CC2)C)=O HBAQYPYDRFILMT-UHFFFAOYSA-N 0.000 description 3
- DCXYFEDJOCDNAF-UHFFFAOYSA-N Asparagine Natural products OC(=O)C(N)CC(N)=O DCXYFEDJOCDNAF-UHFFFAOYSA-N 0.000 description 3
- UHOVQNZJYSORNB-UHFFFAOYSA-N Benzene Chemical compound C1=CC=CC=C1 UHOVQNZJYSORNB-UHFFFAOYSA-N 0.000 description 3
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 description 3
- 241000588724 Escherichia coli Species 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 239000004471 Glycine Substances 0.000 description 3
- DCXYFEDJOCDNAF-REOHCLBHSA-N L-asparagine Chemical compound OC(=O)[C@@H](N)CC(N)=O DCXYFEDJOCDNAF-REOHCLBHSA-N 0.000 description 3
- AYFVYJQAPQTCCC-GBXIJSLDSA-N L-threonine Chemical compound C[C@@H](O)[C@H](N)C(O)=O AYFVYJQAPQTCCC-GBXIJSLDSA-N 0.000 description 3
- 241000700159 Rattus Species 0.000 description 3
- 229920002684 Sepharose Polymers 0.000 description 3
- DPOPAJRDYZGTIR-UHFFFAOYSA-N Tetrazine Chemical compound C1=CN=NN=N1 DPOPAJRDYZGTIR-UHFFFAOYSA-N 0.000 description 3
- YXFVVABEGXRONW-UHFFFAOYSA-N Toluene Chemical compound CC1=CC=CC=C1 YXFVVABEGXRONW-UHFFFAOYSA-N 0.000 description 3
- SPXSEZMVRJLHQG-XMMPIXPASA-N [(2R)-1-[[4-[(3-phenylmethoxyphenoxy)methyl]phenyl]methyl]pyrrolidin-2-yl]methanol Chemical compound C(C1=CC=CC=C1)OC=1C=C(OCC2=CC=C(CN3[C@H](CCC3)CO)C=C2)C=CC=1 SPXSEZMVRJLHQG-XMMPIXPASA-N 0.000 description 3
- PSLUFJFHTBIXMW-WYEYVKMPSA-N [(3r,4ar,5s,6s,6as,10s,10ar,10bs)-3-ethenyl-10,10b-dihydroxy-3,4a,7,7,10a-pentamethyl-1-oxo-6-(2-pyridin-2-ylethylcarbamoyloxy)-5,6,6a,8,9,10-hexahydro-2h-benzo[f]chromen-5-yl] acetate Chemical compound O([C@@H]1[C@@H]([C@]2(O[C@](C)(CC(=O)[C@]2(O)[C@@]2(C)[C@@H](O)CCC(C)(C)[C@@H]21)C=C)C)OC(=O)C)C(=O)NCCC1=CC=CC=N1 PSLUFJFHTBIXMW-WYEYVKMPSA-N 0.000 description 3
- 150000001299 aldehydes Chemical class 0.000 description 3
- 150000001335 aliphatic alkanes Chemical class 0.000 description 3
- 125000003545 alkoxy group Chemical group 0.000 description 3
- 125000005213 alkyl heteroaryl group Chemical group 0.000 description 3
- 235000009582 asparagine Nutrition 0.000 description 3
- 229960001230 asparagine Drugs 0.000 description 3
- 125000004429 atom Chemical group 0.000 description 3
- 230000008901 benefit Effects 0.000 description 3
- HQMRIBYCTLBDAK-UHFFFAOYSA-M bis(2-methylpropyl)alumanylium;chloride Chemical compound CC(C)C[Al](Cl)CC(C)C HQMRIBYCTLBDAK-UHFFFAOYSA-M 0.000 description 3
- 229910052796 boron Inorganic materials 0.000 description 3
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 3
- 150000001768 cations Chemical class 0.000 description 3
- WRJWRGBVPUUDLA-UHFFFAOYSA-N chlorosulfonyl isocyanate Chemical compound ClS(=O)(=O)N=C=O WRJWRGBVPUUDLA-UHFFFAOYSA-N 0.000 description 3
- ZYVSOIYQKUDENJ-WKSBCEQHSA-N chromomycin A3 Chemical compound O([C@@H]1C[C@@H](O[C@H](C)[C@@H]1OC(C)=O)OC=1C=C2C=C3C[C@H]([C@@H](C(=O)C3=C(O)C2=C(O)C=1C)O[C@@H]1O[C@H](C)[C@@H](O)[C@H](O[C@@H]2O[C@H](C)[C@@H](O)[C@H](O[C@@H]3O[C@@H](C)[C@H](OC(C)=O)[C@@](C)(O)C3)C2)C1)[C@H](OC)C(=O)[C@@H](O)[C@@H](C)O)[C@@H]1C[C@@H](O)[C@@H](OC)[C@@H](C)O1 ZYVSOIYQKUDENJ-WKSBCEQHSA-N 0.000 description 3
- 238000003776 cleavage reaction Methods 0.000 description 3
- 229940125936 compound 42 Drugs 0.000 description 3
- 229940125844 compound 46 Drugs 0.000 description 3
- 229940127271 compound 49 Drugs 0.000 description 3
- 230000001268 conjugating effect Effects 0.000 description 3
- 150000004775 coumarins Chemical class 0.000 description 3
- 239000000032 diagnostic agent Substances 0.000 description 3
- 229940039227 diagnostic agent Drugs 0.000 description 3
- 150000004985 diamines Chemical class 0.000 description 3
- 208000035475 disorder Diseases 0.000 description 3
- 229940000406 drug candidate Drugs 0.000 description 3
- 229930182830 galactose Natural products 0.000 description 3
- 150000002337 glycosamines Chemical class 0.000 description 3
- 230000013595 glycosylation Effects 0.000 description 3
- 238000006206 glycosylation reaction Methods 0.000 description 3
- PCHJSUWPFVWCPO-UHFFFAOYSA-N gold Chemical compound [Au] PCHJSUWPFVWCPO-UHFFFAOYSA-N 0.000 description 3
- 229910052737 gold Inorganic materials 0.000 description 3
- 239000010931 gold Substances 0.000 description 3
- 125000004446 heteroarylalkyl group Chemical group 0.000 description 3
- 239000002609 medium Substances 0.000 description 3
- DYGBNAYFDZEYBA-UHFFFAOYSA-N n-(cyclopropylmethyl)-2-[4-(4-methoxybenzoyl)piperidin-1-yl]-n-[(4-oxo-1,5,7,8-tetrahydropyrano[4,3-d]pyrimidin-2-yl)methyl]acetamide Chemical compound C1=CC(OC)=CC=C1C(=O)C1CCN(CC(=O)N(CC2CC2)CC=2NC(=O)C=3COCCC=3N=2)CC1 DYGBNAYFDZEYBA-UHFFFAOYSA-N 0.000 description 3
- IOMMMLWIABWRKL-WUTDNEBXSA-N nazartinib Chemical compound C1N(C(=O)/C=C/CN(C)C)CCCC[C@H]1N1C2=C(Cl)C=CC=C2N=C1NC(=O)C1=CC=NC(C)=C1 IOMMMLWIABWRKL-WUTDNEBXSA-N 0.000 description 3
- 125000002872 norbornadienyl group Chemical group C12=C(C=C(CC1)C2)* 0.000 description 3
- 125000003518 norbornenyl group Chemical group C12(C=CC(CC1)C2)* 0.000 description 3
- 230000000144 pharmacologic effect Effects 0.000 description 3
- 229920003229 poly(methyl methacrylate) Polymers 0.000 description 3
- 239000004926 polymethyl methacrylate Substances 0.000 description 3
- 238000002953 preparative HPLC Methods 0.000 description 3
- 150000003220 pyrenes Chemical class 0.000 description 3
- 230000000717 retained effect Effects 0.000 description 3
- SQVRNKJHWKZAKO-OQPLDHBCSA-N sialic acid Chemical compound CC(=O)N[C@@H]1[C@@H](O)C[C@@](O)(C(O)=O)OC1[C@H](O)[C@H](O)CO SQVRNKJHWKZAKO-OQPLDHBCSA-N 0.000 description 3
- 238000010898 silica gel chromatography Methods 0.000 description 3
- 239000011734 sodium Substances 0.000 description 3
- 238000012360 testing method Methods 0.000 description 3
- 150000004905 tetrazines Chemical class 0.000 description 3
- ANRHNWWPFJCPAZ-UHFFFAOYSA-M thionine Chemical compound [Cl-].C1=CC(N)=CC2=[S+]C3=CC(N)=CC=C3N=C21 ANRHNWWPFJCPAZ-UHFFFAOYSA-M 0.000 description 3
- 231100000331 toxic Toxicity 0.000 description 3
- 230000002588 toxic effect Effects 0.000 description 3
- 238000009966 trimming Methods 0.000 description 3
- GCTFTMWXZFLTRR-GFCCVEGCSA-N (2r)-2-amino-n-[3-(difluoromethoxy)-4-(1,3-oxazol-5-yl)phenyl]-4-methylpentanamide Chemical compound FC(F)OC1=CC(NC(=O)[C@H](N)CC(C)C)=CC=C1C1=CN=CO1 GCTFTMWXZFLTRR-GFCCVEGCSA-N 0.000 description 2
- HEYJIJWKSGKYTQ-DPYQTVNSSA-N (2r,3s,4s,5r)-6-azido-2,3,4,5-tetrahydroxyhexanal Chemical compound [N-]=[N+]=NC[C@@H](O)[C@H](O)[C@H](O)[C@@H](O)C=O HEYJIJWKSGKYTQ-DPYQTVNSSA-N 0.000 description 2
- VEGGTWZUZGZKHY-GJZGRUSLSA-N (2s)-2-[[(2s)-2-amino-3-methylbutanoyl]amino]-5-(carbamoylamino)-n-[4-(hydroxymethyl)phenyl]pentanamide Chemical compound NC(=O)NCCC[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)NC1=CC=C(CO)C=C1 VEGGTWZUZGZKHY-GJZGRUSLSA-N 0.000 description 2
- OOKAZRDERJMRCJ-KOUAFAAESA-N (3r)-7-[(1s,2s,4ar,6s,8s)-2,6-dimethyl-8-[(2s)-2-methylbutanoyl]oxy-1,2,4a,5,6,7,8,8a-octahydronaphthalen-1-yl]-3-hydroxy-5-oxoheptanoic acid Chemical compound C1=C[C@H](C)[C@H](CCC(=O)C[C@@H](O)CC(O)=O)C2[C@@H](OC(=O)[C@@H](C)CC)C[C@@H](C)C[C@@H]21 OOKAZRDERJMRCJ-KOUAFAAESA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 125000001399 1,2,3-triazolyl group Chemical group N1N=NC(=C1)* 0.000 description 2
- FYADHXFMURLYQI-UHFFFAOYSA-N 1,2,4-triazine Chemical group C1=CN=NC=N1 FYADHXFMURLYQI-UHFFFAOYSA-N 0.000 description 2
- MYRTYDVEIRVNKP-UHFFFAOYSA-N 1,2-Divinylbenzene Chemical compound C=CC1=CC=CC=C1C=C MYRTYDVEIRVNKP-UHFFFAOYSA-N 0.000 description 2
- BKWQKVJYXODDAC-UHFFFAOYSA-N 1,2-dihydropyridazine Chemical compound N1NC=CC=C1 BKWQKVJYXODDAC-UHFFFAOYSA-N 0.000 description 2
- KKHFRAFPESRGGD-UHFFFAOYSA-N 1,3-dimethyl-7-[3-(n-methylanilino)propyl]purine-2,6-dione Chemical compound C1=NC=2N(C)C(=O)N(C)C(=O)C=2N1CCCN(C)C1=CC=CC=C1 KKHFRAFPESRGGD-UHFFFAOYSA-N 0.000 description 2
- WGFNXGPBPIJYLI-UHFFFAOYSA-N 2,6-difluoro-3-[(3-fluorophenyl)sulfonylamino]-n-(3-methoxy-1h-pyrazolo[3,4-b]pyridin-5-yl)benzamide Chemical compound C1=C2C(OC)=NNC2=NC=C1NC(=O)C(C=1F)=C(F)C=CC=1NS(=O)(=O)C1=CC=CC(F)=C1 WGFNXGPBPIJYLI-UHFFFAOYSA-N 0.000 description 2
- VVCMGAUPZIKYTH-VGHSCWAPSA-N 2-acetyloxybenzoic acid;[(2s,3r)-4-(dimethylamino)-3-methyl-1,2-diphenylbutan-2-yl] propanoate;1,3,7-trimethylpurine-2,6-dione Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O.CN1C(=O)N(C)C(=O)C2=C1N=CN2C.C([C@](OC(=O)CC)([C@H](C)CN(C)C)C=1C=CC=CC=1)C1=CC=CC=C1 VVCMGAUPZIKYTH-VGHSCWAPSA-N 0.000 description 2
- GOJUJUVQIVIZAV-UHFFFAOYSA-N 2-amino-4,6-dichloropyrimidine-5-carbaldehyde Chemical group NC1=NC(Cl)=C(C=O)C(Cl)=N1 GOJUJUVQIVIZAV-UHFFFAOYSA-N 0.000 description 2
- KOUZWQLNUJWNIA-UHFFFAOYSA-N 2-hydrazinylpyridine-3-carboxamide Chemical compound NNC1=NC=CC=C1C(N)=O KOUZWQLNUJWNIA-UHFFFAOYSA-N 0.000 description 2
- VHYFNPMBLIVWCW-UHFFFAOYSA-N 4-Dimethylaminopyridine Chemical compound CN(C)C1=CC=NC=C1 VHYFNPMBLIVWCW-UHFFFAOYSA-N 0.000 description 2
- DQAZPZIYEOGZAF-UHFFFAOYSA-N 4-ethyl-n-[4-(3-ethynylanilino)-7-methoxyquinazolin-6-yl]piperazine-1-carboxamide Chemical compound C1CN(CC)CCN1C(=O)NC(C(=CC1=NC=N2)OC)=CC1=C2NC1=CC=CC(C#C)=C1 DQAZPZIYEOGZAF-UHFFFAOYSA-N 0.000 description 2
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 2
- DALMAZHDNFCDRP-VMPREFPWSA-N 9h-fluoren-9-ylmethyl n-[(2s)-1-[[(2s)-5-(carbamoylamino)-1-[4-(hydroxymethyl)anilino]-1-oxopentan-2-yl]amino]-3-methyl-1-oxobutan-2-yl]carbamate Chemical compound O=C([C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21)C(C)C)NC1=CC=C(CO)C=C1 DALMAZHDNFCDRP-VMPREFPWSA-N 0.000 description 2
- IGAZHQIYONOHQN-UHFFFAOYSA-N Alexa Fluor 555 Chemical compound C=12C=CC(=N)C(S(O)(=O)=O)=C2OC2=C(S(O)(=O)=O)C(N)=CC=C2C=1C1=CC=C(C(O)=O)C=C1C(O)=O IGAZHQIYONOHQN-UHFFFAOYSA-N 0.000 description 2
- 239000004475 Arginine Substances 0.000 description 2
- KAKZBPTYRLMSJV-UHFFFAOYSA-N Butadiene Chemical compound C=CC=C KAKZBPTYRLMSJV-UHFFFAOYSA-N 0.000 description 2
- JQUCWIWWWKZNCS-LESHARBVSA-N C(C1=CC=CC=C1)(=O)NC=1SC[C@H]2[C@@](N1)(CO[C@H](C2)C)C=2SC=C(N2)NC(=O)C2=NC=C(C=C2)OC(F)F Chemical compound C(C1=CC=CC=C1)(=O)NC=1SC[C@H]2[C@@](N1)(CO[C@H](C2)C)C=2SC=C(N2)NC(=O)C2=NC=C(C=C2)OC(F)F JQUCWIWWWKZNCS-LESHARBVSA-N 0.000 description 2
- 102000005600 Cathepsins Human genes 0.000 description 2
- 108010084457 Cathepsins Proteins 0.000 description 2
- 108091026890 Coding region Proteins 0.000 description 2
- RYGMFSIKBFXOCR-UHFFFAOYSA-N Copper Chemical compound [Cu] RYGMFSIKBFXOCR-UHFFFAOYSA-N 0.000 description 2
- 108020004414 DNA Proteins 0.000 description 2
- 206010011906 Death Diseases 0.000 description 2
- 101150029707 ERBB2 gene Proteins 0.000 description 2
- 101150056653 EndoA gene Proteins 0.000 description 2
- 102000003951 Erythropoietin Human genes 0.000 description 2
- 108090000394 Erythropoietin Proteins 0.000 description 2
- 108010088842 Fibrinolysin Proteins 0.000 description 2
- WOBHKFSMXKNTIM-UHFFFAOYSA-N Hydroxyethyl methacrylate Chemical compound CC(=C)C(=O)OCCO WOBHKFSMXKNTIM-UHFFFAOYSA-N 0.000 description 2
- 206010021143 Hypoxia Diseases 0.000 description 2
- DGAQECJNVWCQMB-PUAWFVPOSA-M Ilexoside XXIX Chemical compound C[C@@H]1CC[C@@]2(CC[C@@]3(C(=CC[C@H]4[C@]3(CC[C@@H]5[C@@]4(CC[C@@H](C5(C)C)OS(=O)(=O)[O-])C)C)[C@@H]2[C@]1(C)O)C)C(=O)O[C@H]6[C@@H]([C@H]([C@@H]([C@H](O6)CO)O)O)O.[Na+] DGAQECJNVWCQMB-PUAWFVPOSA-M 0.000 description 2
- 102000001706 Immunoglobulin Fab Fragments Human genes 0.000 description 2
- 108010054477 Immunoglobulin Fab Fragments Proteins 0.000 description 2
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 2
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 2
- XEEYBQQBJWHFJM-UHFFFAOYSA-N Iron Chemical compound [Fe] XEEYBQQBJWHFJM-UHFFFAOYSA-N 0.000 description 2
- XUJNEKJLAYXESH-REOHCLBHSA-N L-Cysteine Chemical compound SC[C@H](N)C(O)=O XUJNEKJLAYXESH-REOHCLBHSA-N 0.000 description 2
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 2
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 2
- 239000004472 Lysine Substances 0.000 description 2
- FYYHWMGAXLPEAU-UHFFFAOYSA-N Magnesium Chemical compound [Mg] FYYHWMGAXLPEAU-UHFFFAOYSA-N 0.000 description 2
- 229930126263 Maytansine Natural products 0.000 description 2
- 108010006035 Metalloproteases Proteins 0.000 description 2
- 102000005741 Metalloproteases Human genes 0.000 description 2
- 241000699666 Mus <mouse, genus> Species 0.000 description 2
- LVDRREOUMKACNJ-BKMJKUGQSA-N N-[(2R,3S)-2-(4-chlorophenyl)-1-(1,4-dimethyl-2-oxoquinolin-7-yl)-6-oxopiperidin-3-yl]-2-methylpropane-1-sulfonamide Chemical compound CC(C)CS(=O)(=O)N[C@H]1CCC(=O)N([C@@H]1c1ccc(Cl)cc1)c1ccc2c(C)cc(=O)n(C)c2c1 LVDRREOUMKACNJ-BKMJKUGQSA-N 0.000 description 2
- OPFJDXRVMFKJJO-ZHHKINOHSA-N N-{[3-(2-benzamido-4-methyl-1,3-thiazol-5-yl)-pyrazol-5-yl]carbonyl}-G-dR-G-dD-dD-dD-NH2 Chemical compound S1C(C=2NN=C(C=2)C(=O)NCC(=O)N[C@H](CCCN=C(N)N)C(=O)NCC(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC(O)=O)C(=O)N[C@H](CC(O)=O)C(N)=O)=C(C)N=C1NC(=O)C1=CC=CC=C1 OPFJDXRVMFKJJO-ZHHKINOHSA-N 0.000 description 2
- QOVYHDHLFPKQQG-NDEPHWFRSA-N N[C@@H](CCC(=O)N1CCC(CC1)NC1=C2C=CC=CC2=NC(NCC2=CN(CCCNCCCNC3CCCCC3)N=N2)=N1)C(O)=O Chemical compound N[C@@H](CCC(=O)N1CCC(CC1)NC1=C2C=CC=CC2=NC(NCC2=CN(CCCNCCCNC3CCCCC3)N=N2)=N1)C(O)=O QOVYHDHLFPKQQG-NDEPHWFRSA-N 0.000 description 2
- 238000011887 Necropsy Methods 0.000 description 2
- 108091005804 Peptidases Proteins 0.000 description 2
- NQRYJNQNLNOLGT-UHFFFAOYSA-N Piperidine Chemical compound C1CCNCC1 NQRYJNQNLNOLGT-UHFFFAOYSA-N 0.000 description 2
- 108010066816 Polypeptide N-acetylgalactosaminyltransferase Proteins 0.000 description 2
- 239000004793 Polystyrene Substances 0.000 description 2
- 239000004372 Polyvinyl alcohol Substances 0.000 description 2
- ZLMJMSJWJFRBEC-UHFFFAOYSA-N Potassium Chemical compound [K] ZLMJMSJWJFRBEC-UHFFFAOYSA-N 0.000 description 2
- 239000004365 Protease Substances 0.000 description 2
- JUJWROOIHBZHMG-UHFFFAOYSA-N Pyridine Chemical compound C1=CC=NC=C1 JUJWROOIHBZHMG-UHFFFAOYSA-N 0.000 description 2
- 102100037486 Reverse transcriptase/ribonuclease H Human genes 0.000 description 2
- BQCADISMDOOEFD-UHFFFAOYSA-N Silver Chemical compound [Ag] BQCADISMDOOEFD-UHFFFAOYSA-N 0.000 description 2
- PMZURENOXWZQFD-UHFFFAOYSA-L Sodium Sulfate Chemical compound [Na+].[Na+].[O-]S([O-])(=O)=O PMZURENOXWZQFD-UHFFFAOYSA-L 0.000 description 2
- AYFVYJQAPQTCCC-UHFFFAOYSA-N Threonine Natural products CC(O)C(N)C(O)=O AYFVYJQAPQTCCC-UHFFFAOYSA-N 0.000 description 2
- 239000004473 Threonine Substances 0.000 description 2
- ATJFFYVFTNAWJD-UHFFFAOYSA-N Tin Chemical compound [Sn] ATJFFYVFTNAWJD-UHFFFAOYSA-N 0.000 description 2
- RTAQQCXQSZGOHL-UHFFFAOYSA-N Titanium Chemical compound [Ti] RTAQQCXQSZGOHL-UHFFFAOYSA-N 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- ISAKRJDGNUQOIC-UHFFFAOYSA-N Uracil Chemical compound O=C1C=CNC(=O)N1 ISAKRJDGNUQOIC-UHFFFAOYSA-N 0.000 description 2
- HSRXSKHRSXRCFC-WDSKDSINSA-N Val-Ala Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(O)=O HSRXSKHRSXRCFC-WDSKDSINSA-N 0.000 description 2
- HCHKCACWOHOZIP-UHFFFAOYSA-N Zinc Chemical compound [Zn] HCHKCACWOHOZIP-UHFFFAOYSA-N 0.000 description 2
- LNUFLCYMSVYYNW-ZPJMAFJPSA-N [(2r,3r,4s,5r,6r)-2-[(2r,3r,4s,5r,6r)-6-[(2r,3r,4s,5r,6r)-6-[(2r,3r,4s,5r,6r)-6-[[(3s,5s,8r,9s,10s,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-3-yl]oxy]-4,5-disulfo Chemical compound O([C@@H]1[C@@H](COS(O)(=O)=O)O[C@@H]([C@@H]([C@H]1OS(O)(=O)=O)OS(O)(=O)=O)O[C@@H]1[C@@H](COS(O)(=O)=O)O[C@@H]([C@@H]([C@H]1OS(O)(=O)=O)OS(O)(=O)=O)O[C@@H]1[C@@H](COS(O)(=O)=O)O[C@H]([C@@H]([C@H]1OS(O)(=O)=O)OS(O)(=O)=O)O[C@@H]1C[C@@H]2CC[C@H]3[C@@H]4CC[C@@H]([C@]4(CC[C@@H]3[C@@]2(C)CC1)C)[C@H](C)CCCC(C)C)[C@H]1O[C@H](COS(O)(=O)=O)[C@@H](OS(O)(=O)=O)[C@H](OS(O)(=O)=O)[C@H]1OS(O)(=O)=O LNUFLCYMSVYYNW-ZPJMAFJPSA-N 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000002411 adverse Effects 0.000 description 2
- 125000003158 alcohol group Chemical group 0.000 description 2
- 125000003302 alkenyloxy group Chemical group 0.000 description 2
- 125000005133 alkynyloxy group Chemical group 0.000 description 2
- 150000001408 amides Chemical group 0.000 description 2
- 230000000844 anti-bacterial effect Effects 0.000 description 2
- 230000000692 anti-sense effect Effects 0.000 description 2
- 229940088710 antibiotic agent Drugs 0.000 description 2
- 239000003443 antiviral agent Substances 0.000 description 2
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 2
- 125000000732 arylene group Chemical group 0.000 description 2
- XJHABGPPCLHLLV-UHFFFAOYSA-N benzo[de]isoquinoline-1,3-dione Chemical class C1=CC(C(=O)NC2=O)=C3C2=CC=CC3=C1 XJHABGPPCLHLLV-UHFFFAOYSA-N 0.000 description 2
- 230000002051 biphasic effect Effects 0.000 description 2
- 239000008280 blood Substances 0.000 description 2
- 210000004369 blood Anatomy 0.000 description 2
- 239000007853 buffer solution Substances 0.000 description 2
- 150000001728 carbonyl compounds Chemical class 0.000 description 2
- 230000015556 catabolic process Effects 0.000 description 2
- 230000003197 catalytic effect Effects 0.000 description 2
- YCIMNLLNPGFGHC-UHFFFAOYSA-N catechol Chemical group OC1=CC=CC=C1O YCIMNLLNPGFGHC-UHFFFAOYSA-N 0.000 description 2
- 238000005119 centrifugation Methods 0.000 description 2
- 239000007795 chemical reaction product Substances 0.000 description 2
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 2
- 229960001338 colchicine Drugs 0.000 description 2
- 229940126086 compound 21 Drugs 0.000 description 2
- 229940125900 compound 59 Drugs 0.000 description 2
- 239000000470 constituent Substances 0.000 description 2
- 229920001577 copolymer Polymers 0.000 description 2
- 229910052802 copper Inorganic materials 0.000 description 2
- 239000006184 cosolvent Substances 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- 125000000000 cycloalkoxy group Chemical group 0.000 description 2
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 2
- 235000018417 cysteine Nutrition 0.000 description 2
- 125000000151 cysteine group Chemical group N[C@@H](CS)C(=O)* 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- STQGQHZAVUOBTE-VGBVRHCVSA-N daunorubicin Chemical compound O([C@H]1C[C@@](O)(CC=2C(O)=C3C(=O)C=4C=CC=C(C=4C(=O)C3=C(O)C=21)OC)C(C)=O)[C@H]1C[C@H](N)[C@H](O)[C@H](C)O1 STQGQHZAVUOBTE-VGBVRHCVSA-N 0.000 description 2
- 229960000975 daunorubicin Drugs 0.000 description 2
- 238000006731 degradation reaction Methods 0.000 description 2
- 238000001514 detection method Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 150000002016 disaccharides Chemical group 0.000 description 2
- 229960004679 doxorubicin Drugs 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- BJXYHBKEQFQVES-NWDGAFQWSA-N enpatoran Chemical compound N[C@H]1CN(C[C@H](C1)C(F)(F)F)C1=C2C=CC=NC2=C(C=C1)C#N BJXYHBKEQFQVES-NWDGAFQWSA-N 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 229940105423 erythropoietin Drugs 0.000 description 2
- 239000013604 expression vector Substances 0.000 description 2
- 239000007850 fluorescent dye Substances 0.000 description 2
- 229960003692 gamma aminobutyric acid Drugs 0.000 description 2
- BTCSSZJGUNDROE-UHFFFAOYSA-N gamma-aminobutyric acid Chemical compound NCCCC(O)=O BTCSSZJGUNDROE-UHFFFAOYSA-N 0.000 description 2
- 230000002068 genetic effect Effects 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 125000003827 glycol group Chemical group 0.000 description 2
- 150000002336 glycosamine derivatives Chemical class 0.000 description 2
- 229930182470 glycoside Natural products 0.000 description 2
- 150000002338 glycosides Chemical class 0.000 description 2
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 2
- 125000005843 halogen group Chemical group 0.000 description 2
- 230000002489 hematologic effect Effects 0.000 description 2
- 150000002429 hydrazines Chemical class 0.000 description 2
- 230000001146 hypoxic effect Effects 0.000 description 2
- IAJILQKETJEXLJ-LECHCGJUSA-N iduronic acid Chemical compound O=C[C@@H](O)[C@H](O)[C@@H](O)[C@H](O)C(O)=O IAJILQKETJEXLJ-LECHCGJUSA-N 0.000 description 2
- 150000002466 imines Chemical class 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 238000011534 incubation Methods 0.000 description 2
- 238000001802 infusion Methods 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 238000002347 injection Methods 0.000 description 2
- 239000007924 injection Substances 0.000 description 2
- 238000001990 intravenous administration Methods 0.000 description 2
- 238000010253 intravenous injection Methods 0.000 description 2
- 238000002955 isolation Methods 0.000 description 2
- 238000001948 isotopic labelling Methods 0.000 description 2
- 150000002576 ketones Chemical class 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 229910052747 lanthanoid Inorganic materials 0.000 description 2
- 150000002602 lanthanoids Chemical class 0.000 description 2
- 210000004185 liver Anatomy 0.000 description 2
- 229910052749 magnesium Inorganic materials 0.000 description 2
- 239000011777 magnesium Substances 0.000 description 2
- 229910052751 metal Inorganic materials 0.000 description 2
- 239000002184 metal Substances 0.000 description 2
- BDAGIHXWWSANSR-UHFFFAOYSA-N methanoic acid Natural products OC=O BDAGIHXWWSANSR-UHFFFAOYSA-N 0.000 description 2
- 238000002493 microarray Methods 0.000 description 2
- 239000002159 nanocrystal Substances 0.000 description 2
- 229910052759 nickel Inorganic materials 0.000 description 2
- 238000005935 nucleophilic addition reaction Methods 0.000 description 2
- 150000003833 nucleoside derivatives Chemical class 0.000 description 2
- 230000003647 oxidation Effects 0.000 description 2
- 238000007254 oxidation reaction Methods 0.000 description 2
- 230000006320 pegylation Effects 0.000 description 2
- 125000001147 pentyl group Chemical group C(CCCC)* 0.000 description 2
- 239000013612 plasmid Substances 0.000 description 2
- 229940012957 plasmin Drugs 0.000 description 2
- 229920002401 polyacrylamide Polymers 0.000 description 2
- 229920002223 polystyrene Polymers 0.000 description 2
- 229920002451 polyvinyl alcohol Polymers 0.000 description 2
- 230000008092 positive effect Effects 0.000 description 2
- 229910052700 potassium Inorganic materials 0.000 description 2
- 239000011591 potassium Substances 0.000 description 2
- BWHMMNNQKKPAPP-UHFFFAOYSA-L potassium carbonate Chemical compound [K+].[K+].[O-]C([O-])=O BWHMMNNQKKPAPP-UHFFFAOYSA-L 0.000 description 2
- OXCMYAYHXIHQOA-UHFFFAOYSA-N potassium;[2-butyl-5-chloro-3-[[4-[2-(1,2,4-triaza-3-azanidacyclopenta-1,4-dien-5-yl)phenyl]phenyl]methyl]imidazol-4-yl]methanol Chemical compound [K+].CCCCC1=NC(Cl)=C(CO)N1CC1=CC=C(C=2C(=CC=CC=2)C2=N[N-]N=N2)C=C1 OXCMYAYHXIHQOA-UHFFFAOYSA-N 0.000 description 2
- 239000002243 precursor Substances 0.000 description 2
- 230000002035 prolonged effect Effects 0.000 description 2
- 125000000714 pyrimidinyl group Chemical group 0.000 description 2
- 239000002096 quantum dot Substances 0.000 description 2
- 230000002285 radioactive effect Effects 0.000 description 2
- PYWVYCXTNDRMGF-UHFFFAOYSA-N rhodamine B Chemical class [Cl-].C=12C=CC(=[N+](CC)CC)C=C2OC2=CC(N(CC)CC)=CC=C2C=1C1=CC=CC=C1C(O)=O PYWVYCXTNDRMGF-UHFFFAOYSA-N 0.000 description 2
- 229910052703 rhodium Inorganic materials 0.000 description 2
- MHOVAHRLVXNVSD-UHFFFAOYSA-N rhodium atom Chemical compound [Rh] MHOVAHRLVXNVSD-UHFFFAOYSA-N 0.000 description 2
- 210000003497 sciatic nerve Anatomy 0.000 description 2
- 230000007017 scission Effects 0.000 description 2
- 229910052709 silver Inorganic materials 0.000 description 2
- 239000004332 silver Substances 0.000 description 2
- 125000003808 silyl group Chemical group [H][Si]([H])([H])[*] 0.000 description 2
- 229910052708 sodium Inorganic materials 0.000 description 2
- 210000000952 spleen Anatomy 0.000 description 2
- 238000012453 sprague-dawley rat model Methods 0.000 description 2
- 239000000758 substrate Substances 0.000 description 2
- OJXASOYYODXRPT-UHFFFAOYSA-N sulfamoylurea Chemical group NC(=O)NS(N)(=O)=O OJXASOYYODXRPT-UHFFFAOYSA-N 0.000 description 2
- 239000000725 suspension Substances 0.000 description 2
- 238000002560 therapeutic procedure Methods 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- 239000011135 tin Substances 0.000 description 2
- 229910052718 tin Inorganic materials 0.000 description 2
- 229910052719 titanium Inorganic materials 0.000 description 2
- 239000010936 titanium Substances 0.000 description 2
- 230000010474 transient expression Effects 0.000 description 2
- RIOQSEWOXXDEQQ-UHFFFAOYSA-N triphenylphosphine Chemical compound C1=CC=CC=C1P(C=1C=CC=CC=1)C1=CC=CC=C1 RIOQSEWOXXDEQQ-UHFFFAOYSA-N 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 238000000108 ultra-filtration Methods 0.000 description 2
- 210000003462 vein Anatomy 0.000 description 2
- 238000005406 washing Methods 0.000 description 2
- 229910052725 zinc Inorganic materials 0.000 description 2
- 239000011701 zinc Substances 0.000 description 2
- OGNSCSPNOLGXSM-UHFFFAOYSA-N (+/-)-DABA Natural products NCCC(N)C(O)=O OGNSCSPNOLGXSM-UHFFFAOYSA-N 0.000 description 1
- ABJSOROVZZKJGI-OCYUSGCXSA-N (1r,2r,4r)-2-(4-bromophenyl)-n-[(4-chlorophenyl)-(2-fluoropyridin-4-yl)methyl]-4-morpholin-4-ylcyclohexane-1-carboxamide Chemical compound C1=NC(F)=CC(C(NC(=O)[C@H]2[C@@H](C[C@@H](CC2)N2CCOCC2)C=2C=CC(Br)=CC=2)C=2C=CC(Cl)=CC=2)=C1 ABJSOROVZZKJGI-OCYUSGCXSA-N 0.000 description 1
- HEYJIJWKSGKYTQ-KCDKBNATSA-N (2S,3R,4R,5S)-6-azido-2,3,4,5-tetrahydroxyhexanal Chemical compound [N-]=[N+]=NC[C@H](O)[C@@H](O)[C@@H](O)[C@H](O)C=O HEYJIJWKSGKYTQ-KCDKBNATSA-N 0.000 description 1
- IUSARDYWEPUTPN-OZBXUNDUSA-N (2r)-n-[(2s,3r)-4-[[(4s)-6-(2,2-dimethylpropyl)spiro[3,4-dihydropyrano[2,3-b]pyridine-2,1'-cyclobutane]-4-yl]amino]-3-hydroxy-1-[3-(1,3-thiazol-2-yl)phenyl]butan-2-yl]-2-methoxypropanamide Chemical compound C([C@H](NC(=O)[C@@H](C)OC)[C@H](O)CN[C@@H]1C2=CC(CC(C)(C)C)=CN=C2OC2(CCC2)C1)C(C=1)=CC=CC=1C1=NC=CS1 IUSARDYWEPUTPN-OZBXUNDUSA-N 0.000 description 1
- HEYJIJWKSGKYTQ-JGWLITMVSA-N (2r,3s,4r,5r)-6-azido-2,3,4,5-tetrahydroxyhexanal Chemical compound [N-]=[N+]=NC[C@@H](O)[C@@H](O)[C@H](O)[C@@H](O)C=O HEYJIJWKSGKYTQ-JGWLITMVSA-N 0.000 description 1
- LGNCNVVZCUVPOT-FUVGGWJZSA-N (2s)-2-[[(2r,3r)-3-[(2s)-1-[(3r,4s,5s)-4-[[(2s)-2-[[(2s)-2-(dimethylamino)-3-methylbutanoyl]amino]-3-methylbutanoyl]-methylamino]-3-methoxy-5-methylheptanoyl]pyrrolidin-2-yl]-3-methoxy-2-methylpropanoyl]amino]-3-phenylpropanoic acid Chemical compound CC(C)[C@H](N(C)C)C(=O)N[C@@H](C(C)C)C(=O)N(C)[C@@H]([C@@H](C)CC)[C@H](OC)CC(=O)N1CCC[C@H]1[C@H](OC)[C@@H](C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 LGNCNVVZCUVPOT-FUVGGWJZSA-N 0.000 description 1
- ITOFPJRDSCGOSA-KZLRUDJFSA-N (2s)-2-[[(4r)-4-[(3r,5r,8r,9s,10s,13r,14s,17r)-3-hydroxy-10,13-dimethyl-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-17-yl]pentanoyl]amino]-3-(1h-indol-3-yl)propanoic acid Chemical compound C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H](CC[C@]13C)[C@@H]2[C@@H]3CC[C@@H]1[C@H](C)CCC(=O)N[C@H](C(O)=O)CC1=CNC2=CC=CC=C12 ITOFPJRDSCGOSA-KZLRUDJFSA-N 0.000 description 1
- STBLNCCBQMHSRC-BATDWUPUSA-N (2s)-n-[(3s,4s)-5-acetyl-7-cyano-4-methyl-1-[(2-methylnaphthalen-1-yl)methyl]-2-oxo-3,4-dihydro-1,5-benzodiazepin-3-yl]-2-(methylamino)propanamide Chemical compound O=C1[C@@H](NC(=O)[C@H](C)NC)[C@H](C)N(C(C)=O)C2=CC(C#N)=CC=C2N1CC1=C(C)C=CC2=CC=CC=C12 STBLNCCBQMHSRC-BATDWUPUSA-N 0.000 description 1
- ULECDJXUFCGDIS-OKMMGKLZSA-N (3R,4R,5R)-6-azido-N-(2-azidoacetyl)-3,4,5-trihydroxyhexanamide Chemical compound N(=[N+]=[N-])C[C@H]([C@@H]([C@@H](CC(=O)NC(CN=[N+]=[N-])=O)O)O)O ULECDJXUFCGDIS-OKMMGKLZSA-N 0.000 description 1
- ULECDJXUFCGDIS-LRMHIPNDSA-N (3R,4S,5R)-6-azido-N-(2-azidoacetyl)-3,4,5-trihydroxyhexanamide Chemical compound N(=[N+]=[N-])C[C@H]([C@H]([C@@H](CC(=O)NC(CN=[N+]=[N-])=O)O)O)O ULECDJXUFCGDIS-LRMHIPNDSA-N 0.000 description 1
- MDAGZUURIZAVTG-LRMHIPNDSA-N (3R,4S,5R)-N-(2-azidoacetyl)-3,4,5,6-tetrahydroxyhexanamide Chemical compound N(=[N+]=[N-])CC(=O)NC(=O)C[C@@H](O)[C@H](O)[C@H](O)CO MDAGZUURIZAVTG-LRMHIPNDSA-N 0.000 description 1
- ICBDBDHORHIJHW-IWSPIJDZSA-N (6r,7r,8r)-6,7,8,9-tetrahydroxynonane-2,4-dione Chemical group CC(=O)CC(=O)C[C@@H](O)[C@@H](O)[C@H](O)CO ICBDBDHORHIJHW-IWSPIJDZSA-N 0.000 description 1
- 125000000229 (C1-C4)alkoxy group Chemical group 0.000 description 1
- 229920002818 (Hydroxyethyl)methacrylate Polymers 0.000 description 1
- 125000003088 (fluoren-9-ylmethoxy)carbonyl group Chemical group 0.000 description 1
- ZDTVBVUHESZSGN-UHFFFAOYSA-N 1,1-diaminoethanol Chemical compound CC(N)(N)O ZDTVBVUHESZSGN-UHFFFAOYSA-N 0.000 description 1
- QBPPRVHXOZRESW-UHFFFAOYSA-N 1,4,7,10-tetraazacyclododecane Chemical compound C1CNCCNCCNCCN1 QBPPRVHXOZRESW-UHFFFAOYSA-N 0.000 description 1
- ITWBWJFEJCHKSN-UHFFFAOYSA-N 1,4,7-triazonane Chemical compound C1CNCCNCCN1 ITWBWJFEJCHKSN-UHFFFAOYSA-N 0.000 description 1
- LMDZBCPBFSXMTL-UHFFFAOYSA-N 1-Ethyl-3-(3-dimethylaminopropyl)carbodiimide Substances CCN=C=NCCCN(C)C LMDZBCPBFSXMTL-UHFFFAOYSA-N 0.000 description 1
- QXOGPTXQGKQSJT-UHFFFAOYSA-N 1-amino-4-[4-(3,4-dimethylphenyl)sulfanylanilino]-9,10-dioxoanthracene-2-sulfonic acid Chemical compound Cc1ccc(Sc2ccc(Nc3cc(c(N)c4C(=O)c5ccccc5C(=O)c34)S(O)(=O)=O)cc2)cc1C QXOGPTXQGKQSJT-UHFFFAOYSA-N 0.000 description 1
- QRZUPJILJVGUFF-UHFFFAOYSA-N 2,8-dibenzylcyclooctan-1-one Chemical compound C1CCCCC(CC=2C=CC=CC=2)C(=O)C1CC1=CC=CC=C1 QRZUPJILJVGUFF-UHFFFAOYSA-N 0.000 description 1
- ANOJXMUSDYSKET-UHFFFAOYSA-N 2-[2-[2-(2-aminoethoxy)ethoxy]ethoxy]ethanol Chemical compound NCCOCCOCCOCCO ANOJXMUSDYSKET-UHFFFAOYSA-N 0.000 description 1
- JHALWMSZGCVVEM-UHFFFAOYSA-N 2-[4,7-bis(carboxymethyl)-1,4,7-triazonan-1-yl]acetic acid Chemical compound OC(=O)CN1CCN(CC(O)=O)CCN(CC(O)=O)CC1 JHALWMSZGCVVEM-UHFFFAOYSA-N 0.000 description 1
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- MSWZFWKMSRAUBD-IVMDWMLBSA-N 2-amino-2-deoxy-D-glucopyranose Chemical compound N[C@H]1C(O)O[C@H](CO)[C@@H](O)[C@@H]1O MSWZFWKMSRAUBD-IVMDWMLBSA-N 0.000 description 1
- YSUIQYOGTINQIN-UZFYAQMZSA-N 2-amino-9-[(1S,6R,8R,9S,10R,15R,17R,18R)-8-(6-aminopurin-9-yl)-9,18-difluoro-3,12-dihydroxy-3,12-bis(sulfanylidene)-2,4,7,11,13,16-hexaoxa-3lambda5,12lambda5-diphosphatricyclo[13.2.1.06,10]octadecan-17-yl]-1H-purin-6-one Chemical compound NC1=NC2=C(N=CN2[C@@H]2O[C@@H]3COP(S)(=O)O[C@@H]4[C@@H](COP(S)(=O)O[C@@H]2[C@@H]3F)O[C@H]([C@H]4F)N2C=NC3=C2N=CN=C3N)C(=O)N1 YSUIQYOGTINQIN-UZFYAQMZSA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- LFOIDLOIBZFWDO-UHFFFAOYSA-N 2-methoxy-6-[6-methoxy-4-[(3-phenylmethoxyphenyl)methoxy]-1-benzofuran-2-yl]imidazo[2,1-b][1,3,4]thiadiazole Chemical compound N1=C2SC(OC)=NN2C=C1C(OC1=CC(OC)=C2)=CC1=C2OCC(C=1)=CC=CC=1OCC1=CC=CC=C1 LFOIDLOIBZFWDO-UHFFFAOYSA-N 0.000 description 1
- FPQQSJJWHUJYPU-UHFFFAOYSA-N 3-(dimethylamino)propyliminomethylidene-ethylazanium;chloride Chemical compound Cl.CCN=C=NCCCN(C)C FPQQSJJWHUJYPU-UHFFFAOYSA-N 0.000 description 1
- WFOVEDJTASPCIR-UHFFFAOYSA-N 3-[(4-methyl-5-pyridin-4-yl-1,2,4-triazol-3-yl)methylamino]-n-[[2-(trifluoromethyl)phenyl]methyl]benzamide Chemical compound N=1N=C(C=2C=CN=CC=2)N(C)C=1CNC(C=1)=CC=CC=1C(=O)NCC1=CC=CC=C1C(F)(F)F WFOVEDJTASPCIR-UHFFFAOYSA-N 0.000 description 1
- ZAEFNUJIMGOKEC-UHFFFAOYSA-N 3-azidocyclooctyne Chemical compound [N-]=[N+]=NC1CCCCCC#C1 ZAEFNUJIMGOKEC-UHFFFAOYSA-N 0.000 description 1
- OSWFIVFLDKOXQC-UHFFFAOYSA-N 4-(3-methoxyphenyl)aniline Chemical compound COC1=CC=CC(C=2C=CC(N)=CC=2)=C1 OSWFIVFLDKOXQC-UHFFFAOYSA-N 0.000 description 1
- MPMKMQHJHDHPBE-RUZDIDTESA-N 4-[[(2r)-1-(1-benzothiophene-3-carbonyl)-2-methylazetidine-2-carbonyl]-[(3-chlorophenyl)methyl]amino]butanoic acid Chemical compound O=C([C@@]1(N(CC1)C(=O)C=1C2=CC=CC=C2SC=1)C)N(CCCC(O)=O)CC1=CC=CC(Cl)=C1 MPMKMQHJHDHPBE-RUZDIDTESA-N 0.000 description 1
- 229960000549 4-dimethylaminophenol Drugs 0.000 description 1
- JLJZRAUDCHWQPS-YKVPTUPCSA-N 4-oxo-N-[(3R,4R,5R,6R)-2,4,5-trihydroxy-6-(hydroxymethyl)oxan-3-yl]pentanamide Chemical compound O=C(CCC(=O)N[C@H]1C(O)O[C@@H]([C@@H]([C@@H]1O)O)CO)C JLJZRAUDCHWQPS-YKVPTUPCSA-N 0.000 description 1
- LQGKDMHENBFVRC-UHFFFAOYSA-N 5-aminopentan-1-ol Chemical compound NCCCCCO LQGKDMHENBFVRC-UHFFFAOYSA-N 0.000 description 1
- XFJBGINZIMNZBW-CRAIPNDOSA-N 5-chloro-2-[4-[(1r,2s)-2-[2-(5-methylsulfonylpyridin-2-yl)oxyethyl]cyclopropyl]piperidin-1-yl]pyrimidine Chemical compound N1=CC(S(=O)(=O)C)=CC=C1OCC[C@H]1[C@@H](C2CCN(CC2)C=2N=CC(Cl)=CN=2)C1 XFJBGINZIMNZBW-CRAIPNDOSA-N 0.000 description 1
- MJZJYWCQPMNPRM-UHFFFAOYSA-N 6,6-dimethyl-1-[3-(2,4,5-trichlorophenoxy)propoxy]-1,6-dihydro-1,3,5-triazine-2,4-diamine Chemical compound CC1(C)N=C(N)N=C(N)N1OCCCOC1=CC(Cl)=C(Cl)C=C1Cl MJZJYWCQPMNPRM-UHFFFAOYSA-N 0.000 description 1
- RSIWALKZYXPAGW-NSHDSACASA-N 6-(3-fluorophenyl)-3-methyl-7-[(1s)-1-(7h-purin-6-ylamino)ethyl]-[1,3]thiazolo[3,2-a]pyrimidin-5-one Chemical compound C=1([C@@H](NC=2C=3N=CNC=3N=CN=2)C)N=C2SC=C(C)N2C(=O)C=1C1=CC=CC(F)=C1 RSIWALKZYXPAGW-NSHDSACASA-N 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-M Acrylate Chemical compound [O-]C(=O)C=C NIXOWILDQLNWCW-UHFFFAOYSA-M 0.000 description 1
- 229930024421 Adenine Natural products 0.000 description 1
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 1
- 229920000936 Agarose Polymers 0.000 description 1
- 239000012099 Alexa Fluor family Substances 0.000 description 1
- QGZKDVFQNNGYKY-UHFFFAOYSA-O Ammonium Chemical compound [NH4+] QGZKDVFQNNGYKY-UHFFFAOYSA-O 0.000 description 1
- 108010053481 Antifreeze Proteins Proteins 0.000 description 1
- 101100330723 Arabidopsis thaliana DAR2 gene Proteins 0.000 description 1
- 101100330725 Arabidopsis thaliana DAR4 gene Proteins 0.000 description 1
- 208000031648 Body Weight Changes Diseases 0.000 description 1
- 102100025441 Brother of CDO Human genes 0.000 description 1
- 125000000882 C2-C6 alkenyl group Chemical group 0.000 description 1
- 125000003601 C2-C6 alkynyl group Chemical group 0.000 description 1
- XMWRBQBLMFGWIX-UHFFFAOYSA-N C60 fullerene Chemical compound C12=C3C(C4=C56)=C7C8=C5C5=C9C%10=C6C6=C4C1=C1C4=C6C6=C%10C%10=C9C9=C%11C5=C8C5=C8C7=C3C3=C7C2=C1C1=C2C4=C6C4=C%10C6=C9C9=C%11C5=C5C8=C3C3=C7C1=C1C2=C4C6=C2C9=C5C3=C12 XMWRBQBLMFGWIX-UHFFFAOYSA-N 0.000 description 1
- KCBAMQOKOLXLOX-BSZYMOERSA-N CC1=C(SC=N1)C2=CC=C(C=C2)[C@H](C)NC(=O)[C@@H]3C[C@H](CN3C(=O)[C@H](C(C)(C)C)NC(=O)CCCCCCCCCCNCCCONC(=O)C4=C(C(=C(C=C4)F)F)NC5=C(C=C(C=C5)I)F)O Chemical compound CC1=C(SC=N1)C2=CC=C(C=C2)[C@H](C)NC(=O)[C@@H]3C[C@H](CN3C(=O)[C@H](C(C)(C)C)NC(=O)CCCCCCCCCCNCCCONC(=O)C4=C(C(=C(C=C4)F)F)NC5=C(C=C(C=C5)I)F)O KCBAMQOKOLXLOX-BSZYMOERSA-N 0.000 description 1
- UHNRLQRZRNKOKU-UHFFFAOYSA-N CCN(CC1=NC2=C(N1)C1=CC=C(C=C1N=C2N)C1=NNC=C1)C(C)=O Chemical compound CCN(CC1=NC2=C(N1)C1=CC=C(C=C1N=C2N)C1=NNC=C1)C(C)=O UHNRLQRZRNKOKU-UHFFFAOYSA-N 0.000 description 1
- 101100454807 Caenorhabditis elegans lgg-1 gene Proteins 0.000 description 1
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 description 1
- 241000222120 Candida <Saccharomycetales> Species 0.000 description 1
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 1
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 1
- VYZAMTAEIAYCRO-UHFFFAOYSA-N Chromium Chemical compound [Cr] VYZAMTAEIAYCRO-UHFFFAOYSA-N 0.000 description 1
- KRKNYBCHXYNGOX-UHFFFAOYSA-K Citrate Chemical compound [O-]C(=O)CC(O)(CC([O-])=O)C([O-])=O KRKNYBCHXYNGOX-UHFFFAOYSA-K 0.000 description 1
- 102100026735 Coagulation factor VIII Human genes 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- FEWJPZIEWOKRBE-JCYAYHJZSA-N Dextrotartaric acid Chemical compound OC(=O)[C@H](O)[C@@H](O)C(O)=O FEWJPZIEWOKRBE-JCYAYHJZSA-N 0.000 description 1
- 238000006117 Diels-Alder cycloaddition reaction Methods 0.000 description 1
- PGJBQBDNXAZHBP-UHFFFAOYSA-N Dimefox Chemical compound CN(C)P(F)(=O)N(C)C PGJBQBDNXAZHBP-UHFFFAOYSA-N 0.000 description 1
- GKQLYSROISKDLL-UHFFFAOYSA-N EEDQ Chemical compound C1=CC=C2N(C(=O)OCC)C(OCC)C=CC2=C1 GKQLYSROISKDLL-UHFFFAOYSA-N 0.000 description 1
- IAYPIBMASNFSPL-UHFFFAOYSA-N Ethylene oxide Chemical compound C1CO1 IAYPIBMASNFSPL-UHFFFAOYSA-N 0.000 description 1
- BDAGIHXWWSANSR-UHFFFAOYSA-M Formate Chemical compound [O-]C=O BDAGIHXWWSANSR-UHFFFAOYSA-M 0.000 description 1
- GYHNNYVSQQEPJS-UHFFFAOYSA-N Gallium Chemical compound [Ga] GYHNNYVSQQEPJS-UHFFFAOYSA-N 0.000 description 1
- 102000053187 Glucuronidase Human genes 0.000 description 1
- 108010060309 Glucuronidase Proteins 0.000 description 1
- HVLSXIKZNLPZJJ-TXZCQADKSA-N HA peptide Chemical compound C([C@@H](C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC=1C=CC(O)=CC=1)C(=O)N[C@@H](C)C(O)=O)NC(=O)[C@H]1N(CCC1)C(=O)[C@@H](N)CC=1C=CC(O)=CC=1)C1=CC=C(O)C=C1 HVLSXIKZNLPZJJ-TXZCQADKSA-N 0.000 description 1
- 239000007995 HEPES buffer Substances 0.000 description 1
- 101000911390 Homo sapiens Coagulation factor VIII Proteins 0.000 description 1
- 101000798114 Homo sapiens Lactotransferrin Proteins 0.000 description 1
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 1
- CPELXLSAUQHCOX-UHFFFAOYSA-N Hydrogen bromide Chemical compound Br CPELXLSAUQHCOX-UHFFFAOYSA-N 0.000 description 1
- AVXURJPOCDRRFD-UHFFFAOYSA-N Hydroxylamine Chemical compound ON AVXURJPOCDRRFD-UHFFFAOYSA-N 0.000 description 1
- LCWXJXMHJVIJFK-UHFFFAOYSA-N Hydroxylysine Natural products NCC(O)CC(N)CC(O)=O LCWXJXMHJVIJFK-UHFFFAOYSA-N 0.000 description 1
- PMMYEEVYMWASQN-DMTCNVIQSA-N Hydroxyproline Chemical compound O[C@H]1CN[C@H](C(O)=O)C1 PMMYEEVYMWASQN-DMTCNVIQSA-N 0.000 description 1
- 102000018071 Immunoglobulin Fc Fragments Human genes 0.000 description 1
- 108010091135 Immunoglobulin Fc Fragments Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 229930194542 Keto Natural products 0.000 description 1
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- 239000004367 Lipase Substances 0.000 description 1
- 102000004882 Lipase Human genes 0.000 description 1
- 108090001060 Lipase Proteins 0.000 description 1
- 241000124008 Mammalia Species 0.000 description 1
- 102100037510 Metallothionein-1E Human genes 0.000 description 1
- AFVFQIVMOAPDHO-UHFFFAOYSA-N Methanesulfonic acid Chemical compound CS(O)(=O)=O AFVFQIVMOAPDHO-UHFFFAOYSA-N 0.000 description 1
- 238000006845 Michael addition reaction Methods 0.000 description 1
- 102000016943 Muramidase Human genes 0.000 description 1
- 108010014251 Muramidase Proteins 0.000 description 1
- QPCDCPDFJACHGM-UHFFFAOYSA-N N,N-bis{2-[bis(carboxymethyl)amino]ethyl}glycine Chemical compound OC(=O)CN(CC(O)=O)CCN(CC(=O)O)CCN(CC(O)=O)CC(O)=O QPCDCPDFJACHGM-UHFFFAOYSA-N 0.000 description 1
- 108010062010 N-Acetylmuramoyl-L-alanine Amidase Proteins 0.000 description 1
- RPJMPMDUKSRLLF-QNRYFBKSSA-N N-[(3R,4R,5R,6R)-2,4,5-trihydroxy-6-(hydroxymethyl)oxan-3-yl]butanamide Chemical compound CCCC(=O)N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O RPJMPMDUKSRLLF-QNRYFBKSSA-N 0.000 description 1
- RTEOJYOKWPEKKN-HXQZNRNWSA-N N-[(3R,4R,5R,6R)-2,4,5-trihydroxy-6-(hydroxymethyl)oxan-3-yl]propanamide Chemical compound CCC(=O)N[C@H]1C(O)O[C@H](CO)[C@H](O)[C@@H]1O RTEOJYOKWPEKKN-HXQZNRNWSA-N 0.000 description 1
- MNLRQHMNZILYPY-MKFCKLDKSA-N N-acetyl-D-muramic acid Chemical compound OC(=O)[C@@H](C)O[C@H]1[C@H](O)[C@@H](CO)OC(O)[C@@H]1NC(C)=O MNLRQHMNZILYPY-MKFCKLDKSA-N 0.000 description 1
- MNLRQHMNZILYPY-MDMHTWEWSA-N N-acetyl-alpha-D-muramic acid Chemical compound OC(=O)[C@@H](C)O[C@H]1[C@H](O)[C@@H](CO)O[C@H](O)[C@@H]1NC(C)=O MNLRQHMNZILYPY-MDMHTWEWSA-N 0.000 description 1
- UBQYURCVBFRUQT-UHFFFAOYSA-N N-benzoyl-Ferrioxamine B Chemical compound CC(=O)N(O)CCCCCNC(=O)CCC(=O)N(O)CCCCCNC(=O)CCC(=O)N(O)CCCCCN UBQYURCVBFRUQT-UHFFFAOYSA-N 0.000 description 1
- 230000004988 N-glycosylation Effects 0.000 description 1
- 108091028043 Nucleic acid sequence Proteins 0.000 description 1
- GHOKXCNQLUWANE-BTTYYORXSA-N OCCOCCNS(NC(OC[C@@H]1[C@H]2[C@@H]1CCC=CCC2)=O)(=O)=O Chemical compound OCCOCCNS(NC(OC[C@@H]1[C@H]2[C@@H]1CCC=CCC2)=O)(=O)=O GHOKXCNQLUWANE-BTTYYORXSA-N 0.000 description 1
- MUBZPKHOEPUJKR-UHFFFAOYSA-N Oxalic acid Chemical compound OC(=O)C(O)=O MUBZPKHOEPUJKR-UHFFFAOYSA-N 0.000 description 1
- 108091006006 PEGylated Proteins Proteins 0.000 description 1
- 229910019142 PO4 Inorganic materials 0.000 description 1
- 229910052778 Plutonium Inorganic materials 0.000 description 1
- 239000004698 Polyethylene Substances 0.000 description 1
- 239000004743 Polypropylene Substances 0.000 description 1
- 108010026552 Proteome Proteins 0.000 description 1
- 238000003514 Retro-Michael reaction Methods 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- 108020004459 Small interfering RNA Proteins 0.000 description 1
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 1
- 239000005864 Sulphur Substances 0.000 description 1
- WDLRUFUQRNWCPK-UHFFFAOYSA-N Tetraxetan Chemical compound OC(=O)CN1CCN(CC(O)=O)CCN(CC(O)=O)CCN(CC(O)=O)CC1 WDLRUFUQRNWCPK-UHFFFAOYSA-N 0.000 description 1
- 101800001690 Transmembrane protein gp41 Proteins 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 101710090322 Truncated surface protein Proteins 0.000 description 1
- 229910052770 Uranium Inorganic materials 0.000 description 1
- DRTQHJPVMGBUCF-XVFCMESISA-N Uridine Natural products O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-XVFCMESISA-N 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- QCWXUUIWCKQGHC-UHFFFAOYSA-N Zirconium Chemical compound [Zr] QCWXUUIWCKQGHC-UHFFFAOYSA-N 0.000 description 1
- NSVXZMGWYBICRW-ULKQDVFKSA-N [(1s,8r)-9-bicyclo[6.1.0]non-4-ynyl]methanol Chemical compound C1CC#CCC[C@@H]2C(CO)[C@@H]21 NSVXZMGWYBICRW-ULKQDVFKSA-N 0.000 description 1
- USMYACISHVPTHK-PXLJZGITSA-N [4-[[(2s)-5-(carbamoylamino)-2-[[(2s)-2-(9h-fluoren-9-ylmethoxycarbonylamino)-3-methylbutanoyl]amino]pentanoyl]amino]phenyl]methyl (4-nitrophenyl) carbonate Chemical compound O=C([C@H](CCCNC(N)=O)NC(=O)[C@@H](NC(=O)OCC1C2=CC=CC=C2C2=CC=CC=C21)C(C)C)NC(C=C1)=CC=C1COC(=O)OC1=CC=C([N+]([O-])=O)C=C1 USMYACISHVPTHK-PXLJZGITSA-N 0.000 description 1
- SMNRFWMNPDABKZ-WVALLCKVSA-N [[(2R,3S,4R,5S)-5-(2,6-dioxo-3H-pyridin-3-yl)-3,4-dihydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl] [[[(2R,3S,4S,5R,6R)-4-fluoro-3,5-dihydroxy-6-(hydroxymethyl)oxan-2-yl]oxy-hydroxyphosphoryl]oxy-hydroxyphosphoryl] hydrogen phosphate Chemical compound OC[C@H]1O[C@H](OP(O)(=O)OP(O)(=O)OP(O)(=O)OP(O)(=O)OC[C@H]2O[C@H]([C@H](O)[C@@H]2O)C2C=CC(=O)NC2=O)[C@H](O)[C@@H](F)[C@@H]1O SMNRFWMNPDABKZ-WVALLCKVSA-N 0.000 description 1
- 229960000446 abciximab Drugs 0.000 description 1
- 125000002336 acetylhydrazino group Chemical group [H]N([*])N([H])C(=O)C([H])([H])[H] 0.000 description 1
- 230000002378 acidificating effect Effects 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- 230000004913 activation Effects 0.000 description 1
- 125000002252 acyl group Chemical group 0.000 description 1
- 125000004423 acyloxy group Chemical group 0.000 description 1
- 229960002964 adalimumab Drugs 0.000 description 1
- 229960000643 adenine Drugs 0.000 description 1
- 235000004279 alanine Nutrition 0.000 description 1
- 238000005575 aldol reaction Methods 0.000 description 1
- 229960000548 alemtuzumab Drugs 0.000 description 1
- 125000005262 alkoxyamine group Chemical group 0.000 description 1
- 108010004469 allophycocyanin Proteins 0.000 description 1
- 239000000956 alloy Substances 0.000 description 1
- 229910045601 alloy Inorganic materials 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- HSFWRNGVRCDJHI-UHFFFAOYSA-N alpha-acetylene Natural products C#C HSFWRNGVRCDJHI-UHFFFAOYSA-N 0.000 description 1
- 239000004411 aluminium Substances 0.000 description 1
- 229910052782 aluminium Inorganic materials 0.000 description 1
- XAGFODPZIPBFFR-UHFFFAOYSA-N aluminium Chemical compound [Al] XAGFODPZIPBFFR-UHFFFAOYSA-N 0.000 description 1
- PNEYBMLMFCGWSK-UHFFFAOYSA-N aluminium oxide Inorganic materials [O-2].[O-2].[O-2].[Al+3].[Al+3] PNEYBMLMFCGWSK-UHFFFAOYSA-N 0.000 description 1
- 238000010976 amide bond formation reaction Methods 0.000 description 1
- HAMNKKUPIHEESI-UHFFFAOYSA-N aminoguanidine Chemical compound NNC(N)=N HAMNKKUPIHEESI-UHFFFAOYSA-N 0.000 description 1
- 125000002344 aminooxy group Chemical group [H]N([H])O[*] 0.000 description 1
- 238000004873 anchoring Methods 0.000 description 1
- 150000008064 anhydrides Chemical class 0.000 description 1
- 125000000129 anionic group Chemical group 0.000 description 1
- 230000000890 antigenic effect Effects 0.000 description 1
- 239000012736 aqueous medium Substances 0.000 description 1
- 125000004104 aryloxy group Chemical group 0.000 description 1
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 1
- 238000010461 azide-alkyne cycloaddition reaction Methods 0.000 description 1
- 244000052616 bacterial pathogen Species 0.000 description 1
- 229960004669 basiliximab Drugs 0.000 description 1
- 229960003270 belimumab Drugs 0.000 description 1
- SRSXLGNVWSONIS-UHFFFAOYSA-M benzenesulfonate Chemical compound [O-]S(=O)(=O)C1=CC=CC=C1 SRSXLGNVWSONIS-UHFFFAOYSA-M 0.000 description 1
- 125000000499 benzofuranyl group Chemical group O1C(=CC2=C1C=CC=C2)* 0.000 description 1
- 125000004541 benzoxazolyl group Chemical group O1C(=NC2=C1C=CC=C2)* 0.000 description 1
- 125000001797 benzyl group Chemical group [H]C1=C([H])C([H])=C(C([H])=C1[H])C([H])([H])* 0.000 description 1
- 125000001584 benzyloxycarbonyl group Chemical group C(=O)(OCC1=CC=CC=C1)* 0.000 description 1
- 235000021028 berry Nutrition 0.000 description 1
- DRTQHJPVMGBUCF-PSQAKQOGSA-N beta-L-uridine Natural products O[C@H]1[C@@H](O)[C@H](CO)O[C@@H]1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-PSQAKQOGSA-N 0.000 description 1
- 229960000397 bevacizumab Drugs 0.000 description 1
- 230000001588 bifunctional effect Effects 0.000 description 1
- ACBQROXDOHKANW-UHFFFAOYSA-N bis(4-nitrophenyl) carbonate Chemical compound C1=CC([N+](=O)[O-])=CC=C1OC(=O)OC1=CC=C([N+]([O-])=O)C=C1 ACBQROXDOHKANW-UHFFFAOYSA-N 0.000 description 1
- 229910052797 bismuth Inorganic materials 0.000 description 1
- JCXGWMGPZLAOME-UHFFFAOYSA-N bismuth atom Chemical compound [Bi] JCXGWMGPZLAOME-UHFFFAOYSA-N 0.000 description 1
- 230000004579 body weight change Effects 0.000 description 1
- 229960000455 brentuximab vedotin Drugs 0.000 description 1
- 239000012267 brine Substances 0.000 description 1
- 239000007975 buffered saline Substances 0.000 description 1
- 239000006227 byproduct Substances 0.000 description 1
- 239000011575 calcium Substances 0.000 description 1
- 229910052791 calcium Inorganic materials 0.000 description 1
- 229930195731 calicheamicin Natural products 0.000 description 1
- 229960001838 canakinumab Drugs 0.000 description 1
- 210000000234 capsid Anatomy 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 150000001721 carbon Chemical group 0.000 description 1
- 239000002041 carbon nanotube Substances 0.000 description 1
- 229910021393 carbon nanotube Inorganic materials 0.000 description 1
- 150000004649 carbonic acid derivatives Chemical class 0.000 description 1
- 229960000419 catumaxomab Drugs 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 229960003115 certolizumab pegol Drugs 0.000 description 1
- 229960005395 cetuximab Drugs 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 229910052804 chromium Inorganic materials 0.000 description 1
- 239000011651 chromium Substances 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 229910017052 cobalt Inorganic materials 0.000 description 1
- 239000010941 cobalt Substances 0.000 description 1
- GUTLYIVDDKVIGB-UHFFFAOYSA-N cobalt atom Chemical compound [Co] GUTLYIVDDKVIGB-UHFFFAOYSA-N 0.000 description 1
- 229940125810 compound 20 Drugs 0.000 description 1
- 229940125833 compound 23 Drugs 0.000 description 1
- 229940125878 compound 36 Drugs 0.000 description 1
- 229940125807 compound 37 Drugs 0.000 description 1
- 229940127573 compound 38 Drugs 0.000 description 1
- 230000001010 compromised effect Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 239000002872 contrast media Substances 0.000 description 1
- 239000012043 crude product Substances 0.000 description 1
- 125000006165 cyclic alkyl group Chemical group 0.000 description 1
- 125000001995 cyclobutyl group Chemical group [H]C1([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 125000000113 cyclohexyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C([H])([H])C1([H])[H] 0.000 description 1
- 125000001511 cyclopentyl group Chemical group [H]C1([H])C([H])([H])C([H])([H])C([H])(*)C1([H])[H] 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 229960000958 deferoxamine Drugs 0.000 description 1
- 230000022811 deglycosylation Effects 0.000 description 1
- YSMODUONRAFBET-UHFFFAOYSA-N delta-DL-hydroxylysine Natural products NCC(O)CCC(N)C(O)=O YSMODUONRAFBET-UHFFFAOYSA-N 0.000 description 1
- 238000004925 denaturation Methods 0.000 description 1
- 230000036425 denaturation Effects 0.000 description 1
- 229960001251 denosumab Drugs 0.000 description 1
- 238000010511 deprotection reaction Methods 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- 239000003599 detergent Substances 0.000 description 1
- 150000008049 diazo compounds Chemical class 0.000 description 1
- 238000009792 diffusion process Methods 0.000 description 1
- 230000029087 digestion Effects 0.000 description 1
- 238000010790 dilution Methods 0.000 description 1
- 239000012895 dilution Substances 0.000 description 1
- 239000000539 dimer Substances 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- PMMYEEVYMWASQN-UHFFFAOYSA-N dl-hydroxyproline Natural products OC1C[NH2+]C(C([O-])=O)C1 PMMYEEVYMWASQN-UHFFFAOYSA-N 0.000 description 1
- 238000012377 drug delivery Methods 0.000 description 1
- 238000007876 drug discovery Methods 0.000 description 1
- 229960002224 eculizumab Drugs 0.000 description 1
- 238000000132 electrospray ionisation Methods 0.000 description 1
- 230000009088 enzymatic function Effects 0.000 description 1
- YSMODUONRAFBET-UHNVWZDZSA-N erythro-5-hydroxy-L-lysine Chemical compound NC[C@H](O)CC[C@H](N)C(O)=O YSMODUONRAFBET-UHNVWZDZSA-N 0.000 description 1
- STVZJERGLQHEKB-UHFFFAOYSA-N ethylene glycol dimethacrylate Chemical compound CC(=C)C(=O)OCCOC(=O)C(C)=C STVZJERGLQHEKB-UHFFFAOYSA-N 0.000 description 1
- 125000002534 ethynyl group Chemical group [H]C#C* 0.000 description 1
- 239000000284 extract Substances 0.000 description 1
- 238000000605 extraction Methods 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000019253 formic acid Nutrition 0.000 description 1
- 125000002485 formyl group Chemical group [H]C(*)=O 0.000 description 1
- 229910003472 fullerene Inorganic materials 0.000 description 1
- 230000006870 function Effects 0.000 description 1
- 125000002541 furyl group Chemical group 0.000 description 1
- 229910052733 gallium Inorganic materials 0.000 description 1
- 239000000499 gel Substances 0.000 description 1
- 230000030279 gene silencing Effects 0.000 description 1
- 238000012226 gene silencing method Methods 0.000 description 1
- 229960002442 glucosamine Drugs 0.000 description 1
- 229960001743 golimumab Drugs 0.000 description 1
- 238000010559 graft polymerization reaction Methods 0.000 description 1
- 238000006077 hetero Diels-Alder cycloaddition reaction Methods 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 102000050459 human LTF Human genes 0.000 description 1
- 125000000717 hydrazino group Chemical group [H]N([*])N([H])[H] 0.000 description 1
- 150000007857 hydrazones Chemical class 0.000 description 1
- 229930195733 hydrocarbon Natural products 0.000 description 1
- 150000002430 hydrocarbons Chemical class 0.000 description 1
- 230000007062 hydrolysis Effects 0.000 description 1
- 238000006460 hydrolysis reaction Methods 0.000 description 1
- QJHBJHUKURJDLG-UHFFFAOYSA-N hydroxy-L-lysine Natural products NCCCCC(NO)C(O)=O QJHBJHUKURJDLG-UHFFFAOYSA-N 0.000 description 1
- 125000002349 hydroxyamino group Chemical group [H]ON([H])[*] 0.000 description 1
- 150000002443 hydroxylamines Chemical class 0.000 description 1
- 229960002591 hydroxyproline Drugs 0.000 description 1
- 239000012216 imaging agent Substances 0.000 description 1
- 125000002883 imidazolyl group Chemical group 0.000 description 1
- 210000000987 immune system Anatomy 0.000 description 1
- 230000005847 immunogenicity Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 238000010348 incorporation Methods 0.000 description 1
- 229910052738 indium Inorganic materials 0.000 description 1
- APFVFJFRJDLVQX-UHFFFAOYSA-N indium atom Chemical compound [In] APFVFJFRJDLVQX-UHFFFAOYSA-N 0.000 description 1
- 125000001041 indolyl group Chemical group 0.000 description 1
- 230000006698 induction Effects 0.000 description 1
- 229960000598 infliximab Drugs 0.000 description 1
- 238000011081 inoculation Methods 0.000 description 1
- 150000007529 inorganic bases Chemical class 0.000 description 1
- 150000002500 ions Chemical class 0.000 description 1
- 229960005386 ipilimumab Drugs 0.000 description 1
- 229910052742 iron Inorganic materials 0.000 description 1
- 125000000555 isopropenyl group Chemical group [H]\C([H])=C(\*)C([H])([H])[H] 0.000 description 1
- BPHPUYQFMNQIOC-NXRLNHOXSA-N isopropyl beta-D-thiogalactopyranoside Chemical compound CC(C)S[C@@H]1O[C@H](CO)[C@H](O)[C@H](O)[C@H]1O BPHPUYQFMNQIOC-NXRLNHOXSA-N 0.000 description 1
- 239000003446 ligand Substances 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 235000019421 lipase Nutrition 0.000 description 1
- 150000002634 lipophilic molecules Chemical class 0.000 description 1
- 239000004325 lysozyme Substances 0.000 description 1
- 235000010335 lysozyme Nutrition 0.000 description 1
- 229960000274 lysozyme Drugs 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- 201000004792 malaria Diseases 0.000 description 1
- VZCYOOQTPOCHFL-UPHRSURJSA-N maleic acid Chemical compound OC(=O)\C=C/C(O)=O VZCYOOQTPOCHFL-UPHRSURJSA-N 0.000 description 1
- 239000000463 material Substances 0.000 description 1
- QSHDDOUJBYECFT-UHFFFAOYSA-N mercury Chemical compound [Hg] QSHDDOUJBYECFT-UHFFFAOYSA-N 0.000 description 1
- 229910052753 mercury Inorganic materials 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 229910001092 metal group alloy Inorganic materials 0.000 description 1
- 238000012775 microarray technology Methods 0.000 description 1
- 230000000116 mitigating effect Effects 0.000 description 1
- 125000001483 monosaccharide substituent group Chemical group 0.000 description 1
- 230000035772 mutation Effects 0.000 description 1
- WGFRCJXBXWPUGC-NGJRWZKOSA-N n-[(2r,3s,4r,5r)-6-azido-2,3,4,5-tetrahydroxy-1-oxohexan-2-yl]acetamide Chemical compound CC(=O)N[C@](O)(C=O)[C@@H](O)[C@H](O)[C@H](O)CN=[N+]=[N-] WGFRCJXBXWPUGC-NGJRWZKOSA-N 0.000 description 1
- HSTMUUTYHSGDKQ-NGJRWZKOSA-N n-[(2r,3s,4r,5s)-4-azido-2,3,5,6-tetrahydroxy-1-oxohexan-2-yl]acetamide Chemical compound CC(=O)N[C@](O)(C=O)[C@@H](O)[C@H](N=[N+]=[N-])[C@H](O)CO HSTMUUTYHSGDKQ-NGJRWZKOSA-N 0.000 description 1
- WGFRCJXBXWPUGC-KVPKETBZSA-N n-[(2r,3s,4s,5r)-6-azido-2,3,4,5-tetrahydroxy-1-oxohexan-2-yl]acetamide Chemical compound CC(=O)N[C@](O)(C=O)[C@@H](O)[C@@H](O)[C@H](O)CN=[N+]=[N-] WGFRCJXBXWPUGC-KVPKETBZSA-N 0.000 description 1
- HSTMUUTYHSGDKQ-KVPKETBZSA-N n-[(2r,3s,4s,5s)-4-azido-2,3,5,6-tetrahydroxy-1-oxohexan-2-yl]acetamide Chemical compound CC(=O)N[C@](O)(C=O)[C@@H](O)[C@@H](N=[N+]=[N-])[C@H](O)CO HSTMUUTYHSGDKQ-KVPKETBZSA-N 0.000 description 1
- 125000001280 n-hexyl group Chemical group C(CCCCC)* 0.000 description 1
- 239000002086 nanomaterial Substances 0.000 description 1
- 125000001624 naphthyl group Chemical group 0.000 description 1
- 229960005027 natalizumab Drugs 0.000 description 1
- 239000012299 nitrogen atmosphere Substances 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- JFNLZVQOOSMTJK-KNVOCYPGSA-N norbornene Chemical compound C1[C@@H]2CC[C@H]1C=C2 JFNLZVQOOSMTJK-KNVOCYPGSA-N 0.000 description 1
- 229960002450 ofatumumab Drugs 0.000 description 1
- 229960000470 omalizumab Drugs 0.000 description 1
- PIDFDZJZLOTZTM-KHVQSSSXSA-N ombitasvir Chemical compound COC(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@H]1C(=O)NC1=CC=C([C@H]2N([C@@H](CC2)C=2C=CC(NC(=O)[C@H]3N(CCC3)C(=O)[C@@H](NC(=O)OC)C(C)C)=CC=2)C=2C=CC(=CC=2)C(C)(C)C)C=C1 PIDFDZJZLOTZTM-KHVQSSSXSA-N 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 150000007530 organic bases Chemical class 0.000 description 1
- 150000002892 organic cations Chemical class 0.000 description 1
- 239000012074 organic phase Substances 0.000 description 1
- 125000002971 oxazolyl group Chemical group 0.000 description 1
- 150000002923 oximes Chemical class 0.000 description 1
- 125000004043 oxo group Chemical group O=* 0.000 description 1
- 239000001301 oxygen Substances 0.000 description 1
- 229960000402 palivizumab Drugs 0.000 description 1
- 229960001972 panitumumab Drugs 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- CRWVOXFUXPYTRK-UHFFFAOYSA-N pent-4-yn-1-ol Chemical compound OCCCC#C CRWVOXFUXPYTRK-UHFFFAOYSA-N 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- NBIIXXVUZAFLBC-UHFFFAOYSA-K phosphate Chemical compound [O-]P([O-])([O-])=O NBIIXXVUZAFLBC-UHFFFAOYSA-K 0.000 description 1
- 150000003003 phosphines Chemical class 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 229910000073 phosphorus hydride Inorganic materials 0.000 description 1
- 108060006184 phycobiliprotein Chemical class 0.000 description 1
- OYEHPCDNVJXUIW-UHFFFAOYSA-N plutonium atom Chemical compound [Pu] OYEHPCDNVJXUIW-UHFFFAOYSA-N 0.000 description 1
- 229920000724 poly(L-arginine) polymer Polymers 0.000 description 1
- 229920000729 poly(L-lysine) polymer Polymers 0.000 description 1
- 229920001308 poly(aminoacid) Polymers 0.000 description 1
- 229920000435 poly(dimethylsiloxane) Polymers 0.000 description 1
- 108010011110 polyarginine Proteins 0.000 description 1
- 229920000573 polyethylene Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 108091033319 polynucleotide Proteins 0.000 description 1
- 102000040430 polynucleotide Human genes 0.000 description 1
- 239000002157 polynucleotide Substances 0.000 description 1
- 229920001155 polypropylene Polymers 0.000 description 1
- 150000004804 polysaccharides Polymers 0.000 description 1
- 229920001296 polysiloxane Polymers 0.000 description 1
- 229920000915 polyvinyl chloride Polymers 0.000 description 1
- 239000004800 polyvinyl chloride Substances 0.000 description 1
- 229920002102 polyvinyl toluene Polymers 0.000 description 1
- 239000011148 porous material Substances 0.000 description 1
- 235000015320 potassium carbonate Nutrition 0.000 description 1
- 229910000027 potassium carbonate Inorganic materials 0.000 description 1
- 239000008057 potassium phosphate buffer Substances 0.000 description 1
- 239000000843 powder Substances 0.000 description 1
- HJWLCRVIBGQPNF-UHFFFAOYSA-N prop-2-enylbenzene Chemical compound C=CCC1=CC=CC=C1 HJWLCRVIBGQPNF-UHFFFAOYSA-N 0.000 description 1
- 125000004368 propenyl group Chemical group C(=CC)* 0.000 description 1
- 125000001436 propyl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 125000002568 propynyl group Chemical group [*]C#CC([H])([H])[H] 0.000 description 1
- 230000001681 protective effect Effects 0.000 description 1
- 235000004252 protein component Nutrition 0.000 description 1
- 108020001580 protein domains Proteins 0.000 description 1
- 239000008213 purified water Substances 0.000 description 1
- 125000000561 purinyl group Chemical group N1=C(N=C2N=CNC2=C1)* 0.000 description 1
- 125000003373 pyrazinyl group Chemical group 0.000 description 1
- 125000003226 pyrazolyl group Chemical group 0.000 description 1
- PBMFSQRYOILNGV-UHFFFAOYSA-N pyridazine Chemical compound C1=CC=NN=C1 PBMFSQRYOILNGV-UHFFFAOYSA-N 0.000 description 1
- UMJSCPRVCHMLSP-UHFFFAOYSA-N pyridine Natural products COC1=CC=CN=C1 UMJSCPRVCHMLSP-UHFFFAOYSA-N 0.000 description 1
- 125000000168 pyrrolyl group Chemical group 0.000 description 1
- 125000002943 quinolinyl group Chemical group N1=C(C=CC2=CC=CC=C12)* 0.000 description 1
- 229960003876 ranibizumab Drugs 0.000 description 1
- 230000035484 reaction time Effects 0.000 description 1
- 230000009257 reactivity Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- 238000007363 ring formation reaction Methods 0.000 description 1
- 229960004641 rituximab Drugs 0.000 description 1
- 238000007127 saponification reaction Methods 0.000 description 1
- 229910052706 scandium Inorganic materials 0.000 description 1
- SIXSYDAISGFNSX-UHFFFAOYSA-N scandium atom Chemical compound [Sc] SIXSYDAISGFNSX-UHFFFAOYSA-N 0.000 description 1
- 210000002966 serum Anatomy 0.000 description 1
- 239000000741 silica gel Substances 0.000 description 1
- 229910002027 silica gel Inorganic materials 0.000 description 1
- 235000010378 sodium ascorbate Nutrition 0.000 description 1
- PPASLZSBLFJQEF-RKJRWTFHSA-M sodium ascorbate Substances [Na+].OC[C@@H](O)[C@H]1OC(=O)C(O)=C1[O-] PPASLZSBLFJQEF-RKJRWTFHSA-M 0.000 description 1
- 229960005055 sodium ascorbate Drugs 0.000 description 1
- 238000002415 sodium dodecyl sulfate polyacrylamide gel electrophoresis Methods 0.000 description 1
- KSAVQLQVUXSOCR-UHFFFAOYSA-M sodium lauroyl sarcosinate Chemical compound [Na+].CCCCCCCCCCCC(=O)N(C)CC([O-])=O KSAVQLQVUXSOCR-UHFFFAOYSA-M 0.000 description 1
- 229910052938 sodium sulfate Inorganic materials 0.000 description 1
- 235000011152 sodium sulphate Nutrition 0.000 description 1
- PPASLZSBLFJQEF-RXSVEWSESA-M sodium-L-ascorbate Chemical compound [Na+].OC[C@H](O)[C@H]1OC(=O)C(O)=C1[O-] PPASLZSBLFJQEF-RXSVEWSESA-M 0.000 description 1
- RPENMORRBUTCPR-UHFFFAOYSA-M sodium;1-hydroxy-2,5-dioxopyrrolidine-3-sulfonate Chemical compound [Na+].ON1C(=O)CC(S([O-])(=O)=O)C1=O RPENMORRBUTCPR-UHFFFAOYSA-M 0.000 description 1
- HPALAKNZSZLMCH-UHFFFAOYSA-M sodium;chloride;hydrate Chemical compound O.[Na+].[Cl-] HPALAKNZSZLMCH-UHFFFAOYSA-M 0.000 description 1
- 238000001228 spectrum Methods 0.000 description 1
- 230000010473 stable expression Effects 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 239000011550 stock solution Substances 0.000 description 1
- 238000006467 substitution reaction Methods 0.000 description 1
- 125000000472 sulfonyl group Chemical group *S(*)(=O)=O 0.000 description 1
- 150000003461 sulfonyl halides Chemical class 0.000 description 1
- 238000010189 synthetic method Methods 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 229940095064 tartrate Drugs 0.000 description 1
- 125000005207 tetraalkylammonium group Chemical group 0.000 description 1
- 125000000335 thiazolyl group Chemical group 0.000 description 1
- 125000001544 thienyl group Chemical group 0.000 description 1
- 150000007970 thio esters Chemical class 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 229960003989 tocilizumab Drugs 0.000 description 1
- 125000003944 tolyl group Chemical group 0.000 description 1
- 231100000419 toxicity Toxicity 0.000 description 1
- 230000001988 toxicity Effects 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 108700012359 toxins Proteins 0.000 description 1
- FGMPLJWBKKVCDB-UHFFFAOYSA-N trans-L-hydroxy-proline Natural products ON1CCCC1C(O)=O FGMPLJWBKKVCDB-UHFFFAOYSA-N 0.000 description 1
- VZCYOOQTPOCHFL-UHFFFAOYSA-N trans-butenedioic acid Natural products OC(=O)C=CC(O)=O VZCYOOQTPOCHFL-UHFFFAOYSA-N 0.000 description 1
- 230000009466 transformation Effects 0.000 description 1
- 230000032258 transport Effects 0.000 description 1
- 150000003918 triazines Chemical class 0.000 description 1
- 239000001226 triphosphate Substances 0.000 description 1
- 235000011178 triphosphate Nutrition 0.000 description 1
- 239000003656 tris buffered saline Substances 0.000 description 1
- 210000004881 tumor cell Anatomy 0.000 description 1
- 229910021642 ultra pure water Inorganic materials 0.000 description 1
- 238000001946 ultra-performance liquid chromatography-mass spectrometry Methods 0.000 description 1
- 239000012498 ultrapure water Substances 0.000 description 1
- 229940035893 uracil Drugs 0.000 description 1
- DRTQHJPVMGBUCF-UHFFFAOYSA-N uracil arabinoside Natural products OC1C(O)C(CO)OC1N1C(=O)NC(=O)C=C1 DRTQHJPVMGBUCF-UHFFFAOYSA-N 0.000 description 1
- DNYWZCXLKNTFFI-UHFFFAOYSA-N uranium Chemical compound [U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U][U] DNYWZCXLKNTFFI-UHFFFAOYSA-N 0.000 description 1
- 229940045145 uridine Drugs 0.000 description 1
- 229960003824 ustekinumab Drugs 0.000 description 1
- 229960005486 vaccine Drugs 0.000 description 1
- 239000013598 vector Substances 0.000 description 1
- 125000000391 vinyl group Chemical group [H]C([*])=C([H])[H] 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 150000003722 vitamin derivatives Chemical class 0.000 description 1
- 229910052727 yttrium Inorganic materials 0.000 description 1
- 229910052726 zirconium Inorganic materials 0.000 description 1
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
- A61K47/6869—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell the tumour determinant being from a cell of the reproductive system: ovaria, uterus, testes, prostate
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/54—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an organic compound
- A61K47/549—Sugars, nucleosides, nucleotides or nucleic acids
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68031—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being an auristatin
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68033—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a maytansine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/68035—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a pyrrolobenzodiazepine
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6801—Drug-antibody or immunoglobulin conjugates defined by the pharmacologically or therapeutically active agent
- A61K47/6803—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates
- A61K47/6811—Drugs conjugated to an antibody or immunoglobulin, e.g. cisplatin-antibody conjugates the drug being a protein or peptide, e.g. transferrin or bleomycin
- A61K47/6817—Toxins
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6849—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a receptor, a cell surface antigen or a cell surface determinant
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6851—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a determinant of a tumour cell
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
- A61P35/02—Antineoplastic agents specific for leukemia
Definitions
- the present invention is in the field of bioconjugation. More specifically, the invention relates to a specific mode of conjugation to prepare bioconjugates that have a beneficial effect on the therapeutic index of the bioconjugate, in particular in the targeting of HER2-expressing tumours.
- Bioconjugation is the process of linking two or more molecules, of which at least one is a biomolecule.
- the biomolecule(s) may also be referred to as "biomolecule(s) of interest", the other molecule(s) may also be referred to as “target molecule” or “molecule of interest”.
- target molecule or “molecule of interest”.
- the biomolecule of interest (BOI) will consist of a protein (or peptide), a glycan, a nucleic acid (or oligonucleotide), a lipid, a hormone or a natural drug (or fragments or combinations thereof).
- the other molecule of interest may also be a biomolecule, hence leading to the formation of homo- or heterodimers (or higher oligomers), or the other molecule may possess specific features that are imparted onto the biomolecule of interest by the conjugation process.
- the modulation of protein structure and function by covalent modification with a chemical probe for detection and/or isolation has evolved as a powerful tool in proteome-based research and biomedical applications. Fluorescent or affinity tagging of proteins is key to studying the trafficking of proteins in their native habitat. Vaccines based on protein-carbohydrate conjugates have gained prominence in the fight against HIV, cancer, malaria and pathogenic bacteria, whereas carbohydrates immobilized on microarrays are instrumental in elucidation of the glycome.
- Synthetic DNA and RNA oligonucleotides require the introduction of a suitable functionality for diagnostic and therapeutic applications, such as microarray technology, antisense and gene- silencing therapies, nanotechnology and various materials sciences applications.
- a suitable functionality such as microarray technology, antisense and gene- silencing therapies, nanotechnology and various materials sciences applications.
- attachment of a cell-penetrating ligand is the most commonly applied strategy to tackle the low internalization rate of ONs encountered during oligonucleotide-based therapeutics (antisense, siRNA).
- the preparation of oligonucleotide-based microarrays requires the selective immobilization of ONs on a suitable solid surface, e.g. glass.
- two strategic concepts can be recognized in the field of bioconjugation technology: (a) conjugation based on a functional group already present in the biomolecule of interest, such as for example a thiol, an amine, an alcohol or a hydroxyphenol unit or (b) a two-stage process involving engineering of one (or more) unique reactive groups into a BOI prior to the actual conjugation process.
- the first approach typically involves a reactive amino acid side-chain in a protein (e.g. cysteine, lysine, serine and tyrosine), or a functional group in a glycan (e.g. amine, aldehyde) or nucleic acid (e.g. purine or pyrimidine functionality or alcohol).
- Typical examples of a functional group that may be imparted onto the BOI include (strained) alkyne, (strained) alkene, norbornene, tetrazine, azide, phosphine, nitrile oxide, nitrone, nitrile imine, diazo compound, carbonyl compound, (O-alkyl)hydroxylamine and hydrazine, which may be achieved by either chemical or molecular biology approach.
- Each of the above functional groups is known to have at least one reaction partner, in many cases involving complete mutual reactivity.
- cyclooctynes react selectively and exclusively with 1 ,3-dipoles, strained alkenes with tetrazines and phosphines with azides, leading to fully stable covalent bonds.
- some of the above functional groups have the disadvantage of being highly lipophilic, which may compromise conjugation efficiency, in particular in combination with a lipophilic molecule of interest (see below).
- the final linking unit between the biomolecule and the other molecule of interest should preferentially also be fully compatible with an aqueous environment in terms of solubility, stability and biocompatibility.
- a highly lipophilic linker may lead to aggregation (during and/or after conjugation), which may significantly increase reaction times and/or reduce conjugation yields, in particular when the MOI is also of hydrophobic nature.
- highly lipophilic linker- MOI combination may lead to unspecific binding to surfaces or specific hydrophobic patches on the same or other biomolecules. If the linker is susceptible to aqueous hydrolysis or other water- induced cleavage reactions, the components comprising the original bioconjugate separate by diffusion.
- linker should be inert to functionalities present in the bioconjugate or any other functionality that may be encountered during application of the bioconjugate, which excludes, amongst others, the use of linkers featuring for example a ketone or aldehyde moiety (may lead to imine formation), an ⁇ , ⁇ -unsaturated carbonyl compound (Michael addition), thioesters or other activated esters (amide bond formation).
- PEG linkers are highly water soluble, non-toxic, non-antigenic, and lead to negligible or no aggregation. For this reason, a large variety of linear, bifunctional PEG linkers are commercially available from various sources, which can be selectively modified at either end with a (bio)molecule of interest.
- PEG linkers are the product of a polymerization process of ethylene oxide and are therefore typically obtained as stochastic mixtures of chain length, which can be partly resolved into PEG constructs with an average weight distribution centred around 1 , 2, 4 kDa or more (up to 60 kDa).
- dPEGs Homogeneous, discrete PEGs
- dPEGs Homogeneous, discrete PEGs
- the PEG unit itself imparts particular characteristics onto a biomolecule.
- protein PEGylation may lead to prolonged residence in vivo, decreased degradation by metabolic enzymes and a reduction or elimination of protein immunogenicity.
- Several PEGylated proteins have been FDA-approved and are currently on the market.
- PEG linkers are perfectly suitable for bioconjugation of small and/or water-soluble moieties under aqueous conditions.
- the polarity of a PEG unit may be insufficient to offset hydrophobicity, leading to significantly reduced reaction rates, lower yields and induced aggregation issues.
- lengthy PEG linkers and/or significant amounts of organic co-solvents may be required to solubilize the reagents.
- auristatins E or F maytansinoids, duocarmycins, calicheamicins or pyrrolobenzodiazepines (PBDs), with many others are underway.
- PBDs pyrrolobenzodiazepines
- auristatin F all toxic payloads are poorly to non-water- soluble, which necessitates organic co-solvents to achieve successful conjugation, such as 25% dimethylacetamide (DMA) or 50% propylene glycol (PG).
- DMA dimethylacetamide
- PG propylene glycol
- Linkers are known in the art, and disclosed in e.g. WO 2008/070291 , incorporated by reference.
- WO 2008/070291 discloses a linker for the coupling of targeting agents to anchoring components.
- the linker contains hydrophilic regions represented by polyethylene glycol (PEG) and an extension lacking chiral centers that is coupled to a targeting agent.
- PEG polyethylene glycol
- WO 01/88535 discloses a linker system for surfaces for bioconjugation, in particular a linker system having a novel hydrophilic spacer group.
- the hydrophilic atoms or groups for use in the linker system are selected from the group consisting of
- R 3 and R 4 are independently selected from the group consisting of H, OH, C1-C4 alkoxy and Ci-C4 acyloxy.
- WO 2014/100762 describes compounds with a hydrophilic self- immolative linker, which is cleavable under appropriate conditions and incorporates a hydrophilic group to provide better solubility of the compound.
- the compounds comprise a drug moiety, a targeting moiety capable of targeting a selected cell population, and a linker which contains an acyl unit, an optional spacer unit for providing distance between the drug moiety and the targeting moiety, a peptide linker which can be cleavable under appropriate conditions, a hydrophilic self- immolative linker, and an optional second self-immolative spacer or cyclization self-elimination linker.
- the hydrophilic self-immolative linker is e.g. a benzyloxycarbonyl group.
- the invention relates to a method or use for increasing the therapeutic index of a bioconjugate
- a bioconjugate prepared via a specific mode of conjugation exhibits a greater therapeutic index compared to the same bioconjugate, i.e. the same biomolecule, the same target molecule (e.g. active substance) and the same biomolecule drug ratio, obtained via a different mode of conjugation.
- the mode of conjugating a biomolecule to a target molecule is exposed in the linker itself and/or in the attachment point of the linker to the biomolecule. That the linker and/or attachment point could have an effect on the therapeutic index of a bioconjugate, such as an antibody-drug-conjugate, could not be envisioned based on the current knowledge.
- linkers are considered inert when it comes to treatment and are solely present as a consequence of the preparation of the bioconjugate. That the selection of a specific mode of conjugation has an effect on the therapeutic index is unprecedented and a breakthrough discovery in the field of bioconjugates, in particular antibody-drug-conjugates.
- the bioconjugates according to the invention are on one hand more efficacious (therapeutically effective) as the same bioconjugates, i.e. the same biomolecule, the same target molecule (e.g. active substance) and the same biomolecule/target molecule ratio, obtained via a different mode of conjugation, and/or on the other hand exhibit a greater tolerability.
- This finding has dramatic implications on the treatment of subjects with the bioconjugate according to the invention, as the therapeutic window widens. As a result of the expansion of the therapeutic window, the treatment dosages may be lowered and as a consequence potential, unwanted, side-effects are reduced.
- the mode of conjugation according to the invention comprises:
- S(F ) X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
- linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L 2 to obtain the antibody-conjugate wherein linker L comprises S-Z 3 -L 2 and wherein Z 3 is a connecting group resulting from the reaction between Q and F .
- the mode of conjugation according to the invention ensure that the bioconjugate contains a linker L comprising a group according to formula (1 ) or a salt thereof:
- a bioconjugate prepared such that it contains a linker L comprising a group according to formula (1 ) or a salt thereof exhibits a greater therapeutic index compared to the same bioconjugate, i.e. the same biomolecule, the same target molecule (e.g. active substance) and the same biomolecule drug ratio, containing a linker without the group according to formula (1 ) present.
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, wherein D is optionally connected to N via a spacer moiety.
- the mode of conjugation is being used to connect an biomolecule B with a target molecule D via a linker L.
- Conjugation refers to the specific mode of connecting the biomolecule to the target molecule.
- the bioconjugate according to the invention is represented by formula (A):
- - B is a biomolecule
- - L is a linker linking B and D;
- - B is a biomolecule
- - L is a linker linking B and D;
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S or NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
- the method according to embodiment 1 further comprising a
- biomolecule is an antibody and the bioconjugate is an antibody-drug-conjugate.
- target molecule D is an active substance, preferably a cytotoxin.
- bioconjugate has the formula B-Z 3 -L-D, wherein Z 3 is obtained by the reacting reactive group Q with the functional group F .
- Z 3 is obtained by the reacting a linker- conjugate having formula Q -L-D, wherein L comprises a group according to formula (1 ) or a salt thereof:
- - a is independently 0 or 1 ;
- - b is independently 0 or 1 ;
- - c is 0 or 1 ;
- - d is 0 or 1 ;
- - e is 0 or 1 ;
- - f is an integer in the range of 1 to 150;
- - g is 0 or 1 ;
- - i is 0 or 1 ;
- - D is a target molecule
- - Q is a reactive group capable of reacting with a functional group F present on a biomolecule
- - Z is a connecting group that connects Q or Sp 3 to Sp 2 , O or C(O) or N(R 1 );
- - Z 2 is a connecting group that connects D or Sp 4 to Sp 1 , N(R 1 ), O or C(O);
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or R is D, -[(Sp )b(Z 2 ) e (Sp 4 )iD] or -[(Sp 2 )c(Z)
- Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cydoalkylene groups, C5-C200 cydoalkenylene groups, C8-C200 cydoalkynylene groups, C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups and C9-C200 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cydoalkylene groups, cydoalkenylene groups, cydoalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally
- Sp ⁇ Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group consisting of O, S or NR 3 , wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, and wherein Q
- R 9 is hydrogen, a linear or branched Ci - C12 alkyl group or a C4 - C12 (hetero)aryl group.
- R 0 is a (thio)ester group
- R 8 is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups.
- Z is selected from hydrogen, methyl and pyridyl.
- - B is a biomolecule
- - L is a linker linking B and D;
- L comprises a group according to formula (1 ) or a salt thereof:
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2
- R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
- the present invention thus concerns in a first aspect a method or use for increasing the therapeutic index of a bioconjugate, wherein the mode of conjugation according to the invention is comprised in or used to prepare the bioconjugate.
- the mode of conjugation comprises steps (i) and (ii) as defined herein.
- the mode of conjugation comprises the step of preparing the bioconjugate of formula (A) such that linker L as defined above is comprised in the bioconjugate.
- the method or use according to the invention further comprises administering the bioconjugate to a subject in need thereof.
- the invention according to the first aspect can also be worded as the use of the mode of conjugation as defined above in a bioconjugate for increasing the therapeutic index of the bioconjugate, or to the use of linker L as defined above in a bioconjugate for increasing the therapeutic index of the bioconjugate.
- the present invention concerns the treatment of a subject in need thereof, comprising the administration of the bioconjugate according to the invention.
- the bioconjugate is administered in a therapeutically effective dose.
- administration may occur less frequent as in treatment with conventional bioconjugates and/or in a lower dose.
- administration may occur more frequent as in treatment with conventional bioconjugates and/or in a higher dose.
- Administration may be in a single dose or may e.g. occur 1 - 4 times a month, preferably 1 - 2 times a month, more preferable administration occurs once every 3 or 4 weeks, most preferably every 4 weeks.
- the dose of the bioconjugate according to the invention may depend on many factors and optimal doses can be determined by the skilled person via routine experimentation.
- the bioconjugate is typically administered in a dose of 0.01 - 50 mg/kg body weight of the subject, more accurately 0.03 - 25 mg/kg or most accurately 0.05 - 10 mg/kg, or alternatively 0.1 - 25 mg/kg or 0.5 - 10 mg/kg.
- the administration of the bioconjugate according to the invention is at a dose that is lower than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89- 60%, even more preferable 59-30%, most preferably at most 29-10% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 10-29%, more preferably at most 30-59%, even more preferable 60-89%, most preferably at most 90-99% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the administration of the bioconjugate according to the invention is at a dose that is lower than the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89- 60%, even more preferable 59-30%, most preferably at most 29-10% of the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most a factor 1.1 - 1.49 higher, more preferably at most a factor 1 .5 - 1.99 higher, even more preferable a factor 2 - 4.99 higher, most preferably at most a factor 5 - 10 higher of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the preparation of the bioconjugate typically comprises the step of reacting linker-conjugate having the formula Q -L-D, wherein L and D are as defined above and Q is a reactive group capable of reacting with a functional group F , with a biomolecule having the formula B-F , wherein B is as defined above and F is a functional group capable of reacting with Q .
- Q and F react to form a connecting group Z 3 , which is located in the bioconjugate according to formula (A) in the spacer moiety between B and L.
- Figure 1 describes the general concept of conjugation of biomolecules: a biomolecule of interest (BOI) containing one or more functional groups F is incubated with (excess of) a target molecule D (also referred to as molecule of interest or MOI) covalently attached to a reactive group Q via a specific linker.
- a chemical reaction between F and Q takes place, thereby forming a bioconjugate comprising a covalent connection between the BOI and the MOI.
- the BOI may e.g. be a peptide/protein, a glycan or a nucleic acid.
- Figure 2 shows several structures of derivatives of UDP sugars of galactosamine, which may be modified with e.g. a 3-mercaptopropionyl group (11a), an azidoacetyl group (11 b), or an azidodifluoroacetyl group (11c) at the 2-position, or with an azido azidoacetyl group at the 6- position of N-acetyl galactosamine (11d).
- a 3-mercaptopropionyl group 11a
- an azidoacetyl group 11 b
- an azidodifluoroacetyl group 11c
- Figure 3 schematically displays how any of the UDP-sugars 11a-d may be attached to a glycoprotein comprising a GlcNAc moiety 12 (e.g. a monoclonal antibody the glycan of which is trimmed by an endoglycosidase) under the action of a galactosyltransferase mutant or a GalNAc- transferase, thereby generating a ⁇ -glycosidic 1-4 linkage between a GalNAc derivative and GlcNAc (compounds 13a-d, respectively).
- a GlcNAc moiety 12 e.g. a monoclonal antibody the glycan of which is trimmed by an endoglycosidase
- Figure 4 shows how a modified antibody 13a-d may undergo a bioconjugation process by means of nucleophilic addition to maleimide (as for 3-mercaptopropionyl-galactosamine-modified 13a leading to thioether conjugate 14, or for conjugation to a engineered cysteine residue leading to thioether conjugate 17) or upon strain-promoted cycloaddition with a cyclooctyne reagent (as for 13b, 13c or 13d leading to triazoles 15a, 15b or 16, respectively).
- maleimide as for 3-mercaptopropionyl-galactosamine-modified 13a leading to thioether conjugate 14, or for conjugation to a engineered cysteine residue leading to thioether conjugate 17
- a cyclooctyne reagent as for 13b, 13c or 13d leading to triazoles 15a, 15b or 16, respectively.
- Figure 5 shows a representative set of functional groups (F ) in a biomolecule, either naturally present or introduced by engineering, which upon reaction with reactive group Q lead to connecting group Z 3 .
- Functional group F may also be artificially introduced (engineered) into a biomolecule at any position of choice.
- FIG. 6 shows preferred bioconjugates according to the invention.
- Conjugates 81-85 are prepared and the therapeutic index thereof investigated in the examples.
- Conjugates 81-85 are conjugated to trastuzumab as antibody.
- Figures 7A-E depict the results of the tolerability studies of Example 34 for control antibody- conjugate Kadcyla (Fig. 7A) and antibody-conjugates according to the invention 84 (Fig. 7B), 81 (Fig. 7C), 82 (Fig. 7D), 83 (Fig. 7E).
- Percentage body weight change ( ⁇ BW), based on 100 % on the start of treatment (day 1 ), over time is depicted.
- C vehicle treated.
- Figure 8D depicts the results of the efficacy studies of Example 33d for control antibody-conjugate Kadcyla (K) and antibody- conjugates according to the invention 84.
- the conjugation reaction involves on the one hand the biomolecule (BOI) containing a functional group F , and on the other hand the target molecule (MOI) containing a reactive group Q , or a "linker-conjugate" as defined herein, wherein Q reacts with F to form a connecting group that joins the BOI and the MOI in a bioconjugate.
- reactive group Q is joined via a linker to the MOI, said linker comprising the sulfamide moiety according to formula (1 ):
- Reactive group Q may be attached to either ends of the moiety of formula (1 ), in which case the MOI is attached to the opposite end of the moiety of formula (1 ).
- reactive group Q is attached to the moiety of formula (1 ) via the carbonyl end and the MOI is attached via the sulfamide end of the moiety of formula (1 ).
- reactive group Q is attached to the moiety of formula (1 ) via the sulfamide end and the MOI is attached via the carbonyl end of the moiety of formula (1 ).
- indefinite article “a” or “an” does not exclude the possibility that more than one of the elements is present, unless the context clearly requires that there is one and only one of the elements.
- the indefinite article “a” or “an” thus usually means “at least one”.
- the compounds disclosed in this description and in the claims may comprise one or more asymmetric centres, and different diastereomers and/or enantiomers may exist of the compounds.
- the description of any compound in this description and in the claims is meant to include all diastereomers, and mixtures thereof, unless stated otherwise.
- the description of any compound in this description and in the claims is meant to include both the individual enantiomers, as well as any mixture, racemic or otherwise, of the enantiomers, unless stated otherwise.
- the structure of a compound is depicted as a specific enantiomer, it is to be understood that the invention of the present application is not limited to that specific enantiomer.
- the compounds may occur in different tautomeric forms.
- the compounds disclosed in this description and in the claims may exist as cis and trans isomers. Unless stated otherwise, the description of any compound in the description and in the claims is meant to include both the individual cis and the individual trans isomer of a compound, as well as mixtures thereof. As an example, when the structure of a compound is depicted as a cis isomer, it is to be understood that the corresponding trans isomer or mixtures of the cis and trans isomer are not excluded from the invention of the present application. When the structure of a compound is depicted as a specific cis or trans isomer, it is to be understood that the invention of the present application is not limited to that specific cis or trans isomer.
- Unsubstituted alkyl groups have the general formula C n H2n+i and may be linear or branched. Optionally, the alkyl groups are substituted by one or more substituents further specified in this document. Examples of alkyl groups include methyl, ethyl, propyl, 2-propyl, t-butyl, 1-hexyl, 1- dodecyl, etc.
- a cycloalkyl group is a cyclic alkyl group.
- Unsubstituted cycloalkyl groups comprise at least three carbon atoms and have the general formula C n H2n-i .
- the cycloalkyl groups are substituted by one or more substituents further specified in this document. Examples of cycloalkyl groups include cyclopropyl, cyclobutyl, cyclopentyl and cyclohexyl.
- An alkenyl group comprises one or more carbon-carbon double bonds, and may be linear or branched. Unsubstituted alkenyl groups comprising one C-C double bond have the general formula C n H2n-i . Unsubstituted alkenyl groups comprising two C-C double bonds have the general formula C n H2n-3.
- An alkenyl group may comprise a terminal carbon-carbon double bond and/or an internal carbon-carbon double bond.
- a terminal alkenyl group is an alkenyl group wherein a carbon-carbon double bond is located at a terminal position of a carbon chain.
- An alkenyl group may also comprise two or more carbon-carbon double bonds.
- alkenyl group examples include ethenyl, propenyl, isopropenyl, t-butenyl, 1 ,3-butadienyl, 1 ,3-pentadienyl, etc.
- an alkenyl group may optionally be substituted with one or more, independently selected, substituents as defined below.
- an alkenyl group may optionally be interrupted by one or more heteroatoms independently selected from the group consisting of O, N and S.
- An alkynyl group comprises one or more carbon-carbon triple bonds, and may be linear or branched. Unsubstituted alkynyl groups comprising one C-C triple bond have the general formula CnH2n-3.
- An alkynyl group may comprise a terminal carbon-carbon triple bond and/or an internal carbon-carbon triple bond.
- a terminal alkynyl group is an alkynyl group wherein a carbon-carbon triple bond is located at a terminal position of a carbon chain.
- An alkynyl group may also comprise two or more carbon-carbon triple bonds. Unless stated otherwise, an alkynyl group may optionally be substituted with one or more, independently selected, substituents as defined below.
- alkynyl group examples include ethynyl, propynyl, isopropynyl, t-butynyl, etc. Unless stated otherwise, an alkynyl group may optionally be interrupted by one or more heteroatoms independently selected from the group consisting of O, N and S.
- An aryl group comprises six to twelve carbon atoms and may include monocyclic and bicyclic structures.
- the aryl group may be substituted by one or more substituents further specified in this document.
- Examples of aryl groups are phenyl and naphthyl.
- Arylalkyl groups and alkylaryl groups comprise at least seven carbon atoms and may include monocyclic and bicyclic structures.
- the arylalkyl groups and alkylaryl may be substituted by one or more substituents further specified in this document.
- An arylalkyl group is for example benzyl.
- An alkylaryl group is for example 4-i-butylphenyl.
- Heteroaryl groups comprise at least two carbon atoms (i.e. at least C2) and one or more heteroatoms N, O, P or S.
- a heteroaryl group may have a monocyclic or a bicyclic structure.
- the heteroaryl group may be substituted by one or more substituents further specified in this document.
- heteroaryl groups examples include pyridinyl, quinolinyl, pyrimidinyl, pyrazinyl, pyrazolyl, imidazolyl, thiazolyl, pyrrolyl, furanyl, triazolyl, benzofuranyl, indolyl, purinyl, benzoxazolyl, thienyl, phospholyl and oxazolyl.
- Heteroarylalkyl groups and alkylheteroaryl groups comprise at least three carbon atoms (i.e. at least C3) and may include monocyclic and bicyclic structures.
- the heteroaryl groups may be substituted by one or more substituents further specified in this document.
- an aryl group is denoted as a (hetero)aryl group, the notation is meant to include an aryl group and a heteroaryl group.
- an alkyl(hetero)aryl group is meant to include an alkylaryl group and a alkylheteroaryl group
- (hetero)arylalkyl is meant to include an arylalkyl group and a heteroarylalkyl group.
- a C2 - C24 (hetero)aryl group is thus to be interpreted as including a C2 - C24 heteroaryl group and a Ce - C24 aryl group.
- a C3 - C24 alkyl(hetero)aryl group is meant to include a C7 - C24 alkylaryl group and a C3 - C24 alkylheteroaryl group
- a C3 - C24 (hetero)arylalkyl is meant to include a C7 - C24 arylalkyl group and a C3 - C24 heteroarylalkyl group.
- a cycloalkynyl group is a cyclic alkynyl group.
- An unsubstituted cycloalkynyl group comprising one triple bond has the general formula C n H2n-5.
- a cycloalkynyl group is substituted by one or more substituents further specified in this document.
- An example of a cycloalkynyl group is cyclooctynyl.
- a heterocycloalkynyl group is a cycloalkynyl group interrupted by heteroatoms selected from the group of oxygen, nitrogen and sulphur.
- a heterocycloalkynyl group is substituted by one or more substituents further specified in this document.
- An example of a heterocycloalkynyl group is azacyclooctynyl.
- a (hetero)aryl group comprises an aryl group and a heteroaryl group.
- An alkyl(hetero)aryl group comprises an alkylaryl group and an alkylheteroaryl group.
- a (hetero)arylalkyl group comprises a arylalkyl group and a heteroarylalkyl groups.
- a (hetero)alkynyl group comprises an alkynyl group and a heteroalkynyl group.
- a (hetero)cycloalkynyl group comprises an cycloalkynyl group and a heterocycloalkynyl group.
- a (hetero)cycloalkyne compound is herein defined as a compound comprising a (hetero)cycloalkynyl group.
- fused (hetero)cycloalkyne compounds i.e. (hetero)cycloalkyne compounds wherein a second ring structure is fused, i.e. annulated, to the (hetero)cycloalkynyl group.
- a fused (hetero)cyclooctyne compound a cydoalkyi (e.g. a cyclopropyl) or an arene (e.g. benzene) may be annulated to the (hetero)cyclooctynyl group.
- the triple bond of the (hetero)cyclooctynyl group in a fused (hetero)cyclooctyne compound may be located on either one of the three possible locations, i.e. on the 2, 3 or 4 position of the cyclooctyne moiety (numbering according to "lUPAC Nomenclature of Organic Chemistry", Rule A31.2).
- the description of any fused (hetero)cyclooctyne compound in this description and in the claims is meant to include all three individual regioisomers of the cyclooctyne moiety.
- alkyl groups, cydoalkyi groups, alkenyl groups, alkynyl groups, (hetero)aryl groups, (hetero)arylalkyl groups, alkyl(hetero)aryl groups, alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, (hetero)arylene groups, alkyl(hetero)arylene groups, (hetero)arylalkylene groups, (hetero)arylalkenylene groups, (hetero)arylalkynylene groups, alkenyl groups, alkoxy groups, alkenyloxy groups, (hetero)aryloxy groups, alkynyloxy groups and cycloalkyloxy groups may be substituted with one or more substituents independently selected from the group consisting of Ci - Ci2 alkyl groups, C2 - C12 alkenyl groups
- sugar is herein used to indicate a monosaccharide, for example glucose (Glc), galactose (Gal), mannose (Man) and fucose (Fuc).
- sugar derivative is herein used to indicate a derivative of a monosaccharide sugar, i.e. a monosaccharide sugar comprising substituents and/or functional groups. Examples of a sugar derivative include amino sugars and sugar acids, e.g.
- glucosamine (GlcNhb), galactosamine (GalNhb) N-acetylglucosamine (GlcNAc), N-acetylgalactosamine (GalNAc), sialic acid (Sia) which is also referred to as N-acetylneuraminic acid (NeuNAc), and N-acetylmuramic acid (MurNAc), glucuronic acid (GlcA) and iduronic acid (IdoA).
- a sugar derivative also include compounds herein denoted as S(F ) X , wherein S is a sugar or a sugar derivative, and wherein S comprises x functional groups F .
- a core /V-acetylglucosamine substituent (core-GlcNAc substituent) or core /V-acetylglucosamine moiety is herein defined as a GlcNAc that is bonded via C1 to an antibody, preferably via an N- glycosidic bond to the amide nitrogen atom in the side chain of an asparagine amino acid of the antibody.
- the core-GlcNAc substituent may be present at a native glycosylation site of an antibody, but it may also be introduced on a different site on the antibody.
- a core-N- acetylglucosamine substituent is a monosaccharide substituent, or if said core-GlcNAc substituent is fucosylated, a disaccharide core-GlcNAc-(a1-6-Fuc) substituent, further referred to as GlcNAc(Fuc).
- a "core-GlcNAc substituent" is not to be confused with a "core-GlcNAc”.
- a core-GlcNAc is herein defined as the inner GlcNAc that is part of a poly- or an oligosaccharide comprising more than two saccharides, i.e. the GlcNAc via which the poly- or oligosaccharide is bonded to an antibody.
- An antibody comprising a core-N-acetylglucosamine substituent as defined herein is thus an antibody, comprising a monosaccharide core-GlcNAc substituent as defined above, or if said core-GlcNAc substituent is fucosylated, a disaccharide core-GlcNAc(Fuc) substituent. If a core- GlcNAc substituent or the GlcNAc in a GlcNAc-S(F ) x substituent is fucosylated, fucose is most commonly linked a-1 ,6 to 06 of the core-GlcNAc substituent.
- a fucosylated core-GlcNAc substituent is denoted core-GlcNAc(Fuc)
- a fucosylated GlcNAc-S(F ) x substituent is denoted GlcNAc(Fuc)-S(F )x.
- nucleotide is herein used in its normal scientific meaning.
- nucleotide refers to a molecule that is composed of a nucleobase, a five-carbon sugar (either ribose or 2- deoxyribose), and one, two or three phosphate groups. Without the phosphate group, the nucleobase and sugar compose a nucleoside.
- a nucleotide can thus also be called a nucleoside monophosphate, a nucleoside diphosphate or a nucleoside triphosphate.
- the nucleobase may be adenine, guanine, cytosine, uracil or thymine.
- nucleotide examples include uridine diphosphate (UDP), guanosine diphosphate (GDP), thymidine diphosphate (TDP), cytidine diphosphate (CDP) and cytidine monophosphate (CMP).
- UDP uridine diphosphate
- GDP guanosine diphosphate
- TDP thymidine diphosphate
- CDP cytidine diphosphate
- CMP cytidine monophosphate
- protein is herein used in its normal scientific meaning.
- polypeptides comprising about 10 or more amino acids are considered proteins.
- a protein may comprise natural, but also unnatural amino acids.
- glycoprotein is herein used in its normal scientific meaning and refers to a protein comprising one or more monosaccharide or oligosaccharide chains (“glycans”) covalently bonded to the protein.
- a glycan may be attached to a hydroxyl group on the protein (O-linked-glycan), e.g. to the hydroxyl group of serine, threonine, tyrosine, hydroxylysine or hydroxyproline, or to an amide function on the protein (A/-glycoprotein), e.g. asparagine or arginine, or to a carbon on the protein (C-glycoprotein), e.g. tryptophan.
- O-linked-glycan e.g. to the hydroxyl group of serine, threonine, tyrosine, hydroxylysine or hydroxyproline, or to an amide function on the protein (A/-glycoprotein), e.g. asparagine or
- a glycoprotein may comprise more than one glycan, may comprise a combination of one or more monosaccharide and one or more oligosaccharide glycans, and may comprise a combination of N-linked, O-linked and C-linked glycans. It is estimated that more than 50% of all proteins have some form of glycosylation and therefore qualify as glycoprotein.
- glycoproteins include PSMA (prostate-specific membrane antigen), CAL (Candida antartica lipase), gp41 , gp120, EPO (erythropoietin), antifreeze protein and antibodies.
- glycan is herein used in its normal scientific meaning and refers to a monosaccharide or oligosaccharide chain that is linked to a protein.
- the term glycan thus refers to the carbohydrate-part of a glycoprotein.
- the glycan is attached to a protein via the C-1 carbon of one sugar, which may be without further substitution (monosaccharide) or may be further substituted at one or more of its hydroxyl groups (oligosaccharide).
- a naturally occurring glycan typically comprises 1 to about 10 saccharide moieties. However, when a longer saccharide chain is linked to a protein, said saccharide chain is herein also considered a glycan.
- a glycan of a glycoprotein may be a monosaccharide.
- a monosaccharide glycan of a glycoprotein consists of a single N-acetylglucosamine (GlcNAc), glucose (Glc), mannose (Man) or fucose (Fuc) covalently attached to the protein.
- a glycan may also be an oligosaccharide.
- An oligosaccharide chain of a glycoprotein may be linear or branched.
- the sugar that is directly attached to the protein is called the core sugar.
- a sugar that is not directly attached to the protein and is attached to at least two other sugars is called an internal sugar.
- a sugar that is not directly attached to the protein but to a single other sugar, i.e. carrying no further sugar substituents at one or more of its other hydroxyl groups is called the terminal sugar.
- a glycan may be an O-linked glycan, an N-linked glycan or a C-linked glycan.
- an O-linked glycan a monosaccharide or oligosaccharide glycan is bonded to an O-atom in an amino acid of the protein, typically via a hydroxyl group of serine (Ser) or threonine (Thr).
- a monosaccharide or oligosaccharide glycan is bonded to the protein via an N-atom in an amino acid of the protein, typically via an amide nitrogen in the side chain of asparagine (Asn) or arginine (Arg).
- a delinked glycan a monosaccharide or oligosaccharide glycan is bonded to a C-atom in an amino acid of the protein, typically to a C-atom of tryptophan (Trp).
- antibody is herein used in its normal scientific meaning.
- An antibody is a protein generated by the immune system that is capable of recognizing and binding to a specific antigen.
- An antibody is an example of a glycoprotein.
- the term antibody herein is used in its broadest sense and specifically includes monoclonal antibodies, polyclonal antibodies, dimers, multimers, multispecific antibodies (e.g. bispecific antibodies), antibody fragments, and double and single chain antibodies.
- antibody is herein also meant to include human antibodies, humanized antibodies, chimeric antibodies and antibodies specifically binding cancer antigen.
- antibody is meant to include whole antibodies, but also antigen-binding fragments of an antibody, for example an antibody Fab fragment, F(ab')2, Fv fragment or Fc fragment from a cleaved antibody, a scFv-Fc fragment, a minibody, a diabody, a bispecific antibody or a scFv.
- the term includes genetically engineered antibodies and derivatives of an antibody. Antibodies, fragments of antibodies and genetically engineered antibodies may be obtained by methods that are known in the art.
- Typical examples of antibodies include, amongst others, abciximab, rituximab, basiliximab, palivizumab, infliximab, trastuzumab, alemtuzumab, adalimumab, tositumomab-1131 , cetuximab, ibrituximab tiuxetan, omalizumab, bevacizumab, natalizumab, ranibizumab, panitumumab, eculizumab, certolizumab pegol, golimumab, canakinumab, catumaxomab, ustekinumab, tocilizumab, ofatumumab, denosumab, belimumab, ipilimumab and brentuximab.
- the glycoprotein comprising a core-N- acetylglucosamine substituent is an antibody comprising a core-N- acetylglucosamine substituent (core-GlcNAc substituent), preferably a monoclonal antibody (mAb).
- said antibody is selected from the group consisting of IgA, IgD, IgE, IgG and IgM antibodies. More preferably, said antibody is an IgG antibody, and most preferably said antibody is an lgG1 antibody.
- the antibody when said antibody is a whole antibody, the antibody preferably comprises one or more, more preferably one, core-GlcNAc substituent on each heavy chain, said core-GlcNAc substituent being optionally fucosylated. Said whole antibody thus preferably comprises two or more, preferably two, optionally fucosylated, core-GlcNAc substituents.
- said antibody is a single chain antibody or an antibody fragment, e.g. a Fab fragment
- the antibody preferably comprises one or more core-GlcNAc substituents, which are optionally fucosylated.
- said core-GlcNAc substituent may be situated anywhere on the antibody, provided that said substituent does not hinder the antigen-binding site of the antibody.
- said core N-acetylglucosamine substituent is present at a native N-glycosylation site of the antibody.
- a linker is herein defined as a moiety that connects two or more elements of a compound.
- a bioconjugate a biomolecule and a target molecule are covalently connected to each other via a linker; in the linker-conjugate a reactive group Q is covalently connected to a target molecule via a linker; in a linker-construct a reactive group Q is covalently connected to a reactive group Q 2 via a linker.
- a linker may comprise one or more spacer-moieties.
- a spacer-moiety is herein defined as a moiety that spaces (i.e. provides distance between) and covalently links together two (or more) parts of a linker.
- the linker may be part of e.g. a linker- construct, the linker-conjugate or a bioconjugate, as defined below.
- a bioconjugate is herein defined as a compound wherein a biomolecule is covalently connected to a target molecule via a linker.
- a bioconjugate comprises one or more biomolecules and/or one or more target molecules.
- the linker may comprise one or more spacer moieties.
- An antibody- conjugate refers to a bioconjugate wherein the biomolecule is an antibody.
- a biomolecule is herein defined as any molecule that can be isolated from nature or any molecule composed of smaller molecular building blocks that are the constituents of macromolecular structures derived from nature, in particular nucleic acids, proteins, glycans and lipids.
- the biomolecule may also be referred to as biomolecule of interest (BOI).
- BOI biomolecule of interest
- examples of a biomolecule include an enzyme, a (non-catalytic) protein, a polypeptide, a peptide, an amino acid, an oligonucleotide, a monosaccharide, an oligosaccharide, a polysaccharide, a glycan, a lipid and a hormone.
- a target molecule also referred to as a molecule of interest (MOI) is herein defined as molecular structure possessing a desired property that is imparted onto the biomolecule upon conjugation.
- the term "salt thereof means a compound formed when an acidic proton, typically a proton of an acid, is replaced by a cation, such as a metal cation or an organic cation and the like. Where applicable, the salt is a pharmaceutically acceptable salt, although this is not required for salts that are not intended for administration to a patient.
- the compound may be protonated by an inorganic or organic acid to form a cation, with the conjugate base of the inorganic or organic acid as the anionic component of the salt.
- salt means a salt that is acceptable for administration to a patient, such as a mammal (salts with counterions having acceptable mammalian safety for a given dosage regime). Such salts may be derived from pharmaceutically acceptable inorganic or organic bases and from pharmaceutically acceptable inorganic or organic acids.
- “Pharmaceutically acceptable salt” refers to pharmaceutically acceptable salts of a compound, which salts are derived from a variety of organic and inorganic counter ions known in the art and include, for example, sodium, potassium, calcium, magnesium, ammonium, tetraalkylammonium, etc., and when the molecule contains a basic functionality, salts of organic or inorganic acids, such as hydrochloride, hydrobromide, formate, tartrate, besylate, mesylate, acetate, maleate, oxalate, etc.
- sulfamide linker refers to a linker comprising a sulfamide group, more particularly an acylsulfamide group [-C(0)-N(H)-S(0)2-N(R 1 )-] and/or a carbamoyl sulfamide group [-O-C(O)- N(H)-S(0) 2 -N(R 1 )-].
- the term "therapeutic index" has the conventional meaning well known to a person skilled in the art, and refers to the ratio of the dose of drug that is toxic (i.e. causes adverse effects at an incidence or severity not compatible with the targeted indication) for 50% of the population (TD50) divided by the dose that leads to the desired pharmacological effect in 50% of the population (effective dose or ED50).
- Tl TD50 / ED50.
- the therapeutic index may be determined by clinical trials or for example by plasma exposure tests. See also Muller, et al. Nature Reviews Drug Discovery 2012, 1 1 , 751-761 . At an early development stage, the clinical Tl of a drug candidate is often not yet known.
- Tl is typically defined as the quantitative ratio between efficacy (minimal effective dose in a mouse xenograft) and safety (maximum tolerated dose in mouse or rat).
- therapeutic efficacy denotes the capacity of a substance to achieve a certain therapeutic effect, e.g. reduction in tumour volume.
- Therapeutic effects can be measured determining the extent in which a substance can achieve the desired effect, typically in comparison with another substance under the same circumstances.
- a suitable measure for the therapeutic efficacy is the ED50 value, which may for example be determined during clinical trials or by plasma exposure tests.
- the therapeutic effect of a bioconjugate e.g. an ADC
- the efficacy refers to the ability of the ADC to provide a beneficial effect.
- the tolerability of said ADC in a rodent safety study can also be a measure of the therapeutic effect.
- the term "tolerability" refers to the maximum dose of a specific substance that does not cause adverse effects at an incidence or severity not compatible with the targeted indication.
- a suitable measure for the tolerability for a specific substance is the TD50 value, which may for example be determined during clinical trials or by plasma exposure tests.
- the "mode of conjugation” refers to the process that is used to conjugate a target molecule D to a biomolecule B, in particular an antibody AB, as well as to the structural features of the resulting bioconjugate, in particular of the linker that connects the target molecule to the biomolecule, that are a direct consequence of the process of conjugation.
- the mode of conjugation refers to a process for conjugation a target molecule to a biomolecule, in particular an antibody.
- the mode of conjugation refers to structural features of the linker and/or to the attachment point of the linker to the biomolecule that are a direct consequence of the process for conjugation a target molecule to a biomolecule, in particular an antibody.
- the mode of conjugation comprises at least one of "core- GlcNAc functionalization” and “sulfamide linkage” as defined further below.
- the mode of conjugation comprises both the "core-GlcNAc functionalization” and “sulfamide linkage” as defined further below.
- the mode of conjugation according to the invention is referred to as "core- GlcNAc functionalization", which refers to a process comprising:
- S(F ) X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
- linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L 2 to obtain the antibody-conjugate wherein linker L comprises S-Z 3 -L 2 and wherein Z 3 is a connecting group resulting from the reaction between Q and F .
- the antibody is conjugated via a glycan that is trimmed to a core- GlcNAc residue (optionally substituted with a fucose).
- This residue is functionalized with a sugar derivative S(F ) X , comprising 1 or 2 functional groups F , which are subsequently reacted with a functional group Q present on a linker-conjugate comprising target molecule D.
- the structural feature of the resulting linker L that links the antibody with the target molecule, that are a direct consequence of the conjugation process include:
- the point of attachment of the linker L to the antibody AB is at a specific amino acid residue which is glycosylated in the naturally occurring antibody or is an artificially introduced glycosylation site, by mutation of specific amino acid residues in the antibody.
- the point of attachment of the linker to the antibody can be specifically selected, which affords a highly predictable target molecule to antibody ratio (or DAR: "drug antibody ratio").
- the linker L is conjugated to a core-GlcNAc moiety of the antibody, and has the general structure -S-(M) PP -Z 3 -L 2 (D) r .
- Z 3 is a connecting group that is obtained by the reaction between Q and F . Options for Q , F and Z 3 are known to the skilled person and discussed in further detail below.
- Z 3 is connected via linker L 2 to at least one target molecule D (i.e. r > 1 ).
- linker L in particular linker L 2 , comprises the group according to formula (1 ) or a salt thereof as defined for mode of conjugation referred to "sulfamide linkage". It has been found that when the mode of conjugation according to the present embodiment is combined with the "sulfamide linkage" mode of conjugation, the best results were obtained in terms of improving the therapeutic index of the resulting bioconjugates.
- the inventors surprisingly found that using the above process for conjugating the target molecule to the antibody has a beneficial effect on the therapeutic index of the antibody-conjugate.
- the therapeutic index of antibody-conjugates having the mode of conjugation according to the present embodiment have an improved therapeutic index over antibody-conjugates not having the mode of conjugation according to the present embodiment.
- the use of the mode of conjugation according to the present invention is distinct from a process of preparing an antibody-conjugate, wherein the mode of conjugation is used to prepare the antibody-conjugate.
- the mode of conjugation comprises the step of preparing the bioconjugate of formula (A):
- - B is a biomolecule
- - L is a linker linking B and D;
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S or NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
- a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties is contacted with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F ) X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q ⁇ x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F ) X moiety to the core-GlcNAc moiety.
- the glycoprotein is typically an antibody, such as an antibody that has been trimmed to a core-GlcNAc residue as described further below.
- Step (i) affords a modified antibody according to Formula (24):
- S(F ) X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4.
- the antibody comprising a core-GlcNAc substituent, wherein said core- GlcNAc substituent is optionally fucosylated is of the Formula (21 ), wherein AB represents an antibody, GlcNAc is /V-acetylglucosamine, Fuc is fucose, b is 0 or 1 and y is 1 to 4, preferably y is 1 or 2.
- the process according to the invention further comprises the deglycosylation of an antibody glycan having a core N-acetylglucosamine, in the presence of an endoglycosidase, in order to obtain an antibody comprising a core N- acetylglucosamine substituent, wherein said core N-acetylglucosamine and said core N- acetylglucosamine substituent are optionally fucosylated.
- a suitable endoglycosidase may be selected.
- the endoglycosidase is preferably selected from the group consisting of EndoS, EndoA, EndoE, EfEndo18A, EndoF, EndoM, EndoD, EndoH, EndoT and EndoSH and/or a combination thereof, preferably of EndoS, EndoA, EndoF, EndoM, EndoD, EndoH and EndoSH enzymes and/or a combination thereof, the selection of which depends on the nature of the glycan.
- EndoSH is further defined below in the fourth aspect of the present invention.
- the endoglycosidase is EndoS, EndoS49, EndoF, EndoH, EndoSH or a combination thereof, more preferably EndoS, EndoS49, EndoF, EndoSH or a combination thereof.
- the endoglycosidase is EndoS, EndoF or a combination thereof.
- the endoglycosidase is EndoS.
- the endoglycosidase is EndoS49.
- the endoglycosidase is EndoSH. Herien, EndoF typically refers to one of EndoFI , EndoF2 and EndoF3.
- y 2 or 4
- y 1 or 2.
- GlcNAc AB GlcNAc catalyst S(F
- GlcNAc AB GlcNAc S(F
- the antibody AB is capable of targeting tumours that express an antigen selected from 5T4 (TPBG), av-integrin/ITGAV, BCMA, C4.4a, CA-IX, CD19, CD19b, CD22, CD25, CD30, CD33, CD37, CD40, CD56, CD70, CD74, CD79b, c-KIT (CD1 19), CD138/SDC1 , CEACAM5 (CD66e), Cripto, CS1 , DLL3, EFNA4, EGFR, EGFRvlll, Endothelin B Receptor (ETBR), ENPP3 (AGS-16), EpCAM, EphA2, FGFR2, FGFR3, FOLR1 (folate receptor a), gpNMB, guanyl cyclase C (GCC), HER2, Erb-B2, Lamp-1 , Lewis Y antigen, LIV-1 (SLC39A6, ZIP6), Mesothelin (TPBG), av-integrin/ITGA
- the antibody AB is capable of targeting HER2-expressing tumours, including but not limited to low HER2-expressing tumours, more preferably the antibody AB is selected from the group consisting of from trastuzumab, margetuximab, pertuzumab, HuMax- Her2, ertumaxomab, HB-008, ABP-980, BCD-022, CanMab, Herzuma, HD201 , CT-P6, PF- 05280014, COVA-208, FS-102, MCLA-128, CKD-10101 , HT-19 and functional analogues thereof, most preferably trastuzumab.
- S(F )x is defined as a sugar derivative comprising x functional groups F , wherein x is 1 or 2 and F is a functional group capable of reacting with Q present on the linker-conjugate to form a connecting moiety Z 3 .
- the sugar derivative S(F ) X may comprise 1 or 2 functional groups F .
- each functional group F is independently selected, i.e. one S(F ) X may comprise different functional groups F .
- x 1.
- x 2.
- Sugar derivative S(F ) X is derived from a sugar or a sugar derivative S, e.g. an amino sugar or an otherwise derivatized sugar.
- sugars and sugar derivatives examples include galactose (Gal), mannose (Man), glucose (Glc), glucuronic acid (GlucA) and fucose (Fuc).
- An amino sugar is a sugar wherein a hydroxyl (OH) group is replaced by an amino group and examples include N-acetylglucosamine (GlcNAc) and N-acetylgalactosamine (GalNAc).
- examples of an otherwise derivatized sugar include glucuronic acid (GlucA) and N-acetylneuraminic acid (sialic acid).
- Sugar derivative S(F ) X is preferably derived from galactose (Gal), mannose (Man), N-acetylglucosamine (GlcNAc), glucose (Glc), N-acetylgalactosamine (GalNAc), glucuronic acid (GlucA), fucose (Fuc) and N-acetylneuraminic acid (sialic acid), preferably from the group consisting of GlcNAc, Glc, Gal and GalNAc. More preferably S(F ) X is derived from Gal or GalNAc, and most preferably S(F ) X is derived from GalNAc.
- the 1 or 2 functional groups F in S(F ) X may be linked to the sugar or sugar derivative S in several ways.
- the 1 or 2 functional groups F may be bonded to C2, C3, C4 and/or C6 of the sugar or sugar derivative, instead of a hydroxyl (OH) group.
- OH hydroxyl
- fucose lacks an OH-group on C6, if F is bonded to C6 of Fuc, then F takes the place of an H-atom.
- F is an azido group, it is preferred that F is bonded to C2, C4 or C6.
- the one or more azide substituent in S(F ) X may be bonded to C2, C3, C4 or C6 of the sugar or sugar derivative S, instead of a hydroxyl (OH) group or, in case of 6-azidofucose (6- AzFuc), instead of a hydrogen atom.
- the N-acetyl substituent of an amino sugar derivative may be substituted by an azidoacetyl substituent.
- S(F ) X is selected from the group consisting of 2-azidoacetamido-2-deoxy-galactose (GalNAz), 2-azidodifluoroacetamido-2-deoxy-galactose (F2-GalNAz), 6-azido-6-deoxygalactose (6-AzGal), 6-azido-6-deoxy-2-acetamidogalactose (6-AzGalNAc or 6-N 3 -GalNAc), 4-azido-4- deoxy-2-acetamidogalactose (4-AzGalNAc), 6-azido-6-deoxy-2-azidoacetamido-2-deoxygalactose (6-AzGalNAz), 2-azidoacetamido-2-deoxyglucose (GlcNAz), 6-azido-6-deoxyglucose (6-AzGlc), 6-azidoacet
- S(F ))cP wherein F is an azido group are shown below.
- F is a keto group, it is preferred that F is bonded to C2 instead of the OH-group of S.
- F may be bonded to the N- atom of an amino sugar derivative, preferably a 2-amino sugar derivative.
- the sugar derivative then comprises an -NC(0)R 36 substituent.
- R 36 is preferably a C2 - C24 alkyl group, optionally sustituted. More preferably, R 36 is an ethyl group.
- S(F ) X is selected from the group consisting of 2-deoxy-(2-oxopropyl)galactose (2-ketoGal), 2-N- propionylgalactosamine (2-N-propionylGalNAc), 2-N-(4-oxopentanoyl)galactosamine (2-N- LevGal) and 2-N-butyrylgalactosamine (2-N-butyrylGalNAc), more preferably 2-ketoGalNAc and 2-N-propionylGalNAc.
- Examples of S(F )x-P wherein F is a keto group are shown below.
- F is an alkynyl group, preferably a terminal alkynyl group or a (hetero)cycloalkynyl group, it is preferred that said alkynyl group is present on a 2-amino sugar derivative.
- An example of S(F ) X wherein F is an alkynyl group is 2-(but-3-yonic acid amido)-2-deoxy-galactose.
- An example of S(F )x-P wherein F is an alkynyl group is shown below.
- F is selected from the group consisting of an azido group, a keto group and an alkynyl group.
- An azido group is an azide functional group -N3.
- a keto group is a -[C(R 37 )2]oC(0)R 36 group, wherein R 36 is a methyl group or an optionally substituted C2 - C24 alkyl group, R 37 is independently selected from the group consisting of hydrogen, halogen and R 36 , and o is 0 - 24, preferably 0 - 10, and more preferably 0, 1 , 2, 3, 4, 5 or 6.
- R 37 is hydrogen.
- alkynyl group is preferably a terminal alkynyl group or a (hetero)cycloalkynyl group as defined above.
- the alkynyl group is a -[C(R 37 )2]oC ⁇ C-R 37 group, wherein R 37 and o are as defined above; R 37 is preferably hydrogen.
- F is an azide or an alkyne moiety. Most preferably, F is an azido group (-N3). In one embodiment, F is an azide moiety, Q is an (cyclo)alkyne moiety, and Z 3 is a triazole moiety.
- S(F )x-P is selected from the group consisting of GalNAz-UDP (25), 6-AzGal-UDP (26), 6-AzGalNAc-UDP (6-azido-6-deoxy-N-acetylgalactosamine-UDP) (27), 4-AzGalNAz-UDP, 6- AzGalNAz-UDP, 6-AzGlc-UDP, 6-AzGlcNAz-UDP and 2-(but-3-yonic acid amido)-2-deoxy- galactose-UDP (28).
- S(F )x-P is GalNAz-UDP (25) or 6-AzGalNAc-UDP (27).
- Suitable catalyst that are capable of transferring the S(F ) X moiety to the core-GlcNAc moiety are known in the art.
- a suitable catalyst is a catalyst wherefore the specific sugar derivative nucleotide S(F )x-P in that specific process is a substrate. More specifically, the catalyst catalyzes the formation of a p(1 ,4)-glycosidic bond.
- the catalyst is selected from the group of galactosyltransferases and N-acetylgalactosaminyltransferases, more preferably from the group of j8(1 ,4)-N-acetylgalactosaminyltransferases (GalNAcT) and j8(1 ,4)-galactosyltransferases (GalT), most preferably from the group of j8(1 ,4)-N-acetylgalactosaminyltransferases having a mutant catalytic domain.
- the catalyst is a wild-type galactosyltransferase or N-acetylgalactosaminyl- transferase, preferably a N-acetylgalactosaminyltransferase.
- the catalyst is a mutant galactosyltransferase or N-acetylgalactosaminyltransferases, preferably a mutant N-acetylgalactosaminyltransferase. Mutant enzymes described in WO 2016/022027 and PCT/EP2016/059194 (WO 2016/170186) are especially preferred.
- sugar derivative S(F ) X is linked to the core-GlcNAc substituent in step (i), irrespective of whether said GlcNAc is fucosylated or not.
- Step (i) is preferably performed in a suitable buffer solution, such as for example phosphate, buffered saline (e.g. phosphate-buffered saline, tris-buffered saline), citrate, HEPES, tris and glycine.
- a suitable buffer solution such as for example phosphate, buffered saline (e.g. phosphate-buffered saline, tris-buffered saline), citrate, HEPES, tris and glycine.
- Suitable buffers are known in the art.
- the buffer solution is phosphate-buffered saline (PBS) or tris buffer.
- Step (i) is preferably performed at a temperature in the range of about 4 to about 50 °C, more preferably in the range of about 10 to about 45 °C, even more preferably in the range of about 20 to about 40 °C, and most preferably in the range of about 30 to about 37 °C.
- Step (i) is preferably performed a pH in the range of about 5 to about 9, preferably in the range of about 5.5 to about 8.5, more preferably in the range of about 6 to about 8. Most preferably, step (i) is performed at a pH in the range of about 7 to about 8.
- step (ii) the modified antibody is reacted with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L 2 to obtain the antibody-conjugate wherein linker L comprises S-Z 3 -L 2 and wherein Z 3 is a connecting group resulting from the reaction between Q and F .
- linker L comprises S-Z 3 -L 2 and wherein Z 3 is a connecting group resulting from the reaction between Q and F .
- linker-conjugates and preferred embodiments thereof are defined further below.
- the linker L 2 preferably comprises the group according to formula (1 ) or a salt thereof, and said linker is further defined below.
- Complementary functional groups Q for the functional group F on the modified antibody are known in the art.
- reactive group Q and functional group F are capable of reacting in a bioorthogonal reaction, as those reactions do not interfere with the biomolecules present during this reaction.
- Bioorthogonal reactions and functional groups suitable therein are known to the skilled person, for example from Gong and Pan, Tetrahedron Lett. 2015, 56, 2123-2132, and include Staudinger ligations and copper-free Click chemistry.
- Q is selected from the group consisting of 1 ,3-dipoles, alkynes, (hetero)cyclooctynes, cyclooctenes, tetrazines, ketones, aldehydes, alkoxyamines, hydrazines and triphenylphosphine.
- F is an azido group
- linking of the azide-modified antibody and the linker-conjugate preferably takes place via a cycloaddition reaction.
- Functional group Q is then preferably selected from the group consisting of alkynyl groups, preferably terminal alkynyl groups, and (hetero)cycloalkynyl groups.
- linking of the keto-modified antibody with the linker-conjugate preferably takes place via selective conjugation with hydroxylamine derivatives or hydrazines, resulting in respectively oximes or hydrazones.
- Functional group Q is then preferably a primary amino group, e.g. an -NH2 group, an aminooxy group, e.g. -O-NH2, or a hydrazinyl group, e.g. -N(H)NH2.
- the linker-conjugate is then preferably H 2 N-L 2 (D , H 2 N-0-L 2 (D or H 2 N-N(H)-L 2 (D respectively.
- linking of the alkyne-modified antibody with the linker-conjugate preferably takes place via a cycloaddition reaction, preferably a 1 ,3-dipolar cycloaddition.
- Functional group Q is then preferably a 1 ,3-dipole, such as an azide, a nitrone or a nitrile oxide.
- the linker-conjugate is then preferably N 3 -L 2 (D) r .
- an azide on the azide-modified antibody according to the invention reacts with an alkynyl group, preferably a terminal alkynyl group, or a (heter)cycloalkynyl group of the linker-conjugate via a cycloaddition reaction.
- This cycloaddition reaction of a molecule comprising an azide with a molecule comprising a terminal alkynyl group or a (hetero)cycloalkynyl group is one of the reactions that is known in the art as "click chemistry".
- the linker-conjugate comprises a (hetero)cycloalkynyl group, more preferably a strained (hetero)cycloalkynyl group.
- a suitable catalyst preferably a Cu(l) catalyst.
- the linker-conjugate comprises a (hetero)cycloalkynyl group, more preferably a strained (hetero)cycloalkynyl group.
- the (hetero)cycloalkynyl is a strained (hetero)cycloalkynyl group
- SPAAC strain-promoted azide-alkyne cycloaddition
- Strained (hetero)cycloalkynyl groups are known in the art and are described in more detail below.
- step (ii) comprises reacting a modified antibody with a linker-conjugate, wherein said linker-conjugate comprises a (hetero)cycloalkynyl group and one or more molecules of interest, wherein said modified antibody is an antibody comprising a GlcNAc- S(F )x substituent, wherein GlcNAc is an N-acetylglucosamine, wherein S(F ) X is a sugar derivative comprising x functional groups F wherein F is an azido group and x is 1 or 2, wherein said GlcNAc-S(F )x substituent is bonded to the antibody via C1 of the N-acetylglucosamine of said GlcNAc-S(F )x substituent, and wherein said GlcNAc is optionally fucosylated.
- said (hetero)cycloalkynyl group is a strained (hetero)cycloalkyn
- Target molecule D may be selected from the group consisting of an active substance, a reporter molecule, a polymer, a solid surface, a hydrogel, a nanoparticle, a microparticle and a biomolecule.
- active substance relates to a pharmacological and/or biological substance, i.e. a substance that is biologically and/or pharmaceutically active, for example a drug, a prodrug, a diagnostic agent, a protein, a peptide, a polypeptide, a peptide tag, an amino acid, a glycan, a lipid, a vitamin, a steroid, a nucleotide, a nucleoside, a polynucleotide, RNA or DNA.
- peptide tags include cell-penetrating peptides like human lactoferrin or polyarginine.
- An example of a glycan is oligomannose.
- An example of an amino acid is lysine.
- the active substance is preferably selected from the group consisting of drugs and prodrugs. More preferably, the active substance is selected from the group consisting of pharmaceutically active compounds, in particular low to medium molecular weight compounds (e.g. about 200 to about 2500 Da, preferably about 300 to about 1750 Da). In a further preferred embodiment, the active substance is selected from the group consisting of cytotoxins, antiviral agents, antibacterials agents, peptides and oligonucleotides.
- cytotoxins examples include colchicine, vinca alkaloids, anthracyclines, camptothecins, doxorubicin, daunorubicin, taxanes, calicheamycins, tubulysins, irinotecans, enediynes, an inhibitory peptide, amanitin, deBouganin, duocarmycins, maytansines, auristatins, indolinobenzodiazepines or pyrrolobenzodiazepines (PBDs).
- PBDs pyrrolobenzodiazepines
- preferred active substances include vinca alkaloids, anthracyclines, camptothecins, taxanes, tubulysins, amanitin, duocarmycins, maytansines, auristatins, indolinobenzodiazepines and pyrrolobenzodiazepines, in particular vinca alkaloids, anthracyclines, camptothecins, taxanes, tubulysins, amanitin, maytansines and auristatins.
- reporter molecule refers to a molecule whose presence is readily detected, for example a diagnostic agent, a dye, a fluorophore, a radioactive isotope label, a contrast agent, a magnetic resonance imaging agent or a mass label.
- fluorophores also referred to as fluorescent probes
- fluorescent probes A wide variety of fluorophores, also referred to as fluorescent probes, is known to a person skilled in the art.
- fluorophores are described in more detail in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3 rd Ed. 2013, Chapter 10: “Fluorescent probes", p. 395 - 463, incorporated by reference.
- fluorophore include all kinds of Alexa Fluor (e.g. Alexa Fluor 555), cyanine dyes (e.g.
- Cy3 or Cy5 and cyanine dye derivatives, coumarin derivatives, fluorescein and fluorescein derivatives, rhodamine and rhodamine derivatives, boron dipyrromethene derivatives, pyrene derivatives, naphthalimide derivatives, phycobiliprotein derivatives (e.g. allophycocyanin), chromomycin, lanthanide chelates and quantum dot nanocrystals.
- cyanine dye derivatives coumarin derivatives, fluorescein and fluorescein derivatives, rhodamine and rhodamine derivatives, boron dipyrromethene derivatives, pyrene derivatives, naphthalimide derivatives, phycobiliprotein derivatives (e.g. allophycocyanin), chromomycin, lanthanide chelates and quantum dot nanocrystals.
- preferred fluorophores include cyanine dyes, coumarin derivatives, fluorescein and derivatives thereof, pyrene derivatives, naphthalimide derivatives, chromomycin, lanthanide chelates and quantum dot nanocrystals, in particular coumarin derivatives, fluorescein, pyrene derivatives and chromomycin.
- radioactive isotope label examples include 99m Tc, ⁇ , 4m ln, 5 ln, 8 F, 4 C, 64 Cu, 3 ⁇ , 25 l, 2 3 l, 2 2 Bi, 88 Y, 90 Y, 67 Cu, 86 Rh, 88 Rh, 66 Ga, 67 Ga and 0 B, which is optionally connected via a chelating moiety such as e.g.
- DTPA diethylenetriaminepentaacetic anhydride
- DOTA diethylenetriaminepentaacetic anhydride
- DOTA diethylenetriaminepentaacetic anhydride
- DOTA diethylenetriaminepentaacetic anhydride
- DOTA diethylenetriaminepentaacetic anhydride
- DOTA diethylenetriaminepentaacetic anhydride
- DOTA dioxododecane-/V,/V',/V" /V'"-tetraacetic acid
- NOTA 1,4,7-triazacyclononane ⁇ , ⁇ ', ⁇ "- triacetic acid
- TETA 1,4,8, 1 1-tetraazacyclotetradecane-A/,A/',A/" A/"-tetraacetic acid
- DTTA N 1 - (p-isothiocyanatobenzy -diethylenetriamine-A/ ⁇ A/ 2 , A/ 3 ,A/ 3 -tetraacetic acid
- Isotopic labelling techniques are known to a person skilled in the art, and are described in more detail in e.g. G.T. Hermanson, “Bioconjugate Techniques", Elsevier, 3 rd Ed. 2013, Chapter 12: “Isotopic labelling techniques", p. 507 - 534, incorporated by reference.
- Polymers suitable for use as a target molecule D in the compound according to the invention are known to a person skilled in the art, and several examples are described in more detail in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3 rd Ed. 2013, Chapter 18: “PEGylation and synthetic polymer modification", p. 787 - 838, incorporated by reference.
- target molecule D is a polymer
- target molecule D is preferably independently selected from the group consisting of a polyethylene glycol (PEG), a polyethylene oxide (PEO), a polypropylene glycol (PPG), a polypropylene oxide (PPO), a 1 ,xx-diaminoalkane polymer (wherein xx is the number of carbon atoms in the alkane, and preferably xx is an integer in the range of 2 to 200, preferably 2 to 10), a (poly)ethylene glycol diamine (e.g. 1 ,8-diamino-3,6-dioxaoctane and equivalents comprising longer ethylene glycol chains), a polysaccharide (e.g.
- dextran a poly(amino acid) (e.g. a poly(L- lysine)) and a polyvinyl alcohol).
- a poly(amino acid) e.g. a poly(L- lysine)
- a polyvinyl alcohol e.g. a poly(L- lysine)
- preferred polymers include a 1 ,xx-diaminoalkane polymer and polyvinyl alcohol).
- Solid surfaces suitable for use as a target molecule D are known to a person skilled in the art.
- a solid surface is for example a functional surface (e.g. a surface of a nanomaterial, a carbon nanotube, a fullerene or a virus capsid), a metal surface (e.g. a titanium, gold, silver, copper, nickel, tin, rhodium or zinc surface), a metal alloy surface (wherein the alloy is from e.g.
- target molecule D is a solid surface, it is preferred that D is independently selected from the group consisting of a functional surface or a polymer surface.
- Hydrogels are known to the person skilled in the art. Hydrogels are water-swollen networks, formed by cross-links between the polymeric constituents. See for example A. S. Hoffman, Adv. Drug Delivery Rev. 2012, 64, 18, incorporated by reference.
- the target molecule is a hydrogel, it is preferred that the hydrogel is composed of poly(ethylene)glycol (PEG) as the polymeric basis.
- Micro- and nanoparticles suitable for use as a target molecule D are known to a person skilled in the art.
- a variety of suitable micro- and nanoparticles is described in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3 rd Ed. 2013, Chapter 14: “Microparticles and nanoparticles", p. 549 - 587, incorporated by reference.
- the micro- or nanoparticles may be of any shape, e.g. spheres, rods, tubes, cubes, triangles and cones.
- the micro- or nanoparticles are of a spherical shape.
- the chemical composition of the micro- and nanoparticles may vary.
- the micro- or nanoparticle is for example a polymeric micro- or nanoparticle, a silica micro- or nanoparticle or a gold micro- or nanoparticle.
- the polymer is preferably polystyrene or a copolymer of styrene (e.g.
- the surface of the micro- or nanoparticles is modified, e.g. with detergents, by graft polymerization of secondary polymers or by covalent attachment of another polymer or of spacer moieties, etc.
- Target molecule D may also be a biomolecule. Biomolecules, and preferred embodiments thereof, are described in more detail below. When target molecule D is a biomolecule, it is preferred that the biomolecule is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, lipids, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides, enzymes, hormones, amino acids and monosaccharides. Preferred options for D are described further below for the antibody-conjugate according to the third aspect. The bioconjugates in the context of the present invention may contain more than one target molecule D, which may be the same or different.
- r 2.
- those target molecules are different, more preferably they both are active substances, more preferably anti-cancer agents, most preferably cytotoxins.
- the bioconjugate of the present invention comprises two distinct target molecules, preferably two distinct active substances, more preferably two distinct anti-cancer agents, most preferably two distinct cytotoxins.
- the linker-conjugate comprises a (hetero)cycloalkynyl group.
- said linker-conjugate has the Formula (31 ): c
- - L 2 is a linker as defined herein;
- - D is a target molecule
- - r is 1 - 20;
- R 3 is independently selected from the group consisting of hydrogen, halogen, -OR 35 , -NO2, -CN, -S(0)2R 35 , Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R 3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R 35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 -
- - X is C(R 3 )2, O, S or NR 32 , wherein R 32 is R 3 or L 2 (D , and wherein L 2 , D and r are as defined above;
- - aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8.
- said linker-con ugate has the Formula (31 b):
- - L 2 is a linker as defined herein;
- - D is a target molecule
- - r is 1 - 20;
- R 3 is independently selected from the group consisting of hydrogen, halogen, -OR 35 , -NO2, -CN, -S(0)2R 35 , Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R 3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R 35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7
- - X is C(R 3 )2, O, S or NR 32 , wherein R 32 is R 3 or L 2 (D , and wherein L 2 , D and r are as defined above;
- - aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8;
- - aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8;
- aa + aa' is 4, 5, 6 or 7, more preferably aa + aa' is 4, 5 or 6 and most preferably aa + aa' is 5.
- said linker-conjugate has the Formula (31c):
- - L 2 is a linker as defined herein;
- - D is a target molecule
- - r is 1 - 20;
- - 1 is 0 - 10.
- X is C(R 3 )2, O, S or NR 31 .
- a is 5, i.e. said (hetero)cycloalkynyl group is preferably a (hetero)cyclooctyne group.
- X is C(R 32 )2 or NR 32 . When X is C(R 32 )2 it is preferred that R 32 is hydrogen. When X is NR 32 , it is preferred that R 32 is L 2 (D) r . In yet another preferred embodiment, r is 1 to 10, more preferably, r is 1 , 2, 3, 4, 5, 6 7 or 8, more preferably r is 1 , 2, 3, 4, 5 or 6, most preferably r is 1 , 2, 3 or 4.
- the L 2 (D) r substituent may be present on a C-atom in said (hetero)cycloalkynyl group, or, in case of a heterocycloalkynyl group, on the heteroatom of said heterocycloalkynyl group.
- the (hetero)cycloalkynyl group comprises substituents, e.g. an annelated cycloalkyl
- the L 2 (D) r substituent may also be present on said substituents.
- the methods to connect a linker L 2 to a (hetero)cycloalkynyl group on the one end and to a target molecule on the other end, in order to obtain a linker-conjugate, depend on the exact the nature of the linker, the (hetero)cycloalkynyl group and the target molecule. Suitable methods are known in the art.
- the linker-conjugate comprises a (hetero)cyclooctyne group, more preferably a strained (hetero)cyclooctyne group.
- Suitable (hetero)cycloalkynyl moieties are known in the art.
- DIFO, DIF02 and DIF03 are disclosed in US 2009/0068738, incorporated by reference.
- DIBO is disclosed in WO 2009/067663, incorporated by reference.
- DIBO may optionally be sulphated (S-DIBO) as disclosed in J. Am. Chem. Soc. 2012, 134, 5381 .
- BARAC is disclosed in J. Am. Chem. Soc. 2010, 132, 3688 - 3690 and US 201 1/0207147, all incorporated by reference.
- linker-conjugates comprising a (hetero)cyclooctyne group are shown below.
- DIBAC also known as ADIBO or DBCO
- BCN cyclooctyne moieties that are known in the art. DIBAC is disclosed in Chem. Commun. 2010, 46, 97 - 99, incorporated by reference. BCN is disclosed in WO 201 1/136645, incorporated by reference.
- said linker-conjugate has the Formula (32), (33), (34), (35) or (36). In another preferred embodiment, said linker-con ugate has the Formula (37):
- - Y is O, S or NR 32 , wherein R 32 is as defined above; - R 33 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- R 34 is selected from the group consisting of hydrogen, Y-L 2 (D) r , -(CH2)nn-Y-L 2 (D) r , halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups, the alkyl groups optionally being interrupted by one of more hetero-atoms selected from the group consisting of O, N and S, wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are independently optionally substituted; and
- - nn is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10.
- R 3 is hydrogen.
- R 33 is hydrogen.
- n is 1 or 2.
- R 34 is hydrogen, Y-L 2 (D) r or -(CH2)nn-Y-L 2 (D) r .
- R 32 is hydrogen or L 2 (D) r .
- the linker-conjugate has the Formula 38:
- said linker-conjugate has the Formula (39):
- said linker-conjugate has the Formula (35):
- pp and the nature of M depend on the azide-substituted sugar or sugar derivative S(F )x that is present in the azide-modified antibody according to the invention that is linked to a linker-conjugate. If an azide in S(F ) X is present on the C2, C3, or C4 position of the sugar or the sugar derivative (instead of a sugar OH-group), then pp is 0. If the S(F ) X is an azidoacetamido-2- deoxy-sugar derivative, S(F ) X is e.g.
- pp is 1 and M is -N(H)C(0)CH2-. If the azide in S(F ) X is present on the C6 position of the sugar or the sugar derivative, then pp is 0 and M is absent.
- Linkers also referred to as linking units, are well known in the art.
- L is linked to a target molecule as well as to a functional group Q .
- L 2 may for example be selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cycloalkylene groups, C5-C200 cycloalkenylene groups, C8-C200 cycloalkynylene groups, C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups, C9-C200 arylalkynylene groups.
- alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups may be substituted, and optionally said groups may be interrupted by one or more heteroatoms, preferably 1 to 100 heteroatoms, said heteroatoms preferably being selected from the group consisting of O, S and NR 35 , wherein R 35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups.
- heteroatom is O.
- suitable linking units include (poly)ethylene glycol diamines (e.g. 1 ,8-diamino-3,6-dioxaoctane or equivalents comprising longer ethylene glycol chains), polyethylene glycol or polyethylene oxide chains, polypropylene glycol or polypropylene oxide chains and 1 , ⁇ -diaminoalkanes wherein xx is the number of carbon atoms in the alkane.
- cleavable linkers Another class of suitable linkers comprises cleavable linkers.
- Cleavable linkers are well known in the art. For example Shabat ef a/. , Soft Matter 2012, 6, 1073, incorporated by reference herein, discloses cleavable linkers comprising self-immolative moieties that are released upon a biological trigger, e.g. an enzymatic cleavage or an oxidation event.
- cleavable linkers are peptide-linkers that are cleaved upon specific recognition by a protease, e.g.
- cathepsin plasmin or metalloproteases, or glycoside-based linkers that are cleaved upon specific recognition by a glycosidase, e.g. glucuronidase, or nitroaromatics that are reduced in oxygen- poor, hypoxic areas.
- a glycosidase e.g. glucuronidase
- nitroaromatics that are reduced in oxygen- poor, hypoxic areas.
- Preferred linkers L 2 are defined further below for the embodiment on "sulfamide linkage" as well as for the antibody-conjugate according to the third aspect. Preferred linker-conjugates are also defined further below.
- Step (ii) is preferably performed at a temperature in the range of about 20 to about 50 °C, more preferably in the range of about 25 to about 45 °C, even more preferably in the range of about 30 to about 40 °C, and most preferably in the range of about 32 to about 37 °C.
- Step (ii) is preferably performed a pH in the range of about 5 to about 9, preferably in the range of about 5.5 to about 8.5, more preferably in the range of about 6 to about 8. Most preferably, step (ii) is performed at a pH in the range of about 7 to about 8.
- Step (ii) is preferably performed in water. More preferably, said water is purified water, even more preferably ultrapure water or Type I water as defined according to ISO 3696.
- Suitable water is for example milliQ® water. Said water is preferably buffered, for example with phosphate-buffered saline or tris. Suitable buffers are known to a person skilled in the art.
- step (ii) is performed in milliQ water which is buffered with phosphate-buffered saline or tris.
- the reaction of step (ii) is a(n) (cyclo)alkyne-azide conjugation to from a connecting moiety Z 3 that is represented by (10e), (10i), (10g), (10j) or (10k), preferably by (10e), (10i), (1
- cycle A is a 7-10-membered (hetero)cyclic moiety.
- Connecting moieties (10e), (10j) and (10k) may exist in either one of the possible two regioisomers.
- bioconjugate that comprises or that is obtained by the present mode of conjugation is preferably represented by Formula (40) or (40b):
- - AB is an antibody
- S is a sugar or a sugar derivative
- GlcNAc is N-acetylglucosamine
- - R 3 is independently selected from the group consisting of hydrogen, halogen, -OR 35 , -NO2, -CN, -S(0)2R 35 , Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R 3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R 35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24
- - X is C(R 3 )2, O, S or NR 32 , wherein R 32 is R 3 or L 2 (D , wherein L 2 is a linker, and D is as defined in claim 1 ;
- - r is 1 - 20;
- - aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8;
- - aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8;
- - b is 0 or 1 ;
- - pp is 0 or 1 ;
- - M is -N(H)C(0)CH 2 - -N(H)C(0)CF 2 -, -CH2-, -CF 2 - or a 1 ,4-phenylene containing 0 - 4 fluorine substituents, preferably 2 fluorine substituents which are preferably positioned on C2 and C6 or on C3 and C5 of the phenylene;
- the antibody-conjugate according to the invention is of the Formula (41 ):
- AB, L 2 , D, Y, S, M, x, y, b, pp, R 32 , GlcNAc, R 3 , R 33 , R 34 , nn and r are as defined above and wherein said N-acetylglucosamine is optionally fucosylated (b is 0 or 1 ).
- R 3 , R 33 and R 34 are hydrogen and nn is 1 or 2, and in an even more preferred embodiment x is 1.
- the antibody-conjugate is of the Formula (42):
- N- acetylglucosamine is optionally fucosylated (b is 0 or 1 ); or according to regioisomer (42b):
- AB, L 2 , D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated.
- AB, L 2 , D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated.
- the antibody-conjugate is of the Formula (40c):
- AB, L 2 , D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated.
- the antibody-conjugate is of the Formula (40d):
- AB, L 2 , D, S, b, pp, x, y, M and GlcNAc are as defined above, wherein I is 0 - 10 and wherein said N-acetylglucosamine is optionally fucosylated.
- the mode of conjugation according to the invention is referred to as "sulfamide linkage", which refers to the presence of a specific linker L which links the biomolecule B and the target molecule D. All said about the linker L in the context of the present embodiment preferably also applies to the linker, in particular linker L 2 , according to the embodiment on core- GlcNAc functionalization as mode of conjugation.
- the linker L comprises a group according to formula (1 ) or a salt thereof:
- - a is 0 or 1 ; and - R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, wherein D is optionally connected to N via a spacer moiety.
- the salt is preferably a pharmaceutically acceptable salt.
- linker L according to the invention comprises a group according to formula (1 ) wherein a is 0, or a salt thereof.
- linker L thus comprises a group according to formula (2) or a salt thereof:
- linker L according to the invention comprises a group according to formula (1 ) wherein a is 1 , or a salt thereof.
- linker L thus comprises a group according to formula (3) or a salt thereof:
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, wherein D is optionally connected to N via a spacer moiety; In a preferred
- R is hydrogen.
- R is a Ci - C20 alkyl group, more preferably a Ci - C16 alkyl group, even more preferably a Ci - C10 alkyl group, wherein the alkyl group is optionally interrupted by one or more O-atoms, and wherein the alkyl group is optionally substituted with an -OH group, preferably a terminal -OH group.
- R is a (poly)ethyleneglycol chain comprising a terminal -OH group.
- R is selected from the group consisting of hydrogen, methyl, ethyl, n- propyl, i-propyl, n-butyl, s-butyl and t-butyl, more preferably from the group consisting of hydrogen, methyl, ethyl, n-propyl and i-propyl, and even more preferably from the group consisting of hydrogen, methyl and ethyl. Yet even more preferably R is hydrogen or methyl, and most preferably R is hydrogen.
- R is a further target molecule D.
- D is connected to N via one or more spacer-moieties.
- the spacer-moiety if present, is defined as a moiety that spaces, i.e. provides a certain distance between, and covalently links D and N.
- Target molecule D and preferred embodiments thereof are defined in more detail above.
- the group of formula (1 ) can be introduced in one of three options.
- the linker L comprising the group according to formula (1 ) or a salt thereof may be present in the linker-conjugate represented by Q -D, wherein L is the spacer between Q and D.
- the linker L comprising the group according to formula (1 ) or a salt thereof may be present in the biomolecule represented by B-F , wherein L is the spacer between B and F .
- the group according to formula (1 ) or a salt thereof may be formed during the conjugation reaction itself. In the latter option, Q and F are selected as such that their reaction product, i.e.
- connecting group Z 3 contains or is the group according to formula (1 ) or a salt thereof.
- the group according to formula (1 ) or a salt thereof is introduced according to the first or second of the above mentioned options, most preferably according to the first option.
- the positive effect on solubility and absence of in-process aggregation, as recited above improve the efficiency of the conjugation reaction.
- the group according to formula (1 ) or a salt thereof is present in the linker-conjugate, even hydrophobic drugs can readily be subjected to the conjugation reaction.
- the linker-conjugate is represented by Q -D, preferably by Q -L-D, wherein D is a target molecule, L is a linker linking Q and D as further defined above, Q is a reactive group capable of reacting with functional group F on the biomolecule and each occurrence of "-" is independently a bond or a spacer moiety. In one embodiment, "-" is a spacer moiety as defined herein. In one embodiment, "-" is a bond, typically a covalent bond.
- the linker-conjugate is a compound wherein a target molecule is covalently connected to a reactive group Q , preferably via a linker or spacer, most preferably via linker L as defined above. The linker-conjugate may be obtained via reaction of a reactive group Q 2 present on a linker-construct with a reactive group present on a target molecule.
- the group according to formula (1 ), or the salt thereof is situated in between Q and D.
- reactive group Q is covalently bonded to a first end of the group according to formula (1 )
- target molecule D is covalently bonded to a second end of the group according to formula (1 ).
- first end and second end both refer to either the carbonyl or carboxy end of the group according to formula (1 ) or to the sulfamide end of the group according to formula (1 ), but logically not to the same end.
- the linker-conjugate according to the invention may comprise more than one target molecule D, e.g. two, three, four, five, etc. Consequently, the linker-conjugate may thus comprise more than one "second end".
- the linker-conjugate may comprise more than one reactive group Q , i.e. the linker-conjugate may comprise more than one first end.
- the groups Q may be the same or different, and when more than one target molecule D is present the target molecule D may be the same or different.
- the linker-conjugate according to the invention may therefore also be denoted as (Q ) y Sp(D) z , wherein y' is an integer in the range of 1 to 10 and z is an integer in the range of 1 to 10.
- y' is an integer in the range of 1 to 10
- z is an integer in the range of 1 to 10.
- - y' is an integer in the range of 1 to 10;
- - z is an integer in the range of 1 to 10;
- - Q is a reactive group capable of reacting with a functional group F present on a biomolecule
- - Sp is a spacer moiety, wherein a spacer moiety is defined as a moiety that spaces (i.e. provides a certain distance between) and covalently links reactive group Q and target molecule D, preferably wherein said spacer moiety is linker L as defined above, and thus comprises a group according to formula (1 ) or a salt thereof.
- y' is 1 , 2, 3 or 4, more preferably y' is 1 or 2 and most preferably, y' is 1.
- z is 1 , 2, 3, 4, 5 or 6, more preferably z is 1 , 2, 3 or 4, even more preferably z is 1 , 2 or 3, yet even more preferably z is 1 or 2 and most preferably z is 1. More preferably, y' is 1 or 2, preferably 1 , and z is 1 , 2, 3 or 4, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 , 2 or 3, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 or 2, and most preferably y' is 1 and z is 1.
- the linker-conjugate is according to the formula Q Sp(D)4, Q Sp(D)3, Q Sp(D) 2 or Q SpD.
- D is preferably an "active substance” or "pharmaceutically active substance", and refers to a pharmacological and/or biological substance, i.e. a substance that is biologically and/or pharmaceutically active, for example a drug, a prodrug, a diagnostic agent.
- the active substance is selected from the group consisting of drugs and prodrugs. More preferably, the active substance is a pharmaceutically active compounds, in particular low to medium molecular weight compounds (e.g. about 200 to about 2500 Da, preferably about 300 to about 1750 Da).
- the active substance is selected from the group consisting of cytotoxins, antiviral agents, antibacterials agents, peptides and oligonucleotides.
- cytotoxins include colchicine, vinca alkaloids, anthracyclines, camptothecins, doxorubicin, daunorubicin, taxanes, calicheamycins, tubulysins, irinotecans, enediynes, an inhibitory peptide, amanitin, deBouganin, duocarmycins, maytansines, auristatins, pyrrolobenzodiazepines (PBDs) or indolinobenzodiazepines (IBDs).
- PBDs pyrrolobenzodiazepines
- IBDs indolinobenzodiazepines
- Preferred active substances include enediynes, anthracyclines, camptothecins, taxanes, tubulysins, amanitin, duocarmycins, maytansines, auristatins, pyrrolobenzodiazepines or indolinobenzodiazepines, in particular enediynes, anthracyclines, pyrrolobenzodiazepines (PBDs), maytansines and auristatins.
- PBDs pyrrolobenzodiazepines
- the linker-conjugate comprises a reactive group Q that is capable of reacting with a functional group F present on a biomolecule.
- Functional groups are known to a person skilled in the art and may be defined as any molecular entity that imparts a specific property onto the molecule harbouring it.
- a functional group in a biomolecule may constitute an amino group, a thiol group, a carboxylic acid, an alcohol group, a carbonyl group, a phosphate group, or an aromatic group.
- the functional group in the biomolecule may be naturally present or may be placed in the biomolecule by a specific technique, for example a (bio)chemical or a genetic technique.
- the functional group that is placed in the biomolecule may be a functional group that is naturally present in nature, or may be a functional group that is prepared by chemical synthesis, for example an azide, a terminal alkyne or a phosphine moiety.
- the term "reactive group” may refer to a certain group that comprises a functional group, but also to a functional group itself.
- a cyclooctynyl group is a reactive group comprising a functional group, namely a C- C triple bond.
- an N-maleimidyl group is a reactive group, comprising a C-C double bond as a functional group.
- a functional group for example an azido functional group, a thiol functional group or an amino functional group, may herein also be referred to as a reactive group.
- the linker-conjugate may comprise more than one reactive group Q .
- the linker-conjugate comprises two or more reactive groups Q , the reactive groups Q may differ from each other.
- the linker-conjugate comprises one reactive group Q .
- Reactive group Q that is present in the linker-conjugate is able to react with a functional group F that is present in a biomolecule to form connecting group Z 3 .
- reactive group Q needs to be complementary to a functional group F present in a biomolecule.
- a reactive group is denoted as "complementary" to a functional group when said reactive group reacts with said functional group selectively to form connecting group Z 3 , optionally in the presence of other functional groups.
- Complementary reactive and functional groups are known to a person skilled in the art, and are described in more detail below.
- reactive group Q is selected from the group consisting of, optionally substituted, N-maleimidyl groups, halogenated N-alkylamido groups, sulfonyloxy N-alkylamido groups, ester groups, carbonate groups, sulfonyl halide groups, thiol groups or derivatives thereof, alkenyl groups, alkynyl groups, (hetero)cycloalkynyl groups, bicyclo[6.1.0]non-4-yn-9-yl] groups, cycloalkenyl groups, tetrazinyl groups, azido groups, phosphine groups, nitrile oxide groups, nitrone groups, nitrile imine groups, diazo groups, ketone groups, (O-alkyl)hydroxylamino groups, hydrazine groups, halogenated N-maleimidyl groups, 1 , 1-bis(sulfonylmethyl)methylcarbonyl groups or elimination derivative
- Q is an N-maleimidyl group.
- Q is preferably unsubstituted.
- Q is thus preferably according to formula (9a), as shown below.
- a preferred example of such a maleimidyl group is 2,3-diaminopropionic acid (DPR) maleimidyl, which may be connected to the remainder of the linker-conjugate through the carboxylic acid moiety.
- DPR 2,3-diaminopropionic acid
- Q is a halogenated N-alkylamido group.
- Q is according to formula (9b), as shown below, wherein k is an integer in the range of 1 to 10 and R 4 is selected from the group consisting of -CI, -Br and -I.
- k is 1 , 2, 3 or 4, more preferably k is 1 or 2 and most preferably k is 1.
- R 4 is -I or -Br. More preferably, k is 1 or 2 and R 4 is -I or -Br, and most preferably k is 1 and R 4 is -I or Br.
- Q is a sulfonyloxy N-alkylamido group.
- Q is a sulfonyloxy N-alkylamido group
- Q is according to formula (9b), as shown below, wherein k is an integer in the range of 1 to 10 and R 4 is selected from the group consisting of -O-mesyl, -O-phenylsulfonyl and -O-tosyl.
- k is 1 , 2, 3 or 4, more preferably k is 1 or 2, even more preferably k is 1 .
- R 4 is selected from the group consisting of -O-mesyl, -O-phenylsulfonyl and -O-tosyl.
- Q is an ester group.
- the ester group is an activated ester group.
- Activated ester groups are known to the person skilled in the art.
- An activated ester group is herein defined as an ester group comprising a good leaving group, wherein the ester carbonyl group is bonded to said good leaving group.
- Good leaving groups are known to the person skilled in the art.
- the activated ester is according to formula (9c), as shown below, wherein R 5 is selected from the group consisting of -N-succinimidyl (NHS), -N-sulfo-succinimidyl (sulfo-NHS), -(4-nitrophenyl), -pentafluorophenyl or -tetrafluorophenyl (TFP).
- R 5 is selected from the group consisting of -N-succinimidyl (NHS), -N-sulfo-succinimidyl (sulfo-NHS), -(4-nitrophenyl), -pentafluorophenyl or -tetrafluorophenyl (TFP).
- Q is a carbonate group.
- the carbonate group is an activated carbonate group.
- Activated carbonate groups are known to a person skilled in the art.
- An activated carbonate group is herein defined as a carbonate group comprising a good leaving group, wherein the carbonate carbonyl group is bonded to said good leaving group.
- the carbonate group is according to formula (9d), as shown below, wherein R 7 is selected from the group consisting of -N- succinimidyl, -N-sulfo-succinimidyl, -(4-nitrophenyl), -pentafluorophenyl or -tetrafluorophenyl.
- Q is a sulfonyl halide group according to formula (9e) as shown below, wherein X is selected from the group consisting of F, CI, Br and I.
- X is CI or Br, more preferably CI.
- Q is a thiol group (9f), or a derivative or a precursor of a thiol group.
- a thiol group may also be referred to as a mercapto group.
- the thiol derivative is preferably according to formula (9g), (9h) or (9zb) as shown below, wherein R 8 is an, optionally substituted, Ci - C12 alkyl group or a C2 - C12 (hetero)aryl group, V is O or S and R 6 is an, optionally substituted, Ci - C12 alkyl group.
- R 8 is an, optionally substituted, Ci - C6 alkyl group or a C2 - C6 (hetero)aryl group, and even more preferably R 8 is methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl, t-butyl or phenyl. Even more preferably, R 8 is methyl or phenyl, most preferably methyl.
- R 6 is an optionally substituted Ci - C6 alkyl group, and even more preferably R 6 is methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl or t-butyl, most preferably methyl.
- Q is a thiol-derivative according to formula (9g) or (9zb)
- Q is reacted with a reactive group F on a biomolecule
- said thiol- derivative is converted to a thiol group during the process.
- Q is according to formula (9h)
- Q is -SC(0)OR 8 or -SC(S)OR 8 , preferably SC(0)OR 8 , wherein R 8 , and preferred embodiments thereof, are as defined above.
- Q is an alkenyl group, wherein the alkenyl group is linear or branched, and wherein the alkenyl group is optionally substituted.
- the alkenyl group may be a terminal or an internal alkenyl group.
- the alkenyl group may comprise more than one C-C double bond, and if so, preferably comprises two C-C double bonds.
- the alkenyl group is a dienyl group, it is further preferred that the two C-C double bonds are separated by one C-C single bond (i.e. it is preferred that the dienyl group is a conjugated dienyl group).
- said alkenyl group is a C2 - C24 alkenyl group, more preferably a C2 - C12 alkenyl group, and even more preferably a C2 - C6 alkenyl group. It is further preferred that the alkenyl group is a terminal alkenyl group. More preferably, the alkenyl group is according to formula (9i) as shown below, wherein I is an integer in the range of 0 to 10, preferably in the range of 0 to 6, and p is an integer in the range of 0 to 10, preferably 0 to 6. More preferably, I is 0, 1 , 2, 3 or 4, more preferably I is 0, 1 or 2 and most preferably I is 0 or 1 .
- p is 0, 1 , 2, 3 or 4, more preferably p is 0, 1 or 2 and most preferably p is 0 or 1. It is particularly preferred that p is 0 and I is 0 or 1 , or that p is 1 and I is 0 or 1.
- Q is an alkynyl group, wherein the alkynyl group is linear or branched, and wherein the alkynyl group is optionally substituted.
- the alkynyl group may be a terminal or an internal alkynyl group.
- said alkynyl group is a C2 - C24 alkynyl group, more preferably a C2 - C12 alkynyl group, and even more preferably a C2 - C6 alkynyl group. It is further preferred that the alkynyl group is a terminal alkynyl group.
- the alkynyl group is according to formula (9j) as shown below, wherein I is an integer in the range of 0 to 10, preferably in the range of 0 to 6. More preferably, I is 0, 1 , 2, 3 or 4, more preferably I is 0, 1 or 2 and most preferably I is 0 or 1. In a further preferred embodiment, the alkynyl group is according to formula (9j) wherein I is 3.
- Q is a cycloalkenyl group.
- the cycloalkenyl group is optionally substituted.
- said cycloalkenyl group is a C3 - C24 cycloalkenyl group, more preferably a C3 - C12 cycloalkenyl group, and even more preferably a C3 - Cs cycloalkenyl group.
- the cycloalkenyl group is a irans-cycloalkenyl group, more preferably a trans- cyclooctenyl group (also referred to as a TCO group) and most preferably a irans-cyclooctenyl group according to formula (9zi) or (9zj) as shown below.
- the cycloalkenyl group is a cyclopropenyl group, wherein the cyclopropenyl group is optionally substituted.
- the cycloalkenyl group is a norbornenyl group, an oxanorbornenyl group, a norbornadienyl group or an oxanorbornadienyl group, wherein the norbornenyl group, oxanorbornenyl group, norbornadienyl group or an oxanorbornadienyl group is optionally substituted.
- the cycloalkenyl group is according to formula (9k), (9I), (9m) or (9zc) as shown below, wherein T is CH2 or O, R 9 is independently selected from the group consisting of hydrogen, a linear or branched Ci - C12 alkyl group or a C4 - C12 (hetero)aryl group, and R 9 is selected from the group consisting of hydrogen and fluorinated hydrocarbons.
- R 9 is independently hydrogen or a Ci - C6 alkyl group, more preferably R 9 is independently hydrogen or a Ci - C4 alkyl group.
- R 9 is independently hydrogen or methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 9 is independently hydrogen or methyl.
- R 9 is selected from the group of hydrogen and -CF3, -C2F5, -C3F7 and -C4F9, more preferably hydrogen and -CF3.
- the cycloalkenyl group is according to formula (9k), wherein one R 9 is hydrogen and the other R9 is a methyl group.
- the cycloalkenyl group is according to formula (9I), wherein both R 9 are hydrogen.
- the cycloalkenyl group is a norbornenyl (T is CH2) or an oxanorbornenyl (T is O) group according to formula (9m), or a norbornadienyl (T is CH2) or an oxanorbornadienyl (T is O) group according to formula (9zc), wherein R 9 is hydrogen and R 9 is hydrogen or -CF3, preferably -CF3.
- Q is a (hetero)cycloalkynyl group.
- the (hetero)cycloalkynyl group is optionally substituted.
- the (hetero)cycloalkynyl group is a (hetero)cyclooctynyl group, i.e. a heterocyclooctynyl group or a cyclooctynyl group, wherein the (hetero)cyclooctynyl group is optionally substituted.
- the (hetero)cyclooctynyl group is substituted with one or more halogen atoms, preferably fluorine atoms, more preferably the (hetero)cyclooctynyl group is substituted with one fluorine atom, as in mono-fluoro-cyclooctcyne (MFCO).
- MFCO mono-fluoro-cyclooctcyne
- the mono-fluoro-cyclooctcyne group is according to formula (9zo).
- the (hetero)cyclooctynyl group is according to formula (9n), also referred to as a DIBO group, (9o), also referred to as a DIBAC group or (9p), also referred to as a BARAC group, or (9zk), also referred to as a COMBO group, all as shown below, wherein U is O or NR 9 , and preferred embodiments of R 9 are as defined above.
- the aromatic rings in (9n) are optionally O-sulfonylated at one or more positions, whereas the rings of (9o) and (9p) may be halogenated at one or more positions.
- U is preferably O.
- the nitrogen atom attached to R in compound (4b) is the nitrogen atom in the ring of the heterocycloalkyne group such as the nitrogen atom in (9o).
- c, d and g are 0 in compound (4b) and R and Q , together with the nitrogen atom they are attached to, form a heterocycloalkyne group, preferably a heterocyclooctyne group, most preferably the heterocyclooctyne group according to formula (9o) or (9p).
- the carbonyl moiety of (9o) is replaced by the sulfonyl group of the group according to formula (1 ).
- the nitrogen atom to which R is attached is the same atom as the atom designated as U in formula (9n).
- Q is an, optionally substituted, bicyclo[6.1.0]non-4-yn-9-yl] group, also referred to as a BCN group.
- the bicyclo[6.1.0]non-4-yn-9-yl] group is according to formula (9q) as shown below.
- Q is a conjugated (hetero)diene group capable of reacting in a Diels-Alder reaction.
- Preferred (hetero)diene groups include optionally substituted tetrazinyl groups, optionally substituted 1 ,2-quinone groups and optionally substituted triazine groups. More preferably, said tetrazinyl group is according to formula (9r), as shown below, wherein R 9 is selected from the group consisting of hydrogen, a linear or branched Ci - C12 alkyl group or a C4 - C12 (hetero)aryl group.
- R 9 is hydrogen, a Ci - Ce alkyl group or a C4 - C10 (hetero)aryl group, more preferably R 9 is hydrogen, a Ci - C4 alkyl group or a C4 - C6 (hetero)aryl group. Even more preferably R 9 is hydrogen, methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl, t- butyl or pyridyl. Yet even more preferably R 9 is hydrogen, methyl or pyridyl. More preferably, said 1 ,2-quinone group is according to formula (9zl) or (9zm).
- Said triazine group may be any regioisomer. More preferably, said triazine group is a 1 ,2,3-triazine group or a 1 ,2,4-triazine group, which may be attached via any possible location, such as indicated in formula (9zn). The 1 ,2,3-triazine is most preferred as triazine group.
- Q is an azido group according to formula (9s) as shown below.
- Q is an, optionally substituted, triarylphosphine group that is suitable to undergo a Staudinger ligation reaction.
- the phosphine group is according to forumula (9t) as shown below, wherein R 0 is a (thio)ester group.
- R 0 is a (thio)ester group
- R 0 is -C(0)-V-R 11 , wherein V is O or S and R is a Ci - C12 alkyl group.
- R is a Ci - C6 alkyl group, more preferably a Ci - C4 alkyl group.
- R is a methyl group.
- Q is a nitrile oxide group according to formula (9u) as shown below.
- Q is a nitrone group.
- the nitrone group is according to formula (9v) as shown below, wherein R 2 is selected from the group consisting of linear or branched Ci - C12 alkyl groups and C6 - C12 aryl groups.
- R 2 is a Ci - C6 alkyl group, more preferably R 2 is a Ci - C4 alkyl group.
- R 2 is methyl, ethyl, n-propyl, i- propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 2 is methyl.
- Q is a nitrile imine group.
- the nitrile imine group is according to formula (9w) or (9zd) as shown below, wherein R 3 is selected from the group consisting of linear or branched Ci - C12 alkyl groups and C6 - C12 aryl groups.
- R 3 is a Ci - C6 alkyl group, more preferably R 3 is a Ci - C4 alkyl group.
- R 3 is methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 3 is methyl.
- Q is a diazo group.
- the diazo group is according to formula (9x) as shown below, wherein R 4 is selected from the group consisting of hydrogen or a carbonyl derivative. More preferably, R 4 is hydrogen.
- Q is a ketone group. More preferably, the ketone group is according to formula (9y) as shown below, wherein R 5 is selected from the group consisting of linear or branched Ci - C12 alkyl groups and C6 - C12 aryl groups.
- R 5 is a Ci - C6 alkyl group, more preferably R 5 is a Ci - C4 alkyl group.
- R 5 is methyl, ethyl, n- propyl, i-propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 5 is methyl.
- Q is an (O-alkyl)hydroxylamino group. More preferably, the (O- alkyl)hydroxylamino group is according to formula (9z) as shown below.
- Q is a hydrazine group.
- the hydrazine group is according to formula (9za) as shown below.
- Q is a halogenated N-maleimidyl group or a sulfonylated N- maleimidyl group.
- Q is preferably according to formula (9ze) as shown below, wherein R 6 is independently selected from the group consisting of hydrogen F, CI, Br, I -SR 8a and -OS(0)2R 8b , wherein R 8a is an optionally substituted C4 - C12 (hetero)aryl groups, preferably phenyl or pyrydyl, and R 8b is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups, preferably tolyl or methyl, and with the proviso that at least one R 6 is not hydrogen.
- R 6 is halogen (i.e. when R 6 is F, CI, Br or I), it is preferred that R 6 is Br.
- the halogenated N-maleimidyl group is halogentated 2,3-diaminopropionic acid (DPR) maleimidyl, which may be connected to the remainder of the linker-conjugate through the carboxylic acid moiety.
- DPR 2,3-diaminopropionic acid
- Q is a carbonyl halide group according to formula (9zf) as shown below, wherein X is selected from the group consisting of F, CI, Br and I.
- X is CI or Br, and most preferably, X is CI.
- Q is an allenamide group according to formula (9zg).
- Q is a 1 , 1-bis(sulfonylmethyl)methylcarbonyl group according to formula (9zh), or an elimination derivative thereof, wherein R 8 is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups. More preferably, R 8 is an, optionally substituted, Ci - C6 alkyl group or a C4 - C6 (hetero)aryl group, and most preferably a phenyl group.
- conjugation is accomplished via a cycloaddition, such as a Diels-Alder reaction or a 1 ,3-dipolar cycloaddition, preferably the 1 ,3-dipolar cycloaddition.
- the reactive group Q (as well as F on the biomolecule) is selected from groups reactive in a cycloaddition reaction.
- reactive groups Q and F are complementary, i.e. they are capable of reacting with each other in a cycloaddition reaction, the obtained cyclic moiety being connecting group Z 3 .
- one of F and Q is a diene and the other of F and Q is a dienophile.
- Hetero-Diels-Alder reactions with N- and O-containing dienes are known to a person skilled in the art. Any diene known in the art to be suitable for Diels-Alder reactions may be used as reactive group Q or F . Preferred dienes include tetrazines as described above, 1 ,2- quinones as described above and triazines as described above. Although any dienophile known in the art to be suitable for Diels-Alder reactions may be used as reactive groups Q or F , the dienophile is preferably an alkene or alkyne group as described above, most preferably an alkyne group.
- F is the diene and Q is the dienophile.
- Q is a dienophile
- Q is or comprises an alkynyl group
- F is a diene, preferably a tetrazine, 1 ,2-quinone or triazine group.
- one of F and Q is a 1 ,3-dipole and the other of F and Q is a dipolarophile.
- Any 1 ,3-dipole known in the art to be suitable for 1 ,3-dipolar cycloadditions may be used as reactive group Q or F .
- Preferred 1 ,3-dipoles include azido groups, nitrone groups, nitrile oxide groups, nitrile imine groups and diazo groups.
- the dipolarophile is preferably an alkene or alkyne group, most preferably an alkyne group.
- F is the 1 ,3-dipole
- Q is the dipolarophile.
- Q is a dipolarophile
- Q is or comprises an alkynyl group
- F is a 1 ,3-dipole, preferably an azido group.
- Q is selected from dipolarophiles and dienophiles.
- Q is an alkene or an alkyne group.
- Q comprises an alkyne group, preferably selected from the alkynyl group as described above, the cycloalkenyl group as described above, the (hetero)cycloalkynyl group as described above and a bicyclo[6.1.0]non-4-yn-9-yl] group, more preferably Q is selected from the formulae (9j), (9n), (9o), (9p), (9q), (9zk) and (9zo) as defined above and depicted below, such as selected from the formulae (9j), (9n), (9o), (9p), (9q) and (9zk), more preferably selected from the formulae (9n), (9o), (9p), (9q) and (9zk) or from the formulae (9j), (9n), (9q) and (9zo).
- Q is a bicyclo[6.1.0]non-4-yn-9-yl] group, preferably of formula (9q).
- These groups are known to be highly effective in the conjugation with azido-functionalized biomolecules as described herein, and when the sulfamide linker according to the invention is employed in such linker-conjugates, any aggregation is beneficially reduced to a minimum.
- D and Q are covalently attached in the linker-conjugate according to the invention, preferably via linker L as defined above. Covalent attachment of D to the linker may occur for example via reaction of a functional group F 2 present on D with a reactive group Q 2 present on the linker. Suitable organic reactions for the attachment of D to a linker are known to a person skilled in the art, as are functional groups F 2 that are complementary to a reactive group Q 2 . Consequently, D may be attached to the linker via a connecting group Z.
- connecting group refers to the structural element connecting one part of a compound and another part of the same compound.
- the nature of a connecting group depends on the type of organic reaction with which the connection between the parts of said compound was obtained.
- R-C(0)-OH is reacted with the amino group of H 2 N-R' to form R-C(0)-N(H)-R'
- R is connected to R' via connecting group Z
- Z may be represented by the group -C(0)-N(H)-.
- Reactive group Q may be attached to the linker in a similar manner. Consequently, Q may be attached to the spacer-moiety via a connecting group Z.
- the linker-conjugate is a compound according to the formula:
- - y' is an integer in the range of 1 to 10;
- - z is an integer in the range of 1 to 10;
- - Q is a reactive group capable of reacting with a functional group F present on a biomolecule
- - D is a target molecule
- - Sp is a spacer moiety, wherein a spacer moiety is defined as a moiety that spaces (i.e. provides a certain distance between) and covalently links Q and D;
- spacer moiety is linker L, and thus comprises a group according to formula (1) or a salt thereof, wherein the group according to formula (1) is as defined above.
- a in the group according to formula (1) is 0. In another preferred embodiment, a in the group according to formula (1) is 1 .
- Preferred embodiments for y' and z are as defined above for (Q ) y Sp(D) z . It is further preferred that the compound is according to the formula Q (Z w )Sp(Z x )(D) 4 , Q (Z w )Sp(Z x )(D) 3 , Q (Z w )Sp(Z x )(D) 2 or Q (Z w )Sp(Z x )D, more preferably Q (Z w )Sp(Z x )(D) 2 or Q (Z w )Sp(Z x )D and most preferably Q (Z w )Sp(Z x )D, wherein Z w and Z x are as defined above.
- the linker-conjugate is compound according to formula (4a) or (4b), or a salt thereof:
- - a is independently 0 or 1 ;
- - b is independently 0 or 1 ;
- - c is 0 or 1 ;
- - d is 0 or 1 ;
- - e is 0 or 1 ;
- - f is an integer in the range of 1 to 150;
- - g is 0 or 1 ;
- - i is 0 or 1 ;
- - D is a target molecule
- - Q is a reactive group capable of reacting with a functional group F present on a biomolecule
- - Sp is a spacer moiety
- - Sp 2 is a spacer moiety
- - Z is a connecting group that connects Q or Sp 3 to Sp 2 , O or C(O) or N(R 1 );
- - Z 2 is a connecting group that connects D or Sp 4 to Sp 1 , N(R 1 ), O or C(O);
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3- C24 cycloalkyl groups, Ci - C24 (hetero)aryl groups, Ci - C24 alkyl(hetero)aryl groups and Ci - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or
- - R is D, -[(Sp )b(Z 2 )e(Sp 4 )iD] or -[(Sp 2 )c(Z ) d (Sp 3 ) g Q 1 ], wherein D is a further target molecule and Sp 1 , Sp 2 , Sp 3 , Sp 4 , Z , Z 2 , Q , b, c, d, e, g and i are as defined above.
- a is 1 in the compound according to formula (4a) or (4b). In another preferred embodiment, a is 0 in the compound according to formula (4a) or (4b).
- Z is a connecting group that connects Q or Sp 3 to Sp 2 , O or C(O) or N(R 1 ), and Z 2 is a connecting group that connects D or Sp 4 to Sp 1 , N(R 1 ), O or C(O).
- connecting group refers to a structural element connecting one part of a compound and another part of the same compound.
- connecting group Z when present (i.e. when d is 1 ), connects Q (optionally via a spacer moiety Sp 3 ) to the O-atom or the C(O) group of the compound according to formula (4a), optionally via a spacer moiety Sp 2 . More particularly, when Z is present (i.e. d is 1 ), and when Sp 3 and Sp 2 are absent (i.e. g is 0 and c is 0), Z connects Q to the O-atom (a is 1 ) or to the C(O) group (a is 0) of the linker-conjugate according to formula (4a). When Z is present (i.e. when d is 1 ), Sp 3 is present (i.e.
- connecting group Z when present (i.e. when d is 1 ), connects Q (optionally via a spacer moiety Sp 3 ) to the N-atom of the N(R 1 ) group in the linker- conjugate according to formula (4b), optionally via a spacer moiety Sp 2 . More particularly, when Z is present (i.e. d is 1 ), and when Sp 3 and Sp 2 are absent (i.e. g is 0 and c is 0), Z connects Q to the N-atom of the N(R 1 ) group of the linker-conjugate according to formula (4b). When Z is present (i.e. when d is 1 ), Sp 3 is present (i.e.
- Z connects spacer moiety Sp 3 to the N-atom of the N(R 1 ) group of the linker-conjugate according to formula (4b).
- Z connects spacer moiety Sp 3 to spacer moiety Sp 2 of the linker-conjugate according to formula (4b).
- Z connects Q to spacer moiety Sp 2 of the linker-conjugate according to formula (4b).
- connecting group Z 2 when present (i.e. when e is 1 ), connects D (optionally via a spacer moiety Sp 4 ) to the N-atom of the N(R 1 ) group in the linker- conjugate according to formula (4a), optionally via a spacer moiety Sp 1 . More particularly, when Z 2 is present (i.e. e is 1 ), and when Sp 1 and Sp 4 are absent (i.e. b is 0 and i is 0), Z 2 connects D to the N-atom of the N(R 1 ) group of the linker-conjugate according to formula (4a). When Z 2 is present (i.e. when e is 1 ), Sp 4 is present (i.e.
- Z 2 connects spacer moiety Sp 4 to the N-atom of the N(R 1 ) group of the linker-conjugate according to formula (4a).
- Z 2 connects spacer moiety Sp 1 to spacer moiety Sp 4 of the linker-conjugate according to formula (4a).
- Z 2 connects D to spacer moiety Sp 1 of the linker-conjugate according to formula (4a).
- connecting group depends on the type of organic reaction with which the connection between the specific parts of said compound was obtained.
- a large number of organic reactions are available for connecting a reactive group Q to a spacer moiety, and for connecting a target molecule to a spacer-moiety. Consequently, there is a large variety of connecting groups Z and Z 2 .
- Sp ⁇ Sp 2 , Sp 3 and Sp 4 are spacer-moieties.
- Sp 1 , Sp 2 , Sp 3 and Sp 4 may be, independently, absent or present (b, c, g and i are, independently, 0 or 1 ).
- Sp 1 , if present, may be different from Sp 2 , if present, from Sp 3 and/or from Sp 4 , if present.
- Spacer-moieties are known to a person skilled in the art.
- suitable spacer-moieties include (poly)ethylene glycol diamines (e.g. 1 ,8-diamino-3,6-dioxaoctane or equivalents comprising longer ethylene glycol chains), polyethylene glycol chains or polyethylene oxide chains, polypropylene glycol chains or polypropylene oxide chains and 1 ,xx-diaminoalkanes wherein xx is the number of carbon atoms in the alkane.
- cleavable spacer-moieties comprises cleavable spacer-moieties, or cleavable linkers.
- Cleavable linkers are well known in the art. For example Shabat ef a/. , Soft Matter 2012, 6, 1073, incorporated by reference herein, discloses cleavable linkers comprising self-immolative moieties that are released upon a biological trigger, e.g. an enzymatic cleavage or an oxidation event.
- suitable cleavable linkers are disulphide-linkers that are cleaved upon reduction, peptide-linkers that are cleaved upon specific recognition by a protease, e.g.
- suitable cleavable spacer-moieties also include spacer moieties comprising a specific, cleavable, sequence of amino acids. Examples include e.g. spacer-moieties comprising a Val-Ala (valine-alanine) or Val-Cit (valine-citrulline) moiety.
- spacer moieties Sp 1 , Sp 2 , Sp 3 and/or Sp 4 if present, comprise a sequence of amino acids.
- Spacer- moieties comprising a sequence of amino acids are known in the art, and may also be referred to as peptide linkers. Examples include spacer-moieties comprising a Val-Cit moiety, e.g. Val-Cit- PABC, Val-Cit-PAB, Fmoc-Val-Cit-PAB, etc.
- a Val-Cit-PABC moiety is employed in the linker-conjugate.
- spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cycloalkylene groups, C5-C200 cycloalkenylene groups, C8-C200 cycloalkynylene groups,
- alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are interrupted by one or more heteroatoms as defined above, it is preferred that said groups are interrupted by one or more O-atoms, and/or by one or more S-S groups.
- spacer moieties Sp ⁇ Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C100 alkylene groups, C2-C100 alkenylene groups,
- spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C50 alkylene groups, C2-C50 alkenylene groups, C2-C50 alkynylene groups, C3-C50 cycloalkylene groups, C5-C50 cycloalkenylene groups, Cs-Cso cycloalkynylene groups, C7-C50 alkylarylene groups, C7-C50 arylalkylene groups, Cs-Cso arylalkenylene groups and C9-C50 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substitute
- spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, C2-C20 alkenylene groups, C2-C20 alkynylene groups, C3-C20 cycloalkylene groups, C5-C20 cycloalkenylene groups, C8-C20 cycloalkynylene groups, C7-C20 alkylarylene groups, C7-C20 arylalkylene groups, C8-C20 arylalkenylene groups and C9-C20 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted
- alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR 3 , preferably O, wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
- spacer moieties Sp ⁇ Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR 3 , wherein R 3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
- the alkylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR 3 , preferably O and/or S, wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
- Preferred spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 thus include -(CH2)n-, -(CH2CH2)n-, -(CH 2 CH 2 0)n-, -(OCH 2 CH 2 )n-, -(CH 2 CH20)nCH 2 CH2-, -CH 2 CH2(OCH 2 CH2)n-, -(CH2CH 2 CH 2 0)n-, -(OCH2CH 2 CH2)n-, -(CH2CH2CH20)nCH2CH 2 CH2- and -CH2CH2CH2(OCH2CH 2 CH2)n-, wherein n is an integer in the range of 1 to 50, preferably in the range of 1 to 40, more preferably in the range of 1 to 30, even more preferably in the range of 1 to 20 and yet even more preferably in the range of 1 to 15. More preferably n is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10, more preferably 1 , 2, 3, 4, 5, 6, 7 or 8, even more
- Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected, Sp 1 , if present, may be different from Sp 2 , if present, from Sp 3 and/or from Sp 4 , if present.
- Reactive groups Q are described in more detail above.
- reactive group Q is selected from the group consisting of, optionally substituted, N-maleimidyl groups, halogenated N-alkylamido groups, sulfonyloxy N- alkylamido groups, ester groups, carbonate groups, sulfonyl halide groups, thiol groups or derivatives thereof, alkenyl groups, alkynyl groups, (hetero)cycloalkynyl groups, bicyclo[6.1.0]non- 4-yn-9-yl] groups, cycloalkenyl groups, tetrazinyl groups, azido groups, phosphine groups, nitrile oxide groups, nitrone groups, nitrile imine groups, diazo groups, ketone groups, (O- alkyl)hydroxylamino groups, hydrazine groups, halogenated N-maleimi
- Q is according to formula (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj) or (9zk), wherein (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj), (9zk), (9zk), wherein (9a
- Q is according to formula (9a), (9b), (9c), (9f), (9j), (9n), (9o), (9p), (9q), (9s), (9t), (9zh), (9zo) or (9r).
- Q is according to formula (9a), (9j), (9n), (9o), (9q), (9p), (9t), (9zh), (9zo) or (9s)
- Q is according to formula (9a), (9q), (9n), (9o), (9p), (9t), (9zo) or (9zh), and preferred embodiments thereof, as defined above.
- Target molecule D and preferred embodiments for target molecule D in the linker-conjugate according to formula (4a) and (4b) are as defined above.
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is D, -[(Sp ) b (Z 2 ) e (Sp 4 )iD] or -[(Sp 2 )
- R is hydrogen or a Ci - C20 alkyl group, more preferably R is hydrogen or a Ci - C16 alkyl group, even more preferably R is hydrogen or a Ci - C10 alkyl group, wherein the alkyl group is optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 , preferably O, wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups.
- R is hydrogen.
- R is a Ci - C20 alkyl group, more preferably a Ci - C16 alkyl group, even more preferably a Ci - C10 alkyl group, wherein the alkyl group is optionally interrupted by one or more O-atoms, and wherein the alkyl group is optionally substituted with an -OH group, preferably a terminal -OH group.
- R is a polyethyleneglycol chain comprising a terminal -OH group.
- R is a Ci - C12 alkyl group, more preferably a Ci - C6 alkyl group, even more preferably a Ci - C4 alkyl group, and yet even more preferably R is selected from the group consisting of methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl and t-butyl.
- R is a further target molecule D, -[(Sp )b(Z 2 ) e (Sp 4 )iD] or -[(Sp 2 )c(Z )d(Sp 3 )gQ 1 ], wherein D is a target molecule and Sp 1 , Sp 2 , Sp 3 , Sp 4 , Z ⁇ Z 2 , Q ⁇ b, c, d, e, g and i are as defined above.
- the linker-conjugate is according to formula (4a).
- linker-conjugate (4a) comprises two target molecules D, which may be the same or different.
- R is -[(Sp )b(Z 2 ) e (Sp 4 )iD]
- Sp ⁇ b, Z 2 , e, Sp 4 , i and D in -[(Sp ) b (Z 2 ) e (Sp 4 )iD] may be the same or different from Sp ⁇ b, Z 2 , e, Sp 4 , i and D in -[(Sp )b(Z 2 ) e (Sp 4 )iD] that is attached to the N-atom of N(R 1 ).
- both -[(Sp )b(Z 2 ) e (Sp 4 )iD] and -[(Sp ) b (Z 2 ) e (Sp 4 )iD] on the N-atom of N(R 1 ) are the same.
- linker-conjugate (4b) comprises two target molecules Q , which may be the same or different.
- R is -[(Sp 2 )c(Z ) d (Sp 3 ) g Q 1 ]
- Sp 2 , c, Z ⁇ d, Sp 3 , g and D in -[(Sp )b(Z 2 ) e (Sp 4 )iD] may be the same or different from Sp 1 , b, Z 2 , e, Sp 4 , i and Q in the other -[(Sp 2 )c(Z )d(Sp 3 )gQ 1 ] that is attached to the N-atom of N(R 1 ).
- -[(Sp 2 )c(Z )d(Sp 3 )gQ 1 ] groups on the N-atom of N(R 1 ) are the same.
- f is an integer in the range of 1 to 150.
- the linker-conjugate may thus comprise more than one group according to formula (1 ), the group according to formula (1 ) being as defined above.
- a, b, Sp 1 and R are independently selected.
- each a is independently 0 or 1
- each b is independently 0 or 1
- each Sp 1 may be the same or different
- each R may be the same or different.
- f is an integer in the range of 1 to 100, preferably in the range of 1 to 50, more preferably in the range of 1 to 25, and even more preferably in the range of 1 to 15. More preferably, f is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10, even more preferably f is 1 , 2, 3, 4, 5, 6, 7 or 8, yet even more preferably f is 1 , 2, 3, 4, 5 or 6, yet even more preferably f is 1 , 2, 3 or 4, and most preferably f is 1 in this embodiment.
- f is an integer in the range of 2 to 150, preferably in the range of 2 to 100, more preferably in the range of 2 to 50, more preferably in the range of 2 to 25, and even more preferably in the range of 2 to 15. More preferably, f is 2, 3, 4, 5, 6, 7, 8, 9 or 10, even more preferably f is 2, 3, 4, 5, 6, 7 or 8, yet even more preferably f is 2, 3, 4, 5 or 6, yet even more preferably f is 2, 3 or 4, and most preferably f is 2 in this embodiment.
- a is 0 in the compound according to formula (4a) or (4b).
- the linker-conjugate may therefore also be a compound according to formula (6a) or (6b), or a salt thereof:
- a is 1 in the compound according to formula (4a) or (4b).
- the linker-conjugate may therefore also be a compound according to formula (7a) or
- a, b, c, d, e, f, g, D, Q , Sp 1 , Sp 2 , Sp 3 , Z , Z 2 and R , and their preferred embodiments, are as defined above for (4a) and (4b).
- a is 0.
- a is 1.
- linker-conjugate particularly a linker-conjugate according to formula (4a), (4b), (4c), (4d), (6a), (6b), (7a) or (7b), Sp 1 , Sp 2 Sp 3 and Sp 4 , if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group consisting of O, S and NR 3 , wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, and Q is according to formula (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze
- Q is according to formula (9a), (9b), (9c), (9f), (9j), (9n), (9o), (9p), (9q), (9s) (9t), (9zh), (9zo) or (9r).
- Q is according to formula (9a), (9j), (9n), (9o), (9p), (9q), (9t), (9zh), (9zo) or (9s)
- Q is according to formula (9a), (9q), (9n), (9p), (9t), (9zh), (9zo) or (9o), and preferred embodiments thereof, as defined above.
- Linker L as preferably comprised in the linker-conjugate according to formula (4a), (4b), (4c), (4d), (6a), (6b), (7a) or (7b) as defined above, linker as defined above may be represented by formula (8a) and (8b), respectively:
- spacer-moieties (8a) and (8b) may depend on e.g. the nature of reactive groups Q and D in the linker-conjugate, the synthetic method to prepare the linker-conjugate (e.g. the nature of complementary functional group F 2 on a target molecule), the nature of a bioconjugate that is prepared using the linker- conjugate (e.g. the nature of complementary functional group F on the biomolecule).
- the linker-conjugate was prepared via reaction of a reactive group Q 2 that is a cyclooctynyl group according to formula (9n), (9o), (9p), (9q) or (9zk) with an azido functional group F 2 , then preferably Sp 4 is present (i is 1 ).
- At least one of Sp 1 , Sp 2 , Sp 3 and Sp 4 is present, i.e. at least one of b, c, g, and i is not 0. In another preferred embodiment, at least one of Sp 1 and Sp 4 and at least one of Sp 2 and Sp 3 are present.
- linker-moiety (8a) and (8b) also hold for the linker-conjugate when comprised in the bioconjugates according to the invention as described in more detail below.
- Sp 1 , Sp 2 , Sp 3 and Sp 4 are as defined above.
- the biomolecule is represented by B-F , wherein B is a biomolecule and F is a functional group capable of reacting with reactive group Q on the linker-conjugate and "-" is a bond or a spacer moiety.
- the biomolecule is a modified antibody represented by formula (24), wherein F is a functional group capable of reacting with reactive group Q on the linker-conjugate.
- the modified antibody represented by formula (24) and preferred embodiments thereof are defined in detail above.
- biomolecule is a spacer moiety as defined herein.
- “-” is a bond, typically a covalent bond.
- the biomolecule may also be referred to as "biomolecule of interest” (BOI).
- the biomolecule may be a biomolecule as naturally occurring, wherein functional group F is a already present in the biomolecule of interest, such as for example a thiol, an amine, an alcohol or a hydroxyphenol unit. Conjugation with the linker-conjugate then occurs via the first approach as defined above.
- the biomolecule may be a modified biomolecule, wherein functional group F is specifically incorporated into the biomolecule of interest and conjugation with the linker-conjugate occurs via this engineered functionality, i.e. the two-stage approach of bioconjugation as defined above.
- modification of biomolecules to incorporate a specific functionality is known, e.g. from WO 2014/065661 , incorporated herein by reference in its entirety.
- biomolecule B is preferably selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, lipids, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides, enzymes, hormones, amino acids and monosaccharides. More preferably, biomolecule B is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides and enzymes. More preferably, biomolecule B is selected from the group consisting of proteins, including glycoproteins and antibodies, polypeptides, peptides and glycans. Most preferably, biomolecule B is an antibody or an antigen-binding fragment thereof.
- Functional group F is capable of reacting with reactive group Q on the linker-conjugate to form a connecting group Z 3 .
- functional group F is capable of reacting with a complementary reactive group Q .
- Functional groups F that are complementary to reactive groups Q are described in more detail below.
- a reactive group Q that is present in the linker-conjugate is typically reacted with functional group F .
- More than one functional group F may be present in the biomolecule. When two or more functional groups are present, said groups may be the same or different.
- the biomolecule comprises two or more functional groups F, which may be the same or different, and two or more functional groups react with a complementary reactive group Q of a linker-conjugate.
- a biomolecule comprising two functional groups F, i.e. F and F 2 may react with two linker-conjugates comprising a functional group Q , which may be the same or different, to form a bioconjugate.
- Examples of a functional group F in a biomolecule comprise an amino group, a thiol group, a carboxylic acid, an alcohol group, a carbonyl group, a phosphate group, or an aromatic group.
- the functional group in the biomolecule may be naturally present or may be placed in the biomolecule by a specific technique, for example a (bio)chemical or a genetic technique.
- the functional group that is placed in the biomolecule may be a functional group that is naturally present in nature, or may be a functional group that is prepared by chemical synthesis, for example an azide, a terminal alkyne, a cyclopropene moiety or a phosphine moiety.
- F is group capable of reacting in a cycloaddition, such as a diene, a dienophile, a 1 ,3-dipole or a dipolarophile, preferably F is selected from a 1 ,3-dipole (typically an azido group, nitrone group, nitrile oxide group, nitrile imine group or diazo group) or a dipolarophile (typically an alkenyl or alkynyl group).
- a 1 ,3-dipole typically an azido group, nitrone group, nitrile oxide group, nitrile imine group or diazo group
- a dipolarophile typically an alkenyl or alkynyl group
- F is a 1 ,3- dipole when Q is a dipolarophile and F is a dipolarophile when Q is a 1 ,3-dipole, or F is a diene when Q is a dienophile and F is a dienophile when Q is a diene.
- F is a 1 ,3- dipole, preferably F is or comprises an azido group.
- Figure 2 shows several structures of derivatives of UDP sugars of galactosamine, which may be modified with e.g. a thiopropionyl group (11a), an azidoacetyl group (11 b), or an azidodifluoroacetyl group (11c) at the 2-position, or with an azido group at the 6-position of N- acetyl galactosamine (11d).
- functional group F is a thiopropionyl group, an azidoacetyl group, or an azidodifluoroacetyl group.
- Figure 3 schematically displays how any of the UDP-sugars 11a-d may be attached to a glycoprotein comprising a GlcNAc moiety 12 (e.g. a monoclonal antibody the glycan of which is trimmed by an endoglycosidase) under the action of a galactosyltransferase mutant or a GalNAc- transferase, thereby generating a ⁇ -glycosidic 1-4 linkage between a GalNAc derivative and GlcNAc (compounds 13a-d, respectively).
- a GlcNAc moiety 12 e.g. a monoclonal antibody the glycan of which is trimmed by an endoglycosidase
- Preferred examples of naturally present functional groups F include a thiol group and an amino group.
- Preferred examples of a functional group that is prepared by chemical synthesis for incorporation into the biomolecule include a ketone group, a terminal alkyne group, an azide group, a cyclo(hetero)alkyne group, a cyclopropene group, or a tetrazine group.
- complementary reactive groups Q and functional groups F are known to a person skilled in the art, and several suitable combinations of Q and F are described above, and shown in Figure 5.
- a list of complementary groups Q and F is disclosed in in Table 3.1 , pages 230 - 232 of Chapter 3 of G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3 rd Ed.
- a bioconjugate is herein defined as a compound wherein a biomolecule is covalently connected to a target molecule D via a linker.
- a bioconjugate comprises one or more biomolecules and/or one or more target molecules.
- the linker may comprise one or more spacer moieties.
- the bioconjugate according to the invention is conveniently prepared by the process for preparation of a bioconjugate according to the invention, wherein the linker-conjugate comprising reactive group Q is conjugated to a biomolecule comprising functional group F . In this conjugation reaction, groups Q and F react with each other to form a connecting group Z 3 which connects the target molecule D with the biomolecule B.
- the linker- conjugate and the biomolecule thus equally apply to the bioconjugate according to the invention, except for all said for Q and F , wherein the bioconjugate according to the invention contains the reaction product of Q and F , i.e. connecting group Z 3 .
- the invention also concerns the bioconjugates, preferably the antibody-conjugates, described herein.
- the bioconjugate according to the invention has formula (A):
- - B is a biomolecule, preferably an antibody AB;
- - L is a linker linking B and D;
- the bioconjugate is obtainable by the mode of conjugation defined as "core-GlcNAc functionalization", i.e. by steps (i) and (ii) as defined above.
- the bioconjugate according to formula (A) has a linker L comprising a group according to formula (1 ) or a salt thereof:
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or R is a target molecule D, wherein D is optionally connected to N via a spacer moiety.
- "-" is a spacer moiety as defined herein. In one embodiment, "-" is a bond, typically a covalent bond.
- the bioconjugate is presented by B-Z 3 -L-D, wherein B, L, D and "-" are as defined above and Z 3 is a connecting group which is obtainable by reaction of Q with F .
- moiety Z 3 is obtainable by a cycloaddition, preferably a 1 ,3-dipolar cycloaddition reaction, most preferably Z 3 is a 1 ,2,3-triazole ring, which is located in a spacer moiety, preferably the spacer moiety between B and L, most preferably between B and the carbonyl or carboxyl end of the group according to formula (1 ).
- the bioconjugate according to the invention comprises a salt of the group according to formula (1 )
- the salt is preferably a pharmaceutically acceptable salt.
- the bioconjugate according to the invention may comprise more than one target molecule. Similarly, the bioconjugate may comprise more than one biomolecule.
- Biomolecule B and target molecule D are described in more detail above.
- Preferred embodiments for D in the bioconjugate according to the invention correspond to preferred embodiments of D in the linker-conjugate according to the invention as were described in more detail above.
- Preferred embodiments for the linker (8a) or (8b) in the bioconjugate according to the invention correspond to preferred embodiments of the linker in the linker-conjugate, as were described in more detail above.
- Preferred embodiments for B in the bioconjugate according to the invention correspond to preferred embodiments of B in the biomolecule according to the invention as were described in more detail above.
- the bioconjugate according to the invention may also be defined as a bioconjugate wherein a biomolecule is conjugated to a target molecule via a spacer-moiety, wherein the spacer-moiety comprises a group according to formula (1 ), or a salt thereof, wherein the group according to formula (1 ) is as defined above.
- the bioconjugate according to the invention may also be denoted as (B) y Sp(D) z , wherein y' is an integer in the range of 1 to 10 and z is an integer in the range of 1 to 10.
- the invention thus also relates to a bioconjugate according to the formula:
- - y' is an integer in the range of 1 to 10;
- - z is an integer in the range of 1 to 10;
- - B is a biomolecule
- - D is a target molecule
- - Sp is a spacer moiety, wherein a spacer moiety is defined as a moiety that spaces (i.e. provides a certain distance between) and covalently links biomolecule B and target molecule D; and wherein said spacer moiety comprises a group according to formula (1 ) or a salt thereof, wherein the group according to formula (1 ) is as defined above.
- said spacer moiety further comprises a moiety that is obtainable by a cycloaddition, preferably a 1 ,3-dipolar cycloaddition reaction, most preferably a 1 ,2,3-triazole ring, which is located between B and said group according to formula (1 ).
- y' is 1 , 2, 3 or 4, more preferably y' is 1 or 2 and most preferably, y' is 1.
- z is 1 , 2, 3, 4, 5 or 6, more preferably z is 1 , 2, 3 or 4, even more preferably z is 1 , 2 or 3, yet even more preferably z is 1 or 2 and most preferably z is 1. More preferably, y' is 1 or 2, preferably 1 , and z is 1 , 2, 3 or 4, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 , 2 or 3, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 or 2, and most preferably y' is 1 and z is 1.
- the bioconjugate is according to the formula BSp(D)4, BSp(D)3, BSp(D)2 or BSpD.
- the bioconjugate is according to the formula BSp(D)e, BSp(D) 4 or BSp(D) 2 , more preferably BSp(D) 4 or BSp(D) 2 .
- the bioconjugate according to the invention comprises a group according to formula (1 ) as defined above, or a salt thereof.
- the bioconjugate comprises a group according to formula (1 ) wherein a is 0, or a salt thereof.
- the bioconjugate thus comprises a group according to formula (2) or a salt thereof, wherein (2) is as defined above.
- the bioconjugate comprises a group according to formula (1 ) wherein a is 1 , or a salt thereof.
- the bioconjugate thus comprises a group according to formula (3) or a salt thereof, wherein (3) is as defined above.
- R spacer moiety Sp, as well as preferred embodiments of R and Sp, are as defined above for the linker-conjugate according to the invention.
- - h is 0 or 1 ;
- - Z 3 is a connecting group that connects B to Sp 3 , Z Sp 2 , O or C(O);
- - B is a biomolecule.
- h is 1.
- biomolecule B Preferred embodiments of biomolecule B are as defined above.
- the bioconjugate according to the invention is a salt of (5a) or (5b), the salt is preferably a pharmaceutically acceptable salt.
- Z 3 is a connecting group.
- connecting group herein refers to the structural element connecting one part of a compound and another part of the same compound.
- a bioconjugate is prepared via reaction of a reactive group Q present in the linker- conjugate with a functional group F present in a biomolecule.
- connecting group Z 3 depends on the type of organic reaction that was used to establish the connection between the biomolecule and the linker- conjugate. In other words, the nature of Z 3 depends on the nature of reactive group Q of the linker-conjugate and the nature of functional group F in the biomolecule.
- complementary groups Q include N-maleimidyl groups and alkenyl groups, and the corresponding connecting groups Z 3 are as shown in Figure 5.
- complementary groups Q also include allenamide groups.
- complementary groups Q include ketone groups and activated ester groups, and the corresponding connecting groups Z 3 are as shown in Figure 5.
- complementary groups Q include (O- alkyl)hydroxylamino groups and hydrazine groups, and the corresponding connecting groups Z 3 are as shown in Figure 5.
- complementary groups Q include azido groups, and the corresponding connecting group Z 3 is as shown in Figure 5.
- complementary groups Q include alkynyl groups, and the corresponding connecting group Z 3 is as shown in Figure 5.
- complementary groups Q include tetrazinyl groups, and the corresponding connecting group Z 3 is as shown in Figure 5.
- Z 3 is only an intermediate structure and will expel N2, thereby generating a dihydropyridazine (from the reaction with alkene) or pyridazine (from the reaction with alkyne).
- At least one of Z 3 , Sp 3 , Z and Sp 2 is present, i.e. at least one of h, g, d and c is not 0. It is also preferred that at least one of Sp 1 , Z 2 and Sp 4 is present, i.e. that at least one of b, e and i is not 0. More preferably, at least one of Z 3 , Sp 3 , Z and Sp 2 is present and at least one of Sp 1 , Z 2 and Sp 4 is present, i.e. it is preferred that at least one of b, e and i is not 0 and at least one of h, g, d and c is not 0. Process for the preparation of a bioconjugate
- the bioconjugate according to the invention is typically obtained by a process for the preparation of a bioconjugate as defined herein.
- any method of preparing the bioconjugate can be used as long as the obtained bioconjugate comprises linker L as defined herein.
- the group according to formula (1 ) may be present in linker L between B and Z 3 , i.e. it originates form the biomolecule, or between Z 3 and D, i.e. it originates from the linker-conjugate, or Z 3 is or comprises the group according to formula (1 ), i.e.
- the group according to formula (1 ) is formed upon conjugation.
- the group according to formula (1 ) is present in linker L between B and Z 3 or between Z 3 and D, most preferably, the group according to formula (1 ) is present in linker L between Z 3 and D.
- the exact mode of conjugation including the nature of Q and F have a great flexibility in the context of the present invention.
- Many techniques for conjugating BOIs to MOIs are known to a person skilled in the art and can be used in the context of the present invention.
- the conjugation method comprises steps (i) and (ii) as defined above.
- the bioconjugate according to the invention is typically prepared by a process comprising the step of reacting a reactive group Q of the linker-conjugate as defined herein with a functional group F of the biomolecule, also referred to as a biomolecule.
- a biomolecule of interest (BOI) comprising one or more functional groups F is incubated with (excess of) a target molecule D (also referred to as molecule of interest or MOI), covalently attached to a reactive group Q via a specific linker.
- the BOI may e.g. be a peptide/protein, a glycan or a nucleic acid.
- the bioconjugation reaction typically comprises the step of reacting a reactive group Q of the linker-conjugate with a functional group F of a the biomolecule, wherein a bioconjugate of formula (A) is formed, wherein linker L comprises a group according to formula (1 ) or a salt thereof:
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, which is optionally connected to N via a spacer moiety.
- the bioconjugate is prepared via a cycloaddition, such as a (4+2)- cycloaddition (e.g. a Diels-Alder reaction) or a (3+2)-cycloaddition (e.g. a 1 ,3-dipolar cycloaddition).
- a cycloaddition such as a (4+2)- cycloaddition (e.g. a Diels-Alder reaction) or a (3+2)-cycloaddition (e.g. a 1 ,3-dipolar cycloaddition).
- the conjugation is a Diels-Alder reaction or a 1 ,3-dipolar cycloaddition.
- the preferred Diels-Alder reaction is the inverse-electron demand Diels-Alder cycloaddition.
- the 1 ,3-dipolar cycloaddition is used, more preferably the alkyne- azide cycloaddition, and most preferably wherein Q is or comprises an alkyne group and F is an azido group.
- Cycloadditions such as Diels-Alder reactions and 1 ,3-dipolar cycloadditions are known in the art, and the skilled person knowns how to perform them.
- a is 0 in the group according to formula (1 ).
- the linker-conjugate thus comprises a group according to formula (2), as defined above.
- a is 1 in the group according to formula (1 ).
- the linker-conjugate thus comprises a group according to formula (3), as defined above.
- Biomolecules are described in more detail above.
- the biomolecule is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, lipids, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides, enzymes, hormones, amino acids and monosaccharides.
- biomolecule B is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides and enzymes.
- biomolecule B is selected from the group consisting of proteins, including glycoproteins and antibodies, polypeptides, peptides and glycans.
- B is an antibody or an antigen-binding fragment thereof.
- reactive group Q is selected from the group consisting of, optionally substituted, N-maleimidyl groups, halogenated N- alkylamido groups, sulfonyloxy N-alkylamido groups, ester groups, carbonate groups, sulfonyl halide groups, thiol groups or derivatives thereof, alkenyl groups, alkynyl groups, (hetero)cycloalkynyl groups, bicyclo[6.1.0]non-4-yn-9-yl] groups, cycloalkenyl groups, tetrazinyl groups, azido groups, phosphine groups, nitrile oxide groups, nitrone groups, nitrile imine groups, diazo groups, ketone groups, (O-alkyl)hydroxylamino groups, hydrazine groups, halogenated N- maleimidyl groups, 1 , 1-bis(sulfonyl
- Q is according to formula (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj) or (9zk), wherein (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj), (9zk), (9zk), wherein (9a
- Q is according to formula (9a), (9b), (9c), (9f), (9j), (9n), (9o), (9p), (9q), (9s), (9t), (9ze), (9zh), (9zo) or (9r). Even more preferably, Q is according to formula (9a), (9j), (9n), (9o), (9p), (9q), (9t), (9ze), (9zh), (9zo) or (9s), and most preferably, Q is according to formula (9a), (9p),(9q), (9n), (9t), (9ze), (9zh), (9zo) or (9o), and preferred embodiments thereof, as defined above.
- Q comprises an alkyne group, preferably selected from the alkynyl group as described above, the cycloalkenyl group as described above, the (hetero)cycloalkynyl group as described above and a bicyclo[6.1.0]non-4-yn-9-yl] group, more preferably Q is selected from the formulae (9j), (9n), (9o), (9p), (9q), (9zo) and (9zk), as defined above. Most preferably, Q is a bicyclo[6.1.0]non-4-yn-9-yl] group, preferably of formula (9q).
- the linker- conjugate is according to formula (4a) or (4b), or a salt thereof:
- - a is independently 0 or 1 ;
- - b is independently 0 or 1 ;
- - c is 0 or 1 ;
- - d is 0 or 1 ;
- - e is 0 or 1 ;
- - f is an integer in the range of 1 to 150;
- - g is 0 or 1 ;
- - i is 0 or 1 ;
- - D is a target molecule
- - Q is a reactive group capable of reacting with a functional group F present on a biomolecule
- - Z is a connecting group that connects Q or Sp 3 to Sp 2 , O or C(O) or N(R 1 );
- - Z 2 is a connecting group that connects D or Sp 4 to Sp 1 , N(R 1 ), O or C(O);
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C 4 alkyl groups; or R is D, -[(Sp )b(Z 2 ) e (Sp 4 )iD] or -[(Sp 2 )c(Z
- Sp 1 , Sp 2 , Sp 3 and Sp 4 are, independently, spacer moieties, in other words, Sp 1 , Sp 2 , Sp 3 and Sp 4 may differ from each other.
- Sp 1 , Sp 2 , Sp 3 and Sp 4 may be present or absent (b, c, g and i are, independently, 0 or 1 ). However, it is preferred that at least one of Sp 1 , Sp 2 , Sp 3 and Sp 4 is present, i.e. it is preferred that at least one of b, c, g and i is not 0.
- Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cycloalkylene groups, C5-C200 cycloalkenylene groups, C8-C200 cycloalkynylene groups, C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups and C9-C200 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected
- alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are interrupted by one or more heteroatoms as defined above, it is preferred that said groups are interrupted by one or more O-atoms, and/or by one or more S-S groups.
- spacer moieties Sp ⁇ Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C100 alkylene groups, C2-C100 alkenylene groups, C2-C100 alkynylene groups, C3-C100 cycloalkylene groups, C5-C100 cycloalkenylene groups, C8-C100 cycloalkynylene groups, C7-C100 alkylarylene groups, C7-C100 arylalkylene groups, Cs-doo arylalkenylene groups and C9-C100 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally
- spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C50 alkylene groups, C2-C50 alkenylene groups, C2-C50 alkynylene groups, C3-C50 cycloalkylene groups, C5-C50 cycloalkenylene groups, Cs-Cso cycloalkynylene groups, C7-C50 alkylarylene groups, C7-C50 arylalkylene groups, Cs-Cso arylalkenylene groups and C9-C50 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substitute
- spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, C2-C20 alkenylene groups, C2-C20 alkynylene groups, C3-C20 cycloalkylene groups, C5-C20 cycloalkenylene groups, C8-C20 cycloalkynylene groups, C7-C20 alkylarylene groups, C7-C20 arylalkylene groups, C8-C20 arylalkenylene groups and C9-C20 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted
- alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR 3 , preferably O, wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
- spacer moieties Sp ⁇ Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR 3 , wherein R 3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
- the alkylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR 3 , preferably O and/or S-S, wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
- Particularly preferred spacer moieties Sp 1 , Sp 2 , Sp 3 and Sp 4 include -(CH2)n-, -(CH2CH2)n-, -(CH 2 CH 2 0)n-, -(OCH 2 CH 2 )n-, -(CH 2 CH20)nCH 2 CH2-, -CH 2 CH2(OCH 2 CH2)n-, -(CH2CH 2 CH 2 0)n-, -(OCH2CH 2 CH2)n-, -(CH2CH2CH20)nCH2CH 2 CH2- and -CH2CH2CH2(OCH2CH 2 CH2)n-, wherein n is an integer in the range of 1 to 50, preferably in the range of 1 to 40, more preferably in the range of 1 to 30, even more preferably in the range of 1 to 20 and yet even more preferably in the range of 1 to 15. More preferably n is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10, more preferably 1 , 2, 3, 4, 5, 6, 7 or 8, even more
- spacer moieties Sp 1 , Sp 2 , Sp 3 and/or Sp 4 if present, comprise a sequence of amino acids.
- Spacer-moieties comprising a sequence of amino acids are known in the art, and may also be referred to as peptide linkers. Examples include spacer-moieties comprising a Val-Ala moiety or a Val-Cit moiety, e.g. Val-Cit-PABC, Val-Cit-PAB, Fmoc-Val-Cit-PAB, etc.
- Z and Z 2 are a connecting groups.
- Z and Z 2 are independently selected from the group consisting of -0-,
- Sp ⁇ Sp 2 , Sp 3 and Sp 4 are independently selected from the group consisting of linear or branched Ci-C 2 o alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group consisting of O, S and NR 3 , wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, and wherein Q is accordance with the formula
- - 1 is an integer in the range 0 - 10;
- R 0 is a (thio)ester group
- R 8 is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups.
- FIG. 4 shows how a modified antibody 13a-d may undergo a bioconjugation process by means of nucleophilic addition with maleimide (as for 3-mercaptopropionyl-galactosamine-modified 13a leading to thioether conjugate 14, or for conjugation to an engineered cysteine residue leading to thioether conjugate 17) or upon strain-promoted cycloaddition with a cyclooctyne reagent (as for 13b, 13c or 13d, leading to triazoles 15a, 15b or 16, respectively).
- maleimide as for 3-mercaptopropionyl-galactosamine-modified 13a leading to thioether conjugate 14, or for conjugation to an engineered cysteine residue leading to thioether conjugate 17
- a cyclooctyne reagent as for 13b, 13c or 13d, leading to triazoles 15a, 15b or 16, respectively.
- a further advantages of the process for the preparation of a bioconjugate as described herein, and of the linker-conjugates and sulfamide linker according to the invention is that conjugation efficiency increases in case a sulfamide linker is used instead of a typical polyethylene glycol (PEG) spacer.
- An additional advantage of a sulfamide group, in particular of an acylsulfamide or a carbamoylsulfamide group, is its high polarity, which imparts a positive effect on the solubility of a linker comprising such group, and on the construct as a whole, before, during and after conjugation.
- conjugation with linker-conjugate containing the sulfamide linker according to the invention are particularly suited to conjugate hydrophobic target compounds to a biomolecule.
- the high polarity of the sulfamides also has a positive impact in case hydrophobic moieties are conjugated to a biomolecule of interest, which is known to require large amounts of organic co-solvent during conjugation and/or induce aggregation of the bioconjugate.
- High levels of co-solvent up to 25% of DMF or even 50% of DMA, propylene glycol, or DMSO may induce protein denaturation during the conjugation process and/or may require special equipment in the manufacturing process.
- the problem of aggregation associated with the hydrophobic linking moieties in bioconjugates is efficiently solved by using the sulfamide linker according to the invention in the spacer between the target molecule and the reactive group Q in the linker-conjugate in the formation of the bioconjugate.
- An additional advantage of a sulfamide linker according the invention, and its use in bioconjugation processes, is its ease of synthesis and high yields.
- PCT/NL2015/050697 (WO 2016/053107), in particular to Tables 1 - 3, Figures 1 1 - 14, 23 and 24, and Examples 57, 58, 60 and 61 therein. These Tables, Figures and Examples of PCT/NL2015/050697 (WO 2016/053107) are incorporated herein.
- the invention thus concerns in a first aspect the use of a mode of conjugation comprising at least one of "core-GlcNAc functionalization” and "sulfamide linkage", as defined above, for increasing the therapeutic index of a bioconjugate.
- the invention according to the present aspect can also be worded as a method for increasing the therapeutic index of a bioconjugate.
- the mode of conjugation is being used to connect a biomolecule B with a target molecule D via a linker L, wherein the mode of conjugation comprises:
- S(F ) X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
- linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L 2 to obtain the antibody-conjugate wherein linker L comprises S-Z 3 -L 2 and wherein Z 3 is a connecting group resulting from the reaction between Q and F .
- the biomolecule is preferably an antibody
- the bioconjugate is preferably an antibody- conjugate.
- the therapeutic index is increased compared to a bioconjugate which does not comprise or is obtainable by the mode of conjugation according to the invention.
- the therapeutic index is increased compared to a bioconjugate not obtainable by steps (i) and (ii) as defined above, or - in other words - not containing the structural feature of the resulting linker L that links the antibody with the target molecule, that are a direct consequence of the conjugation process.
- the therapeutic index is increased compared to a bioconjugate of formula (A), wherein linker L does not comprise a group according to formula (1 ) or a salt thereof.
- the increased therapeutic index could solely be attributed to the mode of conjugation according to the invention.
- the increased therapeutic index is preferably an increased therapeutic index in the treatment of cancer, in particular in targeting of HER2-expressing tumours.
- the method according to the first aspect of the invention may also be worded as aspect a method for increasing the therapeutic index of a bioconjugate, comprising the step of providing a bioconjugate having the mode of conjugation according to the invention.
- the mode of conjugation according to the invention has an effect on both aspects of the therapeutic index: (a) on the therapeutic efficacy and (b) on the tolerability.
- the present use or method for increasing the therapeutic index is preferably for (a) increasing the therapeutic efficacy, and/or (b) increasing the tolerability of a bioconjugate of formula (A).
- the bioconjugate is an antibody-conjugate and the present use or method is for increasing the therapeutic index of an antibody-conjugate, preferably for (a) increasing the therapeutic efficacy of the antibody- conjugate, and/or (b) increasing the tolerability of the antibody-conjugate.
- the present method or use is for increasing the therapeutic efficacy of the bioconjugate, preferably the antibody-conjugate. In one embodiment, the present method or use is for increasing the tolerability of the bioconjugate, preferably the antibody-conjugate.
- the use or method according to the first aspect is for increasing the therapeutic efficacy of a bioconjugate of formula (A).
- “increasing the therapeutic efficacy” can also be worded as “lowering the effective dose”, “lowering the ED50 value” or “increasing the protective index”.
- the method according to the first aspect is for increasing the tolerability of a bioconjugate of formula (A).
- “increasing the tolerability” can also be worded as “increasing the maximum tolerated dose (MTD)", “increasing the TD50 value", “increasing the safety” or “reducing the toxicity”.
- the method according to the first aspect is for (a) increasing the therapeutic efficacy and (b) increasing the tolerability of a bioconjugate of formula (A).
- the method according to the first aspect is largely non-medical.
- the method is a non-medical or a non-therapeutic method for increasing the therapeutic index of a bioconjugate.
- the first aspect of the invention can also be worded as a mode of conjugation for use in improving the therapeutic index (therapeutic efficacy and/or tolerability) of a bioconjugate, wherein the mode of conjugation is as defined above.
- the present aspect is worded as a the mode of conjugation according to the "core-GlcNAc functionalization" as defined above for use in improving the therapeutic efficacy of a bioconjugate of formula (A), wherein L and (A) are as defined above.
- the present aspect is worded as a mode of conjugation for use in improving the therapeutic index (therapeutic efficacy and/or tolerability) of a bioconjugate, preferably an antibody-conjugate.
- the first aspect concerns the use of a mode of conjugation for the preparation of a bioconjugate, preferably an antibody-conjugate, for improving the therapeutic index (therapeutic efficacy and/or tolerability) of the bioconjugate.
- the invention according to the first aspect can also be worded as the use of a mode of conjugation in a bioconjugate, preferably an antibody-conjugate, or in the preparation of a bioconjugate, preferably an antibody-conjugate, for increasing the therapeutic index (therapeutic efficacy and/or tolerability) of the bioconjugate.
- the use as defined herein may be referred to as non-medical or non-therapeutic use.
- the method, use or mode of conjugation for use according to the first aspect of the invention further comprises the administration of the bioconjugate according to the invention to a subject in need thereof, in particular a patient suffering from a disorder associated with HER2 expression, e.g. selected from breast cancer, pancreatic cancer, bladder cancer, or gastric cancer.
- the subject is a cancer patient, more suitably a patient suffering from HER2-expressing tumours.
- bioconjugates such as antibody-drug-conjugates, is well- known in the field of cancer treatment, and the bioconjugates according to the invention are especially suited in this respect.
- the bioconjugate is administered in a therapeutically effective dose.
- Administration may be in a single dose or may e.g. occur 1 - 4 times a month, preferably 1 - 2 times a month.
- administration occurs once every 3 or 4 weeks, most preferably every 4 weeks.
- administration may occur less frequent as would be the case during treatment with conventional bioconjugates.
- the dose of the bioconjugate according to the invention may depend on many factors and the optimal dosing regime can be determined by the skilled person via routine experimentation.
- the bioconjugate is typically administered in a dose of 0.01 - 50 mg/kg body weight of the subject, more accurately 0.03 - 25 mg/kg or most accurately 0.05 - 10 mg/kg, or alternatively 0.1 - 25 mg/kg or 0.5 - 10 mg/kg. In one embodiment, administration occurs via intravenous injection.
- the invention concerns in a second aspect a method for targeting HER2-expressing cells, including but not limited to low HER2-expressing cells, comprising the administration of the bioconjugate according to the invention.
- HER2-expressing cells may also be referred to as HER2- expressing tumour cells.
- the subject in need thereof is most preferably a cancer patient.
- bioconjugates such as antibody-drug-conjugates, is well-known in the field of cancer treatment, and the bioconjugates according to the invention are especially suited in this respect.
- the method as described is typically suited for the treatment of cancer.
- the bioconjugate according to the invention is described a great detail above, which equally applies to the bioconjugate used in the second aspect of the invention.
- the second aspect of the invention can also be worded as a bioconjugate according to the invention for use in targeting HER2-expressing cells in a subject in need thereof.
- the second aspect concerns the use of a according to the invention for the preparation of a medicament for use in the targeting HER2-expressing cells in a subject in need thereof.
- the targeting of HER2-expressing cells includes one or more of treating, imaging, diagnosing, preventing the proliferation of, containing and reducing HER2- expressing cells, in particular HER2-expressing tumours. Most preferably, the present aspect is for the treatment of HER2-expressing tumours.
- the present aspect concerns a method for the treatment of a subject in need thereof.
- the second aspect of the invention can also be worded as a bioconjugate according to the invention for use in the treatment of a subject in need thereof, preferably for the treatment of cancer.
- the second aspect concerns the use of a bioconjugate according to the invention for the preparation of a medicament for use in the treatment of a subject in need thereof, preferably for use in the treatment of cancer.
- the subject suitably suffers from a disorder associated with HER2-expression, in particular a disorder selected form breast cancer, pancreatic cancer, bladder cancer, or gastric cancer
- target molecule D is an anti-cancer agent, preferably a cytotoxin.
- the bioconjugate is typically administered in a therapeutically effective dose. Administration may be in a single dose or may e.g. occur 1 - 4 times a month, preferably 1 - 2 times a month. In a preferred embodiment, administration occurs once every 3 or 4 weeks, most preferably every 4 weeks.
- the dose of the bioconjugate according to the invention may depend on many factors and the optimal dosing regime can be determined by the skilled person via routine experimentation.
- the bioconjugate is typically administered in a dose of 0.01 - 50 mg/kg body weight of the subject, more accurately 0.03 - 25 mg/kg or most accurately 0.05 - 10 mg/kg, or alternatively 0.1 - 25 mg/kg or 0.5 - 10 mg/kg. In one embodiment, administration occurs via intravenous injection.
- the administration of the bioconjugate according to the invention is at a dose that is lower than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89-60%, even more preferable at most 59-30%, most preferably at most 29-10% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the administration of the bioconjugate according to the invention occurs less frequent as administration would occur for the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the number of administration events is at most 75%, more preferably at most 50% of the number of administration events of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- administration may occur in a higher dose as in treatment with conventional bioconjugates.
- the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 25-50%, more preferably at most 50-75%, most preferably at most 75-100% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the administration of the bioconjugate according to the invention is at a dose that is lower than the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89-60%, even more preferable at most 59-30%, most preferably at most 29-10% of the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the administration of the bioconjugate according to the invention occurs less frequent as administration would occur for the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the number of administration events is at most 75%, more preferably at most 50% of the number of administration events of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- administration may occur in a higher dose as in treatment with conventional bioconjugates.
- the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most a factor 1.1 - 1.49 higher, more preferably at most a factor 1 .5 - 1.99 higher, even more preferable a factor 2 - 4.99 higher, most preferably at most a factor 5 - 10 higher of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
- the use or method or conjugation mode for use according to the present aspect is a bioconjugate for use in the treatment of a subject in need thereof, wherein the bioconjugate is represented by formula (A):
- - B is a biomolecule
- - L is a linker linking B and D; - D is a target molecule;
- L comprises a group according to formula (1 ) or a salt thereof:
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
- the invention pertains to antibody-conjugates that are particularly suitable in targeting HER2-expressing tumours.
- the antibody-conjugates according to the invention comprise an antibody AB connected to a target molecule D via a linker L, wherein the antibody- conjugate comprises or is obtainable by the mode of conjugation according to the invention.
- the antibody-conjugates according to the invention are obtainable by:
- S(F ) X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and (ii) reacting the modified antibody with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L 2 to obtain the antibody-conjugate wherein linker L comprises S-Z 3 -L 2 and wherein Z 3 is a connecting group resulting from the reaction between Q and F .
- antibody AB is capable of targeting HER2-expressing tumours and target molecule D is selected from the group consisting of taxanes, anthracyclines, camptothecins, epothilones, mytomycins, combretastatins, vinca alkaloids, maytansinoids, calicheamycins and enediynes, duocarmycins, tubulysins, amatoxins, dolastatins and auristatins, pyrrolobenzodiazepine dimers, indolino-benzodiazepine dimers, radioisotopes, therapeutic proteins and peptides and toxins (or fragments thereof), kinase inhibitors, MEK inhibitors, KSP inhibitors, and analogs or prodrugs thereof.
- target molecule D is a cytotoxin.
- target molecule D is selected from the group consisting of maytansinoids, pyrrolobenzodiazepine dimers, indolino-benzodiazepine dimers, enediynes, auristatins and anthracyclines.
- D is a pyrrolobenzodiazepine dimer.
- the antibody-conjugate according to the present aspect is according to formula (A) and preferably linker L contains the group according to formula (1 ) or a salt thereof, wherein (A) and (1 ) are as defined above.
- S(F ) X is 6-azido- 6-deoxy-A/-acetylgalactosamine (6-AzGalNAc or 6-N3-GalNAc).
- the antibody AB capable of targeting HER2-expressing tumours is selected from the group consisting of from trastuzumab, margetuximab, pertuzumab, HuMax- Her2, ertumaxomab, HB-008, ABP-980, BCD-022, CanMab, Herzuma, HD201 , CT-P6, PF- 05280014, COVA-208, FS-102, MCLA-128, CKD-10101 , HT-19 and functional analogues thereof. More preferably, the antibody AB capable of targeting HER2-expressing tumours is trastuzumab or a functional analogue thereof.
- the antibody AB is trastuzumab
- target molecule D is selected from the group consisting of maytansinoids, auristatines and pyrrolobenzodiazepine dimer, preferably auristatines selected from the group consisting of MMAD, MMAE, MMAF and functional analogues thereof or maytansinoids selected form the group consisting of DM1 , DM3, DM4, Ahx- May and functional analogues thereof.
- D Ahx- May.
- the antibody-conjugate according is represented by Formula (40) or (40b):
- R 3 is independently selected from the group consisting of hydrogen, halogen, -OR 35 , -NO2, -CN, -S(0)2R 35 , Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R 3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R 35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 -
- - X is C(R 3 )2, O, S or NR 32 , wherein R 32 is R 3 or L 3 (D , wherein L 3 is a linker, and D is as defined in claim 1 ;
- - r is 1 - 20;
- - aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8
- - aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8
- - b is 0 or 1 ;
- - pp is 0 or 1 ;
- - M is -N(H)C(0)CH 2 - -N(H)C(0)CF 2 -, -CH 2 -, -CF 2 - or a 1 ,4-phenylene containing 0 - 4 fluorine substituents, preferably 2 fluorine substituents which are preferably positioned on C2 and C6 or on C3 and C5 of the phenylene;
- the antibody is according to any one of Formulae (41 ), (42), (42b), (35b), (40c) and (40d) as defined above.
- the antibody-conjugate according to the present aspect is a bioconjugate represented by formula (A):
- - B is a biomolecule
- - L is a linker linking B and D;
- L comprises a group according to formula (1 ) or a salt thereof:
- R is selected from the group consisting of hydrogen, Ci C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR 3 wherein R 3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
- conjugates (I) - (XXIV) are listed here below as conjugates (I) - (XXIV).
- the antibody-conjugate according to the present aspect is selected from the conjugates defined here below as (I) - (XXIV), preferably selected from the conjugates defined here below as (I) - (X), more preferably selected from the conjugates defined here below as (I) - (VI).
- the antibody-conjugates according to the present aspect have an improved therapeutic index compared to known antibody-conjugates, wherein the therapeutic index is preferably for the treatment of HER2-expressing tumours.
- the improved therapeutic index may take the form of an improved therapeutic efficacy and/or an improved tolerability.
- the antibody- conjugates according to the present aspect have an improved therapeutic efficacy compared to known antibody-conjugates for the treatment of HER2-expressing tumours.
- the antibody-conjugates according to the present aspect have an improved tolerability compared to known antibody-conjugates for the treatment of HER2-expressing tumours.
- the antibody-conjugates according to the invention outperform the known antibody-conjugates also in other aspects.
- the inventors have found that the present antibody-conjugates exhibit an increased stability (i.e. they exhibit less degradation over time).
- the inventors have also found that the present antibody-conjugates exhibit decreased aggregation issues (i.e. they exhibit less aggregation over time).
- the present antibody-conjugates are a marked improvement over prior art antibody-conjugates.
- the invention thus also concerns the use of the mode of conjugation as defined herein for improving stability of an bioconjugate, typically an antibody-conjugate.
- the invention thus also concerns the use of the mode of conjugation as defined herein for decreasing aggregation of an bioconjugate, typically an antibody-conjugate.
- the invention concerns a fusion enzyme comprising two endoglycosidases.
- the two endoglycosidases EndoS and EndoH are connected via a linker, preferably a -(Gly4Ser)3-(His)6-(Gly4Ser)3- linker.
- the fusion enzyme according to the invention as also referred to as EndoSH.
- the enzyme according to the invention has at least 50% sequence identity with SEQ ID NO: 1 , preferably at least 70%, more preferably at least 80% sequence identity with SEQ ID NO: 1 , such as at least 81 %, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% sequence identity with SEQ ID NO: 1.
- the enzyme of the invention having the above indicated sequence identity to SEQ ID NO: 1 , has EndoS and EndoH activity. Most preferably, the enzyme according to the invention has 100% sequence identity with SEQ ID NO: 1.
- fusion enzymes of EndoS and EndoH wherein the linker is replaced by another suitable linker known in the art, wherein said linker may be a rigid, or flexible.
- said linker is a flexible linker allowing the adjacent protein domains to move relative freely to one another.
- said flexible linker is composed of amino residues like glycine, serine, histidine and/or alanine and has a length of 3 to 59 amino acid residues, preferably 10 to 45 or 15 to 40 amino acid residues, such as 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35, 36, 37, 38, 39 or 40 amino acid residues, or 20 to 38, 25 to 37 or 30 to 36 amino acid residues.
- the fusion enzyme is covalently linked to, or comprises, a tag for ease of purification and or detection as known in the art, such as an Fc-tag, FLAG-tag, poly(His)- tag, HA-tag and Myc-tag.
- Trimming of glycoproteins is known in the art, from e.g. WO 2007/133855 or WO 2014/065661 .
- the enzyme according to the invention exhibits both EndoS and EndoH activity, and is capable of trimming glycans on glycoproteins (such as antibodies) at the core-GlcNAc unit, leaving only the core-GlcNAc residue on the glycoprotein (EndoS activity) as well as well as splitting off high- manose glycans (EndoH activity).
- both activities of the fusion enzyme function smoothly at a pH around 7 - 8, while monomeric EndoH requires a pH of 6 to operate optimally.
- the fusion enzyme according to the invention can be prepared by routine techniques in the art, such as introducing an expression vector (e.g. plasmid) comprising the enzyme coding sequence into a host cell (e.g. E. coli) for expression, from which the enzyme can be isolated.
- an expression vector e.g. plasmid
- a host cell e.g. E. coli
- trastuzumab is efficiently trimmed in a single step.
- 6-N3-GalNAc 6-azido-6- deoxy-A/-acetylgalactosamine
- GalNAz 2-azidoacetamido-2-deoxy-galactose
- F2-GalNAz 2-azidodifluoroacetamido-2-deoxy-galactose.
- RP-HPLC analysis of reduced monoclonal antibodies Prior to RP-HPLC analysis samples were reduced by incubating a solution of 10 ⁇ g (modified) IgG for 15 minutes at 37 °C with 10 mM DTT and 100 mM Tris pH 8.0 in a total volume of 50 ⁇ _. A solution of 49% ACN, 49% MQ and 2% formic acid (50 ⁇ _) was added to the reduced sample.
- Mass spectral analysis of monoclonal antibodies Prior to mass spectral analysis, IgGs were either treated with DTT, which allows analysis of both light and heavy chain, or treated with FabricatorTM (commercially available from Genovis, Lund, Sweden), which allows analysis of the Fc/2 fragment.
- DTT dimethylcellulose
- FabricatorTM commercially available from Genovis, Lund, Sweden
- Trastuzumab was expressed from a stable CHO cell line by Bioceros (Utrecht, Netherlands). The supernatant (2.5 L) was purified using a XK 26/20 column packed with 50 mL protein A sepharose. In a single run 0.5 L supernatant was loaded onto the column followed by washing with at least 10 column volumes of 25 mM Tris pH 7.5, 150 mM NaCI. Retained protein was eluted with 0.1 M Glycine pH 2.7. The eluted product was immediately neutralized with 1.5 M Tris- HCI pH 8.8 and dialyzed against 25 mM Tris pH 8.0.
- Example 2 Transient expression and purification of His-TnGalNAcT(33-421) His-TnGalNAcT(33-421 ) (identified by SEQ ID NO: 3) was transiently expressed in CHO K1 cells by Evitria (Zurich, Switzerland) at 5 L scale. The supernatant was purified using a XK 16/20 column packed with 25 mL Ni sepharose excel (GE Healthcare).
- EndoSH EndoS-(G4S)3-(His)6-(G4S)3-EndoH (EndoSH) coding sequence (EndoSH being identified by SEQ ID NO: 1 ) between Ndel-Hindlll sites was obtained from Genscript.
- the DNA sequence for the EndoSH fusion protein consists of the encoding residues 48-995 of EndoS fused via an /V-terminal linked glycine-serine (GS) linker to the coding residues 41-313 of EndoH.
- the glycine-serine (GS) linker comprises a -(G4S)3-(His)6-EF-(G4S)3- format, allowing spacing of the two enzymes and at the same time introducing a IMAC-purification tag.
- EndoSH fusion protein (identified by SEQ ID NO: 1 ) starts with the transformation of the plasmid (pET22b-EndoSH) into BL21 cells.
- Next step is the inoculation of 500 mL culture (LB medium + Ampilicin) with BL21 cells. When the OD600 reached 0.7 the cultures were induced with 1 mM IPTG (500 [it of 1 M stock solution).
- the column was first washed with buffer A (20 mM Tris buffer, 20 mM imidazole, 500 mM NaCI, pH 7.5). Retained protein was eluted with buffer B (20 mM Tris, 500 mM NaCI, 250 mM imidazole, pH 7.5, 10 mL). Fractions were analysed by SDS-PAGE on polyacrylamide gels (12%). The fractions that contained purified target protein were combined and the buffer was exchanged against 20 mM Tris pH 7.5 and 150 mM NaCI by dialysis performed overnight at 4 °C. The purified protein was concentrated to at least 2 mg/mL using an Amicon Ultra-0.5, Ultracel-10 Membrane (Millipore). The product is stored at -80 °C prior to further use.
- buffer A (20 mM Tris buffer, 20 mM imidazole, 500 mM NaCI, pH 7.5
- buffer B 20 mM Tris, 500 mM NaCI, 250 mM imid
- trastuzumab(GalNAz) 2 13b (Examples 12, 13, 15, 16-1 );
- trastuzumab(F 2 -GalNAz) 2 13c (Examples 1 , 7 - 13, 16-2)
- trastuzumab obtained via stable expression in CHO cells performed by Bioceros (Utrecht, Netherlands) was performed with fusion protein EndoSH.
- trastuzumab (100.8 mL, 2 g, 19.85 mg/ml in 25 mM Tris pH 8.0) was incubated with EndoSH (5.26 mL, 20 mg, 3.8 mg/mL in 25 mM Tris pH 7.5) for approximately 16 hours at 37 °C.
- Mass spectral analysis of a fabricator-digested sample showed one major peak of the Fc/2-fragment (observed mass 24135 Da, approximately 90% of total Fc/2 fragment), corresponding to core-GlcNAc(Fuc)-substituted trastuzumab.
- Trimmed trastuzumab (1 1 .8 mg/mL), obtained by EndoSH treatment of trastuzumab as described above in example 6, was incubated with the substrate 6-N3-GalNAc-UDP (3.3 mM, commercially available from GlycoHub) and His-TnGalNAcT(33-421 ) (0.75 mg/mL) in 10 mM MnCI 2 and 25 mM Tris-HCI pH 8.0 at 30 °C. The reaction was incubated overnight at 30 °C. Biomolecule 13d was purified from the reaction mixture using a XK 26/20 column packed with 50 mL protein A sepharose using an AKTA purifier-10 (GE Healthcare).
- AKTA purifier-10 GE Healthcare
- the eluted IgG was immediately neutralized with 1.5 M Tris-HCI pH 8.8 and dialyzed against PBS pH 7.4. Next the IgG was concentrated using an Amicon Ultra-0.5, Ultracel-10 Membrane (Millipore) to a concentration of 28.5 mg/mL. Mass spectral analysis of a fabricator-digested sample showed one major peak of the Fc/2-fragment (observed mass 24363 Da, approximately 90% of total Fc/2 fragment), corresponding to core 6-N3-GalNAc-GlcNAc(Fuc)-substituted trastuzumab. Linker-coniuqate syntheses: Examples 8-23:
- Chlorosulfonyl isocyanate (CSI; 0.91 mL, 1.48 g, 10 mmol) was added to a cooled (-78 °C) solution of ieri-butanol (5.0 mL, 3.88 g, 52 mmol) in Et.20 (50 mL). The reaction mixture was allowed to warm to rt and was concentrated. The residue was suspended in DCM (200 mL) and subsequently Et3N (4.2 mL, 3.0 g, 30 mmol) and 2-(2-aminoethoxy)ethanol (1.0 mL, 1.05 g; 10 mmol) were added. The resulting mixture was stirred for 10 min and concentrated.
- CSI Chlorosulfonyl isocyanate
- Val-Cit-PABC-Ahx-May.TFA (20 mg; 15.6 ⁇ ) in DMF (0.50 mL) were added triethylamine (6.5 ⁇ ; 4.7 mg; 47 ⁇ ) and a solution of compound 99 (prepared via activation of compound 58 as disclosed in and prepared according to Example 50 of PCT/NL2015/050697 (WO 2016/053107); 24 mg, 46 ⁇ ) in DMF (293 ⁇ ).
- the mixture was left standing for 21 h and 2,2'-(ethylenedioxy)bis(ethylamine) (14 ⁇ , 14 mg, 96 ⁇ ) was added.
- the bioconjugate according to the invention was prepared by conjugation of compound 30 as linker-conjugate to modified biomolecule 13b as biomolecule.
- DMA trastuzumab(azide) 2
- DMA 255 ⁇ , 40 mM solution DMA
- the reaction was incubated overnight at rt followed by purification on a HiLoad 26/600 Superdex200 PG column (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare).
Landscapes
- Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Engineering & Computer Science (AREA)
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Medicinal Chemistry (AREA)
- Veterinary Medicine (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- General Health & Medical Sciences (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Immunology (AREA)
- Cell Biology (AREA)
- Reproductive Health (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Molecular Biology (AREA)
- Oncology (AREA)
- Hematology (AREA)
- Biochemistry (AREA)
- Toxicology (AREA)
- Medicinal Preparation (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
Abstract
The present invention concerns novel and improved antibody-conjugates for targeting HER2. The inventors found that when antibody-conjugates were prepared using a specific mode of conjugation, they exhibit an improved therapeutic index. The mode of conjugation comprises a first step (i) of contacting a glycoprotein comprising 1 - 4 core N-acetylglucosamine moieties with a compound of the formula S(F1)x-P in the presence of a catalyst, wherein S(F1)x is a sugar derivative comprising x functional groups F1 capable of reacting with a functional group Q1, x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F1)x moiety to the core-GlcNAc moiety, to obtain a modified antibody; and a second step (ii) of reacting the modified antibody with a linker-conjugate comprising a functional group Q1 capable of reacting with functional group F1 and a target molecule D connected to Q1 via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q1 and F1. The invention also relates to a use for improving the therapeutic index of an antibody-conjugate and to a method for targeting HER2-expressing cells.
Description
ANTIBODY-CONJUGATES WITH IMPROVED THERAPEUTIC INDEX FOR TARGETING CD30 TUMOURS AND METHOD FOR IMPROVING THERAPEUTIC INDEX OF ANTIBODY-CONJUGATES
Field of the invention
The present invention is in the field of bioconjugation. More specifically, the invention relates to a specific mode of conjugation to prepare bioconjugates that have a beneficial effect on the therapeutic index of the bioconjugate, in particular in the targeting of HER2-expressing tumours.
Background of the invention
Bioconjugation is the process of linking two or more molecules, of which at least one is a biomolecule. The biomolecule(s) may also be referred to as "biomolecule(s) of interest", the other molecule(s) may also be referred to as "target molecule" or "molecule of interest". Typically the biomolecule of interest (BOI) will consist of a protein (or peptide), a glycan, a nucleic acid (or oligonucleotide), a lipid, a hormone or a natural drug (or fragments or combinations thereof). The other molecule of interest (MOI) may also be a biomolecule, hence leading to the formation of homo- or heterodimers (or higher oligomers), or the other molecule may possess specific features that are imparted onto the biomolecule of interest by the conjugation process. For example, the modulation of protein structure and function by covalent modification with a chemical probe for detection and/or isolation has evolved as a powerful tool in proteome-based research and biomedical applications. Fluorescent or affinity tagging of proteins is key to studying the trafficking of proteins in their native habitat. Vaccines based on protein-carbohydrate conjugates have gained prominence in the fight against HIV, cancer, malaria and pathogenic bacteria, whereas carbohydrates immobilized on microarrays are instrumental in elucidation of the glycome. Synthetic DNA and RNA oligonucleotides (ONs) require the introduction of a suitable functionality for diagnostic and therapeutic applications, such as microarray technology, antisense and gene- silencing therapies, nanotechnology and various materials sciences applications. For example, attachment of a cell-penetrating ligand is the most commonly applied strategy to tackle the low internalization rate of ONs encountered during oligonucleotide-based therapeutics (antisense, siRNA). Similarly, the preparation of oligonucleotide-based microarrays requires the selective immobilization of ONs on a suitable solid surface, e.g. glass.
There are numerous examples of chemical reactions suitable to covalently link two (or more) molecular structures. However, labelling of biomolecules poses high restrictions on the reaction conditions that can be applied (solvent, concentration, temperature), while the desire of chemoselective labelling limits the choice of reactive groups. For obvious reasons, biological systems generally flourish best in an aqueous environment meaning that reagents for bioconjugation should be suitable for application in aqueous systems. In general, two strategic concepts can be recognized in the field of bioconjugation technology: (a) conjugation based on a functional group already present in the biomolecule of interest, such as for example a thiol, an amine, an alcohol or a hydroxyphenol unit or (b) a two-stage process involving engineering of one (or more) unique reactive groups into a BOI prior to the actual conjugation process.
The first approach typically involves a reactive amino acid side-chain in a protein (e.g. cysteine, lysine, serine and tyrosine), or a functional group in a glycan (e.g. amine, aldehyde) or nucleic acid (e.g. purine or pyrimidine functionality or alcohol). As summarized inter alia in G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013, incorporated by reference, a large number of reactive functional groups have become available over the years for chemoselective targeting of one of these functional groups, such as maleimide, haloacetamide, activated ester, activated carbonate, sulfonyl halide, activated thiol derivative, alkene, alkyne, allenamide and more, each of which requiring its own specific conditions for conjugation (pH, concentration, stoichiometry, light, etc.). Most prominently, cysteine-maleimide conjugation stands out for protein conjugation by virtue of its high reaction rate and chemoselectivity. However, when no cysteine is available for conjugation, as in many proteins and certainly in other biomolecules, other methods are often required, each suffering from its own shortcomings.
An elegant and broadly applicable solution for bioconjugation involves the two-stage approach. Although more laborious, two-stage conjugation via engineered functionality typically leads to higher selectivity (site-specificity) than conjugation on a natural functionality. Besides that, full stability can be achieved by proper choice of construct, which can be an important shortcoming of one stage conjugation on native functionality, in particular for cysteine-maleimide conjugation. Typical examples of a functional group that may be imparted onto the BOI include (strained) alkyne, (strained) alkene, norbornene, tetrazine, azide, phosphine, nitrile oxide, nitrone, nitrile imine, diazo compound, carbonyl compound, (O-alkyl)hydroxylamine and hydrazine, which may be achieved by either chemical or molecular biology approach. Each of the above functional groups is known to have at least one reaction partner, in many cases involving complete mutual reactivity. For example, cyclooctynes react selectively and exclusively with 1 ,3-dipoles, strained alkenes with tetrazines and phosphines with azides, leading to fully stable covalent bonds. However, some of the above functional groups have the disadvantage of being highly lipophilic, which may compromise conjugation efficiency, in particular in combination with a lipophilic molecule of interest (see below).
The final linking unit between the biomolecule and the other molecule of interest should preferentially also be fully compatible with an aqueous environment in terms of solubility, stability and biocompatibility. For example, a highly lipophilic linker may lead to aggregation (during and/or after conjugation), which may significantly increase reaction times and/or reduce conjugation yields, in particular when the MOI is also of hydrophobic nature. Similarly, highly lipophilic linker- MOI combination may lead to unspecific binding to surfaces or specific hydrophobic patches on the same or other biomolecules. If the linker is susceptible to aqueous hydrolysis or other water- induced cleavage reactions, the components comprising the original bioconjugate separate by diffusion. For example, certain ester moieties are not suitable due to saponification while β- hydroxycarbonyl or γ-dicarbonyl compounds could lead to retro-aldol or retro-Michael reaction, respectively. Finally, the linker should be inert to functionalities present in the bioconjugate or any other functionality that may be encountered during application of the bioconjugate, which excludes, amongst others, the use of linkers featuring for example a ketone or aldehyde moiety
(may lead to imine formation), an α,β-unsaturated carbonyl compound (Michael addition), thioesters or other activated esters (amide bond formation).
Compounds made of linear oligomers of ethylene glycol, so-called polyethylene glycol (PEG) linkers, enjoy particular popularity nowadays in biomolecular conjugation processes. PEG linkers are highly water soluble, non-toxic, non-antigenic, and lead to negligible or no aggregation. For this reason, a large variety of linear, bifunctional PEG linkers are commercially available from various sources, which can be selectively modified at either end with a (bio)molecule of interest. PEG linkers are the product of a polymerization process of ethylene oxide and are therefore typically obtained as stochastic mixtures of chain length, which can be partly resolved into PEG constructs with an average weight distribution centred around 1 , 2, 4 kDa or more (up to 60 kDa). Homogeneous, discrete PEGs (dPEGs) are also known with molecular weights up to 4 kDa and branched versions thereof go up to 15 kDa. Interestingly, the PEG unit itself imparts particular characteristics onto a biomolecule. In particular, protein PEGylation may lead to prolonged residence in vivo, decreased degradation by metabolic enzymes and a reduction or elimination of protein immunogenicity. Several PEGylated proteins have been FDA-approved and are currently on the market.
By virtue of its high polarity, PEG linkers are perfectly suitable for bioconjugation of small and/or water-soluble moieties under aqueous conditions. However, in case of conjugation of hydrophobic, non-water-soluble molecules of interest, the polarity of a PEG unit may be insufficient to offset hydrophobicity, leading to significantly reduced reaction rates, lower yields and induced aggregation issues. In such case, lengthy PEG linkers and/or significant amounts of organic co-solvents may be required to solubilize the reagents. For example, in the field of antibody-drug conjugates, the controlled attachment of a distinct number of toxic payloads to a monoclonal antibody is key, with a payload typically selected from the group of auristatins E or F, maytansinoids, duocarmycins, calicheamicins or pyrrolobenzodiazepines (PBDs), with many others are underway. With the exception of auristatin F, all toxic payloads are poorly to non-water- soluble, which necessitates organic co-solvents to achieve successful conjugation, such as 25% dimethylacetamide (DMA) or 50% propylene glycol (PG). In case of hydrophobic payloads, despite the use of aforementioned co-solvents, large stoichiometries of reagents may be required during conjugation while efficiency and yield may be significantly compromised due to aggregation (in process or after product isolation), as for example described by Senter ef al. in Nat. Biotechn. 2014, 24, 1256-1263, incorporated by reference. The use of long PEG spacers (12 units or more) may partially enhance solubility and/or conjugation efficiency, but it has been shown that long PEG spacers may lead to more rapid in vivo clearance, and hence negatively influence the pharmacokinetic profile of the ADC.
Using conventional linkers (e.g. PEG), effective conjugation is often hampered by the relatively low solubility of the linker-conjugate in aqueous media, especially when a relative water-insoluble or hydrophobic target molecule is used. In their quest for a short, polar spacer that enables fast and efficient conjugation of hydrophobic moieties, the inventors have developed the sulfamide linker, which was found to improve the solubility of the linker-conjugate, which in turn significantly
improves the efficiency of the conjugation and reduces both in process and product aggregation. This is disclosed in patent application PCT/NL2015/050697 (WO 2016/053107), which is incorporated herein in its entirety.
Linkers are known in the art, and disclosed in e.g. WO 2008/070291 , incorporated by reference. WO 2008/070291 discloses a linker for the coupling of targeting agents to anchoring components. The linker contains hydrophilic regions represented by polyethylene glycol (PEG) and an extension lacking chiral centers that is coupled to a targeting agent.
WO 01/88535, incorporated by reference, discloses a linker system for surfaces for bioconjugation, in particular a linker system having a novel hydrophilic spacer group. The hydrophilic atoms or groups for use in the linker system are selected from the group consisting of
0, NH, C=0 (keto group), 0-C=0 (ester group) and CR3R4, wherein R3 and R4 are independently selected from the group consisting of H, OH, C1-C4 alkoxy and Ci-C4 acyloxy.
WO 2014/100762, incorporated by reference, describes compounds with a hydrophilic self- immolative linker, which is cleavable under appropriate conditions and incorporates a hydrophilic group to provide better solubility of the compound. The compounds comprise a drug moiety, a targeting moiety capable of targeting a selected cell population, and a linker which contains an acyl unit, an optional spacer unit for providing distance between the drug moiety and the targeting moiety, a peptide linker which can be cleavable under appropriate conditions, a hydrophilic self- immolative linker, and an optional second self-immolative spacer or cyclization self-elimination linker. The hydrophilic self-immolative linker is e.g. a benzyloxycarbonyl group.
Summary of the invention
The invention relates to a method or use for increasing the therapeutic index of a bioconjugate,
1. e. the conjugate of a biomolecule and a target molecule. The inventors surprisingly found that a bioconjugate prepared via a specific mode of conjugation exhibits a greater therapeutic index compared to the same bioconjugate, i.e. the same biomolecule, the same target molecule (e.g. active substance) and the same biomolecule drug ratio, obtained via a different mode of conjugation. The mode of conjugating a biomolecule to a target molecule is exposed in the linker itself and/or in the attachment point of the linker to the biomolecule. That the linker and/or attachment point could have an effect on the therapeutic index of a bioconjugate, such as an antibody-drug-conjugate, could not be envisioned based on the current knowledge. In the field, linkers are considered inert when it comes to treatment and are solely present as a consequence of the preparation of the bioconjugate. That the selection of a specific mode of conjugation has an effect on the therapeutic index is unprecedented and a breakthrough discovery in the field of bioconjugates, in particular antibody-drug-conjugates.
The bioconjugates according to the invention are on one hand more efficacious (therapeutically effective) as the same bioconjugates, i.e. the same biomolecule, the same target molecule (e.g. active substance) and the same biomolecule/target molecule ratio, obtained via a different mode of conjugation, and/or on the other hand exhibit a greater tolerability. This finding has dramatic implications on the treatment of subjects with the bioconjugate according to the invention, as the
therapeutic window widens. As a result of the expansion of the therapeutic window, the treatment dosages may be lowered and as a consequence potential, unwanted, side-effects are reduced. In one embodiment, the mode of conjugation according to the invention comprises:
(i) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine substituents with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q , x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified antibody according to Formula (24):
(Fuc)b
AB- GlcNAc- -S(F1)X
(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
(ii) reacting the modified antibody with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F .
In one embodiment, the mode of conjugation according to the invention ensure that the bioconjugate contains a linker L comprising a group according to formula (1 ) or a salt thereof:

The inventors surprisingly found that a bioconjugate prepared such that it contains a linker L comprising a group according to formula (1 ) or a salt thereof exhibits a greater therapeutic index compared to the same bioconjugate, i.e. the same biomolecule, the same target molecule (e.g. active substance) and the same biomolecule drug ratio, containing a linker without the group according to formula (1 ) present.
In group according to formula (1 ),
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O,
S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, wherein D is optionally connected to N via a spacer moiety.
In the context of the present invention, the mode of conjugation is being used to connect an biomolecule B with a target molecule D via a linker L. Conjugation refers to the specific mode of connecting the biomolecule to the target molecule. The bioconjugate according to the invention is represented by formula (A):
B-L-D wherein:
- B is a biomolecule;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety.
For the embodiment wherein the mode of conjugation is referred to as "sulfamide linkage", the following embodiments are preferred:
1. Method for increasing the therapeutic index of a bioconjugate, comprising the step of preparing the bioconjugate of formula (A):
B-L-D wherein:
- B is a biomolecule;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety,
by reacting a reactive group Q on a target molecule (D) with a functional group F on a biomolecule (B), such that L comprises a group according to formula (1 ) or a salt thereof:

1
wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and
C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S or NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety. The method according to embodiment 1 , further comprising a step of administering the bioconjugate to a subject in need thereof.
The method according to embodiment 2, wherein the subject is a cancer patient.
The method according to any of the preceding embodiments, wherein the biomolecule is an antibody and the bioconjugate is an antibody-drug-conjugate.
The method according to any of the preceding embodiments, wherein target molecule D is an active substance, preferably a cytotoxin.
The method according to any of the preceding embodiments, wherein the bioconjugate has the formula B-Z3-L-D, wherein Z3 is obtained by the reacting reactive group Q with the functional group F .
The method according to embodiment 6, wherein Z3 is obtained by the reacting a linker- conjugate having formula Q -L-D, wherein L comprises a group according to formula (1 ) or a salt thereof:

1
with a biomolecule having formula B-F , wherein B, D, a and R are as defined in embodiment 1.
The process according to embodiment 7, wherein the linker-conjugate is according to formula (4a) or (4b), or a salt thereof:

4a

4b
wherein:
- a is independently 0 or 1 ;
- b is independently 0 or 1 ;
- c is 0 or 1 ;
- d is 0 or 1 ;
- e is 0 or 1 ;
- f is an integer in the range of 1 to 150;
- g is 0 or 1 ;
- i is 0 or 1 ;
- D is a target molecule;
- Q is a reactive group capable of reacting with a functional group F present on a biomolecule;
- Sp is a spacer moiety;
- Sp2 is a spacer moiety;
- Sp3 is a spacer moiety;
- Sp4 is a spacer moiety;
- Z is a connecting group that connects Q or Sp3 to Sp2, O or C(O) or N(R1 );
- Z2 is a connecting group that connects D or Sp4 to Sp1, N(R1 ), O or C(O); and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or R is D, -[(Sp )b(Z2)e(Sp4)iD] or -[(Sp2)c(Z )d(Sp3)gQ1], wherein D is a target molecule and Sp1, Sp2, Sp3, Sp4, Z , Z2, D, Q , b, c, d, e, g and i are as defined above.
Process according to embodiment 8, wherein Sp1, Sp2, Sp3 and Sp4 are independently selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cydoalkylene groups, C5-C200 cydoalkenylene groups, C8-C200 cydoalkynylene groups, C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups and C9-C200 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cydoalkylene groups, cydoalkenylene groups, cydoalkynylene groups, alkylarylene groups, arylalkylene groups,
arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted. Process according to embodiment 8 or 9, wherein Z and Z2 are independently selected from the group consisting -0-, -S-, -NR2-, -N=N-, -C(O)-, -C(0)NR2-, -OC(O)-, -OC(0)0-, -OC(0)NR2, -NR2C(0)-, -NR2C(0)0-, -NR2C(0)NR2-, -SC(O)-, -SC(0)0-, -SC(0)NR2-, -S(O), -S(0)2-, -OS(0)2-, -OS(0)20-, -OS(0)2NR2-, -OS(O)-, -OS(0)0-, -OS(0)NR2-, -ONR2C(0)-, -ONR2C(0)0-, -ONR2C(0)NR2-, -NR2OC(0)-, -NR2OC(0)0-, -NR2OC(0)NR2-, -ONR2C(S)-, -ONR2C(S)0-, -ONR2C(S)NR2-, -NR2OC(S)-, -NR2OC(S)0-, -NR2OC(S)NR2-, -OC(S)-, -OC(S)0-, -OC(S)NR2-, -NR2C(S)-, -NR2C(S)0-, -NR2C(S)NR2-, -SS(0)2-, -SS(0)20-, -SS(0)2NR2-, -NR2OS(0)-, -NR2OS(0)0-, -NR2OS(0)NR2-, -NR2OS(0)2-, -NR2OS(0)20-, -NR2OS(0)2NR2-, -ONR2S(0)-, -ONR2S(0)0-, -ONR2S(0)NR2-, -ONR2S(0)20-, -ONR2S(0)2NR2-, -ONR2S(0)2-, -OP(0)(R2)2-, -SP(0)(R2)2-, -NR2P(0)(R2)2- and combinations of two or more thereof, wherein R2 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
Process according to any one of embodiments 8 - 10, wherein Sp\ Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group consisting of O, S or NR3, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, and wherein Q


9t 9zh
wherein:
- U is O or NR9, and R9 is hydrogen, a linear or branched Ci - C12 alkyl group or a C4 - C12 (hetero)aryl group.
- R 0 is a (thio)ester group; and
- R 8 is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups.
The method according to any of the preceding embodiments, wherein the reaction between reactive group Q and functional group F is a conjugation reaction selected from thiol-alkene conjugation to from a connecting moiety Z3 that may be represented as (10a) or (10b), amino-(activated) carboxylic acid conjugation to from a connecting moiety Z3 that may be represented as (10c), ketone-hydrazino conjugation to from a connecting moiety Z3 that may be represented as (10d) wherein Y = NH, ketone-oxyamino conjugation to from a connecting moiety Z3 that may be represented as (10d) wherein Y = O, alkyne-azide conjugation to from a connecting moiety Z3 that may be represented as (10e) or (10g) and alkene-1 , 2,4,5- tetrazine conjugation or alkyne-1 ,2,4,5-tetrazine conjugation to from a connecting moiety Z3 that may be represented as (10h) from which N2 eliminates, wherein moieties (10a), (10b), (10c), (10d), (10e), (10g) and (10h) are represented by:

13. The method according to any of the preceding embodiments, wherein a = 0.
14. Bioconjugate for use in the treatment of a subject in need thereof, wherein the bioconjugate is represented by formula (A):
B-L-D
(A),
wherein:
- B is a biomolecule;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety,
wherein L comprises a group according to formula (1 ) or a salt thereof:

wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2
- C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
15. Bioconjugate for use according to embodiment 14, for use in the treatment of cancer.
The present invention thus concerns in a first aspect a method or use for increasing the therapeutic index of a bioconjugate, wherein the mode of conjugation according to the invention is comprised in or used to prepare the bioconjugate. In one embodiment, the mode of conjugation comprises steps (i) and (ii) as defined herein. In an alternative embodiment, the mode of conjugation comprises the step of preparing the bioconjugate of formula (A) such that linker L as defined above is comprised in the bioconjugate. In one embodiment, the method or use according to the invention further comprises administering the bioconjugate to a subject in need thereof. The invention according to the first aspect can also be worded as the use of the mode of conjugation as defined above in a bioconjugate for increasing the therapeutic index of the bioconjugate, or to
the use of linker L as defined above in a bioconjugate for increasing the therapeutic index of the bioconjugate.
In a further aspect, the present invention concerns the treatment of a subject in need thereof, comprising the administration of the bioconjugate according to the invention. Typically, the bioconjugate is administered in a therapeutically effective dose. In view of the increased therapeutic efficacy, administration may occur less frequent as in treatment with conventional bioconjugates and/or in a lower dose. Alternatively, in view of the increased tolerability, administration may occur more frequent as in treatment with conventional bioconjugates and/or in a higher dose. Administration may be in a single dose or may e.g. occur 1 - 4 times a month, preferably 1 - 2 times a month, more preferable administration occurs once every 3 or 4 weeks, most preferably every 4 weeks. As will be appreciated by the person skilled in the art, the dose of the bioconjugate according to the invention may depend on many factors and optimal doses can be determined by the skilled person via routine experimentation. The bioconjugate is typically administered in a dose of 0.01 - 50 mg/kg body weight of the subject, more accurately 0.03 - 25 mg/kg or most accurately 0.05 - 10 mg/kg, or alternatively 0.1 - 25 mg/kg or 0.5 - 10 mg/kg.
In one embodiment, the administration of the bioconjugate according to the invention is at a dose that is lower than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89- 60%, even more preferable 59-30%, most preferably at most 29-10% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention. Alternatively, the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 10-29%, more preferably at most 30-59%, even more preferable 60-89%, most preferably at most 90-99% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
In one embodiment, the administration of the bioconjugate according to the invention is at a dose that is lower than the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89- 60%, even more preferable 59-30%, most preferably at most 29-10% of the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention. Alternatively, the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most a factor 1.1 - 1.49 higher, more preferably at most a factor 1 .5 - 1.99 higher, even more preferable a factor 2 - 4.99 higher, most preferably at most a factor 5 - 10 higher of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
The preparation of the bioconjugate typically comprises the step of reacting linker-conjugate having the formula Q -L-D, wherein L and D are as defined above and Q is a reactive group capable of reacting with a functional group F , with a biomolecule having the formula B-F ,
wherein B is as defined above and F is a functional group capable of reacting with Q . Herein, Q and F react to form a connecting group Z3, which is located in the bioconjugate according to formula (A) in the spacer moiety between B and L. Description of the figures
Figure 1 describes the general concept of conjugation of biomolecules: a biomolecule of interest (BOI) containing one or more functional groups F is incubated with (excess of) a target molecule D (also referred to as molecule of interest or MOI) covalently attached to a reactive group Q via a specific linker. In the process of bioconjugation, a chemical reaction between F and Q takes place, thereby forming a bioconjugate comprising a covalent connection between the BOI and the MOI. The BOI may e.g. be a peptide/protein, a glycan or a nucleic acid.
Figure 2 shows several structures of derivatives of UDP sugars of galactosamine, which may be modified with e.g. a 3-mercaptopropionyl group (11a), an azidoacetyl group (11 b), or an azidodifluoroacetyl group (11c) at the 2-position, or with an azido azidoacetyl group at the 6- position of N-acetyl galactosamine (11d).
Figure 3 schematically displays how any of the UDP-sugars 11a-d may be attached to a glycoprotein comprising a GlcNAc moiety 12 (e.g. a monoclonal antibody the glycan of which is trimmed by an endoglycosidase) under the action of a galactosyltransferase mutant or a GalNAc- transferase, thereby generating a β-glycosidic 1-4 linkage between a GalNAc derivative and GlcNAc (compounds 13a-d, respectively).
Figure 4 shows how a modified antibody 13a-d may undergo a bioconjugation process by means of nucleophilic addition to maleimide (as for 3-mercaptopropionyl-galactosamine-modified 13a leading to thioether conjugate 14, or for conjugation to a engineered cysteine residue leading to thioether conjugate 17) or upon strain-promoted cycloaddition with a cyclooctyne reagent (as for 13b, 13c or 13d leading to triazoles 15a, 15b or 16, respectively).
Figure 5 shows a representative set of functional groups (F ) in a biomolecule, either naturally present or introduced by engineering, which upon reaction with reactive group Q lead to connecting group Z3. Functional group F may also be artificially introduced (engineered) into a biomolecule at any position of choice.
Figure 6 shows preferred bioconjugates according to the invention. Conjugates 81-85 are prepared and the therapeutic index thereof investigated in the examples. Conjugates 81-85 are conjugated to trastuzumab as antibody.
Figures 7A-E depict the results of the tolerability studies of Example 34 for control antibody- conjugate Kadcyla (Fig. 7A) and antibody-conjugates according to the invention 84 (Fig. 7B), 81 (Fig. 7C), 82 (Fig. 7D), 83 (Fig. 7E). Percentage body weight change (Δ BW), based on 100 % on the start of treatment (day 1 ), over time is depicted. C = vehicle treated.
Figure 8A depicts the results of the efficacy studies of Example 33 for control antibody-conjugate Kadcyla (K) and antibody-conjugates according to the invention 81 - 84. Similar results are depicted in Figure 8B, wherein the efficacy of antibody-conjugates according to the invention 85 and control antibody-conjugate Kadcyla (K) are presented, and in Figure 8C, wherein efficacies of
antibody-conjugates according to the invention 95 - 98 are depicted. Efficacies are represented as the change in tumour volume over time, where a greater efficacy leads to a greater reduction or a lesser increase in tumour volume. C = vehicle treated. Figure 8D depicts the results of the efficacy studies of Example 33d for control antibody-conjugate Kadcyla (K) and antibody- conjugates according to the invention 84.
Description of embodiments
In the context of the present invention, the conjugation reaction involves on the one hand the biomolecule (BOI) containing a functional group F , and on the other hand the target molecule (MOI) containing a reactive group Q , or a "linker-conjugate" as defined herein, wherein Q reacts with F to form a connecting group that joins the BOI and the MOI in a bioconjugate. Herein, reactive group Q is joined via a linker to the MOI, said linker comprising the sulfamide moiety according to formula (1 ):

1
Reactive group Q may be attached to either ends of the moiety of formula (1 ), in which case the MOI is attached to the opposite end of the moiety of formula (1 ). In one embodiment, reactive group Q is attached to the moiety of formula (1 ) via the carbonyl end and the MOI is attached via the sulfamide end of the moiety of formula (1 ). In one embodiment, reactive group Q is attached to the moiety of formula (1 ) via the sulfamide end and the MOI is attached via the carbonyl end of the moiety of formula (1 ).
Definitions
The verb "to comprise", and its conjugations, as used in this description and in the claims is used in its non-limiting sense to mean that items following the word are included, but items not specifically mentioned are not excluded.
In addition, reference to an element by the indefinite article "a" or "an" does not exclude the possibility that more than one of the elements is present, unless the context clearly requires that there is one and only one of the elements. The indefinite article "a" or "an" thus usually means "at least one".
The compounds disclosed in this description and in the claims may comprise one or more asymmetric centres, and different diastereomers and/or enantiomers may exist of the compounds. The description of any compound in this description and in the claims is meant to include all diastereomers, and mixtures thereof, unless stated otherwise. In addition, the description of any compound in this description and in the claims is meant to include both the individual
enantiomers, as well as any mixture, racemic or otherwise, of the enantiomers, unless stated otherwise. When the structure of a compound is depicted as a specific enantiomer, it is to be understood that the invention of the present application is not limited to that specific enantiomer. The compounds may occur in different tautomeric forms. The compounds according to the invention are meant to include all tautomeric forms, unless stated otherwise. When the structure of a compound is depicted as a specific tautomer, it is to be understood that the invention of the present application is not limited to that specific tautomer.
The compounds disclosed in this description and in the claims may further exist as exo and endo diastereoisomers. Unless stated otherwise, the description of any compound in the description and in the claims is meant to include both the individual exo and the individual endo diastereoisomers of a compound, as well as mixtures thereof. When the structure of a compound is depicted as a specific endo or exo diastereomer, it is to be understood that the invention of the present application is not limited to that specific endo or exo diastereomer.
Furthermore, the compounds disclosed in this description and in the claims may exist as cis and trans isomers. Unless stated otherwise, the description of any compound in the description and in the claims is meant to include both the individual cis and the individual trans isomer of a compound, as well as mixtures thereof. As an example, when the structure of a compound is depicted as a cis isomer, it is to be understood that the corresponding trans isomer or mixtures of the cis and trans isomer are not excluded from the invention of the present application. When the structure of a compound is depicted as a specific cis or trans isomer, it is to be understood that the invention of the present application is not limited to that specific cis or trans isomer.
Unsubstituted alkyl groups have the general formula CnH2n+i and may be linear or branched. Optionally, the alkyl groups are substituted by one or more substituents further specified in this document. Examples of alkyl groups include methyl, ethyl, propyl, 2-propyl, t-butyl, 1-hexyl, 1- dodecyl, etc.
A cycloalkyl group is a cyclic alkyl group. Unsubstituted cycloalkyl groups comprise at least three carbon atoms and have the general formula CnH2n-i . Optionally, the cycloalkyl groups are substituted by one or more substituents further specified in this document. Examples of cycloalkyl groups include cyclopropyl, cyclobutyl, cyclopentyl and cyclohexyl.
An alkenyl group comprises one or more carbon-carbon double bonds, and may be linear or branched. Unsubstituted alkenyl groups comprising one C-C double bond have the general formula CnH2n-i . Unsubstituted alkenyl groups comprising two C-C double bonds have the general formula CnH2n-3. An alkenyl group may comprise a terminal carbon-carbon double bond and/or an internal carbon-carbon double bond. A terminal alkenyl group is an alkenyl group wherein a carbon-carbon double bond is located at a terminal position of a carbon chain. An alkenyl group may also comprise two or more carbon-carbon double bonds. Examples of an alkenyl group include ethenyl, propenyl, isopropenyl, t-butenyl, 1 ,3-butadienyl, 1 ,3-pentadienyl, etc. Unless stated otherwise, an alkenyl group may optionally be substituted with one or more, independently selected, substituents as defined below. Unless stated otherwise, an alkenyl group may optionally be interrupted by one or more heteroatoms independently selected from the group consisting of
O, N and S.
An alkynyl group comprises one or more carbon-carbon triple bonds, and may be linear or branched. Unsubstituted alkynyl groups comprising one C-C triple bond have the general formula CnH2n-3. An alkynyl group may comprise a terminal carbon-carbon triple bond and/or an internal carbon-carbon triple bond. A terminal alkynyl group is an alkynyl group wherein a carbon-carbon triple bond is located at a terminal position of a carbon chain. An alkynyl group may also comprise two or more carbon-carbon triple bonds. Unless stated otherwise, an alkynyl group may optionally be substituted with one or more, independently selected, substituents as defined below. Examples of an alkynyl group include ethynyl, propynyl, isopropynyl, t-butynyl, etc. Unless stated otherwise, an alkynyl group may optionally be interrupted by one or more heteroatoms independently selected from the group consisting of O, N and S.
An aryl group comprises six to twelve carbon atoms and may include monocyclic and bicyclic structures. Optionally, the aryl group may be substituted by one or more substituents further specified in this document. Examples of aryl groups are phenyl and naphthyl.
Arylalkyl groups and alkylaryl groups comprise at least seven carbon atoms and may include monocyclic and bicyclic structures. Optionally, the arylalkyl groups and alkylaryl may be substituted by one or more substituents further specified in this document. An arylalkyl group is for example benzyl. An alkylaryl group is for example 4-i-butylphenyl.
Heteroaryl groups comprise at least two carbon atoms (i.e. at least C2) and one or more heteroatoms N, O, P or S. A heteroaryl group may have a monocyclic or a bicyclic structure. Optionally, the heteroaryl group may be substituted by one or more substituents further specified in this document. Examples of suitable heteroaryl groups include pyridinyl, quinolinyl, pyrimidinyl, pyrazinyl, pyrazolyl, imidazolyl, thiazolyl, pyrrolyl, furanyl, triazolyl, benzofuranyl, indolyl, purinyl, benzoxazolyl, thienyl, phospholyl and oxazolyl.
Heteroarylalkyl groups and alkylheteroaryl groups comprise at least three carbon atoms (i.e. at least C3) and may include monocyclic and bicyclic structures. Optionally, the heteroaryl groups may be substituted by one or more substituents further specified in this document.
Where an aryl group is denoted as a (hetero)aryl group, the notation is meant to include an aryl group and a heteroaryl group. Similarly, an alkyl(hetero)aryl group is meant to include an alkylaryl group and a alkylheteroaryl group, and (hetero)arylalkyl is meant to include an arylalkyl group and a heteroarylalkyl group. A C2 - C24 (hetero)aryl group is thus to be interpreted as including a C2 - C24 heteroaryl group and a Ce - C24 aryl group. Similarly, a C3 - C24 alkyl(hetero)aryl group is meant to include a C7 - C24 alkylaryl group and a C3 - C24 alkylheteroaryl group, and a C3 - C24 (hetero)arylalkyl is meant to include a C7 - C24 arylalkyl group and a C3 - C24 heteroarylalkyl group.
A cycloalkynyl group is a cyclic alkynyl group. An unsubstituted cycloalkynyl group comprising one triple bond has the general formula CnH2n-5. Optionally, a cycloalkynyl group is substituted by one or more substituents further specified in this document. An example of a cycloalkynyl group is cyclooctynyl.
A heterocycloalkynyl group is a cycloalkynyl group interrupted by heteroatoms selected from the
group of oxygen, nitrogen and sulphur. Optionally, a heterocycloalkynyl group is substituted by one or more substituents further specified in this document. An example of a heterocycloalkynyl group is azacyclooctynyl.
A (hetero)aryl group comprises an aryl group and a heteroaryl group. An alkyl(hetero)aryl group comprises an alkylaryl group and an alkylheteroaryl group. A (hetero)arylalkyl group comprises a arylalkyl group and a heteroarylalkyl groups. A (hetero)alkynyl group comprises an alkynyl group and a heteroalkynyl group. A (hetero)cycloalkynyl group comprises an cycloalkynyl group and a heterocycloalkynyl group.
A (hetero)cycloalkyne compound is herein defined as a compound comprising a (hetero)cycloalkynyl group.
Several of the compounds disclosed in this description and in the claims may be described as fused (hetero)cycloalkyne compounds, i.e. (hetero)cycloalkyne compounds wherein a second ring structure is fused, i.e. annulated, to the (hetero)cycloalkynyl group. For example in a fused (hetero)cyclooctyne compound, a cydoalkyi (e.g. a cyclopropyl) or an arene (e.g. benzene) may be annulated to the (hetero)cyclooctynyl group. The triple bond of the (hetero)cyclooctynyl group in a fused (hetero)cyclooctyne compound may be located on either one of the three possible locations, i.e. on the 2, 3 or 4 position of the cyclooctyne moiety (numbering according to "lUPAC Nomenclature of Organic Chemistry", Rule A31.2). The description of any fused (hetero)cyclooctyne compound in this description and in the claims is meant to include all three individual regioisomers of the cyclooctyne moiety.
Unless stated otherwise, alkyl groups, cydoalkyi groups, alkenyl groups, alkynyl groups, (hetero)aryl groups, (hetero)arylalkyl groups, alkyl(hetero)aryl groups, alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, (hetero)arylene groups, alkyl(hetero)arylene groups, (hetero)arylalkylene groups, (hetero)arylalkenylene groups, (hetero)arylalkynylene groups, alkenyl groups, alkoxy groups, alkenyloxy groups, (hetero)aryloxy groups, alkynyloxy groups and cycloalkyloxy groups may be substituted with one or more substituents independently selected from the group consisting of Ci - Ci2 alkyl groups, C2 - C12 alkenyl groups, C2 - C12 alkynyl groups, C3 - C12 cydoalkyi groups, C5 - C12 cycloalkenyl groups, Cs - C12 cycloalkynyl groups, Ci - C12 alkoxy groups, C2 - C12 alkenyloxy groups, C2 - C12 alkynyloxy groups, C3 - C12 cycloalkyloxy groups, halogens, amino groups, oxo and silyl groups, wherein the silyl groups can be represented by the formula (R20)3Si-, wherein R20 is independently selected from the group consisting of Ci - C12 alkyl groups, C2 - C12 alkenyl groups, C2 - C12 alkynyl groups, C3 - C12 cydoalkyi groups, Ci - C12 alkoxy groups, C2 - C12 alkenyloxy groups, C2 - C12 alkynyloxy groups and C3 - C12 cycloalkyloxy groups, wherein the alkyl groups, alkenyl groups, alkynyl groups, cydoalkyi groups, alkoxy groups, alkenyloxy groups, alkynyloxy groups and cycloalkyloxy groups are optionally substituted, the alkyl groups, the alkoxy groups, the cydoalkyi groups and the cydoalkoxy groups being optionally interrupted by one of more hetero-atoms selected from the group consisting of O, N and S.
The general term "sugar" is herein used to indicate a monosaccharide, for example glucose (Glc), galactose (Gal), mannose (Man) and fucose (Fuc). The term "sugar derivative" is herein used to
indicate a derivative of a monosaccharide sugar, i.e. a monosaccharide sugar comprising substituents and/or functional groups. Examples of a sugar derivative include amino sugars and sugar acids, e.g. glucosamine (GlcNhb), galactosamine (GalNhb) N-acetylglucosamine (GlcNAc), N-acetylgalactosamine (GalNAc), sialic acid (Sia) which is also referred to as N-acetylneuraminic acid (NeuNAc), and N-acetylmuramic acid (MurNAc), glucuronic acid (GlcA) and iduronic acid (IdoA). Examples of a sugar derivative also include compounds herein denoted as S(F )X, wherein S is a sugar or a sugar derivative, and wherein S comprises x functional groups F .
A core /V-acetylglucosamine substituent (core-GlcNAc substituent) or core /V-acetylglucosamine moiety is herein defined as a GlcNAc that is bonded via C1 to an antibody, preferably via an N- glycosidic bond to the amide nitrogen atom in the side chain of an asparagine amino acid of the antibody. The core-GlcNAc substituent may be present at a native glycosylation site of an antibody, but it may also be introduced on a different site on the antibody. Herein, a core-N- acetylglucosamine substituent is a monosaccharide substituent, or if said core-GlcNAc substituent is fucosylated, a disaccharide core-GlcNAc-(a1-6-Fuc) substituent, further referred to as GlcNAc(Fuc). Herein, a "core-GlcNAc substituent" is not to be confused with a "core-GlcNAc". A core-GlcNAc is herein defined as the inner GlcNAc that is part of a poly- or an oligosaccharide comprising more than two saccharides, i.e. the GlcNAc via which the poly- or oligosaccharide is bonded to an antibody.
An antibody comprising a core-N-acetylglucosamine substituent as defined herein is thus an antibody, comprising a monosaccharide core-GlcNAc substituent as defined above, or if said core-GlcNAc substituent is fucosylated, a disaccharide core-GlcNAc(Fuc) substituent. If a core- GlcNAc substituent or the GlcNAc in a GlcNAc-S(F )x substituent is fucosylated, fucose is most commonly linked a-1 ,6 to 06 of the core-GlcNAc substituent. A fucosylated core-GlcNAc substituent is denoted core-GlcNAc(Fuc), a fucosylated GlcNAc-S(F )x substituent is denoted GlcNAc(Fuc)-S(F )x.
The term "nucleotide" is herein used in its normal scientific meaning. The term "nucleotide" refers to a molecule that is composed of a nucleobase, a five-carbon sugar (either ribose or 2- deoxyribose), and one, two or three phosphate groups. Without the phosphate group, the nucleobase and sugar compose a nucleoside. A nucleotide can thus also be called a nucleoside monophosphate, a nucleoside diphosphate or a nucleoside triphosphate. The nucleobase may be adenine, guanine, cytosine, uracil or thymine. Examples of a nucleotide include uridine diphosphate (UDP), guanosine diphosphate (GDP), thymidine diphosphate (TDP), cytidine diphosphate (CDP) and cytidine monophosphate (CMP).
The term "protein" is herein used in its normal scientific meaning. Herein, polypeptides comprising about 10 or more amino acids are considered proteins. A protein may comprise natural, but also unnatural amino acids.
The term "glycoprotein" is herein used in its normal scientific meaning and refers to a protein comprising one or more monosaccharide or oligosaccharide chains ("glycans") covalently bonded to the protein. A glycan may be attached to a hydroxyl group on the protein (O-linked-glycan), e.g. to the hydroxyl group of serine, threonine, tyrosine, hydroxylysine or hydroxyproline, or to an
amide function on the protein (A/-glycoprotein), e.g. asparagine or arginine, or to a carbon on the protein (C-glycoprotein), e.g. tryptophan. A glycoprotein may comprise more than one glycan, may comprise a combination of one or more monosaccharide and one or more oligosaccharide glycans, and may comprise a combination of N-linked, O-linked and C-linked glycans. It is estimated that more than 50% of all proteins have some form of glycosylation and therefore qualify as glycoprotein. Examples of glycoproteins include PSMA (prostate-specific membrane antigen), CAL (Candida antartica lipase), gp41 , gp120, EPO (erythropoietin), antifreeze protein and antibodies.
The term "glycan" is herein used in its normal scientific meaning and refers to a monosaccharide or oligosaccharide chain that is linked to a protein. The term glycan thus refers to the carbohydrate-part of a glycoprotein. The glycan is attached to a protein via the C-1 carbon of one sugar, which may be without further substitution (monosaccharide) or may be further substituted at one or more of its hydroxyl groups (oligosaccharide). A naturally occurring glycan typically comprises 1 to about 10 saccharide moieties. However, when a longer saccharide chain is linked to a protein, said saccharide chain is herein also considered a glycan. A glycan of a glycoprotein may be a monosaccharide. Typically, a monosaccharide glycan of a glycoprotein consists of a single N-acetylglucosamine (GlcNAc), glucose (Glc), mannose (Man) or fucose (Fuc) covalently attached to the protein. A glycan may also be an oligosaccharide. An oligosaccharide chain of a glycoprotein may be linear or branched. In an oligosaccharide, the sugar that is directly attached to the protein is called the core sugar. In an oligosaccharide, a sugar that is not directly attached to the protein and is attached to at least two other sugars is called an internal sugar. In an oligosaccharide, a sugar that is not directly attached to the protein but to a single other sugar, i.e. carrying no further sugar substituents at one or more of its other hydroxyl groups, is called the terminal sugar. For the avoidance of doubt, there may exist multiple terminal sugars in an oligosaccharide of a glycoprotein, but only one core sugar. A glycan may be an O-linked glycan, an N-linked glycan or a C-linked glycan. In an O-linked glycan a monosaccharide or oligosaccharide glycan is bonded to an O-atom in an amino acid of the protein, typically via a hydroxyl group of serine (Ser) or threonine (Thr). In an N-linked glycan a monosaccharide or oligosaccharide glycan is bonded to the protein via an N-atom in an amino acid of the protein, typically via an amide nitrogen in the side chain of asparagine (Asn) or arginine (Arg). In a delinked glycan a monosaccharide or oligosaccharide glycan is bonded to a C-atom in an amino acid of the protein, typically to a C-atom of tryptophan (Trp).
The term "antibody" is herein used in its normal scientific meaning. An antibody is a protein generated by the immune system that is capable of recognizing and binding to a specific antigen. An antibody is an example of a glycoprotein. The term antibody herein is used in its broadest sense and specifically includes monoclonal antibodies, polyclonal antibodies, dimers, multimers, multispecific antibodies (e.g. bispecific antibodies), antibody fragments, and double and single chain antibodies. The term "antibody" is herein also meant to include human antibodies, humanized antibodies, chimeric antibodies and antibodies specifically binding cancer antigen. The term "antibody" is meant to include whole antibodies, but also antigen-binding fragments of an
antibody, for example an antibody Fab fragment, F(ab')2, Fv fragment or Fc fragment from a cleaved antibody, a scFv-Fc fragment, a minibody, a diabody, a bispecific antibody or a scFv. Furthermore, the term includes genetically engineered antibodies and derivatives of an antibody. Antibodies, fragments of antibodies and genetically engineered antibodies may be obtained by methods that are known in the art. Typical examples of antibodies include, amongst others, abciximab, rituximab, basiliximab, palivizumab, infliximab, trastuzumab, alemtuzumab, adalimumab, tositumomab-1131 , cetuximab, ibrituximab tiuxetan, omalizumab, bevacizumab, natalizumab, ranibizumab, panitumumab, eculizumab, certolizumab pegol, golimumab, canakinumab, catumaxomab, ustekinumab, tocilizumab, ofatumumab, denosumab, belimumab, ipilimumab and brentuximab. In a preferred embodiment, the glycoprotein comprising a core-N- acetylglucosamine substituent (core-GlcNAc substituent) is an antibody comprising a core-N- acetylglucosamine substituent (core-GlcNAc substituent), preferably a monoclonal antibody (mAb). Preferably, said antibody is selected from the group consisting of IgA, IgD, IgE, IgG and IgM antibodies. More preferably, said antibody is an IgG antibody, and most preferably said antibody is an lgG1 antibody. When said antibody is a whole antibody, the antibody preferably comprises one or more, more preferably one, core-GlcNAc substituent on each heavy chain, said core-GlcNAc substituent being optionally fucosylated. Said whole antibody thus preferably comprises two or more, preferably two, optionally fucosylated, core-GlcNAc substituents. When said antibody is a single chain antibody or an antibody fragment, e.g. a Fab fragment, the antibody preferably comprises one or more core-GlcNAc substituents, which are optionally fucosylated. In the antibody comprising a core-GlcNAc substituent, said core-GlcNAc substituent may be situated anywhere on the antibody, provided that said substituent does not hinder the antigen-binding site of the antibody. In a preferred embodiment, said core N-acetylglucosamine substituent is present at a native N-glycosylation site of the antibody.
A linker is herein defined as a moiety that connects two or more elements of a compound. For example in a bioconjugate, a biomolecule and a target molecule are covalently connected to each other via a linker; in the linker-conjugate a reactive group Q is covalently connected to a target molecule via a linker; in a linker-construct a reactive group Q is covalently connected to a reactive group Q2 via a linker. A linker may comprise one or more spacer-moieties.
A spacer-moiety is herein defined as a moiety that spaces (i.e. provides distance between) and covalently links together two (or more) parts of a linker. The linker may be part of e.g. a linker- construct, the linker-conjugate or a bioconjugate, as defined below.
A bioconjugate is herein defined as a compound wherein a biomolecule is covalently connected to a target molecule via a linker. A bioconjugate comprises one or more biomolecules and/or one or more target molecules. The linker may comprise one or more spacer moieties. An antibody- conjugate refers to a bioconjugate wherein the biomolecule is an antibody.
A biomolecule is herein defined as any molecule that can be isolated from nature or any molecule composed of smaller molecular building blocks that are the constituents of macromolecular structures derived from nature, in particular nucleic acids, proteins, glycans and lipids. Herein, the biomolecule may also be referred to as biomolecule of interest (BOI). Examples of a biomolecule
include an enzyme, a (non-catalytic) protein, a polypeptide, a peptide, an amino acid, an oligonucleotide, a monosaccharide, an oligosaccharide, a polysaccharide, a glycan, a lipid and a hormone.
A target molecule, also referred to as a molecule of interest (MOI), is herein defined as molecular structure possessing a desired property that is imparted onto the biomolecule upon conjugation. The term "salt thereof means a compound formed when an acidic proton, typically a proton of an acid, is replaced by a cation, such as a metal cation or an organic cation and the like. Where applicable, the salt is a pharmaceutically acceptable salt, although this is not required for salts that are not intended for administration to a patient. For example, in a salt of a compound the compound may be protonated by an inorganic or organic acid to form a cation, with the conjugate base of the inorganic or organic acid as the anionic component of the salt.
The term "pharmaceutically accepted" salt means a salt that is acceptable for administration to a patient, such as a mammal (salts with counterions having acceptable mammalian safety for a given dosage regime). Such salts may be derived from pharmaceutically acceptable inorganic or organic bases and from pharmaceutically acceptable inorganic or organic acids. "Pharmaceutically acceptable salt" refers to pharmaceutically acceptable salts of a compound, which salts are derived from a variety of organic and inorganic counter ions known in the art and include, for example, sodium, potassium, calcium, magnesium, ammonium, tetraalkylammonium, etc., and when the molecule contains a basic functionality, salts of organic or inorganic acids, such as hydrochloride, hydrobromide, formate, tartrate, besylate, mesylate, acetate, maleate, oxalate, etc.
Herein, a sulfamide linker and conjugates of said sulfamide linker are disclosed. The term "sulfamide linker" refers to a linker comprising a sulfamide group, more particularly an acylsulfamide group [-C(0)-N(H)-S(0)2-N(R1)-] and/or a carbamoyl sulfamide group [-O-C(O)- N(H)-S(0)2-N(R1)-].
Herein, the term "therapeutic index" (Tl) has the conventional meaning well known to a person skilled in the art, and refers to the ratio of the dose of drug that is toxic (i.e. causes adverse effects at an incidence or severity not compatible with the targeted indication) for 50% of the population (TD50) divided by the dose that leads to the desired pharmacological effect in 50% of the population (effective dose or ED50). Hence, Tl = TD50 / ED50. The therapeutic index may be determined by clinical trials or for example by plasma exposure tests. See also Muller, et al. Nature Reviews Drug Discovery 2012, 1 1 , 751-761 . At an early development stage, the clinical Tl of a drug candidate is often not yet known. However, understanding the preliminary Tl of a drug candidate is of utmost importance as early as possible, since Tl is an important indicator of the probability of the successful development of a drug. Recognizing drug candidates with potentially suboptimal Tl at earliest possible stage helps to initiate mitigation or potentially re-deploy resources. At this early stage, Tl is typically defined as the quantitative ratio between efficacy (minimal effective dose in a mouse xenograft) and safety (maximum tolerated dose in mouse or rat).
Herein, the term "therapeutic efficacy" denotes the capacity of a substance to achieve a certain
therapeutic effect, e.g. reduction in tumour volume. Therapeutic effects can be measured determining the extent in which a substance can achieve the desired effect, typically in comparison with another substance under the same circumstances. A suitable measure for the therapeutic efficacy is the ED50 value, which may for example be determined during clinical trials or by plasma exposure tests. In case of preclinical therapeutic efficacy determination, the therapeutic effect of a bioconjugate (e.g. an ADC), can be validated by patient-derived tumour xenografts in mice in which case the efficacy refers to the ability of the ADC to provide a beneficial effect. Alternatively the tolerability of said ADC in a rodent safety study can also be a measure of the therapeutic effect.
Herein, the term "tolerability" refers to the maximum dose of a specific substance that does not cause adverse effects at an incidence or severity not compatible with the targeted indication. A suitable measure for the tolerability for a specific substance is the TD50 value, which may for example be determined during clinical trials or by plasma exposure tests. Mode of conjugation
In the context of the present invention, the "mode of conjugation" refers to the process that is used to conjugate a target molecule D to a biomolecule B, in particular an antibody AB, as well as to the structural features of the resulting bioconjugate, in particular of the linker that connects the target molecule to the biomolecule, that are a direct consequence of the process of conjugation. Thus, in one embodiment, the mode of conjugation refers to a process for conjugation a target molecule to a biomolecule, in particular an antibody. In an alternative embodiment, the mode of conjugation refers to structural features of the linker and/or to the attachment point of the linker to the biomolecule that are a direct consequence of the process for conjugation a target molecule to a biomolecule, in particular an antibody.
In the context of the present invention, the mode of conjugation comprises at least one of "core- GlcNAc functionalization" and "sulfamide linkage" as defined further below. Preferably, the mode of conjugation comprises both the "core-GlcNAc functionalization" and "sulfamide linkage" as defined further below.
Core-GlcNAc functionalization
In one embodiment, the mode of conjugation according to the invention is referred to as "core- GlcNAc functionalization", which refers to a process comprising:
(i) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q , x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified antibody according to Formula (24):
(Fuc)b
AB- GlcNAc- -S(F1)X
(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
reacting the modified antibody with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F .
In the present embodiment, the antibody is conjugated via a glycan that is trimmed to a core- GlcNAc residue (optionally substituted with a fucose). This residue is functionalized with a sugar derivative S(F )X, comprising 1 or 2 functional groups F , which are subsequently reacted with a functional group Q present on a linker-conjugate comprising target molecule D. The structural feature of the resulting linker L that links the antibody with the target molecule, that are a direct consequence of the conjugation process include:
(a) The point of attachment of the linker L to the antibody AB is at a specific amino acid residue which is glycosylated in the naturally occurring antibody or is an artificially introduced glycosylation site, by mutation of specific amino acid residues in the antibody. As such, the point of attachment of the linker to the antibody can be specifically selected, which affords a highly predictable target molecule to antibody ratio (or DAR: "drug antibody ratio").
(b) The linker L is conjugated to a core-GlcNAc moiety of the antibody, and has the general structure -S-(M)PP-Z3-L2(D)r. Herein, S is the sugar derivative which is typically connected via 04 to the core-GlcNAc moiety and via any one of C2, C3, C4 and C6, preferably via C6, to Z3, optionally via spacer M (i.e. pp = 0 or 1 ). Z3 is a connecting group that is obtained by the reaction between Q and F . Options for Q , F and Z3 are known to the skilled person and discussed in further detail below. Z3 is connected via linker L2 to at least one target molecule D (i.e. r > 1 ).
(c) In a preferred embodiment, linker L, in particular linker L2, comprises the group according to formula (1 ) or a salt thereof as defined for mode of conjugation referred to "sulfamide linkage". It has been found that when the mode of conjugation according to the present embodiment is combined with the "sulfamide linkage" mode of conjugation, the best results were obtained in terms of improving the therapeutic index of the resulting bioconjugates.
The inventors surprisingly found that using the above process for conjugating the target molecule to the antibody has a beneficial effect on the therapeutic index of the antibody-conjugate. In other words, the therapeutic index of antibody-conjugates having the mode of conjugation according to the present embodiment have an improved therapeutic index over antibody-conjugates not having the mode of conjugation according to the present embodiment.
The use of the mode of conjugation according to the present invention is distinct from a process of preparing an antibody-conjugate, wherein the mode of conjugation is used to prepare the antibody-conjugate. Although many modes of conjugation to prepare antibody-conjugates exists, the inventors have found that selecting a specific mode of conjugation, while keeping the antibody and the target molecule(s) constant, beneficially affects the therapeutic index of the conjugates.
Within the context of the present mode of conjugation referred to as "core-GlcNAc functionalization", in one embodiment the mode of conjugation comprises the step of preparing the bioconjugate of formula (A):
B-L-D
(A),
wherein:
- B is a biomolecule;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety,
by reacting a reactive group Q on a target molecule (D) with a functional group F on a biomolecule (B), such that L compri (1 ) or a salt thereof:

1
wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S or NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
Step (i)
In step (i), a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties is contacted with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar
derivative comprising x functional groups F capable of reacting with a functional group Q\ x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety. Herein, the glycoprotein is typically an antibody, such as an antibody that has been trimmed to a core-GlcNAc residue as described further below.
Step (i) affords a modified antibody according to Formula (24):
(Fuc)b
AB- GlcNAc- -S(F1)X
(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4.
In a preferred embodiment, y = 1 , 2 or 4, more preferably y = 1 or 2 (e.g. when AB is a single chain antibody), or alternatively y = 2 or 4 (e.g. when AB is a double chain antibody). Most preferably y = 2. In one embodiment, the antibody comprising a core-GlcNAc substituent, wherein said core- GlcNAc substituent is optionally fucosylated, is of the Formula (21 ), wherein AB represents an antibody, GlcNAc is /V-acetylglucosamine, Fuc is fucose, b is 0 or 1 and y is 1 to 4, preferably y is 1 or 2.

AEH— GlcNAc (21 )
Such antibody comprising a core-GlcNAc substituent are known in the art and can be prepared by methods known by the skilled person. In one embodiment, the process according to the invention further comprises the deglycosylation of an antibody glycan having a core N-acetylglucosamine, in the presence of an endoglycosidase, in order to obtain an antibody comprising a core N- acetylglucosamine substituent, wherein said core N-acetylglucosamine and said core N- acetylglucosamine substituent are optionally fucosylated. Depending on the nature of the glycan, a suitable endoglycosidase may be selected. The endoglycosidase is preferably selected from the group consisting of EndoS, EndoA, EndoE, EfEndo18A, EndoF, EndoM, EndoD, EndoH, EndoT and EndoSH and/or a combination thereof, preferably of EndoS, EndoA, EndoF, EndoM, EndoD, EndoH and EndoSH enzymes and/or a combination thereof, the selection of which depends on the nature of the glycan. EndoSH is further defined below in the fourth aspect of the present invention. In a further preferred embodiment, the endoglycosidase is EndoS, EndoS49, EndoF, EndoH, EndoSH or a combination thereof, more preferably EndoS, EndoS49, EndoF, EndoSH or a combination thereof. In a further preferred embodiment, the endoglycosidase is EndoS, EndoF
or a combination thereof. In a further preferred embodiment, the endoglycosidase is EndoS. In another preferred embodiment the endoglycosidase is EndoS49. In another preferred embodiment the endoglycosidase is EndoSH. Herien, EndoF typically refers to one of EndoFI , EndoF2 and EndoF3.
In step (i), modification of antibody (21a), wherein y = 1 , leads to a modified antibody comprising one GlcNAc-S(F )x substituent (22) and modification of antibody (21 b), wherein y = 2, leads to a modified antibody comprising two GlcNAc-S(F )x substituents (23). In one embodiment, preferably when AB is a double chain antibody, y = 2 or 4. In one embodiment, preferably when AB is a single chain antibody, y = 1 or 2.
AB
 catalyst
catalyst
(21a) (22)
(Fuc)b (Fuc)b (Fuc)b (Fuc)b
S(P)X-P
GlcNAc AB— GlcNAc catalyst S(F GlcNAc AB— GlcNAc S(F
(21 b) (23) In a preferred embodiment, the antibody AB is capable of targeting tumours that express an antigen selected from 5T4 (TPBG), av-integrin/ITGAV, BCMA, C4.4a, CA-IX, CD19, CD19b, CD22, CD25, CD30, CD33, CD37, CD40, CD56, CD70, CD74, CD79b, c-KIT (CD1 19), CD138/SDC1 , CEACAM5 (CD66e), Cripto, CS1 , DLL3, EFNA4, EGFR, EGFRvlll, Endothelin B Receptor (ETBR), ENPP3 (AGS-16), EpCAM, EphA2, FGFR2, FGFR3, FOLR1 (folate receptor a), gpNMB, guanyl cyclase C (GCC), HER2, Erb-B2, Lamp-1 , Lewis Y antigen, LIV-1 (SLC39A6, ZIP6), Mesothelin (MSLN), MUC1 (CA6, huDS6), MUC16/EA-125, NaPi2b, Nectin-4, Notch3, P- cadherin, PSMA/FOLH1 , PTK7, SLITRK6 (SLC44A4), STEAP1 , TF (CD142) , Trop-1 , Trop- 2/EGP-1 , Trop-3 , Trop-4, preferably HER2-expressing tumours.
In a preferred embodiment, the antibody AB is capable of targeting HER2-expressing tumours, including but not limited to low HER2-expressing tumours, more preferably the antibody AB is selected from the group consisting of from trastuzumab, margetuximab, pertuzumab, HuMax- Her2, ertumaxomab, HB-008, ABP-980, BCD-022, CanMab, Herzuma, HD201 , CT-P6, PF- 05280014, COVA-208, FS-102, MCLA-128, CKD-10101 , HT-19 and functional analogues thereof, most preferably trastuzumab.
S(F )x is defined as a sugar derivative comprising x functional groups F , wherein x is 1 or 2 and F is a functional group capable of reacting with Q present on the linker-conjugate to form a connecting moiety Z3. The sugar derivative S(F )X may comprise 1 or 2 functional groups F . When S(F )x comprises 2 functional groups F , each functional group F is independently selected, i.e. one S(F )X may comprise different functional groups F . In one embodiment, x = 1. In
one embodiment, x = 2. Sugar derivative S(F )X is derived from a sugar or a sugar derivative S, e.g. an amino sugar or an otherwise derivatized sugar. Examples of sugars and sugar derivatives include galactose (Gal), mannose (Man), glucose (Glc), glucuronic acid (GlucA) and fucose (Fuc). An amino sugar is a sugar wherein a hydroxyl (OH) group is replaced by an amino group and examples include N-acetylglucosamine (GlcNAc) and N-acetylgalactosamine (GalNAc). Examples of an otherwise derivatized sugar include glucuronic acid (GlucA) and N-acetylneuraminic acid (sialic acid). Sugar derivative S(F )X is preferably derived from galactose (Gal), mannose (Man), N-acetylglucosamine (GlcNAc), glucose (Glc), N-acetylgalactosamine (GalNAc), glucuronic acid (GlucA), fucose (Fuc) and N-acetylneuraminic acid (sialic acid), preferably from the group consisting of GlcNAc, Glc, Gal and GalNAc. More preferably S(F )X is derived from Gal or GalNAc, and most preferably S(F )X is derived from GalNAc.
Compounds of the formula S(F ))cP, wherein a nucleoside monophosphate or a nucleoside diphosphate P is linked to a sugar derivative S(F )X, are known in the art. For example Wang ef a/. , Chem. Eur. J. 2010, 76, 13343-13345, Filler et ai , ACS Chem. Biol. 2012, 7, 753, Piller ei a/., Bioorg. Med. Chem. Lett. 2005, 15, 5459-5462 and WO 2009/102820, all incorporated by reference herein, disclose a number of compounds S(F ))cP and their syntheses. In a preferred embodiment nucleoside mono- or diphosphate P in S(F ))cP is selected from the group consisting of uridine diphosphate (UDP), guanosine diphosphate (GDP), thymidine diphosphate (TDP), cytidine diphosphate (CDP) and cytidine monophosphate (CMP), more preferably P is selected from the group consisting of uridine diphosphate (UDP), guanosine diphosphate (GDP) and cytidine diphosphate (CDP), most preferably P = UDP.
The 1 or 2 functional groups F in S(F )X may be linked to the sugar or sugar derivative S in several ways. The 1 or 2 functional groups F may be bonded to C2, C3, C4 and/or C6 of the sugar or sugar derivative, instead of a hydroxyl (OH) group. It should be noted that, since fucose lacks an OH-group on C6, if F is bonded to C6 of Fuc, then F takes the place of an H-atom. When F is an azido group, it is preferred that F is bonded to C2, C4 or C6. As was described above, the one or more azide substituent in S(F )X may be bonded to C2, C3, C4 or C6 of the sugar or sugar derivative S, instead of a hydroxyl (OH) group or, in case of 6-azidofucose (6- AzFuc), instead of a hydrogen atom. Alternatively or additionally, the N-acetyl substituent of an amino sugar derivative may be substituted by an azidoacetyl substituent. In a preferred embodiment S(F )X is selected from the group consisting of 2-azidoacetamido-2-deoxy-galactose (GalNAz), 2-azidodifluoroacetamido-2-deoxy-galactose (F2-GalNAz), 6-azido-6-deoxygalactose (6-AzGal), 6-azido-6-deoxy-2-acetamidogalactose (6-AzGalNAc or 6-N3-GalNAc), 4-azido-4- deoxy-2-acetamidogalactose (4-AzGalNAc), 6-azido-6-deoxy-2-azidoacetamido-2-deoxygalactose (6-AzGalNAz), 2-azidoacetamido-2-deoxyglucose (GlcNAz), 6-azido-6-deoxyglucose (6-AzGlc), 6-azido-6-deoxy-2-acetamidoglucose (6-AzGlcNAc), 4-azido-4-deoxy-2-acetamidoglucose (4- AzGlcNAc) and 6-azido-6-deoxy-2-azidoacetamido-2-deoxyglucose (6-AzGlcNAz), more preferably from the group consisting of GalNAz, 4-AzGalNAc and 6-AzGalNAc. Examples of S(F ))cP wherein F is an azido group are shown below. When F is a keto group, it is preferred that F is bonded to C2 instead of the OH-group of S. Alternatively F may be bonded to the N-
atom of an amino sugar derivative, preferably a 2-amino sugar derivative. The sugar derivative then comprises an -NC(0)R36 substituent. R36 is preferably a C2 - C24 alkyl group, optionally sustituted. More preferably, R36 is an ethyl group. In a preferred embodiment S(F )X is selected from the group consisting of 2-deoxy-(2-oxopropyl)galactose (2-ketoGal), 2-N- propionylgalactosamine (2-N-propionylGalNAc), 2-N-(4-oxopentanoyl)galactosamine (2-N- LevGal) and 2-N-butyrylgalactosamine (2-N-butyrylGalNAc), more preferably 2-ketoGalNAc and 2-N-propionylGalNAc. Examples of S(F )x-P wherein F is a keto group are shown below. When F is an alkynyl group, preferably a terminal alkynyl group or a (hetero)cycloalkynyl group, it is preferred that said alkynyl group is present on a 2-amino sugar derivative. An example of S(F )X wherein F is an alkynyl group is 2-(but-3-yonic acid amido)-2-deoxy-galactose. An example of S(F )x-P wherein F is an alkynyl group is shown below.
In one embodiment, F is selected from the group consisting of an azido group, a keto group and an alkynyl group. An azido group is an azide functional group -N3. A keto group is a -[C(R37)2]oC(0)R36 group, wherein R36 is a methyl group or an optionally substituted C2 - C24 alkyl group, R37 is independently selected from the group consisting of hydrogen, halogen and R36, and o is 0 - 24, preferably 0 - 10, and more preferably 0, 1 , 2, 3, 4, 5 or 6. Preferably, R37 is hydrogen. An alkynyl group is preferably a terminal alkynyl group or a (hetero)cycloalkynyl group as defined above. In one embodiment the alkynyl group is a -[C(R37)2]oC≡C-R37 group, wherein R37 and o are as defined above; R37 is preferably hydrogen.
In one embodiment, F is an azide or an alkyne moiety. Most preferably, F is an azido group (-N3). In one embodiment, F is an azide moiety, Q is an (cyclo)alkyne moiety, and Z3 is a triazole moiety.
Several examples (25 - 28) of uridine diphosphates linked to azido- or alkynyl-substituted sugars and sugar derivatives, S(F )x-UDP, are shown below.


Suitable catalyst that are capable of transferring the S(F )X moiety to the core-GlcNAc moiety are known in the art. A suitable catalyst is a catalyst wherefore the specific sugar derivative nucleotide S(F )x-P in that specific process is a substrate. More specifically, the catalyst catalyzes the formation of a p(1 ,4)-glycosidic bond. Preferably, the catalyst is selected from the group of galactosyltransferases and N-acetylgalactosaminyltransferases, more preferably from the group of j8(1 ,4)-N-acetylgalactosaminyltransferases (GalNAcT) and j8(1 ,4)-galactosyltransferases (GalT), most preferably from the group of j8(1 ,4)-N-acetylgalactosaminyltransferases having a mutant catalytic domain. Suitable catalysts and mutants thereof are disclosed in WO 2014/065661 , WO 2016/022027 and PCT/EP2016/059194 (WO 2016/170186), all incorporated herein by reference. In one embodiment, the catalyst is a wild-type galactosyltransferase or N-acetylgalactosaminyl- transferase, preferably a N-acetylgalactosaminyltransferase. In an alternative embodiment, the catalyst is a mutant galactosyltransferase or N-acetylgalactosaminyltransferases, preferably a mutant N-acetylgalactosaminyltransferase. Mutant enzymes described in WO 2016/022027 and PCT/EP2016/059194 (WO 2016/170186) are especially preferred.
These galactosyltransferase (mutant) enzyme catalysts are able to recognize internal sugars and sugar derivatives as an acceptor. Thus, sugar derivative S(F )X is linked to the core-GlcNAc substituent in step (i), irrespective of whether said GlcNAc is fucosylated or not.
Step (i) is preferably performed in a suitable buffer solution, such as for example phosphate, buffered saline (e.g. phosphate-buffered saline, tris-buffered saline), citrate, HEPES, tris and glycine. Suitable buffers are known in the art. Preferably, the buffer solution is phosphate-buffered saline (PBS) or tris buffer. Step (i) is preferably performed at a temperature in the range of about 4 to about 50 °C, more preferably in the range of about 10 to about 45 °C, even more preferably in the range of about 20 to about 40 °C, and most preferably in the range of about 30 to about 37 °C. Step (i) is preferably performed a pH in the range of about 5 to about 9, preferably in the range of about 5.5 to about 8.5, more preferably in the range of about 6 to about 8. Most preferably, step (i) is performed at a pH in the range of about 7 to about 8.
Step (ii)
In step (ii), the modified antibody is reacted with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F . Such reaction occurs under condition such that reactive group Q is reacted with the functional group F of the biomolecule to covalently link the biomolecule to the linker-conjugate. Linker-conjugates and preferred
embodiments thereof are defined further below. The linker L2 preferably comprises the group according to formula (1 ) or a salt thereof, and said linker is further defined below.
Complementary functional groups Q for the functional group F on the modified antibody are known in the art. Preferably, reactive group Q and functional group F are capable of reacting in a bioorthogonal reaction, as those reactions do not interfere with the biomolecules present during this reaction. Bioorthogonal reactions and functional groups suitable therein are known to the skilled person, for example from Gong and Pan, Tetrahedron Lett. 2015, 56, 2123-2132, and include Staudinger ligations and copper-free Click chemistry. It is thus preferred that Q is selected from the group consisting of 1 ,3-dipoles, alkynes, (hetero)cyclooctynes, cyclooctenes, tetrazines, ketones, aldehydes, alkoxyamines, hydrazines and triphenylphosphine. For example, when F is an azido group, linking of the azide-modified antibody and the linker-conjugate preferably takes place via a cycloaddition reaction. Functional group Q is then preferably selected from the group consisting of alkynyl groups, preferably terminal alkynyl groups, and (hetero)cycloalkynyl groups. For example, when F is a keto group, linking of the keto-modified antibody with the linker-conjugate preferably takes place via selective conjugation with hydroxylamine derivatives or hydrazines, resulting in respectively oximes or hydrazones. Functional group Q is then preferably a primary amino group, e.g. an -NH2 group, an aminooxy group, e.g. -O-NH2, or a hydrazinyl group, e.g. -N(H)NH2. The linker-conjugate is then preferably H2N-L2(D , H2N-0-L2(D or H2N-N(H)-L2(D respectively. For example, when F is an alkynyl group, linking of the alkyne-modified antibody with the linker-conjugate preferably takes place via a cycloaddition reaction, preferably a 1 ,3-dipolar cycloaddition. Functional group Q is then preferably a 1 ,3-dipole, such as an azide, a nitrone or a nitrile oxide. The linker-conjugate is then preferably N3-L2(D)r. In a preferred embodiment, in step (ii) an azide on the azide-modified antibody according to the invention reacts with an alkynyl group, preferably a terminal alkynyl group, or a (heter)cycloalkynyl group of the linker-conjugate via a cycloaddition reaction. This cycloaddition reaction of a molecule comprising an azide with a molecule comprising a terminal alkynyl group or a (hetero)cycloalkynyl group is one of the reactions that is known in the art as "click chemistry". In the case of a linker-conjugate comprising a terminal alkynyl group, said cycloaddition reaction needs to be performed in the presence of a suitable catalyst, preferably a Cu(l) catalyst. However, in a preferred embodiment, the linker-conjugate comprises a (hetero)cycloalkynyl group, more preferably a strained (hetero)cycloalkynyl group. When the (hetero)cycloalkynyl is a strained (hetero)cycloalkynyl group, the presence of a catalyst is not required, and said reaction may even occur spontaneously by a reaction called strain-promoted azide-alkyne cycloaddition (SPAAC). This is one of the reactions known in the art as "metal-free click chemistry". Strained (hetero)cycloalkynyl groups are known in the art and are described in more detail below.
Therefore, in a preferred embodiment, step (ii) comprises reacting a modified antibody with a linker-conjugate, wherein said linker-conjugate comprises a (hetero)cycloalkynyl group and one or more molecules of interest, wherein said modified antibody is an antibody comprising a GlcNAc-
S(F )x substituent, wherein GlcNAc is an N-acetylglucosamine, wherein S(F )X is a sugar derivative comprising x functional groups F wherein F is an azido group and x is 1 or 2, wherein said GlcNAc-S(F )x substituent is bonded to the antibody via C1 of the N-acetylglucosamine of said GlcNAc-S(F )x substituent, and wherein said GlcNAc is optionally fucosylated. In a further preferred embodiment, said (hetero)cycloalkynyl group is a strained (hetero)cycloalkynyl group.
Target molecule D may be selected from the group consisting of an active substance, a reporter molecule, a polymer, a solid surface, a hydrogel, a nanoparticle, a microparticle and a biomolecule.
In the context of D, the term "active substance" relates to a pharmacological and/or biological substance, i.e. a substance that is biologically and/or pharmaceutically active, for example a drug, a prodrug, a diagnostic agent, a protein, a peptide, a polypeptide, a peptide tag, an amino acid, a glycan, a lipid, a vitamin, a steroid, a nucleotide, a nucleoside, a polynucleotide, RNA or DNA. Examples of peptide tags include cell-penetrating peptides like human lactoferrin or polyarginine. An example of a glycan is oligomannose. An example of an amino acid is lysine.
When the target molecule is an active substance, the active substance is preferably selected from the group consisting of drugs and prodrugs. More preferably, the active substance is selected from the group consisting of pharmaceutically active compounds, in particular low to medium molecular weight compounds (e.g. about 200 to about 2500 Da, preferably about 300 to about 1750 Da). In a further preferred embodiment, the active substance is selected from the group consisting of cytotoxins, antiviral agents, antibacterials agents, peptides and oligonucleotides. Examples of cytotoxins include colchicine, vinca alkaloids, anthracyclines, camptothecins, doxorubicin, daunorubicin, taxanes, calicheamycins, tubulysins, irinotecans, enediynes, an inhibitory peptide, amanitin, deBouganin, duocarmycins, maytansines, auristatins, indolinobenzodiazepines or pyrrolobenzodiazepines (PBDs). In view of their poor water solubility, preferred active substances include vinca alkaloids, anthracyclines, camptothecins, taxanes, tubulysins, amanitin, duocarmycins, maytansines, auristatins, indolinobenzodiazepines and pyrrolobenzodiazepines, in particular vinca alkaloids, anthracyclines, camptothecins, taxanes, tubulysins, amanitin, maytansines and auristatins.
The term "reporter molecule" herein refers to a molecule whose presence is readily detected, for example a diagnostic agent, a dye, a fluorophore, a radioactive isotope label, a contrast agent, a magnetic resonance imaging agent or a mass label.
A wide variety of fluorophores, also referred to as fluorescent probes, is known to a person skilled in the art. Several fluorophores are described in more detail in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013, Chapter 10: "Fluorescent probes", p. 395 - 463, incorporated by reference. Examples of a fluorophore include all kinds of Alexa Fluor (e.g. Alexa Fluor 555), cyanine dyes (e.g. Cy3 or Cy5) and cyanine dye derivatives, coumarin derivatives, fluorescein and fluorescein derivatives, rhodamine and rhodamine derivatives, boron dipyrromethene derivatives, pyrene derivatives, naphthalimide derivatives, phycobiliprotein derivatives (e.g. allophycocyanin), chromomycin, lanthanide chelates and quantum dot
nanocrystals. In view of their poor water solubility, preferred fluorophores include cyanine dyes, coumarin derivatives, fluorescein and derivatives thereof, pyrene derivatives, naphthalimide derivatives, chromomycin, lanthanide chelates and quantum dot nanocrystals, in particular coumarin derivatives, fluorescein, pyrene derivatives and chromomycin.
Examples of a radioactive isotope label include 99mTc, Ίη, 4mln, 5ln, 8F, 4C, 64Cu, 3Ί, 25l, 23l, 2 2Bi, 88Y, 90Y, 67Cu, 86Rh, 88Rh, 66Ga, 67Ga and 0B, which is optionally connected via a chelating moiety such as e.g. DTPA (diethylenetriaminepentaacetic anhydride), DOTA (1 ,4,7, 10- tetraazacyclododecane-/V,/V',/V" /V'"-tetraacetic acid), NOTA (1 ,4,7-triazacyclononane Ν,Ν',Ν"- triacetic acid), TETA (1 ,4,8, 1 1-tetraazacyclotetradecane-A/,A/',A/" A/"-tetraacetic acid), DTTA (N1- (p-isothiocyanatobenzy -diethylenetriamine-A/^A/2, A/3,A/3-tetraacetic acid), deferoxamine or DFA (A/'-[5-[[4-[[5-(acetylhydroxyamino)pentyl]amino]-1 ,4-dioxobutyl]hydroxyamino]pentyl]-A/-(5-amino- pentyl)-A/-hydroxybutanediamide) or HYNIC (hydrazinonicotinamide). Isotopic labelling techniques are known to a person skilled in the art, and are described in more detail in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013, Chapter 12: "Isotopic labelling techniques", p. 507 - 534, incorporated by reference.
Polymers suitable for use as a target molecule D in the compound according to the invention are known to a person skilled in the art, and several examples are described in more detail in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013, Chapter 18: "PEGylation and synthetic polymer modification", p. 787 - 838, incorporated by reference. When target molecule D is a polymer, target molecule D is preferably independently selected from the group consisting of a polyethylene glycol (PEG), a polyethylene oxide (PEO), a polypropylene glycol (PPG), a polypropylene oxide (PPO), a 1 ,xx-diaminoalkane polymer (wherein xx is the number of carbon atoms in the alkane, and preferably xx is an integer in the range of 2 to 200, preferably 2 to 10), a (poly)ethylene glycol diamine (e.g. 1 ,8-diamino-3,6-dioxaoctane and equivalents comprising longer ethylene glycol chains), a polysaccharide (e.g. dextran), a poly(amino acid) (e.g. a poly(L- lysine)) and a polyvinyl alcohol). In view of their poor water solubility, preferred polymers include a 1 ,xx-diaminoalkane polymer and polyvinyl alcohol).
Solid surfaces suitable for use as a target molecule D are known to a person skilled in the art. A solid surface is for example a functional surface (e.g. a surface of a nanomaterial, a carbon nanotube, a fullerene or a virus capsid), a metal surface (e.g. a titanium, gold, silver, copper, nickel, tin, rhodium or zinc surface), a metal alloy surface (wherein the alloy is from e.g. aluminium, bismuth, chromium, cobalt, copper, gallium, gold, indium, iron, lead, magnesium, mercury, nickel, potassium, plutonium, rhodium, scandium, silver, sodium, titanium, tin, uranium, zinc and/or zirconium), a polymer surface (wherein the polymer is e.g. polystyrene, polyvinylchloride, polyethylene, polypropylene, poly(dimethylsiloxane) or polymethylmethacrylate, polyacrylamide), a glass surface, a silicone surface, a chromatography support surface (wherein the chromatography support is e.g. a silica support, an agarose support, a cellulose support or an alumina support), etc. When target molecule D is a solid surface, it is preferred that D is independently selected from the group consisting of a functional surface or a polymer surface. Hydrogels are known to the person skilled in the art. Hydrogels are water-swollen networks,
formed by cross-links between the polymeric constituents. See for example A. S. Hoffman, Adv. Drug Delivery Rev. 2012, 64, 18, incorporated by reference. When the target molecule is a hydrogel, it is preferred that the hydrogel is composed of poly(ethylene)glycol (PEG) as the polymeric basis.
Micro- and nanoparticles suitable for use as a target molecule D are known to a person skilled in the art. A variety of suitable micro- and nanoparticles is described in e.g. G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013, Chapter 14: "Microparticles and nanoparticles", p. 549 - 587, incorporated by reference. The micro- or nanoparticles may be of any shape, e.g. spheres, rods, tubes, cubes, triangles and cones. Preferably, the micro- or nanoparticles are of a spherical shape. The chemical composition of the micro- and nanoparticles may vary. When target molecule D is a micro- or a nanoparticle, the micro- or nanoparticle is for example a polymeric micro- or nanoparticle, a silica micro- or nanoparticle or a gold micro- or nanoparticle. When the particle is a polymeric micro- or nanoparticle, the polymer is preferably polystyrene or a copolymer of styrene (e.g. a copolymer of styrene and divinylbenzene, butadiene, acrylate and/or vinyltoluene), polymethylmethacrylate (PMMA), polyvinyltoluene, poly(hydroxyethyl methacrylate (pHEMA) or polyethylene glycol dimethacrylate/2-hydroxyethyl methacrylate) [poly(EDGMA HEMA)]. Optionally, the surface of the micro- or nanoparticles is modified, e.g. with detergents, by graft polymerization of secondary polymers or by covalent attachment of another polymer or of spacer moieties, etc.
Target molecule D may also be a biomolecule. Biomolecules, and preferred embodiments thereof, are described in more detail below. When target molecule D is a biomolecule, it is preferred that the biomolecule is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, lipids, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides, enzymes, hormones, amino acids and monosaccharides. Preferred options for D are described further below for the antibody-conjugate according to the third aspect. The bioconjugates in the context of the present invention may contain more than one target molecule D, which may be the same or different. In one embodiment, the bioconjugate of the present invention may contain more than one, preferably two, target molecules connected to the same S (i.e. one of x, r and q > 1 , preferably one of x, r and q = 2), preferably to the same Z3 (i.e. one of r and q > 1 , preferably one of r and q = 2). Most preferably in the context of the present embodiment, r = 2. Preferably, those target molecules are different, more preferably they both are active substances, more preferably anti-cancer agents, most preferably cytotoxins. In one embodiment, the bioconjugate of the present invention comprises two distinct target molecules, preferably two distinct active substances, more preferably two distinct anti-cancer agents, most preferably two distinct cytotoxins.
Preferably, the linker-conjugate comprises a (hetero)cycloalkynyl group. In a preferred embodiment said linker-conjugate has the Formula (31 ):
c

(31 )
wherein:
- L2 is a linker as defined herein;
- D is a target molecule;
- r is 1 - 20;
- R3 is independently selected from the group consisting of hydrogen, halogen, -OR35, -NO2, -CN, -S(0)2R35, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- X is C(R3 )2, O, S or NR32, wherein R32 is R3 or L2(D , and wherein L2, D and r are as defined above;
- q is 0 or 1 , with the proviso that if q is 0 then X is NL2(D)r; and
- aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8.
In another preferred embodiment said linker-con ugate has the Formula (31 b):

wherein:
- L2 is a linker as defined herein;
- D is a target molecule;
- r is 1 - 20;
- R3 is independently selected from the group consisting of hydrogen, halogen, -OR35, -NO2, -CN, -S(0)2R35, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R35 is independently selected from the group consisting
of hydrogen, halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- X is C(R3 )2, O, S or NR32, wherein R32 is R3 or L2(D , and wherein L2, D and r are as defined above;
- q is 0 or 1 , with the proviso that if q is 0 then X is NL2(D)r;
- aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8;
- aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8; and
- aa + aa' < 10.
In a further preferred embodiment, aa + aa' is 4, 5, 6 or 7, more preferably aa + aa' is 4, 5 or 6 and most preferably aa + aa' is 5.
In another preferred embodiment said linker-conjugate has the Formula (31c):
^^^{L2(D)r]q (31c)
wherein:
- L2 is a linker as defined herein;
- D is a target molecule;
- r is 1 - 20;
- q is 0 or 1 , with the proviso that if q is 0 then X is NL2(D)r; and
- 1 is 0 - 10.
In a preferred embodiment, if q is 1 then X is C(R3 )2, O, S or NR31.
In another preferred embodiment, a is 5, i.e. said (hetero)cycloalkynyl group is preferably a (hetero)cyclooctyne group. In another preferred embodiment, X is C(R32)2 or NR32. When X is C(R32)2 it is preferred that R32 is hydrogen. When X is NR32, it is preferred that R32 is L2(D)r. In yet another preferred embodiment, r is 1 to 10, more preferably, r is 1 , 2, 3, 4, 5, 6 7 or 8, more preferably r is 1 , 2, 3, 4, 5 or 6, most preferably r is 1 , 2, 3 or 4.
The L2(D)r substituent may be present on a C-atom in said (hetero)cycloalkynyl group, or, in case of a heterocycloalkynyl group, on the heteroatom of said heterocycloalkynyl group. When the (hetero)cycloalkynyl group comprises substituents, e.g. an annelated cycloalkyl, the L2(D)r substituent may also be present on said substituents.
The methods to connect a linker L2 to a (hetero)cycloalkynyl group on the one end and to a target molecule on the other end, in order to obtain a linker-conjugate, depend on the exact the nature of the linker, the (hetero)cycloalkynyl group and the target molecule. Suitable methods are known in the art.
Preferably, the linker-conjugate comprises a (hetero)cyclooctyne group, more preferably a strained (hetero)cyclooctyne group. Suitable (hetero)cycloalkynyl moieties are known in the art. For example DIFO, DIF02 and DIF03 are disclosed in US 2009/0068738, incorporated by reference. DIBO is disclosed in WO 2009/067663, incorporated by reference. DIBO may
optionally be sulphated (S-DIBO) as disclosed in J. Am. Chem. Soc. 2012, 134, 5381 . BARAC is disclosed in J. Am. Chem. Soc. 2010, 132, 3688 - 3690 and US 201 1/0207147, all incorporated by reference.
Preferred examples of linker-conjugates comprising a (hetero)cyclooctyne group are shown below.

2(D (32) DIF02-L2(D (33) DIF03-L2(D (34)

DIBO-L2(D (35) BARAC-L2(D)r (36) MFCO-L2(D (36a)
Other cyclooctyne moieties that are known in the art are DIBAC (also known as ADIBO or DBCO) and BCN. DIBAC is disclosed in Chem. Commun. 2010, 46, 97 - 99, incorporated by reference. BCN is disclosed in WO 201 1/136645, incorporated by reference.
In a preferred embodiment, said linker-conjugate has the Formula (32), (33), (34), (35) or (36). In another preferred embodiment, said linker-con ugate has the Formula (37):

wherein:
- R , L2, D and r are as defined above;
- Y is O, S or NR32, wherein R32 is as defined above;
- R33 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- R34 is selected from the group consisting of hydrogen, Y-L2(D)r, -(CH2)nn-Y-L2(D)r, halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups, the alkyl groups optionally being interrupted by one of more hetero-atoms selected from the group consisting of O, N and S, wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are independently optionally substituted; and
- nn is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10.
In a further preferred embodiment, R3 is hydrogen. In another preferred embodiment, R33 is hydrogen. In another preferred embodiment, n is 1 or 2. In another preferred embodiment, R34 is hydrogen, Y-L2(D)r or -(CH2)nn-Y-L2(D)r. In another preferred embodiment, R32 is hydrogen or L2(D)r. In a further preferred embodiment, the linker-conjugate has the Formula 38:

BCN-L2Dr (38)
wherein Y, L2, D, nn and r are as defined above.
In another preferred embodiment, said linker-conjugate has the Formula (39):

wherein L2, D and r are as defined above.
In another preferred embodiment, said linker-conjugate has the Formula (35):

(35)
wherein L2, D and r are as defined above.
The value of pp and the nature of M depend on the azide-substituted sugar or sugar derivative S(F )x that is present in the azide-modified antibody according to the invention that is linked to a linker-conjugate. If an azide in S(F )X is present on the C2, C3, or C4 position of the sugar or the sugar derivative (instead of a sugar OH-group), then pp is 0. If the S(F )X is an azidoacetamido-2- deoxy-sugar derivative, S(F )X is e.g. GalNAz or GlcNAz, then pp is 1 and M is -N(H)C(0)CH2-. If the azide in S(F )X is present on the C6 position of the sugar or the sugar derivative, then pp is 0 and M is absent.
Linkers (L2), also referred to as linking units, are well known in the art. In a linker-conjugate as described herein, L is linked to a target molecule as well as to a functional group Q . L2 may for example be selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cycloalkylene groups, C5-C200 cycloalkenylene groups, C8-C200 cycloalkynylene groups, C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups, C9-C200 arylalkynylene groups. Optionally the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups may be substituted, and optionally said groups may be interrupted by one or more heteroatoms, preferably 1 to 100 heteroatoms, said heteroatoms preferably being selected from the group consisting of O, S and NR35, wherein R35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups. Most preferably, the heteroatom is O. Examples of suitable linking units include (poly)ethylene glycol diamines (e.g. 1 ,8-diamino-3,6-dioxaoctane or equivalents comprising longer ethylene glycol chains), polyethylene glycol or polyethylene oxide chains, polypropylene glycol or polypropylene oxide chains and 1 ,χχ-diaminoalkanes wherein xx is the number of carbon atoms in the alkane.
Another class of suitable linkers comprises cleavable linkers. Cleavable linkers are well known in the art. For example Shabat ef a/. , Soft Matter 2012, 6, 1073, incorporated by reference herein, discloses cleavable linkers comprising self-immolative moieties that are released upon a biological trigger, e.g. an enzymatic cleavage or an oxidation event. Some examples of suitable cleavable linkers are peptide-linkers that are cleaved upon specific recognition by a protease, e.g. cathepsin, plasmin or metalloproteases, or glycoside-based linkers that are cleaved upon specific recognition by a glycosidase, e.g. glucuronidase, or nitroaromatics that are reduced in oxygen- poor, hypoxic areas.
Preferred linkers L2 are defined further below for the embodiment on "sulfamide linkage" as well as for the antibody-conjugate according to the third aspect. Preferred linker-conjugates are also defined further below.
Step (ii) is preferably performed at a temperature in the range of about 20 to about 50 °C, more preferably in the range of about 25 to about 45 °C, even more preferably in the range of about 30 to about 40 °C, and most preferably in the range of about 32 to about 37 °C. Step (ii) is preferably
performed a pH in the range of about 5 to about 9, preferably in the range of about 5.5 to about 8.5, more preferably in the range of about 6 to about 8. Most preferably, step (ii) is performed at a pH in the range of about 7 to about 8. Step (ii) is preferably performed in water. More preferably, said water is purified water, even more preferably ultrapure water or Type I water as defined according to ISO 3696. Suitable water is for example milliQ® water. Said water is preferably buffered, for example with phosphate-buffered saline or tris. Suitable buffers are known to a person skilled in the art. In a preferred embodiment, step (ii) is performed in milliQ water which is buffered with phosphate-buffered saline or tris. In one embodiment, the reaction of step (ii) is a(n) (cyclo)alkyne-azide conjugation to from a connecting moiety Z3 that is represented by (10e), (10i), (10g), (10j) or (10k), preferably by (10e), (10i), (1

wherein cycle A is a 7-10-membered (hetero)cyclic moiety. Connecting moieties (10e), (10j) and (10k) may exist in either one of the possible two regioisomers.
The bioconjugate that comprises or that is obtained by the present mode of conjugation is preferably represented by Formula (40) or (40b):

(40b),
wherein:
- AB is an antibody, S is a sugar or a sugar derivative, GlcNAc is N-acetylglucosamine;
- R3 is independently selected from the group consisting of hydrogen, halogen, -OR35, -NO2, -CN, -S(0)2R35, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- X is C(R3 )2, O, S or NR32, wherein R32 is R3 or L2(D , wherein L2 is a linker, and D is as defined in claim 1 ;
- r is 1 - 20;
- q is 0 or 1 , with the proviso that if q is 0 then X is NL2(D)r;
- aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8;
- aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8; and
- aa+aa' < 10.
- b is 0 or 1 ;
- pp is 0 or 1 ;
- M is -N(H)C(0)CH2- -N(H)C(0)CF2-, -CH2-, -CF2- or a 1 ,4-phenylene containing 0 - 4 fluorine substituents, preferably 2 fluorine substituents which are preferably positioned on C2 and C6 or on C3 and C5 of the phenylene;
- x is 1 or 2;
- y is 1 - 4;
- Fuc is fucose. In a preferred embodiment, the antibody-conjugate according to the invention is of the Formula (41 ):
[ffuc)b Ί

(41 ),
wherein AB, L2, D, Y, S, M, x, y, b, pp, R32, GlcNAc, R3 , R33, R34, nn and r are as defined above and wherein said N-acetylglucosamine is optionally fucosylated (b is 0 or 1 ).
In a further preferred embodiment, R3 , R33 and R34 are hydrogen and nn is 1 or 2, and in an even more preferred embodiment x is 1.
In another preferred embodiment, the antibody-conjugate is of the Formula (42):

(42),
wherein AB, L2, D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated (b is 0 or 1 ); or according to regioisomer (42b):
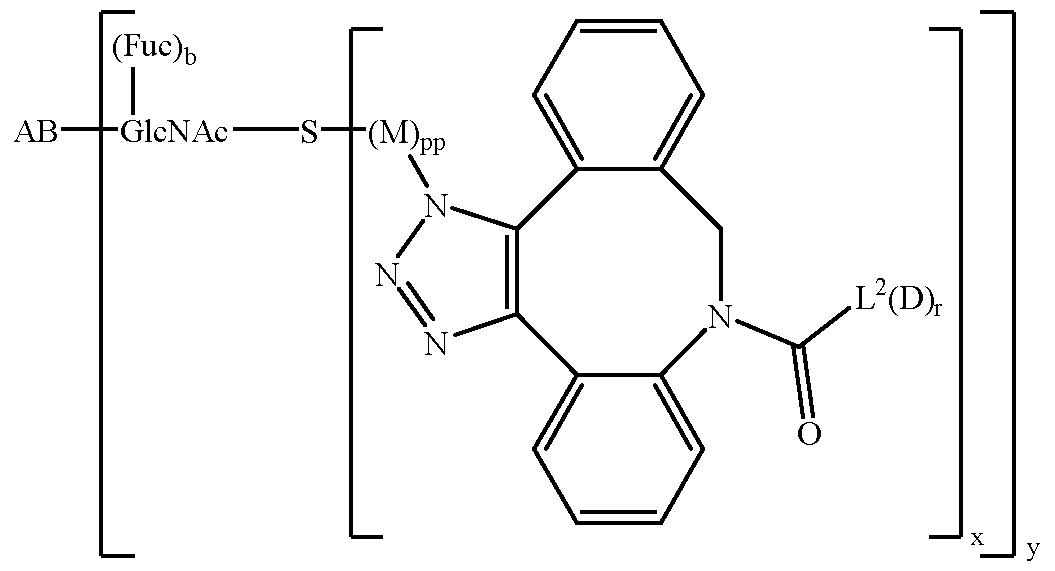
(42b),
wherein AB, L2, D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated.
In another preferred 5b):

(35b),
wherein AB, L2, D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated.
In another preferred embodiment, the antibody-conjugate is of the Formula (40c):

(40c),
wherein AB, L2, D, S, b, pp, x, y, M and GlcNAc are as defined above, and wherein said N- acetylglucosamine is optionally fucosylated.
In another preferred embodiment, the antibody-conjugate is of the Formula (40d):

(40d),
wherein AB, L2, D, S, b, pp, x, y, M and GlcNAc are as defined above, wherein I is 0 - 10 and wherein said N-acetylglucosamine is optionally fucosylated.
Sulfamide linkage
In one embodiment, the mode of conjugation according to the invention is referred to as "sulfamide linkage", which refers to the presence of a specific linker L which links the biomolecule B and the target molecule D. All said about the linker L in the context of the present embodiment preferably also applies to the linker, in particular linker L2, according to the embodiment on core- GlcNAc functionalization as mode of conjugation. The linker L comprises a group according to formula (1 ) or a salt thereof:

1
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, wherein D is optionally connected to N via a spacer moiety.
When the group of formula (1 ) comprises a salt, the salt is preferably a pharmaceutically acceptable salt.
In a preferred embodiment, linker L according to the invention comprises a group according to formula (1 ) wherein a is 0, or a salt thereof. In this embodiment, linker L thus comprises a group according to formula (2) or a salt thereof:

In another preferred embodiment, linker L according to the invention comprises a group according to formula (1 ) wherein a is 1 , or a salt thereof. In this embodiment, linker L thus comprises a group according to formula (3) or a salt thereof:

3
wherein R is as defined above.
In the groups according to formula (1 ), (2) and (3), R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, wherein D is optionally connected to N via a spacer moiety;
In a preferred embodiment, R is hydrogen or a Ci - C20 alkyl group, more preferably R is hydrogen or a Ci - C16 alkyl group, even more preferably R is hydrogen or a Ci - C10 alkyl group, wherein the alkyl group is optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3, preferably O, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups. In a preferred embodiment, R is hydrogen. In another preferred embodiment, R is a Ci - C20 alkyl group, more preferably a Ci - C16 alkyl group, even more preferably a Ci - C10 alkyl group, wherein the alkyl group is optionally interrupted by one or more O-atoms, and wherein the alkyl group is optionally substituted with an -OH group, preferably a terminal -OH group. In this embodiment it is further preferred that R is a (poly)ethyleneglycol chain comprising a terminal -OH group. In another preferred embodiment, R is selected from the group consisting of hydrogen, methyl, ethyl, n- propyl, i-propyl, n-butyl, s-butyl and t-butyl, more preferably from the group consisting of hydrogen, methyl, ethyl, n-propyl and i-propyl, and even more preferably from the group consisting of hydrogen, methyl and ethyl. Yet even more preferably R is hydrogen or methyl, and most preferably R is hydrogen.
In another preferred embodiment, R is a further target molecule D. Optionally, D is connected to N via one or more spacer-moieties. The spacer-moiety, if present, is defined as a moiety that spaces, i.e. provides a certain distance between, and covalently links D and N.
Target molecule D and preferred embodiments thereof are defined in more detail above.
To obtain the bioconjugate of formula (A), the group of formula (1 ) can be introduced in one of three options. First of all, the linker L comprising the group according to formula (1 ) or a salt thereof may be present in the linker-conjugate represented by Q -D, wherein L is the spacer between Q and D. Secondly, the linker L comprising the group according to formula (1 ) or a salt thereof may be present in the biomolecule represented by B-F , wherein L is the spacer between B and F . Thirdly, the group according to formula (1 ) or a salt thereof may be formed during the conjugation reaction itself. In the latter option, Q and F are selected as such that their reaction product, i.e. connecting group Z3, contains or is the group according to formula (1 ) or a salt thereof. Preferably, the group according to formula (1 ) or a salt thereof is introduced according to the first or second of the above mentioned options, most preferably according to the first option. In case the group according to formula (1 ) or a salt thereof is already present as such during the conjugation reaction, the positive effect on solubility and absence of in-process aggregation, as recited above, improve the efficiency of the conjugation reaction. In case the group according to formula (1 ) or a salt thereof is present in the linker-conjugate, even hydrophobic drugs can readily be subjected to the conjugation reaction.
Linker-conjugate
The linker-conjugate is represented by Q -D, preferably by Q -L-D, wherein D is a target molecule, L is a linker linking Q and D as further defined above, Q is a reactive group capable of reacting with functional group F on the biomolecule and each occurrence of "-" is independently
a bond or a spacer moiety. In one embodiment, "-" is a spacer moiety as defined herein. In one embodiment, "-" is a bond, typically a covalent bond. The linker-conjugate is a compound wherein a target molecule is covalently connected to a reactive group Q , preferably via a linker or spacer, most preferably via linker L as defined above. The linker-conjugate may be obtained via reaction of a reactive group Q2 present on a linker-construct with a reactive group present on a target molecule.
Preferably, the group according to formula (1 ), or the salt thereof, is situated in between Q and D. In other words, reactive group Q is covalently bonded to a first end of the group according to formula (1 ), and target molecule D is covalently bonded to a second end of the group according to formula (1 ). Herein, "first end" and "second end" both refer to either the carbonyl or carboxy end of the group according to formula (1 ) or to the sulfamide end of the group according to formula (1 ), but logically not to the same end.
As will be appreciated by the person skilled in the art, the linker-conjugate according to the invention may comprise more than one target molecule D, e.g. two, three, four, five, etc. Consequently, the linker-conjugate may thus comprise more than one "second end". Similarly, the linker-conjugate may comprise more than one reactive group Q , i.e. the linker-conjugate may comprise more than one first end. When more than one reactive group Q is present the groups Q may be the same or different, and when more than one target molecule D is present the target molecule D may be the same or different.
The linker-conjugate according to the invention may therefore also be denoted as (Q )y Sp(D)z, wherein y' is an integer in the range of 1 to 10 and z is an integer in the range of 1 to 10. Herein:
- y' is an integer in the range of 1 to 10;
- z is an integer in the range of 1 to 10;
- Q is a reactive group capable of reacting with a functional group F present on a biomolecule;
- D is an target molecule;
- Sp is a spacer moiety, wherein a spacer moiety is defined as a moiety that spaces (i.e. provides a certain distance between) and covalently links reactive group Q and target molecule D, preferably wherein said spacer moiety is linker L as defined above, and thus comprises a group according to formula (1 ) or a salt thereof.
Preferably, y' is 1 , 2, 3 or 4, more preferably y' is 1 or 2 and most preferably, y' is 1. Preferably, z is 1 , 2, 3, 4, 5 or 6, more preferably z is 1 , 2, 3 or 4, even more preferably z is 1 , 2 or 3, yet even more preferably z is 1 or 2 and most preferably z is 1. More preferably, y' is 1 or 2, preferably 1 , and z is 1 , 2, 3 or 4, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 , 2 or 3, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 or 2, and most preferably y' is 1 and z is 1. In a preferred embodiment, the linker-conjugate is according to the formula Q Sp(D)4, Q Sp(D)3, Q Sp(D)2 or Q SpD.
D is preferably an "active substance" or "pharmaceutically active substance", and refers to a pharmacological and/or biological substance, i.e. a substance that is biologically and/or pharmaceutically active, for example a drug, a prodrug, a diagnostic agent. Preferably, the active substance is selected from the group consisting of drugs and prodrugs. More preferably, the active substance is a pharmaceutically active compounds, in particular low to medium molecular weight compounds (e.g. about 200 to about 2500 Da, preferably about 300 to about 1750 Da). In a further preferred embodiment, the active substance is selected from the group consisting of cytotoxins, antiviral agents, antibacterials agents, peptides and oligonucleotides. Examples of cytotoxins include colchicine, vinca alkaloids, anthracyclines, camptothecins, doxorubicin, daunorubicin, taxanes, calicheamycins, tubulysins, irinotecans, enediynes, an inhibitory peptide, amanitin, deBouganin, duocarmycins, maytansines, auristatins, pyrrolobenzodiazepines (PBDs) or indolinobenzodiazepines (IBDs). Preferred active substances include enediynes, anthracyclines, camptothecins, taxanes, tubulysins, amanitin, duocarmycins, maytansines, auristatins, pyrrolobenzodiazepines or indolinobenzodiazepines, in particular enediynes, anthracyclines, pyrrolobenzodiazepines (PBDs), maytansines and auristatins.
The linker-conjugate comprises a reactive group Q that is capable of reacting with a functional group F present on a biomolecule. Functional groups are known to a person skilled in the art and may be defined as any molecular entity that imparts a specific property onto the molecule harbouring it. For example, a functional group in a biomolecule may constitute an amino group, a thiol group, a carboxylic acid, an alcohol group, a carbonyl group, a phosphate group, or an aromatic group. The functional group in the biomolecule may be naturally present or may be placed in the biomolecule by a specific technique, for example a (bio)chemical or a genetic technique. The functional group that is placed in the biomolecule may be a functional group that is naturally present in nature, or may be a functional group that is prepared by chemical synthesis, for example an azide, a terminal alkyne or a phosphine moiety. Herein, the term "reactive group" may refer to a certain group that comprises a functional group, but also to a functional group itself. For example, a cyclooctynyl group is a reactive group comprising a functional group, namely a C- C triple bond. Similarly, an N-maleimidyl group is a reactive group, comprising a C-C double bond as a functional group. However, a functional group, for example an azido functional group, a thiol functional group or an amino functional group, may herein also be referred to as a reactive group. The linker-conjugate may comprise more than one reactive group Q . When the linker-conjugate comprises two or more reactive groups Q , the reactive groups Q may differ from each other. Preferably, the linker-conjugate comprises one reactive group Q .
Reactive group Q that is present in the linker-conjugate, is able to react with a functional group F that is present in a biomolecule to form connecting group Z3. In other words, reactive group Q needs to be complementary to a functional group F present in a biomolecule. Herein, a reactive group is denoted as "complementary" to a functional group when said reactive group reacts with said functional group selectively to form connecting group Z3, optionally in the presence of other functional groups. Complementary reactive and functional groups are known to a person skilled in
the art, and are described in more detail below.
In a preferred embodiment, reactive group Q is selected from the group consisting of, optionally substituted, N-maleimidyl groups, halogenated N-alkylamido groups, sulfonyloxy N-alkylamido groups, ester groups, carbonate groups, sulfonyl halide groups, thiol groups or derivatives thereof, alkenyl groups, alkynyl groups, (hetero)cycloalkynyl groups, bicyclo[6.1.0]non-4-yn-9-yl] groups, cycloalkenyl groups, tetrazinyl groups, azido groups, phosphine groups, nitrile oxide groups, nitrone groups, nitrile imine groups, diazo groups, ketone groups, (O-alkyl)hydroxylamino groups, hydrazine groups, halogenated N-maleimidyl groups, 1 , 1-bis(sulfonylmethyl)methylcarbonyl groups or elimination derivatives thereof, carbonyl halide groups, allenamide groups, 1 ,2-quinone groups or triazine groups.
In a preferred embodiment, Q is an N-maleimidyl group. When Q is an N-maleimidyl group, Q is preferably unsubstituted. Q is thus preferably according to formula (9a), as shown below. A preferred example of such a maleimidyl group is 2,3-diaminopropionic acid (DPR) maleimidyl, which may be connected to the remainder of the linker-conjugate through the carboxylic acid moiety.
In another preferred embodiment, Q is a halogenated N-alkylamido group. When Q is a halogenated N-alkylamido group, it is preferred that Q is according to formula (9b), as shown below, wherein k is an integer in the range of 1 to 10 and R4 is selected from the group consisting of -CI, -Br and -I. Preferably k is 1 , 2, 3 or 4, more preferably k is 1 or 2 and most preferably k is 1. Preferably, R4 is -I or -Br. More preferably, k is 1 or 2 and R4 is -I or -Br, and most preferably k is 1 and R4 is -I or Br.
In another preferred embodiment, Q is a sulfonyloxy N-alkylamido group. When Q is a sulfonyloxy N-alkylamido group, it is preferred that Q is according to formula (9b), as shown below, wherein k is an integer in the range of 1 to 10 and R4 is selected from the group consisting of -O-mesyl, -O-phenylsulfonyl and -O-tosyl. Preferably k is 1 , 2, 3 or 4, more preferably k is 1 or 2, even more preferably k is 1 . Most preferably k is 1 and R4 is selected from the group consisting of -O-mesyl, -O-phenylsulfonyl and -O-tosyl.
In another preferred embodiment, Q is an ester group. When Q is an ester group, it is preferred that the ester group is an activated ester group. Activated ester groups are known to the person skilled in the art. An activated ester group is herein defined as an ester group comprising a good leaving group, wherein the ester carbonyl group is bonded to said good leaving group. Good leaving groups are known to the person skilled in the art. It is further preferred that the activated ester is according to formula (9c), as shown below, wherein R5 is selected from the group consisting of -N-succinimidyl (NHS), -N-sulfo-succinimidyl (sulfo-NHS), -(4-nitrophenyl), -pentafluorophenyl or -tetrafluorophenyl (TFP).
In another preferred embodiment, Q is a carbonate group. When Q is a carbonate group, it is preferred that the carbonate group is an activated carbonate group. Activated carbonate groups are known to a person skilled in the art. An activated carbonate group is herein defined as a carbonate group comprising a good leaving group, wherein the carbonate carbonyl group is bonded to said good leaving group. It is further preferred that the carbonate group is according to
formula (9d), as shown below, wherein R7 is selected from the group consisting of -N- succinimidyl, -N-sulfo-succinimidyl, -(4-nitrophenyl), -pentafluorophenyl or -tetrafluorophenyl. In another preferred embodiment, Q is a sulfonyl halide group according to formula (9e) as shown below, wherein X is selected from the group consisting of F, CI, Br and I. Preferably X is CI or Br, more preferably CI.
In another preferred embodiment, Q is a thiol group (9f), or a derivative or a precursor of a thiol group. A thiol group may also be referred to as a mercapto group. When Q is a derivative or a precursor of a thiol group, the thiol derivative is preferably according to formula (9g), (9h) or (9zb) as shown below, wherein R8 is an, optionally substituted, Ci - C12 alkyl group or a C2 - C12 (hetero)aryl group, V is O or S and R 6 is an, optionally substituted, Ci - C12 alkyl group. More preferably R8 is an, optionally substituted, Ci - C6 alkyl group or a C2 - C6 (hetero)aryl group, and even more preferably R8 is methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl, t-butyl or phenyl. Even more preferably, R8 is methyl or phenyl, most preferably methyl. More preferably R 6 is an optionally substituted Ci - C6 alkyl group, and even more preferably R 6 is methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl or t-butyl, most preferably methyl. When Q is a thiol-derivative according to formula (9g) or (9zb), and Q is reacted with a reactive group F on a biomolecule, said thiol- derivative is converted to a thiol group during the process. When Q is according to formula (9h), Q is -SC(0)OR8 or -SC(S)OR8, preferably SC(0)OR8, wherein R8, and preferred embodiments thereof, are as defined above.
In another preferred embodiment, Q is an alkenyl group, wherein the alkenyl group is linear or branched, and wherein the alkenyl group is optionally substituted. The alkenyl group may be a terminal or an internal alkenyl group. The alkenyl group may comprise more than one C-C double bond, and if so, preferably comprises two C-C double bonds. When the alkenyl group is a dienyl group, it is further preferred that the two C-C double bonds are separated by one C-C single bond (i.e. it is preferred that the dienyl group is a conjugated dienyl group). Preferably said alkenyl group is a C2 - C24 alkenyl group, more preferably a C2 - C12 alkenyl group, and even more preferably a C2 - C6 alkenyl group. It is further preferred that the alkenyl group is a terminal alkenyl group. More preferably, the alkenyl group is according to formula (9i) as shown below, wherein I is an integer in the range of 0 to 10, preferably in the range of 0 to 6, and p is an integer in the range of 0 to 10, preferably 0 to 6. More preferably, I is 0, 1 , 2, 3 or 4, more preferably I is 0, 1 or 2 and most preferably I is 0 or 1 . More preferably, p is 0, 1 , 2, 3 or 4, more preferably p is 0, 1 or 2 and most preferably p is 0 or 1. It is particularly preferred that p is 0 and I is 0 or 1 , or that p is 1 and I is 0 or 1.
In another preferred embodiment, Q is an alkynyl group, wherein the alkynyl group is linear or branched, and wherein the alkynyl group is optionally substituted. The alkynyl group may be a terminal or an internal alkynyl group. Preferably said alkynyl group is a C2 - C24 alkynyl group, more preferably a C2 - C12 alkynyl group, and even more preferably a C2 - C6 alkynyl group. It is further preferred that the alkynyl group is a terminal alkynyl group. More preferably, the alkynyl group is according to formula (9j) as shown below, wherein I is an integer in the range of 0 to 10, preferably in the range of 0 to 6. More preferably, I is 0, 1 , 2, 3 or 4, more preferably I is 0, 1 or 2
and most preferably I is 0 or 1. In a further preferred embodiment, the alkynyl group is according to formula (9j) wherein I is 3.
In another preferred embodiment, Q is a cycloalkenyl group. The cycloalkenyl group is optionally substituted. Preferably said cycloalkenyl group is a C3 - C24 cycloalkenyl group, more preferably a C3 - C12 cycloalkenyl group, and even more preferably a C3 - Cs cycloalkenyl group. In a preferred embodiment, the cycloalkenyl group is a irans-cycloalkenyl group, more preferably a trans- cyclooctenyl group (also referred to as a TCO group) and most preferably a irans-cyclooctenyl group according to formula (9zi) or (9zj) as shown below. In another preferred embodiment, the cycloalkenyl group is a cyclopropenyl group, wherein the cyclopropenyl group is optionally substituted. In another preferred embodiment, the cycloalkenyl group is a norbornenyl group, an oxanorbornenyl group, a norbornadienyl group or an oxanorbornadienyl group, wherein the norbornenyl group, oxanorbornenyl group, norbornadienyl group or an oxanorbornadienyl group is optionally substituted. In a further preferred embodiment, the cycloalkenyl group is according to formula (9k), (9I), (9m) or (9zc) as shown below, wherein T is CH2 or O, R9 is independently selected from the group consisting of hydrogen, a linear or branched Ci - C12 alkyl group or a C4 - C12 (hetero)aryl group, and R 9 is selected from the group consisting of hydrogen and fluorinated hydrocarbons. Preferably, R9 is independently hydrogen or a Ci - C6 alkyl group, more preferably R9 is independently hydrogen or a Ci - C4 alkyl group. Even more preferably R9 is independently hydrogen or methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R9 is independently hydrogen or methyl. In a further preferred embodiment, R 9 is selected from the group of hydrogen and -CF3, -C2F5, -C3F7 and -C4F9, more preferably hydrogen and -CF3. In a further preferred embodiment, the cycloalkenyl group is according to formula (9k), wherein one R9 is hydrogen and the other R9 is a methyl group. In another further preferred embodiment, the cycloalkenyl group is according to formula (9I), wherein both R9 are hydrogen. In these embodiments it is further preferred that I is 0 or 1. In another further preferred embodiment, the cycloalkenyl group is a norbornenyl (T is CH2) or an oxanorbornenyl (T is O) group according to formula (9m), or a norbornadienyl (T is CH2) or an oxanorbornadienyl (T is O) group according to formula (9zc), wherein R9 is hydrogen and R 9 is hydrogen or -CF3, preferably -CF3.
In another preferred embodiment, Q is a (hetero)cycloalkynyl group. The (hetero)cycloalkynyl group is optionally substituted. Preferably, the (hetero)cycloalkynyl group is a (hetero)cyclooctynyl group, i.e. a heterocyclooctynyl group or a cyclooctynyl group, wherein the (hetero)cyclooctynyl group is optionally substituted. In a further preferred embodiment, the (hetero)cyclooctynyl group is substituted with one or more halogen atoms, preferably fluorine atoms, more preferably the (hetero)cyclooctynyl group is substituted with one fluorine atom, as in mono-fluoro-cyclooctcyne (MFCO). Preferably, the mono-fluoro-cyclooctcyne group is according to formula (9zo). In a further preferred embodiment, the (hetero)cyclooctynyl group is according to formula (9n), also referred to as a DIBO group, (9o), also referred to as a DIBAC group or (9p), also referred to as a BARAC group, or (9zk), also referred to as a COMBO group, all as shown below, wherein U is O or NR9, and preferred embodiments of R9 are as defined above. The aromatic rings in (9n) are optionally O-sulfonylated at one or more positions, whereas the rings of (9o) and (9p) may be
halogenated at one or more positions. For (9n), U is preferably O.
In an especially preferred embodiment, the nitrogen atom attached to R in compound (4b) is the nitrogen atom in the ring of the heterocycloalkyne group such as the nitrogen atom in (9o). In other words, c, d and g are 0 in compound (4b) and R and Q , together with the nitrogen atom they are attached to, form a heterocycloalkyne group, preferably a heterocyclooctyne group, most preferably the heterocyclooctyne group according to formula (9o) or (9p). Herein, the carbonyl moiety of (9o) is replaced by the sulfonyl group of the group according to formula (1 ). Alternatively, the nitrogen atom to which R is attached is the same atom as the atom designated as U in formula (9n). In other words, when Q is according to formula (9n), U may be the right nitrogen atom of the group according to formula (1 ), or U = NR9 and R9 is the remainder of the group according to formula (1 ) and R is the cyclooctyne moiety.
In another preferred embodiment, Q is an, optionally substituted, bicyclo[6.1.0]non-4-yn-9-yl] group, also referred to as a BCN group. Preferably, the bicyclo[6.1.0]non-4-yn-9-yl] group is according to formula (9q) as shown below.
In another preferred embodiment, Q is a conjugated (hetero)diene group capable of reacting in a Diels-Alder reaction. Preferred (hetero)diene groups include optionally substituted tetrazinyl groups, optionally substituted 1 ,2-quinone groups and optionally substituted triazine groups. More preferably, said tetrazinyl group is according to formula (9r), as shown below, wherein R9 is selected from the group consisting of hydrogen, a linear or branched Ci - C12 alkyl group or a C4 - C12 (hetero)aryl group. Preferably, R9 is hydrogen, a Ci - Ce alkyl group or a C4 - C10 (hetero)aryl group, more preferably R9 is hydrogen, a Ci - C4 alkyl group or a C4 - C6 (hetero)aryl group. Even more preferably R9 is hydrogen, methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl, t- butyl or pyridyl. Yet even more preferably R9 is hydrogen, methyl or pyridyl. More preferably, said 1 ,2-quinone group is according to formula (9zl) or (9zm). Said triazine group may be any regioisomer. More preferably, said triazine group is a 1 ,2,3-triazine group or a 1 ,2,4-triazine group, which may be attached via any possible location, such as indicated in formula (9zn). The 1 ,2,3-triazine is most preferred as triazine group.
In another preferred embodiment, Q is an azido group according to formula (9s) as shown below. In another preferred embodiment, Q is an, optionally substituted, triarylphosphine group that is suitable to undergo a Staudinger ligation reaction. Preferably, the phosphine group is according to forumula (9t) as shown below, wherein R 0 is a (thio)ester group. When R 0 is a (thio)ester group, it is preferred that R 0 is -C(0)-V-R11 , wherein V is O or S and R is a Ci - C12 alkyl group. Preferably, R is a Ci - C6 alkyl group, more preferably a Ci - C4 alkyl group. Most preferably, R is a methyl group.
In another preferred embodiment, Q is a nitrile oxide group according to formula (9u) as shown below.
In another preferred embodiment, Q is a nitrone group. Preferably, the nitrone group is according to formula (9v) as shown below, wherein R 2 is selected from the group consisting of linear or branched Ci - C12 alkyl groups and C6 - C12 aryl groups. Preferably, R 2 is a Ci - C6 alkyl group,
more preferably R 2 is a Ci - C4 alkyl group. Even more preferably R 2 is methyl, ethyl, n-propyl, i- propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 2 is methyl.
In another preferred embodiment, Q is a nitrile imine group. Preferably, the nitrile imine group is according to formula (9w) or (9zd) as shown below, wherein R 3 is selected from the group consisting of linear or branched Ci - C12 alkyl groups and C6 - C12 aryl groups. Preferably, R 3 is a Ci - C6 alkyl group, more preferably R 3 is a Ci - C4 alkyl group. Even more preferably R 3 is methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 3 is methyl. In another preferred embodiment, Q is a diazo group. Preferably, the diazo group is according to formula (9x) as shown below, wherein R 4 is selected from the group consisting of hydrogen or a carbonyl derivative. More preferably, R 4 is hydrogen.
In another preferred embodiment, Q is a ketone group. More preferably, the ketone group is according to formula (9y) as shown below, wherein R 5 is selected from the group consisting of linear or branched Ci - C12 alkyl groups and C6 - C12 aryl groups. Preferably, R 5 is a Ci - C6 alkyl group, more preferably R 5 is a Ci - C4 alkyl group. Even more preferably R 5 is methyl, ethyl, n- propyl, i-propyl, n-butyl, s-butyl or t-butyl. Yet even more preferably R 5 is methyl.
In another preferred embodiment, Q is an (O-alkyl)hydroxylamino group. More preferably, the (O- alkyl)hydroxylamino group is according to formula (9z) as shown below.
In another preferred embodiment, Q is a hydrazine group. Preferably, the hydrazine group is according to formula (9za) as shown below.
In another preferred embodiment, Q is a halogenated N-maleimidyl group or a sulfonylated N- maleimidyl group. When Q is a halogenated or sulfonylated N-maleimidyl group, Q is preferably according to formula (9ze) as shown below, wherein R6 is independently selected from the group consisting of hydrogen F, CI, Br, I -SR 8a and -OS(0)2R 8b, wherein R 8a is an optionally substituted C4 - C12 (hetero)aryl groups, preferably phenyl or pyrydyl, and R 8b is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups, preferably tolyl or methyl, and with the proviso that at least one R6 is not hydrogen. When R6 is halogen (i.e. when R6 is F, CI, Br or I), it is preferred that R6 is Br. In one embodiment, the halogenated N-maleimidyl group is halogentated 2,3-diaminopropionic acid (DPR) maleimidyl, which may be connected to the remainder of the linker-conjugate through the carboxylic acid moiety.
In another preferred embodiment, Q is a carbonyl halide group according to formula (9zf) as shown below, wherein X is selected from the group consisting of F, CI, Br and I. Preferably, X is CI or Br, and most preferably, X is CI.
In another preferred embodiment, Q is an allenamide group according to formula (9zg).
In another preferred embodiment, Q is a 1 , 1-bis(sulfonylmethyl)methylcarbonyl group according to formula (9zh), or an elimination derivative thereof, wherein R 8 is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups. More preferably, R 8 is an, optionally substituted, Ci - C6 alkyl group or a C4 - C6 (hetero)aryl group, and most preferably a phenyl group.


9x 9 9z 9za

9zk 9zl 9zm 9zn wherein k, I, X, T, U, V, R4, R5, R6, R7, R8, R9, R 0, R11, R 2, R 3, R 4, R 5, R 6, R 8 and R 9 are as defined above.
In a preferred embodiment of the conjugation process according to the invention as described herein below, conjugation is accomplished via a cycloaddition, such as a Diels-Alder reaction or a 1 ,3-dipolar cycloaddition, preferably the 1 ,3-dipolar cycloaddition. According to this embodiment, the reactive group Q (as well as F on the biomolecule) is selected from groups reactive in a cycloaddition reaction. Herein, reactive groups Q and F are complementary, i.e. they are capable of reacting with each other in a cycloaddition reaction, the obtained cyclic moiety being connecting group Z3.
For a Diels-Alder reaction, one of F and Q is a diene and the other of F and Q is a dienophile. As appreciated by the skilled person, the term "diene" in the context of the Diels-Alder reaction
refers to 1 ,3-(hetero)dienes, and includes conjugated dienes (R2C=CR-CR=CR2), imines (e.g. R2C=CR-N=CR2 or R2C=CR-CR=NR, R2C=N-N=CR2) and carbonyls (e.g. R2C=CR-CR=0 or 0=CR-CR=0). Hetero-Diels-Alder reactions with N- and O-containing dienes are known to a person skilled in the art. Any diene known in the art to be suitable for Diels-Alder reactions may be used as reactive group Q or F . Preferred dienes include tetrazines as described above, 1 ,2- quinones as described above and triazines as described above. Although any dienophile known in the art to be suitable for Diels-Alder reactions may be used as reactive groups Q or F , the dienophile is preferably an alkene or alkyne group as described above, most preferably an alkyne group. For conjugation via a Diels-Alder reaction, it is preferred that F is the diene and Q is the dienophile. Herein, when Q is a diene, F is a dienophile and when Q is a dienophile, F is a diene. Most preferably, Q is a dienophile, preferably Q is or comprises an alkynyl group, and F is a diene, preferably a tetrazine, 1 ,2-quinone or triazine group.
For a 1 ,3-dipolar cycloaddition, one of F and Q is a 1 ,3-dipole and the other of F and Q is a dipolarophile. Any 1 ,3-dipole known in the art to be suitable for 1 ,3-dipolar cycloadditions may be used as reactive group Q or F . Preferred 1 ,3-dipoles include azido groups, nitrone groups, nitrile oxide groups, nitrile imine groups and diazo groups. Although any dipolarophile known in the art to be suitable for 1 ,3-dipolar cycloadditions may be used as reactive groups Q or F , the dipolarophile is preferably an alkene or alkyne group, most preferably an alkyne group. For conjugation via a 1 ,3-dipolar cycloaddition, it is preferred that F is the 1 ,3-dipole and Q is the dipolarophile. Herein, when Q is a 1 ,3-dipole, F is a dipolarophile and when Q is a dipolarophile, F is a 1 ,3-dipole. Most preferably, Q is a dipolarophile, preferably Q is or comprises an alkynyl group, and F is a 1 ,3-dipole, preferably an azido group.
Thus, in a preferred embodiment, Q is selected from dipolarophiles and dienophiles. Preferably, Q is an alkene or an alkyne group. In an especially preferred embodiment, Q comprises an alkyne group, preferably selected from the alkynyl group as described above, the cycloalkenyl group as described above, the (hetero)cycloalkynyl group as described above and a bicyclo[6.1.0]non-4-yn-9-yl] group, more preferably Q is selected from the formulae (9j), (9n), (9o), (9p), (9q), (9zk) and (9zo) as defined above and depicted below, such as selected from the formulae (9j), (9n), (9o), (9p), (9q) and (9zk), more preferably selected from the formulae (9n), (9o), (9p), (9q) and (9zk) or from the formulae (9j), (9n), (9q) and (9zo). Most preferably, Q is a bicyclo[6.1.0]non-4-yn-9-yl] group, preferably of formula (9q). These groups are known to be highly effective in the conjugation with azido-functionalized biomolecules as described herein, and when the sulfamide linker according to the invention is employed in such linker-conjugates, any aggregation is beneficially reduced to a minimum.
As was described above, in the linker-conjugate, Q is capable of reacting with a reactive group F that is present on a biomolecule. Complementary reactive groups F for reactive group Q are known to a person skilled in the art, and are described in more detail below. Some representative examples of reaction between F and Q and their corresponding products comprising connecting group Z3 are depicted in Figure 5.
As described above, D and Q are covalently attached in the linker-conjugate according to the invention, preferably via linker L as defined above. Covalent attachment of D to the linker may occur for example via reaction of a functional group F2 present on D with a reactive group Q2 present on the linker. Suitable organic reactions for the attachment of D to a linker are known to a person skilled in the art, as are functional groups F2 that are complementary to a reactive group Q2. Consequently, D may be attached to the linker via a connecting group Z.
The term "connecting group" herein refers to the structural element connecting one part of a compound and another part of the same compound. As will be understood by the person skilled in the art, the nature of a connecting group depends on the type of organic reaction with which the connection between the parts of said compound was obtained. As an example, when the carboxyl group of R-C(0)-OH is reacted with the amino group of H2N-R' to form R-C(0)-N(H)-R', R is connected to R' via connecting group Z, and Z may be represented by the group -C(0)-N(H)-. Reactive group Q may be attached to the linker in a similar manner. Consequently, Q may be attached to the spacer-moiety via a connecting group Z.
Numerous reactions are known in the art for the attachment of a target molecule to a linker, and for the attachment of a reactive group Q to a linker. Consequently, a wide variety of connecting groups Z may be present in the linker-conjugate.
In one embodiment, the linker-conjugate is a compound according to the formula:
wherein:
- y' is an integer in the range of 1 to 10;
- z is an integer in the range of 1 to 10;
- Q is a reactive group capable of reacting with a functional group F present on a biomolecule;
- D is a target molecule;
- Sp is a spacer moiety, wherein a spacer moiety is defined as a moiety that spaces (i.e. provides a certain distance between) and covalently links Q and D;
- Zw is a connecting group connecting Q to said spacer moiety;
- Zx is a connecting group connecting D to said spacer moiety; and
wherein said spacer moiety is linker L, and thus comprises a group according to formula (1) or a salt thereof, wherein the group according to formula (1) is as defined above.
In a preferred embodiment, a in the group according to formula (1) is 0. In another preferred embodiment, a in the group according to formula (1) is 1 .
Preferred embodiments for y' and z are as defined above for (Q )ySp(D)z. It is further preferred that the compound is according to the formula Q (Zw)Sp(Zx)(D)4, Q (Zw)Sp(Zx)(D)3, Q (Zw)Sp(Zx)(D)2 or Q (Zw)Sp(Zx)D, more preferably Q (Zw)Sp(Zx)(D)2 or Q (Zw)Sp(Zx)D and most preferably Q (Zw)Sp(Zx)D, wherein Zw and Zx are as defined above.
Preferably, Zw and Zx are independently selected from the group consisting of -0-, -S-, -NR2-, -N=N-, -C(O)-, -C(0)NR2-, -OC(O)-, -OC(0)0-, -OC(0)NR2, -NR2C(0)-, -NR2C(0)0-,
-NR2C(0)NR2-, -SC(O)-, -SC(0)0-, -SC(0)NR2-, -S(O)-, -S(0)2-, -OS(0)2-, -OS(0)20-, -OS(0)2NR2-, -OS(O)-, -OS(0)0-, -OS(0)NR2-, -ONR2C(0)-, -ONR2C(0)0-, -ONR2C(0)NR2-, -NR2OC(0)-, -NR2OC(0)0-, -NR2OC(0)NR2-, -ONR2C(S)-, -ONR2C(S)0-, -ONR2C(S)NR2-, -NR2OC(S)-, -NR2OC(S)0-, -NR2OC(S)NR2-, -OC(S)-, -OC(S)0-, -OC(S)NR2-, -NR2C(S)-, -NR2C(S)0-, -NR2C(S)NR2-, -SS(0)2-, -SS(0)20-, -SS(0)2NR2-, -NR2OS(0)-, -NR2OS(0)0-, -NR2OS(0)NR2-, -NR2OS(0)2-, -NR2OS(0)20-, -NR2OS(0)2NR2-, -ONR2S(0)-, -ONR2S(0)0-, -ONR2S(0)NR2-, -ONR2S(0)20-, -ONR2S(0)2NR2-, -ONR2S(0)2-, -OP(0)(R2)2-, -SP(0)(R2)2-, -NR2P(0)(R2)2- and combinations of two or more thereof, wherein R2 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyi groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyi groups being optionally substituted.
Preferred embodiments for D and Q are as defined above.
In one embodiment, the linker-conjugate is compound according to formula (4a) or (4b), or a salt thereof:

- a is independently 0 or 1 ;
- b is independently 0 or 1 ;
- c is 0 or 1 ;
- d is 0 or 1 ;
- e is 0 or 1 ;
- f is an integer in the range of 1 to 150;
- g is 0 or 1 ;
- i is 0 or 1 ;
- D is a target molecule;
- Q is a reactive group capable of reacting with a functional group F present on a biomolecule;
- Sp is a spacer moiety;
- Sp2 is a spacer moiety;
- Sp3 is a spacer moiety;
- Sp4 is a spacer moiety;
- Z is a connecting group that connects Q or Sp3 to Sp2, O or C(O) or N(R1);
- Z2 is a connecting group that connects D or Sp4 to Sp1 , N(R1), O or C(O); and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3- C24 cycloalkyl groups, Ci - C24 (hetero)aryl groups, Ci - C24 alkyl(hetero)aryl groups and Ci - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or
- R is D, -[(Sp )b(Z2)e(Sp4)iD] or -[(Sp2)c(Z )d(Sp3)gQ1], wherein D is a further target molecule and Sp1 , Sp2, Sp3, Sp4, Z , Z2, Q , b, c, d, e, g and i are as defined above.
In a preferred embodiment, a is 1 in the compound according to formula (4a) or (4b). In another preferred embodiment, a is 0 in the compound according to formula (4a) or (4b).
As defined above, Z is a connecting group that connects Q or Sp3 to Sp2, O or C(O) or N(R1), and Z2 is a connecting group that connects D or Sp4 to Sp1 , N(R1), O or C(O). As described in more detail above, the term "connecting group" refers to a structural element connecting one part of a compound and another part of the same compound.
In a compound according to formula (4a), connecting group Z , when present (i.e. when d is 1 ), connects Q (optionally via a spacer moiety Sp3) to the O-atom or the C(O) group of the compound according to formula (4a), optionally via a spacer moiety Sp2. More particularly, when Z is present (i.e. d is 1 ), and when Sp3 and Sp2 are absent (i.e. g is 0 and c is 0), Z connects Q to the O-atom (a is 1 ) or to the C(O) group (a is 0) of the linker-conjugate according to formula (4a). When Z is present (i.e. when d is 1 ), Sp3 is present (i.e. g is 1 ) and Sp2 is absent (i.e. c is 0), Z connects spacer moiety Sp3 to the O-atom (a is 1 ) or to the C(O) group (a is 0) of the linker- conjugate according to formula (4a). When Z is present (i.e. d is 1 ), and when Sp3 and Sp2 are present (i.e. g is 1 and c is 1 ), Z connects spacer moiety Sp3 to spacer moiety Sp2 of the linker- conjugate according to formula (4a). When Z is present (i.e. when d is 1 ), Sp3 is absent (i.e. g is 0) and Sp2 is present (i.e. c is 1 ), Z connects Q to spacer moiety Sp2 of the linker-conjugate according to formula (4a).
In a compound according to formula (4b), connecting group Z , when present (i.e. when d is 1 ), connects Q (optionally via a spacer moiety Sp3) to the N-atom of the N(R1) group in the linker- conjugate according to formula (4b), optionally via a spacer moiety Sp2. More particularly, when Z is present (i.e. d is 1 ), and when Sp3 and Sp2 are absent (i.e. g is 0 and c is 0), Z connects Q to the N-atom of the N(R1) group of the linker-conjugate according to formula (4b). When Z is present (i.e. when d is 1 ), Sp3 is present (i.e. g is 1 ) and Sp2 is absent (i.e. c is 0), Z connects spacer moiety Sp3 to the N-atom of the N(R1) group of the linker-conjugate according to formula
(4b). When Z is present (i.e. d is 1 ), and when Sp3 and Sp2 are present (i.e. g is 1 and c is 1 ), Z connects spacer moiety Sp3 to spacer moiety Sp2 of the linker-conjugate according to formula (4b). When Z is present (i.e. when d is 1 ), Sp3 is absent (i.e. g is 0) and Sp2 is present (i.e. c is 1 ), Z connects Q to spacer moiety Sp2 of the linker-conjugate according to formula (4b).
In the compound according to formula (4a), when c, d and g are all 0, then Q is attached directly to the O-atom (when a is 1 ) or to the C(O) group (when a is 0) of the linker-conjugate according to formula (4a).
In the compound according to formula (4b), when c, d and g are all 0, then Q is attached directly to the N-atom of the N(R1) group of the linker-conjugate according to formula (4b).
In a compound according to formula (4a), connecting group Z2, when present (i.e. when e is 1 ), connects D (optionally via a spacer moiety Sp4) to the N-atom of the N(R1) group in the linker- conjugate according to formula (4a), optionally via a spacer moiety Sp1. More particularly, when Z2 is present (i.e. e is 1 ), and when Sp1 and Sp4 are absent (i.e. b is 0 and i is 0), Z2 connects D to the N-atom of the N(R1) group of the linker-conjugate according to formula (4a). When Z2 is present (i.e. when e is 1 ), Sp4 is present (i.e. i is 1 ) and Sp1 is absent (i.e. b is 0), Z2 connects spacer moiety Sp4 to the N-atom of the N(R1) group of the linker-conjugate according to formula (4a). When Z2 is present (i.e. e is 1 ), and when Sp1 and Sp4 are present (i.e. b is 1 and i is 1 ), Z2 connects spacer moiety Sp1 to spacer moiety Sp4 of the linker-conjugate according to formula (4a). When Z2 is present (i.e. when e is 1 ), Sp4 is absent (i.e. i is 0) and Sp1 is present (i.e. b is 1 ), Z2 connects D to spacer moiety Sp1 of the linker-conjugate according to formula (4a).
In the compound according to formula (4a), when b, e and i are all 0, then D is attached directly to N-atom of the N(R1) group of the linker-conjugate according to formula (4a).
In the compound according to formula (4b), when b, e and i are all 0, then D is attached directly to the O-atom (when a is 1 ) or to the C(O) group (when a is 0) of the linker-conjugate according to formula (4b).
As will be understood by the person skilled in the art, the nature of a connecting group depends on the type of organic reaction with which the connection between the specific parts of said compound was obtained. A large number of organic reactions are available for connecting a reactive group Q to a spacer moiety, and for connecting a target molecule to a spacer-moiety. Consequently, there is a large variety of connecting groups Z and Z2.
In a preferred embodiment of the linker-conjugate according to formula (4a) and (4b), Z and Z2 are independently selected from the group consisting of -0-, -S-, -SS-, -NR2-, -N=N-, -C(O)-, -C(0)NR2-, -OC(O)-, -OC(0)0-, -OC(0)NR2, -NR2C(0)-, -NR2C(0)0-, -NR2C(0)NR2-, -SC(O)-, -SC(0)0-, -S-C(0)NR2-, -S(O)-, -S(0)2-, -OS(0)2-, -OS(0)20-, -OS(0)2NR2-, -OS(O)-, -OS(0)0-, -OS(0)NR2-, -ONR2C(0)-, -ONR2C(0)0-, -ONR2C(0)NR2-, -NR2OC(0)-, -NR2OC(0)0-, -NR2OC(0)NR2-, -ONR2C(S)-, -ONR2C(S)0-, -ONR2C(S)NR2-, -NR2OC(S)-, -NR2OC(S)0-, -NR2OC(S)NR2-, -OC(S)-, -OC(S)0-, -OC(S)NR2-, -NR2C(S)-, -NR2C(S)0-, -NR2C(S)NR2-, -SS(0)2-, -SS(0)20-, -SS(0)2NR2-, -NR2OS(0)-, -NR2OS(0)0-, -NR2OS(0)NR2-, -NR2OS(0)2-, -NR2OS(0)20-, -NR2OS(0)2NR2-, -ONR2S(0)-, -ONR2S(0)0-, -ONR2S(0)NR2-, -ONR2S(0)20-, -ONR2S(0)2NR2-, -ONR2S(0)2-, -OP(0)(R2)2-, -SP(0)(R2)2-, -NR2P(0)(R2)2- and combinations of
two or more thereof, wherein R2 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
As described above, in the compound according to formula (4a) or (4b), Sp\ Sp2, Sp3 and Sp4 are spacer-moieties. Sp1 , Sp2, Sp3 and Sp4 may be, independently, absent or present (b, c, g and i are, independently, 0 or 1 ). Sp1, if present, may be different from Sp2, if present, from Sp3 and/or from Sp4, if present.
Spacer-moieties are known to a person skilled in the art. Examples of suitable spacer-moieties include (poly)ethylene glycol diamines (e.g. 1 ,8-diamino-3,6-dioxaoctane or equivalents comprising longer ethylene glycol chains), polyethylene glycol chains or polyethylene oxide chains, polypropylene glycol chains or polypropylene oxide chains and 1 ,xx-diaminoalkanes wherein xx is the number of carbon atoms in the alkane.
Another class of suitable spacer-moieties comprises cleavable spacer-moieties, or cleavable linkers. Cleavable linkers are well known in the art. For example Shabat ef a/. , Soft Matter 2012, 6, 1073, incorporated by reference herein, discloses cleavable linkers comprising self-immolative moieties that are released upon a biological trigger, e.g. an enzymatic cleavage or an oxidation event. Some examples of suitable cleavable linkers are disulphide-linkers that are cleaved upon reduction, peptide-linkers that are cleaved upon specific recognition by a protease, e.g. cathepsin, plasmin or metalloproteases, or glycoside-based linkers that are cleaved upon specific recognition by a glycosidase, e.g. glucoronidase, or nitroaromatics that are reduced in oxygen-poor, hypoxic areas. Herein, suitable cleavable spacer-moieties also include spacer moieties comprising a specific, cleavable, sequence of amino acids. Examples include e.g. spacer-moieties comprising a Val-Ala (valine-alanine) or Val-Cit (valine-citrulline) moiety.
In a preferred embodiment of the linker-conjugate according to formula (4a) and (4b), spacer moieties Sp1 , Sp2, Sp3 and/or Sp4, if present, comprise a sequence of amino acids. Spacer- moieties comprising a sequence of amino acids are known in the art, and may also be referred to as peptide linkers. Examples include spacer-moieties comprising a Val-Cit moiety, e.g. Val-Cit- PABC, Val-Cit-PAB, Fmoc-Val-Cit-PAB, etc. Preferably, a Val-Cit-PABC moiety is employed in the linker-conjugate.
In a preferred embodiment of the linker-conjugate according to formula (4a) and (4b), spacer moieties Sp1 , Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cycloalkylene groups, C5-C200 cycloalkenylene groups, C8-C200 cycloalkynylene groups,
C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups and C9-C200 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted
and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted. When the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are interrupted by one or more heteroatoms as defined above, it is preferred that said groups are interrupted by one or more O-atoms, and/or by one or more S-S groups.
More preferably, spacer moieties Sp\ Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C100 alkylene groups, C2-C100 alkenylene groups,
C2-C100 alkynylene groups, C3-C100 cycloalkylene groups, C5-C100 cycloalkenylene groups, Cs-doo cycloalkynylene groups, C7-C100 alkylarylene groups, C7-C100 arylalkylene groups, Cs-doo arylalkenylene groups and C9-C100 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
Even more preferably, spacer moieties Sp1, Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C50 alkylene groups, C2-C50 alkenylene groups, C2-C50 alkynylene groups, C3-C50 cycloalkylene groups, C5-C50 cycloalkenylene groups, Cs-Cso cycloalkynylene groups, C7-C50 alkylarylene groups, C7-C50 arylalkylene groups, Cs-Cso arylalkenylene groups and C9-C50 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
Yet even more preferably, spacer moieties Sp1, Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, C2-C20 alkenylene groups, C2-C20 alkynylene groups, C3-C20 cycloalkylene groups, C5-C20 cycloalkenylene groups, C8-C20 cycloalkynylene groups, C7-C20 alkylarylene groups, C7-C20 arylalkylene groups, C8-C20 arylalkenylene groups and C9-C20 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups,
cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
In these preferred embodiments it is further preferred that the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, preferably O, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
Most preferably, spacer moieties Sp\ Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted. In this embodiment, it is further preferred that the alkylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, preferably O and/or S, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
Preferred spacer moieties Sp1 , Sp2, Sp3 and Sp4 thus include -(CH2)n-, -(CH2CH2)n-, -(CH2CH20)n-, -(OCH2CH2)n-, -(CH2CH20)nCH2CH2-, -CH2CH2(OCH2CH2)n-, -(CH2CH2CH20)n-, -(OCH2CH2CH2)n-, -(CH2CH2CH20)nCH2CH2CH2- and -CH2CH2CH2(OCH2CH2CH2)n-, wherein n is an integer in the range of 1 to 50, preferably in the range of 1 to 40, more preferably in the range of 1 to 30, even more preferably in the range of 1 to 20 and yet even more preferably in the range of 1 to 15. More preferably n is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10, more preferably 1 , 2, 3, 4, 5, 6, 7 or 8, even more preferably 1 , 2, 3, 4, 5 or 6, yet even more preferably 1 , 2, 3 or 4.
Since Sp1 , Sp2, Sp3 and Sp4 are independently selected, Sp1 , if present, may be different from Sp2, if present, from Sp3 and/or from Sp4, if present.
Reactive groups Q are described in more detail above. In the linker-conjugate according to formula (4a) and (4b), it is preferred that reactive group Q is selected from the group consisting of, optionally substituted, N-maleimidyl groups, halogenated N-alkylamido groups, sulfonyloxy N- alkylamido groups, ester groups, carbonate groups, sulfonyl halide groups, thiol groups or derivatives thereof, alkenyl groups, alkynyl groups, (hetero)cycloalkynyl groups, bicyclo[6.1.0]non- 4-yn-9-yl] groups, cycloalkenyl groups, tetrazinyl groups, azido groups, phosphine groups, nitrile oxide groups, nitrone groups, nitrile imine groups, diazo groups, ketone groups, (O- alkyl)hydroxylamino groups, hydrazine groups, halogenated N-maleimidyl groups, carbonyl halide
groups, allenamide groups and 1 , 1-bis(sulfonylmethyl)methylcarbonyl groups or elimination derivatives thereof. In a further preferred embodiment, Q is according to formula (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj) or (9zk), wherein (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj), (9zk), (9zo) and preferred embodiments thereof, are as defined above. In a preferred embodiment, Q is according to formula (9a), (9b), (9c), (9f), (9j), (9n), (9o), (9p), (9q), (9s), (9t), (9zh), (9zo) or (9r). In an even further preferred embodiment, Q is according to formula (9a), (9j), (9n), (9o), (9q), (9p), (9t), (9zh), (9zo) or (9s), and in a particularly preferred embodiment, Q is according to formula (9a), (9q), (9n), (9o), (9p), (9t), (9zo) or (9zh), and preferred embodiments thereof, as defined above.
Target molecule D and preferred embodiments for target molecule D in the linker-conjugate according to formula (4a) and (4b) are as defined above.
As described above, R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is D, -[(Sp )b(Z2)e(Sp4)iD] or -[(Sp2)c(Z )d(Sp3)gQ1], wherein D is a further target molecule and Sp\ Sp2, Sp3, Sp4, Z , Z2, Q , b, c, d, e, g and i are as defined above.
In a preferred embodiment, R is hydrogen or a Ci - C20 alkyl group, more preferably R is hydrogen or a Ci - C16 alkyl group, even more preferably R is hydrogen or a Ci - C10 alkyl group, wherein the alkyl group is optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3, preferably O, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups. In a further preferred embodiment, R is hydrogen. In another further preferred embodiment, R is a Ci - C20 alkyl group, more preferably a Ci - C16 alkyl group, even more preferably a Ci - C10 alkyl group, wherein the alkyl group is optionally interrupted by one or more O-atoms, and wherein the alkyl group is optionally substituted with an -OH group, preferably a terminal -OH group. In this embodiment it is further preferred that R is a polyethyleneglycol chain comprising a terminal -OH group. In another further preferred embodiment, R is a Ci - C12 alkyl group, more preferably a Ci - C6 alkyl group, even more preferably a Ci - C4 alkyl group, and yet even more preferably R is selected from the group consisting of methyl, ethyl, n-propyl, i-propyl, n-butyl, s-butyl and t-butyl. In another preferred embodiment, R is a further target molecule D, -[(Sp )b(Z2)e(Sp4)iD] or -[(Sp2)c(Z )d(Sp3)gQ1], wherein D is a target molecule and Sp1 , Sp2, Sp3, Sp4, Z\ Z2, Q\ b, c, d, e,
g and i are as defined above. When R is D or -[(Sp )b(Z2)e(Sp4)iD], it is further preferred that the linker-conjugate is according to formula (4a). In this embodiment, linker-conjugate (4a) comprises two target molecules D, which may be the same or different. When R is -[(Sp )b(Z2)e(Sp4)iD], Sp\ b, Z2, e, Sp4, i and D in -[(Sp )b(Z2)e(Sp4)iD] may be the same or different from Sp\ b, Z2, e, Sp4, i and D in -[(Sp )b(Z2)e(Sp4)iD] that is attached to the N-atom of N(R1 ). In a preferred embodiment, both -[(Sp )b(Z2)e(Sp4)iD] and -[(Sp )b(Z2)e(Sp4)iD] on the N-atom of N(R1 ) are the same.
When R is -[(Sp2)c(Z )d(Sp3)gQ1] , it is further preferred that the linker-conjugate is according to formula (4b). In this embodiment, linker-conjugate (4b) comprises two target molecules Q , which may be the same or different. When R is -[(Sp2)c(Z )d(Sp3)gQ1] , Sp2, c, Z\ d, Sp3, g and D in -[(Sp )b(Z2)e(Sp4)iD] may be the same or different from Sp1 , b, Z2, e, Sp4, i and Q in the other -[(Sp2)c(Z )d(Sp3)gQ1] that is attached to the N-atom of N(R1 ). In a preferred embodiment, -[(Sp2)c(Z )d(Sp3)gQ1] groups on the N-atom of N(R1 ) are the same.
In the linker-conjugate according to formula (4a) and (4b), f is an integer in the range of 1 to 150. The linker-conjugate may thus comprise more than one group according to formula (1 ), the group according to formula (1 ) being as defined above. When more than one group according to formula (1 ) is present, i.e. when f is 2 or more, then a, b, Sp1 and R are independently selected. In other words, when f is 2 or more, each a is independently 0 or 1 , each b is independently 0 or 1 , each Sp1 may be the same or different and each R may be the same or different. In a preferred embodiment, f is an integer in the range of 1 to 100, preferably in the range of 1 to 50, more preferably in the range of 1 to 25, and even more preferably in the range of 1 to 15. More preferably, f is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10, even more preferably f is 1 , 2, 3, 4, 5, 6, 7 or 8, yet even more preferably f is 1 , 2, 3, 4, 5 or 6, yet even more preferably f is 1 , 2, 3 or 4, and most preferably f is 1 in this embodiment. In another preferred embodiment, f is an integer in the range of 2 to 150, preferably in the range of 2 to 100, more preferably in the range of 2 to 50, more preferably in the range of 2 to 25, and even more preferably in the range of 2 to 15. More preferably, f is 2, 3, 4, 5, 6, 7, 8, 9 or 10, even more preferably f is 2, 3, 4, 5, 6, 7 or 8, yet even more preferably f is 2, 3, 4, 5 or 6, yet even more preferably f is 2, 3 or 4, and most preferably f is 2 in this embodiment.
As described above, in a preferred embodiment, a is 0 in the compound according to formula (4a) or (4b). The linker-conjugate may therefore also be a compound according to formula (6a) or (6b), or a salt thereof:


6b
wherein a, b, c, d, e, f, g, i, D, Q\ Sp\ Sp2, Sp3, Sp4, Z , Z2 and R\ and their preferred embodiments, are as defined above for (4a) and (4b).
As described above, in another preferred embodiment, a is 1 in the compound according to formula (4a) or (4b). The linker-conjugate may therefore also be a compound according to formula (7a) or

wherein a, b, c, d, e, f, g, i, D, Q , Sp1 , Sp2, Sp3, Sp4, Z , Z2 and R , and their preferred embodiments, are as defined above for (4a) and (4b).
When Sp4 is absent in the linker-conjugate according to formula (4a), i.e. when i is 0, D is linked to Z2 (when e is 1 ), to Sp1 (when e is 0 and b is 1 ) or to N(R1) (when e is 0 and b is 0). When Sp4 is absent in the linker-conjugate according to formula (4b), i.e. when i is 0, D is linked to Z2 (when e is 1 ), to Sp1 (when e is 0 and b is 1 ), to the O-atom (when a is 1 and b and e are 0) or to the C(O) group (when a is 0 and b and e are 0). The linker-conjugate therefore also may be a compound

4c

4d
wherein a, b, c, d, e, f, g, D, Q , Sp1 , Sp2, Sp3, Z , Z2 and R , and their preferred embodiments, are as defined above for (4a) and (4b). In a preferred embodiment, in the linker-conjugate according to formula (4c) or (4d), a is 0. In another preferred embodiment, in the linker-conjugate according to formula (4c) or (4d), a is 1.
In a specific embodiment of the linker-conjugate, particularly a linker-conjugate according to formula (4a), (4b), (4c), (4d), (6a), (6b), (7a) or (7b), Sp1 , Sp2 Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group consisting of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, and Q is according to formula (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg) (9zh), (9zi), (9zj) or (9zk), wherein (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj), (9zk), (9zo) and preferred embodiments thereof, are as defined above. In a preferred embodiment, Q is according to formula (9a), (9b), (9c), (9f), (9j), (9n), (9o), (9p), (9q), (9s) (9t), (9zh), (9zo) or (9r). In an even further preferred embodiment, Q is according to formula (9a), (9j), (9n), (9o), (9p), (9q), (9t), (9zh), (9zo) or (9s), and in a particularly preferred embodiment, Q is according to formula (9a), (9q), (9n), (9p), (9t), (9zh), (9zo) or (9o), and preferred embodiments thereof, as defined above.
Linker L, as preferably comprised in the linker-conjugate according to formula (4a), (4b), (4c), (4d), (6a), (6b), (7a) or (7b) as defined above, linker as defined above may be represented by formula (8a) and (8b), respectively:


As will be understood by the person skilled in the art, preferred embodiments of spacer-moieties (8a) and (8b) may depend on e.g. the nature of reactive groups Q and D in the linker-conjugate, the synthetic method to prepare the linker-conjugate (e.g. the nature of complementary functional group F2 on a target molecule), the nature of a bioconjugate that is prepared using the linker- conjugate (e.g. the nature of complementary functional group F on the biomolecule).
When Q is for example a cyclooctynyl group according to formula (9n), (9o), (9p), (9q) or (9zk) as defined above, then preferably Sp3 is present (g is 1 ).
When for example the linker-conjugate was prepared via reaction of a reactive group Q2 that is a cyclooctynyl group according to formula (9n), (9o), (9p), (9q) or (9zk) with an azido functional group F2, then preferably Sp4 is present (i is 1 ).
Furthermore, it is preferred that at least one of Sp1 , Sp2, Sp3 and Sp4 is present, i.e. at least one of b, c, g, and i is not 0. In another preferred embodiment, at least one of Sp1 and Sp4 and at least one of Sp2 and Sp3 are present.
When f is 2 or more, it is preferred that Sp1 is present (b is 1 ).
These preferred embodiments of the linker-moiety (8a) and (8b) also hold for the linker-conjugate when comprised in the bioconjugates according to the invention as described in more detail below.
Preferred embodiments of Sp1 , Sp2, Sp3 and Sp4 are as defined above.
Biomolecule
The biomolecule is represented by B-F , wherein B is a biomolecule and F is a functional group capable of reacting with reactive group Q on the linker-conjugate and "-" is a bond or a spacer moiety. Alternatively, the biomolecule is a modified antibody represented by formula (24), wherein F is a functional group capable of reacting with reactive group Q on the linker-conjugate. The modified antibody represented by formula (24) and preferred embodiments thereof are defined in detail above.
In one embodiment, "-" is a spacer moiety as defined herein. In one embodiment, "-" is a bond, typically a covalent bond. The biomolecule may also be referred to as "biomolecule of interest" (BOI). The biomolecule may be a biomolecule as naturally occurring, wherein functional group F is a already present in the biomolecule of interest, such as for example a thiol, an amine, an alcohol or a hydroxyphenol unit. Conjugation with the linker-conjugate then occurs via the first approach as defined above. Alternatively, the biomolecule may be a modified biomolecule, wherein functional group F is specifically incorporated into the biomolecule of interest and conjugation with the linker-conjugate occurs via this engineered functionality, i.e. the two-stage
approach of bioconjugation as defined above. Such modification of biomolecules to incorporate a specific functionality is known, e.g. from WO 2014/065661 , incorporated herein by reference in its entirety.
In the bioconjugate according to the invention, biomolecule B is preferably selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, lipids, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides, enzymes, hormones, amino acids and monosaccharides. More preferably, biomolecule B is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides and enzymes. More preferably, biomolecule B is selected from the group consisting of proteins, including glycoproteins and antibodies, polypeptides, peptides and glycans. Most preferably, biomolecule B is an antibody or an antigen-binding fragment thereof.
Functional group F is capable of reacting with reactive group Q on the linker-conjugate to form a connecting group Z3. To a skilled person, it is clear which functional group F is capable of reacting with a complementary reactive group Q . Functional groups F that are complementary to reactive groups Q , as defined above, and known to a person skilled in the art, are described in more detail below. Some representative examples of reaction between F and Q and their corresponding products comprising connecting group Z3 are depicted in Figure 5.
In the process for the preparation of a bioconjugate according to the invention, a reactive group Q that is present in the linker-conjugate is typically reacted with functional group F . More than one functional group F may be present in the biomolecule. When two or more functional groups are present, said groups may be the same or different. In another preferred embodiment, the biomolecule comprises two or more functional groups F, which may be the same or different, and two or more functional groups react with a complementary reactive group Q of a linker-conjugate. For example a biomolecule comprising two functional groups F, i.e. F and F2, may react with two linker-conjugates comprising a functional group Q , which may be the same or different, to form a bioconjugate.
Examples of a functional group F in a biomolecule comprise an amino group, a thiol group, a carboxylic acid, an alcohol group, a carbonyl group, a phosphate group, or an aromatic group. The functional group in the biomolecule may be naturally present or may be placed in the biomolecule by a specific technique, for example a (bio)chemical or a genetic technique. The functional group that is placed in the biomolecule may be a functional group that is naturally present in nature, or may be a functional group that is prepared by chemical synthesis, for example an azide, a terminal alkyne, a cyclopropene moiety or a phosphine moiety. In view of the preferred mode of conjugation by cycloaddition, it is preferred that F is group capable of reacting in a cycloaddition, such as a diene, a dienophile, a 1 ,3-dipole or a dipolarophile, preferably F is selected from a 1 ,3-dipole (typically an azido group, nitrone group, nitrile oxide group, nitrile imine group or diazo group) or a dipolarophile (typically an alkenyl or alkynyl group). Herein, F is a 1 ,3- dipole when Q is a dipolarophile and F is a dipolarophile when Q is a 1 ,3-dipole, or F is a diene when Q is a dienophile and F is a dienophile when Q is a diene. Most preferably, F is a 1 ,3-
dipole, preferably F is or comprises an azido group.
Several examples of a functional group that is placed into a biomolecule are shown in Figure 2. Figure 2 shows several structures of derivatives of UDP sugars of galactosamine, which may be modified with e.g. a thiopropionyl group (11a), an azidoacetyl group (11 b), or an azidodifluoroacetyl group (11c) at the 2-position, or with an azido group at the 6-position of N- acetyl galactosamine (11d). In one embodiment, functional group F is a thiopropionyl group, an azidoacetyl group, or an azidodifluoroacetyl group.
Figure 3 schematically displays how any of the UDP-sugars 11a-d may be attached to a glycoprotein comprising a GlcNAc moiety 12 (e.g. a monoclonal antibody the glycan of which is trimmed by an endoglycosidase) under the action of a galactosyltransferase mutant or a GalNAc- transferase, thereby generating a β-glycosidic 1-4 linkage between a GalNAc derivative and GlcNAc (compounds 13a-d, respectively).
Preferred examples of naturally present functional groups F include a thiol group and an amino group. Preferred examples of a functional group that is prepared by chemical synthesis for incorporation into the biomolecule include a ketone group, a terminal alkyne group, an azide group, a cyclo(hetero)alkyne group, a cyclopropene group, or a tetrazine group.
As was described above, complementary reactive groups Q and functional groups F are known to a person skilled in the art, and several suitable combinations of Q and F are described above, and shown in Figure 5. A list of complementary groups Q and F is disclosed in in Table 3.1 , pages 230 - 232 of Chapter 3 of G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed.
2013 (ISBN :978-0-12-382239-0), and the content of this Table is expressly incorporated by reference herein. Bioconiugate
A bioconjugate is herein defined as a compound wherein a biomolecule is covalently connected to a target molecule D via a linker. A bioconjugate comprises one or more biomolecules and/or one or more target molecules. The linker may comprise one or more spacer moieties. The bioconjugate according to the invention is conveniently prepared by the process for preparation of a bioconjugate according to the invention, wherein the linker-conjugate comprising reactive group Q is conjugated to a biomolecule comprising functional group F . In this conjugation reaction, groups Q and F react with each other to form a connecting group Z3 which connects the target molecule D with the biomolecule B. All preferred embodiments described herein for the linker- conjugate and the biomolecule thus equally apply to the bioconjugate according to the invention, except for all said for Q and F , wherein the bioconjugate according to the invention contains the reaction product of Q and F , i.e. connecting group Z3. In one aspect, the invention also concerns the bioconjugates, preferably the antibody-conjugates, described herein.
The bioconjugate according to the invention has formula (A):
B-L-D
(A),
wherein:
- B is a biomolecule, preferably an antibody AB;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety.
In a first preferred embodiment, the bioconjugate is obtainable by the mode of conjugation defined as "core-GlcNAc functionalization", i.e. by steps (i) and (ii) as defined above. In a second preferred embodiment, the bioconjugate according to formula (A) has a linker L comprising a group according to formula (1 ) or a salt thereof:

1
wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or R is a target molecule D, wherein D is optionally connected to N via a spacer moiety.
In one embodiment, "-" is a spacer moiety as defined herein. In one embodiment, "-" is a bond, typically a covalent bond.
In a preferred embodiment, the bioconjugate is presented by B-Z3-L-D, wherein B, L, D and "-" are as defined above and Z3 is a connecting group which is obtainable by reaction of Q with F . Preferably, moiety Z3 is obtainable by a cycloaddition, preferably a 1 ,3-dipolar cycloaddition reaction, most preferably Z3 is a 1 ,2,3-triazole ring, which is located in a spacer moiety, preferably the spacer moiety between B and L, most preferably between B and the carbonyl or carboxyl end of the group according to formula (1 ). When the bioconjugate according to the invention comprises a salt of the group according to formula (1 ), the salt is preferably a pharmaceutically acceptable salt.
The bioconjugate according to the invention may comprise more than one target molecule. Similarly, the bioconjugate may comprise more than one biomolecule. Biomolecule B and target molecule D, and preferred embodiments thereof, are described in more detail above. Preferred
embodiments for D in the bioconjugate according to the invention correspond to preferred embodiments of D in the linker-conjugate according to the invention as were described in more detail above. Preferred embodiments for the linker (8a) or (8b) in the bioconjugate according to the invention correspond to preferred embodiments of the linker in the linker-conjugate, as were described in more detail above. Preferred embodiments for B in the bioconjugate according to the invention correspond to preferred embodiments of B in the biomolecule according to the invention as were described in more detail above.
The bioconjugate according to the invention may also be defined as a bioconjugate wherein a biomolecule is conjugated to a target molecule via a spacer-moiety, wherein the spacer-moiety comprises a group according to formula (1 ), or a salt thereof, wherein the group according to formula (1 ) is as defined above.
The bioconjugate according to the invention may also be denoted as (B)y Sp(D)z, wherein y' is an integer in the range of 1 to 10 and z is an integer in the range of 1 to 10.
The invention thus also relates to a bioconjugate according to the formula:
wherein:
- y' is an integer in the range of 1 to 10;
- z is an integer in the range of 1 to 10;
- B is a biomolecule;
- D is a target molecule;
- Sp is a spacer moiety, wherein a spacer moiety is defined as a moiety that spaces (i.e. provides a certain distance between) and covalently links biomolecule B and target molecule D; and wherein said spacer moiety comprises a group according to formula (1 ) or a salt thereof, wherein the group according to formula (1 ) is as defined above.
In a preferred embodiment, said spacer moiety further comprises a moiety that is obtainable by a cycloaddition, preferably a 1 ,3-dipolar cycloaddition reaction, most preferably a 1 ,2,3-triazole ring, which is located between B and said group according to formula (1 ).
Preferably, y' is 1 , 2, 3 or 4, more preferably y' is 1 or 2 and most preferably, y' is 1. Preferably, z is 1 , 2, 3, 4, 5 or 6, more preferably z is 1 , 2, 3 or 4, even more preferably z is 1 , 2 or 3, yet even more preferably z is 1 or 2 and most preferably z is 1. More preferably, y' is 1 or 2, preferably 1 , and z is 1 , 2, 3 or 4, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 , 2 or 3, yet even more preferably y' is 1 or 2, preferably 1 , and z is 1 or 2, and most preferably y' is 1 and z is 1. In a preferred embodiment, the bioconjugate is according to the formula BSp(D)4, BSp(D)3, BSp(D)2 or BSpD. In another preferred embodiment, the bioconjugate is according to the formula BSp(D)e, BSp(D)4 or BSp(D)2, more preferably BSp(D)4 or BSp(D)2.
As described above, the bioconjugate according to the invention comprises a group according to formula (1 ) as defined above, or a salt thereof. In a preferred embodiment, the bioconjugate comprises a group according to formula (1 ) wherein a is 0, or a salt thereof. In this embodiment,
the bioconjugate thus comprises a group according to formula (2) or a salt thereof, wherein (2) is as defined above.
In another preferred embodiment, the bioconjugate comprises a group according to formula (1 ) wherein a is 1 , or a salt thereof. In this embodiment, the bioconjugate thus comprises a group according to formula (3) or a salt thereof, wherein (3) is as defined above.
In the bioconjugate according to the invention, R , spacer moiety Sp, as well as preferred embodiments of R and Sp, are as defined above for the linker-conjugate according to the invention.
In a reof:

5b
wherein a, b, c, d, e, f, g, h, i, D, Sp1 , Sp2, Sp3, Sp4, Z Z2, Z3 and R , and preferred embodiments thereof, are as defined above for linker-conjugate (4a) and (4b); and
- h is 0 or 1 ;
- Z3 is a connecting group that connects B to Sp3, Z Sp2, O or C(O); and
- B is a biomolecule.
Preferably, h is 1.
Preferred embodiments of biomolecule B are as defined above.
When the bioconjugate according to the invention is a salt of (5a) or (5b), the salt is preferably a pharmaceutically acceptable salt.
Z3 is a connecting group. As described above, the term "connecting group" herein refers to the structural element connecting one part of a compound and another part of the same compound. Typically, a bioconjugate is prepared via reaction of a reactive group Q present in the linker- conjugate with a functional group F present in a biomolecule. As will be understood by the person skilled in the art, the nature of connecting group Z3 depends on the type of organic reaction that was used to establish the connection between the biomolecule and the linker- conjugate. In other words, the nature of Z3 depends on the nature of reactive group Q of the linker-conjugate and the nature of functional group F in the biomolecule. Since there is a large number of different chemical reactions available for establishing the connection between a
biomolecule and a linker-conjugate, consequently there is a large number of possibilities for Z3. Several examples of suitable combinations of F and Q , and of connecting group Z3 that will be present in a bioconjugate when a linker-conjugate comprising Q is conjugated to a biomolecule comprising a complementary functional group F , are shown in Figure 5.
When Fls for example a thiol group, complementary groups Q include N-maleimidyl groups and alkenyl groups, and the corresponding connecting groups Z3 are as shown in Figure 5. When F is a thiol group, complementary groups Q also include allenamide groups.
When F is for example an amino group, complementary groups Q include ketone groups and activated ester groups, and the corresponding connecting groups Z3 are as shown in Figure 5. When F is for example a ketone group, complementary groups Q include (O- alkyl)hydroxylamino groups and hydrazine groups, and the corresponding connecting groups Z3 are as shown in Figure 5.
When F is for example an alkynyl group, complementary groups Q include azido groups, and the corresponding connecting group Z3 is as shown in Figure 5.
When F is for example an azido group, complementary groups Q include alkynyl groups, and the corresponding connecting group Z3 is as shown in Figure 5.
When F is for example a cyclopropenyl group, a irans-cyclooctene group or a cyclooctyne group, complementary groups Q include tetrazinyl groups, and the corresponding connecting group Z3 is as shown in Figure 5. In these particular cases, Z3 is only an intermediate structure and will expel N2, thereby generating a dihydropyridazine (from the reaction with alkene) or pyridazine (from the reaction with alkyne).
Additional suitable combinations of F and Q , and the nature of resulting connecting group Z3 are known to a person skilled in the art, and are e.g. described in G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013 (ISBN:978-0-12-382239-0), in particular in Chapter 3, pages 229 - 258, incorporated by reference. A list of complementary reactive groups suitable for bioconjugation processes is disclosed in Table 3.1 , pages 230 - 232 of Chapter 3 of G.T. Hermanson, "Bioconjugate Techniques", Elsevier, 3rd Ed. 2013 (ISBN:978-0-12-382239-0), and the content of this Table is expressly incorporated by reference herein.
In the bioconjugate according to (5a) and (5b), it is preferred that at least one of Z3, Sp3, Z and Sp2 is present, i.e. at least one of h, g, d and c is not 0. It is also preferred that at least one of Sp1, Z2 and Sp4 is present, i.e. that at least one of b, e and i is not 0. More preferably, at least one of Z3, Sp3, Z and Sp2 is present and at least one of Sp1 , Z2 and Sp4 is present, i.e. it is preferred that at least one of b, e and i is not 0 and at least one of h, g, d and c is not 0. Process for the preparation of a bioconjugate
In the various aspects of the present invention, the bioconjugate according to the invention is typically obtained by a process for the preparation of a bioconjugate as defined herein. As the presence of the group according to formula (1 ) or a salt thereof in linker L of the bioconjugate is key in the present invention, any method of preparing the bioconjugate can be used as long as the obtained bioconjugate comprises linker L as defined herein. The group according to formula
(1 ) may be present in linker L between B and Z3, i.e. it originates form the biomolecule, or between Z3 and D, i.e. it originates from the linker-conjugate, or Z3 is or comprises the group according to formula (1 ), i.e. the group according to formula (1 ) is formed upon conjugation. Preferably, the group according to formula (1 ) is present in linker L between B and Z3 or between Z3 and D, most preferably, the group according to formula (1 ) is present in linker L between Z3 and D. Likewise, the exact mode of conjugation, including the nature of Q and F have a great flexibility in the context of the present invention. Many techniques for conjugating BOIs to MOIs are known to a person skilled in the art and can be used in the context of the present invention. In one embodiment, the conjugation method comprises steps (i) and (ii) as defined above.
In one embodiment, the mode of conjugation is selected from any of the conjugation modes depicted in Figure 5, i.e. from thiol-alkene conjugation (preferably cysteine-alkene conjugation, preferably wherein the alkene is a pendant alkene (-C=CH2) or a maleimide moiety, most preferably a maleimide moiety) to from a connecting moiety Z3 that may be represented as (10a) or (10b), amino-(activated) carboxylic acid conjugation (wherein the (activated) carboxylic acid is represented by -C(0)X, wherein X is a leaving group) to from a connecting moiety Z3 that may be represented as (10c), ketone-hydrazino conjugation (preferably acetyl-hydrazino conjugation) to from a connecting moiety Z3 that may be represented as (10d) wherein Y = NH, ketone-oxyamino conjugation (preferably acetyl-oxyamino conjugation) to from a connecting moiety Z3 that may be represented as (10d) wherein Y = O, alkyne-azide conjugation (preferably wherein the alkyne is a pendant alkyne (-C≡CH) or a cyclooctyne moiety, most preferably a cyclooctyne moiety) to from a connecting moiety Z3 that may be represented as (10e), (10f), (10i), (10g), (10j) or (10k), alkene- 1 ,2,4,5-tetrazine conjugation or alkyne-1 ,2,4,5-tetrazine conjugation to from a connecting moiety Z3 that may be represented as (10h) from which N2 will eliminate, giving dihydropyridazine products. Especially preferred conjugation modes are cysteine-alkene conjugation and alkyne- azide conjugation, more preferably cysteine-maleimide conjugation and cyclooctyne-azide conjugation.
The bioconjugate according to the invention is typically prepared by a process comprising the step of reacting a reactive group Q of the linker-conjugate as defined herein with a functional group F of the biomolecule, also referred to as a biomolecule. The linker-conjugate and the biomolecule, and preferred embodiments thereof, are described in more detail above. Such a process is known to a person skilled in the art as conjugation or bioconjugation. Figure 1 shows the general concept of conjugation of biomolecules: a biomolecule of interest (BOI) comprising one or more functional groups F is incubated with (excess of) a target molecule D (also referred to as molecule of interest or MOI), covalently attached to a reactive group Q via a specific linker. In the process of bioconjugation, a chemical reaction between F and Q takes place, thereby forming a bioconjugate comprising a covalent bond between the BOI and the MOI. The BOI may e.g. be a peptide/protein, a glycan or a nucleic acid.
The bioconjugation reaction typically comprises the step of reacting a reactive group Q of the linker-conjugate with a functional group F of a the biomolecule, wherein a bioconjugate of formula (A) is formed, wherein linker L comprises a group according to formula (1 ) or a salt
thereof:

1
wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is a further target molecule D, which is optionally connected to N via a spacer moiety.
In a preferred embodiment, the bioconjugate is prepared via a cycloaddition, such as a (4+2)- cycloaddition (e.g. a Diels-Alder reaction) or a (3+2)-cycloaddition (e.g. a 1 ,3-dipolar cycloaddition). Preferably, the conjugation is a Diels-Alder reaction or a 1 ,3-dipolar cycloaddition. The preferred Diels-Alder reaction is the inverse-electron demand Diels-Alder cycloaddition. In another preferred embodiment, the 1 ,3-dipolar cycloaddition is used, more preferably the alkyne- azide cycloaddition, and most preferably wherein Q is or comprises an alkyne group and F is an azido group. Cycloadditions, such as Diels-Alder reactions and 1 ,3-dipolar cycloadditions are known in the art, and the skilled person knowns how to perform them.
When Q reacts with F , a covalent connection between the biomolecule and the target molecule originating of the linker-conjugate is formed. Complementary reactive groups Q and functional groups F are described in more detail above and below.
In a preferred embodiment of the process for preparing the bioconjugate, a is 0 in the group according to formula (1 ). In this embodiment, the linker-conjugate thus comprises a group according to formula (2), as defined above. In another preferred embodiment of the process for preparing the bioconjugate, a is 1 in the group according to formula (1 ). In this embodiment, the linker-conjugate thus comprises a group according to formula (3), as defined above.
Biomolecules are described in more detail above. Preferably, in the process according to the invention the biomolecule is selected from the group consisting of proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, lipids, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides, enzymes, hormones, amino acids and monosaccharides. More preferably, biomolecule B is selected from the group consisting of
proteins (including glycoproteins and antibodies), polypeptides, peptides, glycans, nucleic acids, oligonucleotides, polysaccharides, oligosaccharides and enzymes. More preferably, biomolecule B is selected from the group consisting of proteins, including glycoproteins and antibodies, polypeptides, peptides and glycans. Most preferably, B is an antibody or an antigen-binding fragment thereof.
In the process for preparing the bioconjugate, it is preferred that reactive group Q is selected from the group consisting of, optionally substituted, N-maleimidyl groups, halogenated N- alkylamido groups, sulfonyloxy N-alkylamido groups, ester groups, carbonate groups, sulfonyl halide groups, thiol groups or derivatives thereof, alkenyl groups, alkynyl groups, (hetero)cycloalkynyl groups, bicyclo[6.1.0]non-4-yn-9-yl] groups, cycloalkenyl groups, tetrazinyl groups, azido groups, phosphine groups, nitrile oxide groups, nitrone groups, nitrile imine groups, diazo groups, ketone groups, (O-alkyl)hydroxylamino groups, hydrazine groups, halogenated N- maleimidyl groups, 1 , 1-bis(sulfonylmethyl)methylcarbonyl groups or elimination derivatives thereof, carbonyl halide groups and allenamide groups.
In a further preferred embodiment, Q is according to formula (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj) or (9zk), wherein (9a), (9b), (9c), (9d), (9e), (9f), (9g), (9h), (9i), (9j), (9k), (9I), (9m), (9n), (9o), (9p), (9q), (9r), (9s), (9t), (9u), (9v), (9w), (9x), (9y), (9z), (9za), (9zb), (9zc), (9zd), (9ze), (9zf), (9zg), (9zh), (9zi), (9zj), (9zk), (9zo), and preferred embodiments thereof, are as defined above for the linker-conjugate according to the invention. More preferably, Q is according to formula (9a), (9b), (9c), (9f), (9j), (9n), (9o), (9p), (9q), (9s), (9t), (9ze), (9zh), (9zo) or (9r). Even more preferably, Q is according to formula (9a), (9j), (9n), (9o), (9p), (9q), (9t), (9ze), (9zh), (9zo) or (9s), and most preferably, Q is according to formula (9a), (9p),(9q), (9n), (9t), (9ze), (9zh), (9zo) or (9o), and preferred embodiments thereof, as defined above.
In an especially preferred embodiment, Q comprises an alkyne group, preferably selected from the alkynyl group as described above, the cycloalkenyl group as described above, the (hetero)cycloalkynyl group as described above and a bicyclo[6.1.0]non-4-yn-9-yl] group, more preferably Q is selected from the formulae (9j), (9n), (9o), (9p), (9q), (9zo) and (9zk), as defined above. Most preferably, Q is a bicyclo[6.1.0]non-4-yn-9-yl] group, preferably of formula (9q).
In a further preferred embodiment of the process for preparing the bioconjugate, the linker- conjugate is according to formula (4a) or (4b), or a salt thereof:

4a

4b
wherein:
- a is independently 0 or 1 ;
- b is independently 0 or 1 ;
- c is 0 or 1 ;
- d is 0 or 1 ;
- e is 0 or 1 ;
- f is an integer in the range of 1 to 150;
- g is 0 or 1 ;
- i is 0 or 1 ;
- D is a target molecule;
- Q is a reactive group capable of reacting with a functional group F present on a biomolecule;
- Sp1 is a spacer moiety;
- Sp2 is a spacer moiety;
- Sp3 is a spacer moiety;
- Sp4 is a spacer moiety;
- Z is a connecting group that connects Q or Sp3 to Sp2, O or C(O) or N(R1);
- Z2 is a connecting group that connects D or Sp4 to Sp1 , N(R1), O or C(O); and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups; or R is D, -[(Sp )b(Z2)e(Sp4)iD] or -[(Sp2)c(Z )d(Sp3)gQ1], wherein D is a target molecule and Sp1 , Sp2, Sp3, Sp4, Z , Z2, Q , b, c, d, e, g and i are as defined above.
Sp1 , Sp2, Sp3 and Sp4 are, independently, spacer moieties, in other words, Sp1 , Sp2, Sp3 and Sp4 may differ from each other. Sp1 , Sp2, Sp3 and Sp4 may be present or absent (b, c, g and i are, independently, 0 or 1 ). However, it is preferred that at least one of Sp1 , Sp2, Sp3 and Sp4 is present, i.e. it is preferred that at least one of b, c, g and i is not 0.
If present, preferably Sp1 , Sp2, Sp3 and Sp4 are independently selected from the group consisting of linear or branched C1-C200 alkylene groups, C2-C200 alkenylene groups, C2-C200 alkynylene groups, C3-C200 cycloalkylene groups, C5-C200 cycloalkenylene groups, C8-C200 cycloalkynylene
groups, C7-C200 alkylarylene groups, C7-C200 arylalkylene groups, C8-C200 arylalkenylene groups and C9-C200 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted. When the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are interrupted by one or more heteroatoms as defined above, it is preferred that said groups are interrupted by one or more O-atoms, and/or by one or more S-S groups.
More preferably, spacer moieties Sp\ Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C100 alkylene groups, C2-C100 alkenylene groups, C2-C100 alkynylene groups, C3-C100 cycloalkylene groups, C5-C100 cycloalkenylene groups, C8-C100 cycloalkynylene groups, C7-C100 alkylarylene groups, C7-C100 arylalkylene groups, Cs-doo arylalkenylene groups and C9-C100 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
Even more preferably, spacer moieties Sp1, Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C50 alkylene groups, C2-C50 alkenylene groups, C2-C50 alkynylene groups, C3-C50 cycloalkylene groups, C5-C50 cycloalkenylene groups, Cs-Cso cycloalkynylene groups, C7-C50 alkylarylene groups, C7-C50 arylalkylene groups, Cs-Cso arylalkenylene groups and C9-C50 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
Yet even more preferably, spacer moieties Sp1, Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, C2-C20 alkenylene groups, C2-C20 alkynylene groups, C3-C20 cycloalkylene groups, C5-C20
cycloalkenylene groups, C8-C20 cycloalkynylene groups, C7-C20 alkylarylene groups, C7-C20 arylalkylene groups, C8-C20 arylalkenylene groups and C9-C20 arylalkynylene groups, the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted.
In these preferred embodiments it is further preferred that the alkylene groups, alkenylene groups, alkynylene groups, cycloalkylene groups, cycloalkenylene groups, cycloalkynylene groups, alkylarylene groups, arylalkylene groups, arylalkenylene groups and arylalkynylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, preferably O, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
Most preferably, spacer moieties Sp\ Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched C1-C20 alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted. In this embodiment, it is further preferred that the alkylene groups are unsubstituted and optionally interrupted by one or more heteroatoms selected from the group of O, S and NR3, preferably O and/or S-S, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, preferably hydrogen or methyl.
Particularly preferred spacer moieties Sp1 , Sp2, Sp3 and Sp4 include -(CH2)n-, -(CH2CH2)n-, -(CH2CH20)n-, -(OCH2CH2)n-, -(CH2CH20)nCH2CH2-, -CH2CH2(OCH2CH2)n-, -(CH2CH2CH20)n-, -(OCH2CH2CH2)n-, -(CH2CH2CH20)nCH2CH2CH2- and -CH2CH2CH2(OCH2CH2CH2)n-, wherein n is an integer in the range of 1 to 50, preferably in the range of 1 to 40, more preferably in the range of 1 to 30, even more preferably in the range of 1 to 20 and yet even more preferably in the range of 1 to 15. More preferably n is 1 , 2, 3, 4, 5, 6, 7, 8, 9 or 10, more preferably 1 , 2, 3, 4, 5, 6, 7 or 8, even more preferably 1 , 2, 3, 4, 5 or 6, yet even more preferably 1 , 2, 3 or 4.
In another preferred embodiment of the process according to the invention, in the linker- conjugates according to formula (4a) and (4b), spacer moieties Sp1 , Sp2, Sp3 and/or Sp4, if present, comprise a sequence of amino acids. Spacer-moieties comprising a sequence of amino acids are known in the art, and may also be referred to as peptide linkers. Examples include spacer-moieties comprising a Val-Ala moiety or a Val-Cit moiety, e.g. Val-Cit-PABC, Val-Cit-PAB, Fmoc-Val-Cit-PAB, etc.
As described above, Z and Z2 are a connecting groups. In a preferred embodiment of the process according to the invention, Z and Z2 are independently selected from the group
consisting of -0-,
-S-, -NR2-, -N=N-, -C(O)-, -C(0)NR2-, -OC(O)-, -OC(0)0-, -OC(0)NR2, -NR2C(0)-, -NR2C(0)0-, -NR2C(0)NR2-, -SC(O)-, -SC(0)0-, -SC(0)NR2-, -S(O)-, -S(0)2-, -OS(0)2-, -OS(0)20-, -OS(0)2NR2-, -OS(O)-, -OS(0)0-, -OS(0)NR2-, -ONR2C(0)-, -ONR2C(0)0-, -ONR2C(0)NR2-, -NR2OC(0)-, -NR2OC(0)0-, -NR2OC(0)NR2-, -ONR2C(S)-, -ONR2C(S)0-, -ONR2C(S)NR2-, -NR2OC(S)-, -NR2OC(S)0-, -NR2OC(S)NR2-, -OC(S)-, -OC(S)0-, -OC(S)NR2-, -NR2C(S)-, -NR2C(S)0-, -NR2C(S)NR2-, -SS(0)2-, -SS(0)20-, -SS(0)2NR2-, -NR2OS(0)-, -NR2OS(0)0-, -NR2OS(0)NR2-, -NR2OS(0)2-, -NR2OS(0)20-, -NR2OS(0)2NR2-, -ONR2S(0)-, -ONR2S(0)0-, -ONR2S(0)NR2-, -ONR2S(0)20-, -ONR2S(0)2NR2-, -ONR2S(0)2-, -OP(0)(R2)2-, -SP(0)(R2)2-, -NR2P(0)(R2)2- and combinations of two or more thereof, wherein R2 is independently selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C2 - C24 alkenyl groups, C2 - C24 alkynyl groups and C3 - C24 cycloalkyl groups, the alkyl groups, alkenyl groups, alkynyl groups and cycloalkyl groups being optionally substituted. In a particularly preferred process according to the invention, Sp\ Sp2, Sp3 and Sp4, if present, are independently selected from the group consisting of linear or branched Ci-C2o alkylene groups, the alkylene groups being optionally substituted and optionally interrupted by one or more heteroatoms selected from the group consisting of O, S and NR3, wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, and wherein Q is accord

9o 9p 9ze

wherein:
- 1 is an integer in the range 0 - 10;
- R 0 is a (thio)ester group; and
- R 8 is selected from the group consisting of, optionally substituted, Ci - C12 alkyl groups and C4 - C12 (hetero)aryl groups.
An embodiment of the process for preparing the bioconjugate is depicted in Figure 4. Figure 4 shows how a modified antibody 13a-d may undergo a bioconjugation process by means of nucleophilic addition with maleimide (as for 3-mercaptopropionyl-galactosamine-modified 13a leading to thioether conjugate 14, or for conjugation to an engineered cysteine residue leading to thioether conjugate 17) or upon strain-promoted cycloaddition with a cyclooctyne reagent (as for 13b, 13c or 13d, leading to triazoles 15a, 15b or 16, respectively). In addition to the increased therapeutic index of the bioconjugates according to the invention, a further advantages of the process for the preparation of a bioconjugate as described herein, and of the linker-conjugates and sulfamide linker according to the invention is that conjugation efficiency increases in case a sulfamide linker is used instead of a typical polyethylene glycol (PEG) spacer. An additional advantage of a sulfamide group, in particular of an acylsulfamide or a carbamoylsulfamide group, is its high polarity, which imparts a positive effect on the solubility of a linker comprising such group, and on the construct as a whole, before, during and after conjugation. In view of this increased polarity, conjugation with linker-conjugate containing the sulfamide linker according to the invention are particularly suited to conjugate hydrophobic target compounds to a biomolecule. The high polarity of the sulfamides also has a positive impact in case hydrophobic moieties are conjugated to a biomolecule of interest, which is known to require large amounts of organic co-solvent during conjugation and/or induce aggregation of the bioconjugate. High levels of co-solvent (up to 25% of DMF or even 50% of DMA, propylene glycol, or DMSO) may induce protein denaturation during the conjugation process and/or may require special equipment in the manufacturing process. Thus, the problem of aggregation associated with the hydrophobic linking moieties in bioconjugates is efficiently solved by using the sulfamide linker according to the invention in the spacer between the target molecule and the reactive group Q in the linker-conjugate in the formation of the bioconjugate. An additional advantage of a sulfamide linker according the invention, and its use in bioconjugation processes, is its ease of
synthesis and high yields.
For evidence of these beneficial effects of the use of the sulfamide linker according to the present invention, reference is made to PCT/NL2015/050697 (WO 2016/053107), in particular to Tables 1 - 3, Figures 1 1 - 14, 23 and 24, and Examples 57, 58, 60 and 61 therein. These Tables, Figures and Examples of PCT/NL2015/050697 (WO 2016/053107) are incorporated herein.
Application
The invention thus concerns in a first aspect the use of a mode of conjugation comprising at least one of "core-GlcNAc functionalization" and "sulfamide linkage", as defined above, for increasing the therapeutic index of a bioconjugate. The invention according to the present aspect can also be worded as a method for increasing the therapeutic index of a bioconjugate. In a preferred embodiment, the mode of conjugation is being used to connect a biomolecule B with a target molecule D via a linker L, wherein the mode of conjugation comprises:
(i) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q , x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified glycoprotein according to Formula (24):

(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
(ii) reacting the modified glycoprotein with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F .
Herein, the biomolecule is preferably an antibody, the bioconjugate is preferably an antibody- conjugate.
Herein, the therapeutic index is increased compared to a bioconjugate which does not comprise or is obtainable by the mode of conjugation according to the invention. Thus, in a first embodiment, the therapeutic index is increased compared to a bioconjugate not obtainable by steps (i) and (ii) as defined above, or - in other words - not containing the structural feature of the resulting linker L that links the antibody with the target molecule, that are a direct consequence of the conjugation process. Thus, in a second embodiment, the therapeutic index is increased compared to a bioconjugate of formula (A), wherein linker L does not comprise a group according to formula (1 ) or a salt thereof.
The inventors surprisingly found that the therapeutic index of the bioconjugates according to the invention was significantly increased when mode of conjugation according to the present invention was used, even if all other factors, in particular the type of biomolecule and the type of target molecule and biomolecule-target molecule-ratio, were kept constant. The increased therapeutic index could solely be attributed to the mode of conjugation according to the invention. The increased therapeutic index is preferably an increased therapeutic index in the treatment of cancer, in particular in targeting of HER2-expressing tumours.
The method according to the first aspect of the invention may also be worded as aspect a method for increasing the therapeutic index of a bioconjugate, comprising the step of providing a bioconjugate having the mode of conjugation according to the invention.
The inventors found that the mode of conjugation according to the invention, as comprised in the bioconjugates according to the invention, has an effect on both aspects of the therapeutic index: (a) on the therapeutic efficacy and (b) on the tolerability. Thus, the present use or method for increasing the therapeutic index is preferably for (a) increasing the therapeutic efficacy, and/or (b) increasing the tolerability of a bioconjugate of formula (A). Preferably the bioconjugate is an antibody-conjugate and the present use or method is for increasing the therapeutic index of an antibody-conjugate, preferably for (a) increasing the therapeutic efficacy of the antibody- conjugate, and/or (b) increasing the tolerability of the antibody-conjugate. In one embodiment, the present method or use is for increasing the therapeutic efficacy of the bioconjugate, preferably the antibody-conjugate. In one embodiment, the present method or use is for increasing the tolerability of the bioconjugate, preferably the antibody-conjugate.
Thus, in one embodiment, the use or method according to the first aspect is for increasing the therapeutic efficacy of a bioconjugate of formula (A). Herein, "increasing the therapeutic efficacy" can also be worded as "lowering the effective dose", "lowering the ED50 value" or "increasing the protective index". Likewise, in one embodiment, the method according to the first aspect is for increasing the tolerability of a bioconjugate of formula (A). Herein, "increasing the tolerability" can also be worded as "increasing the maximum tolerated dose (MTD)", "increasing the TD50 value", "increasing the safety" or "reducing the toxicity". In one especially preferred embodiment, the method according to the first aspect is for (a) increasing the therapeutic efficacy and (b) increasing the tolerability of a bioconjugate of formula (A).
The method according to the first aspect is largely non-medical. In one embodiment, the method is a non-medical or a non-therapeutic method for increasing the therapeutic index of a bioconjugate.
The first aspect of the invention can also be worded as a mode of conjugation for use in improving the therapeutic index (therapeutic efficacy and/or tolerability) of a bioconjugate, wherein the mode of conjugation is as defined above. In one embodiment, the present aspect is worded as a the
mode of conjugation according to the "core-GlcNAc functionalization" as defined above for use in improving the therapeutic efficacy of a bioconjugate of formula (A), wherein L and (A) are as defined above. In one embodiment, the present aspect is worded as a mode of conjugation for use in improving the therapeutic index (therapeutic efficacy and/or tolerability) of a bioconjugate, preferably an antibody-conjugate. In other words, the first aspect concerns the use of a mode of conjugation for the preparation of a bioconjugate, preferably an antibody-conjugate, for improving the therapeutic index (therapeutic efficacy and/or tolerability) of the bioconjugate. The invention according to the first aspect can also be worded as the use of a mode of conjugation in a bioconjugate, preferably an antibody-conjugate, or in the preparation of a bioconjugate, preferably an antibody-conjugate, for increasing the therapeutic index (therapeutic efficacy and/or tolerability) of the bioconjugate. The use as defined herein may be referred to as non-medical or non-therapeutic use.
In one embodiment, the method, use or mode of conjugation for use according to the first aspect of the invention further comprises the administration of the bioconjugate according to the invention to a subject in need thereof, in particular a patient suffering from a disorder associated with HER2 expression, e.g. selected from breast cancer, pancreatic cancer, bladder cancer, or gastric cancer. In one embodiment, the subject is a cancer patient, more suitably a patient suffering from HER2-expressing tumours. The use of bioconjugates such as antibody-drug-conjugates, is well- known in the field of cancer treatment, and the bioconjugates according to the invention are especially suited in this respect.
Typically, the bioconjugate is administered in a therapeutically effective dose. Administration may be in a single dose or may e.g. occur 1 - 4 times a month, preferably 1 - 2 times a month. In a preferred embodiment, administration occurs once every 3 or 4 weeks, most preferably every 4 weeks. In view of the increased therapeutic efficacy, administration may occur less frequent as would be the case during treatment with conventional bioconjugates. As will be appreciated by the person skilled in the art, the dose of the bioconjugate according to the invention may depend on many factors and the optimal dosing regime can be determined by the skilled person via routine experimentation. The bioconjugate is typically administered in a dose of 0.01 - 50 mg/kg body weight of the subject, more accurately 0.03 - 25 mg/kg or most accurately 0.05 - 10 mg/kg, or alternatively 0.1 - 25 mg/kg or 0.5 - 10 mg/kg. In one embodiment, administration occurs via intravenous injection.
Method for targeting HER2-expressing cells
The invention concerns in a second aspect a method for targeting HER2-expressing cells, including but not limited to low HER2-expressing cells, comprising the administration of the bioconjugate according to the invention. HER2-expressing cells may also be referred to as HER2- expressing tumour cells. The subject in need thereof is most preferably a cancer patient. The use of bioconjugates such as antibody-drug-conjugates, is well-known in the field of cancer treatment, and the bioconjugates according to the invention are especially suited in this respect. The method
as described is typically suited for the treatment of cancer. The bioconjugate according to the invention is described a great detail above, which equally applies to the bioconjugate used in the second aspect of the invention. The second aspect of the invention can also be worded as a bioconjugate according to the invention for use in targeting HER2-expressing cells in a subject in need thereof. In other words, the second aspect concerns the use of a according to the invention for the preparation of a medicament for use in the targeting HER2-expressing cells in a subject in need thereof.
In the context of the present aspect, the targeting of HER2-expressing cells includes one or more of treating, imaging, diagnosing, preventing the proliferation of, containing and reducing HER2- expressing cells, in particular HER2-expressing tumours. Most preferably, the present aspect is for the treatment of HER2-expressing tumours.
In one embodiment, the present aspect concerns a method for the treatment of a subject in need thereof. The second aspect of the invention can also be worded as a bioconjugate according to the invention for use in the treatment of a subject in need thereof, preferably for the treatment of cancer. In other words, the second aspect concerns the use of a bioconjugate according to the invention for the preparation of a medicament for use in the treatment of a subject in need thereof, preferably for use in the treatment of cancer.
In the context of the present aspect, the subject suitably suffers from a disorder associated with HER2-expression, in particular a disorder selected form breast cancer, pancreatic cancer, bladder cancer, or gastric cancer
In the context of the present aspect, it is preferred that target molecule D is an anti-cancer agent, preferably a cytotoxin. In the method according to the second aspect, the bioconjugate is typically administered in a therapeutically effective dose. Administration may be in a single dose or may e.g. occur 1 - 4 times a month, preferably 1 - 2 times a month. In a preferred embodiment, administration occurs once every 3 or 4 weeks, most preferably every 4 weeks. As will be appreciated by the person skilled in the art, the dose of the bioconjugate according to the invention may depend on many factors and the optimal dosing regime can be determined by the skilled person via routine experimentation. The bioconjugate is typically administered in a dose of 0.01 - 50 mg/kg body weight of the subject, more accurately 0.03 - 25 mg/kg or most accurately 0.05 - 10 mg/kg, or alternatively 0.1 - 25 mg/kg or 0.5 - 10 mg/kg. In one embodiment, administration occurs via intravenous injection.
In view of the increased therapeutic efficacy, administration may occur less frequent as in treatment with conventional bioconjugates and/or at a lower dose. In one embodiment, the administration of the bioconjugate according to the invention is at a dose that is lower than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89-60%, even more preferable at most 59-30%, most preferably at most 29-10% of the TD50 of the same bioconjugate
but not comprising the mode of conjugation according to the invention. In one embodiment, the administration of the bioconjugate according to the invention occurs less frequent as administration would occur for the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the number of administration events is at most 75%, more preferably at most 50% of the number of administration events of the same bioconjugate but not comprising the mode of conjugation according to the invention. Alternatively, in view of the increased tolerability, administration may occur in a higher dose as in treatment with conventional bioconjugates. In one embodiment, the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 25-50%, more preferably at most 50-75%, most preferably at most 75-100% of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
In view of the increased therapeutic efficacy, administration may occur less frequent as in treatment with conventional bioconjugates and/or at a lower dose. In one embodiment, the administration of the bioconjugate according to the invention is at a dose that is lower than the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most 99-90%, more preferably at most 89-60%, even more preferable at most 59-30%, most preferably at most 29-10% of the ED50 of the same bioconjugate but not comprising the mode of conjugation according to the invention. In one embodiment, the administration of the bioconjugate according to the invention occurs less frequent as administration would occur for the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the number of administration events is at most 75%, more preferably at most 50% of the number of administration events of the same bioconjugate but not comprising the mode of conjugation according to the invention. Alternatively, in view of the increased tolerability, administration may occur in a higher dose as in treatment with conventional bioconjugates. In one embodiment, the administration of the bioconjugate according to the invention is at a dose that is higher than the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention, preferably the dose is at most a factor 1.1 - 1.49 higher, more preferably at most a factor 1 .5 - 1.99 higher, even more preferable a factor 2 - 4.99 higher, most preferably at most a factor 5 - 10 higher of the TD50 of the same bioconjugate but not comprising the mode of conjugation according to the invention.
In one embodiment, the use or method or conjugation mode for use according to the present aspect is a bioconjugate for use in the treatment of a subject in need thereof, wherein the bioconjugate is represented by formula (A):
B-L-D
(A),
wherein:
- B is a biomolecule;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety,
wherein L comprises a group according to formula (1 ) or a salt thereof:

1
wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
Antibody-conjugates according to the invention
In a third aspect, the invention pertains to antibody-conjugates that are particularly suitable in targeting HER2-expressing tumours. The antibody-conjugates according to the invention comprise an antibody AB connected to a target molecule D via a linker L, wherein the antibody- conjugate comprises or is obtainable by the mode of conjugation according to the invention. In particular, the antibody-conjugates according to the invention are obtainable by:
(i) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q , x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified antibody according to Formula (24):

(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
(ii) reacting the modified antibody with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F .
Herein, antibody AB is capable of targeting HER2-expressing tumours and target molecule D is selected from the group consisting of taxanes, anthracyclines, camptothecins, epothilones, mytomycins, combretastatins, vinca alkaloids, maytansinoids, calicheamycins and enediynes, duocarmycins, tubulysins, amatoxins, dolastatins and auristatins, pyrrolobenzodiazepine dimers, indolino-benzodiazepine dimers, radioisotopes, therapeutic proteins and peptides and toxins (or fragments thereof), kinase inhibitors, MEK inhibitors, KSP inhibitors, and analogs or prodrugs thereof. Alternatively, target molecule D is a cytotoxin. In one embodiment according to the present aspect, target molecule D is selected from the group consisting of maytansinoids, pyrrolobenzodiazepine dimers, indolino-benzodiazepine dimers, enediynes, auristatins and anthracyclines. In a preferred embodiment according to the present aspect, target molecule D is a maytansinoids or pyrrolobenzodiazepine dimer, more preferably an auristatine selected from the group consisting of MMAD, MMAE, MMAF and functional analogues thereof or maytansinoid selected from the group of DM1 , DM3, DM4 and Ahx-May or any functional derivative thereof, most preferably D = Ahx-May or any functional derivative thereof. Alternatively, D is a pyrrolobenzodiazepine dimer.
The preferred embodiments for steps (i) and (ii), as defined above, equally apply to the antibody- conjugate according to the invention. The skilled person knowns how to translate these preferred features into structural features of the present antibody-conjugates. In a preferred embodiment, the antibody-conjugate according to the present aspect is according to formula (A) and preferably linker L contains the group according to formula (1 ) or a salt thereof, wherein (A) and (1 ) are as defined above.
Preferred options for S(F )X are described above. In one preferred embodiment, S(F )X is 6-azido- 6-deoxy-A/-acetylgalactosamine (6-AzGalNAc or 6-N3-GalNAc).
In a preferred embodiment, the antibody AB capable of targeting HER2-expressing tumours is selected from the group consisting of from trastuzumab, margetuximab, pertuzumab, HuMax- Her2, ertumaxomab, HB-008, ABP-980, BCD-022, CanMab, Herzuma, HD201 , CT-P6, PF- 05280014, COVA-208, FS-102, MCLA-128, CKD-10101 , HT-19 and functional analogues thereof. More preferably, the antibody AB capable of targeting HER2-expressing tumours is trastuzumab or a functional analogue thereof.
In an especially preferred embodiment, the antibody AB is trastuzumab, and target molecule D is selected from the group consisting of maytansinoids, auristatines and pyrrolobenzodiazepine dimer, preferably auristatines selected from the group consisting of MMAD, MMAE, MMAF and
functional analogues thereof or maytansinoids selected form the group consisting of DM1 , DM3, DM4, Ahx-May and functional analogues thereof. Most preferably, D = Ahx-May.
In a preferred embodiment, the antibody-conjugate according is represented by Formula (40) or (40b):
(Fuc)b
AB - -GlcNAc- ■SH- ■


(40b),
wherein:
- R3 is independently selected from the group consisting of hydrogen, halogen, -OR35, -NO2, -CN, -S(0)2R35, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- X is C(R3 )2, O, S or NR32, wherein R32 is R3 or L3(D , wherein L3 is a linker, and D is as defined in claim 1 ;
- r is 1 - 20;
- q is 0 or 1 , with the proviso that if q is 0 then X is N-L2(D)r;
- aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8;
- aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8; and
- aa+aa' < 10.
- b is 0 or 1 ;
- pp is 0 or 1 ;
- M is -N(H)C(0)CH2- -N(H)C(0)CF2-, -CH2-, -CF2- or a 1 ,4-phenylene containing 0 - 4 fluorine substituents, preferably 2 fluorine substituents which are preferably positioned on C2 and C6 or on C3 and C5 of the phenylene;
- y is 1 - 4;
- Fuc is fucose.
Preferably, aa = 2, aa' = 3, X = C(R3 )2 (i.e. a fused cyclooctene ring is present), wherein one R3 = H and the other R3 is linked together with the further R3 substituent present in the structure according to formula (20b) to form an annelated cyclopropyl ring sharing carbon atoms 5 and 6 of the cyclooctene moiety (when the carbon atoms shared with the triazole ring are numbered 1 and 2). In a preferred embodiment, the antibody is according to any one of Formulae (41 ), (42), (42b), (35b), (40c) and (40d) as defined above.
Preferred features of the antibody-conjugate according to the invention are described above, in particular in the description of step (ii) of the "core-GlcNAc functionalization" as mode of conjugation, and the products thereof.
In one embodiment, the antibody-conjugate according to the present aspect is a bioconjugate represented by formula (A):
B-L-D
(A),
wherein:
- B is a biomolecule;
- L is a linker linking B and D;
- D is a target molecule; and
- each occurrence of "-" is independently a bond or a spacer moiety,
wherein L comprises a group according to formula (1 ) or a salt thereof:

1
wherein:
- a is 0 or 1 ; and
- R is selected from the group consisting of hydrogen, Ci C24 alkyl groups, C3 - C24
cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S and NR3 wherein R3 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
Preferred antibody-conjugates according to the present aspect are listed here below as conjugates (I) - (XXIV). In one embodiment, the antibody-conjugate according to the present aspect is selected from the conjugates defined here below as (I) - (XXIV), preferably selected from the conjugates defined here below as (I) - (X), more preferably selected from the conjugates defined here below as (I) - (VI).
(I) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit-PABC-, D = Ahx-May (conjugate 82);
(II) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2)3-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit- PABC-, D = Ahx-May (conjugate 83);
(III) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-Val-Cit-PABC-, D = Ahx-May (conjugate 81 );
(IV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-N(CH2-CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(V) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH-S(0)2-N(CH2-CH2-0- C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May (conjugate 84);
(VI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Ala-, D = PBD (conjugate 85);
(VII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 2-azidoacetamido-2-deoxy-galactose, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-, D = Ahx-May (conjugate 96);
(VIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 2-azidoacetamido-2-deoxy-galactose, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)4-C(0)-, D = Ahx-May (conjugate 95);
(IX) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 2-azidodifluoroacetamido-2-deoxy-galactose, Q is according to formula
(9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)4-C(0)-, D = Ahx-May (conjugate 97);
(X) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 2-azidodifluoroacetamido-2-deoxy-galactose, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-, D = Ahx-May (conjugate 98);
(XI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9n), wherein U = O, L2 = -C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH-S(0)2-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May.
(XII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9zo), L2 = -C(0)-NH-(CH2)4-C(0)-NH-(CH2)5-0-C(0)-NH-S(0)2-N(CH2-CH2-0-C(0)-Val- Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9j), wherein I = 3, L2 = -0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH-S(0)2-N(CH2- CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XIV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-NH-
S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D)2, each occurrence of D = Ahx-May;
(XVI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D)2, each occurrence of D = Dox;
(XVII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D)2, each occurrence of D = MMAF;
(XVIII)AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q),
L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D)2, each occurrence of D = MMAE;
(XIX) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH-S(0)2-N(CH2-CH2-0- C(0)-Val-Cit-PABC-D)2, each occurrence of D = MMAE;
(XX) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D1 )(CH2-CH2-0-C(0)-Val-Cit-PABC-D2), with D1 = MMAE and D2 = MMAF;
(XXI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D1 )(CH2-CH2-0-C(0)-Val-Cit-PABC-D2), with D1 = MMAE and D2 = Dox;
(XXII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-0-C(0)-Val-Cit- PABC-D1 )(CH2-CH2-0-C(0)-Val-Cit-PABC-D2), with D1 = MMAE and D2 = Ahx-May;
(XXIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )x = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit-PABC-D, each occurrence of D = MMAE; and
(XXIV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q),
L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-Val-Cit-PABC-D, each occurrence of D = MMAE.
The skilled person understands that the antibody-conjugates defined here as (I) - (XXIV) do not contain F = N3 nor Q = (9j), (9n), (9q) or (9zo), but the connecting group Z3 resulting from reaction between F and Q . More specifically, the antibody-conjugates (I) - (VI) and (XIV) to (XXIV) as defined above are according to formula (40b), wherein S = GalNAc, y = 2, x = 1 , b = 0 or 1 , pp = 0 (i.e. M is absent), aa = 2, aa' = 3, X = C(R3 )2, wherein one R3 = H and the other R3 is linked together with the further R3 substituent present in the structure according to formula (40b) to form an annelated cyclopropyl ring sharing carbon atoms 5 and 6 of the cyclooctene moiety (when the carbon atoms shared with the triazole ring are numbered 1 and 2, cf. structure (9q) above), q = 1 , r = 1 or 2 and D and L2 are defined above. More specifically, the antibody- conjugates (VII) and (VIII) as defined above are according to formula (40b), wherein S = GalNAc, y = 2, x = 1 , b = 0 or 1 , pp = 1 , M = -N(H)C(0)CH2- aa = 2, aa' = 3, X = C(R3 )2, wherein one R3 = H and the other R3 is linked together with the further R3 substituent present in the structure
according to formula (40b) to form an annelated cyclopropyl ring sharing carbon atoms 5 and 6 of the cyclooctene moiety (when the carbon atoms shared with the triazole ring are numbered 1 and 2, cf. structure (9q) above), q = 1 , r = 1 or 2 and D and L2 are defined above. More specifically, the antibody-conjugates (IX) and (X) as defined above are according to formula (40b), wherein S = GalNAc, y = 2, x = 1 , b = 0 or 1 , pp = 1 , M = -N(H)C(0)CF2- aa = 2, aa' = 3, X = C(R3 )2, wherein one R3 = H and the other R3 is linked together with the further R3 substituent present in the structure according to formula (40b) to form an annelated cyclopropyl ring sharing carbon atoms 5 and 6 of the cyclooctene moiety (when the carbon atoms shared with the triazole ring are numbered 1 and 2, cf. structure (9q) above), q = 1 , r = 1 or 2 and D and L2 are defined above. More specifically, the antibody-conjugate (XI) as defined above is according to formula (40b), wherein S = GalNAc, y = 2, x = 1 , b = 0 or 1 , pp = 0 (i.e. M is absent), aa = 3, aa' = 2, X = C(R3 )2, wherein R3 = H, wherein two fused phenyl rings are annelated to respectively carbon atoms 3+4 and 7+8 of the cyclooctene moiety and {L2(D)r}q is connected to carbon atom 5 or 6 (when the carbon atoms shared with the triazole ring are numbered 1 and 2, cf. structure (10k) above), q = 1 , r = 1 and D and L2 are defined above. More specifically, the antibody-conjugate (XII) as defined above is according to formula (40b), wherein S = GalNAc, y = 2, x = 1 , b = 0 or 1 , pp = 0 (i.e. M is absent), aa = 0, aa' = 5, X = C(R3 )2, wherein one R3 = F and the other R3 provides the connection with {L2(D)r}q, q = 1 , r = 1 and D and L2 are defined above. More specifically, the antibody-conjugate (XIII) as defined above is according to formula (40d), wherein S = GalNAc, y = 2, x = 1 , b = 0 or 1 , pp = 0 (i.e. M is absent), I = 3, q = 1 , r = 1 and D and L2 are defined above.
The antibody-conjugates according to the present aspect have an improved therapeutic index compared to known antibody-conjugates, wherein the therapeutic index is preferably for the treatment of HER2-expressing tumours. The improved therapeutic index may take the form of an improved therapeutic efficacy and/or an improved tolerability. In one embodiment, the antibody- conjugates according to the present aspect have an improved therapeutic efficacy compared to known antibody-conjugates for the treatment of HER2-expressing tumours. In one embodiment, the antibody-conjugates according to the present aspect have an improved tolerability compared to known antibody-conjugates for the treatment of HER2-expressing tumours.
The antibody-conjugates according to the invention outperform the known antibody-conjugates also in other aspects. The inventors have found that the present antibody-conjugates exhibit an increased stability (i.e. they exhibit less degradation over time). The inventors have also found that the present antibody-conjugates exhibit decreased aggregation issues (i.e. they exhibit less aggregation over time). In view of their improved therapeutic index, increased stability and decreased aggregation, the present antibody-conjugates are a marked improvement over prior art antibody-conjugates. The invention thus also concerns the use of the mode of conjugation as defined herein for improving stability of an bioconjugate, typically an antibody-conjugate. The invention thus also concerns the use of the mode of conjugation as defined herein for decreasing aggregation of an bioconjugate, typically an antibody-conjugate.
Endoglycosidases fusion enzyme
In a fourth aspect, the invention concerns a fusion enzyme comprising two endoglycosidases. In a particular example the two endoglycosidases EndoS and EndoH are connected via a linker, preferably a -(Gly4Ser)3-(His)6-(Gly4Ser)3- linker. The fusion enzyme according to the invention as also referred to as EndoSH. The enzyme according to the invention has at least 50% sequence identity with SEQ ID NO: 1 , preferably at least 70%, more preferably at least 80% sequence identity with SEQ ID NO: 1 , such as at least 81 %, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91 %, 92%, 93%, 94%, 95%, 96%, 97%, 98% or 99% sequence identity with SEQ ID NO: 1. Identity can be readily calculated by known methods and/or computer program methods known in the art such as BLASTP publicly available from NCBI and other sources (BLAST Manual, Altschul, S., et al., NCBI NLM NIH Bethesda, MD 20894; Altschul, S., et al. , J. Mol. Biol. 215:403- 410 (1990). Preferably, the enzyme of the invention, having the above indicated sequence identity to SEQ ID NO: 1 , has EndoS and EndoH activity. Most preferably, the enzyme according to the invention has 100% sequence identity with SEQ ID NO: 1.
Also encompassed are fusion enzymes of EndoS and EndoH, wherein the linker is replaced by another suitable linker known in the art, wherein said linker may be a rigid, or flexible. Preferably, said linker is a flexible linker allowing the adjacent protein domains to move relative freely to one another. Preferably, said flexible linker is composed of amino residues like glycine, serine, histidine and/or alanine and has a length of 3 to 59 amino acid residues, preferably 10 to 45 or 15 to 40 amino acid residues, such as 15, 16, 17, 18, 19, 20, 21 , 22, 23, 24, 25, 26, 27, 28, 29, 30, 31 , 32, 33, 34, 35, 36, 37, 38, 39 or 40 amino acid residues, or 20 to 38, 25 to 37 or 30 to 36 amino acid residues. Optionally, the fusion enzyme is covalently linked to, or comprises, a tag for ease of purification and or detection as known in the art, such as an Fc-tag, FLAG-tag, poly(His)- tag, HA-tag and Myc-tag.
Trimming of glycoproteins is known in the art, from e.g. WO 2007/133855 or WO 2014/065661 . The enzyme according to the invention exhibits both EndoS and EndoH activity, and is capable of trimming glycans on glycoproteins (such as antibodies) at the core-GlcNAc unit, leaving only the core-GlcNAc residue on the glycoprotein (EndoS activity) as well as well as splitting off high- manose glycans (EndoH activity). Surprisingly, both activities of the fusion enzyme function smoothly at a pH around 7 - 8, while monomeric EndoH requires a pH of 6 to operate optimally. The fusion enzyme according to the invention can be prepared by routine techniques in the art, such as introducing an expression vector (e.g. plasmid) comprising the enzyme coding sequence into a host cell (e.g. E. coli) for expression, from which the enzyme can be isolated. A possible approach for the preparation and purification of the fusion enzyme according to the invention is given in examples 3 - 5, and its functioning is demonstrated in example 6, wherein trastuzumab is efficiently trimmed in a single step.
Sequence identification of fusion protein EndoSH (SEQ. ID NO: 1):
1 MPSIDSLHYL SENSKKEFKE ELSKAGQESQ KVKEILAKAQ QADKQAQELA
51 KMKIPEKIPM KPLHGPLYGG YFRTWHDKTS DPTEKDKVNS MGELPKEVDL
101 AFIFHDWTKD YSLFWKELAT KHVPKLNKQG TRVIRTIPWR FLAGGDNSGI
151 AEDTSKYPNT PEGNKALAKA IVDEYVYKYN LDGLDVDVEH DSIPKVDKKE
201 DTAGVERSIQ VFEEIGKLIG PKGVDKSRLF IMDSTYMADK NPLIERGAPY
251 INLLLVQVYG SQGEKGGWEP VSNRPEKTME ERWQGYSKYI RPEQYMIGFS
301 FYEENAQEGN LWYDINSRKD EDKANGINTD ITGTRAERYA RWQPKTGGVK
351 GGIFSYAIDR DGVAHQPKKY AKQKEFKDAT DNIFHSDYSV SKALKTVMLK
401 DKSYDLIDEK DFPDKALREA VMAQVGTRKG DLERFNGTLR LDNPAIQSLE
451 GLNKFKKLAQ LDLIGLSRIT KLDRSVLPAN MKPGKDTLET VLETYKKDNK
501 EEPATIPPVS LKVSGLTGLK ELDLSGFDRE TLAGLDAATL TSLEKVDISG
551 NKLDLAPGTE NRQIFDTMLS TISNHVGSNE QTVKFDKQKP TGHYPDTYGK
601 TSLRLPVANE KVDLQSQLLF GTVTNQGTLI NSEADYKAYQ NHKIAGRSFV
651 DSNYHYNNFK VSYENYTVKV TDSTLGTTTD KTLATDKEET YKVDFFSPAD
701 KTKAVHTAKV IVGDEKTMMV NLAEGATVIG GSADPVNARK VFDGQLGSET
751 DNISLGWDSK QSI IFKLKED GLIKHWRFFN DSARNPETTN KPIQEASLQI
801 FNIKDYNLDN LLENPNKFDD EKYWITVDTY SAQGERATAF SNTLNNITSK
851 YWRWFDTKG DRYSSPWPE LQILGYPLPN ADTIMKTVTT AKELSQQKDK
901 FSQKMLDELK IKEMALETSL NSKIFDVTAI NANAGVLKDC IEKRQLLKKG
951 GGGSGGGGSG GGGSHHHHHH EFGGGGSGGG GSGGGGSAPA PVKQGPTSVA
1001 YVEVNNNSML NVGKYTLADG GGNAFDVAVI FAANINYDTG TKTAYLHFNE
1051 NVQRVLDNAV TQIRPLQQQG IKVLLSVLGN HQGAGFANFP SQQAASAFAK
1101 QLSDAVAKYG LDGVDFDDEY AEYGNNGTAQ PNDSSFVHLV TALRANMPDK
1151 IISLYNIGPA ASRLSYGGVD VSDKFDYAWN PYYGTWQVPG IALPKAQLSP
1201 AAVEIGRTSR STVADLARRT VDEGYGVYLT YNLDGGDRTA DVSAFTRELY
1251 GSEAVRTP
(linker is underlined, EndoH sequence is denoted in italics)
Examples
Tables 1 and 2 below provides an overview of the bioconjugates prepared.
Table 1: General structure of the bioconjugatt


TaWe 2: L/'sf of exemplary bioconjugates



Notes:
* Reaction partners used to prepare the bioconjugate (see Examples below).
** General structure as defined in Table 1 and structure of S(F )X. 6-N3-GalNAc = 6-azido-6- deoxy-A/-acetylgalactosamine; GalNAz = 2-azidoacetamido-2-deoxy-galactose; F2-GalNAz = 2-azidodifluoroacetamido-2-deoxy-galactose.
RP-HPLC analysis of reduced monoclonal antibodies: Prior to RP-HPLC analysis samples were reduced by incubating a solution of 10 μg (modified) IgG for 15 minutes at 37 °C with 10 mM DTT and 100 mM Tris pH 8.0 in a total volume of 50 μΙ_. A solution of 49% ACN, 49% MQ and 2% formic acid (50 μΙ_) was added to the reduced sample. Reverse phase HPLC was performed on a Agilent 1 100 HPLC using a ZORBAX Phoroshell 300SB-C8 1x75 5 μηη (Agilent Technologies) column run at 1 ml/min at 70 °C using a 16.9 minute linear gradient from 25 to 50 % buffer B (with buffer A = 90% MQ, 10% ACN, 0.1 % TFA and buffer B = 90% ACN, 10% MQ, 0.1 % TFA).
Mass spectral analysis of monoclonal antibodies: Prior to mass spectral analysis, IgGs were either treated with DTT, which allows analysis of both light and heavy chain, or treated with Fabricator™ (commercially available from Genovis, Lund, Sweden), which allows analysis of the Fc/2 fragment. For analysis of both light and heavy chain, a solution of 20 μg (modified) IgG was incubated for 5 minutes at 37 °C with 100 mM DTT in a total volume of 4 [it. If present, azide- functionalities are reduced to amines under these conditions. For analysis of the Fc/2 fragment, a solution of 20 μg (modified) IgG was incubated for 1 hour at 37 °C with Fabricator™ (1.25 υ/μί) in phosphate-buffered saline (PBS) pH 6.6 in a total volume of 10 [it. After reduction or Fabricator- digestion the samples were washed trice with milliQ using an Amicon Ultra-0.5, Ultracel-10 Membrane (Millipore) resulting in a final sample volume of approximately 40 [it. Next, the samples were analysed by electrospray ionization time-of -flight (ESI-TOF) on a JEOL AccuTOF. Deconvolved spectra were obtained using Magtran software.
Preparation of protein components: Examples 1 - 2
Example 1: Transient expression and purification of Trastuzumab
Trastuzumab was expressed from a stable CHO cell line by Bioceros (Utrecht, Netherlands). The supernatant (2.5 L) was purified using a XK 26/20 column packed with 50 mL protein A sepharose. In a single run 0.5 L supernatant was loaded onto the column followed by washing with at least 10 column volumes of 25 mM Tris pH 7.5, 150 mM NaCI. Retained protein was eluted with 0.1 M Glycine pH 2.7. The eluted product was immediately neutralized with 1.5 M Tris- HCI pH 8.8 and dialyzed against 25 mM Tris pH 8.0. Next the product was concentrated to approximately 20 mg/mL using a Vivaspin Turbo 15 ultrafiltration unit (Sartorius) and stored at -80 °C prior to further use.
Example 2: Transient expression and purification of His-TnGalNAcT(33-421) His-TnGalNAcT(33-421 ) (identified by SEQ ID NO: 3) was transiently expressed in CHO K1 cells by Evitria (Zurich, Switzerland) at 5 L scale. The supernatant was purified using a XK 16/20 column packed with 25 mL Ni sepharose excel (GE Healthcare). Each run approximately 1.5L supernatant was loaded onto the column followed by washing with at least 10 column volumes of buffer A (20 mM Tris buffer, 5 mM imidazole, 500 mM NaCI, pH 7.5). Retained protein was eluted with buffer B (20 mM Tris, 500 mM NaCI, 500 mM imidazole, pH 7.5). The buffer of the eluted fractions was exchanged to 25 mM Tris pH 8.0 using a HiPrep H26/10 desalting column (GE Healthcare). The purified protein was concentrated to at least 3 mg/mL using a Vivaspin Turbo 4 ultrafiltration unit (Sartorius) and stored at -80 °C prior to further use.
Sequence of His-TnGalNAcT(33-421) (SEQ. ID NO: 3):
1 HHHHHHSPLR TYLYTPLYNA TQPTLRNVER LAANWPKKIP SNYIEDSEEY
51 SIKNISLSNH TTRASWHPP SSITETASKL DKNMTIQDGA FAMISPTPLL
101 ITKLMDSIKS YVTTEDGVKK AEAWTLPLC DSMPPDLGPI TLNKTELELE
151 WVEKKFPEVE WGGRYSPPNC TARHRVAI IV PYRDRQQHLA IFLNHMHPFL
201 MKQQIEYGIF IVEQEGNKDF NRAKLMNVGF VESQKLVAEG WQCFVFHDID
251 LLPLDTRNLY SCPRQPRHMS ASIDKLHFKL PYEDIFGGVS AMTLEQFTRV
301 NGFSNKYWGW GGEDDDMSYR LKKINYHIAR YKMSIARYAM LDHKKSTPNP
351 KRYQLLSQTS KTFQKDGLST LEYELVQWQ YHLYTHILVN IDERS
Examples 3 - 5: Production of endoqlvcosidase EndoSH
Example 3: Cloning of fusion protein EndoSH into pET22B expression vector
A pET22B-vector containing an EndoS-(G4S)3-(His)6-(G4S)3-EndoH (EndoSH) coding sequence (EndoSH being identified by SEQ ID NO: 1 ) between Ndel-Hindlll sites was obtained from Genscript. The DNA sequence for the EndoSH fusion protein consists of the encoding residues 48-995 of EndoS fused via an /V-terminal linked glycine-serine (GS) linker to the coding residues 41-313 of EndoH. The glycine-serine (GS) linker comprises a -(G4S)3-(His)6-EF-(G4S)3- format, allowing spacing of the two enzymes and at the same time introducing a IMAC-purification tag.
Example 4: E. coli expression of fusion protein EndoSH
Expression of the EndoSH fusion protein (identified by SEQ ID NO: 1 ) starts with the transformation of the plasmid (pET22b-EndoSH) into BL21 cells. Next step is the inoculation of 500 mL culture (LB medium + Ampilicin) with BL21 cells. When the OD600 reached 0.7 the cultures were induced with 1 mM IPTG (500 [it of 1 M stock solution).
Example 5: Purification of fusion protein EndoSH from E.coli
After overnight induction at 16 °C the cultures were pelleted by centrifugation. The pellets were resuspended in 40 mL PBS and incubated on ice with 5 ml lysozyme (10 mg/mL) for 30 minutes.
After half an hour 5 ml 10% Triton-X-100 was added and sonicated (10 minutes) on ice. After the sonification the cell debris was removed by centrifugation (10 minutes 8000xg) followed by filtration through a 0,22 μΜ-pore diameter filter. The soluble extract was loaded onto a HisTrap HP 5 mL column (GE Healthcare). The column was first washed with buffer A (20 mM Tris buffer, 20 mM imidazole, 500 mM NaCI, pH 7.5). Retained protein was eluted with buffer B (20 mM Tris, 500 mM NaCI, 250 mM imidazole, pH 7.5, 10 mL). Fractions were analysed by SDS-PAGE on polyacrylamide gels (12%). The fractions that contained purified target protein were combined and the buffer was exchanged against 20 mM Tris pH 7.5 and 150 mM NaCI by dialysis performed overnight at 4 °C. The purified protein was concentrated to at least 2 mg/mL using an Amicon Ultra-0.5, Ultracel-10 Membrane (Millipore). The product is stored at -80 °C prior to further use.
Remodelling of Trastuzumab: Examples 6-7:
The preparation of the following modified biomolecules, suitable as biomolecule to be used in the method according to the invention, is described in PCT/NL2015/050697 (WO 2016/053107):
· trastuzumab(GalNAz)2 13b (Examples 12, 13, 15, 16-1 );
• trastuzumab(F2-GalNAz)2 13c (Examples 1 , 7 - 13, 16-2)
Example 6: Preparation of trimmed trastuzumab by means of fusion protein EndoSH
Glycan trimming of trastuzumab (obtained via stable expression in CHO cells performed by Bioceros (Utrecht, Netherlands)) was performed with fusion protein EndoSH. Thus, trastuzumab (100.8 mL, 2 g, 19.85 mg/ml in 25 mM Tris pH 8.0) was incubated with EndoSH (5.26 mL, 20 mg, 3.8 mg/mL in 25 mM Tris pH 7.5) for approximately 16 hours at 37 °C. Mass spectral analysis of a fabricator-digested sample showed one major peak of the Fc/2-fragment (observed mass 24135 Da, approximately 90% of total Fc/2 fragment), corresponding to core-GlcNAc(Fuc)-substituted trastuzumab.
Example 7: Preparation of trastuzumab(6-N3-GalNAc)2 13d
Trimmed trastuzumab (1 1 .8 mg/mL), obtained by EndoSH treatment of trastuzumab as described above in example 6, was incubated with the substrate 6-N3-GalNAc-UDP (3.3 mM, commercially available from GlycoHub) and His-TnGalNAcT(33-421 ) (0.75 mg/mL) in 10 mM MnCI2 and 25 mM Tris-HCI pH 8.0 at 30 °C. The reaction was incubated overnight at 30 °C. Biomolecule 13d was purified from the reaction mixture using a XK 26/20 column packed with 50 mL protein A sepharose using an AKTA purifier-10 (GE Healthcare). The eluted IgG was immediately neutralized with 1.5 M Tris-HCI pH 8.8 and dialyzed against PBS pH 7.4. Next the IgG was concentrated using an Amicon Ultra-0.5, Ultracel-10 Membrane (Millipore) to a concentration of 28.5 mg/mL. Mass spectral analysis of a fabricator-digested sample showed one major peak of the Fc/2-fragment (observed mass 24363 Da, approximately 90% of total Fc/2 fragment), corresponding to core 6-N3-GalNAc-GlcNAc(Fuc)-substituted trastuzumab.
Linker-coniuqate syntheses: Examples 8-23:
Reference to PCT/NL2015/050697 (WO 2016/053107) is made for the synthesis of the following compounds that are suitable as linker-conjugates to be used in the method according to the invention, or a model thereof:
Compound 18 (Example 20);
Compound 20 (Examples 21 , 23 - 25);
Compound 21 (Examples 26 - 27);
Compound 23 (Examples 29 - 31 );
Compound 26 (Examples 36 - 38);
Compound 30 (Examples 43-1 , 32);
Compound 33 (Examples 36 - 37, 47);
Compound 34 (Examples 36, 37, 48);
Compound 35 (Examples 36 - 37, 49);
Compound 36 (Examples 29, 50);
Compound 37 (Examples 51 - 53);
Compound 38 (Examples 29, 54 - 55);

80

Example 8: Preparation of compound 101
To a solution of BCN-OSu (1 .00 g, 3.43 mmol) in a mixture of THF and water (80 mL/80 mL) were added γ-aminobutyric acid (0.60 g, 5.12 mmol) and Et3N (1.43 mL, 1.04 g, 10.2 mmol). The mixture was stirred for 4 h followed by addition of DCM (200 mL) and a saturated aqueous solution of NH4CI (80 mL). After separation, the aqueous layer was extracted with DCM (2x200 mL). The combined organic layers were dried (Na2S04) and concentrated. The residue was purified with column chromatography (MeOH in DCM 0→ 10%). The product was obtained as a colourless thick oil (730 mg, 2.61 mmol, 76%). Ή NMR (400 MHz, CDCI3) δ (ppm) 4.81 (bs, 1 H), 4.15 (d, J = 8.4 Hz, 2H), 3.30-3.21 (m, 2H), 2.42 (t, J = 7.2 Hz, 2H), 2.35-2.16 (m, 6H), 1.85 (quintet, J = 6.9 Hz, 2H), 1.64-1.51 (m, 2H), 1.35 (quintet, J = 8.4 Hz, 1 H), 1.00-0.90 (m, 2H)
Example 9: Preparation of compound 102
Chlorosulfonyl isocyanate (CSI; 0.91 mL, 1.48 g, 10 mmol) was added to a cooled (-78 °C) solution of ieri-butanol (5.0 mL, 3.88 g, 52 mmol) in Et.20 (50 mL). The reaction mixture was allowed to warm to rt and was concentrated. The residue was suspended in DCM (200 mL) and subsequently Et3N (4.2 mL, 3.0 g, 30 mmol) and 2-(2-aminoethoxy)ethanol (1.0 mL, 1.05 g; 10 mmol) were added. The resulting mixture was stirred for 10 min and concentrated. The residue was purified twice with column chromatography (MeOH in DCM 0→ 10%). The product was obtained as a colourless thick oil (2.9 g, 10 mmol, 100%) H NMR (400 MHz, CDCI3) δ (ppm) 5.75 (bs, 1 H), 3.79-3.74 (m, 2H), 3.67-3.62 (m, 2H), 3.61-3.57 (m, 2H), 3.35-3.28 (m, 2H), 1.50 (s, 9H). Example 10: Preparation of compound 103
To a solution of 102 (2.9 g, 10 mmol) in DCM (40 mL) were added Ac20 (2.9 mL, 3.1 1 g, 30.5 mmol) and Et3N (12.8 mL, 9.29 g, 91.8 mmol). The reaction mixture was stirred for 2 h, washed with a saturated aqeuos solution of NaHCCh (50 mL) and dried (Na2S04). The residue was purified twice with column chromatography (20%→ 100% EtOAc in heptane). The product was obtained as a colourless oil (2.5 g, 7.7 mmol, 77%) Ή NMR (400 MHz, CDCI3) δ (ppm) 5.48 (bs, 1 H), 4.25-4.20 (m, 2H), 3.70-3.60 (m, 4H), 3.33-3.23 (m, 2H), 2.10 (s, 3H), 1.50 (s, 9H)
Example 11: Preparation of compound 104
To a solution of 103 (80 mg, 0.25 mmol) in DCM (8 mL) was added TFA (2 mL). After 40 min, the
reaction mixture was concentrated. The residue was taken up in toluene (30 mL) and the mixture was concentrated. The product was obtained as colourless oil (54 mg, 0.24 mmol, 95%). H NMR (400 MHz, CDC ) δ (ppm) 5.15 (bs, 2H), 4.26-4.18 (m, 2H), 3.71-3.60 (m, 4H), 3.35-3.27 (m, 2H), 2.08 (s, 3H).
Example 12: Preparation of compound 105
To a mixture of BCN-GABA (101 ) (67 mg, 0.24 mmol) and 104 (54 mg, 0.24 mmol) in DCM (20 mL) were added A/-(3-dimethylaminopropyl)-A/'-ethylcarbodiimide hydrochloride (EDCI.HCI; 55 mg, 0.29 mmol) and DMAP (2.8 mg, 23 μιηοΙ). The mixture was stirred for 16 and washed with a saturated aqueous solution of NH4CI (20 mL). After separation, the aqueous layer was extracted with DCM (20 mL). The combined organic layers were dried (Na2S04) and concentrated. The residue was purified with column chromatography (MeOH in DCM 0→ 10%). The product was obtained as a colourless thick oil (50 mg, 0.10 mmol, 42%). H NMR (400 MHz, CDCI3) δ (ppm) 5.83-5.72 (m, 1 H), 5.14-5.04 (m, 1 H), 4.23-4.19 (m, 2H), 4.15 (d, J = 8.1 Hz, 2H), 3.67-3.57 (m, 4H), 3.29-3.18 (m, 4H), 2.41-2.32 (m, 2H), 2.31-2.15 (m, 6H), 2.10 (s, 3H), 1.85 (quintet, J = 6.6 Hz, 2H), 1.65-1.49 (m, 2H), 1.38-1.28 (m, 1 H), 1.00-0.89 (m, 2H)
Example 13: Preparation of compound 106
To a solution of 105 (50 mg, 0.10 mmol) in MeOH (10 mL) was added K2CO3 (43 mg, 0.31 mmol). The mixture was stirred for 3h and diluted with a saturated aqueous solution of NH4CI (20 mL). The mixture was extracted with DCM (3x20 mL). The combined organic layers were dried (Na2S04) and concentrated. The product was obtained as a colourless film (39 mg, 0.09 mmol, 88%). Ή NMR (400 MHz, CDCI3) δ (ppm) 6.25 (bs, 1 H), 5.26-5.18 (m, 1 H), 4.15 (d, J = 8.0 Hz, 2H), 3.77-3.71 (m, 2H), 3.63-3.53 (m, 4H), 3.33-3.27 (m, 2H), 3.27-3.17 (m, 2H), 2.45-2.34 (m, 2H), 2.34-2.14 (m, 6H), 1.85 (quintet, J = 6.7 hz, 2H), 1.65-1.48 (m, 2H), 1.41-1.28 (m, 1 H), 1.01-0.88 (m, 2H).
Example 14: Preparation of compound 107
To a solution of 106 (152 mg, 0.34 mmol) in DCM (20 mL) were added p-nitrophenyl chloroformate (PNP-COCI; 69 mg, 0.34 mmol) and pyridine (28 μί, 27 mg, 0.34 mmol). The mixture was stirred for 1.5 h and concentrated. The residue was purified with column chromatography (50%→ 100% EtOAc in heptane). The product was obtained as a colourless thick oil (98 mg, 0.16 mmol, 47%). Ή NMR (400 MHz, CDCI3) δ (ppm) 8.31-8.26 (m, 2H), 7.46- 7.40 (m, 2H), 5.69-5.59 (m, 1 H), 4.98-4.91 (m, 1 H), 4.46-4.42 (m, 2H), 4.18 (d, J = 8.1 Hz, 2H), 3.79-3.75 (m, 2H), 3.69-3.64 (m, 2H), 3.33-3.24 (m, 4H), 2.39-2.31 (m, 2H), 2.32-2.18 (m, 6H), 1.84 (quintet, J = 6.3 Hz 2H), 1.65-1.50 (m, 2H), 1.35 (quintet, J = 8.5 Hz, 1 H), 1.01-0.91 (m, 2H).
Example 15: Preparation of linker-conjugate 80
To a solution of Val-Cit-PABC-Ahx-May.TFA (20 mg; 15.6 μηηοΙ) in DMF (0.50 mL) were added triethylamine (6.5 μΙ; 4.7 mg; 47 μητιοΙ) and a solution of 107 (19 mg, 31 μιηοΙ) in DMF (31 1 μΙ_). The mixture was left standing for 20 h and 2,2'-(ethylenedioxy)bis(ethylamine) (13.7 μΙ_, 14 mg, 94 μιηοΙ) was added. After 2 h, extra 2,2'-(ethylenedioxy)bis(ethylamine) (13.7 μΙ_, 14 mg, 94 μητιοΙ) was added. After 1.5 h, the reaction mixture was purified by RP HPLC (C18, 30%→ 90% MeCN (1 % AcOH) in water (1 % AcOH). The obtained product was additionally purified by silica column chromatography (DCM→ MeOH/DCM 1/4). The desired product was obtained as a white film (16 mg, 9.9 μπιοΙ, 63%). LCMS (ESI+) calculated for C77HnoCINi2022S+ (M-H20+H+) 1621.73 found 1621.74.
Example 16: Preparation of compound 109
To a solution of 2-(2-(2-(2-aminoethoxy)ethoxy)ethoxy)ethanol (539 mg, 2.79 mmol) in DCM (100 mL) were added BCN-OSu (0.74 g, 2.54 mmol) and Et3N (1.06 mL, 771 mg, 7.62 mmol). The resulting solution was stirred for 2.5 h and washed with a saturated aqueous solution of NH4CI (100 mL). After separation, the aqueous phase was extracted with DCM (100 mL). The combined organic phases were dried (Na2S04) and concentrated. The residue was purified with column chromatography (MeOH in DCM 0→ 10%). The product was obtained as a colourless oil (965 mg, 2.61 mmol, quant). H NMR (400 MHz, CDCI3) δ (ppm) 5.93 (bs, 1 H), 4.14 (d, J = 8.0 Hz, 2H), 3.77-3.69 (m, 4H), 3.68-3.59 (m, 8H), 3.58-3.52 (m, 2H), 3.42-3.32 (m, 2H), 2.35-2.16 (m, 6H), 1.66-1.51 (m, 2H), 1 .36 (quintet, J = 8.7 Hz, 1 H), 0.99-0.87 (m, 2H).
Example 17: Preparation of compound 110
To a solution of 109 (0.96 g, 2.59 mmol) in DCM (50 mL) was added p-nitrophenyl chloroformate (680 mg, 3.37 mmol) and Et3N (1.08 mL, 784 mg, 7.75 mmol). The mixture was stirred for 16 h and concentrated. The residue was purified twice with column chromatography (20% → 70% EtOAc in heptane (column 1 ) and 20%→ 100% EtOAc in heptane (column 2)). The product was obtained as a slightly yellow thick oil (0.91 g, 1.70 mmol, 66%). H NMR (400 MHz, CDCI3) δ (ppm) 8.31-8.26 (m, 2H), 7.42-7.37 (m, 2H), 5.19 (bs, 1 H), 4.47-4.43 (m, 2H), 4.15 (d, J = 8.0 Hz, 2H), 3.84-3.80 (m, 2H), 3.74-3.61 (m, 8H), 3.59-3.53 (m, 2H), 3.42-3.32 (m, 2H), 2.35-2.16 (m, 6H), 1.66-1.50 (m, 2H), 1.40-1.30 (m, 1 H), 1.00-0.85 (m, 2H).
Example 18: Preparation of linker-conjugate 77
To a solution of Val-Cit-PABC-Ahx-May.TFA (23.4 mg; 18.2 μηηοΙ) in DMF (0.50 mL) were added triethylamine (6.5 μΙ; 4.7 mg; 47 μηηοΙ) and a solution of 110 (12.5 mg, 23.4 μηηοΙ) in DMF (373 [it). The mixture was left standing for 42 h and 2,2'-(ethylenedioxy)bis(ethylamine) (13.7 μί, 14 mg, 94 μητιοΙ) was added. After 4 h, the reaction mixture was purified by RP HPLC (C18, 30%→ 90% MeCN (1 % AcOH) in water (1 % AcOH). The obtained product was additionally purified by silica column chromatography (DCM→ MeOH/DCM 1/4). The desired product was obtained as a
colourless film (19.5 mg, 12.5 μηηοΙ, 68%). LCMS (ESI+) calculated for C77HnoCINio02iS+ (M- Η2Ο+Ι-Γ) 1545.75 found 1546.82.
Example 19: Preparation of linker-conjugate 78
A solution of Val-Cit-PABC-Ahx-May.TFA (20 mg; 15.6 μηηοΙ) in DMF (0.50 mL) were added triethylamine (6.5 μΙ; 4.7 mg; 47 μητιοΙ) and a solution of compound 99 (prepared via activation of compound 58 as disclosed in and prepared according to Example 50 of PCT/NL2015/050697 (WO 2016/053107); 24 mg, 46 μηηοΙ) in DMF (293 μί). The mixture was left standing for 21 h and 2,2'-(ethylenedioxy)bis(ethylamine) (14 μί, 14 mg, 96 μιηοΙ) was added. After 2 h, extra 2,2'- (ethylenedioxy)bis(ethylamine) (7 μΙ_, 7.1 mg, 48 μιηοΙ) was added. After 1 h, the reaction mixture was purified by RP HPLC (C18, 30% → 90% MeCN (1 % AcOH) in water (1 % AcOH). The obtained product was additionally purified by silica column chromatography (DCM→ MeOH/DCM 1/4). The desired product was obtained as a colourless film(16 mg, 10 μιηοΙ, 64%). LCMS (ESI+) calculated for C73H103CIN1 1021 S+ (M-H20+H+) 1536.67 found 1536.75

71 R : H
PNP-COCI
7 722 R R : = P PNNPP 1
73 R = CO-VC-PAB-Ahx-May VC-PAB-Ahx-May
Example 20-1: Preparation of 70
To a solution of BCN-OH (2.0 g, 13.31 mmol) in DCM (200 mL) under a nitrogen atmosphere was added chlorosulfonyl isocyanate (1.16 mL, 13.31 mmol) and the resulting solution was stirred at rt for 30 min. Then, Et3N (3.7 mL, 26.62 mmol) was added dropwise followed by the dropwise addition of 2-(2-aminoethoxy)ethanol (1.47 mL, 14.64 mmol). After 15 min, sat. aqueous NhUCI solution (200 mL) was added and the layers were separated. The water phase was extracted with DCM (2 x 150 mL), the combined organic layers were dried over sodium sulphate, filtered and concentrated in vacuo. Flash chromatography (0 - 10 % MeOH in DCM) afforded the product (2.87 g, 7.96 mmol, 60%). Ή-NMR (400 MHz, CD3OD): δ 4.30 (d, J = 8.4 Hz, 2H), 3.72-3.67 (m, 2H), 3.61 (t, J = 5.2 Hz, 2H), 3.59-3.55 (m, 2H), 3.25 (t J = 5.2 Hz, 2H), 2.38-2.20 (m, 6H), 1.74- 1.58 (m, 2H), 1 .45 (quint, J = 8.8 Hz, 1 H), 1.07-0.95 (m, 2H). Example 20-2: Preparation of 72
To a stirring solution of 70 (47 mg, 0.13 mmol) in DCM (10 mL) was added CSI (1 1 [it, 18 mg, 0.13 mmol). After 30 min, Et3N (91 μί, 66 mg, 0.65 mmol) and a solution of diethanolamine (16 mg, 0.16 mmol) in DMF (0.5 mL) were added (provides intermediate 71 ). After 30 minutes p- nitrophenyl chloroformate (52 mg, 0.26 mmol) and Et3N (54 μί, 39 mg, 0.39 mmol) were added.
After an additional 4.5 h, the reaction mixture was concentrated and the residue was purified by gradient column chromatography (33 → 66% EtOAc/heptane (1 % AcOH)) to afford 72 as colourless oil (88 mg, 0.098 mmol, 75%). Ή NMR (400 MHz, CDCIs) δ (ppm) 8.28-8.23 (m, 4H), 7.42-7.35 (m, 4H), 4.52 (t, J = 5.4 Hz, 4H), 4.30 (d, J = 8.3 Hz, 2H), 4.27-4.22 (m, 2H), 3.86 (t, J = 5.3 Hz, 4H), 3.69-3.65 (m, 2H), 3.64-3.59 (m, 2H), 3.30-3.22 (m, 2H), 2.34-2.14 (m, 6H), 1.62-1.46 (m, 2H), 1 .38 (quintet, J = 8.7 Hz, 1 H), 1.04-0.92 (m, 2H).
Example 21: Preparation of linker-conjugate 73
A solution of 72 (3.9 mg, 4.3 μηηοΙ) and Et3N (3.0 μΙ_, 2.2 mg, 21.5 μηηοΙ) in DMF (1 mL) was added to a solution of Val-Cit-PABC-Ahx-May.TFA (10 mg, 8.6 μηηοΙ) in DMF (100 μΙ_). The mixture was allowed to react o.n. and was subsequently concentrated. The residue was purified via reversed phase (C18) HPLC chromatography (30 → 90% MeCN (1 % AcOH) in H2O (1 % AcOH) to give product 73 (3.9 mg, 1.32 μηηοΙ, 31 %). LRMS (ESI+) m/z calcd for C136H196CI2N22O43S2 (M+2H+)/2 =1480.13; found 1480.35. LRMS (ESI+) m/z calcd for C85H119CIN14O31S2 (M+2H+)/2 = 965.36; found 965.54. As a side-product, the mono-Ahx-May substituted derivative of 73 was isolated (not depicted). LRMS (EST) calculated for
2+ m/z 965.36 found 965.54.

Example 22: Preparation of 75
To a suspension of NH2-Val-Ala-OH (16 mg, 0.085 mmol) in DMF (0.5 mL) were added a solution of 99 (22 mg, 0.042 mmol) in DMF (0.5 mL) and Et3N (21 mg, 29 μί, 0.21 mmol). The resulting reaction mixture was rolled for 26 h and poured out in a mixture of DCM (10 mL) and potassium phosphate buffer (pH 3.0, 10 mL). After separation, the aqueous phase was extracted with DCM (20 mL). The combined organic layers were dried (Na2S04) and concentrated. The residue was purified by column chromatography (50% EtOAc in heptane→ EtOAc (1 % AcOH in eluens). The product was obtained as a colourless film (18 mg, 31 μηηοΙ, 75%). H NMR (400 MHz, CDCI3) δ (ppm) 7.02 (d, J = 7.1 Hz, 1 H), 6.29 (bs, 1 H), 5.92 (d, J = 9.0 Hz, 1 H), 4.56(quintet, J = 7.1 Hz, 1 H), 4.42-4.35 (m, 1 H), 4.28 (d, J = 8.2 Hz, 2H), 4.10-4.01 (m, 2H), 3.72-3.55 (m, 4H), 3.35-
3.25 (m, 2H), 2.35-2.10 (m, 6H), 1.63-1.48 (m, 2H), 1.45 (d, J = 7.2 Hz, 3H), 1.39 (quintet, J = 8.9 Hz, 1 H), 1.02-0.94 (m, 2H), 0.97 (d, J = 6.8 Hz, 3H), 0.92 (d, J = 6.8 Hz, 3H).
Example 23: Preparation of linker-conjugate 76
To a vial containing 2-ethoxy-1-ethoxycarbonyl-1 ,2-dihydroquinoline (2.6 mg, 1 1 μητιοΙ) was added a solution of 75 (6.1 mg, 1 1 μητιοΙ) in a mixture of MeOH and DCM (5/95, 1.0 mL). The resulting mixture was left for 30 min. To the reaction mixture was added NH2-PBD (5.0 mg, 6.9 μιηοΙ) in a mixture of MeOH and DCM (5/95, 0.5 mL). The resulting mixture was left standing for 74 h and concentrated. The residue was purified by silica gel chromatography (DCM→ MeOH/DCM 1/9). The product was obtained as a colourless film (2.6 mg, 2.03 μιηοΙ). LCMS (EST) calculated for C66H76N9Oi6S+ (M+H+) 1282.51 found 1282.70
Antibodv-druq-conjuqates production: Example 24-32 Example 24: Conjugation of 13b with 30 to obtain conjugate 96 (VII)
The bioconjugate according to the invention was prepared by conjugation of compound 30 as linker-conjugate to modified biomolecule 13b as biomolecule. To a solution of trastuzumab(azide)2 (13b) (15.5 mL, 255 mg, 16.47 mg/ml in PBS pH 7.4) was added DMA (1 .45 mL) and compound 30 (255 μί, 40 mM solution DMA). The reaction was incubated overnight at rt followed by purification on a HiLoad 26/600 Superdex200 PG column (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the reduced sample showed one major heavy chain product (observed mass 50938 Da, approximately 80% of total heavy chain fragment), corresponding to the conjugated heavy chain. Example 25: Conjugation of 13b with 33 to obtain conjugate 95 (VIII)
The bioconjugate according to the invention was prepared by conjugation of compound 33 as linker-conjugate to modified biomolecule 13b as biomolecule. To a solution of trastuzumab(azide)2 (13b) (607 μί, 10 mg, 16.47 mg/ml in PBS pH 7.4) was added MilliQ (50 μί) and compound 33 (10 μί, 40 mM solution in DMA). The reaction was incubated overnight at rt followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the reduced sample showed one major heavy chain product (observed mass 50982 Da, approximately 80% of total heavy chain fragment), corresponding to the conjugated heavy chain. Example 26: Conjugation of 13c with 30 to obtain conjugate 98 (X)
The bioconjugate according to the invention was prepared by conjugation of compound 30 as linker-conjugate to modified biomolecule 13c as biomolecule. To a solution of trastuzumab(azide)2 (13c) (14.25 mL, 250 mg, 17.55 mg/ml in PBS pH 7.4) was added DMA (1 .4 mL) and compound 30 (250 [it, 40 mM solution DMA). The reaction was incubated overnight at rt followed by purification on a HiLoad 26/600 Superdex200 PG column (GE Healthcare) on an AKTA Purifier-10
(GE Healthcare). Mass spectral analysis of the reduced sample showed one major heavy chain product (observed mass 50969 Da, approximately 70% of total heavy chain fragment), corresponding to the conjugated heavy chain. Example 27: Conjugation of 13c with 33 to obtain conjugate 97 (IX)
The bioconjugate according to the invention was prepared by conjugation of compound 33 as linker-conjugate to modified biomolecule 13c as biomolecule. To a solution of trastuzumab(azide)2 (13c) (14.25 ml_, 250 mg, 17.55 mg/ml in PBS pH 7.4) was added compound 33 (188 μΙ_, 40 mM solution DMA). The reaction was incubated overnight at rt followed by purification on a HiLoad 26/600 Superdex200 PG column (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the reduced sample showed one major heavy chain product (observed mass 51020 Da, approximately 90% of total heavy chain fragment), corresponding to the conjugated heavy chain. Example 28: Conjugation of 13d with 78 to obtain conjugate 82 (I)
A bioconjugate according to the invention was prepared by conjugation of compound 78 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (8.18 ml_, 270 mg, 33.0 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (7.12 ml_), DMF (2.48 mL) and compound 78 (225 μΙ_, 40 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a HiLoad 26/600 Superdex200 PG (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 25921 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 1.90.
Example 29: Conjugation of 13d with 80 to obtain conjugate 83 (II)
A bioconjugate according to the invention was prepared by conjugation of compound 80 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (8.18 mL, 270 mg, 33.0 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (7.12 mL), DMF (2.49 mL) and compound 80 (210 [it, 40 mM solution in DMF). The reaction was incubated at rt for approximately 40 hrs followed by purification on a HiLoad 26/600 Superdex200 PG (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator- digested sample showed one major product (observed mass 26010 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 1.93.
Example 30: Conjugation of 13d with 77 to obtain conjugate 81 (III)
A bioconjugate according to the invention was prepared by conjugation of compound 77 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (8.18 mL, 270 mg, 33.0 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (5.328 mL),
DMF (4.28 mL) and compound 77 (225 [it, 40 mM solution in DMF). After overnight incubation at rt RP-HPLC analysis indicated an incomplete reaction. Additional compound 77 (45 μΙ_, 40 mM solution in DMF) was added to the reaction mixture and followed by overnight incubation at rt. The reaction was dialyzed against PBS pH 7.4 (0.5 L) and purified on a HiLoad 26/600 Superdex200 PG (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 25931 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 1.91. Example 31: Conjugation of 13d with 73 to obtain conjugate 84 (V)
A bioconjugate according to the invention was prepared by conjugation of compound 73 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (4.09 mL, 135 mg, 33.0 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (2.66 mL), DMF (2.14 mL) and compound 73 (1 13 μί, 40 mM solution in DMF). The reaction was incubated at rt overnight followed by dialysis against PBS pH 7.4 (0.5L) and purification on a HiLoad 26/600 Superdex200 PG (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 227331 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP- HPLC analysis of the reduced sample indicated an average DAR of 3.78.
Example 32: Conjugation of 13d with 76 to obtain conjugate 85 (VI)
The bioconjugate according to the invention was prepared by conjugation of 76 as linker- conjugate to modified biomolecule 13d as biomolecule. To a solution of trastuzumab(6-N3- GalNAc)2 (13d) (320 [it, 7.2 mg, 22.5 mg/ml in PBS pH 7.4) was added 76 (44.5 μί, 10 mM solution DMF) and DMF (66 μί). The reaction was incubated two times overnight at rt followed by dilution with PBS (1 mL) and concentration using an Amicon Ultra-0.5, Ultracel-10 Membrane spinfilters (Millipore). Next the conjugate was purified on a HiLoad 26/600 Superdex200 PG column (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the sample after fabricator™ treatment showed one major Fc/2 product (observed mass 25649 Da, approximately 90% of total Fc/2), corresponding to the conjugate 85.
Examples 33-39: Efficacy, tolerability and stability studies
Example 33a: HER2 efficacy studies [T226 PDX-model]
Female SHO mice (Crl:SHO-Prkdcscid Hrhr), 6- to 9-week-old at the beginning of the experimental phase, obtained from Charles River Laboratories (France), weighing 15-25 grams, were grafted with 20 mm3 tumour (T226) fragment in the subcutaneous tissue. Healthy mice weighing at least 17 g were included in the grafting procedure. Mice were allocated to different groups according to their tumour volume to give homogenous mean and median tumour volume in each treatment arms. Groups of 5 mice with established growing tumours and tumour volume
ranging 60 to 200 mm3 were injected i.v. with either vehicle, Kadcyla (1.3 mg/kg (mpk)), ADCs 81, 82, 83 and 84 (at 9 mg/kg). Tumours were measured twice weekly for a period of 60 days. The results on tumour volume are depicted in figure 8A (median data depicted). Example 33b: HER2 efficacy studies [HBCx-13b PDX-model]
Female SHO mice (Crl:SHO-Prkdcscid Hrhr), 6- to 9-week-old at the beginning of the experimental phase, obtained from Charles River Laboratories (France), weighing 15-25 grams, were grafted with 20 mm3 tumour (HBCx-13b) fragment in the subcutaneous tissue. When the tumour volume was in the range of 62 and 256 mm3, mice were allocated according to their tumour volume to give homogenous mean and median tumour volume in each treatment arm. Groups of five mice were injected twice (at day 0 and day 8) i.v. with a dose of either vehicle, ADC 95, 96, 97 or 98 (at 6 mg/kg). Tumours were measured twice weekly for a period of 60 days. The results on tumour volume are depicted in figure 8C (median data depicted). Example 33c: HER2 efficacy studies [HBCx-15 PDX-model]
Female SHO mice (Crl:SHO-Prkdcscid Hrhr), 6- to 9-week-old at the beginning of the experimental phase, obtained from Charles River Laboratories (France), weighing 15-25 grams were grafted with 20 mm3 tumour (HBCx-15) fragment in the subcutaneous tissue. When the tumour volume was in the range of 62 and 256 mm3, mice were allocated according to their tumour volume to give homogenous mean and median tumour volume in each treatment arm. Groups of five mice were injected i.v. with a single dose of either vehicle, Kadcyla (9 mg/kg) or 85 (at 0.5 mg/kg). Tumours were measured twice weekly for a period of 60 days. The results on tumour volume are depicted in figure 8B (mean data depicted). Example 33d: HER2 efficacy studies [T226 PDX-model]
Female SHO mice (Crl:SHO-Prkdcscid Hrhr), 6- to 9-week-old at the beginning of the experimental phase, obtained from Charles River Laboratories (France), weighing 15-25 grams, were grafted with 20 mm3 tumour (T226) fragment in the subcutaneous tissue. Healthy mice weighing at least 17 g were included in the grafting procedure. Mice were allocated to different groups according to their tumour volume to give homogenous mean and median tumour volume in each treatment arms. Groups of 5 mice with established growing tumours and tumour volume ranging 60 to 200 mm3 were injected i.v. with either vehicle, Kadcyla (at 3 and 9 mg/kg (mpk)) or 84 (at 3 and 9 mg/kg). Tumours were measured twice weekly for a period of 60 days. The results on tumour volume are depicted in figure 8D (mean data depicted).
Example 34a: HER2 tolerability studies
Sprague Dawley rats (3 males and 3 females per group): OFA:SD, 6-week-old at the beginning of the experimental phase, obtained from Charles River Laboratories, Saint-Germain-Nuelles, France, were treated with 97 ((1 ) at 20 mg/kg and (2) 40 mg/kg), or 98 ((1 ) at 20 mg/kg and (2) 40 mg/kg) intravenous (bolus) injection using a microflex infusion set introduced into a tail vein (2
ml_ kg at 1 mL/min). One group of animals (control) was treated with vehicle. After dosing, all animals were maintained for a 5-day observation period. Surviving animals were killed on day 5. Each animal were weighed at the time of randomization/selection, prior to dosing (day 0) and on days 2 and 4. All animals (including any found dead or killed moribund) were submitted to full necropsy procedures. Histopathological examinations of the liver, spleen and sciatic nerve was performed for all animals. Blood samples (including for animals killed moribund) were collected and subjected to determination of both hematological as well as serum clinical chemistry parameters. The results demonstrate that the animals were able to tolerate the conjugate according to the invention (97) and the conjugate with a prior art linker (98) equally well. No significant differences in platelet count and body weight were observed, while both parameters decreased rapidly for the Kadcy la-treated rats.
Example 34b: HER2 tolerability studies
Sprague Dawley rats (2 females per group), 6-week-old at the beginning of the experimental phase, obtained from Charles River Laboratories, USA, were treated with ADC 84 (at 20 mg/kg (mpk), 35 mpk, 50 mpk and 60 mpk), or ADCs 81 , 82 and 83 (at 40 mg/kg (mpk), 70 mpk, 100 mpk and 120 mpk) intravenous (bolus) injection using a microflex infusion set introduced into a tail vein (2 mL/kg at 1 mL/min). One group of animals (control) was treated with vehicle and another group was treated with Kadcyla (at 20 mg/kg (mpk), 35 mpk, 50 mpk and 60 mpk). After dosing, all animals were maintained for a 12-day observation period. Surviving animals were killed on day 12. Each animal was weighed at the time of randomization/selection, prior to dosing (day 0) and on all consecutive days of treatment. All animals (including any found dead or killed moribund) were submitted to full necropsy procedures. Gross histopathological examinations of the liver, spleen and sciatic nerve was performed for all animals. Blood samples (including for animals killed moribund) were collected and subjected to determination of both hematological parameters. The results for the percentage bodyweight loss of the rats for the different dose regimes per ADC are depicted in Figure 7. It was clear form these results that the bodyweight-based MTD for Kadcyla is between 50 mpk and 60 mpk whereas for the bodyweight-based MTD for ADC 84 (DAR4) was found to be between >60 mpk. For the ADCs 81 , 82 and 83 (all DAR2) the bodyweight-based MTDs were found to be >120 mpk with no significant bodyweight loss observed for any of these ADCs at the highest dose-level.

Example 35: Synthesis of compound 42
To a solution of DIBO (0.220 g, 1.00 mmol, 1.00 equiv) in DCM (15.0 mL) under nitrogen was added dropwise chlorosulfonyl isocyanide (CSI, 88.1 μΙ_, 1.00 mmol, 1.00 equiv). The resulting reaction mixture was stirred at room temperature for 20 minutes, followed by the dropwise addition of Et3N (282 μΙ_, 2.00 mmol, 2.00 equiv). The reaction mixture was stirred for 5 minutes, followed by the addition of 2-(2-aminoethoxy)ethanol (2-AEE, 1 12 1 .10 mmol, 1.10 equiv). The reaction was quenched after stirring for 20 minutes at room temperature through the addition of sat. aq. NhUCI (pH 4.0, 30.0 mL). The resulting mixture was extracted with DCM (25 mL, 2*) and EtOAc (20 mL, 2*) and the combined organic layers were dried (Na2S04) and then concentrated in vacuo. The residue was purified by flash column chromatography (0-7% MeOH in DCM), affording compound 42 (422 mg, 98%) as a light yellow oil. Ή NMR (CDCb): 7.60-7.57 (m, 1 H), 7.47-7.40 (m, 2H), 7.40-7.27 (m, 5H), 5.55-5.51 (m, 1 H), 3.60-3.53 (m, 4H), 3.48-3.42 (m, 2H), 3.35-3.28 (m, 6H), 3.28-3.22 (m, 2H), 2.93-2.82 (m, 1 H). LCMS (ESI+) calculated for C2iH22N2Na06S+ (M+Na+) 453.1 1 found 452.98
Example 36: Synthesis of compound 43
To a solution of compound 42 (0.192 g, 0.446 mmol, 1.00 equiv) in DCM (30.0 mL) under nitrogen was added dropwise chlorosulfonyl isocyanide (CSI, 38.8 μί, 0.446 mmol, 1.00 equiv). The resulting reaction mixture was stirred at room temperature for 20 minutes, followed by the dropwise addition of Et3N (31 1 μί, 2.23 mmol, 5.00 equiv). The resulting reaction mixture was stirred for 5 minutes at room temperature, followed by the addition of a solution of diethanolamine (DEA, 51 .3 [it, 0.535 mmol, 1.20 equiv) in DMF (1 .5 mL). The reaction mixture was stirred for 60
minutes at room temperature, followed by the addition of 4-nitrophenyl chloroformate (0.180 g, 0.893 mmol, 2.00 equiv) and additional Et3N (187 μΙ_, 1.34 mmol, 3.01 equiv). The resulting reaction mixture was stirred for 18 hours and then concentrated in vacuo. The residue was purified by flash column chromatography (0-6% MeOH in DCM), affording compound 43 (187 mg) as a white solid. Ή NMR (CDCb): 8.29-8.18 (m, 5H), 7.41-7.28 (m, 1 1 H), 5.85-5.72 (m, 1 H), 5.61- 5.55 (s, 1 H), 4.59-4.49 (t, J = 5.26 Hz, 1 H), 4.47-4.36 (t, J = 5.35 Hz, 4H), 4.18-4.08 (m, 2H), 3.78-3.67 (t, J = 5.33 Hz, 4H), 3.65-3.49 (m, 4H), 3.35-3.25 (m, 2H), 3.26-3.15 (m, 1 H), 3.01-2.93 (m, 1 H). LCMS (ESI+) calculated for C^HssNeNaO^" (M+Na+) 993.15 found 992.97 Example 37: Preparation of linker-conjugate 44
To a solution of compound 43 (1 1.4 mg, 1 1.7 μιηοΙ, 1.00 equiv) in DCM (0.400 mL) was added Et3N (6.00 [it, 58.7 μηηοΙ, 5.00 equiv), followed by the addition of a solution of Val-Cit-PAB- Maytansin TFA (vc-PABC-May.TFA, 30.0 mg, 23.4 μηηοΙ, 2.00 equiv) in DMF (450 μΙ_). The resulting reaction mixture was left at room temperature for 96 hours. The reaction was quenched with 2,2-(ethylenedioxy)bis(ethylamine) (15.0 μΙ_, 99.7 μητιοΙ, 8.52 equiv) and left at room temperature for 2 hours. The mixture was then purified by HPLC. Concentration of the collected fraction in vacuo yielded compound 44 (10.9 mg) as a light pink solid. LCMS (EST) calculated for Ci4oHi9oCI2N22037S22+ (M-2H20-2C02+2H+) 1453.13 found 1453.23 Example 38-41 : Preparation of linker-conjugate 48
Fmoc-CI, NaHCO;
H?N' "OH FmocHN OH
Dioxane/H ?0
45
1) CSI, Et3N 2) PNP-COCI
DEA Et N

Dioxane (30 mL) and sat. aq. NaHCCh (60 mL) were mixed and the resulting suspension was filtered over a glassfilter. To the this solution was added 5-amino-1-pentanol (2.03 g, 19.7 mmol, 1.00 equiv), followed by a solution of Fmoc-CI (5.16 g, 19.9 mmol, 1.01 equiv) in dioxane (30 mL). The reaction was stirred at room temperature for 2.5 hours and then quenched with 1 M aq. HCI (300 mL). The mixture was extracted with EtOAc (600 mL) and the organic layer was washed with 1 M aq. HCI (250 mL), sat. aq. NaHCCb (150 mL), brine (150 mL), dried (Na2S04) and concentrated in vacuo. The residue was purified by flash column chromatography (0-2% MeOH in CHC ), providing compound 45 (5.39 g, 84%) as a white solid. Ή NMR (CDCI3): 7.77 (d, J = 7.47 Hz, 2H), 7.59 (d, J = 7.53 Hz, 2H), 7.46-7.37 (m, 2H), 7.37-7.28 (m, 2H), 4.86-4.74 (bs, 1 H), 4.51- 4.36 (m, 2H), 4.21 (t, J = 6.91 Hz, 1 H), 3.65 (q, J = 5.29 Hz, 2H), 3.26-3.03 (m, 2H), 1.61-1.48 (m, 4H), 1.48-1.26 (m, 3H).
Example 39: Synthesis of compound 46
To a solution of compound 45 (0.397 g, 1.22 mmol, 1.00 equiv) in DCM (55.0 mL) under nitrogen was added dropwise chlorosulfonyl isocyanide (CSI, 106 μί, 1.22 mmol, 1.00 equiv) and the resulting reaction mixture was stirred at room temperature for 20 minutes. Et3N (0.850 mL, 6.10 mmol, 5.00 equiv) was added dropwise and the mixture was stirred for 10 minutes at room temperature, followed by the addition of a solution of diethanolamine (DEA, 0.144 g, 1.37 mmol, 1.12 equiv) in DMF (1.7 mL). The reaction mixture was stirred for 2 hours at room temperature, followed by the addition of 4-nitrophenyl chloroformate (0.492 g, 2.44 mmol, 2.00 equiv) and additional Et3N (0.340 mL, 2.44 mmol, 2.00 equiv). The resulting reaction mixture was stirred for 18 hours and then concentrated in vacuo. The residue was diluted with DCM (100 mL) and sat. aq. NH4CI (pH = 3.3, 50 mL) was added. The resulting biphasic system was separated and the water layer was extracted with DCM (50 mL). The combined organic layers were dried (Na2S04) and then concentrated in vacuo. The residue was purified by flash column chromatography (0-5% MeOH in DCM), followed by a second purification by flash column chromatography (65% EtOAc in heptane), affording compound 46 (342 mg) as a white powder. H NMR (CDCI3): 8.54-8.32 (bs, 1 H), 8.27-8.21 (m, 4H), 7.76 (d, J = 7.38 Hz, 2H), 7.59 (d, J = 7.53 Hz, 2H), 7.42-7.33 (m, 6H), 7.33-7.27 (m, 2H), 4.86 (t, J = 5.72 Hz, 1 H), 4.51 (t, J = 5.45 Hz, 4H), 4.43 (d, J = 6.81 , 2H), 4.21 (t, J = 6.58, 1 H), 4.17-4.09 (m, 2H), 3.84 (t, J = 5.46 Hz, 4H), 3.19 (q, J = 7.50 Hz, 2H), 1.72-1.63 (m, 2H), 1.63-1.48 (m, 2H), 1.48-1.36 (m, 2H).
Example 40: Synthesis of compound 47
To a vial containing compound 46 (10.0 mg, 1 1.5 μιηοΙ, 1 .00 equiv) was added a solution of Et3N (8.00 [it, 57.7 μηηοΙ, 5.00 equiv) and Val-Cit-PABC-Maytansin TFA (vc-PABC-May.TFA, 30.0 mg, 23.4 μητιοΙ, 2.02 equiv) in DMF (450 μί). The resulting reaction mixture was left at room temperature for 72 hours. The reaction was quenched with 2,2-(ethylenedioxy)-bis(ethylamine) (15.0 [it, 99.7 μηηοΙ, 8.67 equiv) and left for 1.5 hours. Next, piperidine (10.0 μί, 101 μηηοΙ, 8.76 equiv) was added the mixture was left at room temperature for 1 hour and then purified by HPLC.
Concentration of the collected fraction in vacuo yielded compound 47 (10.0 mg) as a light yellow oil. LCMS (ESI+) calculated for Ci29Hi86CI2N22037S22+ (M-2H20-2C02+2H+) 1289.62 found 1290.15 Example 41: Preparation of linker-conjugate 48
To a solution of compound 47 (1.00 mg, 0.370 μιηοΙ, 1.00 equiv) in DMF (50.0 μΙ_) was added a 10% v/v solution of Et3N in DMF (3.6 [it, 2.58 μηηοΙ, 6.98 equiv), followed by a solution of OSu- activated monofluoro-substituted cyclooctyn (MFCO-Apa-OSu (obtained from Berry & Associates, Dexter, USA), 0.140 mg, 0.368 μηηοΙ, 0.99 equiv) in DMF (5 μΙ_). The resulting mixture was left at room temperature for 6 hours and then purified by HPLC. Concentration of the collected fraction in vacuo yielded compound 48 (0.95 mg) as a white solid. UPLC-MS (EST) calculated for Ci4i H205CI2FN2204oS2+ (M+2H+) 1484.19 found 1484.3
Example 42-44: Preparation of linker-conjugate 51

51
Example 42: Synthesis of compound 49
To a solution of 4-pentyn-1-ol (0.931 mL, 10.0 mmol, 1.00 equiv) in DCM (150 mL) was added dropwise chlorosulfonyl isocyanide (CSI, 0.870 mL, 10.0 mmol, 1 .00 equiv). The resulting reaction mixture was stirred at room temperature for 15 minutes, followed by the slow addition of Et3N (2.80 mL, 20.0 mmol, 2.00 equiv). The reaction mixture was stirred for 6 minutes, followed by the addition of 2-(2-aminoethoxy)ethanol (2-AEE, 1 .1 1 mL, 1 1.0 mmol, 1 .10 equiv). The reaction was quenched after stirring for 13 minutes at room temperature through the addition of sat. aq. NhUCI (pH 3.75, 150 mL). The resulting mixture was extracted with DCM (150 mL, 2*) and the combined organic layers were dried (Na2S04) and then concentrated in vacuo. The residue was purified by flash column chromatography (1-10% MeOH in DCM), affording compound 49 (392 mg) as a
yellow oil. Ή NMR (CDCIs): 6.10-5.90 (bs, 1 H), 4.37-4.25 (t, J = 6.21 Hz, 2H), 3.81-3.73 (m, 2H), 3.63 (t, J = 4.52 Hz, 2H), 3.61-3.56 (m, 2H), 3.43-3.27 (m, 2H), 2.38-2.25 (m, 2H), 2.00 (t, J = 2.70, Hz, 1 H), 1.90 (p, J = 6.45 Hz, 2H). Example 43: Synthesis of compound 50
To a solution of compound 49 (0.258 g, 0.877 mmol, 1.00 equiv) in DCM (60.0 mL) under nitrogen was added dropwise chlorosulfonyl isocyanide (CSI, 76.0 μΙ_, 0.877 mmol, 1.00 equiv) and the resulting reaction mixture was stirred at room temperature for 15 minutes. Et3N (0.61 1 mL, 4.39 mmol, 5.00 equiv) was added dropwise and the mixture was stirred for 5 minutes at room temperature, followed by the addition of a solution of diethanolamine (DEA, 100 μί, 1.04 mmol, 1.19 equiv) in DMF (5 mL). The reaction mixture was stirred for 35 minutes at room temperature, followed by the addition of 4-nitrophenyl chloroformate (0.356 g, 1.77 mmol, 2.00 equiv) and additional Et3N (0.367 mL, 2.63 mmol, 3.00 equiv). The resulting reaction mixture was stirred for 18 hours and then concentrated in vacuo. The residue was diluted with DCM (50 mL) and sat. aq. NH4CI (20 mL) was added. The resulting biphasic system was separated and the water layer was extracted with DCM (50 mL, 2*) and EtOAc (50 mL, 2*). The combined organic layers were dried (Na2S04) and then concentrated in vacuo. The residue was purified by flash column chromatography (0-6% MeOH in DCM), affording compound 50 (265 mg, -67% pure) as a yellow oil, containing circa 30% DMF, which was used without further purification. H NMR (CDCI3): 8.30- 8.21 (m, 4H), 7.42-7.34 (m, 4H), 5.92-5.80 (m, 1 H), 4.57-4.45 (m, 4H), 4.31-4.27 (m, 2H), 4.27- 4.23 (m, 2H), 3.85 (m, J = 5.42 Hz, 4H), 3.76-3.70 (m, 1 H), 3.70-3.64 (m, 2H), 3.64-3.58 (m, 3H), 3.35-3.21 (m, 2H), 2.33-2.23 (m, 2H), 2.02-1.96 (m, 1 H), 1.92-1.83 (m, 2H).
Example 44: Preparation of linker-conjugate 51
To a solution of compound 50 (15.1 mg, 1 1.6 μιηοΙ, 1.00 equiv) in DCM (0.400 mL) was added Et3N (8.15 μί, 58.4 μηηοΙ, 5.04 equiv), followed by the addition of a solution of Val-Cit-PABC- Maytansine TFA (vc-PABC-May.TFA, 30.0 mg, 23.4 μηηοΙ, 2.02 equiv) in DMF (450 μί). The resulting reaction mixture was left at room temperature for 48 hours. The reaction was quenched with 2,2-(ethylenedioxy)bis(ethylamine) (15.0 μί, 99.7 μητιοΙ, 8.60 equiv) and left for 2 hours at room temperature and then concentrated in vacuo. The residue was taken up in a total of 900 [it of DMF and then purified by HPLC. Concentration of the collected fraction in vacuo yielded compound 51 (13.1 mg) as a pink/red solid. LCMS (ESI+) calculated for Ci29Hi86CI2N22037S22+ (M- 2H20-2C02+2H+) 1385.1 1 found 1385.33

Example 45: Synthesis of 55
To a solution of 99 (1.44 g, 2.74 mmol) in DCM (120 mL) were added a solution of diaminoethanol (0.35g, 3.29 mmol) in DMF (8 mL) and Et3N (0.83 g, 1.15 mL, 8.22 mmol). The resulting mixture was stirred for 18 h and saturated aqueous NhUCI was added. After separation, the aqueous phase was extracted with dichloromethane (3 * 120 mL). The combined organic layers were dried (Na2S04) and concentrated. The residue was purified by silica chromatography (0→ 15% MeOH in DCM). The fractions containing the desired product were pooled and concentrated. The residue was dissolved in EtOAc (100 mL) and concentrated. The desired product was obtained as a colorless film (0.856 g, 1.74 mmol, 64%). Ή NMR (400 MHz, CDCIs) δ ppm 6.28 (bs, 1 H), 4.33- 4.30 (m, 2H, 4.28 (d, 2H, J = 8.2 Hz), 3.89-3.81 (m, 4H), 3.70-3.64 (m, 2H), 3.63-3.58 (m, 2H), 3.52 (t, 4H, J = 5.0 Hz), 3.32 (t, 2H, J = 4.8 Hz), 2.36-2.18 (m, 6H), 1.64-1.50 (m, 2H), 1.39 (quintet, 1 H, J = 8.6 Hz), 1.05-0.94 (m, 2H).
Example 46: Synthesis of 56
To a solution of 55 (635 mg, 1 .29 mmol) in DCM (40 mL) were added 4-nitrophenyl chloroformate (520 mg, 2.58 mmol) and Et3N (0.65 g, 0.90 mL). The resulting mixture was stirred for 20 h and concentrated. The residue was purified by silica chromatography (1st column: 50% → 100% EtOAc in heptane; 2nd column: 50%→ 100% EtOAc (1 % AcOH)). The fractions containing the
desired product were pooled and concentrated. The residue was dissolved in DCM (2 mL), heptane (8 mL) was added and the mixture was concentrated. The desired product was obtained as a white solid (306 mg, 0.37 mmol, 29%).Ή NMR (400 MHz, CDCIs) δ ppm 8.31-8.25 (m, 4H), 7.44-7.37 (m, 4H), 5.74-5.68 (m, 1 H), 4.53-4.45 (m, 4H), 4.36-4.31 (m, 2H), 4.26 (m, 2H, J = 8.2 Hz), 3.80-3.71 (m, 4H), 3.70-3.65 (m, 2H), 3.62-3.57 (m, 2H), 3.28 (q, 2H, J = 4.8 Hz), 2.35-2.15 (m, 6H), 1.60-1.50 (m, 2H), 1.36 (quintet, 1 H, J = 8.7 Hz), 1.04-0.94 (m, 2H).
Example 47: Synthesis of 57
To a solution of 55 (80 mg, 0.163 mmol) in DCM (10 mL) were added chlorosulfonyl isocyanate (CSI, 46 mg, 18 μί, 0.33 mmol), Et3N (82.8 mg, 1 14 μί, 0.815 mmol) and 2-(2- aminoethoxy)ethanol (43 mg, 41 μί, 0.41 mmol). After 2 hours of stirring, water (10 mL) was added and the layers were separated. After addition of EtOAc to the aqueous phase, the pH of the aqueous phase was adjusted to 4.0 through careful addition of aqueous HCI (1 N). The layers were separated and the aqueous phase was extracted with EtOAc (20 mL). The pH of the aqueous layer was 4 during extraction. The combined organic layers were dried (Na2S04) and concentrated. The product was purified by silica gel chromatography (0→20% MeOH in DCM). The fractions containing the desired product were pooled and concentrated. The residue was dissolved in EtOAc (6 mL), and the mixture was concentrated (2*). The desired product was obtained as a colorless thick oil (53 mg, 0.058 mmol, 36%). H NMR (400 MHz, CD3OD) δ ppm 4.36-4.22 (m, 8H), 3.75-3.50 (m, 20H), 3.25-3.20 (m, 6 H), 2.34-2.14 (m, 6H), 1.70-1.55 (m, 2H), 1 .44 (quintet, 1 H, J = 8.7 Hz), 1.04-0.94 (m, 2H).
Example 48: Synthesis of 58
To a solution of 57 (49 mg, 54 μητιοΙ) in DMF (0.5 mL) were added DCM (5 mL), 4-nitrophenyl chloroformate (22 mg, 107 μητιοΙ) and Et3N (27 mg, 38 μί, 270 μιηοΙ). The mixture was stirred for 2 days, concentrated and the residue was purified by silica gel chromatography (0→10% MeOH in DCM 2x). The desired product was obtained as a colorless film (4.5 mg, 3.6 μιηοΙ, 14%). Additionally, from the first silica gel column purification, fractions containing the intermediate mono-4-nitrophenylcarbonate functionalized product were pooled and concentrated. The resulting mono-functionalized product (27 mg, 25 μιηοΙ) was redissolved in DCM (2 mL) and 4-nitrophenyl chloroformate (5.1 mg, 25 μιηοΙ) and Et3N (7.6 mg, 10 μί, 75 μιηοΙ) were added. The resulting mixture was stirred for 19 h. and more 4-nitrophenyl chloroformate (6.5 mg, 32 μητιοΙ) was added. The mixture was stirred for an additional 4.5 h and concentrated. The residue was purified by silica column chromatography and afforded additional desired product as a colourless film. (1 1 mg, 8.9 μπιοΙ, 35%). 1 H NMR (400 MHz, CDCI3) δ ppm 8.31-8.25 (m, 4H), 7.44-7.39 (m, 4H), 6.18 (bs, 1 H), 6.05-5.96 (m, 1 H), 5.94-5.84 (m, 1 H), 4.47-4.43 (m, 4H), 4.37-4.24 (m, 8H), 3.80- 3.76 (m, 4H), 3.72-3.52 (m, 12H), 3.37-3.29 (m, 6H), 2.36-2.16 (m, 6H), 1 .65-1.45 (m, 2H), 1.38 (quintet, 1 H, J = 8.6 Hz), 1.03-0.93 (m, 2H).
Example 49: Preparation of linker-conjugate 59
To a solution of 58 (15.5 mg, 12.5 μηηοΙ) in DMF (400 μΙ_) were added Et3N (6.3 mg, 8.7 μΙ_) and a solution of vc-PABC-May.TFA (32 mg, 25 μιηοΙ) in DMF (480 μΙ_). The resulting mixture was left standing for 2 days after which 2,2'-(ethylenedioxy)bis(ethylamine) (14.6 μΙ_, 15 mg, 100 μιηοΙ) was added to quench the reaction. After 2 hour the reaction mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H20 (1 % AcOH). The desired product was obtained as white solid (18.1 mg, 5.5 μιηοΙ, 44%). LCMS (EST) calculated for Ci44H2i2CI2N25045S33+ ((M-2C02-2H20)+3H+)/3 1059.12 found 1059.71.

Example 50-1: Synthesis of 53a
To a solution of 110 (0.15 g; 0.28 mmol) in DCM (20 mL) were added a solution of diethanolamine (47 mg; 0.45 mmol) in DMF (1 mL) and Et3N (1 17 μί; 85 mg; 0.84 mmol). The resulting mixture was stirred at rt for 16 h, washed with a saturated aqueous solution of NH4CI, dried (Na2S04) and concenctrated. The residue was purified by flash column chromatography (DCM→ MeOH/DCM 1/9). The product was obtained as a colourless oil (95 mg; 0.19 mmol; 68%).1 H NMR (400 MHz, CDCI3) δ (ppm) 5.63 (bs, 1 H), 4.32-4.27 (m, 2H), 4.14 (d, 2H, J = 8.0 Hz), 3.89-3.77 (m, 4H), 3.73-3.68 (m, 2H), 3.67-3.60 (m, 8H), 3.58-3.53 (m, 2H), 3.52-3.44 (m, 4H), 3.40-3.32 (m, 2H), 2.35-2.15 (m, 6H), 1.65-1.50 (m, 2H), 1.42-1.30 (m, 1 H), 0.99-0.88 (m, 2H).
Example 50-2: Synthesis of 53b
To a solution of 53a (93 mg, 0.19 mmol) in DCM (20 mL) were added 4-nitrophenyl chloroformate (94 mg, 0.47 mmol) and triethylamine (132 μί; 96 mg; 0.95 mmol). The resulting reaction mixture was stirred for 17 h, washed with water (10 mL), dried (Na2S04) and concentrated. The residue was purified by flash column chromatography (DCM→ MeOH/DCM 1/9). The desired product was obtained as a slightly coloured oil (45 mg; 0.054 mmol; 28%) 1 H NMR (400 MHz, CDCI3) δ (ppm) 8.30-8.23 (m, 4H), 7.42-7.33 (m, 4H), 5.32-5.23 (m, 1 H), 4.44 (t, 4H, J = 5.4 Hz), 4.32- 4.26 (m, 2H), 4.14 (d, 2H, J = 8.0 Hz), 3.78-3.67 (m, 6H), 3.67-3.57 (m, 8H), 3.54 (t, 2H, J = 5.1 Hz), 3.40-3.30 (m, 2H), 2.33-2.13 (m, 6H), 1.64-1.46 (m, 2H), 1 .41-1 .27 (m, 1 H), 0.99-0.86 (m, 2H).
Example 51: Preparation of linker conjugate 54
To a solution of vc-PABC-Ahx-May (5.3 mg, 4.1 μηηοΙ) in DMF (499 μΙ_) were added Et3N (1 .4 μΙ_, 1.0 mg, 10.3 μιηοΙ) and a solution of 53b (1.7 mg, 2.0 μιηοΙ) in DMF (128 μΙ_). The resulting mixture was heated to 35 °C, left for 20 min., heated to 45 °C and left for 21 h. 2,2 - (Ethylenedioxy)bis(ethylamine) (6.0 μΙ_, 6.1 mg, 41 μητιοΙ) was added and after 1 hour the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H2O (1 % AcOH). The desired product was obtained as white solid (3.0 mg, 1.04 μητιοΙ, 52%). LCMS (ESI+) calculated for Ci4oH202CI2N2o04i2+ (M+2H+)/2 1444.69 found 1446.78.
Example 52: Preparation of linker-conjugate 60

A solution of 56 (17 μΙ_, 53 mg/mL in DMF, 1 .1 1 μηηοΙ), a solution of vc-PABC-Ahx-May.TFA (286 μΙ_, 10 mg/mL in DMF, 2.22 μηηοΙ, 2 equiv.) and a solution of Et3N (7.7 μΙ_, 10% in DMF, 5.5 μηηοΙ, 5 equiv.) were added together, mixed and left to stand at RT without stirring for 23 h. The reaction mixture was quenched with 2,2'-(ethylenedioxy)bis(ethylamine) (1.3 μΙ_, 8.9 μιηοΙ, 8 equiv.) and left standing for 1 h. The crude product was purified by preparative HPLC (30 to 90 % MeCN in H2O, 1 % AcOH, 50 fractions, product found in fractions 34 and 35). Yield: 1.8 mg (57%). Exact Mass = 2878.28. LC-MS (C18 Waters, 25 min): Rt = 14.07 min.; found m/z = 935, 920, 701 , 485.

Example 53: Synthesis of compound 61
A solution of 56 (1250 μΙ_, 80 mM in DMF, 100 μηηοΙ), a solution of vc-PAB-OH (80 mg, 210 μηηοΙ, 2.1 eguiv., in 2 mL DMF) and Et3N (84 μΙ_, 600 μιηοΙ, 6 eguiv.) were added together and stirred at
RT for 40 h. Bis-(p-nitrophenyl)carbonate ((PNP)2CO, 183 mg, 600 μηηοΙ, 6 equiv.) and Et3N (84 [it, 600 μιηοΙ, 6 equiv.) were added and the mixture was stirred at RT for 16 h. The mixture was then purified by silica column chromatography (12 g silica, 45 fractions, 20 mL/fraction, 20 mL/min, 0 to 15% MeOH in DCM, product found in fractions 26-32, Rf (DCM/MeOH, 9/1 ) = 0.14). Yield: 96.6 mg (colourless oil, 59%). Exact Mass = 1631.61. LC-MS (C18 Waters, 25 min): Rt = 14.72 min.; found m/z = 985, 906, 756, 633, 61 1 , 559, 579.
Example 54: Preparation of linker-conjugate 62
A solution of 61 (1 16 μΙ_, 20 mM in DMF, 2.3 μιηοΙ) was added to a solution containing doxorubicine.HCI (5.4 mg, 9.3 μηηοΙ, 4 equiv.), Et3N (51 μΙ_, 10% in DMF, 37 μηηοΙ, 16 equiv.) and DMF (400 [it). The resulting solution was mixed and left to stand at RT without stirring for 4 h. The crude reaction mixture was purified by preparative HPLC (30 to 90 % MeCN in H2O, 1 % AcOH, 50 fractions, product found in fractions 26-27). Yield: 2.9 mg (red solid, 52%). Mol. Wt = 2441.50; Exact Mass = 2439.90. LC-MS (C18 Waters, 25 min): Rt = 1 1.98 min.; m/z = 1243.
Examples 56-58: Preparation of linker-conjugates 63 - 66

To a solution of vc-PABC-MMAF.TFA (5.5 mg, 4.4 μηηοΙ) in DMF (529 μί) were added Et3N (1 .1 mg, 1.5 μί, 1 1 μητιοΙ) and a solution of 56 (1.8 mg, 2.2 μητιοΙ) in DMF (34 μΙ_). The resulting mixture was left standing for 19h. Additional Et3N (1.1 mg, 1.5 μΙ_) was added and the mixture was left standing for another 23h after which 2,2'-(ethylenedioxy)bis(ethylamine) (2.6 μΙ_, 2.6 mg, 18 μητιοΙ) was added to quench the reaction. After 4 hours the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H2O (1 % AcOH). The desired product was obtained as a colorless film (3.6 mg, 1.3 μιηοΙ, 58%). LCMS (EST) calculated for (Ci38H226N23037S3+)/3 ((M+3H+)/3) 939.85 found 940.47
xample 56: Preparation of linker-conjugate 64

To a solution of vc-PABC-MMAE.TFA (32.3 mg, 26 μηηοΙ) in DMF (1 .0 mL) were added Et3N (7.4 mg, 10 μί, 72.6 μmol) and a solution of 56 (20 mg, 24.2 μηηοΙ) in DMF (500 μΙ_). The resulting mixture was diluted with DMF (200 μΙ_) and left standing for 19h. After addition of DCM (1 mL), the resulting mixture was purified by silica column chromatography (DCM → 20% MeOH in DCM (2*)) yielding two products. The monofunctionalized product (1 arm with vc-PABC-MMAE and 1 arm with PNP, 64a) was obtained as a white colourless film (15.9 mg, 8.8 μιηοΙ, 36%). LCMS (ESI+) calculated for (C86Hi3oNi4026S2+) 2 ((M+2H+)/2 903.45 found 904.15. The bisfunctionalized product (64) was obtained as a white colourless film (8.4 mg, 3.0 μιηοΙ, 12%). LCMS (EST) calculated for (Ci38H22oN23035S3+)/3 ((M+3H+)/3) 930.53 found 931.18a

28 μιηοΙ) was added to 72 (4.0 mg, 4.5 μιηοΙ). The resulting mixture was left standing for 20.5 hours after which 2,2'-(ethylenedioxy)bis(ethylamine) (13 μί, 14 mg, 92 μητιοΙ) was added to quench the reaction. After 3.5 hours the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H20 (1 % AcOH). The desired product was obtained as a white solid (8.8 mg, 3.1 μηηοΙ, 68%). LCMS (ESI+) calculated for (Ci38H22iN24037S23+)/3 ((M+3H+)/3) 956.85 found 957.71
Example 58: Preparation of linker-conjugate 66
To a solution of vc-PABC-MMAF.TFA (1.4 mg, 1 .1 1 μηηοΙ) were added 10% Et3N in DMF (4.6 μί, 0.34 mg, 3.33 μηηοΙ) and a solution of 64a (2.0 mg, 1.1 1 μηηοΙ) in DMF (1 1 1 μί). The resulting
mixture was left standing for 22 h. A 10 vol% solution of 2,2'-(ethylenedioxy)-bis(ethylamine) in DMF was added (6.5 μΙ_, 0.66 mg, 4.5 μιηοΙ) after 2.5 hours to quench the reaction. The crude mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H2O (1 % AcOH). The desired product was obtained as a white solid (1.8 mg, 0.64 μητιοΙ, 58%). LCMS (ESI+) calculated for (CissFbi/ffeCbeS2' )/2 ((M+2H+)/2) 1402.28 found 1403.47.
Example 59-60: Preparation of linker-conjugate 68

Example 59: Synthesis of compound 67
A solution of doxorubicine.HCI (66 mg, 86 μηηοΙ) and Et3N (36 μΙ_, 258 μηηοΙ, 3 equiv.) in DMF (2 mL) and a solution of Fmoc-Val-Cit-PAB-PNP (obtained from Iris Biotech, Marktredwitz, Germany, 50 mg, 86 μιηοΙ, 1 equiv.) in DMF (2 mL) were added together and stirred at RT for 88 h. Besides coupling of doxorubicine to vc-PAB-PNP, Fmoc deprotection also occurred when leaving the reaction for a prolonged period of time. The mixture was concentrated in vacuo to a volume of 400 [it and purified by silica column chromatography (12 g silica, 45 fractions, 20 mL fraction, 10 mL/min, 0 to 50% MeOH in DCM, product found in fractions 20-23, Rf (DCM/MeOH, 4/1 ) = 0.04). The combined fractions 20-23 were concentrated in vacuo (27 mg) and further purified by preparative HPLC (5 to 95 % MeCN in H2O, 1 % AcOH, 50 fractions, product found in fractions 21- 28). Yield: 18.8 mg (red solid, 23%). Mol. Wt = 948.98; Exact Mass = 948.38. LC-MS (C18 Waters, 25 min): Rt = 9.13 min.; m/z = 949.
Example 60: Preparation of linker-conjugate 68
To a solution of vc-PABC-Dox (1 .7 mg, 1.8 μηηοΙ) in DMF (44 μί) were added 10% Et3N in DMF (4.6 [it, 0.34 mg, 3.33 μηηοΙ) and a solution of 64a (2.0 mg, 1.1 1 μηηοΙ) in DMF (1 1 1 μί). The resulting mixture was left standing for 23 h. A 10 vol% solution of 2,2'-(ethylenedioxy)- bis(ethylamine) in DMF was added (6.5 μΙ_, 0.66 mg, 4.5 μιηοΙ) to quench the reaction. After 2 hours the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H2O (1 % AcOH). The fractions containing the product were pooled and concentrated and then purified by silica chromatography (0→20% MeOH in DCM), which yielded
2.6 mg (0.99 μηηοΙ) of the desired product. LCMS (ESI+) calculated for Ci26Hi79Ni9Na2039S2 (M+2Na+)/2 1330.61 found 1331.07
Examples 61-63: Preparation of linker-conjugates 69, 111 and 112
Example 61: Preparation of linker-conjugate 69
To a solution of vc-PABC-Ahx-May.TFA (1.4 mg, 1.1 1 μηηοΙ) in DMF (70 μΙ_) were added 10% Et3N in DMF (4.6 [it, 0.34 mg, 3.33 μηηοΙ) and a solution of 64a (2.0 mg, 1.1 1 μηηοΙ) in DMF (1 1 1 [it). The resulting mixture was left standing for 2 days. A 10 vol% solution of 2,2'- (ethylenedioxy)bis(ethylamine) in DMF was added (6.5 μΙ_, 0.66 mg, 4.5 μιηοΙ) to quench the reaction. After 2.5 hours the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H20 (1 % AcOH). The resulting product was obtained as a white solid (2.6 mg, 0.92 μηηοΙ, 83%). LCMS (ESI+) calculated for Ci36H203CIN22Na2O35S2+((M-CO2-H2O)+2Na=)/2 1408.70 found 1409.65 Example 62: Preparation of linker-conjugate 111
A solution of 54 (4.7 mg, 8.9 μηηοΙ) in DMF (200 μί) and Et3N (2.7 mg, 3.7 μί) were added to vc- PABC-MMAE.TFA (10 mg, 8.9 μιηοΙ). The resulting mixture was left standing for 23 h. after which 2,2'-(Ethylenedioxy)bis(ethylamine) (13 μΙ_, 14 mg, 92 μητιοΙ) was added to quench the reaction. After 4 hours the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H2O (1 % AcOH). The desired product was obtained as a colourless film (10.7 mg, 7.1 μπιοΙ, 80%). LCMS (ESI+) calculated for C74Hi i7Ni20i9S+ (M+H+) 1509.83 found 1510.29
Example 63: Preparation of linker-conjugate 112
To a solution of vc-PABC-MMAE.TFA (13.9 mg, 1 1.2 μηηοΙ) in DMF (400 μί) were added Et3N (3.4 [it, 2.5 mg, 24.3 μηηοΙ) and a solution of 110 (3.0 mg, 5.6 μηηοΙ) in DMF (200 μί). The reaction mixture was diluted with DMF (50 μί). After 25 min., additional Et3N (0.80 mg, 1.1 μί) and 110 (2.2 mg, 4.2 μητιοΙ) in DMF (33 μΙ_) were added. The resulting mixture was left standing for 17 h. after which the mixture was purified via reversed phase (C18) HPLC chromatography (30→90% MeCN (1 % AcOH) in H2O (1 % AcOH). The desired product was obtained as a colourless film (10.9 mg, 7.2 μηηοΙ, 73%). LCMS (ESI+) calculated for C78H124N11O19+ (M+H+) 1518.91 found 1519.09
Examples 64-78: Preparation of antibodv-druq-conjuqates
Example 64: Conjugation of 13d with 44 to obtain conjugate XI
A bioconjugate according to the invention was prepared by conjugation of compound 44 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (4.239 mL, 120 mg, 28.31 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (1.761 mL), DMF (1.680 mL) and compound 44 (0.320 mL, 10 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a HiLoad 26/600 Superdex200 PG (GE
Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator- digested sample showed one major product (observed mass 27398 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.77.
Example 65: Conjugation of 13d with 48 to obtain conjugate XII
A bioconjugate according to the invention was prepared by conjugation of compound 48 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (10 μΙ_, 330 ig, 33.0 mg/ml in PBS pH 7.4) was added propylene glycol (2.5 μΙ_), and compound 48 (2.5 μΙ_, 10 mM solution in DMF). The reaction was incubated at rt overnight. Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27336 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 1.40. Example 66: Conjugation of 13d with 51 to obtain conjugate XIII
A bioconjugate according to the invention was prepared by conjugation of compound 51 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (12.25 [it, 286 μg, 23.34 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (1 1.85 [it) and compound 51 (7.60 μΙ_, 2 mM solution in DMF). In a separate tube, to a solution of CuSC (35.5 μί, 15 mM solution in PBS pH 7.4) was added tris[(1-hydroxypropyl-1 A -1 ,2,3-triazol-4- yl)methyl]amine (THPTA) (6.7 μΙ_, 160 mM solution in DMF), amino guanidine.HCI (26.6 μΙ_, 100 mM solution in PBS pH 7.4) and sodium ascorbate (20 [it, 400 mM solution in PBS pH 7.4). The THPTA-CuSC complex was mixed and incubated at rt for 10 minutes. An aliquot of the THPTA- CuSC complex (6.3 μΙ_) was added to the solution containing trastuzumab-(6-N3-GalNAc)2 (13d) and compound 51. The reaction was mixed and incubated at rt. After 2 hrs the buffer was exchanged to PBS pH 7.4 by spinfiltration (Amicon Ultra-0.5, Ultracel-10 Membrane, Millipore) to remove the THPTA-CuSC complex and excess alkyne. Mass spectral analysis of the fabricator- digested sample showed one major product (observed mass 27261 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.69.
Example 67: Conjugation of 13d with 59 to obtain conjugate XIV
A bioconjugate according to the invention was prepared by conjugation of compound 59 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (4.769 mL, 135 mg, 28.31 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (1.981 mL), DMF (1.890 mL) and compound 59 (360 [it, 10 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27668 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample
indicated an average DAR of 3.68.
Example 68: Conjugation of 13d with 60 to obtain conjugate XV
A bioconjugate according to the invention was prepared by conjugation of compound 60 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (4.769 ml_, 135 mg, 28.31 mg/ml in PBS pH 7.4) was added propylene glycol (4.95 mL), and compound 60 (270 μΙ_, 20 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27248 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.54.
Example 69: Conjugation of 13d with 63 to obtain conjugate XVII
A bioconjugate according to the invention was prepared by conjugation of compound 63 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (8.18 mL, 270 mg, 33.0 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (7.12 mL), DMF (2.48 mL) and compound 63 (225 μί, 40 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 25921 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 1.90. Example 67: Conjugation of 13d with 68 to obtain conjugate XXI
A bioconjugate according to the invention was prepared by conjugation of compound 68 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (129 [it, 2.57 mg, 19.85 mg/ml in PBS pH 7.4) was added compound 68 (60 μί, 10 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare).. Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 26980 Da, approximately 80% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.55. Example 71: Conjugation of 13d with 62 to obtain conjugate XVI
A bioconjugate according to the invention was prepared by conjugation of compound 62 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (202 μί, 4.0 mg, 19.9 mg/ml in PBS pH 7.4) was added propylene glycol (170 μί) and compound 62 (32 μί, 10 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10
(GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 26806 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.70.
Example 72: Conjugation of 13d with 64 to obtain conjugate XVIII
A bioconjugate according to the invention was prepared by conjugation of compound 64 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (360 μΙ_, 7.0 mg, 19.5 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (13.5 μΙ_), DMF (81 .6 μL) and compound 64 (1 1.7 [it, 20 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27155 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.58.
Example 73: Conjugation of 13d with 65 to obtain conjugate XIX
A bioconjugate according to the invention was prepared by conjugation of compound 65 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (334 μ|_, 6.67 mg, 20.0 mg/ml in PBS pH 7.4) was added DMF (100 μΙ_) and compound 65 (1 1.13 μί, 20 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27238 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.58.
Example 74: Conjugation of 13d with 66 to obtain conjugate XX
A bioconjugate according to the invention was prepared by conjugation of compound 66 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (353 μΙ_, 7.0 mg, 19.9 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (210 μΙ_), DMF (44.7 μί) and compound 66 (48.6 μί, 9.6 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27169 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment.
Example 75: Conjugation of 13d with 69 to obtain conjugate XXII
A bioconjugate according to the invention was prepared by conjugation of compound 69 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3-
GalNAc)2 (13d) (360 μΙ_, 7.0 mg, 19.5 mg/ml in PBS pH 7.4) was added DMF (23.4 μ|_) and compound 69 (93.3 μΙ_, 10 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27200 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment.
Example 76: Conjugation of 13d with 111 to obtain conjugate XXIII
A bioconjugate according to the invention was prepared by conjugation of compound 111 as linker-conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6- N3-GalNAc)2 (13d) (360 μΙ_, 7.0 mg, 19.5 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (60.1 μΙ_), DMF (42.0 [it) and compound 111 (4.67 μί, 40 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 25874.2 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.69.
Example 77: Conjugation of 13d with 112 to obtain conjugate XXIV
A bioconjugate according to the invention was prepared by conjugation of compound 21 as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (13d) (235 μΙ_, 6.7 mg, 28.5 mg/ml in PBS pH 7.4) was added PBS pH 7.4 (99 μΙ_), DMF (100.3 μί) and compound 112 (11.2 μί, 40 mM solution in DMF). The reaction was incubated at rt overnight followed by purification on a Superdex200 10/300 GL (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 25884 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.72. Example 78: Conjugation of 13d with 54 to obtain conjugate IV
A bioconjugate according to the invention was prepared by conjugation of compound as linker- conjugate to azide-modified trastuzumab as biomolecule. To a solution of trastuzumab-(6-N3- GalNAc)2 (235 [it, 6.7 mg, 28.5 mg/ml in PBS pH 7.4) was added propylene glycol (190 [it) and compound 54 (45 μί, 10 mM solution in DMF). The reaction was incubated at rt for 36 hours followed by purification on a HiLoad 26/600 Superdex200 PG (GE Healthcare) on an AKTA Purifier-10 (GE Healthcare). Mass spectral analysis of the fabricator-digested sample showed one major product (observed mass 27254 Da, approximately 90% of total Fc/2 fragment), corresponding to the conjugated Fc/2 fragment. RP-HPLC analysis of the reduced sample indicated an average DAR of 3.46.
Claims
Claims
1. Antibody-conjugate comprising an antibody AB connected to a target molecule D via a linker L, obtainable by:
(i) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q\ x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified antibody according to Formula (24):
(Fuc)b
AB- GlcNAc S(F1)X
y
(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
(ii) reacting the modified antibody with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F\
wherein antibody AB is capable of targeting HER2-expressing tumours and target molecule D is selected from the group consisting of taxanes, anthracyclines, camptothecins, epothilones, mytomycins, combretastatins, vinca alkaloids, maytansinoids, calicheamycins and enediynes, duocarmycins, tubulysins, amatoxins, dolastatins and auristatins, pyrrolobenzodiazepine dimers, indolino-benzodiazepine dimers, radioisotopes, therapeutic proteins and peptides (or fragments thereof), kinase inhibitors, MEK inhibitors, KSP inhibitors, and analogues or prodrugs thereof.
The antibody-conjugate according to claim 1 , wherein the antibody is capable of targeting HER2-expressing tumours and is selected from trastuzumab, margetuximab, pertuzumab, HuMax-Her2, ertumaxomab, HB-008, ABP-980, BCD-022, CanMab, Herzuma, HD201 , CT- P6, PF-05280014, COVA-208, FS-102, MCLA-128, CKD-10101 , HT-19 and functional analogues thereof.
The antibody-conjugate according to claim 1 or 2, wherein linker L2 comprises a group according to formula (1 ) or a salt thereof:

1
wherein:
- a is 0 or 1 ; and
- R3 is selected from the group consisting of hydrogen, Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3
- C24 (hetero)arylalkyl groups, the Ci - C24 alkyl groups, C3 - C24 cycloalkyl groups, C2 - C24 (hetero)aryl groups, C3 - C24 alkyl(hetero)aryl groups and C3 - C24 (hetero)arylalkyl groups optionally substituted and optionally interrupted by one or more heteroatoms selected from O, S or NR33 wherein R33 is independently selected from the group consisting of hydrogen and Ci - C4 alkyl groups, or R3 is an additional target molecule D, wherein the target molecule is optionally connected to N via a spacer moiety.
The antibody-conjugate according to any one of claims 1 to 3, wherein antibody AB is trastuzumab and target molecule D is selected from the group of maytansinoids, auristatines and pyrrolobenzodiazepine dimer, preferably auristatines selected from the group consisting of MMAD, MMAE, MMAF and functional analogues thereof or maytansinoids selected form the group consisting of DM1 , DM3, DM4, Ahx-May and functional analogues thereof.
The antibody-conjugate according to any one of claims 1 to 4, wherein:
(I) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit- PABC-, D = Ahx-May;
(II) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2)3-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2- C(0)-Val-Cit-PABC- D = Ahx-May;
(III) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-Val-Cit-PABC-, D = Ahx-May;
(IV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to
formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-N(CH2-CH2-0-C(0)- Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(V) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH-S(0)2-
N(CH2-CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(VI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Ala-, D = PBD;
(VII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 2-azidoacetamido-2-deoxy-galactose, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-, D = Ahx-May;
(VIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 2-azidoacetamido-2-deoxy-galactose, Q is according to formula
(9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)4-C(0)-, D = Ahx-May;
(IX) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 2-azidodifluoroacetamido-2-deoxy-galactose, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)4-C(0)-, D = Ahx- May;
(X) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 2-azidodifluoroacetamido-2-deoxy-galactose, Q is according to formula (9q), L2 = -CH2-0-C(0)-(CH2-CH2-0)4-C(0)-, D = Ahx-May;
(XI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9n), wherein U = O, L2 = -C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH- S(0)2-N(CH2-CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May.
(XII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9zo), L2 = -C(0)-NH-(CH2)4-C(0)-NH-(CH2)5-0-C(0)-NH-S(0)2-
N(CH2-CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9j), wherein I = 3, L2 = -0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH- S(0)2-N(CH2-CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XIV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Ahx-May;
(XVI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = Dox;
(XVII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = MMAF;
(XVIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2-
0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = MMAE;
(XIX) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-NH-S(0)2- N(CH2-CH2-0-C(0)-Val-Cit-PABC-D)2, each occurrence of D = MMAE;
(XX) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D1 )(CH2-CH2-0-C(0)-Val-Cit-PABC-D2), with D1 = MMAE and D2 = MMAF;
(XXI) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D1 )(CH2-CH2-0-C(0)-Val-Cit-PABC-D2), with D1 = MMAE and D2 = Dox;
(XXII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-N(CH2-CH2- 0-C(0)-Val-Cit-PABC-D1 )(CH2-CH2-0-C(0)-Val-Cit-PABC-D2), with D1 = MMAE and D2 = Ahx-May;
(XXIII) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-S(0)2-NH-(CH2-CH2-0)2-C(0)-Val-Cit- PABC-D, each occurrence of D = MMAE;
(XXIV) AB = trastuzumab, wherein S(F )X is connected to the core-GlcNAc linked to amino acid N300, S(F )X = 6-azido-6-deoxy-A/-acetylgalactosamine, Q is according to formula (9q), L2 = -CH2-0-C(0)-NH-(CH2-CH2-0)4-C(0)-Val-Cit-PABC-D, each occurrence of D = MMAE.
Use of a mode of conjugation for increasing the therapeutic index of a bioconjugate, wherein the mode of conjugation is being used to connect a biomolecule B with a target molecule D via a linker L, wherein the mode of conjugation comprises:
(ii) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q\ x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified glycoprotein according to Formula (24):
(Fuc)b
AB- GlcNAc S(F1)X
(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
reacting the modified glycoprotein with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F .
Use according to claim 6, wherein the antibody AB is capable of targeting tumours that express an antigen selected from 5T4 (TPBG), av-integrin/ITGAV, BCMA, C4.4a, CA-IX, CD19, CD19b, CD22, CD25, CD30, CD33, CD37, CD40, CD56, CD70, CD74, CD79b, c-KIT (CD1 17), CD138/SDC1 , CEACAM5 (CD66e), Cripto, CS1 , DLL3, EFNA4, EGFR, EGFRvlll, Endothelin B Receptor (ETBR), ENPP3 (AGS-16), EpCAM, EphA2, FGFR2, FGFR3, FOLR1 (folate receptor a), gpNMB, guanyl cyclase C (GCC), HER2, Erb-B2, Lamp-1 , Lewis Y antigen, LIV-1 (SLC39A6, ZIP6), Mesothelin (MSLN), MUC1 (CA6, huDS6), MUC16/EA-125, NaPi2b, Nectin-4, Notch3, P-cadherin, PSMA/FOLH1 , PTK7, SLITRK6 (SLC44A4), STEAP1 , TF (CD142) , Trop-1 , Trop-2/EGP-1 , Trop-3 , Trop-4, preferably HER2-expressing tumours.
Use according to claim 6 or 7, wherein increasing the therapeutic index of an antibody- conjugate is selected from:
(a) increasing the therapeutic efficacy of the antibody-conjugate; and/or
(b) increasing the tolerability of the antibody-conjugate.
9. Use according to any one of claims 6 to 8, wherein the reaction of step (ii) is a(n) (cyclo)alkyne-azide conjugation reaction to from a connecting moiety Z3 that is represented by by:

wherein cycle A is a 7-10-membered (hetero)cyclic moiety.
10. Use according to any one of claims 6 to 9, wherein one of F is an azide moiety, Q is an (cyclo)alkyne moiety, and Z3 is a triazole moiety.
1 1. Use according to any one of claims 6 to 10, wherein x is 1 or 2, preferably wherein x is 1.
12. Use according to any one of claims 6 to 1 1 , wherein S(F )X is 6-azido-6-deoxy-/V- acetylgalactosamine.
13. Use according to any one of claims 6 to 12, wherein the antibody-conjugate is represented by Formula (40) or (40b):

(40b),
wherein:
R3 is independently selected from the group consisting of hydrogen, halogen, -OR35, -NO2, -CN, -S(0)2R35, Ci - C24 alkyl groups, Ce - C24 (hetero)aryl groups, C7 - C24
alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups and wherein the alkyl groups, (hetero)aryl groups, alkyl(hetero)aryl groups and (hetero)arylalkyl groups are optionally substituted, wherein two substituents R3 may be linked together to form an annelated cycloalkyl or an annelated (hetero)arene substituent, and wherein R35 is independently selected from the group consisting of hydrogen, halogen, Ci - C24 alkyl groups, C6 - C24 (hetero)aryl groups, C7 - C24 alkyl(hetero)aryl groups and C7 - C24 (hetero)arylalkyl groups;
- X is C(R3 )2, O, S or NR32, wherein R32 is R3 or L3(D , wherein L3 is a linker, and D is as defined in claim 1 ;
- r is 1 - 20;
q is 0 or 1 , with the proviso that if q is 0 then X is N-L2(D)r;
- aa is 0, 1 , 2, 3, 4, 5, 6, 7 or 8;
- aa' is 0,1 , 2, 3, 4, 5, 6, 7 or 8; and
- aa+aa' < 10.
b is 0 or 1 ;
pp is 0 or 1 ;
- M is -N(H)C(0)CH2-, -N(H)C(0)CF2-, -CH2-, -CF2- or a 1 ,4-phenylene containing 0 - 4 fluorine substituents, preferably 2 fluorine substituents which are preferably positioned on C2 and C6 or on C3 and C5 of the phenylene;
y is 1 - 4;
Fuc is fucose
or wherein the antibody-conjugate the antibody-conjugate is represented by Formula (40d):

(40d),
wherein AB, L2, D, S, b, pp, x, y and M are as defined above and wherein I is 0
The use according to any one of claims 6 to 13, wherein D is an active substance, preferably an anti-cancer agent. 15. Method for targeting HER2-expressing cells, comprising administering to a subject in need thereof an antibody-conjugate, comprising an antibody AB connected to a target molecule D via a linker L, wherein the antibody-conjugate is obtainable by:
0) contacting a glycoprotein comprising 1 - 4 core /V-acetylglucosamine moieties with a compound of the formula S(F )x-P in the presence of a catalyst, wherein S(F )X is a sugar derivative comprising x functional groups F capable of reacting with a functional group Q , x is 1 or 2 and P is a nucleoside mono- or diphosphate, and wherein the catalyst is capable of transferring the S(F )X moiety to the core-GlcNAc moiety, to obtain a modified antibody according to Formula (24):
(Fuc)b
AB- GlcNAc- -S(F1)X
(24)
wherein S(F )X and x are as defined above; AB represents an antibody; GlcNAc is N- acetylglucosamine; Fuc is fucose; b is 0 or 1 ; and y is 1 , 2, 3 or 4; and
(ii) reacting the modified antibody with a linker-conjugate comprising a functional group Q capable of reacting with functional group F and a target molecule D connected to Q via a linker L2 to obtain the antibody-conjugate wherein linker L comprises S-Z3-L2 and wherein Z3 is a connecting group resulting from the reaction between Q and F\
wherein antibody AB is capable of targeting HER2-expressing tumours.
16. The method according to claim 15, wherein the targeting HER2-expressing cells includes one or more of treating, imaging, diagnosing, preventing the proliferation of, containing and reducing HER2-expressing cells, in particular HER2-expressing tumours.
17. The method according to claim 15 or 16, wherein the subject suffers from a disorder selected from breast cancer, bladder cancer, pancreatic cancer, gastric cancer. 18. The method according to any one of claims 15 - 17, wherein target molecule D is an anticancer agent, preferably a cytotoxin.
19. The method according to any one of claims 15 - 18, wherein the bioconjugate comprises two distinct target molecules D, preferably two distinct anti-cancer agents, most preferably two distinct cytotoxins.
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US16/076,293 US11338043B2 (en) | 2016-02-08 | 2017-02-08 | Antibody-conjugates with improved therapeutic index for targeting HER2 tumours and method for improving therapeutic index of antibody-conjugates |
| CN201780022005.6A CN109069658B (en) | 2016-02-08 | 2017-02-08 | Antibody-conjugates with improved therapeutic index for targeting HER2 tumors and methods for improving the therapeutic index of antibody-conjugates |
| EP17703993.0A EP3413915A1 (en) | 2016-02-08 | 2017-02-08 | Antibody-conjugates with improved therapeutic index for targeting her2 tumours and method for improving therapeutic index of antibody-conjugates |
| US17/749,953 US20230127659A1 (en) | 2016-02-08 | 2022-05-20 | Antibody-conjugates with improved therapeutic index for targeting her2 tumours and method for improving therapeutic index of antibody-conjugates |
Applications Claiming Priority (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP16154739 | 2016-02-08 | ||
| EP16154739.3 | 2016-02-08 | ||
| EP16154712 | 2016-02-08 | ||
| EP16154712.0 | 2016-02-08 | ||
| EP16173595 | 2016-06-08 | ||
| EP16173595.6 | 2016-06-08 | ||
| JP2016155929A JP2017200902A (en) | 2016-02-08 | 2016-08-08 | Novel antibody-conjugate with improved therapeutic index for targeting HER2 tumor and method for improving therapeutic index of antibody-conjugate |
| JP2016-155929 | 2016-08-08 |
Related Child Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| US16/076,293 A-371-Of-International US11338043B2 (en) | 2016-02-08 | 2017-02-08 | Antibody-conjugates with improved therapeutic index for targeting HER2 tumours and method for improving therapeutic index of antibody-conjugates |
| US17/749,953 Continuation US20230127659A1 (en) | 2016-02-08 | 2022-05-20 | Antibody-conjugates with improved therapeutic index for targeting her2 tumours and method for improving therapeutic index of antibody-conjugates |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| WO2017137457A1 true WO2017137457A1 (en) | 2017-08-17 |
| WO2017137457A9 WO2017137457A9 (en) | 2018-10-25 |
Family
ID=57995207
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| PCT/EP2017/052790 WO2017137457A1 (en) | 2016-02-08 | 2017-02-08 | Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates |
Country Status (1)
| Country | Link |
|---|---|
| WO (1) | WO2017137457A1 (en) |
Cited By (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3413916A1 (en) * | 2016-02-08 | 2018-12-19 | Synaffix B.V. | Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates |
| WO2019110725A1 (en) * | 2017-12-06 | 2019-06-13 | Synaffix B.V. | Enediyne conjugates |
| WO2020094670A1 (en) * | 2018-11-05 | 2020-05-14 | Synaffix B.V. | Antibody-conjugates for targeting of tumours expressing trop-2 |
| WO2020245229A1 (en) | 2019-06-03 | 2020-12-10 | Synaffix B.V. | Acetal-based cleavable linkers |
| WO2022049211A1 (en) | 2020-09-02 | 2022-03-10 | Synaffix B.V. | Methods for the preparation of bioconjugates |
| WO2022051665A1 (en) * | 2020-09-03 | 2022-03-10 | Dyne Therapeutics, Inc. | Methods of preparing protein-oligonucleotide complexes |
| WO2022108452A1 (en) * | 2020-11-20 | 2022-05-27 | Synaffix B.V. | Tyrosine-based antibody conjugates |
| CN114605367A (en) * | 2020-12-03 | 2022-06-10 | 中国人民解放军军事科学院军事医学研究院 | Linker containing coumarin and antibody conjugate drug containing same |
| US11384098B2 (en) | 2017-02-08 | 2022-07-12 | Adc Therapeutics Sa | Pyrrolobenzodiazepine-antibody conjugates |
| WO2022167689A1 (en) * | 2021-02-08 | 2022-08-11 | Synaffix B.V. | Multifunctional antibodies |
| WO2022187591A1 (en) | 2021-03-05 | 2022-09-09 | Go Therapeutics, Inc. | Anti-glyco-cd44 antibodies and their uses |
| WO2023014863A1 (en) | 2021-08-05 | 2023-02-09 | Go Therapeutics, Inc. | Anti-glyco-muc4 antibodies and their uses |
| WO2023065137A1 (en) * | 2021-10-20 | 2023-04-27 | Glyco-Therapy Biotechnology Co., Ltd. | Site-specific glycoprotein conjugates and methods for making the same |
| US11786605B2 (en) | 2020-01-09 | 2023-10-17 | Mersana Therapeutics, Inc. | Site specific antibody-drug conjugates with peptide-containing linkers |
| WO2024038065A1 (en) | 2022-08-15 | 2024-02-22 | Synaffix B.V. | Anthracyclins and conjugates thereof |
| EP4161582A4 (en) * | 2020-06-05 | 2024-05-15 | Development Center for Biotechnology | Antibody-drug conjugates containing an anti-mesothelin antibody and uses thereof |
| WO2024117938A1 (en) * | 2022-11-30 | 2024-06-06 | Общество с ограниченной ответственностью "СИСТЕМА-БИОТЕХ" | Methods for producing bioconjugates for liver-specific targeted proteome modulation |
| WO2024153232A1 (en) * | 2023-01-19 | 2024-07-25 | 上海盛迪医药有限公司 | Tyrosinase-mediated protein site-specific conjugation and use thereof |
| WO2024160926A1 (en) | 2023-01-31 | 2024-08-08 | Synaffix B.V. | Homogeneous antibody-conjugates with high payload loading |
Citations (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001088535A1 (en) | 2000-05-16 | 2001-11-22 | Biochip Technologies Gmbh | Linker system for activating surfaces for bioconjugation and mehtods for their use |
| US20050276812A1 (en) * | 2004-06-01 | 2005-12-15 | Genentech, Inc. | Antibody-drug conjugates and methods |
| WO2007133855A2 (en) | 2006-03-27 | 2007-11-22 | University Of Maryland Biotechnology Institute | Glycoprotein synthesis and remodeling by enzymatic transglycosylation |
| WO2008070291A2 (en) | 2006-10-24 | 2008-06-12 | Kereos, Inc. | Improved linkers for anchoring targeting ligands |
| US20090068738A1 (en) | 2004-11-01 | 2009-03-12 | The Regents Of The University Of California | Compositions and methods for modification of biomolecules |
| WO2009067663A1 (en) | 2007-11-21 | 2009-05-28 | University Of Georgia Research Foundation, Inc. | Alkynes and methods of reacting alkynes with 1,3-dipole-functional compounds |
| WO2009102820A2 (en) | 2008-02-11 | 2009-08-20 | Government Of The U.S A., As Represented By The Secretary, Department Of Health And Human Services | Modified sugar substrates and methods of use |
| US20110207147A1 (en) | 2010-02-12 | 2011-08-25 | Jewett John C | Compositions and Methods for Modification of Biomolecules |
| WO2011136645A1 (en) | 2010-04-27 | 2011-11-03 | Stichting Katholieke Universiteit, More Particularly Radboud University Nijmegen | Fused cyclooctyne compounds and their use in metal-free click reactions |
| WO2014065661A1 (en) | 2012-10-23 | 2014-05-01 | Synaffix B.V. | Modified antibody, antibody-conjugate and process for the preparation thereof |
| WO2014100762A1 (en) | 2012-12-21 | 2014-06-26 | Biolliance C.V. | Hydrophilic self-immolative linkers and conjugates thereof |
| WO2014177771A1 (en) * | 2013-05-02 | 2014-11-06 | Glykos Finland Oy | Conjugates of a glycoprotein or a glycan with a toxic payload |
| WO2015057063A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Modified glycoprotein, protein-conjugate and process for the preparation thereof |
| WO2015057065A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Glycoengineered antibody, antibody-conjugate and methods for their preparation |
| WO2015057064A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Modified glycoprotein, protein-conjugate and process for the preparation thereof |
| WO2015057066A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Glycoengineered antibody, antibody-conjugate and methods for their preparation |
| WO2016022027A1 (en) | 2014-08-04 | 2016-02-11 | Synaffix B.V. | Process for the modification of a glycoprotein using a βeta-(1,4)-n-acetylgalactosaminyltransferase or a mutant thereof |
| WO2016053107A1 (en) | 2014-10-03 | 2016-04-07 | Synaffix B.V. | Sulfamide linker, conjugates thereof, and methods of preparation |
| WO2016170186A1 (en) | 2015-04-23 | 2016-10-27 | Synaffix B.V. | PROCESS FOR THE MODIFICATION OF A GLYCOPROTEIN USING A GLYCOSYLTRANSFERASE THAT IS OR IS DERIVED FROM A β(1,4)-N-ACETYLGALACTOSAMINYLTRANSFERASE |
-
2017
- 2017-02-08 WO PCT/EP2017/052790 patent/WO2017137457A1/en active Application Filing
Patent Citations (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2001088535A1 (en) | 2000-05-16 | 2001-11-22 | Biochip Technologies Gmbh | Linker system for activating surfaces for bioconjugation and mehtods for their use |
| US20050276812A1 (en) * | 2004-06-01 | 2005-12-15 | Genentech, Inc. | Antibody-drug conjugates and methods |
| US20090068738A1 (en) | 2004-11-01 | 2009-03-12 | The Regents Of The University Of California | Compositions and methods for modification of biomolecules |
| WO2007133855A2 (en) | 2006-03-27 | 2007-11-22 | University Of Maryland Biotechnology Institute | Glycoprotein synthesis and remodeling by enzymatic transglycosylation |
| WO2008070291A2 (en) | 2006-10-24 | 2008-06-12 | Kereos, Inc. | Improved linkers for anchoring targeting ligands |
| WO2009067663A1 (en) | 2007-11-21 | 2009-05-28 | University Of Georgia Research Foundation, Inc. | Alkynes and methods of reacting alkynes with 1,3-dipole-functional compounds |
| WO2009102820A2 (en) | 2008-02-11 | 2009-08-20 | Government Of The U.S A., As Represented By The Secretary, Department Of Health And Human Services | Modified sugar substrates and methods of use |
| US20110207147A1 (en) | 2010-02-12 | 2011-08-25 | Jewett John C | Compositions and Methods for Modification of Biomolecules |
| WO2011136645A1 (en) | 2010-04-27 | 2011-11-03 | Stichting Katholieke Universiteit, More Particularly Radboud University Nijmegen | Fused cyclooctyne compounds and their use in metal-free click reactions |
| WO2014065661A1 (en) | 2012-10-23 | 2014-05-01 | Synaffix B.V. | Modified antibody, antibody-conjugate and process for the preparation thereof |
| WO2014100762A1 (en) | 2012-12-21 | 2014-06-26 | Biolliance C.V. | Hydrophilic self-immolative linkers and conjugates thereof |
| WO2014177771A1 (en) * | 2013-05-02 | 2014-11-06 | Glykos Finland Oy | Conjugates of a glycoprotein or a glycan with a toxic payload |
| WO2015057063A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Modified glycoprotein, protein-conjugate and process for the preparation thereof |
| WO2015057065A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Glycoengineered antibody, antibody-conjugate and methods for their preparation |
| WO2015057064A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Modified glycoprotein, protein-conjugate and process for the preparation thereof |
| WO2015057066A1 (en) * | 2013-10-14 | 2015-04-23 | Synaffix B.V. | Glycoengineered antibody, antibody-conjugate and methods for their preparation |
| WO2016022027A1 (en) | 2014-08-04 | 2016-02-11 | Synaffix B.V. | Process for the modification of a glycoprotein using a βeta-(1,4)-n-acetylgalactosaminyltransferase or a mutant thereof |
| WO2016053107A1 (en) | 2014-10-03 | 2016-04-07 | Synaffix B.V. | Sulfamide linker, conjugates thereof, and methods of preparation |
| WO2016170186A1 (en) | 2015-04-23 | 2016-10-27 | Synaffix B.V. | PROCESS FOR THE MODIFICATION OF A GLYCOPROTEIN USING A GLYCOSYLTRANSFERASE THAT IS OR IS DERIVED FROM A β(1,4)-N-ACETYLGALACTOSAMINYLTRANSFERASE |
Non-Patent Citations (29)
| Title |
|---|
| A. S. HOFFMAN, ADV. DRUG DELIVERY REV., vol. 64, 2012, pages 18 |
| ALTSCHUL, S. ET AL., J. MOL. BIOL., vol. 215, 1990, pages 403 - 410 |
| ALTSCHUL, S. ET AL.: "BLAST Manual", NCBI NLM NIH BETHESDA |
| BEERLI R R ET AL: "Sortase Enzyme-Mediated Generation of Site-Specifically Conjugated Antibody Drug Conjugates with High In Vitro and In Vivo Potency", PLOS ONE, PUBLIC LIBRARY OF SCIENCE, US, vol. 10, no. 7, 1 July 2015 (2015-07-01), pages e0131177 - 1, XP002756397, ISSN: 1932-6203, [retrieved on 20150101], DOI: 10.1371/JOURNAL.PONE.0131177 * |
| CHEM. COMMUN., vol. 46, 2010, pages 97 - 99 |
| F. LHOSPICE ET AL: "Site-Specific Conjugation of Monomethyl Auristatin E to Anti-CD30 Antibodies Improves Their Pharmacokinetics and Therapeutic Index in Rodent Models", MOLECULAR PHARMACEUTICS, vol. 12, no. 6, 1 June 2015 (2015-06-01), US, pages 1863 - 1871, XP055327463, ISSN: 1543-8384, DOI: 10.1021/mp500666j * |
| G. D. LEWIS PHILLIPS ET AL: "Targeting HER2-Positive Breast Cancer with Trastuzumab-DM1, an Antibody-Cytotoxic Drug Conjugate", CANCER RESEARCH, vol. 68, no. 22, 15 November 2008 (2008-11-15), pages 9280 - 9290, XP055013498, ISSN: 0008-5472, DOI: 10.1158/0008-5472.CAN-08-1776 * |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER, article "Fluorescent probes", pages: 395 - 463 |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER, article "Isotopic labelling techniques", pages: 507 - 534 |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER, article "Microparticles and nanoparticles", pages: 549 - 587 |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER, article "PEGylation and synthetic polymer modification", pages: 787 - 838 |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER, pages: 229 - 258 |
| G.T. HERMANSON: "Bioconjugate Techniques", 2013, ELSEVIER, pages: 230 - 232 |
| GONG; PAN, TETRAHEDRON LETT., vol. 56, 2015, pages 2123 - 2132 |
| H. K. ERICKSON ET AL: "The Effect of Different Linkers on Target Cell Catabolism and Pharmacokinetics/Pharmacodynamics of Trastuzumab Maytansinoid Conjugates", MOLECULAR CANCER THERAPEUTICS, vol. 11, no. 5, 9 March 2012 (2012-03-09), US, pages 1133 - 1142, XP055333152, ISSN: 1535-7163, DOI: 10.1158/1535-7163.MCT-11-0727 * |
| HONGWEN LI ET AL: "An anti-HER2 antibody conjugated with monomethyl auristatin E is highly effective in HER2-positive human gastric cancer", CANCER BIOLOGY & THERAPY, vol. 17, no. 4, 6 February 2016 (2016-02-06), US, pages 346 - 354, XP055378130, ISSN: 1538-4047, DOI: 10.1080/15384047.2016.1139248 * |
| J. AM. CHEM. SOC., vol. 132, 2010, pages 3688 - 3690 |
| J. AM. CHEM. SOC., vol. 134, 2012, pages 5381 |
| JEFFREY SCOTT C ET AL: "Development and properties of beta-glucuronide linkers for monoclonal antibody-drug conjugates", BIOCONJUGATE CHEMISTRY,, vol. 17, no. 3, 1 May 2006 (2006-05-01), pages 831 - 840, XP002423719, ISSN: 1043-1802, DOI: 10.1021/BC0600214 * |
| MULLER ET AL., NATURE REVIEWS DRUG DISCOVERY, vol. 11, 2012, pages 751 - 761 |
| PILLER ET AL., ACS CHEM. BIOL., vol. 7, 2012, pages 753 |
| PILLER ET AL., BIOORG. MED. CHEM. LETT., vol. 15, 2005, pages 5459 - 5462 |
| REMON VAN GEEL ET AL: "Chemoenzymatic Conjugation of Toxic Payloads to the Globally Conserved N-Glycan of Native mAbs Provides Homogeneous and Highly Efficacious Antibody-Drug Conjugates", BIOCONJUGATE CHEMISTRY, vol. 26, no. 11, 10 June 2015 (2015-06-10), pages 2233 - 2242, XP055249394, ISSN: 1043-1802, DOI: 10.1021/acs.bioconjchem.5b00224 * |
| REMON VAN GEEL ET AL: "Chemoenzymatic Conjugation of Toxic Payloads to the Globally Conserved N-Glycan of Native mAbs Provides Homogeneous and Highly Efficacious Antibody-Drug Conjugates: Supplementary information General Method and Materials", BIOCONJUGATE CHEMISTRY 2015, 26, 11, 1 January 2015 (2015-01-01), pages 2233 - 2242, XP055378444, Retrieved from the Internet <URL:http://pubs.acs.org/doi/suppl/10.1021/acs.bioconjchem.5b00224> [retrieved on 20170602], DOI: http://pubs.acs.org/doi/suppl/10.1021/acs.bioconjchem.5b00224 * |
| SENTER ET AL., NAT. BIOTECHN., vol. 24, 2014, pages 1256 - 1263 |
| THOMAS H. PILLOW ET AL: "Site-Specific Trastuzumab Maytansinoid Antibody-Drug Conjugates with Improved Therapeutic Activity through Linker and Antibody Engineering", JOURNAL OF MEDICINAL CHEMISTRY, vol. 57, no. 19, 9 October 2014 (2014-10-09), pages 7890 - 7899, XP055268691, ISSN: 0022-2623, DOI: 10.1021/jm500552c * |
| WANG ET AL., CHEM. EUR. J., vol. 16, 2010, pages 13343 - 13345 |
| XUEJING YAO ET AL: "A novel humanized anti-HER2 antibody conjugated with MMAE exerts potent anti-tumor activity", BREAST CANCER RESEARCH AND TREATMENT., vol. 153, no. 1, 8 August 2015 (2015-08-08), US, pages 123 - 133, XP055370764, ISSN: 0167-6806, DOI: 10.1007/s10549-015-3503-3 * |
Cited By (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3413916A1 (en) * | 2016-02-08 | 2018-12-19 | Synaffix B.V. | Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates |
| US11384098B2 (en) | 2017-02-08 | 2022-07-12 | Adc Therapeutics Sa | Pyrrolobenzodiazepine-antibody conjugates |
| WO2019110725A1 (en) * | 2017-12-06 | 2019-06-13 | Synaffix B.V. | Enediyne conjugates |
| CN111683686A (en) * | 2017-12-06 | 2020-09-18 | 西纳福克斯股份有限公司 | Enediyne conjugates |
| US20230346965A1 (en) * | 2017-12-06 | 2023-11-02 | Synaffix B.V. | Enediyne conjugates |
| US11547763B2 (en) | 2017-12-06 | 2023-01-10 | Synahix B.V. | Enediyne conjugates |
| WO2020094670A1 (en) * | 2018-11-05 | 2020-05-14 | Synaffix B.V. | Antibody-conjugates for targeting of tumours expressing trop-2 |
| CN113260384A (en) * | 2018-11-05 | 2021-08-13 | 西纳福克斯股份有限公司 | Antibody conjugates for targeting TROP-2 expressing tumors |
| WO2020245229A1 (en) | 2019-06-03 | 2020-12-10 | Synaffix B.V. | Acetal-based cleavable linkers |
| US11786605B2 (en) | 2020-01-09 | 2023-10-17 | Mersana Therapeutics, Inc. | Site specific antibody-drug conjugates with peptide-containing linkers |
| EP4161582A4 (en) * | 2020-06-05 | 2024-05-15 | Development Center for Biotechnology | Antibody-drug conjugates containing an anti-mesothelin antibody and uses thereof |
| WO2022049211A1 (en) | 2020-09-02 | 2022-03-10 | Synaffix B.V. | Methods for the preparation of bioconjugates |
| WO2022051665A1 (en) * | 2020-09-03 | 2022-03-10 | Dyne Therapeutics, Inc. | Methods of preparing protein-oligonucleotide complexes |
| WO2022108452A1 (en) * | 2020-11-20 | 2022-05-27 | Synaffix B.V. | Tyrosine-based antibody conjugates |
| NL2026947B1 (en) * | 2020-11-20 | 2022-07-01 | Synaffix Bv | Tyrosine-based antibody conjugates |
| CN114605367A (en) * | 2020-12-03 | 2022-06-10 | 中国人民解放军军事科学院军事医学研究院 | Linker containing coumarin and antibody conjugate drug containing same |
| CN114605367B (en) * | 2020-12-03 | 2023-06-27 | 中国人民解放军军事科学院军事医学研究院 | Coumarin-containing linker and antibody-conjugated drug containing the same |
| WO2022167689A1 (en) * | 2021-02-08 | 2022-08-11 | Synaffix B.V. | Multifunctional antibodies |
| WO2022187591A1 (en) | 2021-03-05 | 2022-09-09 | Go Therapeutics, Inc. | Anti-glyco-cd44 antibodies and their uses |
| WO2023014863A1 (en) | 2021-08-05 | 2023-02-09 | Go Therapeutics, Inc. | Anti-glyco-muc4 antibodies and their uses |
| WO2023065137A1 (en) * | 2021-10-20 | 2023-04-27 | Glyco-Therapy Biotechnology Co., Ltd. | Site-specific glycoprotein conjugates and methods for making the same |
| WO2024038065A1 (en) | 2022-08-15 | 2024-02-22 | Synaffix B.V. | Anthracyclins and conjugates thereof |
| WO2024117938A1 (en) * | 2022-11-30 | 2024-06-06 | Общество с ограниченной ответственностью "СИСТЕМА-БИОТЕХ" | Methods for producing bioconjugates for liver-specific targeted proteome modulation |
| WO2024153232A1 (en) * | 2023-01-19 | 2024-07-25 | 上海盛迪医药有限公司 | Tyrosinase-mediated protein site-specific conjugation and use thereof |
| WO2024160926A1 (en) | 2023-01-31 | 2024-08-08 | Synaffix B.V. | Homogeneous antibody-conjugates with high payload loading |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2017137457A9 (en) | 2018-10-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11957763B2 (en) | Sulfamide linkers for use in bioconjugates | |
| US20230127659A1 (en) | Antibody-conjugates with improved therapeutic index for targeting her2 tumours and method for improving therapeutic index of antibody-conjugates | |
| WO2017137457A1 (en) | Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates | |
| JP7488003B2 (en) | Bioconjugates Containing Sulfamide Linkers for Use in Therapy - Patent application | |
| US11850286B2 (en) | Sulfamide linker, conjugates thereof, and methods of preparation | |
| EP3413916A1 (en) | Antibody-conjugates with improved therapeutic index for targeting cd30 tumours and method for improving therapeutic index of antibody-conjugates | |
| CN113260384A (en) | Antibody conjugates for targeting TROP-2 expressing tumors | |
| JP2017200902A (en) | Novel antibody-conjugate with improved therapeutic index for targeting HER2 tumor and method for improving therapeutic index of antibody-conjugate | |
| JP2017197512A (en) | Novel antibody-conjugates with improved therapeutic index for targeting cd30 tumors and methods for improving therapeutic index of antibody-conjugates | |
| EP4450489A1 (en) | Stable 4-isoxazoline conjugates | |
| WO2024218164A1 (en) | Stable 4-isoxazoline conjugates |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| 121 | Ep: the epo has been informed by wipo that ep was designated in this application |
Ref document number: 17703993 Country of ref document: EP Kind code of ref document: A1 |
|
| NENP | Non-entry into the national phase |
Ref country code: DE |
|
| WWE | Wipo information: entry into national phase |
Ref document number: 2017703993 Country of ref document: EP |
|
| ENP | Entry into the national phase |
Ref document number: 2017703993 Country of ref document: EP Effective date: 20180910 |