JP4257563B2 - Information processing apparatus and method, recording medium, and database construction apparatus - Google Patents
Information processing apparatus and method, recording medium, and database construction apparatus Download PDFInfo
- Publication number
- JP4257563B2 JP4257563B2 JP2000261030A JP2000261030A JP4257563B2 JP 4257563 B2 JP4257563 B2 JP 4257563B2 JP 2000261030 A JP2000261030 A JP 2000261030A JP 2000261030 A JP2000261030 A JP 2000261030A JP 4257563 B2 JP4257563 B2 JP 4257563B2
- Authority
- JP
- Japan
- Prior art keywords
- data stream
- divided data
- search
- database
- divided
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images









Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Reverberation, Karaoke And Other Acoustics (AREA)
Description
【0001】
【発明の属する技術分野】
本発明は、情報処理装置および方法、記録媒体、並びにデータベース構築装置に関し、例えば、テレビジョン放送などで使用された楽曲に関する情報のデータベースを構築する場合に用いて好適な情報処理装置および方法、記録媒体、並びにデータベース構築装置に関する。
【0002】
【従来の技術】
例えば、視聴者がテレビジョン放送を視聴しているとき、番組の中で使用された楽曲についての属性情報(曲名、歌手名等)を知りたいと思うことがあり、従来、そのような要求に応じて、放送番組において使用された楽曲についての属性情報を提供するサービス機関が存在する。
【0003】
【発明が解決しようとする課題】
そのようなサービス機関においては、テレビジョン放送などで使用された楽曲についての属性情報を時系列的に整理してデータベースを構築しているが、当該データベースを構築する過程の大半を人力に頼っている。すなわち、当該データベースは、各種の楽曲に精通している人がテレビジョン放送等の番組をリアルタイムで視聴しながら、または録画した番組を視聴しながら楽曲を検知し、検知した楽曲の曲名、歌手名などを判定して、判定した情報を蓄積することによって構築されている。
【0004】
このように、放送された楽曲についての属性情報をデータベース化する従来の方法は、人力に頼っているが故、楽曲が放送されてからデータベースに登録されるまでに1日程度の遅延を要してしまう課題があった。
【0005】
また、放送された番組を録画し、それを再生してデータベースを構築する方法は、放送される番組に含まれる楽曲以外の部分も記録するので、記録に用いる記録媒体の容量が有効に利用されていない課題がある。
【0006】
さらに人力に頼っているが故、処理能力に限界があり、放送番組の数が一層増加した場合などにおいては、人材が不足する事態が考えられる。
【0007】
本発明はこのような状況に鑑みてなされたものであり、テレビジョン放送などで使用された楽曲に関する属性情報のデータベースを自動的に構築できるようにすることを目的とする。
【0008】
【課題を解決するための手段】
本発明の情報処理装置は、データストリームを入力する入力手段と、データストリームの入力時刻を供給する供給手段と、データストリームに入力時刻を対応付けて蓄積する蓄積手段と、1次検索処理として、入力されたデータストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、データストリームを所定の期間毎に分割して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、生成した特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理手段と、2次検索前処理として、蓄積手段に蓄積されたデータストリームを所定の期間毎に読み出して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、分割データストリームに、生成された特徴情報と入力時刻を対応付けて、検索履歴データベースを構築し、検索履歴データベースに記録されている分割データストリームであって、検索結果データベースに記録されていない分割データストリームを特定し、特定された分割データストリームに特徴情報および入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理手段と、2次検索処理として、2次検索待ちデータベースに登録されている分割データストリームの特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースに追加登録する処理を行う2次検索処理手段とを含む。
【0009】
本発明の情報処理方法は、入力手段による、データストリームを入力する入力ステップと、供給手段による、データストリームの入力時刻を供給する供給ステップと、蓄積手段による、データストリームに入力時刻を対応付けて蓄積する蓄積ステップと、1次検索処理手段による、入力されたデータストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、データストリームを所定の期間毎に分割して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、生成した特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理ステップと、2次検索前処理手段による、蓄積手段に蓄積されたデータストリームを所定の期間毎に読み出して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、分割データストリームに、生成された特徴情報と入力時刻を対応付けて、検索履歴データベースを構築し、検索履歴データベースに記録されている分割データストリームであって、検索結果データベースに記録されていない分割データストリームを特定し、特定された分割データストリームに特徴情報および入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理ステップと、2次検索処理手段による、2次検索待ちデータベースに登録されている分割データストリームの特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースに追加登録する処理を行う2次検索処理ステップとを含む。
【0010】
本発明のプログラムは、データストリームを入力する入力ステップと、データストリームの入力時刻を供給する供給ステップと、データストリームに入力時刻を対応付けて蓄積する蓄積ステップと、1次検索処理として、入力されたデータストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、データストリームを所定の期間毎に分割して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、生成した特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理ステップと、2次検索前処理として、蓄積手段に蓄積されたデータストリームを所定の期間毎に読み出して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、分割データストリームに、生成された特徴情報と入力時刻を対応付けて、検索履歴データベースを構築し、検索履歴データベースに記録されている分割データストリームであって、検索結果データベースに記録されていない分割データストリームを特定し、特定された分割データストリームに特徴情報および入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理ステップと、2次検索処理として、2次検索待ちデータベースに登録されている分割データストリームの特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースに追加登録する処理を行う2次検索処理ステップとを含む処理を情報処理装置のコンピュータに実行させる、コンピュータが読み取り可能なプログラムが記録されている。
【0011】
本発明のデータベース構築装置は、パッケージメディアに記録されたコンテンツデータを読み出す読み出し手段と、読み出されたコンテンツデータの特徴情報を抽出する抽出手段と、コンテンツデータの属性情報に、抽出された特徴情報を対応付けてコンテンツデータベースを構築する構築手段と、データストリームを入力する入力手段と、データストリームの入力時刻を供給する供給手段と、データストリームに入力時刻を対応付けて蓄積する蓄積手段と、1次検索処理として、入力されたデータストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、データストリームを所定の期間毎に分割して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、生成した特徴情報に基づき、コンテンツデータベースを参照して、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理手段と、2次検索前処理として、蓄積手段に蓄積されたデータストリームを所定の期間毎に読み出して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、分割データストリームに、生成された特徴情報と入力時刻を対応付けて、検索履歴データベースを構築し、検索履歴データベースに記録されている分割データストリームであって、検索結果データベースに記録されていない分割データストリームを特定し、特定された分割データストリームに特徴情報および入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理手段と、2次検索処理として、2次検索待ちデータベースに登録されている分割データストリームの特徴情報に基づき、コンテンツデータベースを参照して、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースに追加登録する処理を行う2次検索処理手段とを含む。
【0012】
本発明においては、1次検索処理として、入力されたデータストリームが処理可能であるか否か判定され、処理可能であると判定された場合に、データストリームを所定の期間毎に分割して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、生成した特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースを構築する処理を行う。また、2次検索前処理として、蓄積手段に蓄積されたデータストリームを所定の期間毎に読み出して分割データストリームを生成し、分割データストリームの種類を判別し、所定の種類のデータと判別された場合、分割データストリームの特徴情報を生成し、分割データストリームに、生成された特徴情報と入力時刻を対応付けて、検索履歴データベースを構築し、検索履歴データベースに記録されている分割データストリームであって、検索結果データベースに記録されていない分割データストリームを特定し、特定された分割データストリームに特徴情報および入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う。さらに、2次検索処理として、2次検索待ちデータベースに登録されている分割データストリームの特徴情報に基づき、分割データストリームに対応する属性情報を検索し、検索結果として分割データストリームに対応する属性情報が得られた場合、分割データストリームに、検索した属性情報と入力時刻を対応付けて、検索結果データベースに追加登録する処理を行う。
【0015】
【発明の実施の形態】
本発明を適用したデータベース構築システムの構成例について、図1を参照して説明する。このデータベース構築システムは、音楽CD(Compact Disc)等のパッケージメディアに記録されている楽曲の音声信号を読み出し、その楽曲の特徴を検出して、曲名等の属性情報に対応付けて楽曲データベースを構築する楽曲データベース(DB)構築装置1、および、テレビジョン放送などの番組から楽曲を検知してその楽曲の特徴を検出し、楽曲データベース構築装置1が構築した楽曲データベースに照合して、楽曲の曲名等の属性情報を、放送時刻と対応付けてプレイリストデータベースを構築するプレイリストデータベース(DB)構築装置8より構成される。
【0016】
楽曲データベース構築装置1の構成例について説明する。入力部2は、プレーヤ7から入力される楽曲の音声信号を受け付け、後段の種別判定部3以降において処理可能なWAVE形式等の信号に変換して種別判定部3に出力する。種別判定部3は、WAVE形式等の音声信号を解析し、当該楽曲を特定可能な音楽的な特徴を判定して変換部4に出力する。変換部4は、種別判定部3が判定した音楽的な特徴を数値化して当該楽曲の特徴情報を生成し、記録部5に出力する。
【0017】
記録部5は、変換部4が生成した特徴情報に、当該楽曲の属性情報(楽曲ID、楽曲名、歌手名(演奏者名)、作詞者名、作曲者名、当該音楽CDの発売元、著作権所有者名等)を対応付けて楽曲データベースを構築し、記録媒体6に記録する。
【0018】
なお、楽曲の属性情報のうち、音楽CD等のパッケージメディアに記録されている情報は読み出して利用するようにし、その他の情報は、楽曲データベース構築装置1のユーザが入力するようにする。
【0019】
プレーヤ7は、音楽CD等に記録されている楽曲の音声信号を読み出して楽曲データベース構築装置1の入力部2に出力する。プレーヤ7はまた、音楽CD等に属性情報が記録されている場合、それらも読み出して楽曲データベース構築装置1の入力部2に出力する。
【0020】
次に、プレイリストデータベース構築装置8の構成例について説明する。入力部9は、チューナ18または記録再生部11から入力されるテレビジョン放送などの音声信号を受け付けて所定の期間(例えば、1分間)毎に区切り、後段の種別判定部12以降において処理可能なWAVE形式等の信号に変換して、時刻供給部10から供給される時刻(当該音声信号の放送時刻に相当する)の情報とともに種別判定部12に出力する。入力部9はまた、チューナ18からの音声信号に、時刻供給部10からの時刻情報を対応付けて記録再生部11に出力する。
【0021】
時刻情報供給部10は、NTP(Network Time Protocol)サーバ等に接続して内蔵する時計を整合し、その時計が示す時刻情報を入力部9に出力する。記録再生部11は、入力部9から入力される音声信号を所定の方式(例えば、MPEG2方式)を用いてエンコードし、同時に入力される時刻情報に対応付けて記録媒体(不図示)に記録する。また、記録再生部11は、記録媒体からエンコードされている音声信号と時刻情報を読み出し、デコードして入力部9に供給する。
【0022】
種別判定部12は、入力部9から入力される所定の期間毎の音声信号の種別を、楽曲、会話、物体の動作音などに分類し、楽曲に分類した音声信号を変換部13に出力する。変換部13は、楽曲に分類した音声信号の音楽的な特徴を検出して数値化し、特徴情報として照合部14に出力する。照合部14は、変換部13から入力される特徴情報を、楽曲データベース構築装置1が構築した楽曲データベースと照合し、その照合結果を集計部15に出力する。具体的には、楽曲データベースに特徴情報が一致する楽曲が存在すると判定した場合、その属性情報を楽曲データベースから読み出して、時刻情報とともに集計部15に出力する。反対に、特徴情報が一致する楽曲が存在しないと判定した場合、照合部14は、変換部13で変換した特徴情報と時刻情報を照合結果として集計部15に出力する。なお、楽曲データベースに特徴情報が一致する楽曲が存在するか否かは、数値化された特徴情報の差異が所定の閾値以下であるか否かに基づいて判定する。
【0023】
集計部15は、照合部14から入力される照合結果を集計し、プレイリストデータベースを生成して記録部16に出力する。ここで、プレイリストとは、所定の放送チャンネルにおいて使用された楽曲の属性情報が時系列的に蓄積されたものであり、その項目は、放送局名(チャンネル)、放送日時の他、楽曲データベースから読み出した属性情報(楽曲ID、楽曲名、歌手名(演奏者名)、作詞者名、作曲者名、当該CDの発売元、著作権所有者名等)から成る。
【0024】
集計部15はまた、入力部9、変換部13、記録媒体17等から図示せぬ経路を介して入力される処理結果等を集計し、所定のデータベース(詳細後述)を生成して記録部16に出力する。記録部16は、集計部15から入力されるプレイリストデータベース等を記録媒体17に記録する。
【0025】
チューナ18は、テレビジョン放送やラジオ放送の放送信号を受信し、所定のチャンネルの音声信号をプレイリストデータベース構築装置8の入力部9に出力する。
【0026】
次に、楽曲データベース構築装置1の楽曲データベース構築処理について、図2のフローチャートを参照して説明する。ステップS1において、入力部2は、プレーヤ7から楽曲の音声信号を取得し、後段の種別判定部3以降において処理可能なWAVE形式等の信号に変換して種別判定部3に出力する。ステップS2において、種別判定部3は、WAVE形式等の音声信号を解析し、当該楽曲を特定可能な音楽的な特徴を判定して変換部4に出力する。変換部4は、種別判定部3が判定した音楽的な特徴を数値化して当該楽曲の特徴情報を生成し、記録部5に出力する。
【0027】
ステップS3において、記録部5は、変換部4から入力された特徴情報に、所定の方法によって入力した当該楽曲の属性情報を対応付けて楽曲データベースを構築し、記録媒体6に記録する。
【0028】
なお、この楽曲データベース構築処理は、既存の音楽CD等や新たに発売される音楽CDに対して速やかに実行するようにする。また、音楽CD化されていないコマーシャルソングなどについても、その音源を可能な限り調達して楽曲データベース構築処理を施すようにする。
【0029】
次に、プレイリストデータベース構築装置8の第1の動作例について、図3のフローチャートを参照して説明する。ステップS11において、チューナ18は、テレビジョン放送やラジオ放送の放送信号を受信し、所定のチャンネルの音声信号をプレイリストデータベース構築装置8の入力部9に出力する。
【0030】
入力部9は、チューナ18から入力された音声信号に時刻供給部10からの時刻情報を対応付けて記録再生部11に出力する。記録再生部11は、入力部9から順次入力された音声信号を所定の方式でエンコードし、同時に入力された時刻情報に対応付けて記録媒体に記録する。
【0031】
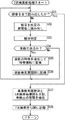
ステップS12において、1次検索処理が実行される。1次検索処理の詳細について、図4のフローチャートを参照して説明する。
【0032】
ステップS21において、入力部9は、種別判定部12以降において上段からの信号を処理可能であるか否かを判定する。処理可能であると判定された場合、処理はステップS22に進む。
【0033】
ステップS22において、入力部9は、チューナ18から入力された音声信号を所定の期間毎に区切り、WAVE形式等の信号に変換して時刻供給部10からの時刻情報とともに種別判定部12に出力する。
【0034】
ステップS23において、種別判定部12は、入力部9から入力された所定の期間毎の音声信号の種別を分類する。ステップS24において、種別判定部12は、ステップS23での種別の判別結果が楽曲であるか否かを判定し、種別の判別結果が楽曲であると判定した場合、処理はステップS25に進む。
【0035】
ステップS25において、種別判定部12は、処理対象となっているWAVE形式等の音声信号を変換部13に出力する。変換部13は、種別判定部12から入力された、楽曲に分類された音声信号の音楽的な特徴を検出して数値化し、特徴情報として照合部14に出力する。ステップS26において、照合部14は、変換部13から入力された特徴情報を、楽曲データベース構築装置1が構築した楽曲データベースと照合し、その照合結果として、楽曲データベースに特徴情報が一致する楽曲が存在すると判定された場合、その属性情報と時刻情報(放送時刻)を集計部15に出力する。
【0036】
ステップS27において、集計部15は、照合部14から入力された照合結果(楽曲の属性情報と放送時刻情報)を登録した1次検索結果データベースを生成して記録部16に出力する。記録部16は、集計部15から入力された1次検索結果データベースを記録媒体17に記録する。
【0037】
なお、ステップS21において、種別判定部12以降が上段からの信号を処理可能ではないと判定された場合、図3のステップS13にリターンする。
【0038】
また、ステップS24において、種別の判別結果が楽曲ではないと判定された場合、処理はステップS21に戻り、それ以降の処理が繰り返される。
【0039】
図3に戻る。ステップS13において、2次検索前処理が実行される。なお、この2次検索前処理は、ステップS12での1次検索処理と平行して実行するようにしてもよい。
【0040】
2次検索前処理の詳細について、図5のフローチャートを参照して説明する。ステップS31において、記録再生部11は、図3のステップS11の処理でエンコードした音声信号を記録した記録媒体に、まだ読み出しておらず、入力部9に供給していない期間の音声信号があるか否かを判定する。入力部9に供給していない期間の音声信号があると判定された場合、処理はステップS32に進む。
【0041】
ステップS32において、記録再生部11は、記録媒体からエンコードされた音声信号を所定の期間(例えば、1分間)毎を読み出してデコードし、入力部9に出力する。入力部9は、記録再生部11からの音声信号をWAVE形式等の信号に変換して時刻供給部10からの時刻情報とともに種別判定部12に出力する。
【0042】
ステップS33において、種別判定部12は、入力部9から入力された所定の期間毎の音声信号の種別を分類する。ステップS34において、種別判定部12は、ステップS23での種別の判別結果が楽曲であるか否かを判定し、種別の判別結果が楽曲であると判定した場合、処理はステップS35に進む。
【0043】
ステップS35において、種別判定部12は、処理対象となっているWAVE形式等の音声信号を変換部13に出力する。変換部13は、種別判定部12から入力された、楽曲に分類された音声信号の音楽的な特徴を検出して数値化し、特徴情報として集計部15に出力する。ステップS36において、集計部15は、楽曲と判定された音声信号が放送された時刻とその特徴情報を対応付けて楽曲検索履歴データベースを構築し、記録部16に出力する。よって、楽曲検索履歴データベースには、放送の一連の音声信号のうち、楽曲と判定された期間の時刻情報と、それに対応する特徴情報が登録されることになる。記録部16は、集計部15から入力された楽曲検索履歴データベースを記録媒体17に記録する。
【0044】
なお、ステップS34において、種別の判別結果が楽曲であると判定されない場合、ステップS35,S36の処理はスキップされる。
【0045】
処理はステップS31に戻り、入力部9に供給していない期間の音声信号がないと判定されるまで、以降の処理が繰り返される。そして、ステップS31において、入力部9に供給していない期間の音声信号がないと判定された場合、処理はステップS37に進む。
【0046】
ステップS37において、集計部15は、ステップS36で記録された楽曲検索履歴データベースと、1次検索処理のステップS27で記録された1次検索結果データベースを比較して、楽曲検索履歴データベースの記録のうち、1次検索結果データベースに対応する記録が存在しないもの、すなわち、楽曲の期間であるとして判定されているが、その楽曲名等の属性情報が判明していない音声信号の放送時刻とその特徴情報を抽出し、それらを登録した2次検索待ちデータベースを生成して記録部17に出力する。ステップS38において、記録部17は、集計部15から入力された2次検索待ちデータベースを記録媒体17に記録する。
【0047】
処理は図3のステップS14にリターンする。ステップS14において、2次検索処理が開始される。この2次検索処理の詳細について、図6のフローチャートを参照して説明する。
【0048】
ステップS41において、集計部15は、2次検索前処理で生成した2次検索待ちデータベースに、当該2次検索処理を施していない記録(楽曲と判定された音声信号の放送時刻と、その特徴情報)があるか否かを判定する。当該2次検索処理を施していない記録があると判定された場合、処理はステップS42に進む。
【0049】
ステップS42において、2次検索待ちデータベースから、所定の期間の楽曲と判定された音声信号の放送時刻とその特徴情報が読み出され、照合部14に供給される。ステップS43において、照合部14は、供給された特徴情報を楽曲データベース構築装置1が構築した楽曲データベースと照合し、その照合結果を集計部15に出力する。照合結果としては、楽曲データベースに特徴情報が一致する楽曲が存在すると判定された場合(楽曲名等が判明した場合)、楽曲データベースからの楽曲の属性情報と放送時刻が集計部15に出力され、特徴情報が一致する楽曲が存在しない場合(楽曲名等が判明しない場合)、その特徴情報と放送時刻が集計部15に出力される。
【0050】
ステップS44において、集計部15は、照合部14から入力された照合結果に基づき、2次検索待ちデータベースから読み出された音声信号の楽曲名等が判明したか否かを判定する。楽曲名等が判明したと判定された場合、処理はステップS45に進む。ステップS45において、集計部15は、照合部14から照合結果として入力された楽曲の属性情報と放送時刻から成る2次検索結果データベースを生成して記録部16に出力する。記録部16は、集計部15から入力された2次検索結果データベースを記録媒体17に記録する。
【0051】
ステップS44において、楽曲名等が判明しないと判定された場合、処理はステップS46に進む。ステップS46において、集計部15は、照合部14から照合結果として入力された、楽曲と判定された音声信号の特徴情報とその放送時刻から成る未検索データベースを生成して記録部16に出力する。記録部16は、集計部15から入力された未検索データベースを記録媒体17に記録する。
【0052】
その後、ステップS41に戻り、2次検索待ちデータベースに当該2次検索処理を施していない記録はないと判定されるまで、以降の処理が繰り返される。2次検索待ちデータベースに当該2次検索処理を施していない記録はないと判定された場合、処理は図3のステップS15にリターンする。
【0053】
ステップS15において、集計部15は、ステップS12で生成した1次検索結果データベースの記録と、ステップS14で生成した2次検索結果データベースの記録を合成してプレイリストデータベースを構築し、記録部16に出力する。記録部16は、集計部15から入力されたプレイリストデータベースを記録媒体17に記録する。
【0054】
なお、ステップS46で生成した未検索データベースの記録(音声信号の特徴情報と放送時刻)については、例えば、人力によって処理し、楽曲が特定できた場合には、その情報をプレイリストデータベースに追加する。
【0055】
以上説明したように、プレイリストデータベース構築装置8の第1の動作例によれば、チューナ18から供給されるリアルタイムな音声信号に対して1次検索処理を施して1次検索結果データベースを生成し、リアルタイムな処理が限界に達した場合、2次検索前処理で楽曲と判定され、かつ、1次検索処理で楽曲名等が特定されなかった音声信号の期間に対し、2次検索処理を施して2次検索結果データベースを生成し、それらを合成してプレイリストデータベースを構築するようにしたので、テレビジョン放送等の音声信号に対して種別判定、特徴抽出等をそれぞれ2回ずつ施すことになる。よって、テレビジョン放送等の音声信号に含まれる楽曲を取りこぼすことが抑止され、楽曲名等を特定する確率が向上する。
【0056】
次に、プレイリストデータベース構築装置8の第2の動作例について、図7のフローチャートを参照して説明する。ステップS51において、チューナ18は、テレビジョン放送やラジオ放送の放送信号を受信し、所定のチャンネルの音声信号をプレイリストデータベース構築装置8の入力部9に出力する。
【0057】
入力部9は、チューナ18から入力された音声信号に時刻供給部10からの時刻情報を対応付けて記録再生部11に出力する。記録再生部11は、入力部9から順次入力された音声信号を所定の方式でエンコードし、同時に入力された時刻情報に対応付けて記録媒体に記録する。
【0058】
ステップS52において、1次検索処理が実行される。1次検索処理の詳細について、図8のフローチャートを参照して説明する。
【0059】
ステップS61において、入力部9は、種別判定部12以降において上段からの信号を処理可能であるか否かを判定する。処理可能であると判定された場合、処理はステップS62に進む。
【0060】
ステップS62において、入力部9は、チューナ18から入力された音声信号を所定の期間毎に区切り、WAVE形式等の信号に変換して時刻供給部10からの時刻情報とともに種別判定部12に出力する。
【0061】
ステップS63において、種別判定部12は、入力部9から入力された所定の期間毎の音声信号の種別を分類する。ステップS64において、種別判定部12は、ステップS63での種別の判別結果が楽曲であるか否かを判定し、種別の判別結果が楽曲であると判定した場合、処理はステップS65に進む。
【0062】
ステップS65において、種別判定部12は、処理対象となっているWAVE形式等の音声信号を変換部13に出力する。変換部13は、種別判定部12から入力された、楽曲に分類された音声信号の音楽的な特徴を検出して数値化し、特徴情報として照合部14に出力する。ステップS66において、照合部14は、変換部13から入力された特徴情報を、楽曲データベース構築装置1が構築した楽曲データベースと照合し、照合結果を集計部15に出力する。照合結果としては、楽曲データベースに特徴情報が一致する楽曲が存在すると判定された場合(楽曲名等が判明した場合)、楽曲データベースからの楽曲の属性情報と放送時刻が集計部15に出力され、特徴情報が一致する楽曲が存在しない場合(楽曲名等が判明しない場合)、その特徴情報と放送時刻が集計部15に出力される。
【0063】
ステップS67において、集計部15は、照合部14から入力された照合結果に基づき、楽曲と判定された音声信号の楽曲名等が判明したか否かを判定する。楽曲名等が判明したと判定された場合、処理はステップS68に進む。ステップS68において、集計部15は、照合部14から照合結果として入力された楽曲の属性情報と放送時刻を用い、1次検索結果データベースを生成して記録部16に出力する。記録部16は、集計部15から入力された1次検索結果データベースを記録媒体17に記録する。
【0064】
ステップS67において、楽曲名等が判明しないと判定された場合、処理はステップS69に進む。ステップS69において、集計部15は、照合部14から照合結果として入力された、楽曲と判定された音声信号の特徴情報とその放送時刻から成る2次検索待ちデータベースを生成して記録部16に出力する。記録部16は、集計部15から入力された2次検索待ちデータベースを記録媒体17に記録する。
【0065】
その後、ステップS61に戻り、種別判定部12以降において上段からの信号を処理不可能であると判定されるまで、以降の処理が繰り返される。同様に、ステップS64において、種別の判別結果が楽曲ではないと判定された場合にも、処理はステップS61に戻る。
【0066】
ステップS61において、種別判定部12以降において上段からの信号を処理不可能であると判定された場合、その時刻以降の音声信号に対して1次検索処理が施されていない旨が2次検索待ちデータベースに記録された後、処理は図7のステップS53にリターンする。ここで、2次検索待ちデータベースには、1次検索処理を施された結果、楽曲と判定されて、かつ、楽曲名等が判明していない音声信号の特徴情報と放送時刻、および、種別判定部12以降が処理不可能となったために1次検索処理が施されていない音声信号の放送時刻が記録されていることになる。
【0067】
ステップS53において、2次検索処理が実行される。2次検索処理の詳細について、図9のフローチャートを参照して説明する。
【0068】
ステップS71において、集計部15は、1次検索処理で生成した2次検索待ちデータベースに、当該2次検索処理を施していない記録(楽曲と判定された音声信号の放送時刻とその特徴情報、1次検索処理が施されていない音声信号の放送時刻)があるか否かを判定する。当該2次検索処理を施していない記録があると判定された場合、処理はステップS92に進む。
【0069】
ステップS72において、2次検索待ちデータベースから、楽曲と判定された音声信号の放送時刻とその特徴情報が読み出されて照合部14に供給される。なお、2次検索待ちデータベースから1次検索処理が施されていない音声信号の放送時刻が読み出された場合には、その情報に基づいて、ステップS52で記録した音声信号が所定の期間毎に読み出され、種別判定部12によって種別判定され、そこで楽曲と判定された期間に対してだけ、特徴情報が抽出されて特徴情報に変換されて放送時刻とともに照合部14に供給される。
【0070】
ステップS73において、照合部14は、供給された特徴情報を楽曲データベース構築装置1が構築した楽曲データベースと照合し、その照合結果を集計部15に出力する。ステップS74において、集計部15は、照合部14から入力された照合結果に基づき、処理の対象としている音声信号の楽曲名等が判明したか否かを判定する。楽曲名等が判明したと判定された場合、処理はステップS75に進む。ステップS75において、集計部15は、照合部14から照合結果として入力された楽曲の属性情報と放送時刻を用いて2次検索結果データベースを生成して記録部16に出力する。記録部16は、集計部15から入力された2次検索結果データベースを記録媒体17に記録する。
【0071】
ステップS74において、楽曲名等が判明しないと判定された場合、処理はステップS76に進む。ステップS76において、集計部15は、照合部14から照合結果として入力された、楽曲と判定された音声信号の特徴情報とその放送時刻から成る未検索データベースを生成して記録部16に出力する。記録部16は、集計部15から入力された未検索データベースを記録媒体17に記録する。
【0072】
その後、ステップS71に戻り、2次検索待ちデータベースに当該2次検索処理を施していない記録はないと判定されるまで、以降の処理が繰り返される。2次検索待ちデータベースに当該2次検索処理を施していない記録はないと判定された場合、処理は図7のステップS54にリターンする。
【0073】
ステップS54において、集計部15は、ステップS52で生成した1次検索結果データベースの記録と、ステップS53で生成した2次検索結果データベースの記録を合成してプレイリストデータベースを構築し、記録部16に出力する。記録部16は、集計部15から入力されたプレイリストデータベースを記録媒体17に記録する。
【0074】
なお、ステップS76で生成した未検索データベースの記録(音声信号の特徴情報と放送時刻)については、例えば、人力によって処理し、楽曲が特定できた場合には、その情報をプレイリストデータベースに追加する。
【0075】
以上説明したように、プレイリストデータベース構築装置8の第2の動作例によれば、チューナ18から供給される音声信号に対して種別判定、特徴検出等をそれぞれ1回だけ施すことになるので、上述した第1の動作例に比較して、一連の処理にかかる時間を減少させることが可能となる。
【0076】
なお、本実施の形態においては、テレビジョン放送やラジオ放送の音声信号に含まれる楽曲についてのプレイリストデータベースを構築する例について説明したが、本発明は、テレビジョン放送等の映像データに含まれる特定の画像のプレイリストデータベースを作成する場合などに適用することが可能である。
【0077】
また、本発明は、テレビジョン放送やラジオ放送に限らず、あらゆるストリーミングデータに含まれる所定の種別の情報のプレイリストデータベースを構築する場合に適用することが可能である。
【0078】
ところで、上述した一連の処理、またはその一部の処理は、ハードウェアにより実行させることもできるが、ソフトウェアにより実行させることもできる。一連の処理をソフトウェアにより実行させる場合には、そのソフトウェアを構成するプログラムが、専用のハードウェアに組み込まれているコンピュータ、または、各種のプログラムをインストールすることで、各種の機能を実行することが可能な、例えば汎用のパーソナルコンピュータなどに、記録媒体からインストールされる。
【0079】
図10は、汎用のパーソナルコンピュータの構成例を示している。このパーソナルコンピュータは、CPU(Central Processing Unit)21を内蔵している。CPU21にはバス24を介して、入出力インタフェース25が接続されている。入出力インタフェース25には、キーボード、マウスなどの入力デバイスよりなる入力部26、処理結果を外部に出力する出力部27、インタネットなどネットワークを介してデータを通信する通信部28、プログラムを格納するハードディスクドライブ29、および、磁気ディスク31乃至半導体メモリ34に対してデータを読み書きするドライブ30が接続されている。バス24には、ROM(Read Only Memory)22およびRAM(Random Access Memory)23が接続されている。
【0080】
プログラムが記録された記録媒体は、パーソナルコンピュータとは別に、ユーザにプログラムを提供するために配布される、プログラムが記録されている磁気ディスク31(フロッピディスクを含む)、光ディスク32(CD-ROM(Compact Disc-Read Only Memory)、DVD(Digital Versatile Disc)を含む)、光磁気ディスク33(MD(Mini Disc)を含む)、もしくは半導体メモリ34などよりなるパッケージメディア、または、プログラムが一時的もしくは永続的に格納されるROMやハードディスクなどにより構成される。記録媒体へのプログラムの格納は、必要に応じてルータ、モデムなどのインタフェースを介して、ローカルエリアネットワーク、インタネット、ディジタル衛星放送といった、有線または無線の通信媒体を利用して行われる。
【0081】
このパーソナルコンピュータに上述したような処理を実行させるプログラムは、記録媒体に格納された状態でパーソナルコンピュータに供給され、ドライブ30によって読み出されて、ハードディスクドライブ29にインストールされている。ハードディスクドライブ29にインストールされているプログラムは、入力部26に入力されるユーザからのコマンドに対応するCPU21の指令によって、ハードディスクドライブ29からRAM23にロードされて実行される。
【0082】
なお、本明細書において、記録媒体に記録されるプログラムを記述するステップは、記載された順序に従って時系列的に行われる処理はもちろん、必ずしも時系列的に処理されなくとも、並列的あるいは個別に実行される処理をも含むものである。
【0083】
また、本明細書において、システムとは、複数の装置により構成される装置全体を表すものである。
【0084】
【発明の効果】
以上のように、本発明によれば、データストリームに含まれる所定の種類のデータに関する属性情報のデータベースを自動的に構築する事が可能となる。
【図面の簡単な説明】
【図1】本発明を適用したデータベース構築システムの構成例を示すブロック図である。
【図2】楽曲データベース構築装置1の楽曲データベース構築処理を説明するフローチャートである。
【図3】プレイリストデータベース構築装置8の第1のプレイリストデータベース構築処理を説明するフローチャートである。
【図4】図3のステップS12の1次検索処理の詳細を説明するフローチャートである。
【図5】図3のステップS13の2次検索前処理の詳細を説明するフローチャートである。
【図6】図3のステップS14の2次検索処理の詳細を説明するフローチャートである。
【図7】プレイリストデータベース構築装置8の第2のプレイリストデータベース構築処理を説明するフローチャートである。
【図8】図7のステップS52の1次検索処理の詳細を説明するフローチャートである。
【図9】図7のステップS53の2次検索処理の詳細を説明するフローチャートである。
【図10】汎用のパーソナルコンピュータの構成例を示すブロック図である。
【符号の説明】
1 楽曲データベース構築装置, 2 入力部, 3 種別判定部, 4 変換部, 5 記録部, 6 記録媒体, 7 プレーヤ, 8 プレイリストデータベース構築装置, 9 入力部, 10 時刻情報供給部, 11 記録再生部, 12 種別判定部, 13 変換部, 14 照合部, 15 集計部, 16 記録部, 17 記録媒体[0001]
BACKGROUND OF THE INVENTION
The present invention relates to an information processing apparatus and method. , recoding media And database construction device For example, an information processing apparatus and method suitable for use in constructing a database of information related to music used in television broadcasting, etc. , recoding media And database construction device About.
[0002]
[Prior art]
For example, when a viewer is watching a television broadcast, he / she may want to know attribute information (song name, singer name, etc.) about the music used in the program. Accordingly, there are service organizations that provide attribute information about music used in broadcast programs.
[0003]
[Problems to be solved by the invention]
In such service organizations, a database is constructed by organizing attribute information about music used in television broadcasting in a time series, but most of the process of constructing the database relies on human power. Yes. That is, the database detects a song while a person who is familiar with various songs watches a television broadcast program or the like in real time or watches a recorded program, and detects the song name and singer name of the detected song. It is constructed by accumulating the determined information.
[0004]
As described above, the conventional method of creating a database of attribute information about broadcasted music relies on human power, so it takes a delay of about one day from the time the music is broadcast until it is registered in the database. There was a problem.
[0005]
In addition, the method of recording a broadcasted program and reproducing it to construct a database also records parts other than the music included in the broadcasted program, so the capacity of the recording medium used for recording is effectively utilized. There are not challenges.
[0006]
Furthermore, since it relies on human power, there is a limit to processing capacity, and when the number of broadcast programs further increases, there may be a situation where human resources are insufficient.
[0007]
The present invention has been made in view of such a situation, and an object thereof is to automatically construct a database of attribute information relating to music used in television broadcasting or the like.
[0008]
[Means for Solving the Problems]
The information processing apparatus according to the present invention includes an input unit that inputs a data stream, a supply unit that supplies an input time of the data stream, a storage unit that stores the input time in association with the data stream, and a primary search process. If it is determined whether the input data stream can be processed and if it is determined that it can be processed, A data stream is divided every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and if it is determined to be a predetermined type of data, the feature information of the divided data stream is generated and generated Based on the feature information, the attribute information corresponding to the divided data stream is searched, and when the attribute information corresponding to the divided data stream is obtained as a search result, the searched attribute information and the input time are associated with the divided data stream. , A primary search processing means for performing processing for constructing a search result database, and secondary search pre-processing, In accumulation means The accumulated data stream is read every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and when it is determined as the predetermined type of data, the feature information of the divided data stream is generated, The divided data stream is a divided data stream that is recorded in the search history database by associating the generated feature information and the input time with the divided data stream, and is recorded in the search history database. Secondary search preprocessing means for performing processing for identifying a stream, associating feature information and input time with the specified divided data stream and registering them in the secondary search wait database, and waiting for secondary search as secondary search processing Based on the feature information of the divided data stream registered in the database, the divided data When attribute information corresponding to a stream is searched and attribute information corresponding to a divided data stream is obtained as a search result, the searched attribute information and input time are associated with the divided data stream and additionally registered in the search result database. Secondary search processing means for performing the processing.
[0009]
An information processing method according to the present invention includes an input step of inputting a data stream by an input unit, a supply step of supplying an input time of the data stream by a supply unit, and an input time associated with the data stream by an accumulation unit. By the accumulation step to accumulate and the primary search processing means, If it is determined whether the input data stream can be processed and if it is determined that it can be processed, A data stream is divided every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and if it is determined to be a predetermined type of data, the feature information of the divided data stream is generated and generated Based on the feature information, the attribute information corresponding to the divided data stream is searched, and when the attribute information corresponding to the divided data stream is obtained as a search result, the searched attribute information and the input time are associated with the divided data stream. , By a primary search processing step for performing processing for constructing a search result database, and a secondary search preprocessing means, In accumulation means The accumulated data stream is read every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and when it is determined as the predetermined type of data, the feature information of the divided data stream is generated, The divided data stream is a divided data stream that is recorded in the search history database by associating the generated feature information and the input time with the divided data stream, and is recorded in the search history database. A secondary search preprocessing step for performing a process of specifying a stream, associating feature information and an input time with the specified divided data stream and registering it in the secondary search waiting database, and a secondary search by the secondary search processing means Based on the feature information of the divided data stream registered in the waiting database When attribute information corresponding to a data stream is searched and attribute information corresponding to a divided data stream is obtained as a search result, the searched attribute information and input time are associated with the divided data stream and added to the search result database. And a secondary search processing step for performing a registration process.
[0010]
The program of the present invention includes an input step for inputting a data stream, a supply step for supplying the input time of the data stream, an accumulation step for storing the data stream in association with the input time, and a primary search process. If it is determined whether the input data stream can be processed and if it is determined that it can be processed, A data stream is divided every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and if it is determined to be a predetermined type of data, the feature information of the divided data stream is generated and generated Based on the feature information, the attribute information corresponding to the divided data stream is searched, and when the attribute information corresponding to the divided data stream is obtained as a search result, the searched attribute information and the input time are associated with the divided data stream. As a primary search processing step for performing a process for constructing a search result database and a secondary search pre-processing, In accumulation means The accumulated data stream is read every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and when it is determined as the predetermined type of data, the feature information of the divided data stream is generated, The divided data stream is a divided data stream that is recorded in the search history database by associating the generated feature information and the input time with the divided data stream, and is recorded in the search history database. A secondary search pre-processing step for performing processing for specifying a stream, associating feature information and input time with the specified divided data stream and registering it in the secondary search waiting database, and waiting for secondary search as the secondary search processing Based on the feature information of the divided data stream registered in the database, the divided data When attribute information corresponding to a divided data stream is obtained as a search result, the attribute information corresponding to the divided data stream is associated with the divided data stream and added to the search result database. Causing the computer of the information processing apparatus to execute processing including a secondary search processing step for performing processing of registration , Computer readable The program is recorded.
[0011]
The database construction apparatus according to the present invention includes a reading means for reading content data recorded on a package medium, an extracting means for extracting feature information of the read content data, and feature information extracted as attribute information of the content data. A construction means for constructing a content database in association with each other, an input means for inputting a data stream, a supply means for supplying an input time of the data stream, a storage means for associating an input time with the data stream, and 1 As the next search process, If it is determined whether the input data stream can be processed and if it is determined that it can be processed, A data stream is divided every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and if it is determined to be a predetermined type of data, the feature information of the divided data stream is generated and generated Based on the feature information, the attribute information corresponding to the divided data stream is searched by referring to the content database, and the attribute information corresponding to the divided data stream is obtained as a search result. And a primary search processing means for performing a process of constructing a search result database by associating the input time with each other, In accumulation means The accumulated data stream is read every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and when it is determined as the predetermined type of data, the feature information of the divided data stream is generated, The divided data stream is a divided data stream that is recorded in the search history database by associating the generated feature information and the input time with the divided data stream, and is recorded in the search history database. Secondary search preprocessing means for performing processing for identifying a stream, associating feature information and input time with the specified divided data stream and registering them in the secondary search wait database, and waiting for secondary search as secondary search processing Content based on the feature information of the divided data stream registered in the database Referring to the database, the attribute information corresponding to the divided data stream is searched, and when the attribute information corresponding to the divided data stream is obtained as a search result, the searched attribute information and the input time are associated with the divided data stream. Secondary search processing means for performing a process of additionally registering in the search result database.
[0012]
In the present invention, as the primary search process, When it is determined whether the input data stream is processable and it is determined that it can be processed, A data stream is divided every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and if it is determined to be a predetermined type of data, the feature information of the divided data stream is generated and generated Based on the feature information, the attribute information corresponding to the divided data stream is searched, and when the attribute information corresponding to the divided data stream is obtained as a search result, the searched attribute information and the input time are associated with the divided data stream. Then, process to build the search result database. As secondary search pre-processing, In accumulation means The accumulated data stream is read every predetermined period to generate a divided data stream, the type of the divided data stream is determined, and when it is determined as the predetermined type of data, the feature information of the divided data stream is generated, The divided data stream is a divided data stream that is recorded in the search history database by associating the generated feature information and the input time with the divided data stream, and is recorded in the search history database. A process of specifying a stream and associating the specified divided data stream with the feature information and the input time in the secondary search waiting database is performed. Further, as secondary search processing, attribute information corresponding to the divided data stream is searched based on the characteristic information of the divided data stream registered in the secondary search waiting database, and attribute information corresponding to the divided data stream is obtained as a search result. Is obtained, the attribute information searched and the input time are associated with the divided data stream and additionally registered in the search result database.
[0015]
DETAILED DESCRIPTION OF THE INVENTION
A configuration example of a database construction system to which the present invention is applied will be described with reference to FIG. This database construction system reads audio signals of music recorded on package media such as music CDs (Compact Discs), detects the characteristics of the music, and constructs a music database in association with attribute information such as music titles. The music database (DB) construction device 1 to be detected and the music titles of the music are detected by detecting the music from the program such as a television broadcast and detecting the characteristics of the music. And the like, and a playlist database (DB) construction device 8 that constructs a playlist database in association with the broadcast time.
[0016]
A configuration example of the music database construction device 1 will be described. The input unit 2 receives the audio signal of the music input from the player 7, converts it into a signal in the WAVE format or the like that can be processed by the subsequent type determination unit 3 and outputs it to the type determination unit 3. The type determination unit 3 analyzes an audio signal in the WAVE format, etc., determines a musical feature that can identify the music piece, and outputs it to the conversion unit 4. The conversion unit 4 converts the musical feature determined by the type determination unit 3 into a numerical value, generates feature information of the music, and outputs it to the recording unit 5.
[0017]
The recording unit 5 includes, in the feature information generated by the conversion unit 4, attribute information (music ID, music name, singer name (player name), songwriter name, composer name, distributor of the music CD, The music database is constructed by associating the copyright owner name and the like, and recorded on the recording medium 6.
[0018]
Of the music attribute information, information recorded on a package medium such as a music CD is read and used, and other information is input by the user of the music database construction device 1.
[0019]
The player 7 reads the audio signal of the music recorded on the music CD and outputs it to the input unit 2 of the music database construction apparatus 1. If the attribute information is recorded on the music CD or the like, the player 7 also reads out the attribute information and outputs it to the input unit 2 of the music database construction device 1.
[0020]
Next, a configuration example of the playlist database construction device 8 will be described. The
[0021]
The time
[0022]
The type determination unit 12 classifies the type of the audio signal input from the
[0023]
The totaling unit 15 totals the collation results input from the collation unit 14, generates a playlist database, and outputs the playlist database to the recording unit 16. Here, a playlist is a collection of attribute information of music used in a predetermined broadcast channel in time series, and its items include a broadcast station name (channel), broadcast date and time, and a music database. Attribute information (music ID, music name, singer name (performer name), songwriter name, composer name, CD release source, copyright owner name, etc.).
[0024]
The totaling unit 15 also totals processing results input from the
[0025]
The
[0026]
Next, the music database construction processing of the music database construction device 1 will be described with reference to the flowchart of FIG. In step S <b> 1, the input unit 2 acquires the audio signal of the music from the player 7, converts it into a signal in a WAVE format or the like that can be processed by the subsequent type determination unit 3 and outputs it to the type determination unit 3. In step S <b> 2, the type determination unit 3 analyzes an audio signal such as a WAVE format, determines a musical feature that can identify the music piece, and outputs it to the conversion unit 4. The conversion unit 4 converts the musical feature determined by the type determination unit 3 into a numerical value, generates feature information of the music, and outputs it to the recording unit 5.
[0027]
In step S <b> 3, the recording unit 5 constructs a music database by associating the feature information input from the conversion unit 4 with the attribute information of the music input by a predetermined method, and records it in the recording medium 6.
[0028]
Note that this music database construction process is promptly executed for an existing music CD or the like or a newly released music CD. Also, for commercial songs that are not made into music CDs, the sound source is procured as much as possible and the music database construction process is performed.
[0029]
Next, a first operation example of the playlist database construction device 8 will be described with reference to the flowchart of FIG. In step S <b> 11, the
[0030]
The
[0031]
In step S12, a primary search process is executed. Details of the primary search processing will be described with reference to the flowchart of FIG.
[0032]
In step S <b> 21, the
[0033]
In step S <b> 22, the
[0034]
In step S <b> 23, the type determination unit 12 classifies the type of the audio signal for each predetermined period input from the
[0035]
In step S <b> 25, the type determination unit 12 outputs an audio signal such as a WAVE format that is a processing target to the conversion unit 13. The conversion unit 13 detects and quantifies the musical features of the audio signal classified as music input from the type determination unit 12, and outputs it to the collation unit 14 as feature information. In step S <b> 26, the collation unit 14 collates the feature information input from the conversion unit 13 with the music database constructed by the music database construction device 1, and as a collation result, there is a music whose feature information matches the music database. If it is determined, the attribute information and time information (broadcast time) are output to the counting unit 15.
[0036]
In step S <b> 27, the counting unit 15 compares the collation result (music attribute information and broadcast time) input from the collation unit 14. Time Information) is registered, and a primary search result database is generated and output to the recording unit 16. The recording unit 16 records the primary search result database input from the totaling unit 15 in the recording medium 17.
[0037]
If it is determined in step S21 that the type determination unit 12 and subsequent units cannot process the signal from the upper stage, the process returns to step S13 in FIG.
[0038]
If it is determined in step S24 that the type determination result is not music, the process returns to step S21, and the subsequent processing is repeated.
[0039]
Returning to FIG. In step S13, secondary search pre-processing is executed. This secondary search in front The process is executed in parallel with the primary search process in step S12. like May be.
[0040]
Details of the secondary search pre-processing will be described with reference to the flowchart of FIG. In step S31, the recording / reproducing
[0041]
In step S <b> 32, the recording / reproducing
[0042]
In step S <b> 33, the type determination unit 12 classifies the type of the audio signal for each predetermined period input from the
[0043]
In step S <b> 35, the type determination unit 12 outputs an audio signal such as a WAVE format that is a processing target to the conversion unit 13. The conversion unit 13 detects and digitizes the musical features of the audio signal classified into music input from the type determination unit 12, and outputs it to the totaling unit 15 as feature information. In step S <b> 36, the totaling unit 15 constructs a music search history database by associating the time when the audio signal determined to be music is broadcast and the feature information thereof, and outputs the music search history database to the recording unit 16. Therefore, in the music search history database, time information of a period determined to be a music and a feature information corresponding thereto are registered in a series of broadcast audio signals. The recording unit 16 records the music search history database input from the totaling unit 15 in the recording medium 17.
[0044]
If it is not determined in step S34 that the type determination result is music, the processes in steps S35 and S36 are skipped.
[0045]
The processing returns to step S31, and the subsequent processing is repeated until it is determined that there is no audio signal in a period not supplied to the
[0046]
In step S37, the counting unit 15 compares the music search history database recorded in step S36 with the primary search result database recorded in step S27 of the primary search process, and records the music search history database. Broadcasting time and feature information of an audio signal that is determined not to have a record corresponding to the primary search result database, that is, a period of music but whose attribute information such as the music name is not known Are extracted, a secondary search waiting database in which they are registered is generated and output to the recording unit 17. In step S <b> 38, the recording unit 17 records the secondary search waiting database input from the totaling unit 15 in the recording medium 17.
[0047]
The process returns to step S14 in FIG. In step S14, the secondary search process is started. Details of the secondary search processing will be described with reference to the flowchart of FIG.
[0048]
In step S41, the tabulation unit 15 records in the secondary search waiting database generated in the secondary search pre-processing without the secondary search process (broadcast time of the audio signal determined to be a song and its characteristic information). ) Is determined. If it is determined that there is a record that has not been subjected to the secondary search process, the process proceeds to step S42.
[0049]
In step S <b> 42, the broadcast time of the audio signal determined to be the music of the predetermined period and the characteristic information thereof are read from the secondary search waiting database and supplied to the matching unit 14. In step S <b> 43, the collation unit 14 collates the supplied feature information with the music database constructed by the music database construction device 1, and outputs the collation result to the aggregation unit 15. As a collation result, when it is determined that there is a song whose feature information matches in the song database (when a song name or the like is found), the song attribute information and broadcast time from the song database are output to the counting unit 15. When there is no music with matching feature information (when the song name or the like is not found), the feature information and the broadcast time are output to the totaling unit 15.
[0050]
In step S <b> 44, the totaling unit 15 determines whether or not the song name of the audio signal read from the secondary search waiting database is found based on the collation result input from the collation unit 14. If it is determined that the song name or the like has been found, the process proceeds to step S45. In step S <b> 45, the counting unit 15 generates a secondary search result database including the music attribute information input from the verification unit 14 as the verification result and the broadcast time, and outputs the database to the recording unit 16. The recording unit 16 records the secondary search result database input from the totaling unit 15 in the recording medium 17.
[0051]
If it is determined in step S44 that the music title or the like is not found, the process proceeds to step S46. In step S <b> 46, the totaling unit 15 generates an unsearched database that is input from the collating unit 14 as the collation result and includes the feature information of the audio signal determined to be a music and its broadcast time, and outputs the database to the recording unit 16. The recording unit 16 records the unsearched database input from the totaling unit 15 in the recording medium 17.
[0052]
Thereafter, the process returns to step S41, and the subsequent processing is repeated until it is determined that there is no record that has not been subjected to the secondary search processing in the secondary search wait database. If it is determined that there is no record that has not been subjected to the secondary search process in the secondary search waiting database, the process returns to step S15 in FIG.
[0053]
In step S15, the counting unit 15 combines the record of the primary search result database generated in step S12 and the record of the secondary search result database generated in step S14 to construct a playlist database. Output. The recording unit 16 records the playlist database input from the totaling unit 15 in the recording medium 17.
[0054]
Note that the unsearched database record (audio signal feature information and broadcast time) generated in step S46 is processed by, for example, human power, and if the music can be identified, the information is added to the playlist database. .
[0055]
As described above, according to the first operation example of the playlist database construction device 8, the primary search processing is performed on the real-time audio signal supplied from the
[0056]
Next, a second operation example of the playlist database construction device 8 will be described with reference to the flowchart of FIG. In step S51, the
[0057]
The
[0058]
In step S52, a primary search process is executed. Details of the primary search process will be described with reference to the flowchart of FIG.
[0059]
In step S <b> 61, the
[0060]
In step S <b> 62, the
[0061]
In step S <b> 63, the type determination unit 12 classifies the type of the audio signal for each predetermined period input from the
[0062]
In step S <b> 65, the type determination unit 12 outputs an audio signal such as a WAVE format that is a processing target to the conversion unit 13. The conversion unit 13 detects and quantifies the musical features of the audio signal classified as music input from the type determination unit 12, and outputs it to the collation unit 14 as feature information. In step S <b> 66, the collation unit 14 collates the feature information input from the conversion unit 13 with the music database constructed by the music database construction device 1, and outputs the collation result to the aggregation unit 15. As a collation result, when it is determined that there is a song whose feature information matches in the song database (when a song name or the like is found), the song attribute information and broadcast time from the song database are output to the counting unit 15. When there is no music with matching feature information (when the song name or the like is not found), the feature information and the broadcast time are output to the totaling unit 15.
[0063]
In step S <b> 67, the counting unit 15 determines whether or not the music name of the audio signal determined to be a music has been found based on the verification result input from the verification unit 14. If it is determined that the song name or the like has been found, the process proceeds to step S68. In step S <b> 68, the tabulation unit 15 generates a primary search result database using the attribute information and broadcast time of the music input as the collation result from the collation unit 14 and outputs them to the recording unit 16. The recording unit 16 records the primary search result database input from the totaling unit 15 in the recording medium 17.
[0064]
If it is determined in step S67 that the music title or the like is not found, the process proceeds to step S69. In step S <b> 69, the totaling unit 15 generates a secondary search wait database that is input from the verification unit 14 as a verification result and includes the feature information of the audio signal determined to be a music and its broadcast time, and outputs the database to the recording unit 16. To do. The recording unit 16 records the secondary search waiting database input from the totaling unit 15 in the recording medium 17.
[0065]
Thereafter, the process returns to step S61, and the subsequent processing is repeated until it is determined that the signal from the upper stage cannot be processed in the type determination unit 12 and thereafter. Similarly, when it is determined in step S64 that the type determination result is not music, the process returns to step S61.
[0066]
If it is determined in step S61 that the signal from the upper stage cannot be processed by the type determination unit 12 or later, the fact that the primary search processing has not been performed on the audio signal after that time is awaiting the secondary search. After being recorded in the database, the process returns to step S53 in FIG. Here, in the secondary search waiting database, as a result of performing the primary search process, it is determined that the song is a song, and the feature information and broadcast time of the audio signal whose song name or the like is not known, and the type determination The broadcast time of the audio signal that has not been subjected to the primary search process because the part 12 and later cannot be processed is recorded.
[0067]
In step S53, a secondary search process is executed. Details of the secondary search process will be described with reference to the flowchart of FIG.
[0068]
In step S71, the counting unit 15 records in the secondary search waiting database generated by the primary search process a record that has not been subjected to the secondary search process (broadcast time of the audio signal determined to be a song and its characteristic information, 1 It is determined whether or not there is an audio signal broadcast time that has not been subjected to the next search process. If it is determined that there is a record that has not been subjected to the secondary search process, the process proceeds to step S92.
[0069]
In step S <b> 72, the broadcast time of the audio signal determined to be a song and its characteristic information are read from the secondary search waiting database and supplied to the matching unit 14. When the broadcast time of the audio signal that has not been subjected to the primary search process is read from the secondary search waiting database, the audio signal recorded in step S52 is read at predetermined intervals based on the information. The feature information is extracted, converted into feature information, and supplied to the collation unit 14 together with the broadcast time only for a period in which the information is read out, determined by the type determination unit 12 and determined as a music piece there.
[0070]
In step S <b> 73, the collation unit 14 collates the supplied feature information with the music database constructed by the music database construction device 1, and outputs the collation result to the aggregation unit 15. In step S <b> 74, the totaling unit 15 determines whether or not the music name of the audio signal to be processed has been found based on the collation result input from the collation unit 14. If it is determined that the song name or the like has been found, the process proceeds to step S75. In step S <b> 75, the aggregation unit 15 generates a secondary search result database using the music attribute information and the broadcast time input from the verification unit 14 as the verification result, and outputs the database to the recording unit 16. The recording unit 16 records the secondary search result database input from the totaling unit 15 in the recording medium 17.
[0071]
If it is determined in step S74 that the music title or the like is not found, the process proceeds to step S76. In step S <b> 76, the totaling unit 15 generates an unsearched database including the feature information of the audio signal determined as the music and the broadcast time, which are input from the verification unit 14 as the verification result, and outputs the database to the recording unit 16. The recording unit 16 records the unsearched database input from the totaling unit 15 in the recording medium 17.
[0072]
Thereafter, the process returns to step S71, and the subsequent processing is repeated until it is determined that there is no record that has not been subjected to the secondary search processing in the secondary search waiting database. If it is determined that there is no record that has not been subjected to the secondary search process in the secondary search waiting database, the process returns to step S54 in FIG.
[0073]
In step S54, the counting unit 15 combines the record of the primary search result database generated in step S52 and the record of the secondary search result database generated in step S53 to construct a playlist database, and stores it in the recording unit 16. Output. The recording unit 16 records the playlist database input from the totaling unit 15 in the recording medium 17.
[0074]
Note that the unsearched database record (audio signal feature information and broadcast time) generated in step S76 is processed by, for example, human power, and if the music can be specified, the information is added to the playlist database. .
[0075]
As described above, according to the second operation example of the playlist database construction device 8, the type determination, the feature detection, etc. are performed only once for the audio signal supplied from the
[0076]
In the present embodiment, an example of constructing a playlist database for music included in audio signals of television broadcasts and radio broadcasts has been described. However, the present invention is included in video data such as television broadcasts. The present invention can be applied when creating a playlist database of specific images.
[0077]
In addition, the present invention is not limited to television broadcasting and radio broadcasting, and can be applied to constructing a playlist database of predetermined types of information included in all streaming data.
[0078]
Incidentally, the series of processes described above or a part of the processes can be executed by hardware, but can also be executed by software. When a series of processing is executed by software, a program constituting the software may execute various functions by installing a computer incorporated in dedicated hardware or various programs. For example, it is installed from a recording medium in a general-purpose personal computer or the like.
[0079]
FIG. 10 shows a configuration example of a general-purpose personal computer. This personal computer includes a CPU (Central Processing Unit) 21. An input /
[0080]
The recording medium on which the program is recorded is distributed to provide the program to the user separately from the personal computer, and the magnetic disk 31 (including the floppy disk) on which the program is recorded, the optical disk 32 (CD-ROM ( Package media, such as Compact Disc-Read Only Memory (DVD), DVD (Digital Versatile Disc), magneto-optical disc 33 (including MD (Mini Disc)), or
[0081]
A program for causing the personal computer to execute the processing as described above is supplied to the personal computer in a state stored in a recording medium, read by the
[0082]
In the present specification, the step of describing the program recorded in the recording medium is not limited to the processing performed in time series according to the described order, but is not necessarily performed in time series, either in parallel or individually. The process to be executed is also included.
[0083]
Further, in this specification, the system represents the entire apparatus constituted by a plurality of apparatuses.
[0084]
【The invention's effect】
As described above, the present invention In According to De It is possible to automatically construct a database of attribute information relating to a predetermined type of data included in the data stream.
[Brief description of the drawings]
FIG. 1 is a block diagram showing a configuration example of a database construction system to which the present invention is applied.
FIG. 2 is a flowchart for explaining music database construction processing of the music database construction device 1;
FIG. 3 is a flowchart illustrating a first playlist database construction process of the playlist database construction device 8;
FIG. 4 is a flowchart for explaining details of a primary search process in step S12 of FIG.
FIG. 5 is a flowchart illustrating details of secondary search pre-processing in step S13 of FIG. 3;
6 is a flowchart illustrating details of a secondary search process in step S14 of FIG.
FIG. 7 is a flowchart illustrating a second playlist database construction process of the playlist database construction device 8;
FIG. 8 is a flowchart illustrating details of a primary search process in step S52 of FIG.
FIG. 9 is a flowchart illustrating details of the secondary search process in step S53 of FIG.
FIG. 10 is a block diagram illustrating a configuration example of a general-purpose personal computer.
[Explanation of symbols]
DESCRIPTION OF SYMBOLS 1 Music database construction apparatus, 2 Input part, 3 Type determination part, 4 Conversion part, 5 Recording part, 6 Recording medium, 7 Player, 8 Playlist database construction apparatus, 9 Input part, 10 Time information supply part, 11 Recording / reproduction Section, 12 type determination section, 13 conversion section, 14 collation section, 15 counting section, 16 recording section, 17 recording medium
Claims (6)
前記データストリームを入力する入力手段と、
前記データストリームの入力時刻を供給する供給手段と、
前記データストリームに前記入力時刻を対応付けて蓄積する蓄積手段と、
1次検索処理として、
入力された前記データストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、前記データストリームを所定の期間毎に分割して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
生成した前記特徴情報に基づき、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理手段と、
2次検索前処理として、
前記蓄積手段に蓄積された前記データストリームを所定の期間毎に読み出して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
前記分割データストリームに、生成された前記特徴情報と前記入力時刻を対応付けて、検索履歴データベースを構築し、
前記検索履歴データベースに記録されている分割データストリームであって、前記検索結果データベースに記録されていない分割データストリームを特定し、特定された前記分割データストリームに前記特徴情報および前記入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理手段と、
2次検索処理として、
前記2次検索待ちデータベースに登録されている前記分割データストリームの前記特徴情報に基づき、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、前記検索結果データベースに追加登録する処理を行う2次検索処理手段と
を含む情報処理装置。In an information processing apparatus for constructing a database related to a predetermined type of data included in a data stream,
Input means for inputting the data stream;
Supply means for supplying an input time of the data stream;
Storage means for storing the input time in association with the data stream;
As the primary search process,
It is determined whether or not the input data stream can be processed, and when it is determined that the data stream can be processed, the data stream is divided every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Based on the generated feature information, search for attribute information corresponding to the divided data stream,
When attribute information corresponding to the divided data stream is obtained as a search result, a primary search is performed for associating the searched attribute information and the input time with the divided data stream to construct a search result database. Processing means;
As secondary search pre-processing,
Read the data stream stored in the storage means every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Corresponding the generated feature information and the input time to the divided data stream, constructing a search history database,
A divided data stream recorded in the search history database and not recorded in the search result database is specified, and the feature information and the input time are associated with the specified divided data stream Secondary search preprocessing means for performing processing for registration in the secondary search waiting database;
As a secondary search process,
Based on the feature information of the divided data stream registered in the secondary search waiting database, search for attribute information corresponding to the divided data stream;
When attribute information corresponding to the divided data stream is obtained as a search result, a process of additionally registering the searched attribute information and the input time in the divided data stream in association with the input time is performed 2 An information processing apparatus including: next search processing means.
請求項1に記載の情報処理装置。The information processing apparatus according to claim 1, wherein the data stream includes at least one of a television broadcast signal and a radio broadcast signal.
請求項1に記載の情報処理装置。The information processing apparatus according to claim 1, wherein the predetermined type of data is music data.
データストリームの入力時刻を供給する供給手段と、
データストリームに前記入力時刻を対応付けて蓄積する蓄積手段と、
1次検索処理を行う1次検索処理手段と、
2次検索前処理を行う2次検索前処理手段と、
2次検索処理を行う2次検索処理手段とを備え、
前記データストリームに含まれる所定の種類のデータに関するデータベースを構築する情報処理装置の情報処理方法において、
前記入力手段による、前記データストリームを入力する入力ステップと、
前記供給手段による、前記データストリームの入力時刻を供給する供給ステップと、
前記蓄積手段による、前記データストリームに前記入力時刻を対応付けて蓄積する蓄積ステップと、
1次検索処理手段による、
入力された前記データストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、前記データストリームを所定の期間毎に分割して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
生成した前記特徴情報に基づき、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理ステップと、
2次検索前処理手段による、
前記蓄積手段に蓄積された前記データストリームを所定の期間毎に読み出して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
前記分割データストリームに、生成された前記特徴情報と前記入力時刻を対応付けて、検索履歴データベースを構築し、
前記検索履歴データベースに記録されている分割データストリームであって、前記検索結果データベースに記録されていない分割データストリームを特定し、特定された前記分割データストリームに前記特徴情報および前記入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理ステップと、
2次検索処理手段による、
前記2次検索待ちデータベースに登録されている前記分割データストリームの前記特徴情報に基づき、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、前記検索結果データベースに追加登録する処理を行う2次検索処理ステップと
を含む情報処理方法。An input means for inputting a data stream;
Supply means for supplying the input time of the data stream;
Storage means for storing the input time in association with the data stream;
Primary search processing means for performing primary search processing;
Secondary search preprocessing means for performing secondary search preprocessing;
Secondary search processing means for performing secondary search processing,
In the information processing method of the information processing apparatus for constructing a database related to a predetermined type of data included in the data stream,
An input step of inputting the data stream by the input means;
A supplying step of supplying an input time of the data stream by the supplying means;
A storage step of storing the input time in association with the data stream by the storage means;
By the primary search processing means,
It is determined whether or not the input data stream can be processed, and when it is determined that the data stream can be processed, the data stream is divided every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Based on the generated feature information, search for attribute information corresponding to the divided data stream,
When attribute information corresponding to the divided data stream is obtained as a search result, a primary search is performed for associating the searched attribute information and the input time with the divided data stream to construct a search result database. Processing steps;
By secondary search preprocessing means,
Read the data stream stored in the storage means every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Corresponding the generated feature information and the input time to the divided data stream, constructing a search history database,
A divided data stream recorded in the search history database and not recorded in the search result database is specified, and the feature information and the input time are associated with the specified divided data stream A secondary search preprocessing step for performing a process of registering in the secondary search waiting database;
By secondary search processing means,
Based on the feature information of the divided data stream registered in the secondary search waiting database, search for attribute information corresponding to the divided data stream;
When attribute information corresponding to the divided data stream is obtained as a search result, a process of additionally registering the searched attribute information and the input time in the divided data stream in association with the input time is performed 2 An information processing method comprising: a next search processing step.
前記データストリームを入力する入力ステップと、
前記データストリームの入力時刻を供給する供給ステップと、
前記データストリームに前記入力時刻を対応付けて蓄積する蓄積ステップと、
1次検索処理として、
入力された前記データストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、前記データストリームを所定の期間毎に分割して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
生成した前記特徴情報に基づき、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理ステップと、
2次検索前処理として、
前記蓄積手段に蓄積された前記データストリームを所定の期間毎に読み出して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
前記分割データストリームに、生成された前記特徴情報と前記入力時刻を対応付けて、検索履歴データベースを構築し、
前記検索履歴データベースに記録されている分割データストリームであって、前記検索結果データベースに記録されていない分割データストリームを特定し、特定された前記分割データストリームに前記特徴情報および前記入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理ステップと、
2次検索処理として、
前記2次検索待ちデータベースに登録されている前記分割データストリームの前記特徴情報に基づき、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、前記検索結果データベースに追加登録する処理を行う2次検索処理ステップと
を含む処理を情報処理装置のコンピュータに実行させる、コンピュータが読み取り可能なプログラムが記録されている記録媒体。A program for controlling an information processing apparatus that builds a database related to a predetermined type of data included in a data stream,
An input step of inputting the data stream;
A supplying step of supplying an input time of the data stream;
An accumulation step of associating and accumulating the input time with the data stream;
As the primary search process,
It is determined whether or not the input data stream can be processed, and when it is determined that the data stream can be processed, the data stream is divided every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Based on the generated feature information, search for attribute information corresponding to the divided data stream,
When attribute information corresponding to the divided data stream is obtained as a search result, a primary search is performed for associating the searched attribute information and the input time with the divided data stream to construct a search result database. Processing steps;
As secondary search pre-processing,
Read the data stream stored in the storage means every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Corresponding the generated feature information and the input time to the divided data stream, constructing a search history database,
A divided data stream recorded in the search history database and not recorded in the search result database is specified, and the feature information and the input time are associated with the specified divided data stream A secondary search preprocessing step for performing a process of registering in the secondary search waiting database;
As a secondary search process,
Based on the feature information of the divided data stream registered in the secondary search waiting database, search for attribute information corresponding to the divided data stream;
When attribute information corresponding to the divided data stream is obtained as a search result, a process of additionally registering the searched attribute information and the input time in the divided data stream in association with the input time is performed 2 A recording medium on which a computer-readable program is recorded , which causes a computer of an information processing apparatus to execute processing including a next search processing step.
パッケージメディアに記録されたコンテンツデータを読み出す読み出し手段と、
読み出された前記コンテンツデータの特徴情報を抽出する抽出手段と、
前記コンテンツデータの属性情報に、抽出された前記特徴情報を対応付けてコンテンツデータベースを構築する構築手段と、
データストリームを入力する入力手段と、
前記データストリームの入力時刻を供給する供給手段と、
前記データストリームに前記入力時刻を対応付けて蓄積する蓄積手段と、
1次検索処理として、
入力された前記データストリームが処理可能であるか否か判定し、処理可能であると判定した場合に、前記データストリームを所定の期間毎に分割して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
生成した前記特徴情報に基づき、前記コンテンツデータベースを参照して、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、検索結果データベースを構築する処理を行う1次検索処理手段と、
2次検索前処理として、
前記蓄積手段に蓄積された前記データストリームを所定の期間毎に読み出して分割データストリームを生成し、
前記分割データストリームの種類を判別し、
前記所定の種類のデータと判別された場合、前記分割データストリームの特徴情報を生成し、
前記分割データストリームに、生成された前記特徴情報と前記入力時刻を対応付けて、検索履歴データベースを構築し、
前記検索履歴データベースに記録されている分割データストリームであって、前記検索結果データベースに記録されていない分割データストリームを特定し、特定された前記分割データストリームに前記特徴情報および前記入力時刻を対応付けて2次検索待ちデータベースに登録する処理を行う2次検索前処理手段と、
2次検索処理として、
前記2次検索待ちデータベースに登録されている前記分割データストリームの前記特徴情報に基づき、前記コンテンツデータベースを参照して、前記分割データストリームに対応する属性情報を検索し、
検索結果として前記分割データストリームに対応する属性情報が得られた場合、前記分割データストリームに、検索した前記属性情報と前記入力時刻を対応付けて、前記検索結果データベースに追加登録する処理を行う2次検索処理手段と
を含むデータベース構築装置。In a database construction device for constructing a database related to a predetermined type of data included in a data stream,
Reading means for reading the content data recorded on the package media;
Extraction means for extracting feature information of the read content data;
Construction means for constructing a content database by associating the extracted feature information with the attribute information of the content data;
An input means for inputting a data stream;
Supply means for supplying an input time of the data stream;
Storage means for storing the input time in association with the data stream;
As the primary search process,
It is determined whether or not the input data stream can be processed, and when it is determined that the data stream can be processed, the data stream is divided every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Based on the generated feature information, referring to the content database, search for attribute information corresponding to the divided data stream,
When attribute information corresponding to the divided data stream is obtained as a search result, a primary search is performed for associating the searched attribute information and the input time with the divided data stream to construct a search result database. Processing means;
As secondary search pre-processing,
Read the data stream stored in the storage means every predetermined period to generate a divided data stream,
Determining the type of the divided data stream;
When it is determined that the data is the predetermined type, the feature information of the divided data stream is generated,
Corresponding the generated feature information and the input time to the divided data stream, constructing a search history database,
A divided data stream recorded in the search history database and not recorded in the search result database is specified, and the feature information and the input time are associated with the specified divided data stream Secondary search preprocessing means for performing processing for registration in the secondary search waiting database;
As a secondary search process,
Based on the feature information of the divided data stream registered in the secondary search waiting database, the attribute database corresponding to the divided data stream is searched with reference to the content database,
When attribute information corresponding to the divided data stream is obtained as a search result, a process of additionally registering the searched attribute information and the input time in the divided data stream in association with the input time is performed 2 A database construction device comprising: next search processing means.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2000261030A JP4257563B2 (en) | 2000-08-30 | 2000-08-30 | Information processing apparatus and method, recording medium, and database construction apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2000261030A JP4257563B2 (en) | 2000-08-30 | 2000-08-30 | Information processing apparatus and method, recording medium, and database construction apparatus |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2002073648A JP2002073648A (en) | 2002-03-12 |
| JP2002073648A5 JP2002073648A5 (en) | 2005-11-04 |
| JP4257563B2 true JP4257563B2 (en) | 2009-04-22 |
Family
ID=18748949
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2000261030A Expired - Fee Related JP4257563B2 (en) | 2000-08-30 | 2000-08-30 | Information processing apparatus and method, recording medium, and database construction apparatus |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4257563B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7822741B2 (en) * | 2004-06-21 | 2010-10-26 | Microsoft Corporation | API for programmatic retrieval and replay of database trace |
| JP2009199678A (en) * | 2008-02-22 | 2009-09-03 | Sony Corp | Information processing apparatus and method, and program |
-
2000
- 2000-08-30 JP JP2000261030A patent/JP4257563B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2002073648A (en) | 2002-03-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8490123B2 (en) | Method and device for generating a user profile on the basis of playlists | |
| KR101001178B1 (en) | Video playback device, apparatus in the same, method for indexing music videos and computer-readable storage medium having stored thereon computer-executable instructions | |
| JP4398242B2 (en) | Multi-stage identification method for recording | |
| US6748360B2 (en) | System for selling a product utilizing audio content identification | |
| US7031921B2 (en) | System for monitoring audio content available over a network | |
| US6931451B1 (en) | Systems and methods for modifying broadcast programming | |
| US6574594B2 (en) | System for monitoring broadcast audio content | |
| US20050044561A1 (en) | Methods and apparatus for identifying program segments by detecting duplicate signal patterns | |
| JP2005322401A (en) | Method, device, and program for generating media segment library, and custom stream generating method and custom media stream sending system | |
| CN101142591A (en) | Content sampling and identification | |
| EP1197020A2 (en) | Electronic music and programme storage, comprising the recognition of programme segments, such as recorded musical performances and system for the management and playback of these programme segments | |
| US20060224616A1 (en) | Information processing device and method thereof | |
| JP4992592B2 (en) | Information processing apparatus, information processing method, and program | |
| JP2005526349A (en) | Signal processing method and configuration | |
| JP4877811B2 (en) | Specific section extraction device, music recording / playback device, music distribution system | |
| JP4257563B2 (en) | Information processing apparatus and method, recording medium, and database construction apparatus | |
| US20050012563A1 (en) | Method and system for the simulataneous recording and identification of audio-visual material | |
| JP2009147775A (en) | Program reproduction method, apparatus, program, and medium | |
| JP2004334160A (en) | Characteristic amount extraction device | |
| JP2001075992A (en) | Method and system for sound retrieval and computer- readable recording medium | |
| JP2009026258A (en) | Recorder and recording method | |
| JP5424306B2 (en) | Information processing apparatus and method, program, and recording medium | |
| CN101169954A (en) | Streaming audio recording method and device | |
| JP3565261B2 (en) | Data search method, information providing system, and recording medium | |
| WO2006075303A2 (en) | Broadcasting signal containing music data |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20050810 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20050810 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080807 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080918 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20081104 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081209 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090108 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090121 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120213 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |