
Web Speech API mới giúp bạn dễ dàng thêm tính năng nhận dạng lời nói vào các trang web. API này cho phép kiểm soát chính xác và linh hoạt đối với các chức năng nhận dạng lời nói trong Chrome phiên bản 25 trở lên. Dưới đây là một ví dụ với văn bản được nhận dạng xuất hiện gần như ngay lập tức khi đang nói.
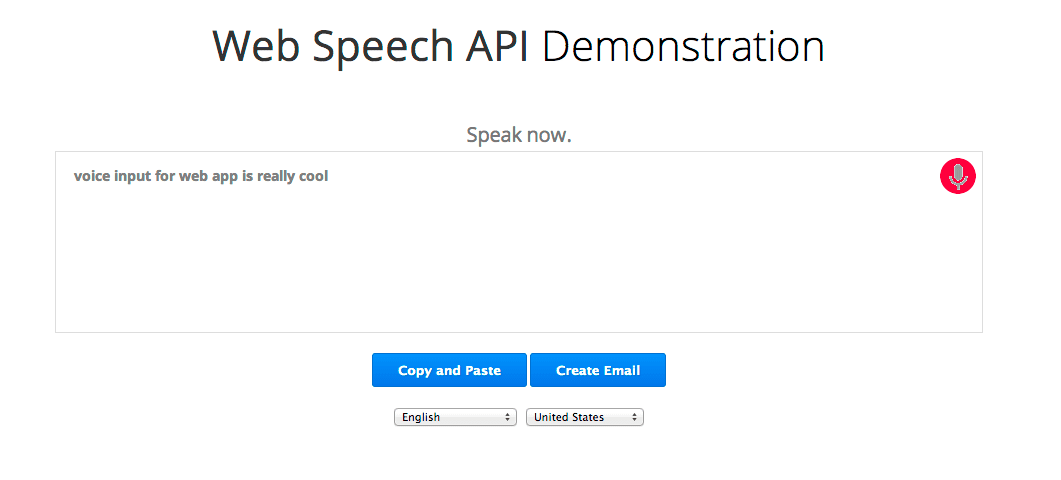
Hãy cùng tìm hiểu sâu hơn. Trước tiên, chúng ta sẽ kiểm tra xem trình duyệt có hỗ trợ Web Speech API hay không bằng cách kiểm tra xem đối tượng webkitSpeechRecognition có tồn tại hay không. Nếu không, người dùng nên nâng cấp trình duyệt của mình. (Vì vẫn đang trong quá trình thử nghiệm nên API này hiện đang được nhà cung cấp sử dụng tiền tố.) Cuối cùng, chúng ta tạo đối tượng webkitSpeechRecognition cung cấp giao diện lời nói cũng như thiết lập một số thuộc tính cũng như trình xử lý sự kiện của đối tượng đó.
if (!('webkitSpeechRecognition' in window)) {
upgrade();
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
recognition.onend = function() { ... }
...
Giá trị mặc định của continuous là false, nghĩa là khi người dùng ngừng nói, tính năng nhận dạng lời nói sẽ ngừng hoạt động. Chế độ này phù hợp với văn bản đơn giản như các trường nhập dữ liệu ngắn. Trong bản minh hoạ này, chúng ta đã đặt giá trị này thành true để quá trình ghi nhận tiếp tục diễn ra ngay cả khi người dùng tạm dừng trong khi nói.
Giá trị mặc định của interimResults là false, nghĩa là kết quả duy nhất mà trình nhận dạng trả về là kết quả cuối cùng và sẽ không thay đổi. Bản minh hoạ thiết lập giá trị này là true (đúng) để chúng tôi nhận được kết quả sớm và kết quả tạm thời có thể thay đổi. Hãy xem kỹ bản minh hoạ, văn bản màu xám là văn bản tạm thời và đôi khi thay đổi, trong khi văn bản màu đen là phản hồi của trình nhận dạng, được đánh dấu là cuối cùng và sẽ không thay đổi.
Để bắt đầu, người dùng nhấp vào nút micrô. Nút này sẽ kích hoạt mã này:
function startButton(event) {
...
final_transcript = '';
recognition.lang = select_dialect.value;
recognition.start();
Chúng tôi đặt ngôn ngữ nói cho trình nhận dạng lời nói "lang" vào giá trị BCP-47 mà người dùng đã chọn thông qua danh sách thả xuống lựa chọn, ví dụ: "en-US" cho tiếng Anh (Mỹ). Nếu bạn không đặt thuộc tính này, thì chế độ mặc định sẽ được đặt thành ngôn ngữ của hệ phân cấp và thành phần gốc trong tài liệu HTML. Tính năng nhận dạng lời nói của Chrome hỗ trợ nhiều ngôn ngữ (xem bảng “langs” trong nguồn minh hoạ), cũng như một số ngôn ngữ viết từ phải sang trái không có trong bản minh hoạ này, chẳng hạn như he-IL và ar-EG.
Sau khi đặt ngôn ngữ, chúng ta gọi recognition.start() để kích hoạt trình nhận dạng lời nói. Khi bắt đầu ghi âm, nó sẽ gọi trình xử lý sự kiện onstart. Sau đó, đối với mỗi tập hợp kết quả mới, nó sẽ gọi trình xử lý sự kiện onresult.
recognition.onresult = function(event) {
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
final_span.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
}
Trình xử lý này nối tất cả kết quả nhận được cho đến thời điểm hiện tại thành hai chuỗi: final_transcript và interim_transcript. Chuỗi kết quả có thể bao gồm "\n", chẳng hạn như khi người dùng nói "đoạn mới", vì vậy chúng ta sử dụng hàm linebreak để chuyển đổi các chuỗi này thành thẻ HTML <br> hoặc <p>. Cuối cùng, hàm này đặt các chuỗi này làm innerHTML của các phần tử <span> tương ứng: final_span được tạo kiểu bằng văn bản màu đen và interim_span được tạo kiểu bằng văn bản màu xám.
interim_transcript là một biến cục bộ và được tạo lại hoàn toàn mỗi khi sự kiện này được gọi vì có thể tất cả kết quả tạm thời đã thay đổi kể từ sự kiện onresult gần đây nhất. Chúng ta có thể làm tương tự cho final_transcript chỉ bằng cách bắt đầu vòng lặp for từ 0. Tuy nhiên, vì văn bản cuối cùng không bao giờ thay đổi, nên chúng ta đã làm cho mã ở đây hiệu quả hơn một chút bằng cách đặt final_transcript thành một thuộc tính chung để sự kiện này có thể bắt đầu vòng lặp for tại event.resultIndex và chỉ thêm bất kỳ văn bản cuối cùng mới nào.
Vậy là xong! Phần mã còn lại chỉ là để làm cho mọi thứ trông đẹp mắt. Chế độ này sẽ duy trì trạng thái, hiển thị cho người dùng một số thông báo cung cấp thông tin và hoán đổi hình ảnh GIF trên nút micrô giữa micrô tĩnh, hình ảnh dấu gạch chéo và ảnh động micrô với chấm đỏ nhấp nháy.
Hình ảnh dấu gạch chéo đôi sẽ xuất hiện khi recognition.start() được gọi, sau đó được thay thế bằng micrô-animate khi onstart kích hoạt. Thông thường, điều này xảy ra quá nhanh đến mức không nhận thấy dấu gạch chéo. Tuy nhiên, vào lần đầu tiên sử dụng tính năng nhận dạng lời nói, Chrome cần phải xin phép người dùng để có quyền sử dụng micrô. Trong trường hợp đó, onstart chỉ kích hoạt khi và nếu người dùng cho phép. Các trang được lưu trữ trên HTTPS không cần phải yêu cầu cấp quyền nhiều lần, trong khi các trang được lưu trữ trên HTTP thì có.
Vì vậy, hãy làm cho trang web của bạn trở nên sống động bằng cách cho phép chúng lắng nghe ý kiến của người dùng!
Chúng tôi rất mong nhận được ý kiến phản hồi của bạn...
- Đối với nhận xét về thông số kỹ thuật của W3C Web Speech API: email, bản lưu trữ thư, nhóm cộng đồng
- Đối với các nhận xét về việc triển khai thông số kỹ thuật này của Chrome: email, lưu trữ thư
Tham khảo Sách trắng về quyền riêng tư của Chrome để tìm hiểu cách Google xử lý dữ liệu giọng nói từ API này.