- Surveys & Programs
- Data & Tools
- Fast Facts
- News & Events
- Publications & Products
- About Us

|
Statistical Standards Program
Table of Contents Introduction 1. Development of Concepts and Methods 2. Planning and Design of Surveys 3. Collection of Data 4. Processing and Editing of Data 5. Analysis of Data / Production of Estimates or Projections 6. Establishment of Review Procedures 7. Dissemination of Data Glossary Appendix A Appendix B ·Measuring Bias ·Problems with Ignoring Item Nonresponse ·Imputing Item Nonresponse ·Data Analysis with Imputed Data ·Comparisons of Methods ·References Appendix C Appendix D Publication information For help viewing PDF files, please click here |
APPENDIX B: EVALUATING THE IMPACT OF IMPUTATIONS FOR ITEM NONRESPONSE |
|
By Marilyn Seastrom, Steve Kaufman, Ralph Lee An incomplete data record for a survey respondent results in item nonresponse that cannot be ignored. Survey nonresponse can result in an increase in the mean square errors of survey estimates and a distortion of the univariate and multivariate distributions of survey variables, and thus may result in biased estimates of means, variances, and covariances (FCSM, 2001). Measuring Bias The degree of nonresponse error or bias is a function of two factors: the nonresponse rate and how much the respondents and nonrespondents differ on survey variables of interest. For example, in the case of item nonresponse on family income, a comparison of the characteristics of the respondents and nonrespondents on other items that were completed by the item nonrespondent can be used to assess whether there are any systematic differences. In the case of our example, parent's education, parent's occupation, and race-ethnicity (or a longer list) might be good candidates to examine for an indication of the amount of bias associated with the missing income data. The mathematical formulation to estimate bias for a sample mean is:

nt = the number of cases in the sample (i.e., nt = nr + nm), using the base weight nm = the number of nonrespondent cases, using the base weight nr = the number of respondent cases, using the base weight
The relative bias provides a measure of the magnitude of the bias:
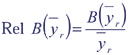
Rel B( The bias ratio provides an indication of how confidence intervals are affected by bias:
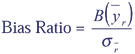
Next, since the estimate total for variable y is the sum of the estimates for the respondents and the nonrespondents:
which is also equal to the product of the number of respondents times the mean value for the respondents added to the number of nonrespondents times the mean value for nonrespondents:
The bias for the estimate of a total, yr, is:
Thus, the bias is small if the number of nonrespondents is small or if the mean for nonrespondents is low. The bias for an estimate of variance is:
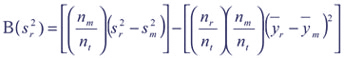
Note first, that the first term is similar to the equation for the bias of the mean, in that it is the product of the nonresponse rate and a difference ¾ in this case the difference is that between the variance of the respondents and the nonrespondents. The second term is the product of the response rates for respondents and nonrespondents and the squared difference between the means for the respondents less the nonrespondents. Suppose the variances for respondents and nonrespondents are similar (a more reasonable assumption than assuming this for the means), then the nonresponse rate times zero or a small difference is negligible. When this is the case, the bias in the variance is a function of the product of the response and nonresponse rates and the contribution from the squared difference in the mean values for respondents less nonrespondents. In other words, the bias in the variance is a function of the amount of nonresponse and the difference in the means for respondents and nonrespondents and it will always result in an underestimate of the variance. Consider the example in which the variance is the same for respondents and nonrespondents and the response rate is 70 percent. The bias formula reduces to the second term:

The product of the response rates is .21 and the squared difference of the means, some value z, will be positive regardless of which mean is larger. The bias is then equal to:
If the variances of the respondents and nonrespondents are the same, the variance will always be underestimated. However, in some cases the variances associated with respondents and nonrespondents may not be equal. For example, consider the case of income reporting where nonrespondents are likely to be concentrated at the upper and lower ends of the distribution, leaving the respondents more clustered in the middle. It will result in a larger variance associated with the nonrespondents than the variance for the respondents. Thus the difference between the two variances will be negative. Continuing with the earlier example, the bias for an estimate of the variance becomes:
Where j is the difference between the two variance estimates. Again, the variance is underestimated. In fact, j is likely to always be smaller than z, since variances decrease as the sample size increases. However, the differences in the means are not affected by sample size; and as a result, are likely to be larger in large-scale surveys. Thus, more of the bias is due to the differences in the means and the variance will always be underestimated. The bias for an estimate of covariance is:
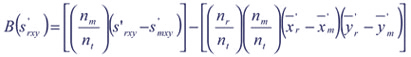
Consider the case where respondents are defined as those who answered
both y and a second variable x. Here r' is the
number of cases with answers to both x and y, with the
prime used to indicate the joint response. If s'wy = s'mwy
the covariance is not necessarily underestimated. When the estimates
of covariance are equal for respondents and nonrespondents, the bias
will be negative (i.e., an underestimate of the covariance) if the signs
on |




