Python for R users
•Download as PPTX, PDF•
4 likes•898 views

Python provides similar functionality to R for data analysis and machine learning tasks. Key differences include using import statements to load packages rather than library, and minor syntactic variations such as brackets [] instead of parentheses (). Common data analysis operations like reading data, creating data frames, applying machine learning algorithms, and visualizing results can be performed in both languages.







![Functions R Python
Getting quick summary(like
mean, std. deviation etc. ) of data in
the data frame “df”
summary(df)
returns mean, median , maximum, minimum, first quarter and
third quarter
df.describe()
returns count, mean, standard
deviation, maximum, minimum, 25%,
50% and 75%
Getting a compact view of the data
structure of the object.
str(df) df.info()
To check for all available methods
for the object.
isS4(object_name)
# to check if the object is S4 type
is(object_name, 'refClass')
# to check if the object is RC type
# if both are false then object is of S3 type:
methods(class = class(object_name))
# if object is of S4 type:
showMethods(classes = class(object_name))
dir(diamonds)
Setting row names and columns
names of the data frame “df”
rownames(df) = c("A", "B", "C", "D", "E", "F")
colnames(df) = c("P", "Q", "R", "S")
df.index=[“A”, ”B”, “C”, ”D”,
“E”, ”F”]
df.columns=[“P”, ”Q”, “R”, ”S”]
Data Frame: Inspecting and Viewing Data](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-8-320.jpg)

![Functions R Python
Sorting the data in the data
frame “df” by column name “P”
df[order(df$P),] df.sort_values(by=['P'])
This command is deprecated:
df.sort(['P'])
Data Frame: Sorting Data](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-10-320.jpg)

![Functions R Python
Slicing the rows of a data frame
from row no. “x” to row no.
“y”(including row x and y)
df[x:y,] df[x1:y]
Python starts counting from 0
Slicing the columns name “X”,”Y” etc. of
a data frame “df”
myvars < c(“X”,”Y”)
newdata < df[myvars]
df.loc[:,[‘X’,’Y’]]
Selecting the the data from row no. “x”
to “y” and column no. “a” to “b”
df[x:y,a:b] df.iloc[x1:y,a1:b]
Selecting the element at row no.
“x” and column no. “y”
df[x,y] df.iat[x1,y1]
Selecting column of the data frame df$column_name df.column_name
Data Frame: Data Selection](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-12-320.jpg)

![Functions R Python
Using a single column’s
values to select data, column
name “A”
subset(df,A>0) df[df.A > 0]
It will select the all the rows in which the
corresponding value in column A of that
row is greater than 0
df[df.A > 0]
It will do the same as the R function
Data Frame: Data Selection
R Python](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-14-320.jpg)



![Functions R
Python
(import math and numpy library)
Convert character variable to numeric variable as.numeric(x) For a single value: int(x), long(x), float(x)
For list, vectors etc.: map(int,x), map(float,x)
Convert factor/numeric variable to character
variable
paste(x) For a single value: str(x)
For list, vectors etc.: map(str,x)
Check missing value in an object is.na(x) math.isnan(x)
Delete missing value from an object na.omit(list) cleanedList = [x for x in list if str(x) != 'nan']
Calculate the number of characters in character
value
nchar(x) len(x)
Data Manipulation](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-19-320.jpg)

![Functions
R
(import lubridate library)
Python
(import datetime library)
Scatter Plot plot(variable1,variable2) import matplotlib.pyplot as plt
plt.scatter(variable1,variable2)
plt.show()
Boxplot boxplot(Var) plt.boxplot(Var)
plt.show()
Histogram hist(Var) plt.hist(Var)
plt.show()
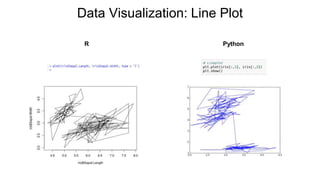
Line Plot plot(var1, var2, type = 'l') plt.plot(var1, var2)
plt.show()
Bubble Plot symbols(var1, var2, circles = var3,
inches = 0.2)
plt.scatter(var1, var2, s = var3*200)
plt.show()
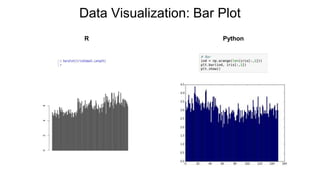
Bar Plot barplot(var) plt.bar(np.arange(len(var)), df[:,1])
plt.show()
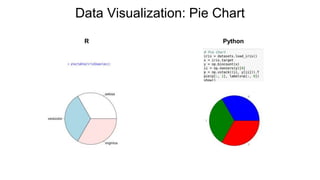
Pie Chart pie(Var) from pylab import *
pie(Var)
show()
Data Visualization](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-21-320.jpg)








![R(Using svm* function) Python(Using sklearn** library)
library(e1071)
data(iris)
trainset <iris[1:149,]
testset <iris[150,]
svm.model < svm(Species ~ ., data =
trainset, cost = 100, gamma = 1, type= 'C classification')
svm.pred< predict(svm.model,testset[5])
svm.pred
#Loading Library
from sklearn import svm
#Importing Dataset
from sklearn import datasets
#Calling SVM
clf = svm.SVC()
#Loading the package
iris = datasets.load_iris()
#Constructing training data
X, y = iris.data[:1], iris.target[:1]
#Fitting SVM
clf.fit(X, y)
#Testing the model on test data
print clf.predict(iris.data[1])
Output: Virginica Output: 2, corresponds to Virginica
*To know more about svm function in R visit: http://cran.r-project.org/web/packages/e1071/
**To install sklearn library visit : http://scikit-learn.org/, To know more about sklearn svm visit: http://scikit-
learn.org/stable/modules/generated/sklearn.svm.SVC.html
Machine Learning: SVM on Iris Dataset](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-33-320.jpg)
![R(Using lm* function) Python(Using sklearn** library)
data(iris)
total_size<dim(iris)[1]
num_target<c(rep(0,total_size))
for (i in 1:length(num_target)){
if(iris$Species[i]=='setosa'){num_target[i]<0}
else if(iris$Species[i]=='versicolor')
{num_target[i]<1}
else{num_target[i]<2}
}
iris$Species<num_target
train_set <iris[1:149,]
test_set <iris[150,]
fit<lm(Species ~ 0+Sepal.Length+ Sepal.Width+
Petal.Length+ Petal.Width , data=train_set)
coefficients(fit)
predict.lm(fit,test_set)
from sklearn import linear_model
from sklearn import datasets
iris = datasets.load_iris()
regr = linear_model.LinearRegression()
X, y = iris.data[:1], iris.target[:1]
regr.fit(X, y)
print(regr.coef_)
print regr.predict(iris.data[1])
Output: 1.64 Output: 1.65
*To know more about lm function in R visit: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/lm.html
**To know more about sklearn linear regression visit : http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html
Machine Learning: Linear Regression on Iris Dataset](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-34-320.jpg)
![R(Using randomForest* package) Python(Using sklearn** library)
library(randomforest)
data(iris)
total_size <- dim(iris)[1]
num_target <- c(rep(0, total_size))
for (i in 1:length(num_target)){
if(iris$Species[i]=='setosa'){num_target[i]<0}
else if(iris$Species[i]=='versicolor'){num_target[i]<1}
else{num_target[i]<2}}
iris$Species<num_target
train_set <iris[1:149,]
test_set <iris[150,]
iris.rf < randomForest(Species ~ .,
data=train_set,ntree=100,importance=TRUE, proximity=TRUE)
print(iris.rf)
predict(iris.rf, test_set[5], predict.all=TRUE)
from sklearn import ensemble
from sklearn import datasets
clf = ensemble.RandomForestClassifier(n_estimators = 100,
max_depth=10)
iris = datasets.load_iris()
X, y = iris.data[:1], iris.target[:1]
clf.fit(X, y)
print clf.predict(iris.data[1])
Output: 1.845 Output: 2
*To know more about randomForest package in R visit: http://cran.r-project.org/web/packages/randomForest/
** To know more about sklearn random forest visit : http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html
Machine Learning: RandomForest on Iris Dataset](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-35-320.jpg)
![R(Using rpart* package) Python(Using sklearn** library)
library(rpart)
data(iris)
sub <- c(1:149)
fit <- rpart(Species ~ ., data = iris, subset = sub)
fit
predict(fit, iris[sub,], type = "class")
from sklearn import datasets
from sklearn.tree import DecisionTreeClassifier
clf = DecisionTreeClassifier(random_state=0)
iris = datasets.load_iris()
X, y = iris.data[:1], iris.target[:1]
clf.fit(X, y)
print clf.predict(iris.data[1])
Output: Virginica Output: 2, corresponds to virginica
*To know more about rpart package in R visit: http://cran.r-project.org/web/packages/rpart/
**To know more about sklearn desicion tree visit : http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html
Machine Learning: Decision Tree on Iris Dataset](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-36-320.jpg)
![R(Using e1071* package) Python(Using sklearn** library)
library(e1071)
data(iris)
trainset <iris[1:149,]
testset <iris[150,]
classifier<naiveBayes(trainset[,1:4], trainset[,5])
predict(classifier, testset[,5])
from sklearn import datasets
from sklearn.naive_bayes import GaussianNB
clf = GaussianNB()
iris = datasets.load_iris()
X, y = iris.data[:1], iris.target[:1]
clf.fit(X, y)
print clf.predict(iris.data[1])
Output: Virginica Output: 2, corresponds to virginica
*To know more about e1071 package in R visit: http://cran.r-project.org/web/packages/e1071/
**To know more about sklearn Naive Bayes visit : http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html
Machine Learning: Gaussian Naive Bayes on Iris
Dataset](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-37-320.jpg)
![R(Using kknn* package) Python(Using sklearn** library)
library(kknn)
data(iris)
trainset <iris[1:149,]
testset <iris[150,]
iris.kknn < kknn(Species~., trainset,testset, distance =
1, kernel = "triangular")
summary(iris.kknn)
fit < fitted(iris.kknn)
fit
from sklearn import datasets
from sklearn.neighbors import
KNeighborsClassifier
knn = KNeighborsClassifier()
iris = datasets.load_iris()
X, y = iris.data[:1], iris.target[:1]
knn.fit(X,y)
print knn.predict(iris.data[1])
Output: Virginica Output: 2, corresponds to virginica
*To know more about kknn package in R visit: https://cran.r-project.org/web/packages/kknn/
**To know more about sklearn k nearest neighbours visit: http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html
Machine Learning: K Nearest Neighbours on Iris
Dataset](https://image.slidesharecdn.com/pythonforrusers-160412193902/85/Python-for-R-users-38-320.jpg)

Python for R users
- 1. PYTHON for R Users By- Satyarth Praveen
- 2. Functions R Python Downloading and installing a package install.packages('name') pip install name Load a package library(name) import name as other_name Checking working directory getwd() import os os.getcwd() Setting working directory setwd(‘path’) os.chdir(‘path’) List files in a directory dir(‘path’) os.listdir(‘path’) List all objects ls() globals() Remove an object rm('name') del('object') See manual for the function help(help) help(help) See the type of an object class(object) type(object) Basic Commands
- 3. Functions R Python (Using pandas package) Creating a data frame “df” of dimension 6x4 (6 rows and 4 columns) containing random numbers A<- matrix(runif(24,0,1),nrow=6,ncol=4) df<-data.frame(A) Here, • runif function generates 24 random numbers between 0 to 1 • matrix function creates a matrix from those random numbers, nrow and ncol sets the numbers of rows and columns to the matrix • data.frame converts the matrix to data frame import numpy as np import pandas as pd A=np.random.randn(6,4) df=pd.DataFrame(A) Here, • np.random.randn generates a matrix of 6 rows and 4 columns; this function is a part of numpy** library • pd.DataFrame converts the matrix in to a data frame To read a csv from a URL or a file. read.csv("URL or file_name") Import pandas as pd pd.read_csv("URL or file_name") Data Frame Creation *To install Pandas library visit: http://pandas.pydata.org/; To import Pandas library type: import pandas as pd; **To import Numpy library type: import numpy as np;
- 4. Data Frame Creation R Python
- 5. Functions R Python Getting the names of rows and columns of data frame “df” rownames(df) colnames(df) df.index df.columns Seeing the top and bottom “x” rows of the data frame “df” head(df, x) tail(df, x) df.head(x) df.tail(x) Getting dimension of data frame “df” dim(df) df.shape Length of data frame “df” length(df) returns the number of columns of the data frame len(df) returns no. of rows in data frames To view the correlation among the columns of the data frames cor(df) df.corr() To view the unique entries of a vector unique(df$column_name) df.column_name.unique() Frequency count of each value in the column in the data frame table(diamonds$cut) OR summary(diamonds$cut) pd.value_counts(diamonds.cut) Data Frame: Inspecting and Viewing Data
- 6. Functions R Python Group the data frame as per the values of a column library(dplyr) df <- tbl_df(df) groupby_df <- df %>% group_by(column_name) Import pandas as pd groupby_df = pd.groupby(df, df.column_name) To perform a grouped mean on the column ‘column_name’ of the data frame summarise(groupby_df, mean(column_name)) groupby_df.column_name.mean() Frequency table for the values in 2 columns table(df$column_name1, df$column_name2) pd.crosstab(df.column_name1, df.column_name2, margins='TRUE') Data Frame: Inspecting and Viewing Data
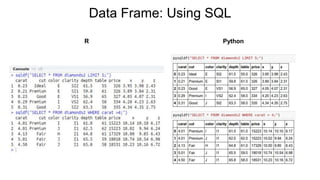
- 7. Data Frame: Inspecting and Viewing Data R Python
- 8. Functions R Python Getting quick summary(like mean, std. deviation etc. ) of data in the data frame “df” summary(df) returns mean, median , maximum, minimum, first quarter and third quarter df.describe() returns count, mean, standard deviation, maximum, minimum, 25%, 50% and 75% Getting a compact view of the data structure of the object. str(df) df.info() To check for all available methods for the object. isS4(object_name) # to check if the object is S4 type is(object_name, 'refClass') # to check if the object is RC type # if both are false then object is of S3 type: methods(class = class(object_name)) # if object is of S4 type: showMethods(classes = class(object_name)) dir(diamonds) Setting row names and columns names of the data frame “df” rownames(df) = c("A", "B", "C", "D", "E", "F") colnames(df) = c("P", "Q", "R", "S") df.index=[“A”, ”B”, “C”, ”D”, “E”, ”F”] df.columns=[“P”, ”Q”, “R”, ”S”] Data Frame: Inspecting and Viewing Data
- 9. Data Frame: Inspecting and Viewing Data R Python
- 10. Functions R Python Sorting the data in the data frame “df” by column name “P” df[order(df$P),] df.sort_values(by=['P']) This command is deprecated: df.sort(['P']) Data Frame: Sorting Data
- 11. Data Frame: Sorting Data R Python
- 12. Functions R Python Slicing the rows of a data frame from row no. “x” to row no. “y”(including row x and y) df[x:y,] df[x1:y] Python starts counting from 0 Slicing the columns name “X”,”Y” etc. of a data frame “df” myvars < c(“X”,”Y”) newdata < df[myvars] df.loc[:,[‘X’,’Y’]] Selecting the the data from row no. “x” to “y” and column no. “a” to “b” df[x:y,a:b] df.iloc[x1:y,a1:b] Selecting the element at row no. “x” and column no. “y” df[x,y] df.iat[x1,y1] Selecting column of the data frame df$column_name df.column_name Data Frame: Data Selection
- 13. Data Frame: Data Selection R Python
- 14. Functions R Python Using a single column’s values to select data, column name “A” subset(df,A>0) df[df.A > 0] It will select the all the rows in which the corresponding value in column A of that row is greater than 0 df[df.A > 0] It will do the same as the R function Data Frame: Data Selection R Python
- 15. Functions R Python To run an sql query on a data frame library(sqldf) library(tcltk) sqldf("SELECT * FROM diamonds2 LIMIT 5;") sqldf("SELECT * FROM diamonds2 WHERE carat >4;") from pandasql import sqldf pysqldf = lambda q: sqldf(q, globals()) # a replacement of the above lambda function would be: # def pysqldf(q): # return sqldf(q, globals()) # q here is the query. pysqldf("SELECT * FROM diamonds2 LIMIT 5;") pysqldf("SELECT * FROM diamonds2 WHERE carat > 4;") Data Frame: Using SQL
- 16. Data Frame: Using SQL R Python
- 17. Functions R Python (import math and numpy library) Sum sum(x) math.fsum(x) Square Root sqrt(x) math.sqrt(x) Standard Deviation sd(x) numpy.std(x) Log log(x, base) math.log(x,base) Mean mean(x) numpy.mean(x) Median median(x) numpy.median(x) Mathematical Functions
- 19. Functions R Python (import math and numpy library) Convert character variable to numeric variable as.numeric(x) For a single value: int(x), long(x), float(x) For list, vectors etc.: map(int,x), map(float,x) Convert factor/numeric variable to character variable paste(x) For a single value: str(x) For list, vectors etc.: map(str,x) Check missing value in an object is.na(x) math.isnan(x) Delete missing value from an object na.omit(list) cleanedList = [x for x in list if str(x) != 'nan'] Calculate the number of characters in character value nchar(x) len(x) Data Manipulation
- 20. Functions R (import lubridate library) Python (import datetime library) Getting time and date at an instant Sys.time() datetime.datetime.now() Parsing date and time in format: YYYY MM DD HH:MM:SS d<Sys.time() d_format<ymd_hms(d) d=datetime.datetime.now() format= “%Y %b %d %H:%M:%S” d_format=d.strftime(format) Data & Time Manipulation R Python
- 21. Functions R (import lubridate library) Python (import datetime library) Scatter Plot plot(variable1,variable2) import matplotlib.pyplot as plt plt.scatter(variable1,variable2) plt.show() Boxplot boxplot(Var) plt.boxplot(Var) plt.show() Histogram hist(Var) plt.hist(Var) plt.show() Line Plot plot(var1, var2, type = 'l') plt.plot(var1, var2) plt.show() Bubble Plot symbols(var1, var2, circles = var3, inches = 0.2) plt.scatter(var1, var2, s = var3*200) plt.show() Bar Plot barplot(var) plt.bar(np.arange(len(var)), df[:,1]) plt.show() Pie Chart pie(Var) from pylab import * pie(Var) show() Data Visualization
- 22. Data Visualization: Scatter Plot R Python
- 23. Data Visualization: Box Plot R Python
- 24. Data Visualization: Box Plot R Python
- 25. Data Visualization: Factor Plot R Python
- 26. Data Visualization: Histogram R Python
- 27. Data Visualization: Line Plot R Python
- 28. Data Visualization: Bubble Plot R Python
- 29. Data Visualization: Bar Plot R Python
- 30. Data Visualization: Pie Chart R Python
- 31. Data Visualization: Joint Plot R Python
- 32. Data Visualization: ggplot R Python
- 33. R(Using svm* function) Python(Using sklearn** library) library(e1071) data(iris) trainset <iris[1:149,] testset <iris[150,] svm.model < svm(Species ~ ., data = trainset, cost = 100, gamma = 1, type= 'C classification') svm.pred< predict(svm.model,testset[5]) svm.pred #Loading Library from sklearn import svm #Importing Dataset from sklearn import datasets #Calling SVM clf = svm.SVC() #Loading the package iris = datasets.load_iris() #Constructing training data X, y = iris.data[:1], iris.target[:1] #Fitting SVM clf.fit(X, y) #Testing the model on test data print clf.predict(iris.data[1]) Output: Virginica Output: 2, corresponds to Virginica *To know more about svm function in R visit: http://cran.r-project.org/web/packages/e1071/ **To install sklearn library visit : http://scikit-learn.org/, To know more about sklearn svm visit: http://scikit- learn.org/stable/modules/generated/sklearn.svm.SVC.html Machine Learning: SVM on Iris Dataset
- 34. R(Using lm* function) Python(Using sklearn** library) data(iris) total_size<dim(iris)[1] num_target<c(rep(0,total_size)) for (i in 1:length(num_target)){ if(iris$Species[i]=='setosa'){num_target[i]<0} else if(iris$Species[i]=='versicolor') {num_target[i]<1} else{num_target[i]<2} } iris$Species<num_target train_set <iris[1:149,] test_set <iris[150,] fit<lm(Species ~ 0+Sepal.Length+ Sepal.Width+ Petal.Length+ Petal.Width , data=train_set) coefficients(fit) predict.lm(fit,test_set) from sklearn import linear_model from sklearn import datasets iris = datasets.load_iris() regr = linear_model.LinearRegression() X, y = iris.data[:1], iris.target[:1] regr.fit(X, y) print(regr.coef_) print regr.predict(iris.data[1]) Output: 1.64 Output: 1.65 *To know more about lm function in R visit: https://stat.ethz.ch/R-manual/R-devel/library/stats/html/lm.html **To know more about sklearn linear regression visit : http://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LinearRegression.html Machine Learning: Linear Regression on Iris Dataset
- 35. R(Using randomForest* package) Python(Using sklearn** library) library(randomforest) data(iris) total_size <- dim(iris)[1] num_target <- c(rep(0, total_size)) for (i in 1:length(num_target)){ if(iris$Species[i]=='setosa'){num_target[i]<0} else if(iris$Species[i]=='versicolor'){num_target[i]<1} else{num_target[i]<2}} iris$Species<num_target train_set <iris[1:149,] test_set <iris[150,] iris.rf < randomForest(Species ~ ., data=train_set,ntree=100,importance=TRUE, proximity=TRUE) print(iris.rf) predict(iris.rf, test_set[5], predict.all=TRUE) from sklearn import ensemble from sklearn import datasets clf = ensemble.RandomForestClassifier(n_estimators = 100, max_depth=10) iris = datasets.load_iris() X, y = iris.data[:1], iris.target[:1] clf.fit(X, y) print clf.predict(iris.data[1]) Output: 1.845 Output: 2 *To know more about randomForest package in R visit: http://cran.r-project.org/web/packages/randomForest/ ** To know more about sklearn random forest visit : http://scikit-learn.org/stable/modules/generated/sklearn.ensemble.RandomForestClassifier.html Machine Learning: RandomForest on Iris Dataset
- 36. R(Using rpart* package) Python(Using sklearn** library) library(rpart) data(iris) sub <- c(1:149) fit <- rpart(Species ~ ., data = iris, subset = sub) fit predict(fit, iris[sub,], type = "class") from sklearn import datasets from sklearn.tree import DecisionTreeClassifier clf = DecisionTreeClassifier(random_state=0) iris = datasets.load_iris() X, y = iris.data[:1], iris.target[:1] clf.fit(X, y) print clf.predict(iris.data[1]) Output: Virginica Output: 2, corresponds to virginica *To know more about rpart package in R visit: http://cran.r-project.org/web/packages/rpart/ **To know more about sklearn desicion tree visit : http://scikit-learn.org/stable/modules/generated/sklearn.tree.DecisionTreeClassifier.html Machine Learning: Decision Tree on Iris Dataset
- 37. R(Using e1071* package) Python(Using sklearn** library) library(e1071) data(iris) trainset <iris[1:149,] testset <iris[150,] classifier<naiveBayes(trainset[,1:4], trainset[,5]) predict(classifier, testset[,5]) from sklearn import datasets from sklearn.naive_bayes import GaussianNB clf = GaussianNB() iris = datasets.load_iris() X, y = iris.data[:1], iris.target[:1] clf.fit(X, y) print clf.predict(iris.data[1]) Output: Virginica Output: 2, corresponds to virginica *To know more about e1071 package in R visit: http://cran.r-project.org/web/packages/e1071/ **To know more about sklearn Naive Bayes visit : http://scikit-learn.org/stable/modules/generated/sklearn.naive_bayes.GaussianNB.html Machine Learning: Gaussian Naive Bayes on Iris Dataset
- 38. R(Using kknn* package) Python(Using sklearn** library) library(kknn) data(iris) trainset <iris[1:149,] testset <iris[150,] iris.kknn < kknn(Species~., trainset,testset, distance = 1, kernel = "triangular") summary(iris.kknn) fit < fitted(iris.kknn) fit from sklearn import datasets from sklearn.neighbors import KNeighborsClassifier knn = KNeighborsClassifier() iris = datasets.load_iris() X, y = iris.data[:1], iris.target[:1] knn.fit(X,y) print knn.predict(iris.data[1]) Output: Virginica Output: 2, corresponds to virginica *To know more about kknn package in R visit: https://cran.r-project.org/web/packages/kknn/ **To know more about sklearn k nearest neighbours visit: http://scikit-learn.org/stable/modules/generated/sklearn.neighbors.NearestNeighbors.html Machine Learning: K Nearest Neighbours on Iris Dataset
- 39. Thank You