
새로운 JavaScript Web Speech API를 사용하면 웹페이지에 음성 인식을 쉽게 추가할 수 있습니다. 이 API를 사용하면 Chrome 버전 25 이상에서 음성 인식 기능을 세밀하게 제어하고 유연하게 조정할 수 있습니다. 다음 예에서는 말하는 동안 인식된 텍스트가 거의 즉시 표시됩니다.
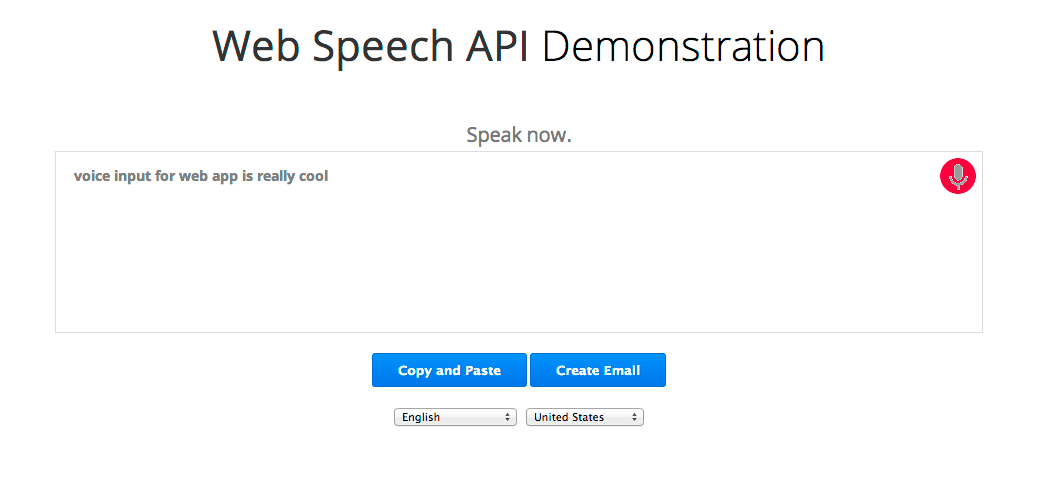
자세히 살펴보겠습니다. 먼저 webkitSpeechRecognition 객체가 있는지 확인하여 브라우저가 Web Speech API를 지원하는지 확인합니다. 그렇지 않은 경우 사용자가 브라우저를 업그레이드하는 것이 좋습니다. API는 아직 실험 단계이므로 현재 공급업체에서 프리픽스를 사용합니다. 마지막으로 음성 인터페이스를 제공하는 webkitSpeechRecognition 객체를 만들고 일부 속성 및 이벤트 핸들러를 설정합니다.
if (!('webkitSpeechRecognition' in window)) {
upgrade();
} else {
var recognition = new webkitSpeechRecognition();
recognition.continuous = true;
recognition.interimResults = true;
recognition.onstart = function() { ... }
recognition.onresult = function(event) { ... }
recognition.onerror = function(event) { ... }
recognition.onend = function() { ... }
...
continuous의 기본값은 false입니다. 즉, 사용자가 말을 중지하면 음성 인식이 종료됩니다. 이 모드는 짧은 입력란과 같은 간단한 텍스트에 적합합니다. 이 데모에서는 true로 설정하여 사용자가 말하는 동안 잠시 멈추더라도 인식이 계속되도록 합니다.
interimResults의 기본값은 false입니다. 즉, 인식기에서 반환된 유일한 결과만 최종 결과이며 변경되지 않습니다. 데모에서는 이 값을 true로 설정하므로 변경될 수 있는 중간 결과를 조기에 얻을 수 있습니다. 데모를 주의 깊게 살펴보세요. 회색 텍스트는 임시로 사용되어 때때로 변경되는 반면 검은색 텍스트는 최종으로 표시되고 변경되지 않는 인식기의 응답입니다.
시작하려면 사용자가 마이크 버튼을 클릭하면 다음 코드가 트리거됩니다.
function startButton(event) {
...
final_transcript = '';
recognition.lang = select_dialect.value;
recognition.start();
음성 인식기 'lang'의 음성 언어를 설정합니다. 를 사용자가 선택 드롭다운 목록을 통해 선택한 BCP-47 값으로 대체합니다(예: 영어-미국의 경우 'en-US'). 설정하지 않으면 HTML 문서 루트 요소 및 계층 구조의 lang이 기본값이 됩니다. Chrome 음성 인식은 다양한 언어(데모 소스의 'langs' 표 참고)뿐만 아니라 이 데모에 포함되지 않은 오른쪽에서 왼쪽으로 쓰는 언어(예: he-IL, ar-EG)도 지원합니다.
언어를 설정한 후 recognition.start()를 호출하여 음성 인식기를 활성화합니다. 오디오 캡처를 시작하면 onstart 이벤트 핸들러를 호출하고, 새로운 결과 세트마다 onresult 이벤트 핸들러를 호출합니다.
recognition.onresult = function(event) {
var interim_transcript = '';
for (var i = event.resultIndex; i < event.results.length; ++i) {
if (event.results[i].isFinal) {
final_transcript += event.results[i][0].transcript;
} else {
interim_transcript += event.results[i][0].transcript;
}
}
final_transcript = capitalize(final_transcript);
final_span.innerHTML = linebreak(final_transcript);
interim_span.innerHTML = linebreak(interim_transcript);
};
}
이 핸들러는 지금까지 수신된 모든 결과를 final_transcript와 interim_transcript의 두 문자열로 연결합니다. 결과 문자열에는 '\n'이 포함될 수 있습니다(예: 사용자가 '새 단락'을 말할 때). 따라서 linebreak 함수를 사용하여 이러한 문자열을 HTML 태그 <br> 또는 <p>로 변환합니다. 마지막으로 이러한 문자열을 상응하는 <span> 요소의 innerHTML로 설정합니다. 검은색 텍스트로 스타일이 지정된 final_span와 회색 텍스트로 스타일이 지정된 interim_span를 설정합니다.
interim_transcript는 로컬 변수이며, 이 이벤트가 호출될 때마다 완전히 다시 빌드됩니다. 마지막 onresult 이벤트 이후 모든 중간 결과가 변경되었을 수 있기 때문입니다. for 루프를 0에서 시작하면 final_transcript에도 동일한 작업을 할 수 있습니다. 그러나 최종 텍스트는 변경되지 않으므로 final_transcript를 전역으로 만들어 코드를 좀 더 효율적으로 만들었습니다. 따라서 이 이벤트가 event.resultIndex에서 for 루프를 시작하고 새로운 최종 텍스트만 추가할 수 있습니다.
완료되었습니다. 나머지 코드는 모든 것을 멋지게 만들기 위해 존재합니다. 상태를 유지하고 사용자에게 유용한 메시지를 표시하며 마이크 버튼의 GIF 이미지를 정적 마이크, 마이크 슬래시 이미지 및 깜빡이는 빨간색 점으로 mic-animated 사이에서 전환합니다.
마이크 슬래시 이미지는 recognition.start()가 호출될 때 표시되고 onstart가 실행되면 mic-animate로 대체됩니다. 일반적으로 이런 일이 너무 빠르게 진행되어 슬래시가 눈에 띄지 않지만 음성 인식을 처음 사용할 때는 Chrome에서 사용자에게 마이크 사용 권한을 요청해야 합니다. 이 경우 사용자가 권한을 허용하는 경우에만 onstart가 실행됩니다. HTTPS로 호스팅되는 페이지에서는 권한을 반복적으로 요청할 필요가 없는 반면, HTTP 호스팅 페이지에서는 권한을 요청할 필요가 없습니다.
사용자의 말을 들을 수 있도록 하여 웹페이지에 생동감을 불어넣으세요.
여러분의 의견을 기다립니다...
Google에서 이 API의 음성 데이터를 처리하는 방법을 알아보려면 Chrome 개인 정보 보호 백서를 참고하세요.