
Biochemistry/Print version
Introduction
[edit | edit source]Intro: What Is Biochemistry?
[edit | edit source]Biochemistry is the study of the chemistry of, and relating to, biological organisms. It forms a bridge between biology and chemistry by studying how complex chemical reactions and chemical structures give rise to life and life's processes. Biochemistry is sometimes viewed as a hybrid branch of organic chemistry which specializes in the chemical processes and chemical transformations that take place inside of living organisms, but the truth is that the study of biochemistry should generally be considered neither fully "biology" nor fully "chemistry" in nature. Biochemistry incorporates everything in size between a molecule and a cell and all the interactions between them. The aim of biochemists is to describe in molecular terms the structures, mechanisms and chemical processes shared by all organisms, providing organizing principles that underlie life in all its diverse forms.
Biochemistry essentially remains the study of the structure and function of cellular components (such as enzymes and cellular organelles) and the processes carried out both on and by organic macromolecules - especially proteins, but also carbohydrates, lipids, nucleic acids, and other biomolecules. All life forms alive today are generally believed to have descended from a single proto-biotic ancestor, which could explain why all known living things naturally have similar biochemistries. Even when it comes to matters which could appear to be arbitrary - such as the genetic code and meanings of codons, or the "handedness" of various biomolecules - it is irrefutable fact that all marine and terrestrial living things demonstrate certain unchanging patterns throughout every level of organization, from family and phylum to kingdom and clade.
Biochemistry is, most simply put, the chemistry of life.
Thermodynamics
[edit | edit source]Why Do Substances React?
[edit | edit source]Chemical (and thus, biochemical) reactions only occur to a significant extent if they are energetically favorable. If the products are more stable than the reactants, then in general the reaction will, over time, tend to go forward. Ashes are more stable than wood, so once the energy of activation is supplied (e.g., by a match), the wood will burn. There are plenty of exceptions to the rule, of course, but as a rule of thumb it's pretty safe to say that if the products of a reaction represent a more stable state, then that reaction will go in the forward direction.
There are two factors that determine whether or not reactions changing reactants into products are considered to be favorable: these two factors are simply called enthalpy and entropy.
Enthalpy
[edit | edit source]Simply put, enthalpy is the heat content of a substance (H). Most people have an intuitive understanding of what heat is... we learn as children not to touch the burners on the stove when they are glowing orange. Enthalpy is not the same as that kind of heat. Enthalpy is the sum of all the internal energy of a substance's matter plus its pressure times its volume. Enthalpy is therefore defined by the following equation:

where (all units given in SI)
- H is the enthalpy
- U is the internal energy, (joules)
- P is the pressure of the system, (Pascals)
- and V is the volume, (cubic meters)
If the enthalpy of the reactants while being converted to products ends up decreasing (ΔH < 0), that means that the products have less enthalpy than the reactants and energy is released to the environment. This reaction type is termed exothermic. In the course of most biochemical processes there is little change in pressure or volume, so the change in enthalpy accompanying a reaction generally reflects the change in the internal energy of the system. Thus, exothermic reactions in biochemistry are processes in which the products are lower in energy than the starting materials.
As an example, consider the reaction of glucose with oxygen to give carbon dioxide and water. Strong bonds form in the products, reducing the internal energy of the system relative to the reactants. This is a highly exothermic reaction, releasing 2805 kJ of energy per mole of glucose that burns (ΔH = -2805 kJ/mol). That energy is given off as heat.
| ΔH | reactants/products | environment | favorable |
|---|---|---|---|
| < 0 | releases heat | heats up | yes |
| > 0 | gains heat | cools down | no |
Entropy
[edit | edit source]Entropy (symbol S) is the measure of randomness in something. It represents the most likely of statistical possibilities of a system, so the concept has extremely broad applications. In chemistry of all types, entropy is generally considered important in determining whether or not a reaction goes forward based on the principle that a less-ordered system is more statistically probable than a more-ordered system.
What does that mean, really? Well, if the volcano Mt. Vesuvius erupted next to a Roman-Empire era Mediterranean city, would the volcano be more likely to destroy the city, or build a couple of skyscrapers there? It's pretty obvious what would happen (or, rather, what did happen) because it makes sense to us that natural occurrences favor randomness (destruction) over order (construction, or in this case, skyscrapers). Entropy is just a mathematical way of expressing these essential differences.
When it comes to chemistry, there are three major concepts based on the concept of entropy:
- Intramolecular states (Degrees of freedom)
- The more degrees of freedom (how much the molecules can move in space) a molecule has, the greater the degree of randomness, and thus, the greater the entropy.
- There are three ways molecules can move in space, and each has a name: rotation = movement around an axis, vibration = intramolecular movement of two bonded atoms in relation to each other, and translation = a molecule moving from place to place.
- Intermolecular structures
- When molecules can interact with each other by forming non-covalent bonds a structure is often created.
- This tends to reduce randomness (and thus entropy) since any such association between molecules stabilizes the motion of both and decreases the possibilities for a random distribution.
- Number of possibilities
- The more molecules present, the more ways of distributing the molecules in space - which because of statistical probabilities means more potential for randomness.
- Also, if there is more space available to distribute the molecules within, the randomness increases for precisely the same reason
- solid matter (least entropy) << liquids << gases (most entropy)
Changes in entropy are denoted as ΔS. For the reasons stated above (in the volcano situation), the increase of entropy (ΔS > 0) is considered to be favorable as far as the Universe in general is concerned. A decrease in entropy is generally not considered favorable unless an energetic component in the reaction system can make up for the decrease in entropy (see free energy below).
| ΔS | entropy | favorable |
|---|---|---|
| > 0 | increases | yes |
| < 0 | decreases | no |
Gibbs Free Energy
[edit | edit source]Changes of both enthalpy (ΔH) and entropy (ΔS) combined decide how favorable a reaction is. For instance, burning a piece of wood releases energy (exothermic, favorable) and results in a substance with less structure (CO2 and H2O gas, both of which are less 'ordered' than solid wood). Thus, one could predict that once a piece of wood was set on fire, it would continue to burn until it was gone. The fact that it does so is ascribed to the change in its Gibbs Free Energy.
The overall favorability of a reaction was first described by the prominent chemist Josiah Willard Gibbs, who defined the free energy of a reaction as
- ΔG = ΔH - T ΔS
where T is the temperature on the Kelvin temperature scale. The formula above assumes that pressure and temperature are constant during the reaction, which is almost always the case for biochemical reactions, and so this book makes the same assumption throughout.
The unit of ΔG (for Gibbs) is the "joule" in SI systems, but the unit of "calorie" is also often used because of its convenient relation to the properties of water. This book will use both terms as convenient, but the preference should really be for the SI notation.
What Does ΔG Really Mean?
[edit | edit source]If ΔG < 0 then the reactants should convert into products (signifying a forward reaction)... eventually. (Gibbs free energy says nothing about a reaction's rate, only its probability.) Likewise, for a given reaction if ΔG > 0 then it is known that the reverse reaction is favored to take place. A state where ΔG = 0 is called equilibrium, and this is the state where the reaction in both the forward and reverse directions take place at the same rate, thus not changing the net effect on the system.
How is equilibrium best explained? Alright, as an example set yourself on the living room carpet with your most gullible younger relative (a little nephew, niece or cousin will work fine). Take out a set of Monopoly, take one ten dollar bill for yourself and give your little relative the rest. Now both of you give the other 5% of all that you have. Do this again, and again, and again-again-again until eventually... you both have the same amount of money. This is precisely what the equilibrium of a reaction means, though equilibrium only very rarely results in an even, 50-50% split of products and reactants.
ΔG naturally varies with the concentration of reactants and products. When ΔG reaches 0, the reaction rate in the forward direction and the reaction rate in the reverse direction are the same, and the concentration of reactants and products no longer appears to change; this state is called the point of chemical equilibrium. You and your gullible little relative have stopped gaining and losing Monopoly money, respectively; you both keep exchanging the same amount each turn. Note again that equilibrium is dynamic. Chemical reaction does not cease at equilibrium, but products are converted to reactants and reactants are converted to products at exactly the same rate.
A small ΔG (that is, a value of ΔG close to 0) indicates that a reaction is somewhat reversible; the reaction can actually run backwards, converting products back to reactants. A very large ΔG (that is, ΔG >> 0 or ΔG << 0) is precisely the opposite, because it indicates that a given reaction is irreversible, i.e., once the reactants become products there are very few molecules that go back to reactants.
Metabolic pathways
[edit | edit source]The food we consume is processed to become a part of our cells; DNA, proteins, etc. If the biochemical reactions involved in this process were reversible, we would convert our own DNA back to food molecules if we stop eating even for a short period of time. To prevent this from happening, our metabolism is organized in metabolic pathways. These pathways are a series of biochemical reactions which are, as a whole, irreversible. The reactions of a pathway occur in a row, with the products of the first reaction being the reactants of the second, and so on:
- A ⇌ B ⇌ C ⇌ D ⇌ E
At least one of these reactions has to be irreversible, e.g.:
- A ⇀ B ⇌ C ⇌ D ⇀ E
The control of the irreversible steps (e.g., A → B) enables the cell to control the whole pathway and, thus, the amount of reactants used, as well as the amount of products generated.
Some metabolic pathways do have a "way back", but it is not the same pathway backwards. Instead, while using the reversible steps of the existing pathway, at least one of the irreversible reactions is bypassed by another (irreversible) one on the way back from E to A:
- E ⇀ X ⇌ C ⇌ B ⇀ A
This reaction is itself controlled, letting the cell choose the direction in which the pathway is running.
Free energy and equilibrium
[edit | edit source]For ΔG, the free energy of a reaction, standard conditions were defined:
- concentration of reactants and products at 1Mol/dm³
- temperature at 25°C
- acidity at pH 7.0
Under these standard conditions, ΔG0' is defined as the standard free energy change.
For a reaction
- A + B ⇌ C + D
the ratio of products to reactants is given by keq' (=keq at pH 7.0):
![{\displaystyle k_{eq}^{\prime }={{\text{products}} \over {\text{reactants}}}={[C][D] \over [A][B]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0c6a882dd325456e78cf9946f774d3ae5d3a8b8c)
The relationship of ΔG0' and keq' is
- ΔG0' = - R T ln keq' = - R T 2.30 log10 keq'
with
- R = 8.315 [J mol-1 K-1] (molar gas constant)
- T = temperature [K]
- In = loge ("e" equals to 2.71828...)
In theory, we can now decide if a reaction is favorable (ΔG0' < 0). However, the reaction might need a catalyst to occur within a reasonable amount of time. In biochemistry, such a catalyst is called an enzyme.
The purpose of DNA melting or DNA denaturation is emphasizing and demonstrating the life cycles of all organisms and the origin of replication. The origin of replication specific structure varies from species to species. Furthermore, the particular sequence of the origin of replication is in a genome which is the human genes. Nevertheless, DNA replication is also part of origin of replication which examen in the living organism such as prokaryotes and eukaryotes.
Thermodynamically, there are two important contributions on the DNA denaturation. One of them is the breaking all of the hydrogen bonds between the bases in the double helix; the other one is to overcome the stacking stability/energy of bases on top of each other. There are several methods to denature DNA; heat is known as the most common one use in laboratory. We just have to heat the sample to reach above its melting point, the unstack ability of DNA can be then monitored. Melting point and denaturation of DNA depend on several factors: the length of DNA, base-composition of DNA, the condition of the DNA and also the composition of buffer. For instance, the longer DNA will contain more H-bonds and more intermolecular forces compared to the shorter one; therefore, denaturations of longer DNA requires more time and more heat. Base-composition of DNA can also play as a key factor because A:T requires two hydrogen bonds and G:C interaction requires three hydrogen bonds. The region of DNA which contains more A:T will melt/denature more rapidly compared to G:C. We can also see how the condition of DNA is important because condition of DNA is related to whether the DNA is relax, supercoiled, linear or heavily nicked. It is important because it allow us to examine how much intermolecular forces existing in the double helix. Finally, condition of buffer is also playing an essential role to study DNA denaturation because it allow us to control the amount of ions present in the solution during the entire process.
Biologically, DNA denaturation can happen inside the cell during DNA replication or translation. In both cases, DNA denaturation is an essential step and a beginning to start each of the process. Most of the time, denaturation happened because of binding of protein or enzymes to a specific region of DNA, the binding will likely lead to open or denature of the helix. However, the actual meaning of the DNA melting is the denaturation of DNA which changes the structure of DNA from double stranded into single stranded. The processes of DNA denaturation is unwinding the double stranded deoxyribonucleic acid and breaks it into two single stranded by breaking the hydrogen bonding between the bases. DNA denaturation is also known of DNA annealing because it is reservable . The main steps DNA annealing are double helical will go through the denaturation to become partially denatured DNA then it will separated the strands into two single strand of DNA in random coils.
Catalysis
[edit | edit source]Catalysis refers to the acceleration of the rate of a chemical reaction by a substance, called a catalyst, that is itself unchanged by the overall reaction. Catalysis is crucial for any known form of life, as it makes chemical reactions happen much faster than they would "by themselves", sometimes by a factor of several million times.
A common misunderstanding is that catalysis "makes the reaction happen", that the reaction would not otherwise proceed without the presence of the catalyst. However, a catalyst cannot make a thermodynamically unfavorable reaction proceed. Rather, it can only speed up a reaction that is already thermodynamically favorable. Such a reaction in the absence of a catalyst would proceed, even without the catalyst, although perhaps too slowly to be observed or to be useful in a given context.
Catalysts accelerate the chemical reaction by providing a lower energy pathway between the reactants and the products. This usually involves the formation of an intermediate, which cannot be formed without the catalyst. The formation of this intermediate and subsequent reaction generally has a much lower activation energy barrier than is required for the direct reaction of reactants to products.
Catalysis is a very important process from an industrial point of view since the production of most industrially important chemicals involve catalysis. Research into catalysis is a major field in applied science, and involves many fields of chemistry and physics.
Two types of catalysis are generally distinguished. In homogeneous catalysis the reactants and catalyst are in the same phase. For example acids (H+ ion donors) are common catalysts in many aqueous reactions. In this case both the reactants and the catalysts are in the aqueous phase. In heterogeneous catalysis the catalyst is in a different phase than the reactants and products. Usually, the catalyst is a solid and the reactants and products are gases or liquids. In order for the reaction to occur one or more of the reactants must diffuse to the catalyst surface and adsorb onto it. After reaction, the products must desorb from the surface and diffuse away from the solid surface. Frequently, this transport of reactants and products from one phase to another plays a dominant role in limiting the rate of reaction. Understanding these transport phenomena is an important area of heterogeneous catalyst research.
Enzymes
[edit | edit source]Enzyme (from Greek, in ferment) are special protein molecules whose function is to facilitate or otherwise accelerate most chemical reactions in cells. They are simply biological catalysts. Most enzymes are proteins, although a few are catalytic RNA molecules called ribozymes. Many chemical reactions occur within biological cells, but without catalysts most of them happen too slowly in the test tube to be biologically relevant.
Enzymes can also serve to couple two or more reactions together, so that a thermodynamically favorable reaction can be used to "drive" a thermodynamically unfavorable one. One of the most common examples is enzymes which use the dephosphorylation of ATP to drive some otherwise unrelated chemical reaction.
Chemical reactions need a certain amount of activation energy to take place. Enzymes can increase the reaction speed by favoring or enabling a different reaction path with a lower activation energy (Fig. 1), making it easier for the reaction to occur. Enzymes are large globular proteins that catalyze (accelerate) chemical reactions. They are essential for the function of cells. Enzymes are very specific as to the reactions they catalyze and the chemicals (substrates) that are involved in the reactions. Substrates fit their enzymes like a key fits its lock (Fig. 2). Many enzymes are composed of several proteins that act together as a unit. Most parts of an enzyme have regulatory or structural purposes. The catalyzed reaction takes place in only a small part of the enzyme called the active site, which is made up of approximately 2 - 20 amino acids.

The substrates (A and B) need a large amount of energy (E1) to reach the intermediate state A...B, which then reacts to form the end product (AB). The enzyme (E) creates a microenvironment in which A and B can reach the intermediate state (A...E...B) more easily, reducing the amount of energy needed (E2). As a result, the reaction is more likely to take place, thus improving the reaction speed.

Enzymes can perform up to several million catalytic reactions per second. To determine the maximum speed of an enzymatic reaction, the substrate concentration is increased until a constant rate of product formation is achieved (Fig. 3). This is the maximum velocity (Vmax) of the enzyme. In this state, all enzyme active sites are saturated with substrate. This was proposed in 1913 by Leonor Michaelis and Maud Menten. Since the substrate concentration at Vmax cannot be measured exactly, enzymes are characterized by the substrate concentration at which the rate of reaction is half its maximum. This substrate concentration is called the Michaelis-Menten constant (KM). Many enzymes obey Michaelis-Menten kinetics.

The speed V means the number of reactions per second that are catalyzed by an enzyme. With increasing substrate concentration [S], the enzyme is asymptotically approaching its maximum speed Vmax, but never actually reaching it. Because of that, no [S] for Vmax can be given. Instead, the characteristic value for the enzyme is defined by the substrate concentration at its half-maximum speed (Vmax/2). This KM value is also called Michaelis-Menten constant.
Several factors can influence the reaction speed, catalytic activity, and specificity of an enzyme. Besides de novo synthesis (the production of more enzyme molecules to increase catalysis rates), properties such as pH or temperature can denature an enzyme (alter its shape) so that it can no longer function. More specific regulation is possible by posttranslational modification (e.g., phosphorylation) of the enzyme or by adding cofactors like metal ions or organic molecules (e.g., NAD+, FAD, CoA, or vitamins) that interact with the enzyme. Allosteric enzymes are composed of several subunits (proteins) that interact with each other and thus influence each other's catalytic activity. Enzymes can also be regulated by competitive inhibitors (Fig. 4) and non-competitive inhibitors and activators (Fig. 5). Inhibitors and activators are often used as medicines, but they can also be poisonous.

A competitive inhibitor fits the enzyme as well as its real substrate, sometimes even better. The inhibitor takes the place of the substrate in the active center, but cannot undergo the catalytic reaction, thus inhibiting the enzyme from binding with a substrate molecule. Some inhibitors form covalent bonds with the enzyme, deactivating it permanently (suicide inhibitors). In terms of the kinetics of a competitive inhibitor, it will increase Km but leave Vmax unchanged.

Non-competitive inhibitors/activators (I) do not bind to the active center, but to other parts of the enzyme (E) that can be far away from the substrate (S) binding site. By changing the conformation (the three-dimensional structure) of the enzyme (E), they disable or enable the ability of the enzyme (E) to bind its substrate (S) and catalyze the desired reaction. The noncompetitive inhibitor will lower Vmax but leave Km unchanged.
An uncompetitive inhibitor will only bind to the enzyme-substrate complex forming an enzyme-substrate-inhibitor (ESI) complex and cannot be overcome by additional substrate. Since the ESI is nonreactive, Vmax is effectively lowered. The uncompetitive inhibitor will in turn lower the Km due to a lower concentration of substrate needed to achieve half the maximum concentration of ES.
Several enzymes can work together in a specific order, creating metabolic pathways (e.g., the citric acid cycle, a series of enzymatic reactions in the cells of aerobic organisms, important in cellular respiration). In a metabolic pathway, one enzyme takes the product of another enzyme as a substrate. After the catalytic reaction, the product is then passed on to another enzyme. The end product(s) of such a pathway are often non-competitive inhibitors (Fig. 5) for one of the first enzymes of the pathway (usually the first irreversible step, called committed step), thus regulating the amount of end product made by the pathway (Fig. 6).

- The basic feedback inhibition mechanism, where the product (P) inhibits the committed step (A⇀B).
- Sequential feedback inhibition. The end products P1 and P2 inhibit the first committed step of their individual pathway (C⇀D or C⇀F). If both products are present in abundance, all pathways from C are blocked. This leads to a buildup of C, which in turn inhibits the first common committed step A⇀B.
- Enzyme multiplicity. Each end product inhibits both the first individual committed step and one of the enzymes performing the first common committed step.
- Concerted feedback inhibition. Each end product inhibits the first individual committed step. Together, they inhibit the first common committed step.
- Cumulative feedback inhibition. Each end product inhibits the first individual committed step. Also, each end product partially inhibits the first common committed step.
Enzymes are essential to living organisms, and a malfunction of even a single enzyme out of approximately 2,000 present in our bodies can lead to severe or lethal illness. An example of a disease caused by an enzyme malfunction in humans is phenylketonuria (PKU). The enzyme phenylalanine hydroxylase, which usually converts the essential amino acid phenylalanine into tyrosine does not work, resulting in a buildup of phenylalanine that leads to mental retardation. Enzymes in the human body can also be influenced by inhibitors in good or bad ways. Aspirin, for example, inhibits an enzyme that produces prostaglandins (inflammation messengers), thus suppressing pain. But not all enzymes are in living things. Enzymes are also used in everyday products such as biological washing detergents where they speed up chemical reactions, (to get your clothes clean).
Digestive and Metabolic Enzymes
[edit | edit source]In the previous section we have been talking about the digestive enzymes, both the ones produced by the body, such as salivary amylase, and the food enzymes. Their primary role is for the digestion of food. Another class of enzymes is called metabolic enzymes. Their role is to catalyze chemical reactions involving every process in the body, including the absorption of oxygen. Our cells would literally starve for oxygen even with an abundance of oxygen without the action of the enzyme, cytochrome oxidase. Enzymes are also necessary for muscle contraction and relaxation. The fact is, without both of these classes of enzymes, (digestive and metabolic,) life could not exist. Digestive enzymes function as biological catalysts in which it helps to breakdown carbohydrates, proteins, and fats. On the other hand, metabolic enzymes function as a remodel of cells. Digestion of food has a high priority and demand for enzymes; digestive enzymes get priority over metabolic enzymes. Any deficiency in metabolic enzyme can lead to over work, which could lead to enlarge organs in order to perform the increased workload. The result is unhealthy and could cause enlarged heart or pancreas. The deficiencies of metabolic enzymes can have a tremendous impact on health. As we grow older enzyme level decline and the efficiency in the body decline.
Enzyme naming conventions
[edit | edit source]By common convention, an enzyme's name consists of a description of what it does, with the word ending in "-ase". Examples are alcohol dehydrogenase and DNA polymerase. Kinases are enzymes that transfer phosphate groups. The International Union of Biochemistry and Molecular Biology has developed a nomenclature for enzymes, the EC numbers; each enzyme is described by a sequence of four numbers, preceded by "EC". The first number broadly classifies the enzyme based on its mechanism:
- EC 1 Oxidoreductases: catalyze oxidation/reduction reactions
- EC 2 Transferases: transfer a functional group (e.g., a methyl or phosphate group)
- EC 3 Hydrolases: catalyze the hydrolysis of various bonds
- EC 4 Lyases: cleave various bonds by means other than hydrolysis and oxidation
- EC 5 Isomerases: catalyze isomerization changes within a single molecule
- EC 6 Ligases: join two molecules with covalent bonds
Some other important enzymes are: Protease: breaks the protein into amino acids in high acidity environments such as stomach, pancreatic and intestinal juices. Act on bacteria, viruses and some cancerous cells. Amylase: Break complex carbohydrates such as starch into simpler sugars (dextrin and maltose). It found in the intestines, pancreas and also in salivary glands. Lipase: breaks down fats and some fat soluble vitamins (A,E,K, and D). helpful in treating cardiovascular diseases. Cellulase: break down cellulose that found in fruits, grains, and vegetables. It increases the nutritional values of vegetables, and fruits. Pectinase: break down pectin that found in citrus fruits, carrots, beets, tomatoes, and apple. Antioxidants: protect from free radical negative effect that can damage cell in the body. Cathepsin: break animal protein down. Lactase: break down lactose that found in milk products. the production of lactase decrease with age. Invertase: assimilate sucrose that can contribute to digestive stress if not digested properly. Papain: break down protein and help the body in digestion. Bromelain: Break proteins that found in plants and animals. it could help the body to fight cancer and treat inflammation. Glucoamylase: break down maltose that found in all grains in to two glucose molecules.
Metabolism and energy
[edit | edit source]Metabolism
[edit | edit source]Anabolism and catabolism
[edit | edit source]Metabolism (Fig. 1) is, broadly speaking, the conversion of food into energy, cell components, and waste products.

Figure 1: Overview of metabolism
The above diagram shows the different parts of metabolism:
- energy source, which is, after all, the sun, whose energy is harvested through photosynthesis
- catabolism, the breakdown of food into chemical energy, which is needed in
- anabolism, the construction of complex cell molecules from small environmental molecules, utilizing chemical energy
Catabolic reactions release energy and are therefore exergonic, while anabolic reactions use up energy and are therefore endergonic.
High-energy phosphates
[edit | edit source]Due to the large variety of food compounds, and the large number of biochemical reactions which need energy in anabolism, it would be quite inefficient to couple a specific anabolic reaction to a specific energy source in catabolism. Instead, the cell uses an intermediate compound, a kind of universal energy currency. This intermediate is called high-energy phosphate.
But when is a phosphate group called "high-energy", and how does it differ from a "low-energy" phosphate? A giveaway is the ΔG0' of hydrolysis. Hydrolysis separates a phosphate from a compound by adding water:
O O R-OP-OH + H2O ⇌ R-OH + HO-P-OH O O
The ΔG0' of a low-energy (or "inorganic") phosphate group (called Pi) is 9-20 kJ mol-1, while the ΔG0' of a high-energy phosphate (denoted Ⓟ) is ~30 kJ mol-1.
pKa value
[edit | edit source]Now what makes this Ⓟ so special? To explain this, we must take a little excourse into pH and pKa values. A phosphate group has between zero and three OH groups. This allows Ⓟ to exist in up to four different forms (0, 1, 2, and 3 OH groups, Fig. 2), depending on the pH value of the surrounding solution. A pKa value gives us the pH value at which 50% of the molecules are in one form (e.g., 1 OH group) and another (e.g., 2 OH groups). This is expressed by the Henderson-Hasselbalch equation :
![{\displaystyle {pH}={pK}_{a}+log{[base] \over [acid]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/c76e01f52dd2a8970a93ded61f409e95ebe9726a)

Figure 2: The four possible forms of a phosphate group. pKa2 represents the conditions in the cell.
Now to the promised difference between Ⓟ and PPi. The breaking of the ester bond of an ROⓅ releases more energy than the breaking of a PPi bond (Fig. 3), because of
- electrostatic repulsion between the two phosphate groups in PPi
- resonance stabilization of two Pi groups, compared to PPi (Fig. 4)

Figure 3: Hydrolysis of Ⓟ and PPi.

Figure 4: Resonance stabilization of Pi.
Resonance stabilization means that both OH and =O can "travel" around the phosphate. Of course, this is a crude analogy; they do not really move, the electrons are just "smeared" around the phosphate atom. This is also indicated by the use of the ↔ arrow, instead of ⇌; the three forms do not exist, they are just a way of writing down the chemical reality.
As you can see in Fig. 3, the ΔG0' value for PPi⇌2Pi is ≪0, shifting the reaction strongly in favor of the 2Pi.
Molecules using high-energy phosphates
[edit | edit source]Anhydride between phosphoric acid and carboxyl group
[edit | edit source]Hydrolysis : ΔG0' = -49.3 kJ mol-1

Guanidine phosphate
[edit | edit source]Hydrolysis : ΔG0' = -43.0 kJ mol-1

Enol phosphate
[edit | edit source]In the below picture, the final product should not have a carbon-carbon double bond, but a single bond with CH3 on the top. It is an error.
Hydrolysis : ΔG0' = -61.9 kJ mol-1

ATP
[edit | edit source]Adenosine triphosphate contains one low-energy and two high-energy phosphate bonds:

Low energy : ΔG0' = -14,2 kJ mol-1
High energy : ΔG0' = -30.5 kJ mol-1
- ATP is regenerated from ADP (adenosine diphosphate), Pi and energy (from food); H2O is released in the process.
- ATP is the short-term energy "currency" of the cell.
- ATP concentration in the cell is low (ATP: 2-8mM; ADP:0,2-0,8mM). ATP is generated in high "turn over".
- ATP performs its chemical work through coupled reactions.
- Coupled reactions are always Ⓟ transfers, never direct hydrolysis
Basically, any ATP-driven reaction is reversible, building ATP from ADP and Pi in the process. However, some ATP-driven reactions should never be reversed; these include nucleotide and protein synthesis. If these were reversed, the organism would disassemble its own DNA and proteins for energy, a rather unfortunate strategy. For reactions that should never be reversed, ATP can be broken down into AMP (adenosine monophosphate) and PPi, which in turn becomes 2×Pi. This reaction has a ΔG0' of -65,7 kJ mol-1, which is totally irreversible under in vivo conditions.
It should be noted that AMP can not directly be converted to ATP again. Instead, the enzyme AMP kinase forms two ADP molecules from one ATP and one AMP. The resulting ADPs are then treated as described above.
Non-covalent bonds
[edit | edit source]The destruction of covalent bonds takes up huge amounts of energy. The breakdown of an O2 molecule into two oxygen atoms needs ~460 kJ mol-1. Thus, nowhere in "living" biochemistry are covalent bonds actually destroyed; if one is broken, another one is created. This is where non-covalent bonds come in, they are weak enough to be broken down easily, and to form "bonds" again. For this reason, many biochemical functions are using so-called weak/secondary/non-covalent bonds.
Weak bonds are created and destroyed much more easily than covalent ones. The typical range of energy needed to destroy such a weak bond is 4-30 kJ mol-1. Thus, the formation of weak bonds is energetically favorable, but these bonds are also easily broken by kinetic (thermal) energy (the normal movement of molecules). Biochemical interactions are often temporary (e.g., a substrate has to leave an enzyme quickly after being processed), for which the weakness of these bonds is essential. Also, biochemical specificity (e.g., enzyme-substrate-recognition) is achieved through weak bonds, utilizing two of their major properties:
- Since individual weak bonds are, well, weak, several of them have to occur in a specific pattern at the same time in roughly the same place.
- The short range of weak bonds.
The link that follows demonstrates the type of non-covalent forces: [1] There are three basic types of weak bonds, and a fourth "pseudo-bond":
Ionic bonds
[edit | edit source]Ionic bonds are electrostatic attractions between permanently charged groups. Ionic bonds are not directed. Example:
- X-CO2- ..... H3+N-Y
- ~ 20 kJ mol-1
Hydrogen bonds
[edit | edit source]Hydrogen bonds are also established by electrostatic attraction. These attractions do not occur between permanently charged groups, but rather between atoms temporarily charged by a dipole moment, resulting from the different electronegativity of atoms within a group. Hydrogen bonds are even weaker than ionic bonds, and they are highly directional, usually along a straight line. Besides being weaker than ionic bonds, hydrogen bonds are also weaker, and longer than similar covalent bonds. Hydrogen bonds are unique because they only exist when the Hydrogen is bonded to an oxygen (O), Nitrogen (N), or Fluorine (F), but the most common hydrogen bonds in biochemistry are:
- X-OH ..... O-Y
- X-OH ..... N-Y
- X-NH ..... O-Y
- X-NH ..... N-Y
Hydrogen bonds equal an energy between 12-29 kJ mol, whereas covalent bonds are much higher. For example, the covalent bond between oxygen and hydrogen is about 492 KJ mol-1.
Hydrogen Bonds and Water
[edit | edit source]Water has unique properties; after all, it is chosen to be the universal solvent. The unique properties of water are due to hydrogen bonding between all the oxygen and hydrogen atoms of the content. The hydrogen bonds occurring in water are about 2 angstroms apart from each other. Although hydrogen bonding is only about 5% as strong as covalent bond, they still cause water to have a high boiling point, and a high surface tension. The following link will take you to the structure of water and its Hydrogen Bonding.
Van der Waals attractions
[edit | edit source]Van der Waals attractions are established between electron density-induced dipoles. They form when the outer electron shells of two atoms almost (but not quite) touch. The distance of the atoms is very important for these weak interactions. If the atoms are too far apart, the interactions are too weak to establish; if the atoms are too close to each other, their electron shells will repel each other. Van der Waals attractions are highly unspecific; they can occur between virtually any two atoms. Their energy is between 4-8 kJ mol-1.
Hydrophobic interactions
[edit | edit source]Hydrophobic forces are not actually bonds, so this list has four items, but still just three bond types. In a way hydrophobic forces are the negation of the hydrogen bonds of a polar solute, usually water, enclosing a nonpolar molecule. For a polar solute like water, it is energetically unfavorable to "waste" a possible hydrogen bond by exposing it towards a nonpolar molecule. Thus, water will arrange itself around any nonpolar molecule in such a way that no hydrogen bonds point towards that molecule. This results in a higher order, compared to "freely" moving water, which leads to a lower entropy level and is thus energetically unfavorable. If there is more than one nonpolar molecule in the solute, it is favorable for the nonpolar molecules to aggregate in one place, reducing their surrounding, ordered "shell" of water to a minimal surface. Also, in large molecules, such as proteins, the hydrophobic (nonpolar) parts of the molecule will tend to turn towards the inside, while the polar parts will tend to turn towards the surface of the molecule.
References
[edit | edit source]Cooke, Rosa-lee. Properties of Water. Lecture 10. Mountain Empire Community College. n.d. Web. http://water.me.vccs.edu/courses/env211/lesson10_print.htm
Kimball, John W.. Hydrogen Bonds. Kimball’s Biology Pages. Feb. 12, 2011. Web. http://users.rcn.com/jkimball.ma.ultranet/BiologyPages/H/Hbonds_water.gif
Lower, Stephen. States of matter: Water and hydrogen bonding. General Chemistry Virtual Textbooks. 2009. Aug. 26, 2010. Web. http://www.chem1.com/acad/webtext/states/water.html
n.p. Covalent vs. Non-Covalent Bonds. n.d. http://www.pearsonhighered.com/mathews/ch02/c02cv.htm
W. W. Norton & Company. Hydrogen Bonding in Water. Web. 2012. http://www.wwnorton.com/college/chemistry/gilbert2/tutorials/chapter_10/water_h_bond/
WyzAnt Tutoring. WyzAnt Tutoring. Bonds. 2012. Web. http://www.wyzant.com/Help/Science/Chemistry/Bonds/
pKa values
[edit | edit source]It is difficult to discuss the subject of biochemistry without a firm foundation in general chemistry and organic chemistry, but if one doesn't remember the concept of the Acid Dissociation Constant (pKa) from Organic Chemistry, one can read up on the topic below.
Buffers are essential to biochemical reactions, as they provide a (more or less) stable pH value for reactions to take place under constantly changing circumstances. The pH value in living cells tends to fall between 7.2 and 7.4, and this pH level is generally maintained by weak acids. (The pH values in lysosomes and peroxisomes differ from this value, as do the pH measurements of the stomach and other organs found in various types of plants and animals.)
An acid is here defined simply as any molecule that can release a proton (H+) into a solution. Stronger acids are more likely to release a proton, due to their atomic and molecular properties. The tendency of an acid to release a proton is called the dissociation constant (Ka) of that substance, with
![{\displaystyle {K}_{a}={[{H}^{+}][{A}^{-}] \over [HA]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7f85f756d083fc3ed30e806bb5590e36fb963516)
for HA <-> H+ + A-.
A larger Ka value means a greater tendency to dissociate a proton, and thus it means the substance is a stronger acid. The pH at which 50% of the protons are dissociated can therefore be calculated as:
- pKa = -log ( Ka )
This equation is known as the Henderson-Hasselbalch equation.
![{\displaystyle {pH}={pK}_{a}+\log {[{\text{base}}] \over [{\text{acid}}]}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/80f8547bca6ac73537bd86d1ceaf1f33828aa04c)
The Henderson-Hasselbalch equation is derived from the adjacent Ka expression. By taking the logarithm of base ten to both sides, the next part of the equation is obtained. Using the logarithmic property of multiplication, the [H+] breaks from the expression. Since log Ka is equal to -pKa and log [H+] is equal to -pH, they are then substituted. To obtain what is known as the Henderson-Hasselbalch equation, -pKa and -pH are subtracted from their respective sides to yield a positive equation.
The Henderson-Hasselbalch equation interestingly enough predicts the behavior of buffer solutions. A solution of 1 M ethanoic (acetic) acid [HA] and 1 M sodium ethanoate [A-] will have a pH equal to the pKa of ethanoic acid: 4.76.
If we added acid to pure water up to a concentration of 0.1 M, the pH would become 1. If we add the same concentration of acid to the buffer solution, it will react with the ethanoate to form ethanoic acid. The ethanoate concentration would drop to 0.9 M and the ethanoic acid concentration should rise to 1.1 M. The pH becomes 4.67 - very different from the pH=1 without a buffer.
Similarly, adding 0.1 M alkali changes the pH of the buffer to 4.85, instead of pH=13 without buffer. Due to the amphipathic nature of amino acids - which are the monomer building blocks of all proteins, physiological conditions are always considered to be buffered, which plays a major role in the conformations and reactivities of substrates in the cell's liquid interior, its cytosol.
A very small (which would include a large negative value) pKa indicates a very strong acid. A pKa value between 4 and 5 is the most common range for organic acid compounds.
Proteins
[edit | edit source]Proteins are a primary constituent of living things and one of the chief classes of molecules studied in biochemistry. Proteins provide most of the molecular machinery of cells. Many are enzymes or subunits of enzymes. Other proteins play structural or mechanical roles, such as those that form the struts and joints of the cytoskeleton. Each protein is linear polymers built of amino acids. Proteins are also nutrient sources for organisms that do not produce their own energy from sunlight and/or are unable to fix nitrogen. Proteins can interact with one another and with others molecules to form complexes.
Index of chapters and main sections
Introduction
[edit | edit source]Protein role and importance
[edit | edit source]Proteins are among the fundamental molecules of biology. They are common to all life present on Earth today, and are responsible for most of the complex functions that make life possible. They are also the major structural constituent of living beings. According to the Central Dogma of Molecular Biology (proposed by Francis Crick in 1958), information is transferred from DNA to RNA to proteins. DNA functions as a storage medium for the information necessary to synthesize proteins, and RNA is responsible for (among other things) the translation of this information into protein molecules, as part of the ribosome.
Virtually all the complex chemical functions of the living cell are performed by protein-based catalysts called enzymes. Specifically, enzymes either make or break chemical bonds. Protein enzymes should not be confused with RNA-based enzymes (also called ribozymes), a group of macromolecules that perform functions similar to protein enzymes. Further, most of the scaffolding that holds cells and organelles together is made of proteins. In addition to their catalytic functions, proteins can transmit and commute signals from the extracellular environment, duplicate genetic information, assist in transforming the energy in light and chemicals with astonishing efficiency, convert chemical energy into mechanical work, and carry molecules between cell compartments.
Functions not performed by proteins
[edit | edit source]Proteins do so much that it's important to note what proteins don't do. Currently there are no known proteins that can directly replicate themselves. Prions are no exception to this rule. It is theorized that prions may be able to act as a structural template for other chemically (but not structurally) identical proteins, but they can't function as a native template for protein synthesis de novo. Proteins don't act as fundamental energy reserves in most organisms, as their metabolism is slower and inefficient compared to sugars or lipids. They are, on the other hand, a fundamental nitrogen and amino acid reserve for many organisms. Proteins do not directly function as a membrane in most organisms, except viruses; however, they are often important components of these structures, lending both stability and structural support.
Proteins as polymers of amino acids
[edit | edit source]Composition and Features
[edit | edit source]Proteins are composed of a linear (not branched and not forming rings) polymer of amino acids. The twenty genetically encoded amino acids are molecules that share a central core: The α-carbon is bonded to a primary amino (-NH2) terminus, a carboxylic acid (-COOH) terminus, a hydrogen atom, and the amino acid side chain, also called the "R-group". The R-group determines the identity of the amino acid. In an aqueous solution, at physiological pH (~6.8), the amino group will be in the protonated -NH3+ form, and the carboxylic acid will be in the deprotonated -COO- form, forming a zwitterion. Most amino acids that make up proteins are L-isomers, although a few exotic creatures use D-isomers in their proteins. It is important to note that levorotatory (L) and dextrorotatory (D) are not specific to rectus (R) and sinister (S) configurations. A levorotatory form of a protein can be either R or S configuration. Levorotatory and dextrorotatory refer to how the proteins bend light in a polarimeter.

Amino acids polymerize via peptide bonds, which is a type of amide bond. A peptide bond is formed upon the dehydration of the carboxy-terminus of one amino acid with the amine terminus of a second amino acid. The resulting carbonyl group's carbon atom is directly bound to the nitrogen atom of a secondary amine. A peptide chain will have an unbound amino group free at one end (called the N-terminus) and a single free carboxylate group at the other end (called the C-terminus).
The written list of the amino acids linked together in a protein, in order, is called its primary structure. By convention, peptide sequences are written from N-terminus to C-terminus. This convention mimics the way polypeptides are synthesized by the ribosome in the cell. Small polymers of less than 20 amino acids long are more often called peptides or polypeptides. Proteins can have sequences as short as 20-30 amino acids to gigantic molecules of more than 3,000 amino acids (like Titin,a human muscle protein).
Genetically-Encoded Amino Acids
[edit | edit source]While there are theoretically billions of possible amino acids, most proteins are formed of only 20 amino acids: the genetically-encoded (or more precisely, proteogenic) amino acids. Note that all amino acids except glycine have a chiral center at their α-carbons. (Glycine has two hydrogens on its α-carbon, and therefore it is achiral.) Besides glycine, all proteogenic amino acids are L-amino acids, meaning they have the same absolute configuration as L-glyceraldehyde. This is the same as the S-configuration, with the exception of cysteine, which contains a sulfur atom in its side chain, and so the naming priority changes. D-amino acids are sometimes found in nature, as in the cell walls of certain bacteria, but they are rarely incorporated into protein chains.
The side-chains of proteogenic amino acids are quite varied: they range from a single hydrogen atom (as for glycine, the simplest amino acid) to the indole heterocycle, as found in tryptophan. There are polar, charged and hydrophobic amino acids. The chemical richness of amino acids is at the base of the complexity and versatility of proteins.
Post-Translational Modification
[edit | edit source]There are two major types of post-translational modifications to protein: those that cleave the bonds of the peptide backbone and those that add or remove functional groups to the sidechains of individual amino acids. In the first type of post-translational modification, specialized enzymes called proteases recognize specific amino acids of a protein and break the associated peptide bond, thereby irreversibly modifying the primary structure. In the second major type of modification, the amino acid side chains of a given protein are chemically modified by enzymatic reactions or are spontaneously formed (non-enzymatic). Examples of sidechain modifications are quite numerous, but common ones include oxidation, acylation, glycosylation (addition of a glycan, or sugar), methylation, and phosphorylation. Both types of post-translational modifications are capable of exerting positive and negative control over a given protein or enzyme.
The importance of protein structure
[edit | edit source]Generally speaking, the function of a protein is completely determined by its structure. Molecules like DNA, which perform a fairly small set of functions, have an almost fixed structure that's fairly independent from sequence. By contrast, protein molecules perform functions as different as digesting sugars or moving muscles. To perform so many different functions, proteins come in many different structures. The protein function is almost completely dependent on protein structure. Enzymes must recognize and react with their substrates with precise positioning of critical chemical groups in the three-dimensional space. Scaffold proteins must be able to precisely dock other proteins or components and position them in space in the correct fashion. Structural proteins like Collagen must face mechanical stresses and be able to build a regular matrix where cells can adhere and proliferate. Motor proteins must reversibly convert chemical energy in movement, in a precise fashion.
Protein folding depends on sequence
[edit | edit source]As Anfinsen demonstrated in the 1960's, proteins acquire their structure by spontaneous folding of the polypeptide chain into the minimal energy configuration. Most proteins require no external factors in order to fold (although specialized protein exist in cells, called chaperones, that help other, misfolded, proteins acquire their correct structure) — the protein sequence itself uniquely determines the structure. Often the whole process takes place in milliseconds. Despite the apparent chemical simplicity of proteins, the vast number of permutations of twenty amino acids in a linear sequence leads to an amazing number of different protein folds. Nevertheless, protein structures share several characteristics in common: they are almost all built of a few secondary structure elements (short-range structural patterns that are recurrent in protein structures) and even the way these elements combine is often repeated in common motifs. Nonetheless, it is still impossible to know what structure a given protein sequence will yield in solution. This is known as the protein folding problem, and it is one of the most important open problems in modern molecular biology.
Protein denaturation
[edit | edit source]Proteins can lose their structure if put in unsuitable chemical (e.g. high or low pH; high salt concentrations; hydrophobic environment) or physical (e.g. high temperature; high pressure) conditions. This process is called denaturation. Denatured proteins have no defined structure and, especially if concentrated, tend to aggregate into insoluble masses. Protein denaturation is by no means an exotic event: a boiled egg becomes solid just because of denaturation and subsequent aggregation of its proteins. Denatured proteins can sometimes refold when put again in the correct environment, but sometimes the process is irreversible (especially after aggregation: the boiled egg is again an example). It is finally the proteins which are responsible for susceptibility or resistance to a pathogen or parasite.
Proteins can fold into domains
[edit | edit source]A significant number of proteins, especially large proteins, have a structure divided into several independent domains. These domains can often perform specific functions in a protein. For example, a cell membrane receptor might have an extracellular domain to bind a target molecule and an intracellular domain that binds other proteins inside the cell, thereby transducing a signal across the cell membrane.
The domain of a protein is determined by the secondary structure of a protein there are four main types of domain structures: alpha-helix, beta-sheet, beta-turns, and random coil.
The alpha-helix is when the polypeptide chain forms a helix shape with the amino acids side chains sticking out, usually about 10 amino acids long. The alpha-helix gets its strength by forming internal hydrogen bonds, that occur between amino acid 1 and 4 along the length of the helix. A high concentration of Glycine's in a row tend towards the alpha-helix conformation.
The beta-sheet structure is composed of poly-peptide chains stacking forming hydrogen bonds between the sheets. You can form parallel sheets by stacking in the same direction N-C terminal on top of N-C terminal or form anti-parallel by stacking in opposite directions N-C terminal on top of C-N terminal. Beta-turns link two anti-parallel beta strands by a 4 amino acid loop in a defined conformation.
A random coil is a portion of the protein that has no defined secondary structure.
Domains of a protein then come from unique portions of the peptide that are made up of these types of secondary structure.
The chemistry of proteins
[edit | edit source]Amino acid structure and chemistry
[edit | edit source]General features
[edit | edit source]Amino acids consist of a primary amine bound to an aliphatic carbon atom (the so-called α-carbon), which in turn is bound to a carboxylic acid group. At least one hydrogen atom is bound to the α-carbon; in addition, the α-carbon bears a side chain, which is different for different amino acids. In a neutral aqueous solution, amino acids exist in two forms. A very small fraction of amino acid molecules will be neutral, with a deprotonated amino group and a protonated carboxylic acid group. However, the overwhelming majority of molecules will be in a Zwitterion tautomer, with a positive charge on the (protonated) amino group and a negative charge on the (deprotonated) carboxylate group.
Amino acids are linked via a Peptide bond. (From an organic chemistry perspective, a peptide bond is a type of amide group.) A peptide bond consists of a carbonyl group's carbon atom directly bound to the nitrogen atom of a secondary amine. A peptide chain will have an unbound amino group free at one end (called the N-terminus) and a single free carboxylate group at the other end (called the C-terminus).
The peptide bond is planar, because resonance between the carbonyl group and the amino nitrogen lends the C-N bond a partial double-bond character. (It is possible to draw a resonance structure with a double bond between the carbon atom and the nitrogen atom, with a formal negative charge on the oxygen atom and a formal positive charge on the nitrogen.) This prevents rotation around the C-N bond, locking the peptide bond in the trans conformation, and holding six atoms in a plane: the α-carbon of one amino acid, the carbonyl carbon and oxygen atoms, the amino nitrogen and hydrogen atoms, and the &alpha-carbon of the second amino acid are all co-planar.
The structure of a peptide chain's "backbone" can be described uniquely by the torsion angles between adjacent peptide units. The φ-angle is the torsion angle between the α-carbon and the carbonyl carbon of one amino acid; the ψ-angle is the torsion angle between the amino nitrogen and the α-carbon.

Two amino acids with different side chains react when the amino-terminus (red) of one joins the carboxy-terminus (blue) of another are linked by an amide bond (green). See also the mechanism of peptide bond formation.
It is important to note that the formation of this peptide bond is highly unfavorable under standard conditions. However, in the human body, there are enzymes that assist in facilitating this reaction, making peptide bond formation and proteins possible.
Chemical classification of aminoacids
[edit | edit source]The 20 amino acids encoded by the genetic code are:

They are not shown in their zwitterionic state for clarity. At physiological pH (~pH 6.8), all would be so, except proline, which is a five-membered ring. Charged side-chains are shown ionic when they exist as such at physiological pH.
Protein Electrophoresis
[edit | edit source]Protein Electrophoresis is a method in which a mixture of proteins can be separated and analyzed. Electrophoresis is based on the mobility of ions in an electric field. The charge distribution of the molecules is critical in the separation of all electrophoresis. In an electric field, electrophoresis is a passage of charged molecules in solution. Positively charged ions have tendency toward a negative electrode and inversely, negatively charged ions have tendency toward a positive electrode. The molecular weight results to a molecular friction which is directly proportional to the molecular charge and its voltage and inversely proportional to a molecule's mobility in an electric field.
Gel electrophoresis is performed to analyze the molecular weights and the charge of the protein and is mostly used in electrophoresis of the protein. The gel electrophoresis is carried out in a thin piece of polyacrylamide. The crosslinked of acrylamide and N,N'-methylene-bis-acrylamide forms the polyacrylamide by polymerization. The size has an important effect in the movement of the protein molecule. The smaller molecules of protein would result in a faster passage of the molecules through the gel pores.
The separation of the protein molecules in the gel affects the protein activity. In this process, first the protein reduces the disruption of disulfide bonding by heating which results in purification and denaturalization. Next, the sodium dodecyl sulfate, abbreviated as SDS, (and ionic detergent) is added. SDS is an anionic detergent which dissolve hydrophobic molecules and denatures protein molecules without breaking peptide bonds. This result in the dislocation of the structure of the protein changes the secondary, tertiary and quaternary to the primary structure with negative charge. Then the protein is passed through the gel. For denatured proteins, SDS can form a steady charge mass ratio in binding with proteins.
The polyacrylamide gel electrophoresis is a very sensitive method capable of a bearing a high resolution and it is analytically used in the studies in the separation techniques.
Isoelectric point
[edit | edit source]The isoelectric point (pI) is the pH-value in which a protein is neutral, that is, has zero net charge. To be clear, it is not the pH value where a protein has all bases deprotonated and all acids protonated, but rather the value where positive and negative charges cancel out to zero.
Calculating pI: An aminoacid with n ionizable groups with their respective pKa values pK1, pK2, ... pkn will have the pI equal to the average of the group pkas:
pI=(pK1+pK2+...+pkn)/n
Most proteins have many ionizable sidechains in addition to their amino- and carboxy- terminal groups. The pI is different for each protein and it can be theoretically calculated according Henderson-Hasselbalch equation if we know amino acids composition of protein.
In order to experimentally determine a protein's pI 2-Dimensional Electrophoresis (2-DE) can be used. The proteins of a cell lysate are applied to a pH immobilized gradient strip, upon electrophoresis the proteins migrate to their pI within the strip. The second dimension of 2-DE is the separation of proteins by MW using a SDS-gel. To clearly understand isoelectric point, you have to keep in mind that the positively charged groups are balanced by the negatively charged groups. For simple amino acid " alanine", the isoelectric point is an average of the PKa of the carboxyl with PK1 of (2.34) and ammonium with PK2 of (9.69) groups. So, the PI for the simple amino acid " alanine" is calculated as:(2.34+9.69)/2 which is equal to 6.02. When additional basic or acidic groups are added as a side-chain functions, the isoelectric point pI will be the average of the pKa's of the most similar acids. Example for this concept could be aspartic acid in which the similar acids are alpha-carboxyl function with pKa of 2.1 and the side chain carboxyl function with a pKa of 3.9. Thus, the pI for aspartic acid is (2.1+3.9)/2=3.0. Another example is arginine, its similar acids are guanidinium on the side chain with pKa of 12.5 and the alpha-ammonium function with pKa of 9.0. Thus the calculated pI for arginine= (12.5+9.0)/2=10.75. pI does not has a unite.
The peptidic bond
[edit | edit source]Two amino acid molecules can be covalently joined through a substituted amide linkage, termed a peptide bond, to yield a dipeptide. this link is formed by dehydration (removal of the water molecules - one hydrogen atom from one amino acid and an OH group from the other). This process can then continue to join other amino acids and yield in an amino acid chain. When there are few amino acids in a chain, it is called an oligopeptide, when there are many it is called a polypeptide. although the terms "protein" and "polypeptide" are sometimes used to describe the same thing, the term polypeptide is generally used when the molecular weight of the chain is below 10,000. An amino acid unit in a peptide is often called a residue.
Disulfide bonds
[edit | edit source]Disulfide bonds form between the sulfur atoms of two cysteine side chains in a protein. The side chains undergo a reversible oxidation of the sulfhydryl groups of the cysteine, which results in covalent bonding of the sulfur atoms (S-S). This bonding is called a "disulfide bridge". Typically, disulfides don't form on the surface of proteins because of the presence of reducing agents in the cytoplasm. These bonds are of great importance concerning the shaping of protein structure; their formation guides the folding of peptide chains as the proteins are produced. Structural proteins that have to be rigorously stable (for example, Keratin, which is found in nail, horn and crustacean shell) often contain a large number of disulfide bonds.

Post-translational modifications
[edit | edit source]After a protein is synthesized inside the cell, it is usually modified by the addition of extra functional groups to the polypeptide chain. These can be sugar or phosphate groups and may confer to the protein special functions such as: the ability to recognize other molecules, to integrate in the plasma membrane, to catalyze biochemical reactions, and various other processes. It is in the interest of the biochemist to understand what proteins are modified, what the modification is, and where it is located. An easy way to do this is by using mass spectrometry. In a sample of protein submitted to mass spectrometry you will see both modified and unmodified protein signals. The change in mass between these signals will correspond to the change in mass of your protein due to your post-translation modification.
Protein structure and folding
[edit | edit source]What is protein folding?
[edit | edit source]Protein folding is commonly a fast or very fast process, often but not always reversible, taking no more than a few milliseconds to occur. It can be viewed as a complex compromise between the different chemical interactions that can happen between the amino acid sidechains, the amidic backbone and the solvent. There are literally millions of possible three-dimensional configurations, often with minimal energetic differences between them. That's why we're still almost unable to predict the folding of a given polypeptide chain ab initio.Protein folding problem is that scientist still has failed to crack the code that governs folding. Moreover, the ability of biological polymers such as protein fold into well-defined structures is remarkable thermodynamically. An unfolded polymer exists are random coils, each copy of an unfolded polymers will have different conformation, yielding a mixture of many possible conformation.
Folding depends only on primary structure
[edit | edit source]In 1954 Christian Anfinsen demonstrated that the folding of a protein in a given environment depends only on its primary structure - the amino acid sequence. This conclusion was by no means obvious, given the complexity of the folding process and the paucity of biochemical knowledge at the time. The process of folding often begins co-translationally, so that the N-terminus of the protein begins to fold while the C-terminal portion of the protein is still being synthesized by the ribosome. Specialized proteins called chaperones assist in the folding of other proteins. Meanwhile, protein folding is a thermodynamically driven process: that is, proteins fold by reaching their thermodynamically most stable structure. The path followed by the protein in the potential energy landscape is far from obvious, however. Many local and non-local interactions take part in the process, and the space of possible structures is enormous. As of today molecular dynamics simulations are giving invaluable hints on the first stages of the folding process. It is known now that the unfolded state still retains key long-range interactions and that the local propensity of the sequence to fold in a given secondary structure element narrow the "search" in the so-called conformational space. This seems to mean that biological proteins somehow evolved to properly fold. In fact, many random amino acid sequences only acquire ill-defined structures (molten globules) or no structure at all.
There are some general rules, however. Hydrophobic amino acids will tend to be kept inside the structure, with little or no contact with the surrounding water; conversely, polar or charged amino acids will be often exposed to solvent. Very long proteins will often fold in various distinct modules, instead of in a single large structure.
The Ramachandran plot
[edit | edit source]The Ramachandran plot was invented by professor G.N.Ramachandran, a very eminent scientist from India. He discovered the triple helix structure of collagen in 1954 a year after the double helix structure was put forth. In a polypeptide the main chain N-Calpha and Calpha-C bonds relatively are free to rotate. These rotations are represented by the torsion angles phi and psi, respectively.
G N Ramachandran used computer models of small polypeptides to systematically vary phi and psi with the objective of finding stable conformations. For each conformation, the structure was examined for close contacts between atoms. Atoms were treated as hard spheres with dimensions corresponding to their van der Waals radii. Therefore, phi and psi angles which cause spheres to collide correspond to sterically disallowed conformations of the polypeptide backbone
Intramolecular forces in protein folding
[edit | edit source]The tertiary structure is held together by hydrogen bonds, hydrophilic interactions, ionic interactions, and/or disulfide bonds.
The protein folding problem
[edit | edit source]The protein folding problem relates to what is known as the Levinthal paradox. Levinthal calculated that if a fairly small protein is composed of 100 amino acids and each amino acid residue has only 3 possible conformations (an underestimate) then the entire protein can fold into 3100-1 or 5x1047 possible conformations. Even if it takes only 10-13 of a second to try each conformation it would take 1027 years to try them all. Obviously a protein doesn't take that long to fold, so randomly trying out all possible conformations is not the way proteins fold. Since most proteins fold on a timescale of the order of milliseconds it is clear that the process is directed in some manner dependent on the constituents of the chain. The protein folding problem which has perplexed scientists for over thirty years is that of understanding how the tertiary structure of a protein is related to its primary structure, because it has been proven that the primary structure of a protein holds the only information necessary for the protein to fold. Ultimately the aim is also to be able to predict what pathway the protein will take.
Folding in extreme environments
[edit | edit source]Most proteins are not capable of maintaining their three-dimensional shape when they are exposed to environmental extremes such as a low or high pH, or a highly variable temperature.
Changes in the pH of the proteins environment may alter the charges on the amino acid side chains that form the whole protein, so that repulsive or attractive forces may form, altering the secondary and tertiary structure of the protein as a whole, as a result the shape of the enzyme is warped, and the now non-functional protein is said to be denatured.
A high or exceptionally low temperature can cause the constitutive bonds on the protein to be broken, again resulting in the protein being rendered non-functional.
It is important to note that certain proteins, mainly digestive enzymes such as trypsin, are capable of with-standing a pH as low as 1. If the pH of such an enzymes environment were to increase to approximately pH5, it would be inactivated.
Protein misfolding
[edit | edit source]The way that a protein folds is one of the most important factors influencing its properties, as this is what determines which active groups are exposed for interaction. If the protein misfolds, its properties can be markedly changed. One example of this is in Transmissible Spongiform Encephalopathies, such as BSE, and Scrapie. In these, the prion protein, which is involved in the brain's copper metabolism, misfolds, and starts forming plaques, which destroy brain tissue.
Protein structural levels
[edit | edit source]Biochemists refer to four distinct aspects of a protein's structure:
Primary structure
[edit | edit source]Primary structure is practically a synonym of the amino acid sequence. It can also contain informations on amino acids linked by peptide bonds. Primary structure is typically written as a string of three letter sequences, each representing an amino acid. Peptides and proteins must have the correct sequence of amino acids.
Secondary structure
[edit | edit source]Secondary structure elements are elementary structural patterns that are present in most,if not all,known proteins. These are highly patterned sub-structures --alpha helix and beta sheet-- consisting of loops between elements or segments of polypeptide chain that assume no stable shape. Secondary structure elements, when mapped on the sequence and depicted in the relative position they have in respect to each other, define the topology of the protein. It is also relevant to note that hydrogen bonding between residues is the cause for secondary structure features; secondary structure is usually described to beginning biochemists as (almost) entirely independent of residue side-chain interactions.
Tertiary structure
[edit | edit source]Tertiary structure is the name given to refer to the overall shape of a single protein molecule. Although tertiary structure is sometimes described (especially to beginning biology and biochemistry students) as being a result of interactions between amino acid residue side chains, a more correct understanding of tertiary structure is the interactions between elements of secondary protein structure, i.e. alpha-helices and beta-pleated sheets. Tertiary structure is often referred to as the "fold structure" of a protein, since it is the result of the complex three-dimensional interplay of other structural and environmental elements.
Super-tertiary structure (protein modules)
[edit | edit source]Some literature refers to elements of super-tertiary structure, which often refers to elements of folding that, for whatever reason, do not neatly fit into the category of tertiary structure. Often this level of distinction is saved for graduate level coursework. Protein denaturation can be a reversible or an irreversible process, i.e., it may be possible or impossible to make the protein regain its original spatial conformation.
Quaternary structure
[edit | edit source]Quaternary structure is the shape or structure that results from the union of more than one protein molecule, usually called subunit proteins subunits in this context, which function as part of the larger assembly or protein complex.
And it refers to the regular association of two or more polypeptide chains to form a complex. A multi-subunit protein may be composed of two or more identical polypeptides, or it may include different polypeptides.
Quaternary structure tends to be stabilized mainly by weak interactions between residues exposed on surfaces polypeptides within a complex.
Secondary structure elements
[edit | edit source]The alpha helix
[edit | edit source]
The alpha helix is a periodic structure formed when main-chain atoms from residues spaced four residues apart hydrogen bond with one another. This gives rise to a helical structure, which in natural proteins is always right-handed. Each turn of the helix comprises 3.6 amino acids. Alpha helices are stiff, rod-like structures which are found in many unrelated proteins. One feature of these structures is that they tend to show a bias in the distribution of hydrophobic residues such that they tend to occur primarily on one face of the helix.
The amino acids in an α helix are arranged in a helical structure, about 5 Å wide. Each amino acid results in a 100° turn in the helix, and corresponds to a translation of 1.5Å along the helical axis. The helix is tightly packed; there is almost no free space within the helix. All amino acid side-chains are arranged at the outside of the helix. The N-H group of amino acid (n) can establish a hydrogen bond with the C=O group of amino acid (n+4).
Short polypeptides usually are not able to adopt the alpha helical structure, since the entropic cost associated with the folding of the polypeptide chain is too high. Some amino acids (called helix breakers) like proline will disrupt the helical structure.
Ordinarily, a helix has a buildup of positive charge at the N-terminal end and negative charge at the C-terminal end which is a destabilizing influence. As a result, α helices are often capped at the N-terminal end by a negatively charged amino acid (like glutamic acid) in order to stabilize the helix dipole. Less common (and less effective) is C-terminal capping with a positively charged protein like lysine.
α helices have particular significance in DNA binding motifs, including helix-turn-helix motifs, leucine zipper motifs and zinc finger motifs. This is because of the structural coincidence of the α helix diameter of 12Å being the same as the width of the major groove in B-form DNA.
α helices are one of the basic structural elements in proteins, together with beta sheets.
The peptide backbone of an α helix has 3.6 amino acids per turn.
The beta sheet
[edit | edit source]
The β sheet (also β-pleated sheet) is a commonly occurring form of regular secondary structure in proteins, first proposed by Linus Pauling and Robert Corey in 1951. It consists of two or more amino acid sequences within the same protein that are arranged adjacently and in parallel, but with alternating orientation such that hydrogen bonds can form between the two strands. The amino acid chain is almost fully extended throughout a β strand, lessening the probability of bulky steric clashes. The Ramachandran plot shows optimal conformation with angle phi = -120 to -60 degrees and angle psi = 120 to 160 degrees. The N-H groups in the backbone of one strand establish hydrogen bonds with the C=O groups in the backbone of the adjacent, parallel strand(s). The cumulative effect of multiple such hydrogen bonds arranged in this way contributes to the sheet's stability and structural rigidity and integrity: for example, cellulose's beta-1,4 glucose structure. The side chains from the amino acid residues found in a β sheet structure may also be arranged such that many of the adjacent side chains on one side of the sheet are hydrophobic, while many of those adjacent to each other on the alternate side of the sheet are polar or charged (hydrophilic). Some sequences involved in a β sheet, when traced along the backbone, take a hairpin turn in orientation (direction), sometimes through one or more prolines. The α-C atoms of adjacent strands stand 3.5Å apart. In addition to the parallel beta sheet, there is also the anti-parallel beta sheet. The hydrogen-bond still exists in this conformation but the main difference lies in the directionality of the protein. In this conformation the proteins run in opposite directions, but the resulting hydrogen bonds connect directly across from one another instead of the diagonal. In short, beta sheets can be purely parallel, anti-parallel, or even mixed.
The random coil
[edit | edit source]A protein that completely lacks secondary structure is a random coil. In random coil, the only fixed relationship between amino acids is that between adjacent residues through the peptide bond. As a result, random coil can be detected from the absence of the signals in a multidimensional nuclear magnetic resonance experiment that depend on particular peptide-peptide interactions. Likewise in the images produced in crystallography experiments, pieces of random coil appear simply as an absence of "electron density" or contrast. Random coil is also easily distinguished by circular dichroism. Denaturing reduces a protein entirely to random coil.
Less common secondary structure elements
[edit | edit source]Certain other periodic structures rarely appear in proteins, some of which are similar to the more common types. For example, two variants of the alpha-helix also occur, the 3-10 helix and the pi helix. These have helical pitches of 3 and 4.4 residues per turn respectively, corresponding to hydrogen bonds forming between residue i and i+3 for the 3-10 helix and between i and i+5 for the pi helix. Both are usually very short (1 turn or so) and have been seen only at the ends of alpha helices.
Tertiary structure elements
[edit | edit source]Alpha-only structures
[edit | edit source]Structures that contain only Alpha Helices
Beta-only structures
[edit | edit source]Common folds and modules
[edit | edit source]The Rossman fold
[edit | edit source]The Rossmann fold is a protein structural motif found in proteins that bind nucleotides, especially the cofactor NAD. The structure is composed of three or more parallel beta strands linked by two alpha helices in the topological order beta-alpha-beta-alpha-beta. Because each Rossmann fold can bind one nucleotide, binding domains for dinucleotides such as NAD consist of two paired Rossmann folds that each bind one nucleotide moiety of the cofactor molecule. Single Rossmann folds can bind mononucleotides such as the cofactor FMN.
The motif is named for Michael Rossmann who first pointed out that this was a frequently occurring motif in nucleotide binding proteins.
The hemoglobin fold
[edit | edit source]The immunoglobulin fold
[edit | edit source]Keratin
[edit | edit source]Found in hair and in the palms of human hands.
Collagen
[edit | edit source]Types of protein
[edit | edit source]Biochemistry/Proteins/Types of protein
Carbohydrates
[edit | edit source]Introduction
[edit | edit source]"Carbohydrates" are chemically defined as "polyhydroxy aldehyde or polyhydroxy ketones or complex substances which on hydrolysis yield polyhydroxy aldehyde or polyhydroxy ketone." Carbohydrates are one of the fundamental classes of macromolecules found in biology. Carbohydrates are commonly found in most organisms, and play important roles in organism structure, and are a primary energy source for animals and plants. Most carbohydrates are sugars or composed mainly of sugars. By far, the most common carbohydrate found in nature is glucose, which plays a major role in cellular respiration and photosynthesis. Some carbohydrates are for structural purposes, such as cellulose (which composes plants' cell walls) and chitin (a major component of insect exoskeletons). However, the majority of carbohydrates are used for energy purposes, especially in animals. Carbohydrates are made up of a 1:2:1 ratio of Carbon, Hydrogen, and Oxygen (CH2O)n
Simple Carbohydrates (Monosaccharides)
[edit | edit source]These are used only for energy in living organisms. Simple carbohydrates are also known as "Monosaccharides".The chemical formula for all the monosaccharides is CnH2nOn. They are all structural isomers of each other. There are two main types of monosaccharides. The first type are aldoses, containing an aldehyde on the first carbon, and the second type are ketoses, which have a ketone on the second carbon (This carbonyl group is always located on the second carbon).
Name Formula Aldoses Ketoses Trioses C3 H6 O3 Glycerose Dihydroxyacetone Tetroses C4 H8 O4 Erythrose Erythrulose Pentoses C5 H10 O5 Ribose Ribulose Hexoses C6 H12 O6 Glucose Fructose Heptose C7 H14 O7 Glucoheptose Sedoheptulose
The suffix -oses is kept for the aldoses & the suffix -uloses is kept for the ketoses except fructose. Ketoses are as common as aldoses. The most abundant monosaccharide in nature is the 6-Carbon sugar -i.e.D-Glucose. All aldoses are reducing sugars. Many ketoses are also considered reducing sugars because they can isomerise to aldoses.
Monomers
[edit | edit source]There are two main forms of monomers, aldoses and ketoses, of which, all have the same backbone. The simplest form of monomers are trioses. The trioses consist of three carbons in the backbone.
Fructose
[edit | edit source]Fructose is a ketohexose with the molecular formula of C6H12O6 ; which is same as the molecular formula of Glucose but different structure. The structure of fructose differs from glucose at carbon 1 and 2 by the location of the carbonyl group. Fructose is the sweetest naturally occurring sugar. Fructose is also called levulose and fruit sugar; fructose is also found in fruits, root vegetables(such as sweet potato and onion) and honey. It is a isomer of glucose and a ketose simple sugar. Fructose has the highest solubility among all sugars. Fructose can be converted to its isomer glucose, after it enters the blood stream.
CH2OH
C=O
OH-C-H
H-C-OH
H-C-OH
CH2OH
Glucose
[edit | edit source]The hexoses glucose, galactose, and fructose are important monosaccharides. Glucose is the most prevalent monosaccharide in diet. The most common hexose, D-glucose, C6H12O6 also known as dextrose and blood sugar, is found in fruits, vegetables, corn syrup, and honey. Glucose is a building block of the disaccharides(sucrose,maltose,lactose) and polysaccharides (glycogen,cellulose,starch). In the body, excess glucose is converted to glycogen and then stored in the muscle and liver.
CHO
H-C-OH
OH-C-H
H-C-OH
H-C-OH
CH2OH
Galactose
[edit | edit source]Galactose is a sugar component of the disaccharide lactose, as found in milk. It is not as sweet as glucose and is separated from the glucose in lactose via hydrolysis.In addition, galactose is an aldohexose that does not occur in the free form in nature; galactose has an important role in the cellular membrane of the brain and nervous system. D-galactose has a structure similar to D-glucose and the only difference between them is in the arrangement of the –OH group on carbon number 4. Galactose can be found in human breast milk and is incorporated into the structure of Human Milk Oligosaccharides. The backbone of Human Milk Oligosaccharides is the disaccharide lactose, which is formed by the linkage between galactose and glucose sugars..
Oligosachharides
Tha oligosachharides yields 2 to 10 monosachharides on hydrolysis. Disachharides are most common oligosachharide found in nature.
Disaccharides
[edit | edit source]Monosaccharides are simple forms of sugars consisting of one sugar, disaccharides on the other hand, consists of two. The two sugars are bonded together via a glycosidic bond. Most linkages between sugars occur between the first and fourth carbon on the sugars.
Polysaccharides
[edit | edit source]Sugars do not stop at disaccharides, they are much more complex than that. Multiple sugars are linked together forming many polysaccharides. Polysaccharides are made up of monosaccharides linked together.
Compound Carbohydrates (Disaccharides)
[edit | edit source]These are used by living organisms for energy. They are composed of two monosaccharides joined together by the process known as dehydration synthesis. In this process, one molecule loses one hydrogen atom, while the other loses one hydrogen atom and one oxygen atom. The reverse of this is hydrolysis, where water is added to break down a molecule into two or more simpler molecules. Disaccharides have the chemical equation C12H22O11. The reason it does not follow the 1:2:1 ratio is, obviously, due to the H2O taken way from it. Some examples of disaccharides are:
Disachharides
Non reducing reducing
C1-C1 glycosidic C1-C2 glycosidic C1-C4 glycosidic C1-C6 glycosidic
linkage linkage linkage linkage
Trehalose Sucrose Lactose Gentiobiose
Maltose Melibiose
Cellobiose Isomaltose
Maltose
[edit | edit source]- Chemistry-
Maltose is a white crystal sugar, also known as malt sugar and a reducing disaccharide made from two glucose units. The bonding of two glucose units is called 1-4 glycosidic linkage which joins the carbon number 1 of one glucose to carbon number 4 of the second glucose.In the presence of enzyme maltase,1-4 linkage of two glucose is broken down and maltose is hydrolized into glucose
- occurrence-
Maltose is present in sprouting barley. It is the major product of hydrolysis of starch.
-
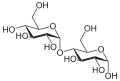 alpha - maltose
alpha - maltose -
 beta - maltose
beta - maltose


Sucrose
[edit | edit source]3Occurrence- It is the costituent of sugarcane. it is also found in Beet,carrot, etc. Nectar of flower is particularly rich in sucrose. 3Chemistry- Sucrose is white crystal sugar.When heated above its melting point it forms a brown substance known as "Caramel". it is non reducing sugar. Sucrose is formed by the C1-C2 glucosidic bond between glucose & fructose. Sucrose on hydrolysis yield equimolar mixture of glucose & fructose which is offen called as "invert sugar" by the "enzyme".


Lactose
[edit | edit source]3 Occurrence- It is found in milk of animal. It is also "Milk sugar". The percentage of lactose in human milk is 6.8 % & in cow milk is 4.8 % 3 Chemistry- Lactose is made by the C1-C4 glycosidic bond between galactose & glucose. The hydrolysis of Lactose gives the monosacchride: glucose + glactose by the enzyme lactase. Lactose can be a reducing sugar.
-
 β-D-galactopyranosyl-(1→4)-D-glucose
β-D-galactopyranosyl-(1→4)-D-glucose -
 The molecular structure of α-lactose, as determined by X-ray crystallography.
The molecular structure of α-lactose, as determined by X-ray crystallography.

Complex Carbohydrates (Polysaccharides)
[edit | edit source]Polysaccharides, also called as glycanes, are high molecular weight which on hydrolysis yield monosaccharides. Some sources of complex carbohydrates are pasta, bread, rice, cereals, crackers, corn, beans, potatoes, pumpkin, and peas. Digestion of complex carbohydrates could take more time because digestive enzyme have to work harder to break down the chain into individual sugars. Complex carbohydrates contain hundreds of sugar units. Studies show that glucose levels both rise and fall more slowly after the consumption of bread compared to sugars or fruit, suggesting slower digestion.[1] Both monosaccharides and disaccharides are used only for energy. Another difference is that while monosaccharides and disaccharides can be used for energy immediately, polysaccharides release their energy slowly. Research shows that the carbohydrate oxidation rate rises more slowly after the consumption of bread rather than sucrose following an overnight fast. The carbohydrate oxidation rate is also lower over a six-hour period following the consumption of bread in lieu of sucrose.[2] Chemically , the polysaccharide may be distinguished into homopolysachharide & heteropolysachharide. Homopolysachharides which on hydrolysis yield only single monosachharide. Eg. starch, cellulose, etc. Hateropolysachharide which on hydrolysis yield two or more monosaccharide. Eg. heparin, chondroitin, etc.
POLYSACHHARIDE
Homopolysachharide Heteropolysachharide
Starch Mucopolysachharids
Glucogen Chondroitin
Inulin Hyaluronic acid
Cellulose Keratosulfate
Pectin Heparin
Chitin Vegetable gum
Xylan Agar agar
polysachharide may be classified on the basis of functional aspect as Nutritive & Structural. Nutritive- starch,glycogen,inulin etc. Structural- cellulose,chitin,pectin,etc.
Cellulose (Fiber)
[edit | edit source]Cellulose is a special kind of carbohydrate. It is insoluble and most organisms can not produce enzymes to break it down. It is made by β-D-glucose. It is found only in plants, and it's found in the cell wall. It is composed of β glucose molecules, which create a more rigid structure. Cotton used to make clothes etc. is cellulose from around the seeds of the cotton plant. Fibre helps the plant keep a strong structure. Humans can't digest fibre.it gives no color with iodine.It is completely absent in meat, egg, fish & milk.
Starch
[edit | edit source]Starch is the energy storage molecule of plants.It is formed by long chains of α glucose molecules linked together. It is mostly found in potato. Starch is actually a mixture of 2 types of molecules, amylose and amylopectin. These large polysaccharides are very good for energy storage because they have lots of glucose molecules crammed into a small space which can then be easily broken off, one at a time, by hydrolysis and then used for energy. It is hydrolysed by enzyme Amylase.It is non reducinh sugar. It gives blue, purple colour with iodine
Glycogen
[edit | edit source]Glycogen is the energy storage molecule of animals. It is formed by branched chains of alpha glucose molecules with 1-4 glycosidic bonds on the main chains and 1-6 glycosidic bonds to form the branches. Humans store small amounts of glycogen in the liver and muscles. It is created when there are high blood sugar levels. The pancreas secretes insulin, which stimulates the creation of glycogen from glucose and signals the body to use glucose as its main form of energy. It is non reducing sugar. It gives red colour with iodine.
References
[edit | edit source]- ↑ Wolever, Thomas M. S. (2006), The Glycaemic Index: A Physiological Classification of Dietary Carbohydrate, CABI, pg. 65, ISBN 9781845930516. “Indeed, blood glucose responses elicited by pure sugars and fruits suggest rapid absorption because the blood glucose concentration rises more quickly and falls more rapidly than after bread (Wolever et al., 1993; Lee and Wolever, 1998).”
- ↑ Daly ME, Vale C, Walker M, Littlefield A, Alberti KG, Mathers JC (2000). "Acute fuel selection in response to high-sucrose and high-starch meals in healthy men." Am J Clin Nutr 71, 1516-1524. See Figure 1.
n.p. Carbohydrates Notes. n.d. www.chem.ucla.edu/harding/notes/notes_14C_carbos.pdf
Membranes and Lipids
[edit | edit source]
Membranes And Lipids
[edit | edit source]All cells, from simple prokaryotic bacteria to complex multicellular organisms are surrounded by a membrane. The membrane acts as a selective barrier, letting some substances into the cell and preventing other substances from entering. The membrane also actively transports substances between the inside and outside of the cell, using cellular energy to do so. This is important in regulating the concentration of many substances which must be maintained within strict limits. The cell also contains membrane bound compartments, where the membrane acts as a barrier for the separation of different environments, like lysosomes which have a high pH that would be toxic to the rest of the cell. This chapter is about the chemical composition of the membrane and how this creates the functionality of the membrane.
The Lipid Bilayer
[edit | edit source]The first person to link lipids with the cell membrane may have been Charles Ernest Overton, who was studying heredity in plants. Part of his studies involved studying which substances absorbed into plant cells most quickly. After characterizing a large number of substances, he came up with the idea that cell membranes were composed of something similar to the lipids found in vegetable oils, and that substances are absorbed into the cells by dissolving through the membrane.
The next big step came when Gorter and Grendel extracted the lipids from red blood cells and compared the surface area of the lipids spread out on water compared to the surface area of the red blood cells. They found the lipid surface area was twice that of the red blood cells, and concluded that the lipids must be arranged in a layer two lipid molecules thick. This is what biologists now call the lipid bilayer, and to understand the construction of the bilayer, we need to understand the lipids themselves.
Fatty Acids
[edit | edit source]A fatty acid is simply a linear carbon chain with a carboxylic acid group at one end.
Fatty acids usually have between 14 and 24 carbon atoms and may have one or more double bonds. These double bonds are almost always in the cis configuration.
 Fatty acids have both common names and systematic names. The systematic name is based on the alkane or alkene with the same number of carbon atoms, with the final e of the hydrocarbon replaced with oic acid. For example Laurate (Figure x)
Fatty acids have both common names and systematic names. The systematic name is based on the alkane or alkene with the same number of carbon atoms, with the final e of the hydrocarbon replaced with oic acid. For example Laurate (Figure x) ![]() is a fatty acid with 12 carbon atoms and no double bonds, so the systematic name is dodecanoic acid, and the ionized form is dodecanoate.
(saturated fatty acid table)
If there are double bonds, the location is marked with the symbol Δ with a superscript number indicating the location of the double bond and preceded by cis or trans to indicate configuration (but almost invariably cis in natural fatty acids). Carbon atoms are counted from the carboxyl end, as in Figure x, so a dodecenoate acid with a cis double bond between carbon atoms 9 and 10 would be: cis-Δ9-dodecenoate.
is a fatty acid with 12 carbon atoms and no double bonds, so the systematic name is dodecanoic acid, and the ionized form is dodecanoate.
(saturated fatty acid table)
If there are double bonds, the location is marked with the symbol Δ with a superscript number indicating the location of the double bond and preceded by cis or trans to indicate configuration (but almost invariably cis in natural fatty acids). Carbon atoms are counted from the carboxyl end, as in Figure x, so a dodecenoate acid with a cis double bond between carbon atoms 9 and 10 would be: cis-Δ9-dodecenoate.
The number 2, 3 and last carbon atom are called the α, β and ω atoms, respectively.
One common shorthand for describing fatty acids is based on the fact that multiple double bonds are placed three bonds apart. This allows the acid to be described by the length of its carbon chain, number of double bonds, and location of the final double bond, relative to the ω carbon.
Under this system, for instance, Docosahexaenoic Acid (DHA),a very important constituent of membranes in the brain and eyes, can by listed as 22:6 ω-3.
This corresponds to:
22 carbons and 6 double bonds, of which the final double bond is at ω-3.
This is equivalent to 22:6 Δ4, 7, 10, 13, 16, 19, or, in its full IUPAC form, cis-docosa - 4, 7, 10, 13, 16, 19 - hexaenoic acid.
Phosphoglycerides
[edit | edit source]Phosphoglycerides are composed of a glycerol back bone with substituents in the following arrangements:
- Hydroxyl #1 of glycerol is usually esterified to a saturated fatty acid
- Hydroxyl #2 of glycerol is usually esterified to an unsaturated fatty acid
- Hydroxyl #3 of glycerol is esterified to a phosphate group
 The simplest phosphoglyceride is phosphatidate (picture). Other phosphoglycerides can be made when a group with a hydroxyl is esterified to the phosphate group of phosphatidate. There are four common substituents for phosphatidate. Serine, ethanolamine and choline are structurally similar, while inositol is different:
The simplest phosphoglyceride is phosphatidate (picture). Other phosphoglycerides can be made when a group with a hydroxyl is esterified to the phosphate group of phosphatidate. There are four common substituents for phosphatidate. Serine, ethanolamine and choline are structurally similar, while inositol is different:


When the fatty acid esterified to hydroxyl #2 is a cis- configured polyunsaturated fatty acid (i.e. one with more than one double bond), it tends to curl, and thus prevents the molecules from packing so closely together in a membrane. This makes the membrane more flexible.
Sphingolipids
[edit | edit source]Sphingolipids', have the same overall shape as phosphoglycerides but have different chemistry, using sphingosine in place of glycerol. Sphingosine has a long hydrocarbon tail similar to fatty acids attached to a structure that is similar to the amino acid serine. A fatty acid can attach to the amine group, and a "head" group can attach to a hydroxyl (see Figure x). Sphingolipids are named according to this head group:
- If there is no head group it is called a ceramide
- If the head group is phosphate and choline, it is called sphingomyelin
- If the head group is a sugar, it is called a glycosphingolipid (or a glycolipid)
The majority of sphingolipids are of the third type, glycosphingolipids. It is thought they have functions in cell recognition and protection in addition to their structural role in the membrane.
Sphingolipids are known to regulate activity in cells, such as immune responses, production of cells, and development of specialized cells. Although these are under the spatial and temporal control, it was recently discovered that sphingosine kinases will be focused on therapeutic effects on enzymes for people with cancer and other conditions.
-
 General structures of sphingolipids
General structures of sphingolipids

Formation Of The Bilayer
[edit | edit source]If we compare the structures of phosphoglycerides and sphingolipids, we see that they are very similar compounds. Each lipid has two long hydrophobic hydrocarbon "tails" and a single polar "head". Since the molecule has both polar and nonpolar moieties, it is said to be amphipathic. It is the amphipathic nature of these molecules that causes them to form bilayers, mediated by four forces:
- The hydrophobic effect- this causes the hydrophobic tails to come together. This is the strongest force driving the formation of the bilayer. It is a consequence of the increased entropy in water molecules when non polar substances are aggregated in water.
- Van der Waals forces between the hydrophobic tails.
- Electrostatic forces of the head groups.
- Hydrogen bonds between the head groups.
One possible structure that satisfies the above forces is called a micelle (pictures). This is common with free fatty acids, but not with most phosphoglycerides and sphingolipids because these groups have twice as many acyl chains per head than the fatty acid (picture), and it is difficult to pack them all into the center of the micelle. Phospholipids and sphingolipids more often form a bilayer in a sheet or a sphere (picture). This is the so called lipid bilayer.
Lipid Motion
[edit | edit source]Studying Motion
[edit | edit source]NMR, ESR, X-Ray, Differential scanning calorimetry
FRAP is a good way to measure diffusion of receptors through a lipid membrane after tagging the protein of interest with a GFP construct
Intramolecular Motion
[edit | edit source]There are three basic kinds of motion within the lipid molecules: stretching between bonds, rotating between bonds, and wagging between bonds (?). [picture] 99% of motion within liquid crystal is due to rotation about carbon-carbon bonds. Unsaturated fatty acids of membrane lipids rotate more often. This is because of the packed arrangement of the lipid bilayer. When there is rotation about one bond, an adjacent bond rotates to compensate for steric clashes [pictures]. Since double bonds in fatty acids are nearly always cis, they introduce kinks in the fatty acid. When a bond adjacent to a double bond rotates, the other bond adjacent to the double bond also rotates, and the whole thing moves like an old fashioned bit and brace [pictures]. It takes more energy to rotate the double bonds closer to the head groups due to [angle thing picture]. Double bonds react with O2 readily and create poisons [more] bacteria have [cyclopropane picture].
Types of Membrane Protein Diffusion
[edit | edit source]Rotational
Lateral
Liquid crystal
Flip Flop
Plasma Membrane Function
[edit | edit source]Barrier
[edit | edit source]Interior of cell is separated from surrounding environment. to keep undesirable substances out keep desirable substances in intracellulat membranes:act to compartmentalize functions within eukaryotic cells(ex:mitochondria,chloroplast)
Transport Regulation
[edit | edit source]The lipid membrane is impermeable to many essential nutrients to the cell, such as glucose. In order to get the proper nutrients into the cell protein transporters are constantly moving through the membrane. For the example of glucose, there are several isoforms of the glucose transporter, some of which are specific for only certain types of cells. One of the more interesting transporter is the water transporter: aquaporins. Even though water can get through the membrane, at times the cell needs more water than can be provided through diffusion.
Cell Communication
[edit | edit source]Gap junctions are channels found between cells that allow for the cytoplasm to exchange between the cells. This is how very fast signalling can occur by cells close together.
Cell Adhesion
[edit | edit source]Several classes of proteins are responsible for cells sticking together: Cadherins
Summary
[edit | edit source]Lipids and the Plasma Membrane
[edit | edit source]Membranes And Lipids
[edit | edit source]All cells, from simple prokaryotic bacteria to complex multicellular organisms are surrounded by a membrane. The membrane acts as a selective barrier, letting some substances into the cell and preventing other substances from entering,and it also actively transports substances between the inside and outside of the cell, using cellular energy to do so. This is important in regulating the concentration of many substances which must be maintained within strict limits. The cell also contains membrane bound compartments, where the membrane acts as a barrier for the separation of different environments, like lysosomes which have a high pH that would be toxic to the rest of the cell. Furthermore, lipids are polar molecules that are generally soluble in organic solvents due to large number of nonpolar bonds in lipids. Their ability to form membranes are as a result of their hydrophobic properties, which is contributed by their fatty acids. Membranes are amphipatic.
The Lipid Bilayer
[edit | edit source]The first person to link lipids with the cell membrane may have been Charles Ernest Overton, who was studying heredity in plants. Part of his studies involved studying which substances absorbed into plant cells most quickly. After characterizing a large number of substances, he came up with the idea that cell membranes were composed of something similar to the lipids found in vegetable oils, and that substances are absorbed into the cells by dissolving through the membrane.
The next big step came when Gorter and Grendel extracted the lipids from red blood cells and compared the surface area of the lipids spread out on water compared to the surface area of the red blood cells. They found the lipid surface area was twice that of the red blood cells, and concluded that the lipids must be arranged in a layer two lipid molecules thick. Lipid bilayer is a double layer membrane formed from phospholipids. Phospholipids are composed of a polar head group and non-polar fatty acid tails. The arrangement of the phospholipids makes the cell membrane permeable.
Fatty Acids
[edit | edit source]A fatty acid is a linear of carboxylic acid with a long hydrocarbon chain. In fatty acids, the non-polar hydrocarbon chain gives the molecule a non- polar character
Fatty acids usually have between 14 and 24 carbon atoms and their carbon chain may have one or more double bonds. In naturally occurring fatty acids, these double bonds are mostly in cis configuration.
Fatty acids have both common names and systematic names. The systematic name is based on the alkane or alkene with the same number of carbon atoms, with the final e of the hydrocarbon replaced with oic acid, if the carbon chain of the fatty acid is saturated (without double bond in its carbon chain), and "enoic acid" if there is double in its carbon chain. For example Laurate (Figure x) ![]() is a fatty acid with 12 carbon atoms and no double bonds, so the systematic name is dodecanoic acid, and the ionized form is dodecanoate.
(saturated fatty acid table)
If there are double bonds, the location is marked with the symbol Δ with a superscript number indicating the location of the double bond and preceded by cis or trans to indicate configuration (but almost invariably cis). Carbon atoms are counted from the carboxyl end, as in Figure x, so a dodecenoate acid with a cis double bond between carbon atoms 9 and 10 would be: cis-Δ9-dodecenoate.
is a fatty acid with 12 carbon atoms and no double bonds, so the systematic name is dodecanoic acid, and the ionized form is dodecanoate.
(saturated fatty acid table)
If there are double bonds, the location is marked with the symbol Δ with a superscript number indicating the location of the double bond and preceded by cis or trans to indicate configuration (but almost invariably cis). Carbon atoms are counted from the carboxyl end, as in Figure x, so a dodecenoate acid with a cis double bond between carbon atoms 9 and 10 would be: cis-Δ9-dodecenoate.
The number 2, 3 and last carbon atom are called the α, β and ω atoms, respectively.
Biological fatty acids usually contain an even number of carbon atoms, with numbers of 16 and 18 being most common. The length of the fatty acid chain and the degree of saturation contributes largely to their distinct properties. The shorter the chain length and the more unsaturation in the fatty acid enhances their fluidity, thus lowering their melting point.
Phosphoglycerides
[edit | edit source]Phosphoglycerides are esters of two fatty acids, phosphoric acid and a trifunctional alcohol- glycerol. The fatty acids are attached to the glycerol at the 1 and 2 positions on glycerol through ester bonds. Phosphoglycerides are composed of a glycerol back bone with substituents in the following arrangements:
- Hydroxyl #1 of glycerol is usually esterified to a saturated fatty acid
- Hydroxyl #2 of glycerol is usually esterified to an unsaturated fatty acid
- Hydroxyl #3 of glycerol is esterified to a phosphate group
The simplest phosphoglyceride is phosphatidate (picture). Other phosphoglycerides can be made when a group with a hydroxyl is esterified to the phosphate group of phosphatidate. There are four common substituents for phosphatidate. Serine, ethanolamine and choline are structurally similar, while inositol is different:
Sphingolipids
[edit | edit source]Sphingolipids are a second type of lipid found in cell membranes, particularly nerve cells and brain tissues. They do not contain glycerol, but retain the two alcohols with the middle position occupied by an amine and have the same overall shape as phosphoglycerides but have different chemistry, using sphingosine in place of glycerol. Sphingosine has a long hydrocarbon tail similar to fatty acids attached to a structure that is similar to the amino acid serine. A fatty acid can attach to the amine group, and a "head" group can attach to a hydroxyl (see Figure x). Sphingolipids are named according to this head group:
- If there is no head group it is called a ceramide
- If the head group is phosphate and choline, it is called sphingomyelin
- If the head group is a sugar, it is called a glycosphingolipid (or a glycolipid)
The majority of sphingolipids are of the third type, glycosphingolipids. It is thought they have functions in cell recognition and protection in addition to their structural role in the membrane.
Formation Of The Bilayer
[edit | edit source]If we compare the structures of phosphoglycerides and sphingolipids, we see that they are very similar compounds. Each lipid has two long hydrophobic hydrocarbon "tails" and a single polar "head". Since the molecule has both polar and nonpolar moieties, it is said to be amphipathic. It is the amphipathic nature of these molecules that causes them to form bilayers, mediated by four forces:
- The hydrophobic effect- this causes the hydrophobic tails to come together. This is the strongest force driving the formation of the bilayer. It is a consequence of the increased entropy in water molecules when non polar substances are aggregated in water.
- Van der Walls forces between the hydrophobic tails.
- Electrostatic forces of the head groups.
- Hydrogen bonds between the head groups.
One possible structure that satisfies the above forces is called a micelle (pictures). This is common with free fatty acids, but not with most phosphoglycerides and sphingolipids because these groups have twice as many acyl chains per head than the fatty acid (picture), and it is difficult to pack them all into the center of the micelle. Phospholipids and sphingolipids more often form a bilayer in a sheet or a sphere (picture). This is the so called lipid bilayer. Lipid bilayer is permeable to water molecules and other small, uncharged molecules like oxygen, carbon dioxide. A bimolecular sheet formed by amphipathic molecules in which the hydrophobic moieties are on the inside of the sheet and the hydrophilic ones are on the aqueous outside.
Lipid Motion
[edit | edit source]Studying Motion
[edit | edit source]NMR, ESR, X-Ray, Differential scanning calorimetry
Intramolecular Motion
[edit | edit source]There are three basic kinds of motion within the lipid molecules: stretching between bonds, rotating between bonds, and wagging between bonds (?). [picture] 99% of motion within liquid crystal is due to rotation about carbon-carbon bonds. Unsaturated fatty acids of membrane lipids rotate more often. This is because of the packed arrangement of the lipid bilayer. When there is rotation about one bond, an adjacent bond rotates to compensate for steric clashes [pictures]. Since double bonds in fatty acids are nearly always cis, they introduce kinks in the fatty acid. When a bond adjacent to a double bond rotates, the other bond adjacent to the double bond also rotates, and the whole thing moves like an old fashioned bit and brace [pictures]. It takes more energy to rotate the double bonds closer to the head groups due to [angle thing picture]. Double bonds react with O2 readily and create poisons [more] bacteria have [cyclopropane picture]. Furthermore, NMR rotating frame relaxation studies of the intramolecular motion in methionine-enkephalin.
Diffusion
[edit | edit source]One of the most notable properties of the lipid membrane is the ability of a single lipid to diffuse. This property was discovered using the "fluorescence recovery after photobleaching," also known as FRAP. In this experiment, the cell surface is first labeled with a fluorescent chromophore. Afterwards, a specific region is then bleached with intense light, leaving a prominent mark. In the bleached area, the experimenters noticed that as time progressed, bleached molecules moved out from the bleached area and unbleached molecules moved towards the bleached area. This shows that the lipid bilayer allows for molecule movement within the membrane.
There are two kinds of diffusion: lateral and transverse (flip-flop). The lateral diffusion is exactly as it sounds like. In a lipid bilayer, one lipid molecule can move pass the adjacent one. The transverse molecule works a bit differently. It still displaces one over its adjacent counterpart, and crosses over to the other side of the lipid bilayer. It is important to note that the lateral diffusion is substantially faster than the transverse. Studies show that the transverse diffusion only happens once every few hours. Diffusion is the movement of a particle from area of high concentration to low concentration, and it is not to be confused with osmosis, which is the movement of water through a semi-permeable membrane. Diffusion depends on CO2 and O2 concentrate inside and outside of alveolar sack.
Plasma Membrane Function
[edit | edit source]Transportation Methods
[edit | edit source]The membrane regulates molecule transport through a variety of means. There are two general categories that each transportation regulation falls into: passive transport and active transport. Passive transport is the movement of molecules down its concentration gradient: in other words, higher concentration to lower concentration. The diffusion of water, a special case, is called "osmosis." Not all molecules can diffuse through the phospholipid bilayer. The ones that can are usually hydrophobic molecules (i.e. oxygen), nonpolar molecules (i.e. benzene), or small uncharged polar molecules (i.e. water). The hydrophobic and nonpolar molecules can dissolve through the bilayer because of the similar polarites of the bilayer and the molecule itself. The small uncharged polar molecules usually require a membrane channel to diffuse i.e. aquaporins for water. The molecules that do not pass through the layer with ease are large & uncharged, polar, or ions. Examples of each are glucose, sucrose, and hydrogen ion, respectively. To sum up the defining characteristics of what passes or does not pass through the membrane, they are size, charge, and polarity.
Normally, hydrophilic molecules would not be able to cross the phospholipid bilayer due to the difference in polarities. However, it is observed that hydrophilic molecules do cross the membrane protein through a different mechanism than the hydrophobic molecules. While hydrophobic molecules diffuse through the membrane due to their similar polarities, hydrophilic molecules require a molecule called a membrane protein (integral or peripheral), which transfers the molecule in both active and passive transport. A few examples of passive transport are simple diffusion and facilitated diffusion. Simple diffusion is when a solute moves from an area of high concentration to an area of low concentration to establish equilibrium via a channel protein. Facilitated diffusion still moves from an area of higher concentration to lower concentration but instead of a channel protein, it is a carrier protein. This carrier protein, also called permeases, accelerates the rate of transport greatly. Active transport moves the molecules from an area of low concentration to an area of high concentration (the opposite of passive transport). This transport moving molecules up its concentration gradient requires energy, usually from ATP (adenosine triphosphate). A common example used to explain this concept is the sodium-potassium pump. In the human cell, there is usually a high concentration of sodium on the outside the cell and a low concentration of sodium inside the cell. The opposite applies to the concentrations of potassium: high on the inside and low on the outside. The mechanism begins by sodium ion binding to the sodium-potassium pump protein with its gap close off from the cell's external environment. The binding of sodium ion signals to the cell to use convert ATP to ADP (adenosine triphosphate). This reaction will release energy and add a phosphate group to the protein, enabling the protein to change its conformation and release the bound sodium ions to the external cell environment. After the release of sodium ions, potassium ions from the same area will bind to the protein. The potassium ion binding will signal to the protein to convert the bound phosphate group to unbound inorganic phosphate and change the conformation of the protein to release the potassium ions into the cell. Afterwards, the sodium ions bind again and the cycle repeats.
A few other energy-driven processes are endocytosis and exocytosis. Endocytosis are when large molecules are transported into the cell. Exocytosis are when molecules are expelled from the cell. An example of receptor-mediated endocytosis occurs in eukaryotes. It is important for the different membranes in the cell to either join or separate in order to perform certain functions such as engulf, transport, or even release molecules essential for the body. This process is facilitated by LDL, a low-density lipoprotein. External cellular LDL float first binds to its corresponding receptor, called the LDL receptor. The cell membrane then engulfs the LDL and the LDL receptor into the cell, forming a vesicle to keep it unharmed from the cell hydrophilic environment. The complex then separates to protein and receptor counterparts. The LDL fuses with a lysosome, breaking down the LDL with the release of cholesterol as a by-product. A short example of exocytosis would be either the insulin secretion in the blood, or the transport of neurotransmitters at the gap junction during an action potential. A more specific example lies in Golgi's vesicular transport. In eukaryotes, the endoplasmic reticulum (ER) sends transport vesicles to the Golgi apparatus created from proteins. Some of the vesicles fuse with the lysosomes resulting in digestion. Some of the other transport vesicles with essential proteins for the plasma membrane will diffuse in to the membrane due to their similar polarities, releasing the protein content out into the cell's environment.
Different concentrations with regards to internal and external cell environment have different effects on animal cells and plant cells. In a hypertonic solution (concentration of solute is greater on the outside than on the inside), the cell would attempt to create an equilibrium by releasing its water content to the external cell environment. By doing so, the concentrations may be equal if there is enough water in the cell. Also, the cell would end up being shriveled. In the plant cell, the same things occurs. However, because plant cells have cell walls, instead of being shriveled, it is plasmolyzed. On the other extreme, hypotonic solution, when the concentration is solute is lower on the outside than the inside, the cell will become lysed. The attempt to establish equilibrium lies in the water's entrance into the cell to lower the concentration in the cell. In the plant cell, this is called turgid instead of lysed. On a sidenote, this is the normal preference of the plant cell. In an isotonic solution (concentrations are equal on both sides of the cell), the net content of water in and out of the cell remains the cell. This is the eukaryote's preferred state. In the plant cell, it is termed flaccid. Membrance proteins called transporters facilitate the passage of molecules across membrance, there is involved at least three step: dinding, conformational change fo the protein, and release. There are two types of transporter: passive transporters which use no energy, and active transporters that employ ATP to drive transport.
Cell Communication
[edit | edit source]cell-to- cell communication is essential for multicellular organisms such as human or an oak creatures in which they must communicate in order for them to develop from fertilized egg and then survive and reproduce in turn. Communication between cells is very important for many unicellular organisms that must find matters and food in order for them to develop and to sexually reproduce. An early example of cell communication is Saccharomyces cerevisiae in which the cells of that yeast use chemical signaling to identify cells of opposite mating and to start the mating process. The study of cell communication could help to answer some of the most important questions and medicine in areas ranging between embryological development to hormone action to the development of cancer and other related diseases.
On a side note, not only is cell-to-cell communication imperative, but also with other molecules. Different kinds of molecules communicate differently with the internal programming of the cell. For example, synaptic transmitters, such as acetylcholine, bind to a certain G-protein and activates intracellular 2nd messengers. Another way for synaptic transmitters to bind is via a protein complex (integral/membrane protein) including an ion channel. The net result of both pathways change the state of ion channel conformation in the membrane. Another example, steroid hormones, diffuse through the cell membrane and eventually changes the protein programming in certain cells. As for the peptide hormone, it binds to a G-protein, activates intracellular 2nd messengers, and changes the transcription paradigm. Due to the peptide hormone's hydrophobic character and the cell membrane nonpolarity, it requires secondary messenger interaction whereas the steroid hormone (also nonpolar) can directly communicate and diffuse into the cell. Cell-cell communication is essential for multicellular organisms. Cells usually communicate by releasing chemical messenger targeted for cell. Some messengers travel short distances such as molecules are allied local regulators. Animal growth factors which are compounds that stimulate nearby target cells to grow and multiply. Numerous cells can simulaneously receive and respond to the molecules of growth factors produced by single cell in their vicinity.
Cell Adhesion
[edit | edit source]Cell adhesion is any glandular cells in ctenophores, turbellarian used for adhesion to a substrate and for capture. Cell adhesion occurs when one cell binds to another surface such as another cell or some other inanimate surface. Cell adhesion molecules serve as intermediates that hold the cell to another surface.
Summary
[edit | edit source]Complex Lipid Metabolism and Cholesterol
[edit | edit source]Introduction
[edit | edit source]Dietary fats serve a variety of function in the body. One of the most important function is as a metabolic fuel, per gram, fats yield twice as much energy as carbohydrate. All steroid hormones are derived initially from lipid, and these in turn are responsible for the regulation of body functions such as growth, development and the appearance of sexual characteristics as a result of sex hormones. Essential fatty acids, such as linoleic acid and α-linolenic acid are prostaglandin and ecosanoid precursors.
Lipid Droplets (LDs)
[edit | edit source]The LDs takes part of a hydrophobic phase in the cytosol and are composed of an organic phase of neutral lipids. This hydrophobic core stores metabolic energy and membrane components making them the central region for lipid metabolism. They also take part in protein storage, degradation, and viral replication. The formal definition for Lipid Droplets is "the cytoplasmic organelle composed of a hydrophobic core of neutral lipids bounded by a phospholipid monolayer and specific proteins" [1]
How were they Discovered
[edit | edit source]These droplets were found in the nineteenth century by the method of light microscopy of cellular organelles. Lipid Droplets were often called liposomes until the in vitro vesicles were generated in 1960's and this new vesicles were named liposomes. Since this moment the Lipid Droplets were referred as lipid bodies, fat bodies, spherosomes, or simply LDs. LDs were mainly ignored on research until a protein that specifically localized to LD surface was identified in 1991 [1]
Where are they found?
[edit | edit source]LDs are found in most cells. LDs can be found among bacterias and eukaryote, although their number and size vary greatly in different cell types.
What is their functions?
[edit | edit source]The LDs provide building blocks for membranes for energy metabolism. LDs have the ability to package hydrophobic lipids, such as TGs, without water, providing a very efficient form of energy storage. It has also been found that there are links between lipid synthesis pathways and LDs. LDs also serve as organizing center for specific lipids and have been linked to protein storage with the possibility of also storing unfolded membrane proteins. LDs have also been found to be involved in the hepatitis C virus assembly.
Digestion and Absorption of Lipids
[edit | edit source]Lingual Lipase
Short Chain Fatty Acids
Long Chain Fatty Acids
Bile
[edit | edit source]Primary Bile Acids Bile Salts Secondary Bile Acids
Chylomicron Formation
[edit | edit source]Micelles
Very Low Density Lipoprotein (vLDL)
[edit | edit source]Low Density Lipoprotein (LDL)
[edit | edit source]Low density lipoprotein (LDL) is known as bad cholesterol. When the level of LDL is high in the blood, it could slowly build up inside the arteries that pump the blood to the brain and the heart. LDL and other substances can cause atherosclerosis. Atherosclerosis is a disease that happened when the arteries became less flexible and narrow due to the plaque that LDL and other substances form.
High Density Lipoprotein (HDL)
[edit | edit source]Cholesterol can not dissolved in the blood there for it has to be transported in and out of the cells by carrier called lipoprotein. There are two type of lipoprotein: low-density lipoprotein ( LDL) and high-density lipoprotein HDL. high density lipoproteins (HDL) are known as good cholesterol because high level of HDL could prevent from heat attacks. Some scientists believe that high-density lipoprotein (HDL) slow the build up of plaque in which it removes cholesterol from arteries.
Reference
[edit | edit source][1] Walther, Tobias C., and Robert V. Farese, Jr. "Lipid Droplets and Cellular Lipid Metabolism." National Center for Biotechnology Information. U.S. National Library of Medicine, n.d. Web. 06 Dec. 2012. <http://www.ncbi.nlm.nih.gov/pubmed/22524315>.
Enzymes
[edit | edit source]Introduction
[edit | edit source]Enzymes are macromolecules that act as organic catalysts in most of the organism's biochemical reactions that have functions indispensable to maintenance and activity of life. It is crucial to note that reaction rates of certain chemical conversions occurring in living organisms are extremely low, and catalysis is necessary to maintain reasonable time of cell development and division. Majority of functional enzymes are proteins, like trypsin, fumarase or papain. A small subset of enzymes are composed of RNA and are known as ribozymes, for example hammerhead ribozyme, responsible for cleaving and joining at a specific site of RNA molecule, or 23S rRNA of prokaryotic 50S ribosome subunit activity of peptidyl transferase. The general mechanism by which enzymes work is by reducing the energy required to start the reaction, otherwise known as the activation energy. Microorganisms producing certain enzymes, or extracted and purified enzymes alone have extremely varied uses: ethanol production (Saccharomyces cerevisiae, Zymomonas mobilis) forensic science (restriction enzymes), and polymerase chain reaction amongst them. Uses of enzymes are not purely scientific. These diverse molecules form a huge part of industries such as brewing and pharmaceuticals; the use of enzymes alone in the brewing process of Guinness is worth over a billion euro to the Irish economy.
Structure of Enzymes
[edit | edit source]Model enzymes are monomeric, globular proteins. Majority of studies on nature of enzymatic reactions were conducted on trypsin, chymotrypsin or amylase. As every protein, to work correctly enzymes require proper folding, and, by consequence, are susceptible to deactivation by denaturation. The key to enzyme activity is a structure called active site. Interactions between residues of polypeptide chain aminoacids cause them to create a structure of defined size, shape and sequence. The difference between active site and structural domain is that the latter is able to recognize (recognition site) and process a defined molecule. Whether the interaction between the molecule and recognition site is sterical (shape-based), hydrophobic (chymotrypsin) or ionic (trypsin) it is always specific and temporal. Inhibitors often use specific covalent binding to an active site, which deactivates enzyme permanently.
Two theories regarding active sites were created. Theory of key and lock states that active site and substrate are of matching size and shape - substrate being a key and active site a lock. Binding of perfectly matching molecule would induce conformational changes of enzyme, causing catalysis. Second theory of induced fit states that active site and substrate have different, mismatching structures. When substrate meets active site it induces it to assume certain conformation, whether it is by removing structural water molecules, or straining interactions between aminoacid residues.
Mechanism of Enzymes
[edit | edit source]The mechanism how enzymes work is done by lowering the activation energy of the reaction which the specific enzyme is to catalyse. Each of the enzyme is entirely specific to the reactants; it will only work for one specific reaction, this is due to the unique active site of each enzyme. The enzyme's active site is in a unique 3D shape, with a unique pattern of electrostatic charge and hydrophobicity. Here the specific substrates -- the substances upon which the enzyme works -- are temporarily combined with the enzyme, forming an enzyme substrate complex, or ESC. The reaction then occurs, and the product of the reaction separates from the enzyme, at which point the product may be used. The enzyme is then capable of repeating the reaction many thousands of times, although they may have to be replaced every so often.
Activity of Enzymes Control of Enzyme activity in Cell The production of enzymes can be enhanced or diminished by changing the internal environment of the cell. This is called enzyme induction and inhabitation. The enzyme inhibitor or the enzyme inductor will be bound to the enzyme and either decrease or increase the activity of the enzyme. The inhibitor stops the entre of substrate to the active site. It can be reversible or irreversible. Enzyme activities are compartmentalized; this means that the reduced activity of one enzyme can lower the productivity of another, since they are linked. Some enzymes will be activated by environmental factors inside your body, for example the lowering of body pH changes the activity of hemagglutinin in influenza. Thus, the lower the potential energy barrier to reaction, the more reactants have sufficient energy and, hence, the faster the reaction will occur. All catalysts, including enzymes, function by forming a transition state, with the reactants, of lower free energy than would be found in the uncatalysed reaction.
Enzyme Graph
Enzymes do not modify the equilibrium of a reaction. Enzymes only catalyze or speeds up the rate of reaction by stabilizing the transition state and do not participate in the chemical reaction. The transition state is the highest activation energy (Ea) on a reaction coordinate in which the molecule is only partially reacted. The activation energy is lowered when a catalyst (enzyme) is used. When an enzyme is not used, the activation energy of a reaction is much higher, which will take the reaction much longer to proceed. The enzyme is complementary to the transition state and not the substrate, in order to facilitate the reaction efficiently. A catalyst is present in the reactants and also appears in the end products.

Properties of Enzymes
[edit | edit source]1. Enzymes are sensitive to heat, and are denatured by excess heat or (inactivated by excess cold), i.e. their active site becomes permanently warped, thus the enzyme is unable to form an enzyme substrate complex. This is what happens when you fry an egg, the egg white (albumen, a type of protein, not an enzyme), is denatured. 2. Enzymes are created in cells but are capable of functioning outside of the cell. This allows the enzymes to be immobilised, without killing them. 3. Enzymes are sensitive to pH, the rate at which they can conduct reaction is dependent upon the pH of where the reaction is taking place, e.g. pepsin in the stomach has an optimum pH of about pH2. Whereas salivary amylase has an optimum pH of about 7. 4. Enzymes are reusable, and some enzymes are capable of catalysing many hundreds of thousands of reactions every second, e.g. catalase working on hydrogen peroxide. 5. Enzymes will only catalyse one reaction, e.g. invertase will only produce glucose and fructose, when a glucose solution is passed over beads of enzyme (see Immobilisation). 6. The reaction rate for an enzyme is limited by its saturation point. Saturation is essentially the point at which an enzyme can no longer speed up the reaction to compensate for the increase in substrate concentration (push the equilibrium towards the products). Graphically this is portrayed as a horizontal asymptote and is also called the maximum velocity. Each enzyme has its own maximum velocity for a given substrate. Measuring the rate of product formation with varying concentrations of substrate is one way of determining the maximum velocity of an enzyme. 7. Enzymes are capable of working in reverse, this acts as a cut off point for the amount of product being produced. If there are excess reactants the reaction will keep going and be reversed, so that there is no overload or build up of product. Enzymes are catalysts in the breaking down of substances by bonding with them briefly. Hydrogen peroxide they break it down into water and oxygen much faster than it would naturally occur. Inside the body they are used to break down food and to start off the digestion process. They are proteins they are affected by the pH level of the substance and also the temperature of the substance. The last important note is that obviously the concentration of the enzyme will affect how well it works.They are substrate specific which is illustrated by the lock and key hypothesis.
Enzymes may be immobilised in two ways, firstly by bonding them chemically to some sort of rigid structure, and secondly by physically placing the enzymes on an insoluble support structure, e.g. a gel or bead. The second method of enzyme immobilisation is much more common, is cheaper, but it does reduce the enzyme's ability to catalyse reactions.
Steps in Enzyme immobilization
1. Make up a 5% w/v solution of sodium alginate, and leave to stand overnight, to mix properly.
2. Add the enzyme, or in this case, a cell e.g. yeast, to the alginate solution, and mix in well. At this point the mixture will be very thick, and should be left for twenty minutes to eliminate the air bubbles, from the solution; such air bubbles would increase the surface area of the beads, making them less efficient.
3. Take a syringe, and fill it with the alginate/cell matrix.
4. Make a 2% w/v solution of Calcium Chloride.
5. Hold the syringe about 20 cm perpendicularly above the calcium chloride solution, and drip in the alginate solution, trying to create the smallest possible beads, approx 3-4mm in diameter.
6. Remove and discard any alginate strings or floating beads from the chloride solution.
7. Rinse the beads in deionised water.
8. Using a retort stand set up two tap funnels above each other, placing the beads in the bottom funnel, and strong glucose in the top.
9. Allow the glucose to run through the beads, and draw off the product.
The product is a type of alcohol, which should not be ingested as it is impossible to tell whether it is ethanol or methanol, the later being toxic.
Naming Enzymes
[edit | edit source]Until quite recently enzymes have been given arbitrary names, for example, ptylin (amylase), this tells us nothing of what the enzyme acts upon, instead biologists have devised a means of naming enzymes, whereby enzymes end -ase; e.g. DNA Helicase, they have also included a clue as to what the enzyme acts upon; DNA Helicase working to separate nucleotides in a chain of DNA. Other common enzymes include protease, lipases, pepsin, amylase, and lysomase.
References
[edit | edit source]Berg, Jeremy M. Biochemistry 6th Edition. New York, W. H. Freeman and Company, 2007.
Metabolism
[edit | edit source]What is life? What makes life work? Life is not static; it is defined by activity. A cell has to perform certain tasks to stay alive. This activity has to be powered by fuel; the fuel is converted into energy, to keep the cell running, building blocks for new biomolecules, and waste products. This process is called metabolism.
ATP as an intermediate energy carrier
[edit | edit source]We have already seen how ATP is a universal "energy currency" in the cell, and how its high-energy phosphate can store and release this energy efficiently. But ATP is only a short-term energy storage; a hard-working human can use up to one pound of ATP per minute. How can that be?
The answer lies in the medium- and long-term energy storage molecules, notably phosphoenol pyruvate (PEP), acetyl phosphate, and creatine phosphate. Each of these molecules carries a phosphate group with an ever higher transfer potential than that of ATP. ATP is continuously regenerated by transferring phosphate groups from these molecules to ADP. For example, the reaction of creatine phosphate is
a reaction which is catalyzed by the creatine kinase, and highly in favor of the "ATP side" of the equation.
Electron carriers
[edit | edit source]Most of the energy of eucaryotic lifeforms derives from oxidating fuel molecules, that is, the transfer of electrons from fuel molecules to oxygen. The fuel molecules are oxidized, while the oxygen is reduced. A rather radical form of oxidation is fire, which oxidizes its fuel directly with oxygen. As spontaneous combustion one ones cells is rather unpleasant, the electrons are carried through several steps from the fuel molecules to the final electron acceptor, oxygen. The flow of electrons causes a proton gradient in the mitochondrial membranes, which in turn is used by the enzyme ATPase (or proton pump) to generate ATP. This process, utilizing anelectron transport chain, is called oxidative phosphorylation.
The electron carrier molecules of choice are NADH and FADH2. They are pyridine nucleotides (also called flavions).
| Reduced form | Oxidized form | |
|---|---|---|
| NADH | NADH | NAD+ |
| FADH2 | FADH2 | FAD |
Both molecules are also for biosyntheses that require reducing power. Especially a variant of NADH, NADPH, is used for this purpose.
With all these high-energy bonds and electron-carrying molecules around, one would expect to see wild, uncontrolled chemical reactions occurring in the cell. However, the opposite is the case: Without a catalyst, ATP is quite slow to hydrolize and give its phosphate group to water. Also, all three electron-carrying molecules, NADH, NADPH, and FADH2, are slow to react with O2 without a catalyst.
Cancer Cell Metabolism
[edit | edit source]Glutamine addiction: a new therapeutic target in cancer
The Warburg observation that cancer cells use up an unusually high level of glucose and produce more lactic acid has been around since the 1920’s. It wasn’t noted till 1955 by Eagle, that cancer cells also use up a high level of the amino acid glutamine. In the article, Glutamine addiction: a new therapeutic target in cancer, Wise and Thompson highlight the role glutamine plays in cancer cell growth, protein translation, anaplerosis, and macromolecular synthesis.
Glutamine is the chief donor of nitrogen to cancer cells for the cells to multiply. When glutamine gives up its amide, it is converted into glutamic acid, which is the main nitrogen donor for nonessential amino acid synthesis. This amino acid biosynthesis makes glutamine a main ingredient for the cancer cells’ need for protein translation. Stemming off of biosynthesis is Myc, a basic protein that binds 11 of the genes involved in nucleotide biosynthesis. Myc activation is a commonly observed in cancer and is identified as the driving force behind the spread of lymphomas and small cell lung cancer. Myc facilitates glutamine consumption and supports the change of glutamine into glutamic acid, and finally into lactic acid. This satisfies the Warburg observation of the unusual lactic acid production of cancer cells.
The target of rapamycine (TOR) controls many cell functions such as cell growth, reproduction, motility, and protein synthesis. The “master regulator of protein translation, the mammalian target of rapamycin complex (TOR), is responsive to glutamine levels” (Wise and Thompson, 2010). This was initially discovered in yeast, where TOR activation was found to be dependent on glutamine levels.
The article also describes how glutamine adds to macromolecular (DNA, RNA, and proteins) synthesis by producing NADPH (nicotinamide adenide dinucleotide phosphate, a reducing agent in anabolic reactions) and providing the cancer cell with a substrate source which refills the mitochondrial carbon pool (anaplerosis). This refilling of the carbon pool is necessary for the synthesis of proteins, lipids, and nucleotides.
All of these facts relating glutamine importance to cancer cells may be a potential target in altering cancer cell metabolism. However, it is still unknown if this is a viable target for the treatment of cancer. Ideas include suppressing the glutamine uptake, TOR activation, or the anaplerosis of the cancer cells. Using an enzyme to lower blood glutamine levels is another possible method.
References
[edit | edit source]Wise & Thompson, Glutamine addiction: a new therapeutic target in cancer, 2010, Department of Cancer Biology, University of Pennsylvania, Elsevier Ltd.
Glycolysis
[edit | edit source]Introduction
[edit | edit source]Glycolysis is the process which glucose is divided into two molecules of pyruvate. In fact, glycolysis considered a linear pathway of ten enzyme-mediated steps. The pathway for glycolysis has two phases: the energy investment phase and energy generation phase. The first five steps in the glycolysis are the energy investment "preparatory phase", which produce glyceraldehyde 3-phosphate. Energy generation phase is the last five steps of glycolysis, which produce the final two pyruvate molecules product. Glycolysis occurs in cytoplasm and can be achieved in the absence of oxygen. In the body, the source of glucose for glycolysis comes from dietary disaccharides and monosaccharides.
Glycolysis is the first step in carbohydrate metabolism, the end result of which is the conversion of glucose to carbon dioxide and water. When total oxidation of glucose to carbon dioxide ended, a large amount of energy is converted into ATP.
During glycolysis, two molecules of NADH and a net two molecules of ATP are generated (two molecules of ATP are used to get the pathway started, but four molecules are then synthesized). Thus, there is a net production of two ATP molecules for each glucose molecule converted to two molecules of pyruvate.
At the end of the process, only a small part of all glucose energy is released and the rest of the potential energy stays in pyruvate molecules which are further oxidized to firstly to acetyl- CoA and later on carbon dioxide by TCA cycle. The NADH and FADH2 gained from TCA cycle enter into ETC to produce ATP via oxidative phosphorylation. For this reason aerobic degradation is much more efficient than anaerobic metabolism. That is why the aerobic mechanism is now much more spread within living organisms, but nevertheless anaerobic pathways still take place even in animals under certain physiological circumstances.
Overview
[edit | edit source]Glycolysis is a central pathway for the catabolism of carbohydrates in which the six-carbon sugars are split to three-carbon compounds with subsequent release of energy used to transform ADP to ATP. Glycolysis can proceed under anaerobic (without oxygen) and aerobic conditions.
Glycolysis is a 10-step pathway which converts glucose to 2 pyruvate molecules. The overall Glycolysis can be written as a net equation:
Glucose + 2ADP + 2NAD+ → 2Pyruvate + 2ATP + 2NADH
Glycolysis enzymes:
- Hexokinase (HK)
- Phosphoglucoisomerase (PGI)
- Phosphofructokinase (PFK)
- Aldolase (ALDO)
- Triose phosphate isomerase (TPI)
- Glyceraldehyde-3-phosphate dehydrogenase (GAPDH)
- Phosphoglycerate kinase (PGK)
- Phosphoglycerate mutase (PGM)
- Enolase (ENO)
- Pyruvate kinase (PK)
Glycolysis compounds:
- Glucose
- Glucose 6-Phosphate (G6P)
- Fructose 6-Phosphate (F6P)
- Fructose 1,6-Bisphosphate (F1,6BP)
- Glyceraldehyde 3-Phosphate (GADP)
- Dihydroxyacetone Phosphate (DHAP)
- 1,3-Bisphosphoglyceric acid (1,3PG)
- 3-Phosphoglyceric acid (3PG)
- 2-Phosphoglyceric acid (2PG)
- Phosphoenolpyruvate (PEP)
- Pyruvate
Visual overview
[edit | edit source]
Detailed description of the ten step
[edit | edit source]Step 1: Glucose phosphorylation at its 6th carbon catalysed by glucokinase (hexokinase IV) or other hexokinases:

Glucose that enters the cell has only one fate: it is converted to glucose-6-phosphate by a typical kinase reaction. When glucose is phosphorylated, it is trapped inside of the cell because phosphoryl at 6th carbon pushes phospholipid membrane thus glucose-6-phosphate even could not close to plasma membrane.
ATP is used as phosphoryl group reservoir.
Mg2+ found as a cofactor of the enzyme. Presence of Mg2+ shields the charge on the phosphoryl of ATP. So compounds can come closer in an easier way.
At the reaction, a pyrophosphate bond is cleaved (-7.5 kcal/mole) and a phosphate ester bond is formed (+3 kcal/mole), resulting in a net -4.0 kcal/mole. Thus it can be concluded that product (glucose-6-phosphate) has less energy than the reactant (glucose). Less energy means that more stability. Therefore, product is more stable than the reactant. This condition makes the reaction irreversible.
Step 2: Isomerization of glucose-6-phosphate catalysed by means of phosphoglucoisomerase:

This convertion is reversible. Via converting 6C cyclic compound to 5C cyclic compound which includes oxygen in the cyclic part as seen at 6C compound, too, it is aimed to produce a molecule that is able to be splited into two equal carbon contented (3C) compound.
Step 3: Second phosphorylation catalysed by phosphofructokinase:

By the help of this step, division into two equal carbon contented (3C) compound also balanced in terms of phosphoryl group.
Again Mg2+ is found as a cofactor of the enzyme. It functions like seen at step 1.
This reaction is irreversible as it can be implied from its negative δG0
Step 4: Cleavage to two triose phosphates catalysed by aldolase:

Now, two molecules of 3C compound is generated.
Step 5: Isomerization of dihydroxyacetone phosphate catalysed by triose phosphate isomerase:

After this step each reaction occurs double time because 2 molecules of glyceraldehyde-3-phosphate exists for further steps.
Step 6: Generation of 1,3-bisphosphoglycerate catalysed by glyceraldehyde-3-phosphate dehydrogenase:

Here, it is goaled to insert phosphoryl group which will be transferred to ADP to create ATP, later. Also production of NADH happens.
Step 7: Production of 3-phosphoglycerate via substrate-level phosphorylation catalysed by phosphoglycerate kinase:

The first step which ATP is produced is step 7.
Step 8: Phosphate transfer from 3rd carbon to 2nd carbon of 3-Phosphoglycerate catalysed by phosphoglycerate mutase:

Via the effect of this reaction, resonance at PEP (step 8 product) is achieved.
Step 9: Synthesis of phosphoenolpyruvate catalysed by enolase:

Water exit occurs.
Step 10: Substrate-level phosphorylation. Pyruvate synthesis catalysed by pyruvate kinase:

ATP is produced. Pyruvate tautomerizes rapidly and nonenzymatically to its keto form from its enol form. It is the last and one of the irreversible steps of glycolysis.
References
[edit | edit source]- Nelson, D. L., & Cox, M. M. (2008). Glycolysis, gluconeogenesis, and the pentose phosphate pathway. Lehninger Principles of Biochemistry, 4, 521-559.
- Berg JM, Tymoczko JL, Stryer L. Biochemistry. 5th edition. New York: W H Freeman; 2002. Chapter 16, Glycolysis and Gluconeogenesis.
Pyruvate Dehydrogenase
[edit | edit source]Metabolism, as all other functions in the human body, is not a simple mechanism. Although performed extremely fast, metabolism has many complex steps. For the multiple steps, there are multiple enzymes catalyzing the process. One of the steps of metabolism is taking pyruvate (from glycolysis) and converting it into CO2 and acetyl-CoA (used in the krebs cycle). In order to perform this action, so it will not be a lengthy process, an enzyme is necessary. The enzyme that catalyzes this action is pyruvate dehydrogenase. Aside from being an enzyme catalyzing the complex steps of metabolism, pyruvate dehydrogenase is very complex, too. The pyruvate dehydrogenase is an extremely complex structure made up of several enzymes: E1, E2, and E3. Since it does contain a complex structure, these enzymes are present within the structure multiple times. Overall, pyruvate dyhydrogenase is a dehydrogenase. As most dehydrogenase do, pyruvate dehydrogenase performs it job with the cofactor of NAD+. NAD+ performs its function by converting NAD+ to NADH+H+. This enzyme complex utilizes substrate channelling which means it achieves the reaction void of releasing its substrate into the reaction solution. The enzyme includes cofactors bound to itself, their names are TPP, Lipoate and FAD.

Regulation
[edit | edit source]Pyruvate dehydrogenase is negatively regulated by its own product acetyl CoA, ATP, NADH, and fatty acids while it is being positively regulated via AMP, CoA, NAD+, Ca2+. It is sensible because presence of much acetyl CoA, ATP,NADH, and fatty acids refers that there is enough energy or energy source so no need to convert pyruvate into acetyl CoA because there is enough energy and for CoA, NAD+, Ca2+ it is vice versa.
Pyruvate dehydrogenase deficiency
[edit | edit source]As previously stated, pyruvate dehydrogenase is the enzyme in charge of changing pyruvate into acetyl-CoA (acetyl coenzyme A), a necessity to start the Krebs’s cycle. The question at hang is can pyruvate dehydrogenase go wrong? The answer is yes, and although uncommon, pyruvate dehydrogenase deficiency is an example of what occurs when pyruvate dehydrogenase cannot perform its job. The question left unanswered is what pyruvate dehydrogenase deficiency is? Pyruvate dehydrogenase deficiency is a buildup of lactic acid, or lactic acidosis, which can be life-threatening for many. The most common forms of this lactic acid buildup can cause symptoms such as nausea, abnormal heartbeat, and vomiting. Pyruvate dehydrogenase is also characterized by varies neurological problems. The most common issues occurring with neurological abnormalities are slow mental abilities and motor skills such as sitting. Other neurological problems range from having poor coordination to difficulty walking to being intellectually disabled.
References
[edit | edit source]Nelson, D. L., Lehninger, A. L., & Cox, M. M. (2008). Lehninger principles of biochemistry.
Diwan, Joyce J. 2007. Pyruvate Dehydrogenous and The Kreb's Cycle. Web. http://www.rpi.edu/dept/bcbp/molbiochem/MBWeb/mb1/part2/krebs.htm
Pyruvate Dehydrogenous and The Kreb's Cycle. College of Science / Microbiology. Aug. 3, 1999. Web. http://www.science.siu.edu/microbiology/micr425/425Notes/05-PyrKrebs.html
Genetics Home Reference. Pyruvate dehydrogenase deficiency. Nov. 19. 2012. Web. http://ghr.nlm.nih.gov/condition/pyruvate-dehydrogenase-deficiency
Tricarboxylic Acid Cycle
[edit | edit source]Citric acid cycle, also known as Tricarboxylic Acid Cycle(TCA), is a metabolic pathway where oxidation of sugars, fats and proteins proceeds. Components of the cycle locate in mitochondrial matrix, in eukaryote organisms. But it is important to know that eukaryotes includes cytoplasmic isozymes of citric acid cycle enzymes, in cytoplasm. For prokaryotes, citric acid elements have to present at the cytoplasm.

Pyruvate, obtained by glycolysis and other metabolic functions, cannot enter directly to citric acid cycle. Pyruvate is converted to acetyl- CoA via the help of pyruvate dehydrogenase complex in an irreversible way. At the end of this reaction pyruvate at the cytosol degraded and newly formed acetyl CoA is released into mitochondria. Then acetyl CoA is able to encounter with citric acid enzymes, because there is no barrier to prevent this event.
The first reaction of citric acid cycle is citrate synthesis with the condensation of acetyl CoA and oxaloacetate. First step has highly negative delta G value which is the one of the sign shows us this step is irreversible.
The second reaction uses citrate as a substrate and produce iso- citrate. However, the enzyme catalysing the reaction carries out its job in two steps. In the beginning citrate is used and cis- aconitate is formed. As the further step cis- acotinase used in order to produce isocitrate. This explains where the name of enzyme originates. Here, delta G is positive however reaction continues to go in the direction of products, how? The answer is based on Le Chatelier' s principle. According to Le Chatelier' s principle, the reaction tends to go to the side which is lowering in amount. In this step, the depletion of iso- citrate via the action of isocitrate dehydrogenase, which is the is processor of the next step, leads reaction to go to the side of products.
At the 3rd step, isocitrate is converted to alpha-ketoglutarate by means of isocitrate dehydrogenase. The reaction has negative delta G thus it is irreversible.
The fourth step contains the oxidation of alpha-ketoglutarate to succinyl-CoA via the help of the enzyme, named as alpha-ketoglutarate dehydrogenase. The 4th is known as last irreversible step of Krebs cycle.
In the 5th reaction, passage from succinyl-CoA to succinate is seen. This step is reversible however proceeds to product's side because of Le Chatelier' s principle.
The 6th step is catalyzed by an enzyme which is both the member of TCA cycle and Electron Transport Chain (ETC). The enzyme has two name as Complex II and succinate dehydrogenase. It uses succinate and releases fumarase.
In seventh step, fumarate to malate conversion is observed. The reaction is reversible. However, the enzyme found in this step is highly stereospecific and only uses L-malate and trans- maleate(fumarate) as substrate.
The 8th step is the last step where oxidation of malate to oxaloacetate occurs.
Acetyl CoA is not only site which cycle starts
[edit | edit source]
Regulation
[edit | edit source]Regulation of Krebs cycle achieved by regulating enzymes of irreversible steps of the cycle. But also via regulation pyruvate dehydrogenase can be controlled because this enzyme provides main substrate, acetyl CoA, for the cycle. For regulation of pyruvate dehydrogenase, please investigate Biochemistry/Conversion of pyruvate to acetyl CoA page.

Dual nature of Krebs cycle
[edit | edit source]Krebs cycle functions as both anabolic and catabolic pathway. This event makes it an amphibolic pathway. If they are used as precursors for other compounds, how does the cycle proceed? The answer is anaplerotic reactions, which are responsible for the replenishment of pathway intermediates and utilizes NADP+ for this mission.

References
[edit | edit source]- Nelson, D. L., Lehninger, A. L., & Cox, M. M. (2008). Lehninger principles of biochemistry.
Electron Transport Chain
[edit | edit source]The electron transport chain is a system of molecules through which electrons are transferred to generate ATP. It has an important role in both photosynthesis and cellular respiration.
Oxidative phosphorylation
[edit | edit source]Mitochondria is a double membraned organelle where most of the ATP, of the cell, is harvested by means of oxidative phosphorylation. The outer membrane of the mitochondria is highly permeable to most of the small molecules (<500 g/mol) and ions, as opposed to inner one. The inner membrane consists of folds, which have special name cristae, providing more surface area for ETC (electron transfer chain) elements. The matrix contains pyruvate dehydrogenase complex alongside citric acid cycle enzymes, fatty acids beta-oxidation enzymes and amino acid oxidation elements. Thus, except glycolysis happens at cytoplasm, oxidation of most of the fuels occurs at mitochondrial matrix. Therefore, most of the electrons transferred to electron carriers such as NAD and FAD directly available for processing of ETC. Electron transfer to NAD and NADPH is achieved by the help of Nicotinamide Nucleotide-Linked Dehydrogenases. Reactions catalyzed via Nicotinamide Nucleotide-Linked Dehydrogenases can be processed to reverse direction, by again by these enzyme.
Standard reduction potential value implies that how much a molecule is disposed to be reduced. The greater value infers the greater tendency to be reduced.
For NAD and NADP standard reduction potential is majorly determined molecules themselves. FAD is similar to NAD and NADP however it differs at its relation with its linked protein. NAD and NADP are water-soluble after reaction occurs NAD and NADPH dissociates from the enzyme. As segregate from NAD and NADP, FAD found as bound to the enzyme, meaning it is a prosthetic group. Because of this permanent link, standard reduction potential of FAD is decided by the enzyme FAD associated.
There are differences between NAD and NADPH, too. After electron acceptance, NADH is directed in order to enter ETC whereas NADPH contributes anabolic reactions. In addition to this, NADP and NAD do not stored at the same place, instead they deposit at different parts of the cells.
Electrons carried via NADH and FADH2 are transported to complexes some of which pumps H+ from matrix to intermembrane space. But passage between complexes also requires some electron carriers. These carriers are respectively Ubiquinone (Coenzyme Q, shortly just Q), Iron sulphur proteins and cytochromes.
![]()
There are four unique electron carrier complexes in the respiratory chain:
- Complex I: NADH dehydrogenase
- Composed of 42 different polypeptide chains.
- Has several Fe-S centers.
- NADH + H + FMN <---> NAD + FMNH2
- Transfers 2 electrons from NADH to Q.
- Pumps 4 protons from matrix to IMS.
- Complex II: Succinate Dehydrogense
- Transfers 2 electrons from succinate to coenzyme Q.
- Contains 4 different protein subunits:
- Subunit A: FAD, succinate binding
- Subunit B: 3 Fe-S centers
- Subunit C: integral membrane protein, Q binding
- Subunit D: does not participate in electron transfer to Q, instead reduces the frequency of some leaking electrons form reactive oxygen Species: ROS.
- Complex III: Ubiquinone Cytochrome C Oxidoreductase
- Composed of 22 subunits: heme groups and Fe-S centers
- Transfers of 2 electrons QH2 to Cytochrome C.
- Pumps 4 protons into IMS.
- Complex IV: Cytochrome C Oxidase
- Contains 13 subunits, prosthetic groups such as cytochromes and Fe-S centers.
- Transfers 2 electrons from cytochrome C to oxygen, reducing it to H2O.
- Pumps 2 protons into IMS
By the pumping electrons to IMS, proton motive force is generated. Then, via the backflow of hydrogen ions into matrix (mediated by ATP synthase) phosphorylation of ADP to ATP occurs.
For oxidative phosphorylation, oxidation and phosphorylation are said to be coupled. the base idea for this is the event that if one of them does not function, other one cannot proceed. Oxidation of electron carriers provides proton passage form matrix to IMS, thus promotes the activity of ATP synthase. ATP synthase, in concaminant to ATP production, replenishes matrix protons by pumping electrons from IMS to matrix. In conclusion ETC and ATP synthase promotes their action, in relation looks like mutualism.
ETC in photosynthesis
[edit | edit source]In photosynthesis, when light is absorbed in photosystem 2, electrons are energized. They are transferred to the reaction center. From the reaction center, the electrons enter the electron transport chain and pass the etransport[check spelling] chain molecules. Then the 2 deenergized electrons are reenergized in Photosystem 1 (is second because PSII was discovered first) and they go to the NADP+ reductase which transfers their electrons to a coenzyme, converting it to NADPH+ The two electrons used must be replaced, so water is broken down producing 2 protons (H+) which concentrate in the thylakoid membrane, 2 electrons replaced in PSII and oxygen released as O2. Protons go down proton pumps and a concentration gradient forms as protons move from the stroma into the thylakoid space. Protons move down gradient through ATP synthase which forms ATP. Energy is stored.
DNA and RNA
[edit | edit source]Deoxyribonucleic acid (DNA) and ribonucleic acid (RNA) are the information storage molecules and working templates for the construction of proteins. Every living cell and virus encodes its genetic information using either DNA or RNA. It is a true marvel of evolution that the vast amount of information needed to produce a human being can fit inside cells.
Friedrich Miescher first isolated DNA and RNA from used surgical bandages in 1869. A series of experiments done by Oswald Avery, Colin MacLeod, and Maclyn McCarty in 1944 defined DNA as the genetic information. They injected virulent encapsulated bacteria into a mouse. As it a result, it died. On the contrary, nonvirulent nonencapsulated bacteria did not kill the mouse. Also, heating the virulent encapsulated bacteria and injecting did not kill the mouse either. The surprise lied in mixing the heat-killed virulent encapsulated bacteria with nonvirulent nonencapsulated bacteria did kill the mouse. Avery's group kept isolating factors until they discovered what killed the mouse, which was the DNA. In conclusion, the nonpathogenic bacteria was made pathogenic by DNA transfer from a pathogenic stain. A.D. Hershey and Martha Chase's work in 1952 reconfirmed that DNA is the carrier of genetic information. Hershey and Chase's group conducted an experiment involving two phages. One of the phages was radioactively labeled with heavy phosphorus to highlight the DNA and heavy sulfur to highlight the protein. The two phages inserted their "genetic material" into the bacterial cell. Afterwards, these cells were "blended" to remove the phage heads. The resulting radioactively-labeled heavy phosphorus was found in the cell. This experiment showed that DNA alone was sufficient to make new viruses, and therefore, defined as the genetic information. Rosalind Franklin, Chargaff, and other chemists provided information that led to the discovery of DNA as well. Franklin provided crystallographic data that implied a helical structure. Chargaff's rule said that the adenine content was equal to the thymine content and cytosine was equal to guanine. Also the aromaticity of the electron-rich purine and pyrimidine rings allowed for tautomer shifts between the keto and enol form. The keto tautomer (lactam) dominated at physiological pH. Garnering all this information, James Watson and Francis Crick discovered the structure of DNA (double-helix) in 1953.
Structure of DNA and RNA
[edit | edit source]DNA is a polymer of nucleotides. Nucleotides consist of a pentose sugar (2-deoxyribose for DNA and ribose for RNA), a phosphate group (), and a nitrogen-containing base. There are five nitrogen bases - adenine, guanine, thymine, cytosine and uracil. Individual nucleotides are connected by phosphodiester bonds to form polynucleotides.

{kind=link}

DNA exists as a double helix of two (2) strands of polynucleotides. According to the principle of complementarity nucleotides A (adenine) bases are bound with a hydrogen bridge to the T (thymine) or U (uracil in case of RNA) on the other thread and similarly C (cytosine) bind themselves to G (guanine). This principle allows for DNA and RNA replication and for limited possibilities of repairing the genetic information when one of the threads gets damaged.
Difference between DNA and RNA
[edit | edit source]DNA is the permanent genetic information storage medium, found in the nucleus of most cells of most living organisms. RNA is, in the case of eukaryotes, the medium that transfers the genetic information from the nucleus to the cytoplasm where proteins are synthesized. The most basic structural difference between a DNA molecule and an RNA molecule is that DNA lacks an hydroxyl group at its 2' carbon while RNA has an hydroxyl group at its 2' carbon.
There are three major types of RNA:
- messenger RNA (mRNA) - temporarily created RNA used for transferring the information from the DNA in the nucleus to the ribosome in the cytoplasm where it is "read," or translated, and a protein is synthesized.Each gene produce a separate mRNA molecule when a certain protein is needed in the cell. In addition, the size of an mRNA depends on the number of nucletides in that particular gene.
- transfer RNA (tRNA) - Is the smallest of the RNA molecules and it is associated with the ribosome and delivers an amino acid to be attached to the growing protein. Only the tRna can translate the genetic information into amino acid for proteins.
Each tRNA contains an "anticodon" which is a series of 3 bases that complements 3 bases on mRNA.
- ribosomal RNA (rRNA) - a major constituent of the ribosome with both structural and catalytic properties.
Additionally, by 2005, other types of RNA, such as siRNA (small, interfering RNA) and miRNA have been characterized.
DNA structure is typically a double stranded molecule with long chain of nucleotides, while RNA is a single stranded molecule " in most biological roles" and it has shorter chain of nucleotide. Deoxyribose sugar in DNA is less reactive because of the carbon- hydrogen bonds. DNA has small grooves to prevent the enzymes to attack DNA. on the other hand, RNA contain ribose sugar which is more reactive because of the carbon-hydroxyl bonds. RNA not stable in its alkaline conditions.RNA has larger grooves than that of DNA, which makes RNA easier to be attacked by enzymes. DNA has a unique features because of its helix geometry which is in B-form. DNA is protected completely by the body in which the body destroys any enzymes that cleave DNA. In contrast the helix geometry of RNA is in the A- form; RNA can be broken down and reused. RNA is more resistance to be damage by Ultra- violet rays, while DNA can be damaged if exposed to Ultra-violet rays. DNA can be found in nucleus, while RNA can be found in nucleus and cytoplasm. The bases of DNA are A,T,C,and G, DNA is a long polymer with phosphate and deoxyribose backbone. In contrast, RNA bases are A,U, C,and G, RNA backbone contain ribose and phosphate. The job of DNA on the cell is to store and transmit genetic information. RNA job is to transfer the genetic codes that are needed for the creation of proteins from the nucleus to the ribosome, this process prevents the DNA from leaving the nucleus, so DNA stays safe.
Plasmid
[edit | edit source]Plasmids are small, circular DNA molecules that replicate separately from the much larger bacterial chromosome can be use in laboratory to manipulate genes. Plasmids can carry almost any gene and they can passed it on from one generation of bacteria to the next generation, therefore plasmids are key tools for “gene cloning” which is the production of multiple identical copies of a gene carrying piece of DNA
DNA Replication ;Semi-conservative replication
[edit | edit source]In the process of DNA replication, as cells divide, copies of DNA must be produced in order to transfer the genetic information. In DNA replication, the strands in the original DNA separate, and then each of the parent strands make copies by synthesizing complementary strands. Enzyme called helicase will start The process of replication by catalyzing the unwinding of protein of the double helix. This enzyme can break the H bonds between the complementary bases. These single strands now act as templates for the synthesis of new complementary strands. The energy for the reaction can be provided when a nucleoside triphosphate bonds to a sugar (at the end of a growing strand), and 2 phosphate group are cleaved. Then a T in the template forms H bond with an A in ATP, and a G on the template forms H bond with CTP. After the entire double helix of the parent DNA is copied, the new DNA molecule will form . The new DNA molecule is consist of one strand from the parent (original) DNA and one strand from the daughter strand( newly synthesized strand). This process is called "semi-conservative replication".
Recombination
[edit | edit source]Recombination refers to ways in which DNA modification leads to distinct gene expressions and functions. Deletions, insertions and substitutions are the most useful changes implemented for the synthesis of new genes. Recombination techniques and recombinant DNA technologies has made possible the modification and creation of new genes for specific proposes. These techniques helps clone, amplified and introduce new DNA into suitable cells for replication. Restriction enzymes and DNA ligase play a vital role in the production of recombinant DNA. Vectors are useful for cloning. Plasmids or viral DNA (lambda Phage) used to introduced a DNA sequence into a cell is refer as vector.
The semi-conservative hypothesis was confirmed by both Matthew Meselson and Franklin Stahl in 1958. The parent DNA was labeled with "heavy nitrogen," the radioisotope of fifteen. This radioactive nitrogen was made through growing E. coli with ammonium chloride (also with "heavy nitrogen") environment. Directly after the labeling of "heavy nitrogen" to the parent DNA strand, it was transferred to a medium with only regular nitrogen (isotope of fourteen). The proposed question was "What is the distribution between the two nitrogens in the DNA molecules after successive rounds of replication?" Using density-gradient equilibrium sedimentation, this question was answered. In this centrifugation, similar densities were grouped together in the tube. Afterwards, an absorbance was applied with ultra-violet light to determine the density bands of all the different kinds of DNA in the solution. After one generation, a unique single density band was shown. It was not exactly the band of heavy nitrogen nor the regular band of regular nitrogen, but rather halfway between the two. This proved that DNA was not conservative but semi-conservative due to this nitrogen hybrid. One generation after this one, there were two nitrogen-14 molecules and two hybrid nitrogen molecules. The probability and statistics of this second generation reassures the semi-conservative hypothesis.
As DNA strands can combine and form molecules, it can also be melted, resulting in separation or denaturation. It is important to note that the heat from the melting process does not disrupt the DNA structure, but rather DNA helicase takes energy from the heat, separating the DNA strands. The denaturation process occurs at about ninety-four degrees Fahrenheit where the double strands are converted to single stands. Absorbance readings were taken to reconfirm the denaturation process. When the DNA molecule is in its double-stranded form, it absorbs less UV light. In its single-stranded form, it absorbs more UV light because the single strand is more exposed than its double-strand counterpart. This is known as the hypochromic effect. In a PCR, polymerase chain reaction, it utilizes this denaturation capability in its primary step. Afterwards, it is then annealed at fifty to sixty degrees Fahrenheit. In this step, this is where the primers bind to their corresponding flanking DNA base sequence. In the last step, DNA polymerization, it requires a few ingredients: heat-resistant DNA polymerase, magnesium ion, buffer, and corresponding nucleotides. The DNA polymerase requires heat resistance because throughout the entire process, it undergoes a constant temperatures changes. The magnesium stabilizes the phosphate backbone. The buffer prevents drastic changes in pH, because if the pH lies near the extremes on the scale, it may denature the DNA so drastically that it will not recombine. This final step of DNA polymerization happens at the "melting temperature." The melting temperature is the temperature at which half of the DNA is single-stranded and the other half is double-stranded. At this optimal temperature of seventy-two degrees Fahrenheit, the DNA is amplified with its respective primers, replicating at an exponential rate.
DNA manipulation: human's effort to desire DNA and "read" DNA
[edit | edit source]Restriction endonucleases
[edit | edit source]What's endonuclease?--Endonucleases are enzymes that can recognize specific base sequences in double-helical DNA and cleave, at specific places, both strands of that duplex. Many prokaryotes contain restriction enzymes. Biologically, they cleave foreign DNA molecules. Because the sites recognized by its own restriction enzymes are metylated, the cells' own DNA are not cleaved. One striking properties of endonucleases is that they recognize DNA cleavage sites by "two-fold symmetry". In another word, within the cleavage site domain (usually 4 to 8 base pair), there exists a center, around which the cleavage site rotate 180 degree, the whole cleavage site would be indistinguishable. The following graph shows an example of how endonuclease recognize cleavage site by symmetry..After cleavage from several different endonulcease, a DNA sample would be sliced into many different duplex fragments, which are then separated by electrophoresis. The restriction fragments are then denatured to form single stranded DNA, which are then transferred to a nitrocellulose sheet, where they are exposed to a 32P-labeled single-stranded DNA probe. The single-stranded DNA are then hybridized by the radio active complementary strand. These duplex are then examined by autoradiography, which reveals the sequence of the DNA. This technique is named Southern plot, after Edwin South, who invented the technique. The following image shows the steps for creating a southern plot.
DNA sequencing
[edit | edit source]DNA subunits are dGMP, dAMP, dCMP and dTMP. In a DNA molecule, these subunits are connected in a way that their phosphate on 5 prime carbon are bonded to another subunit's hydroxy group on 3 prime carbon. If there is no hydroxy group on 3 prime carbon, then the DNA polymeration will be terminated. Utilizing this idea, subunit analogies were invented, ddGMP, ddAMP, ddCMP and ddTMP. These analogies have the same structure as their parent molecule except that they have hydrogen on 3 prime carbon instead of hydroxyl group. In practice, target DNA template is put into four polymeration environments, dNTP+ddGMP or ddAMP or ddCMP or ddTMP, respectively.. Statically, fragments with different length terminated at base, G, A, C, T will be formed, respectively. Then these fragments will be separated by electrophoresis, which will tell the sequence of the target DNA.
DNA synthesis
[edit | edit source]Although nature synthesize DNA from 5 prime carbon to 3 prime carbon, human synthesize DNA from 3 prime carbon to 5 prime carbon. The following monomer is commercially available for each of the base and is used as basic building block for DNA synthesis. It starts with the subunit with the first base bonded to resin by the 3 prime hydroxyl group. The second monomer with its own 5 hydroxyl protected by DMT (protecting group) was activated on its 3 prime phosphate, which is attached to the 5 prime hydroxyl group by nucleophilic substitution. Then the phosphite is oxidized by iodine to yield phosphate. Then DMT is removed to make the 5 prime hydroxyl available for the incoming of the third monomer. The graphical representation is shown below.
Polymerase Chain Reaction (PCR)
[edit | edit source]It is used for amplification of DNA. It includes three stages: DNA denaturation, oligonucleotide annealing, and DNA polymerization. In each cycle, the DNA duplex is denatured at first, then the primers for both strands (forward and reverse) bind to the desired sites and at last both strands polymerize to form the desired sequence. What needed in PCR are the DNA containing the desired sequence, primers for both strands, heat resistant DNA polymerase, dNTP and constantly changing temperature. The following image shows the detailed steps in PCR.

RNA Editing
[edit | edit source]Introduction
[edit | edit source]Adenosine deaminases (ADAR) are mRNA editing enzymes that alternate a double stranded RNA sequence by tuning it. When tuning the mRNA, ADARs retype the nucleotides of the mRNA at certain, specific points they wish to change. Because ADARs can change the sequence of mRNA, they can create or remove a splice site, delete or alter the meaning of a codon, and finally change the sequence of the RNA altogether. ADAR plays a vital part in editing mRNA and modulating the mRNA translational activity and is mainly found in the nervous system and is important in regulating the nervous systems. Lacking the ADAR gene is very detrimental to health.
Function
[edit | edit source]
RNA splicing and RNA editing are very similar to one another. RNA splicing is more of a cut, copy, and past process while RNA editing is an alteration of one or more nucleotides. There are mainly two types of ADAR that alternate the sequence of a single nucleotide. The first type of ADAR retypes cytidine nucleotides into uridine nucleotides while a second type of ADAR retypes adenosine into inosine.
mRNA consisting of many inosine nucleotides in its sequence is known to be very abundant in the nucleus and only mRNAs that leave the nucleus can be translated. In this case, ADAR is modulating the translational activities of mRNAs. In modulating the translational activities of the specified mRNA, it is also modulating the abundance of the certain proteins that are expressed in the edited mRNA. Also, increasing inosine can stabilize the structure of mRNA. Hence, ADAR can function as an mRNA stabilizer too.
ADARs target the coding sequence, introns, and 5’ and 3’ untranslated reigions (UTR). ADAR targets the coding sequence by changing the nucleotide which then changes the geometry of the protein. Change in the geometry of the protein may yield to higher protein-protein affinity interaction. This high protein-protein affinity can improve biological reactions by facilitating those reactions. Alternation of the non-coding sites such as introns, 5’, and 3’ UTR is still unknown. The only thing that is known is that alternating the sequence within these sites can create new splice sites.
Importance of ADAR
[edit | edit source]
Adar is mainly found in the nervous system because it plays a very important role in regulating the nervous system. One of Adars’ primary functions is its regulation of the nervous system. Adar regulates the nervous system by editing the glutamate receptors’ mRNA. These glutamate receptors construct the glutamate-gated ion channels which are important in transferring electrical signals between neurons. When ADARs edit gluR mRNA, they change the calcium permeability of these glutamate channels. They can either lower the calcium permeability for certain glutamate channel or increase calcium permeability for other glutamate channels. Regulation of calcium permeability is important to proper neurotransmission between neurons.
Disease connecting to ADAR
[edit | edit source]
Adenosine deaminase Deficiency (ADD) is caused by the lack of ADAR gene. Hence ADARs editing is important for survival especially for human. Without ADAR, the body can not break down the toxin deoxyadenosine. The accumulation of this toxin destroys the immune cells making its host vulnerable to infection from bacteria and viruses.
Seizures can also be caused by ADAR. Unedited version of gluR mRNA strongly causes seizures. When a seizure happens, the body mechanism increases the level of ADAR activity to edit gluR mRNA to prevent future seizures.
DNA Replication:Initiation
[edit | edit source]
There are multiple mechanisms that have been proposed for the melting of the DNA strand and the subsequent unwinding of the double helix during the initiation process of DNA replication.
Two recently proposed models are E1 and LTag. These two models function differently to attain the same overall goal of melting the DNA double helix due to differences in their overall structure.
E1 model: In the E1 hexamer, there are six ß-hairpins in the central channel of the protein. They are arranged in a staircase-like structure. Two adjacent E1 trimers assemble at the origin point to melt the double-stranded DNA. A ring shaped E1 hexamer is then formed around the melted single-stranded DNA and the DNA is then pumped through the ring hexamer to from a fork that allows for the replication of the DNA.
Ltag: The channel diameters of these hexamers vary between 13-17 angstroms. The hexamer responsible for melting has an assortment of planar ß-hairpins in the narrow channel. Two of these hexamers surround the origin point of the double-stranded DNA and squeeze the area together. This causes the melting of the dsDNA by forcing the breakage of base pairing. The two single-stranded DNA strands are then pumped into a larger channeland finally out through two separate Zn-domains. This allows for the replication of the DNA.
The two mechanisms here are built solely on the structural knowledge of the proteins involved in the process and as such more experimental support is needed to confirm.
There are not an excessive amount of helicases. Currently, work is being done in discerning the more simple helicases, and trying to find the different mechanisms that they may have. While there are some similarities, for example helicases all seem to have a hexameric structure, there are also differences as well in their structures that contribute greatly to the differences in their mechanisms.
-This article refers to a recently published article in Curr Opin Struct Biol. published 2010, Sep. 24.: "Origin DNA melting and unwinding in DNA replication" by Gai et al.
Respiratory Pigments
[edit | edit source]In humans, these pigments include hemoglobin and myoglobin, the latter is present in red muscle fibers. Hemoglobin is a coordination compound of iron. It had attachment sites for gases, namely oxygen and carbon dioxide. Its reactivity depends upon partial pressure of these gases. The presence of heme makes it appear red colored. Myoglobin is present in muscles to make available extra oxygen.
Cell Signaling Pathways
[edit | edit source]Biochemistry/Cell Signaling Pathways
Bioinformatics
[edit | edit source]Homology
[edit | edit source]When scientists study the relationship between proteins between different species they must determine whether or not these proteins are homologous to one another. Homologous proteins are proteins that have a common ancestor. There are two classes of homologs. They are ortholog and paralog. Orthologs are homologous proteins that are found among different species but have similar function. Orthologs occurs due to speciation. Paralog are homologous proteins that are found within the same species. They have very similar structure but serve different functions within the organism. Paralogs are due to gene duplication within the specie. Scientists finds out whether the proteins are homologous or not by studying the DNA sequence, amino acid sequence, the tertiary structure of the protein. In other word, they study the sequence alignment and structural alignment of the protein.
Sequence Alignment
[edit | edit source]When analyzing the DNA sequence or the amino acid sequence similarity and differences , scientists study the alignment of the DNA sequence or the alignment of the amino acid alignment of the protein. Alignment of DNA sequences is less sensitive to that of the alignment of amino acid. DNA sequence only consists of 4 bases. This means that the chance that both residues are the same is 1 out of 4. For the amino acid sequence, the chance that both residues are the same is 1 out of 21. The scoring of the degree of similarity of the alignment of each case is determined by Matrix. There are a variety of methods in order to determine the optimal alignment of nucleotide sequences. One famous method is determined by the Needleman Wunsch algorithm.
Matrix
[edit | edit source]Matrix is a method used to determine the degree or similarity between the sequences (DNA or Amino Acid). Matrix takes account of two factors which are conservation and frequency.
Conversation determines whether or not a certain residue can substitute for another residue by comparing the residue’s physical factors such as their hydrophobicity, charge, and size. For example if two residues are both hydrophobic they may substitute for each other. If two residues have different charges, chance that they can substitute for one another is very slim.
Frequency states how often a residue occurs. For example, if sequence A has a 20% of residue A and 30% of residue B and if sequence B has 21% of residue A and 35% of residue B, these residues A and B prevalence may indicate that these sequences are related to one another.
The techniques used by matrix are the sliding between sequences, the gap introduced within the sequence, and the deletion of certain residues within the sequence. This method is used in order to improve the alignment’s similarity. In sliding, one sequence is sided in reference to the other. For example after the sliding the sequence by one residue, the similarity between the sequences may increase because more residues are identical or similar to one another. Gaps are introduces within the sequence in order to increase the residue similarity. For example if a sequence A have this particular range of residues that are not important or critical to its function or structure but have an important residue rang after the non-important residue range and the other sequence B lacks the sequence unimportant residue range but does have the same important residue range of sequence A. Then a gap is introduces in sequence B in order to make for the non important residue range. For deletion, certain residues are omitted in the sequence. Unimportant residues are usually deleted in order to increase the similarity between the sequences.
There are two types of matrices. They are identity matrix and substitution matrix. Identity matrix only assign points to residues that are identical where as substitution may assign points to residues that are different yet alike in a conservative perspective. Substitution matrix are more accurate than that of identity matrix because in taking account for conservation substitution, substitution matrix give large positive score to the sequence where frequent substitution occur and large negative score where rare substitution occur . Hence substitution matrix is more sensitive to that of the identity matrix.
Structural Alignment
[edit | edit source]Structural alignment is the analysis of the degree of similarity between primary, secondary and tertiary structure. In protein, the tertiary structure is more conserved than that of primary structure because tertiary structure is more closely related to the protein’s function. The purpose of structural alignment is to improve sequence alignment (method discussed before this) by creating a sequence template. Since some regions are more conserved than other, sequence template is template that maps out the conserved amino acid residues that are structurally and functionally important to a particular protein family member. Hence sequence template helps find protein that belongs to certain family member.
SIRCh Link for Bioinformatics (Selected Internet Resourcess)