Author: Maddy Osman

A robots.txt file is a tool you can use to tell search engines exactly which pages you want (or don't want) crawled.
Editing your robots.txt file is an advanced skill. Before you make any changes, you need to understand what the file is and how to use it.
Keep reading to learn how a robots.txt file works and how you can use it to take greater control over your SEO efforts.
What is the robots.txt file?
A robots.txt file is a document that specifies which of your site pages and files can and can’t be requested by web crawlers.

A web crawler (also sometimes referred to as a spider or bot) is a computer program that identifies web pages online. Crawlers work by scanning the text and following all the links on a web page.
After a crawler finds a new web page, it sorts and stores the information it discovers. In the case of a search engine crawler, this information forms part of the search index. Each search engine uses its own crawlers to discover and catalog pages on the internet.
Web crawlers for search engines like Google and Bing are some of the most frequently discussed bots, but other services like backlink checking tools and social media platforms also use crawlers to understand content around the web and may visit your site regularly. You can see how often and how many bots are visiting your site in your bot log reports.

When a crawler visits your site, the first thing it does is download the robots.txt file, if there is one. Crawlers use the instructions in the robots.txt file to determine whether or not they can continue crawling certain pages and how they should crawl the site overall. You can use your robots.txt file to optimize your crawl or (if you are an experienced site manager) even block specific bots from crawling your site at all.
Your robots.txt file also tells search engine crawlers which page links and files it can request on your website. The file contains instructions that “allow” or “disallow” particular requests. The “allow” command tells crawlers that they can follow the links on your pages, while the “disallow” command tells crawlers they cannot follow those links. You can use the “disallow” command to prevent search engines from crawling (following the links on) certain sections of your website.
To make your sitemap available to Google, include your sitemap in your robots.txt file. A sitemap declaration is included within the Wix robots.txt for indexable sites, but self-built websites should ensure that a correct sitemap is available. Including a sitemap here can support consistent crawling and indexing.
Without a robots.txt file, crawlers will proceed to crawl all the pages on your website. For small websites (under 500 URLs), this is unlikely to change how or how often your site is crawled and indexed. But, as you add more content and functionality to your site, your robots.txt file takes on more importance.
How a robots.txt file can be used for SEO
For your website to appear in search results, search engines need to crawl your pages. The job of the robots.txt file is to help search engine crawlers focus on pages that you would like to be visible in search results.
In some cases, using a robots.txt file can benefit your SEO by telling search engine crawlers how to crawl your website. Here are some of the ways you can use a robots.txt file to improve your SEO:
01. Exclude private pages from search
Sometimes, you’ll have pages that don’t need to appear in search results. These pages could include test versions of your website (also known as staging sites) or login pages.
Telling crawlers to skip these private pages helps maximize your crawl budget (the number of pages a search engine will crawl and index in a given time period) and makes sure that search engines only crawl the pages you want to appear in search results.
Note: Search engines don't crawl content blocked by a robots.txt file, but they may still discover and index disallowed URLs if they're linked to from other places on the internet, including your other pages. This means that the URL could potentially appear in search results. For ways to prevent your content from appearing in search results, see the alternatives to robots.txt section below.
02. Prevent resource file indexation
Creating a website can require uploading resource files such as images, videos, and PDFs. Since you may not want these pages to be crawled and indexed, you can use a robots.txt file to limit crawl traffic to your resource files.
Additionally, your robots.txt file can stop these files from appearing in Google searches. This helps ensure that both search engines and your site users are directed to only your most relevant content.
03. Manage website traffic
You can use a robots.txt file to do more than keep website pages and files private. It can also be used to set rules for crawlers that prevent your website from being overloaded with requests.
Specifically, you can specify a crawl delay in your robots.txt file. A crawl delay tells search engines how long to wait before restarting the crawl process. For example, you can set a crawl delay of 60 seconds: Instead of crawlers overloading your website with a flood of requests, the requests come in at one-minute intervals. This helps to prevent possible errors when loading your website.
04. Declare your sitemap
As specified within Google’s documentation, you should include a line on your robots.txt that specifies the location of your sitemap. This helps Googlebot (and other bots) find your sitemap quickly and efficiently.

If this is not present, then the sitemap may not be crawled regularly, which can cause delays and inconsistencies in how your site is indexed, thus making it harder to rank.
Alternatives to robots.txt crawl directives
If you want to prevent Google from indexing individual pages or files, other methods, like robots meta tags and the X-Robots-Tag, may be a better option than doing so via your robots.txt file.
Robots meta tags
Adding or modifying robots meta tags can send specific directives to bots for certain pages. For example, to prevent search engine crawlers from indexing a single page, you can add a "noindex" meta tag into the <head> of that page.
Depending on your site’s configuration there are a few ways to update your site’s robots meta tags.
Use robots meta tag tool presets to make bulk updates
If you have SEO tools on your site or in your CMS, you may be able to apply robots meta tags to single pages, sections of your site, or the site overall by adjusting your settings.
For instance, if you are a Wix user, you can edit your SEO Settings to customize the robots meta tags for page types in bulk. Wix offers eight robots meta tags presets that are recognized by multiple search engines, but additional tags may also be relevant for your website. For example, if you would like to manage crawlability with regards to Bing or Yandex, you may wish to manually include tags specific to their bots.

Or, to noindex the entire site (remove it from search results), you can update the Set site preferences panel.

Other SEO tools may have similar presets, so it is worth checking the documentation to confirm what is available.
Use robots meta tag tools to make updates to single pages
To change the settings for a single page, you can add a robots meta tag into the head of the relevant page.
If you have a Wix website, you can add or update custom meta tags in the Advanced SEO tab as you edit a single page.
X-Robots-Tag on single pages
Alternatively, robots meta tags can be inserted as an HTML snippet in the <head> section of your page. You can specify a noindex directive, which tells crawlers not to include the page in search results, or add other tags as required.
You might want to use a robots meta tag on pages such as:
“Thank you” pages
Internal search results pages
PPC landing pages
The X-Robots-Tag prevents search engines from indexing your resource files.
Unlike a robots.txt file, the robots meta tag and X-Robots-Tag work better for single pages. If you want to manage crawl traffic for entire website sections, it’s better to use a robots.txt file.
Wix site owners can toggle indexing settings by page by navigating from the Wix Editor to Pages (in the left-hand navigation). On any page where you’d like to make changes, click Show More and SEO Basics. Turn the Let search engines index this page toggle on or off depending on your preferred indexing status.

The robots.txt file on Wix
Your Wix website includes a robots.txt file that you can view and customize. Take care—a mistake in the file could remove your entire website from search results. If you’re not comfortable working with advanced website features, it’s best to get help from an SEO professional.
You can view your website’s robots.txt file by going to the robots.txt editor in the SEO Tools page. You can click the Reset to Default button within the Robots.txt Editor to restore the original file (if needed). If you simply want to view your robots.txt file, you can do so by navigating to mydomain.com/robots.txt (where “mydomain.com” is your site’s domain).
Understanding your robots.txt file on Wix
If you’re going to make changes to your robots.txt file, you should first familiarize yourself with how Google handles the file.
In addition, you need to be familiar with some basic terminology in order to create instructions for crawlers.
Crawler: A computer program that identifies web pages online, usually for the purpose of indexing.
User-agent: A way to specify certain crawlers. For example, you can differentiate between crawlers for Google Search and Google Images.
Directives: The guidelines you can give the crawler (or specified user-agent) in a robots.txt file. Directives include “allow” and “disallow.”
Robots.txt syntax
Syntax is the set of rules used for reading and writing a computer program or file. Robots.txt uses code that begins by specifying the user-agent, followed by a set of directives.
Take a look at the following code:
User-agent: Googlebot-News
Disallow: /admin
Disallow: /login
In the above example, the specified user-agent is “Googlebot-News” and there are two “disallow” directives.
The code tells the Google News crawler that it can’t crawl the website’s admin or login pages.
As mentioned above, user-agents can refer to more than just different Googlebots. They can be used to set rules for different search engines. Here’s a list of user-agents for popular search engines.
If you want your rules to apply to all search engine crawlers, you can use the code
User-agent: *
followed by your directives.
Besides “allow” and “disallow,” there’s another common directive to understand: crawl-delay. Crawl-delay specifies how many seconds a crawler should wait before crawling each link.
For example,
User-agent: msnbot
Crawl-delay: 10
states that crawlers for MSN search must wait 10 seconds before crawling each new link. This code group only specifies a crawl delay—it doesn’t block MSN from any website sections.
Note: You can include multiple directives in one code grouping.
Making changes to your robots.txt file on Wix
Before you make any changes to your robots.txt file, read Google’s guidelines for robots.txt files. To edit your robots.txt file, go to SEO Tools under Marketing & SEO in your site's dashboard.
Then, follow these steps to edit your robots.txt file:
Click Robots.txt Editor
Click View File
Use the This is your current file text box to add directives to your robots.txt file
Click Save Changes
Click Save and Reset

Verifying changes to your robots.txt file
You can use Google’s URL Inspection Tool to verify your changes.
Type in a webpage address that you have disallowed to check if it’s being crawled and indexed by Google. For example, if you disallow the “/admin” section of your website, you can type “mywebsite.com/admin” into the URL Inspection Tool to see if Google is crawling it. If your robots.txt file was submitted correctly, you should receive a message that your URL is not on Google.
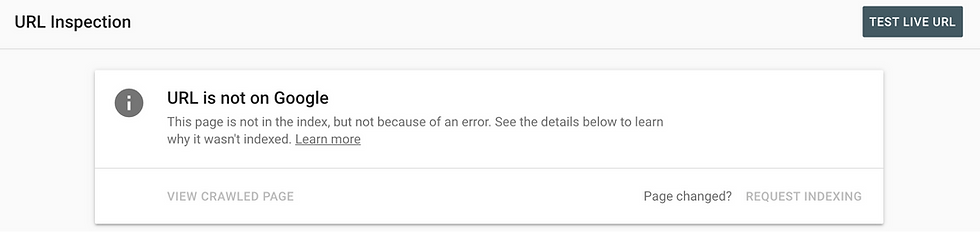
Remember, you have to verify your domain with Google Search Console before using the URL Inspection Tool. You can use Wix SEO Setup Checklist to connect your website to Google and verify your domain. Then, any time you submit changes to your robots.txt file, re-submit your sitemap as well.
When it comes to SEO, measure twice, cut once
There are several ways you can use your robots.txt file to strengthen your SEO. There are also a multitude of reasons why you might want to make some of your pages inaccessible to crawlers.
Now that you’re familiar with a variety of use cases, ensure that you’re selecting the right option for your purposes—in some instances, using robots meta tags may be more appropriate than disallowing via your robots.txt file. Ask yourself, are you simply looking to noindex a page? Or, are you trying to prevent resource file indexation, for example? Carefully consider what you’re trying to achieve before implementing any changes and record your changes so that you can reference them later.

Maddy Osman - Founder, the blogsmith Maddy Osman is the bestselling author of Writing for Humans and Robots: The New Rules of Content Style, and one of Semrush and BuzzSumo's Top 100 Content Marketers. She's also a digital native with a decade-long devotion to creating engaging content and the founder of The Blogsmith content agency. Twitter | Linkedin