CN114663552B - Virtual fitting method based on 2D image - Google Patents
Virtual fitting method based on 2D image Download PDFInfo
- Publication number
- CN114663552B CN114663552B CN202210573730.5A CN202210573730A CN114663552B CN 114663552 B CN114663552 B CN 114663552B CN 202210573730 A CN202210573730 A CN 202210573730A CN 114663552 B CN114663552 B CN 114663552B
- Authority
- CN
- China
- Prior art keywords
- image
- graph
- semantic
- network
- clothing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 238000000034 method Methods 0.000 title claims abstract description 60
- 230000011218 segmentation Effects 0.000 claims abstract description 59
- 238000012937 correction Methods 0.000 claims abstract description 10
- 238000007781 pre-processing Methods 0.000 claims abstract description 10
- 230000006870 function Effects 0.000 claims description 60
- 238000005070 sampling Methods 0.000 claims description 17
- 230000000694 effects Effects 0.000 claims description 14
- 230000008569 process Effects 0.000 claims description 14
- 125000004432 carbon atom Chemical group C* 0.000 claims description 11
- 238000010606 normalization Methods 0.000 claims description 9
- 238000012545 processing Methods 0.000 claims description 9
- 230000009467 reduction Effects 0.000 claims description 9
- 230000004913 activation Effects 0.000 claims description 6
- 230000008859 change Effects 0.000 claims description 6
- 238000013528 artificial neural network Methods 0.000 claims description 5
- 238000004364 calculation method Methods 0.000 claims description 5
- 238000004040 coloring Methods 0.000 claims description 5
- 238000005457 optimization Methods 0.000 claims description 5
- PXFBZOLANLWPMH-UHFFFAOYSA-N 16-Epiaffinine Natural products C1C(C2=CC=CC=C2N2)=C2C(=O)CC2C(=CC)CN(C)C1C2CO PXFBZOLANLWPMH-UHFFFAOYSA-N 0.000 claims description 3
- 238000001914 filtration Methods 0.000 claims description 3
- 230000000873 masking effect Effects 0.000 claims description 3
- 238000011176 pooling Methods 0.000 claims description 3
- 238000012216 screening Methods 0.000 claims description 3
- 230000009466 transformation Effects 0.000 claims description 3
- 150000001875 compounds Chemical class 0.000 claims 1
- 238000012986 modification Methods 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 210000003423 ankle Anatomy 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 238000004590 computer program Methods 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 210000003127 knee Anatomy 0.000 description 2
- 238000002372 labelling Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 210000000707 wrist Anatomy 0.000 description 2
- 230000002159 abnormal effect Effects 0.000 description 1
- 230000004075 alteration Effects 0.000 description 1
- 238000013473 artificial intelligence Methods 0.000 description 1
- 230000009286 beneficial effect Effects 0.000 description 1
- 239000002131 composite material Substances 0.000 description 1
- 230000007547 defect Effects 0.000 description 1
- 230000006872 improvement Effects 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T11/00—2D [Two Dimensional] image generation
- G06T11/60—Editing figures and text; Combining figures or text
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/22—Matching criteria, e.g. proximity measures
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F18/00—Pattern recognition
- G06F18/20—Analysing
- G06F18/24—Classification techniques
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06N—COMPUTING ARRANGEMENTS BASED ON SPECIFIC COMPUTATIONAL MODELS
- G06N3/00—Computing arrangements based on biological models
- G06N3/02—Neural networks
- G06N3/04—Architecture, e.g. interconnection topology
- G06N3/045—Combinations of networks
-
- G—PHYSICS
- G06—COMPUTING; CALCULATING OR COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T2210/00—Indexing scheme for image generation or computer graphics
- G06T2210/16—Cloth
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Data Mining & Analysis (AREA)
- General Physics & Mathematics (AREA)
- Life Sciences & Earth Sciences (AREA)
- Artificial Intelligence (AREA)
- General Engineering & Computer Science (AREA)
- Evolutionary Computation (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Evolutionary Biology (AREA)
- Bioinformatics & Computational Biology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Computational Linguistics (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- Health & Medical Sciences (AREA)
- General Health & Medical Sciences (AREA)
- Molecular Biology (AREA)
- Computing Systems (AREA)
- Mathematical Physics (AREA)
- Software Systems (AREA)
- Image Processing (AREA)
- Processing Or Creating Images (AREA)
Abstract
The invention discloses a virtual fitting method based on a 2D image, and relates to the technical field of virtual fitting. The method comprises the following steps: inputting image data required by virtual fitting, and generating a fitting region semantic graph, a non-fitting region semantic graph and a clothing correction graph through preprocessing operation; generating a human body semantic segmentation graph after fitting under the constraint of introducing an integrated discriminator and a multi-level loss function through an end-to-end semantic splicing network; predicting a deformed clothing image under the constraint of introducing a frequency domain classifier and a regular constraint loss function through a clothing deformation network; splicing the image of the try-on person and the deformed garment image to obtain a rough try-on result picture; and calculating and reducing the artifact area through a normalized network, and finally obtaining a fine fitting result image. The method solves the problem that the garment and the human body are misplaced to generate artifacts in the prior art, so that the generated picture keeps more details, and a high-resolution fitting picture is generated.
Description
Technical Field
The present invention relates to the field of virtual fitting technology, and more particularly, to a virtual fitting method based on 2D images.
Background
In recent years, with the rapid development of digital technology and the continuous upgrade of artificial intelligence technology, important power and support are provided for the development of virtual fitting technology. The 'house economy' is prosperous, and daily clothes purchasing is also transferred to the line. The appearance of the virtual fitting can enable sellers to display the advantages and the disadvantages of the clothes more objectively, so that both sides of a transaction can know information more intuitively, the transaction is facilitated, unnecessary workload is reduced, the working efficiency is improved, and the user requirements are met.
At present, many research institutes at home and abroad are conducting relevant research, but the synthetic image aiming at 2D is still limited to low resolution, which is a key factor influencing the satisfaction degree of online consumers. With the increase of the resolution of the image, the artifact of the misaligned area between the deformed clothes and the human body becomes obvious in the final result, and the body part and the texture definition of the clothes in the final result are poor, so that the fitting effect is seriously influenced.
Chinese patent publication No. CN 112232914a discloses a four-stage virtual fitting method and apparatus based on 2D images, which assist in generating a fitting composite image by predicting semantic segmentation images and arm images after fitting, and solve the problem of artifact existing in the prior art that does not match, but the technique cannot realize virtual fitting on high-resolution 2D images, and has poor effect of maintaining the texture definition of high-resolution images.
Disclosure of Invention
Aiming at the defects or the improvement requirements of the prior art, the invention provides a virtual fitting method based on a 2D image, aiming at solving the problem of artifacts in a high-resolution fitting image, keeping more texture details and improving the fitting effect.
To achieve the above object, according to an aspect of the present invention, there is provided a virtual fitting method based on a 2D image, including the steps of:
(1) inputting a 2D image, a human body semantic segmentation image and a clothing image of a try-on person, dividing the human body semantic segmentation image into a try-on semantic area and a non-try-on semantic area through preprocessing operation, and performing masking and correction processing on the clothing image to generate a clothing mask image and a clothing correction image;
(2) inputting a clothing semantic graph and a non-fitting area semantic graph, and generating a human body semantic segmentation graph after fitting through an end-to-end semantic splicing network under the constraint of introducing an integrated discriminator and a multi-level loss function;
(3) predicting a deformed clothing image under the constraint of introducing a frequency domain classifier and a regular constraint loss function through a clothing deformation network according to the tried-on semantic segmentation image, the human body posture image and the clothing image;
(4) according to the image of the try-on person, coloring the semantic graph of the non-try-on area to obtain a colored graph of the non-try-on area, and splicing the colored graph with the deformed clothing image to obtain a rough try-on result graph;
(5) inputting the rough fitting result image and the semantic segmentation image after fitting into a normalized network, calculating and reducing an artifact area, and finally obtaining a fine fitting result image.
Preferably, in the method for virtual fitting based on 2D images, the preprocessing process in step (1) includes two parts: one part, inputting a human body semantic segmentation graph, comprising 7 semantic information which are sequentially: semantic information for hair, face, neck, hand, under-garment, clothing, and arm, and labeling each semantic information with a different pixel value may be expressed as: y = & a 1 ,a 2 , a 3 ,…, a 7 Dividing the human body semantic segmentation graph into a non-try-on area semantic graph according to different semantic information pixel values in the preprocessing process: y is 1 ={a 1 , a 2 , a 3 , a 4 , a 5 And fitting area semantic map: y is 2 ={a 6 ,a 7 And the semantic graph of the non-fitting area comprises: semantic information of hair, face, neck, hand, lower garment, the fitting region semantic graph includes: semantic information of clothing and arms; and inputting a clothing image, performing mask processing on the clothing image, namely setting the pixel value of a clothing region in the clothing image to be 0 and the pixel value of the background to be 255 to obtain a clothing mask image, and performing affine transformation on the clothing image according to the position information of the pixel points in the semantic graph of the try-on region to enable the outline of the clothing image to be consistent with the outline of the semantic graph of the try-on region, thereby obtaining a clothing correction graph and preparing for subsequent clothing deformation.
Preferably, the semantic splicing network in the virtual fitting method based on the 2D image is an end-to-end network, the input is a clothing semantic map and a non-fitting area semantic map, the image features are extracted through a convolution layer and downsampled, the compressed image is expanded to the original size through a deconvolution layer to obtain a rough fitting human body semantic segmentation map, and finally the rough fitting human body semantic segmentation map is input to an integrated discriminator to perform similarity calculation, and a fitting human body semantic segmentation map with the highest similarity is output after multiple rounds of semantic splicing. And a multi-level loss function is introduced in the semantic splicing process, the prediction result is subjected to fine-grained optimization, and a semantic splicing network is encouraged to generate finer details.
Preferably, the integrated discriminator is formed by splicing n deep convolutional networks with the same network structure, the size of n is related to the resolution of an input picture, and each deep convolutional network is formed by sequentially connecting a pooling layer, a convolutional layer, a normalization layer and an active layer. The input of the integrated discriminator is a real picture and a prediction picture, and the output is the feature similarity of the two pictures. The n deep convolutional networks respectively distinguish the real image from the predicted image on n different scales, and the influence of the prediction result of each deep convolutional network on the final result is controlled by setting a coefficient, so that the semantic splicing network is encouraged to generate more details. Each deep convolution network corresponds to a characteristic matching loss function, and the characteristic matching loss functions together form a multi-level loss function of the integrated discriminator.
Preferably, the multi-level loss function is represented as:

in the above formula, the first and second carbon atoms are, representing deep convolutional networksD 1 Generated for semantic splicing networksG(1) The features of the image match the loss function,
representing deep convolutional networksD 1 Generated for semantic splicing networksG(1) The features of the image match the loss function, is a coefficient that controls the effect of different scales of deep convolutional network loss on the multi-level loss function, i.e.
is a coefficient that controls the effect of different scales of deep convolutional network loss on the multi-level loss function, i.e. 。
。
Preferably, the garment deformation network in the 2D image-based virtual fitting method is an end-to-end network, the input is a tried-on semantic segmentation graph, a garment image and a human body posture graph, under the constraint of 18 key point positions in the human body posture graph, pixel information of key point positions of the tried-on semantic segmentation graph and the garment image is respectively extracted through two branches, a frequency domain classifier is introduced, pixel information of the deformed garment image is predicted by using an interpolation method, a regular constraint loss function is introduced to control the deformation degree of the garment, and finally the deformed garment image is output.
The canonical constraint loss function is expressed as:

in the above formula, the first and second carbon atoms are, representing coordinate points before and after deformation respectivelyxThe value of the one or more of the one,
representing coordinate points before and after deformation respectivelyxThe value of the one or more of the one,



the loss function of the garment deformation network is expressed as:

in the above formula, the first and second carbon atoms are, is a conditional-confrontation-loss function,
is a conditional-confrontation-loss function, is a function of the cross-entropy loss of the pixel,
is a function of the cross-entropy loss of the pixel, is a function of the loss of the regular constraint,λ 1 ,λ 2 ,λ 3 is a coefficient for adjusting the three loss functions to the total loss functionThe influence of (c).
is a function of the loss of the regular constraint,λ 1 ,λ 2 ,λ 3 is a coefficient for adjusting the three loss functions to the total loss functionThe influence of (c).
Preferably, the frequency domain classifier is to divide the features in the frequency domain space by setting a threshold, on one hand, more attention points are placed on the generated low-frequency feature information to enhance the content information of the image, on the other hand, noise points and high-frequency information are distinguished by means of the tried-on semantic segmentation map to extract more useful high-frequency information, and the texture fineness of the high-frequency region of the image is enhanced by using an interpolation method, so that the quality of the generated image is improved. The specific process of the frequency domain classifier comprises the following steps:
first, a spatial domain feature map of the clothing image is extracted from the convolutional layer, and a frequency domain feature map is obtained by using discrete fourier transform, which can be expressed as:

wherein,S i,j feature map representing spatial domainiGo to the firstjThe spatial feature component of the column is,F i,j representing the first in a frequency domain profileiGo to the firstjFrequency characteristic components of the columns, DFT () being a discrete fourier transform function;
then, learning through a neural network structure to obtain an importance weight of each frequency feature component in the frequency domain feature map, identifying the frequency feature component with the weight greater than a threshold as a low-frequency information feature component, and identifying the frequency feature component with the weight less than the threshold as a high-frequency information feature component, which can be expressed as:

wherein, is shown asiGo to the firstjA frequency feature component of which column category is z, which is indicated as a low-frequency information feature component when z =0, which is indicated as a high-frequency information feature component when z =1,k i,j is shown asiGo to the firstjThe importance weights of the column frequency feature components,λis a threshold value;
is shown asiGo to the firstjA frequency feature component of which column category is z, which is indicated as a low-frequency information feature component when z =0, which is indicated as a high-frequency information feature component when z =1,k i,j is shown asiGo to the firstjThe importance weights of the column frequency feature components,λis a threshold value;
and finally, further screening noise information in a high-frequency information characteristic channel through the position information in the tried semantic segmentation image, filtering image noise by using a low-pass filter, and filling image content and texture information by using an interpolation method.
Optionally, the spline interpolation method includes: tension spline interpolation, regular spline interpolation, and thin plate spline interpolation.
Preferably, in the virtual fitting method based on 2D images, the step (4) includes: firstly, extracting pixel point values of a try-on person image, assigning the pixel point values to a non-try-on area semantic graph of a corresponding area again, re-coloring the non-try-on area semantic graph to obtain a non-try-on area color graph, and then inputting the non-try-on area color graph and a deformed clothing image into a semantic splicing network together to obtain a rough try-on result graph. In the semantic splicing network, firstly, the color image of a non-fitting area and the characteristics of a deformed garment image are extracted through a convolution layer and down-sampled, then the compressed image is expanded into the original size through a reverse convolution layer to obtain a rough fitting human body semantic segmentation image, finally, the rough fitting result image is input into an integrated discriminator to carry out similarity calculation, and a fitting result image with the highest similarity is output after multiple rounds of semantic splicing. And a multi-level loss function is introduced in the semantic splicing process, the prediction result is subjected to fine-grained optimization, and a semantic splicing network is encouraged to generate finer details.
Preferably, the processing procedure for removing artifacts in the virtual fitting method based on 2D images includes: firstly, extracting image features of a rough fitting result graph through a deep neural network, obtaining a semantic segmentation graph of the rough fitting result graph through up-sampling, and solving a difference value with the semantic segmentation graph after fitting, wherein the difference value can be expressed as:
Artifact=R-S
wherein,Artifactpixel information representing the region of the artifact,Ra graph showing the results of a rough fitting,Srepresenting semantic segmentation after fittingA drawing;
obtaining an image with a small part of pixel values larger than 0, wherein the pixel points with the pixel values larger than 0 are the pixel points of the artifact region, and identifying the region in the rough fitting result image according to the position information of the artifact region; then, through a multilayer normalized network, two type variable coefficients are learnedαAndβrespectively controlling the reduction degree of the artifact area in the x-axis direction and the y-axis direction for reducing the size of the artifact area; and finally, sampling the adjusted feature picture into the size of the original picture through an upper sampling layer, and filling lost pixel point values by using an interpolation method to generate a more fine fitting result picture.
Optionally, the interpolation method includes: nearest neighbor interpolation, bilinear interpolation, and bicubic interpolation.
Preferably, the input of the normalization network is a coarse fitting result graph, the output is a fine fitting result graph, and the normalization network comprises two stages of acquiring an artifact semantic graph and eliminating artifact information:
the first stage of acquiring an artifact semantic graph comprises two sub-networks which are set as networks 1-1 and 1-2, wherein the network 1-1 comprises n layers of convolution layers, image features are extracted through the convolution layers, n layers of deconvolution layers map images to be in original sizes through deconvolution, the output of each convolution layer is used as the input of each deconvolution layer, the convolution layers are connected with the deconvolution layers through residual error structures, and results are output after the last layer of deconvolution; the network 1-2 comprises an image difference module, two images with the same size are input, and a result graph obtained by difference of the two images is output. The value of n is related to the size of the input picture, and generally, when the size of the input picture is 1024 × 768, n =3,4 has a good experimental effect.
The second stage of eliminating artifact information includes one network 2-1, with the network 2-1 comprising two parallel branches, the first branch comprising one convolution layer, one activation layer, one area regularization layer, one down sampling layer, one up sampling layer and one addition layer connected serially, and the second branch comprising one single area regularization layer and the final result output after the addition layer.
The region regularization layer is used for standardizing an artifact region, firstly obtaining the spatial position of the artifact region, and then calculating a type variable coefficient through a convolution networkαAndβintroducing a plane deformation loss function to control the reduction degree of the artifact region, and preventing the pixel point information of the human body part from being wrongly modified due to excessive reduction so as to assist in reducing the artifact region; and the addition layer is used for fusing output results of the two branches.
Preferably, the planar deformation loss function is expressed as:

in the above formula, the first and second carbon atoms are, respectively representing characteristic points of the artefact areax,yThe coordinates of the position of the object to be imaged,
respectively representing characteristic points of the artefact areax,yThe coordinates of the position of the object to be imaged, representing the euclidean distance between two nodes,i,jis a quantity of deformation, and the deformation quantity,α,βis the deformation coefficient.
representing the euclidean distance between two nodes,i,jis a quantity of deformation, and the deformation quantity,α,βis the deformation coefficient.
In general, compared with the prior art, the above technical solution contemplated by the present invention can achieve the following beneficial effects:
(1) the input picture is preprocessed through preprocessing, a fitting area and a non-fitting area are distinguished, pixel information of the non-fitting area can be better reserved, and more details of a fitting result image are reserved; the clothing image is corrected in space, so that subsequent better deformation of the clothing image is facilitated.
(2) The human body posture graph containing more key point information is used for assisting in generating the semantic segmentation image and the clothing deformation image, so that the semantic segmentation precision is higher, the clothing deformation robustness is improved, the regular constraint loss function and the frequency domain classifier are introduced, and the problem of clothing texture distortion caused by abnormal distortion deformation is solved.
(3) The problem that artifacts occur due to the fact that clothes are not matched with a human body under the condition of high resolution is solved by using the normalization network, the virtual fitting effect of the high-resolution 2D image is greatly improved, and the fitting effect and the user experience are improved.
Drawings
Fig. 1 is a schematic flow chart of a virtual fitting method based on a 2D image according to an embodiment of the present invention;
fig. 2 is a normalized network diagram of a virtual fitting method based on a 2D image according to an embodiment of the present invention.
Detailed Description
In order to make the objects, technical solutions and advantages of the present invention more apparent, the present invention is further described in detail below with reference to the accompanying drawings and embodiments. It should be understood that the specific embodiments described herein are merely illustrative of the invention and are not intended to limit the invention. In addition, the technical features involved in the embodiments of the present invention described below may be combined with each other as long as they do not conflict with each other.
Fig. 1 is a schematic flow chart of a virtual fitting method for a 2D image according to an embodiment; the embodiment provides a virtual fitting method of a 2D image, which comprises the following steps:
(1) inputting a 2D image, a human body semantic segmentation map and a clothing image of a try-on person, dividing the human body semantic segmentation map into a try-on semantic region and a non-try-on semantic region through preprocessing operation, and performing masking and correction processing on the clothing image to generate a clothing mask map and a clothing correction map;
wherein, the pretreatment process comprises two parts: one part, inputting a human body semantic segmentation graph, comprising 7 semantic information which are sequentially: semantic information for hair, face, neck, hand, under-garment, clothing, and arm, and labeling each semantic information with a different pixel value may be expressed as: y = & a 1 , a 2 , a 3 ,…, a 7 Dividing the human body semantic segmentation chart into non-try-on area words according to different semantic information pixel values in the preprocessing processSense graph: y is 1 ={a 1 , a 2 , a 3 , a 4 , a 5 And a semantic map of a try-on area: y is 2 ={a 6 ,a 7 And the semantic graph of the non-fitting area comprises: semantic information of hair, face, neck, hand, lower garment, the fitting region semantic graph includes: semantic information of clothing and arms; and inputting a clothing image, performing mask processing on the clothing image, namely setting the pixel value of a clothing region in the clothing image to be 0 and the pixel value of the background to be 255 to obtain a clothing mask image, and performing affine transformation on the clothing image according to the position information of the pixel points in the semantic graph of the try-on region to enable the outline of the clothing image to be consistent with the outline of the semantic graph of the try-on region, thereby obtaining a clothing correction graph and preparing for subsequent clothing deformation.
(2) Inputting a clothing semantic graph and a non-fitting area semantic graph, generating a fitted human body semantic segmentation graph through an end-to-end semantic splicing network under the constraint of introducing an integrated discriminator and a multi-level loss function, wherein the clothing semantic graph is prepared in advance and is input data of the network;
the semantic splicing network is an end-to-end network, a clothing semantic graph and a non-try-on area semantic graph are input, image features are extracted through a convolution layer and downsampled, a compressed image is expanded to be of the original size through an anti-convolution layer, a rough try-on human body semantic segmentation graph is obtained, the rough try-on human body semantic segmentation graph is input to an integrated discriminator to be subjected to similarity calculation, and a try-on human body semantic segmentation graph with the highest similarity is output after multiple rounds of semantic splicing. And a multi-level loss function is introduced in the semantic splicing process, the prediction result is subjected to fine-grained optimization, and a semantic splicing network is encouraged to generate finer details.
The integrated discriminator is formed by splicing n deep convolution networks with the same network structure, the size of n is related to the resolution of an input picture, and the experimental effect of n =3 and 4 is better when the size of the input picture is 1024 × 768. The deep convolutional network is formed by sequentially connecting a pooling layer, a convolutional layer, a normalization layer and an activation layer. The input of the integrated discriminator is a real picture and a prediction picture, and the output is the feature similarity of the two pictures. The n deep convolutional networks respectively distinguish the real image from the predicted image on n different scales, and the influence of the prediction result of each deep convolutional network on the final result is controlled by setting a coefficient, so that the semantic splicing network is encouraged to generate more details. Each deep convolution network corresponds to a characteristic matching loss function, and the characteristic matching loss functions together form a multi-level loss function of the integrated discriminator.
Wherein the multi-level loss function is represented as:

in the above formula, the first and second carbon atoms are, representing deep convolutional networksD 1 Generated for semantic splicing networksG(1) The features of the image match the loss function (which is existing),
representing deep convolutional networksD 1 Generated for semantic splicing networksG(1) The features of the image match the loss function (which is existing),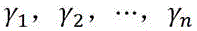 is a coefficient that controls the effect of different scales of deep convolutional network loss on the multi-level loss function, i.e.
is a coefficient that controls the effect of different scales of deep convolutional network loss on the multi-level loss function, i.e. 。
。
(3) Predicting a deformed garment image under the constraint of introducing a frequency domain classifier and a regular constraint loss function through a garment deformation network according to the tried-on semantic segmentation image, a human body posture image and the garment image, wherein the human body posture image is prepared in advance and is input data of the network;
the clothing deformation network is an end-to-end network, the input is a tried-on semantic segmentation graph, a clothing image and a human body posture graph, under the constraint of 18 key point positions in the human body posture graph, pixel information of the key point positions of the tried-on semantic segmentation graph and the clothing image is respectively extracted through two branches, a frequency domain classifier is introduced, the pixel information of the deformed clothing image is predicted by using an interpolation method, a regular constraint loss function is introduced to control the deformation degree of clothing, and finally the deformed clothing image is output, wherein the 18 key points comprise: nose, neck, right shoulder, right elbow, right wrist, left shoulder, left elbow, left wrist, right hip, right knee, right ankle, left hip, left knee, left ankle, right eye, left eye, right ear, and left ear.
The frequency domain classifier divides the features in a frequency domain space by setting a threshold, on one hand, more attention points are placed on the generated low-frequency feature information to enhance the content information of the image, on the other hand, noise points and high-frequency information are distinguished by means of a tried-on semantic segmentation graph to extract more useful high-frequency information, and the texture fineness of the high-frequency region of the image is enhanced by using an interpolation method, so that the quality of the generated image is improved. The specific process of the frequency domain classifier comprises the following steps:
first, a spatial domain feature map of the clothing image is extracted from the convolutional layer, and a frequency domain feature map is obtained by using discrete fourier transform, which can be expressed as:

wherein,S i,j feature map representing spatial domainiGo to the firstjThe spatial feature component of the column is,F i,j representing the first in a frequency domain profileiGo to the firstjFrequency characteristic components of the columns, DFT () being a discrete fourier transform function;
then, learning through a neural network structure to obtain an importance weight of each frequency feature component in the frequency domain feature map, identifying the frequency feature component with the weight greater than a threshold as a low-frequency information feature component, and identifying the frequency feature component with the weight less than the threshold as a high-frequency information feature component, which can be expressed as:

wherein, is shown asiGo to the firstjA frequency feature component of which column category is z, which is indicated as a low-frequency information feature component when z =0, which is indicated as a high-frequency information feature component when z =1,k i,j is shown asiGo to the firstjThe importance weights of the column frequency feature components,λis a threshold value;
is shown asiGo to the firstjA frequency feature component of which column category is z, which is indicated as a low-frequency information feature component when z =0, which is indicated as a high-frequency information feature component when z =1,k i,j is shown asiGo to the firstjThe importance weights of the column frequency feature components,λis a threshold value;
and finally, further screening noise information in a high-frequency information characteristic channel through the position information in the tried-on semantic segmentation image, filtering image noise by using a low-pass filter, and filling image content and texture information by using an interpolation method.
The spline interpolation method comprises the following steps: tension spline interpolation, regular spline interpolation, and thin plate spline interpolation.
Wherein the regular constraint loss function is represented as:

in the above formula, the first and second carbon atoms are, representing coordinate points before and after deformation respectivelyxThe value of the one or more of the one,
representing coordinate points before and after deformation respectivelyxThe value of the one or more of the one, representing coordinate points before and after deformation respectivelyyThe value of the one or more of the one,
representing coordinate points before and after deformation respectivelyyThe value of the one or more of the one, to representxThe square of the amount of change in the coordinate in the axial direction,
to representxThe square of the amount of change in the coordinate in the axial direction, to representyThe amount of change in the coordinates in the direction,α,βis two learnable parameters for controlling the clothesxShaft andydegree of deformation in the axial direction;
to representyThe amount of change in the coordinates in the direction,α,βis two learnable parameters for controlling the clothesxShaft andydegree of deformation in the axial direction;
wherein the loss function of the garment deformation network is represented as:

in the above formula, the first and second carbon atoms are, is a conditional opposition loss function (which is existing),
is a conditional opposition loss function (which is existing), is the pixel cross entropy loss function (which is existing),
is the pixel cross entropy loss function (which is existing), is a function of the loss of the regular constraint,λ 1 ,λ 2 ,λ 3 are coefficients that are used to adjust the effect of the three loss functions on the overall loss function.
is a function of the loss of the regular constraint,λ 1 ,λ 2 ,λ 3 are coefficients that are used to adjust the effect of the three loss functions on the overall loss function.
(4) And according to the image of the try-on person, coloring the semantic graph of the non-try-on area to obtain a colored graph of the non-try-on area, and splicing the colored graph with the deformed clothing image to obtain a rough try-on result graph.
Firstly, extracting pixel point values of a try-on person image, assigning the pixel point values to a non-try-on area semantic graph of a corresponding area again, re-coloring the non-try-on area semantic graph to obtain a non-try-on area color graph, and then inputting the non-try-on area color graph and a deformed clothing image into a semantic splicing network together to obtain a rough try-on result graph. In the semantic splicing network, firstly, the color image of a non-fitting area and the characteristics of a deformed garment image are extracted through a convolution layer and down-sampled, then the compressed image is expanded into the original size through a reverse convolution layer to obtain a rough fitting human body semantic segmentation image, finally, the rough fitting result image is input into an integrated discriminator to carry out similarity calculation, and a fitting result image with the highest similarity is output after multiple rounds of semantic splicing. And a multi-level loss function is introduced in the semantic splicing process, the prediction result is subjected to fine-grained optimization, and a semantic splicing network is encouraged to generate finer details.
(5) Inputting the rough fitting result image and the semantic segmentation image after fitting into a normalized network, calculating and reducing an artifact area, and finally obtaining a fine fitting result image.
The processing procedure for removing the artifact comprises the following steps: firstly, extracting image features of a rough fitting result graph through a deep neural network, obtaining a semantic segmentation graph of the rough fitting result graph through up-sampling, and solving a difference value with the semantic segmentation graph after fitting, wherein the process can be expressed as:
Artifact=R-S
wherein,Artifactpixel information representing the region of the artifact,Ra graph showing the results of a rough fitting,Srepresenting a semantic segmentation graph after fitting;
obtaining an image with a small part of pixel values larger than 0, wherein the pixel points with the pixel values larger than 0 are the pixel points of the artifact region, and identifying the region in the rough fitting result image according to the position information of the artifact region; then, through a normalized network, two type variable coefficients are learnedαAndβrespectively controlling the reduction degree of the artifact region in the x-axis direction and the y-axis direction for reducing the size of the artifact region; and finally, sampling the adjusted feature picture into the size of the original picture through an upper sampling layer, and filling lost pixel point values by using an interpolation method to generate a more fine fitting result picture.
Wherein the interpolation method comprises: nearest neighbor interpolation, bilinear interpolation, and bicubic interpolation.
The normalization network inputs a rough fitting result graph and outputs a fine fitting result graph, and comprises two stages of acquiring an artifact semantic graph and eliminating artifact information:
the first stage of acquiring an artifact semantic graph comprises two sub-networks which are set as networks 1-1 and 1-2, wherein the network 1-1 comprises n layers of convolution layers, image features are extracted through the convolution layers, n layers of deconvolution layers map images to be in original sizes through deconvolution, the output of each convolution layer is used as the input of each deconvolution layer, the convolution layers are connected with the deconvolution layers through residual error structures, and results are output after the last layer of deconvolution; the network 1-2 comprises an image difference module, two images with the same size are input, and a result graph obtained by difference of the two images is output. The value of n is related to the size of the input picture, and generally, when the size of the input picture is 1024 × 768, n =3,4 has a good experimental effect.
The second stage of eliminating artifact information includes one network 2-1, with the network 2-1 comprising two parallel branches, the first branch comprising one convolution layer, one activation layer, one area regularization layer, one down sampling layer, one up sampling layer and one addition layer connected serially, and the second branch comprising one single area regularization layer and the final result output after the addition layer.
The region regularization layer is used for standardizing an artifact region, firstly obtaining the spatial position of the artifact region, and then calculating a type variable coefficient through a convolution networkαAndβintroducing a plane deformation loss function to control the reduction degree of the artifact region, and preventing the pixel point information of the human body part from being wrongly modified due to excessive reduction so as to assist in reducing the artifact region; and the addition layer is used for fusing output results of the two branches.
Wherein the planar deformation loss function is expressed as:

in the above formula, the first and second carbon atoms are, respectively representing characteristic points of the artefact areax,yThe coordinates of the position of the object to be imaged,
respectively representing characteristic points of the artefact areax,yThe coordinates of the position of the object to be imaged, representing the euclidean distance between two nodes,i,jis the amount of the deformation,α,βis the deformation coefficient.
representing the euclidean distance between two nodes,i,jis the amount of the deformation,α,βis the deformation coefficient.
Fig. 2 is a normalized network diagram of a virtual fitting method of a 2D image according to an embodiment;
the normalized network is a trial result graph with coarse input and fine output after removing the false shadow. The normalized network consists of two stages: the first stage is used for acquiring an artifact semantic map and comprises 3 convolutional layers, 3 deconvolution layers and a difference calculating module; the second stage is used for eliminating artifact information and comprises two branches, wherein one branch comprises a convolution layer, an activation layer, a region regularization layer, a down-sampling layer and an up-sampling layer, the other branch only comprises the region regularization layer, and finally, the results of the two branches are fused through an addition layer.
The method not only enables the semantic segmentation precision to be higher, but also increases the robustness of clothing deformation, enables the fitting result image to retain more details, greatly improves the virtual fitting effect of the high-resolution 2D image, and improves the fitting effect and the user experience.
As will be appreciated by one skilled in the art, embodiments of the present application may be provided as a method, system, or computer program product. Accordingly, the present application may take the form of an entirely hardware embodiment, an entirely software embodiment or an embodiment combining software and hardware aspects. Furthermore, the present application may take the form of a computer program product embodied on one or more computer-usable storage media (including, but not limited to, disk storage, CD-ROM, optical storage, and the like) having computer-usable program code embodied therein. The scheme in the embodiment of the application can be implemented by adopting various computer languages, such as object-oriented programming language Java and transliterated scripting language JavaScript.
While the preferred embodiments of the present application have been described, additional variations and modifications in those embodiments may occur to those skilled in the art once they learn of the basic inventive concepts. Therefore, it is intended that the appended claims be interpreted as including preferred embodiments and all alterations and modifications as fall within the scope of the application.
It will be apparent to those skilled in the art that various changes and modifications may be made in the present application without departing from the spirit and scope of the application. Thus, if such modifications and variations of the present application fall within the scope of the claims of the present application and their equivalents, the present application is intended to include such modifications and variations as well.
Claims (5)
1. A virtual fitting method based on 2D images is characterized by comprising the following steps:
inputting a 2D image, a human body semantic segmentation image and a clothing image of a try-on person, dividing the human body semantic segmentation image into a try-on area and a non-try-on area through preprocessing operation, and performing masking and correction processing on the clothing image to generate a clothing mask image and a clothing correction image;
step (2), inputting a clothing semantic graph and a non-fitting area semantic graph, and generating a human body semantic segmentation graph after fitting under the constraint of introducing an integrated discriminator and a multi-level loss function through an end-to-end semantic splicing network;
step (3), predicting a deformed garment image under the constraint of introducing a frequency domain classifier and a regular constraint loss function through a garment deformation network according to the tried-on semantic segmentation graph, the human body posture graph and the garment image;
the clothing deformation network in the step (3) is an end-to-end network, the semantic segmentation graph, the clothing image and the human body posture graph after fitting are input, under the constraint of a plurality of key point positions in the human body posture graph, pixel information of the key point positions of the semantic segmentation graph and the clothing image after fitting is respectively extracted through two branches by a deep convolution network, a frequency domain classifier is introduced, the pixel information of the clothing image after deformation is predicted by using an interpolation method, a regular constraint loss function is introduced to control the deformation degree of the clothing, and finally the clothing image after deformation is output;
the canonical constraint loss function is expressed as:

in the above formula, the first and second carbon atoms are, representing coordinate points before and after deformation respectivelyxThe value of the one or more of the one,
representing coordinate points before and after deformation respectivelyxThe value of the one or more of the one,



the loss function of the garment deformation network is expressed as:

in the above formula, the first and second carbon atoms are, is a conditional-confrontation-loss function,
is a conditional-confrontation-loss function, is a function of the cross-entropy loss of the pixel,
is a function of the cross-entropy loss of the pixel, is a function of the loss of the regular constraint,λ 1 ,λ 2 ,λ 3 is a coefficient for adjusting the influence of the three loss functions on the total loss function;
is a function of the loss of the regular constraint,λ 1 ,λ 2 ,λ 3 is a coefficient for adjusting the influence of the three loss functions on the total loss function;
in the step (3), the intermediate frequency domain classifier divides the features in a frequency domain space by setting a threshold, on one hand, more attention points are placed on the generated low frequency feature information to enhance the content information of the image, on the other hand, noise points and high frequency information are distinguished by means of the tried-on semantic segmentation graph to extract more useful high frequency information, and the texture fineness of the high frequency region of the image is enhanced by using an interpolation method, so that the quality of the generated image is improved; the specific process of the frequency domain classifier comprises the following steps:
first, a spatial domain feature map of the clothing image is extracted from the convolutional layer, and a frequency domain feature map is obtained by using discrete fourier transform, which can be expressed as:

wherein,S i,j representing features in the spatial domainiGo to the firstjThe spatial feature component of the column is,F i,j representing the first in a frequency domain profileiGo to the firstjFrequency characteristic components of the columns, DFT () being a discrete fourier transform function;
then, learning through a neural network structure to obtain an importance weight of each frequency feature component in the frequency domain feature map, identifying the frequency feature component with the weight greater than a threshold as a low-frequency information feature component, and identifying the frequency feature component with the weight less than the threshold as a high-frequency information feature component, which can be expressed as:

wherein, is shown asiGo to the firstjA frequency feature component of which column category is z, which is indicated as a low-frequency information feature component when z =0, which is indicated as a high-frequency information feature component when z =1,k i,j is shown asiGo to the firstjThe importance weights of the column frequency feature components,λis a threshold value;
is shown asiGo to the firstjA frequency feature component of which column category is z, which is indicated as a low-frequency information feature component when z =0, which is indicated as a high-frequency information feature component when z =1,k i,j is shown asiGo to the firstjThe importance weights of the column frequency feature components,λis a threshold value;
finally, further screening noise information in a high-frequency information characteristic channel through position information in the tried semantic segmentation image, filtering image noise by using a low-pass filter, and filling image content and texture information by using an interpolation method;
step (4), according to the image of the try-on person, coloring the semantic graph of the non-try-on area to obtain a colored graph of the non-try-on area, and then splicing the colored graph with the deformed clothing image to obtain a rough try-on result graph;
and (5) inputting the rough fitting result image and the fitted semantic segmentation image into a normalized network, calculating and reducing an artifact area, and finally obtaining a fine fitting result image.
2. The virtual fitting method based on 2D images as claimed in claim 1, wherein: after the 2D image, the human body semantic segmentation map and the clothing image of the try-on person are input in the step (1), the preprocessing process comprises two parts:
one part, inputting a human body semantic segmentation graph, comprising 7 semantic information which are sequentially: semantic information of hair, face, neck, hand, under garment, clothing, and arm, and each semantic information is labeled with a different pixel value, which can be expressed as: y = & a 1 ,a 2 , a 3 ,…, a 7 Dividing the human body semantic segmentation graph into a non-try-on area semantic graph according to different semantic information pixel values in the preprocessing process: y is 1 ={a 1 , a 2 , a 3 , a 4 , a 5 And a semantic map of a try-on area: y is 2 ={a 6 ,a 7 And the semantic graph of the non-fitting area comprises: semantic information of hair, face, neck, hand, lower garment, the fitting region semantic graph includes: semantic information of clothing and arms;
and inputting a clothing image, performing mask processing on the clothing image, namely setting the pixel value of a clothing region in the clothing image to be 0 and the pixel value of the background to be 255 to obtain a clothing mask image, and performing affine transformation on the clothing image according to the position information of the pixel points in the semantic graph of the try-on region to enable the outline of the clothing image to be consistent with the outline of the semantic graph of the try-on region, thereby obtaining a clothing correction graph and preparing for subsequent clothing deformation.
3. The virtual fitting method based on 2D images as claimed in claim 1, wherein: the semantic splicing network in the step (2) is an end-to-end network, a clothing semantic graph and a non-try-on area semantic graph are input, image features are extracted through a convolution layer and are down-sampled, a compressed image is up-sampled into an original size through a reverse convolution layer, a rough try-on human body semantic segmentation graph is obtained, the rough try-on human body semantic segmentation graph is input to an integrated discriminator to be subjected to similarity calculation, and a try-on human body semantic segmentation graph with the highest similarity is output after multiple rounds of semantic splicing; the integrated discriminator is formed by splicing n depth convolution networks with the same network structure, the size of n is related to the resolution of an input picture, and the depth convolution network is formed by sequentially connecting a pooling layer, a convolution layer, a normalization layer and an activation layer; the input of the integrated discriminator is a real picture and a predicted picture, the output of the integrated discriminator is the feature similarity of the two pictures, the n depth convolution networks respectively distinguish the real picture and the predicted picture on n different scales, and the influence of the prediction result of each depth convolution network on the final result is controlled by setting a coefficient, so that the semantic splicing network is encouraged to generate more details; each deep convolutional network corresponds to a characteristic matching loss function and forms a multi-level loss function of the integrated discriminator together, fine-grained optimization is carried out on the prediction result, and the semantic splicing network is encouraged to generate finer details;
the multi-level loss function is expressed as:

in the above formula, the first and second carbon atoms are, representing deep convolutional networksD 1 Generated for semantic splicing networksG(1) The features of the image match the loss function,
representing deep convolutional networksD 1 Generated for semantic splicing networksG(1) The features of the image match the loss function, is a coefficient that controls the effect of different scales of deep convolutional network loss on the multi-level loss function, i.e.
is a coefficient that controls the effect of different scales of deep convolutional network loss on the multi-level loss function, i.e. 。
。
4. The virtual fitting method based on 2D images as claimed in claim 1, wherein: the processing procedure for removing the artifacts in the step (5) comprises the following steps: firstly, extracting image features of a rough fitting result graph through a deep convolutional network, obtaining a semantic segmentation graph of the rough fitting result graph through up-sampling, and solving a difference value with the semantic segmentation graph after fitting, wherein the process can be expressed as:
Artifact=R-S
wherein,Artifactpixel information representing the region of the artifact,Ra graph showing the results of a rough fitting,Srepresenting the semantic segmentation graph after the try-on;
obtaining an image with only a small part of pixel values larger than 0, wherein the pixel points with the pixel values larger than 0 are the pixel points of the artifact region, and identifying the region in the rough fitting result image according to the position information of the artifact region; then, through a normalized network, two type variable coefficients are learnedαAndβrespectively controlling the reduction degree of the artifact area in the x-axis direction and the y-axis direction for reducing the size of the artifact area; and finally, sampling the adjusted feature picture into the size of the original picture through an upper sampling layer, and filling lost pixel point values by using an interpolation method to generate a more fine fitting result picture.
5. The virtual fitting method based on 2D images as claimed in claim 1, wherein: in the step (5), the input of the normalization network is a rough fitting result graph, the output is a fine fitting result graph, and the normalization network comprises two stages of acquiring an artifact semantic graph and eliminating artifact information:
the first stage of acquiring an artifact semantic graph comprises two sub-networks which are set as networks 1-1 and 1-2, wherein the network 1-1 comprises n layers of convolution layers, image features are extracted through the convolution layers, n layers of deconvolution layers map images to be in original sizes through deconvolution, the output of each convolution layer is used as the input of each deconvolution layer, the convolution layers are connected with the deconvolution layers through residual error structures, and results are output after the last layer of deconvolution; the network 1-2 comprises an image difference calculating module, two images with the same size are input, and a result graph obtained by calculating the difference of the two images is output; wherein the value of n is related to the size of the input picture;
the second stage of eliminating artifact information comprises a network 2-1, wherein the network 2-1 is composed of two parallel branches, wherein the first branch is formed by sequentially connecting a convolution layer, an activation layer, a region regularization layer, a down sampling layer, an up sampling layer and an addition layer in series, the second branch is formed by a single region regularization layer, and the final result is output after the addition layer;
the region regularization layer is used for standardizing the artifact region, firstly obtaining the spatial position of the artifact region, and then calculating a type variable coefficient through a convolution networkαAndβintroducing a plane deformation loss function to control the reduction degree of the artifact region, and preventing the pixel point information of the human body part from being wrongly modified due to excessive reduction so as to assist in reducing the artifact region; the addition layer is used for fusing output results of the two branches;
wherein the planar deformation loss function is expressed as:

in the above-mentioned formula, the compound has the following structure, respectively representing characteristic points of the artefact areax,yThe coordinates of the position of the object to be imaged,
respectively representing characteristic points of the artefact areax,yThe coordinates of the position of the object to be imaged, representing the euclidean distance between two nodes,i,jis the amount of the deformation,α,βis the deformation coefficient.
representing the euclidean distance between two nodes,i,jis the amount of the deformation,α,βis the deformation coefficient.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210573730.5A CN114663552B (en) | 2022-05-25 | 2022-05-25 | Virtual fitting method based on 2D image |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| CN202210573730.5A CN114663552B (en) | 2022-05-25 | 2022-05-25 | Virtual fitting method based on 2D image |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| CN114663552A CN114663552A (en) | 2022-06-24 |
| CN114663552B true CN114663552B (en) | 2022-08-16 |
Family
ID=82038409
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| CN202210573730.5A Active CN114663552B (en) | 2022-05-25 | 2022-05-25 | Virtual fitting method based on 2D image |
Country Status (1)
| Country | Link |
|---|---|
| CN (1) | CN114663552B (en) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN115937964B (en) * | 2022-06-27 | 2023-12-15 | 北京字跳网络技术有限公司 | Method, device, equipment and storage medium for estimating gesture |
| CN115496990B (en) * | 2022-11-18 | 2023-03-24 | 武汉纺织大学 | Deep learning-based garment image analysis method |
| CN115761143B (en) * | 2022-12-07 | 2023-09-19 | 武汉纺织大学 | 3D virtual reloading model generation method and device based on 2D image |
Citations (28)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103578004A (en) * | 2013-11-15 | 2014-02-12 | 西安工程大学 | Method for displaying virtual fitting effect |
| CN103597519A (en) * | 2011-02-17 | 2014-02-19 | 麦特尔有限公司 | Computer implemented methods and systems for generating virtual body models for garment fit visualization |
| KR20140125507A (en) * | 2013-04-19 | 2014-10-29 | 정상학 | Virtual fitting apparatus and method using digital surrogate |
| CN104156966A (en) * | 2014-08-11 | 2014-11-19 | 石家庄铁道大学 | Pseudo 3D real-time virtual fitting method based on mobile terminal |
| CN104813340A (en) * | 2012-09-05 | 2015-07-29 | 体通有限公司 | System and method for deriving accurate body size measures from a sequence of 2d images |
| GB201510752D0 (en) * | 2015-06-18 | 2015-08-05 | Morris Gary | Personalized garment image processing |
| CN105354876A (en) * | 2015-10-20 | 2016-02-24 | 何家颖 | Mobile terminal based real-time 3D fitting method |
| JP2016038812A (en) * | 2014-08-08 | 2016-03-22 | 株式会社東芝 | Virtual try-on apparatus, virtual try-on method and a program |
| WO2016109884A1 (en) * | 2015-01-05 | 2016-07-14 | Valorbec Limited Partnership | Automated recommendation and virtualization systems and methods for e-commerce |
| EP3091510A1 (en) * | 2015-05-06 | 2016-11-09 | Reactive Reality GmbH | Method and system for producing output images and method for generating image-related databases |
| CN109740529A (en) * | 2018-12-29 | 2019-05-10 | 广州二元科技有限公司 | A kind of virtual fit method drawn based on neural network |
| WO2019193467A1 (en) * | 2018-04-05 | 2019-10-10 | Page International Fz Llc | Method and device for the virtual try-on of garments based on augmented reality with multi-detection |
| CN110852941A (en) * | 2019-11-05 | 2020-02-28 | 中山大学 | Two-dimensional virtual fitting method based on neural network |
| JP2020097803A (en) * | 2018-12-18 | 2020-06-25 | 成衛 貝田 | Virtual fitting system |
| WO2020131518A1 (en) * | 2018-12-19 | 2020-06-25 | Seddi, Inc. | Learning-based animation of clothing for virtual try-on |
| CN111709874A (en) * | 2020-06-16 | 2020-09-25 | 北京百度网讯科技有限公司 | Image adjusting method and device, electronic equipment and storage medium |
| CN111768472A (en) * | 2020-05-29 | 2020-10-13 | 北京沃东天骏信息技术有限公司 | Virtual fitting method and device and computer-readable storage medium |
| CN111787242A (en) * | 2019-07-17 | 2020-10-16 | 北京京东尚科信息技术有限公司 | Method and apparatus for virtual fitting |
| CN112232914A (en) * | 2020-10-19 | 2021-01-15 | 武汉纺织大学 | Four-stage virtual fitting method and device based on 2D image |
| CN112233222A (en) * | 2020-09-29 | 2021-01-15 | 深圳市易尚展示股份有限公司 | Human body parametric three-dimensional model deformation method based on neural network joint point estimation |
| CN112330580A (en) * | 2020-10-30 | 2021-02-05 | 北京百度网讯科技有限公司 | Method, device, computing equipment and medium for generating human body clothes fusion image |
| CN112613439A (en) * | 2020-12-28 | 2021-04-06 | 湖南大学 | Novel virtual fitting network |
| CN113012303A (en) * | 2021-03-10 | 2021-06-22 | 浙江大学 | Multi-variable-scale virtual fitting method capable of keeping clothes texture characteristics |
| CN113052980A (en) * | 2021-04-27 | 2021-06-29 | 云南大学 | Virtual fitting method and system |
| KR20210099353A (en) * | 2020-02-04 | 2021-08-12 | 엔에이치엔 주식회사 | Clothing virtual try-on service method on deep-learning and apparatus thereof |
| CN113781164A (en) * | 2021-08-31 | 2021-12-10 | 深圳市富高康电子有限公司 | Virtual fitting model training method, virtual fitting method and related device |
| WO2022002961A1 (en) * | 2020-06-29 | 2022-01-06 | L'oréal | Systems and methods for improved facial attribute classification and use thereof |
| CN114419335A (en) * | 2022-01-06 | 2022-04-29 | 百果园技术(新加坡)有限公司 | Training and texture migration method of texture recognition model and related device |
Family Cites Families (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010019925A1 (en) * | 2008-08-15 | 2010-02-18 | Brown Technology Partnerships | Method and apparatus for estimating body shape |
| DE102015213832B4 (en) * | 2015-07-22 | 2023-07-13 | Adidas Ag | Method and device for generating an artificial image |
| US9996763B2 (en) * | 2015-09-18 | 2018-06-12 | Xiaofeng Han | Systems and methods for evaluating suitability of an article for an individual |
| US10939742B2 (en) * | 2017-07-13 | 2021-03-09 | Shiseido Company, Limited | Systems and methods for virtual facial makeup removal and simulation, fast facial detection and landmark tracking, reduction in input video lag and shaking, and a method for recommending makeup |
| US11321769B2 (en) * | 2018-11-14 | 2022-05-03 | Beijing Jingdong Shangke Information Technology Co., Ltd. | System and method for automatically generating three-dimensional virtual garment model using product description |
| RU2019125602A (en) * | 2019-08-13 | 2021-02-15 | Общество С Ограниченной Ответственностью "Тексел" | COMPLEX SYSTEM AND METHOD FOR REMOTE SELECTION OF CLOTHES |
| US11080817B2 (en) * | 2019-11-04 | 2021-08-03 | Adobe Inc. | Cloth warping using multi-scale patch adversarial loss |
-
2022
- 2022-05-25 CN CN202210573730.5A patent/CN114663552B/en active Active
Patent Citations (29)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN103597519A (en) * | 2011-02-17 | 2014-02-19 | 麦特尔有限公司 | Computer implemented methods and systems for generating virtual body models for garment fit visualization |
| CN104813340A (en) * | 2012-09-05 | 2015-07-29 | 体通有限公司 | System and method for deriving accurate body size measures from a sequence of 2d images |
| KR20140125507A (en) * | 2013-04-19 | 2014-10-29 | 정상학 | Virtual fitting apparatus and method using digital surrogate |
| CN103578004A (en) * | 2013-11-15 | 2014-02-12 | 西安工程大学 | Method for displaying virtual fitting effect |
| JP2016038812A (en) * | 2014-08-08 | 2016-03-22 | 株式会社東芝 | Virtual try-on apparatus, virtual try-on method and a program |
| CN104156966A (en) * | 2014-08-11 | 2014-11-19 | 石家庄铁道大学 | Pseudo 3D real-time virtual fitting method based on mobile terminal |
| WO2016109884A1 (en) * | 2015-01-05 | 2016-07-14 | Valorbec Limited Partnership | Automated recommendation and virtualization systems and methods for e-commerce |
| EP3091510A1 (en) * | 2015-05-06 | 2016-11-09 | Reactive Reality GmbH | Method and system for producing output images and method for generating image-related databases |
| GB201510752D0 (en) * | 2015-06-18 | 2015-08-05 | Morris Gary | Personalized garment image processing |
| CN105354876A (en) * | 2015-10-20 | 2016-02-24 | 何家颖 | Mobile terminal based real-time 3D fitting method |
| WO2019193467A1 (en) * | 2018-04-05 | 2019-10-10 | Page International Fz Llc | Method and device for the virtual try-on of garments based on augmented reality with multi-detection |
| JP2020097803A (en) * | 2018-12-18 | 2020-06-25 | 成衛 貝田 | Virtual fitting system |
| WO2020131518A1 (en) * | 2018-12-19 | 2020-06-25 | Seddi, Inc. | Learning-based animation of clothing for virtual try-on |
| CN109740529A (en) * | 2018-12-29 | 2019-05-10 | 广州二元科技有限公司 | A kind of virtual fit method drawn based on neural network |
| CN111787242A (en) * | 2019-07-17 | 2020-10-16 | 北京京东尚科信息技术有限公司 | Method and apparatus for virtual fitting |
| WO2021008166A1 (en) * | 2019-07-17 | 2021-01-21 | 北京京东尚科信息技术有限公司 | Method and apparatus for virtual fitting |
| CN110852941A (en) * | 2019-11-05 | 2020-02-28 | 中山大学 | Two-dimensional virtual fitting method based on neural network |
| KR20210099353A (en) * | 2020-02-04 | 2021-08-12 | 엔에이치엔 주식회사 | Clothing virtual try-on service method on deep-learning and apparatus thereof |
| CN111768472A (en) * | 2020-05-29 | 2020-10-13 | 北京沃东天骏信息技术有限公司 | Virtual fitting method and device and computer-readable storage medium |
| CN111709874A (en) * | 2020-06-16 | 2020-09-25 | 北京百度网讯科技有限公司 | Image adjusting method and device, electronic equipment and storage medium |
| WO2022002961A1 (en) * | 2020-06-29 | 2022-01-06 | L'oréal | Systems and methods for improved facial attribute classification and use thereof |
| CN112233222A (en) * | 2020-09-29 | 2021-01-15 | 深圳市易尚展示股份有限公司 | Human body parametric three-dimensional model deformation method based on neural network joint point estimation |
| CN112232914A (en) * | 2020-10-19 | 2021-01-15 | 武汉纺织大学 | Four-stage virtual fitting method and device based on 2D image |
| CN112330580A (en) * | 2020-10-30 | 2021-02-05 | 北京百度网讯科技有限公司 | Method, device, computing equipment and medium for generating human body clothes fusion image |
| CN112613439A (en) * | 2020-12-28 | 2021-04-06 | 湖南大学 | Novel virtual fitting network |
| CN113012303A (en) * | 2021-03-10 | 2021-06-22 | 浙江大学 | Multi-variable-scale virtual fitting method capable of keeping clothes texture characteristics |
| CN113052980A (en) * | 2021-04-27 | 2021-06-29 | 云南大学 | Virtual fitting method and system |
| CN113781164A (en) * | 2021-08-31 | 2021-12-10 | 深圳市富高康电子有限公司 | Virtual fitting model training method, virtual fitting method and related device |
| CN114419335A (en) * | 2022-01-06 | 2022-04-29 | 百果园技术(新加坡)有限公司 | Training and texture migration method of texture recognition model and related device |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114663552A (en) | 2022-06-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114663552B (en) | Virtual fitting method based on 2D image | |
| Li et al. | Low-light image enhancement via progressive-recursive network | |
| CN112634137B (en) | Hyperspectral and panchromatic image fusion method for extracting multiscale spatial spectrum features based on AE | |
| CN110097609B (en) | Sample domain-based refined embroidery texture migration method | |
| CN112614077B (en) | Unsupervised low-illumination image enhancement method based on generation countermeasure network | |
| CN108830818B (en) | Rapid multi-focus image fusion method | |
| CN108932536A (en) | Human face posture method for reconstructing based on deep neural network | |
| CN110853119B (en) | Reference picture-based makeup transfer method with robustness | |
| CN113129236B (en) | Single low-light image enhancement method and system based on Retinex and convolutional neural network | |
| CN112232914A (en) | Four-stage virtual fitting method and device based on 2D image | |
| CN113222875B (en) | Image harmonious synthesis method based on color constancy | |
| CN113160033A (en) | Garment style migration system and method | |
| WO2023066173A1 (en) | Image processing method and apparatus, and storage medium and electronic device | |
| CN114782298B (en) | Infrared and visible light image fusion method with regional attention | |
| CN116402691B (en) | Image super-resolution method and system based on rapid image feature stitching | |
| CN110232730A (en) | A kind of three-dimensional face model textures fusion method and computer-processing equipment | |
| Kim et al. | Detail restoration and tone mapping networks for x-ray security inspection | |
| Li et al. | RDMA: low-light image enhancement based on retinex decomposition and multi-scale adjustment | |
| CN113920014A (en) | Neural-networking-based combined trilateral filter depth map super-resolution reconstruction method | |
| CN113516604A (en) | Image restoration method | |
| Zeng | Low-light image enhancement algorithm based on lime with pre-processing and post-processing | |
| CN116362972B (en) | Image processing method, device, electronic equipment and storage medium | |
| Wu et al. | SyFormer: Structure-Guided Synergism Transformer for Large-Portion Image Inpainting | |
| CN117593178A (en) | Virtual fitting method based on feature guidance | |
| Yao et al. | A multi-expose fusion image dehazing based on scene depth information |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PB01 | Publication | ||
| PB01 | Publication | ||
| SE01 | Entry into force of request for substantive examination | ||
| SE01 | Entry into force of request for substantive examination | ||
| GR01 | Patent grant | ||
| GR01 | Patent grant |