

When you see the mythical Ouroboros, it’s perfectly logical to think, “Well, that won’t last.” A potent symbol — swallowing your own tail — but difficult in practice. It may be the case for AI as well, which, according to a new study, may be at risk of “model collapse” after a few rounds of being trained on data it generated itself.
In a paper published in Nature, British and Canadian researchers led by Ilia Shumailov at Oxford show that today’s machine learning models are fundamentally vulnerable to a syndrome they call “model collapse.” As they write in the paper’s introduction:
We discover that indiscriminately learning from data produced by other models causes “model collapse” — a degenerative process whereby, over time, models forget the true underlying data distribution …
How does this happen, and why? The process is actually quite easy to understand.
AI models are pattern-matching systems at heart: They learn patterns in their training data, then match prompts to those patterns, filling in the most likely next dots on the line. Whether you ask, “What’s a good snickerdoodle recipe?” or “List the U.S. presidents in order of age at inauguration,” the model is basically just returning the most likely continuation of that series of words. (It’s different for image generators, but similar in many ways.)
But the thing is, models gravitate toward the most common output. It won’t give you a controversial snickerdoodle recipe but the most popular, ordinary one. And if you ask an image generator to make a picture of a dog, it won’t give you a rare breed it only saw two pictures of in its training data; you’ll probably get a golden retriever or a Lab.
Now, combine these two things with the fact that the web is being overrun by AI-generated content and that new AI models are likely to be ingesting and training on that content. That means they’re going to see a lot of goldens!
And once they’ve trained on this proliferation of goldens (or middle-of-the road blogspam, or fake faces, or generated songs), that is their new ground truth. They will think that 90% of dogs really are goldens, and therefore when asked to generate a dog, they will raise the proportion of goldens even higher — until they basically have lost track of what dogs are at all.
This wonderful illustration from Nature’s accompanying commentary article shows the process visually:
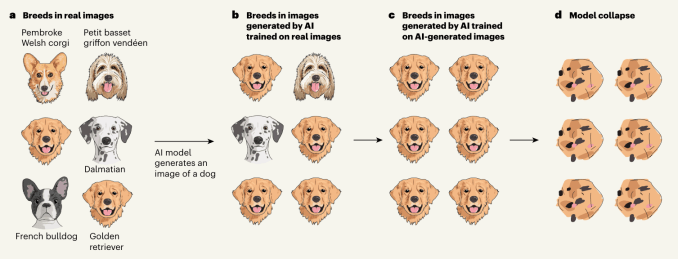
A similar thing happens with language models and others that, essentially, favor the most common data in their training set for answers — which, to be clear, is usually the right thing to do. It’s not really a problem until it meets up with the ocean of chum that is the public web right now.
Basically, if the models continue eating each other’s data, perhaps without even knowing it, they’ll progressively get weirder and dumber until they collapse. The researchers provide numerous examples and mitigation methods, but they go so far as to call model collapse “inevitable,” at least in theory.
Though it may not play out as the experiments they ran show it, the possibility should scare anyone in the AI space. Diversity and depth of training data is increasingly considered the single most important factor in the quality of a model. If you run out of data, but generating more risks model collapse, does that fundamentally limit today’s AI? If it does begin to happen, how will we know? And is there anything we can do to forestall or mitigate the problem?
The answer to the last question at least is probably yes, although that should not alleviate our concerns.
Qualitative and quantitative benchmarks of data sourcing and variety would help, but we’re far from standardizing those. Watermarks of AI-generated data would help other AIs avoid it, but so far no one has found a suitable way to mark imagery that way (well … I did).
In fact, companies may be disincentivized from sharing this kind of information, and instead hoard all the hyper-valuable original and human-generated data they can, retaining what Shumailov et al. call their “first mover advantage.”
[Model collapse] must be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of LLM-generated content in data crawled from the Internet.
… [I]t may become increasingly difficult to train newer versions of LLMs without access to data that were crawled from the Internet before the mass adoption of the technology or direct access to data generated by humans at scale.
Add it to the pile of potentially catastrophic challenges for AI models — and arguments against today’s methods producing tomorrow’s superintelligence.






