
Wikimedia Apps/Team/Android/Machine Assisted Article Descriptions
Experiment background
The Android team is teaming up with Research and EPFL to improve article descriptions, also known as short descriptions and occasionally referred to as beams.
Currently Android app users can create and edit article descriptions via suggested edits. Article descriptions go to Wikidata with the exception of article descriptions for English Wikipedia. The Android team has received feedback that new users produce low-quality article descriptions (T279702). In 2022, the team placed a temporary restriction on Suggested Edits for users that had less than 3 edits for English Wikipedia users (T304621) with the intent on finding methods of improving the quality of article descriptions by new users.
EPFL and Research reached out to the Android team with a model called Descartes that can generate descriptions performing on par with human editors. Descartes takes the information on a Wikipedia article page and provides a short description of the article while adhering to the guidance of what makes an article description helpful. During initial evaluation of the model, it was preferred more than 50% of the time over human generated article descriptions. Additionally, Descartes held a 91.3% accuracy rate in testing. Despite these very promising results, the team wanted to do our due diligence by conducting an ABC test to ensure the suggestions will improve the quality of article descriptions when suggested to new editors, without introducing or increasing existing bias. We created an API which is hosted on Toolforge and will integrate the model into our existing interface in order to conduct our experiment. We will patrol edits made through the experiment in partnership with volunteers to not burden patrollers.
Product requirements
- Users being able to provide feedback on individual suggestions should they detect issues
- Accommodate two machine generated suggestions to test which beam is more accurate
- Onboard users to Machine Generated suggestions
- Reminder popups of checking for bias when clicking a suggestion on a biography
- Only experienced users will see suggestions for biographies
- Ability for users to write in their own response and edit a suggestion
- Incorporate icon that identifies the product uses machine learning
- Multilingual compatibility with mBART25
Objective and indicators
As a first step in the implementation of this project, the Android team will develop a MVP with the purpose of:
- Determine if suggestions made through the Descartes model increases the quality of article description additions and edits made using the Wikipedia Android app. To understand how the suggested article description changes user behavior, we will evaluate:
- If introduction of suggestions alters the stickiness of the task type across editing tenure
- Variability in task completion time relative to quality of edits
- How often users modify suggestions before hitting publish
- The optimal design and user workflow to encourage accuracy and task retention
- What, if any, additional measures need to be in place to discourage bad or bias suggestions
- Determine if the algorithm holds up when exposed to more users:
- Does the accuracy and preference rate change when exposed to more users
- Does the accuracy and preference rate of using the suggestion vary greatly across languages
- Is the algorithm introducing bias (e.g. misgendering) or not accurately representing critical nuance for Biographies of Living Persons
- How does the accuracy rate and performance change when showing more than one suggestion
Should the 30 day experiment show promising results based on the indicators above, the team will introduce the feature to all users and remove our 3 edit requirement for suggested edits. We will also take steps to expand the number of languages to mBART 50 and migrate the API from toolforge to a more permanent home.
Volunteer Graders
The team will partner with volunteers to patrol edits made during the time of the experiment and assign a grade to the edit.
This will serve as one input for determining if the quality of edits increase when using machine generated article descriptions. Volunteer graders can sign up below or reach out to ARamadan-WMF.
The commitment for serving as a volunteer grader is up to one hour a week for four weeks.
Decision to be made
This A/B test will help us make the following decision:
- Expand the feature to all users
- Use suggestion as a means to train new users and remove 3 edit minimum gate
- Migrate model to more permanent API
- Show 1 or 2 beams
- Expand to mBART 50
ABC Logic Explanation
- Experiment will include only logged in users, in order to stabilize distribution.
The only users that will see the suggestions are those in mBART25
- Of those in mBART25 half will see suggestions (B: Treatment) and half will not see suggestions (Control)
- Of those in mBART25 only users that have more than 50 edits can see suggestions for Biographies of Living Persons, and if the users are in the non-BLP group, they will remain in it, even if they cross 50 edits during the experiment.
Additionally, we care about how the answers to our experiment will differ by language wiki and user experience (<50 New vs. 50+ Experienced).
Decision to be made
- If the accuracy rate for edits that came from the suggestion is less than those manually written, we will not keep the feature in the app. The accuracy rate will be determined based on manual patrolling.
- If the accuracy rate for edits that came from the suggestion is less than 80%, we will not keep the feature in the app. The accuracy rate will be determined based on manual patrolling.
- If the time spent to complete the task using the suggestion is double the average rate as those that do not see suggestions we will need to compare it to reports to see if there are performance issues
- If time spent to complete the task using the suggestion is less than the average without a negative impact to accuracy rate, we will consider it a positive indicator to expand the feature to more users
- If users that see the suggestion modify the suggestions more often than submitting it without modification, we will evaluate its accuracy rate compared to users that did not see the suggestions and determine if the suggestion is a good starting point for users and how it differs by user experience
- If users that see the suggestion modify the suggestions more often than submitting them without modification, we will look for trends in the modification and offer a recommendation to EPFL to update the model
- If beam one is chosen more than 25% of the time than beam two while having an equal or higher accuracy rate, we will only show beam one in the future
- If users that see treatment return to the task multiple times (1,2,7,14 days) at a rate 15% or more than the control group without a negative impact to accuracy, we will take steps to expand the feature
- If our risks are triggered we will implement our contingency plan
- If users that see the treatment do not select a suggestion more than 50% of the time after viewing the suggestions, we will not expand the feature
In aggregate, there should be at least 1500 people with a stretch goal of **2,000 people** and 4,000 edits included in the A/B test across the following mBART25 wikis: English, Russian, Vietnamese, Japanese, German, Romanian, French, Finnish, Korean, Spanish, Chinese (sim), Italian, Dutch, Arabic, Turkish, Hindi, Czech, Lithuanian, Latvian, Kazakh, Estonian, Nepali, Sinhala, Gujarati, and Burmese.
Risk management
Any time Machine Learning is used, we introduce a greater deal of risks than what is already involved in software development. For that reason, we are tracking and managing risks associated with this project alongside our Security and Legal team.
| Risk | Cause | Level | Response | Response Action | Trigger | Contingency Plan |
|---|---|---|---|---|---|---|
| Algorithm Defames Living People | Algorithm pulls controversial aspects of a living person and includes it in description. | Low | Mitigate | We will monitor the output of what gets published and see what is reported to make adjustments to the learning model. In testing we haven't seen a case of this, quite the opposite, we see cases of the algorithm whitewashing history. As an extra precaution, we will only allow experienced editors to edit biographies of living people. | Defamation detected during patrolling | Remove suggestions on BLPs completely |
| Overwhelm patrollers | New feature increases interest in task type and algorithm doesn't increase quality of edits | Med | Mitigate | We will have a dedicated team of people that will patrol the edits from this feature to not overwhelm volunteer patrollers, and give advanced notice to Wikidata and English Community. | Staff unable to keep up with patrolling demands | Restrict the number of tasks with suggestions in a day |
| Proposes NSFW Content | There is NSFW content in the article that is suggested for the description | Low | Mitigate | The algorithm pulls primarily from the first paragraph. We have a reporting mechanism and will be patrolling edits. | If 2% or more users report a problem | We will hardcode block words based on the abuse filter |
| Users abandon task due to performance issues | The model is on a temporary host and showing more than one option can take a while for generation | Med | Mitigate | Load answers in the background before users click the button to show suggestions. | 4/10 users express performance issues during usability testing | Show one option or make other changes to UI |
| Misgendering or ethnic hallucinations | Algorithm incorrectly genders people or provides incorrect ethnciity | Med | Mitigate | During the experiment this is something we will deliberately look for in patrolling and monitor reports | If reported more than 2% of time | We will pause the feature and hard code reminders and decrease suggestion to one suggestion |
How to follow along
We have created T316375 as our Phabricator Epic to track this work. We encourage your collaboration there or on our Talk Page.
There will also be periodic updates to this page as we make progress. You can also test the model at https://ml-article-descriptions.toolforge.org/. Please keep in mind, there are a bunch of filters that are being added client side to improve the quality of the model. Those safeguards can be read in the Risk Management portion of this page.
Updates
July 2024: API available through LiftWing
We appreciate everyone's patience as we've worked with the Machine Learning team to migrate the model to LiftWing. In August we will clean up the client side code to remove test conditions and add in improvements mentioned in the January 2024 update. In the following months we will reach out to different language communities to make the feature available to them in the app.
If you are a developer and would like to build a gadget using the API, you can read the documentation here.
January 2024: Results of Experiment
Languages Included in grading:
- Arabic
- Czech
- German
- English
- Spanish
- French
- Gujarati
- Hindi
- Italian
- Japanese
- Russian
- Turkish
Additional languages monitored by staff that did not have community graders:
- Finnish
- Kazakh
- Korean
- Burmese
- Dutch
- Romanian
- Vietnamese
Was there a difference between Machine Accepted and Human Generated Edit Average and Median Grades:
| Graded Edits | Avg Grade | Median Grade |
| Machine Accepted Edits | 4.1 | 5 |
| Human Generated Edits | 4.2 | 5 |
- Note: 5 was the highest possible score
How did the model hold up across languages?
| Language | Machine Accepted
Edits Avg. Grade |
Human Generated
Edits Avg. Grade |
Machine Avg.
Grade Higher? |
Recommendation of if feature should be enabled |
| ar* | 2.8 | 2.1 | TRUE | No |
| cs | 4.5 | Not Applicable | Yes | |
| de | 3.9 | 4.1 | FALSE | 50+ Edits Required |
| en | 4.0 | 4.5 | FALSE | 50+ Edits Required |
| es | 4.5 | 4.1 | TRUE | Yes |
| fr | 4.0 | 4.1 | FALSE | 50+ Edits Required |
| gu* | 1.0 | Not Applicable | No | |
| hi | 3.8 | Not Applicable | 50+ Edits Required | |
| it | 4.2 | 4.4 | FALSE | 50+ Edits Required |
| ja | 4.0 | 4.5 | FALSE | 50+ Edits Required |
| ru | 4.7 | 4.3 | TRUE | Yes |
| tr | 3.8 | 3.4 | TRUE | Yes |
| Other language communities | Not Applicable | Not Applicable | Not Applicable | Can be enabled upon request |
- Note: We will not enable the feature without engaging communities first.
* Indicates language communities where there weren’t many suggestions to grade which we believe had an impact on the score
How often were Machine Suggestions Accepted, Modified or Rejected?
| Edit type | % of Total Machine Edits |
| Machine suggestion accepted | 23.49% |
| Machine suggestion modified | 14.49% |
| Machine suggestion rejected | 62.02% |
What was the distribution of Machine Accepted Article Descriptions with a score of 3 or higher?
| Score | Percent Distribution |
| < 3 | 10.0% |
| >= 3 | 90.0% |
How did the Machine Accepted Article Descriptions scoring change when taking editor experience into account?
| Editor Experience | Average Edit Grade | Median Edit Grade |
| Under 50 Edits | 3.6 | 4 |
| Over 50 Edits | 4.4 | 5 |
Our experiment tested two beams to see which was more accurate and performant. To avoid bias, the placement of the suggestion to the user switched positions each time. The results are:
| Beam Selected | Average Edit Grade | % Distribution |
| 1 | 4.2 | 64.7% |
| 2 | 4.0 | 35.3% |
- Note: When rereleasing the feature we will only display beam 1.
How often are people making edits (modifications) to the machine suggestion before publishing?
| Edit Type | Modification Distribution |
| Machine Accepted Not Modified | 61.85% |
| Machine Accepted Modified | 38.15% |
How do users modifying the machine suggestion impact accuracy?
| Machine Graded Edits | Avg. Score |
| Not Modified | 4.2 |
| Modified | 4.1 |
- Note: Due to there not being an impact on accuracy if a user modifies the suggestion or not we do not see a need to require users to make a change to the recommendation, but we should still maintain a UI that encourages edits to the machine suggestion
How often did a grader say they would revert vs rewrite an edit based on if it was Machine Suggested or Human Generated?
| Graded Edits: | % edits would revert | % edits would rewrite |
| Editor accepted suggestion | 2.3% | 25.0% |
| Editor saw suggestion but wrote out their own description instead | 5.7% | 38.4% |
| Human edit no exposure to suggestion | 15.0% | 25.8% |
- Note: We defined revert as the edit is so inaccurate it is not worth trying to make a minor modification to improve it as a patroller. Rewrite was defined as a patroller would just modify what was published by the user to improve it. Over the course of the experiment only 20 machine edits were reverted across all projects, which was not statistically significant so we could not compare actual reverts, instead we went based on recommendations by graders. Only two language communities have their article descriptions live on Wikipedia, which means patrolling is less frequent for most language communities due to descriptions being hosted on Wikidata.
What insights did we gain through the feature’s report function?
0.5% of unique users reported the feature. Below is a distribution of the type of feedback we received:
| Feedback/Response | % Distribution of feedback |
| Not enough info | 43% |
| Inappropriate suggestion | 21% |
| Incorrect dates | 14% |
| Cannot see description | 7% |
| "Unnecessary hook" | 7% |
| Faulty spelling | 7% |
Does the feature have an impact on retention?
| Retention Period | Group 0
(No treatment) |
Groups 1 and 2 |
| 1-day average return rate: | 35.4% | 34.9% |
| 3-day average return rate: | 29.5% | 30.3% |
| 7-day average return rate: | 22.6% | 24.1% |
| 14-day average return rate: | 14.7% | 15.8% |
- Note: Users exposed to Machine Assisted Article Descriptions had a marginally higher return rate as compared to users not exposed to the feature
Next Steps:
The experiment was run on Cloud Services, which is not a sustainable solution. There are enough positive indicators to make the feature available to communities that desire it. The apps team will work in partnership with our Machine Learning to migrate the model to Liftwing, once it has been migrated and sufficiently tested for performance, we will re-engage our language communities to determine where to enable the feature and what additional improvements can be made to the model. Modifications that are currently top of mind include:
- Restrain Biographies of Living Persons (BLP): During the experiment we allowed users with over 50 edits to add descriptions to Biographies of Living Persons with the help of Machine Assistance. We recognize there are concerns about permanently suggesting article descriptions on these articles. While we did not see evidence of issues related to Biographies of Living Persons, we are happy to not show suggestions on BLPs.
- Only use Beam 1: Beam 1 consistently outperformed Beam 2 when it came to suggestions. As a result, we will only show one recommendation, and it will be from Beam 1.
- Modify Onboarding & Guidance: During the experiment we had an onboarding screen about machine suggestions. We would add back in guidance around machine suggestions when rereleasing the feature. It would be helpful to hear feedback from the community about what guidance they would like us to provide to users about writing effective article descriptions so that we can improve onboarding.
If there are other obvious errors, please leave a message on our project talk page so that we can address it. An example of an obvious error is displaying incorrect dates. We noticed this error during testing on the app and added a filter that prevents recommendations descriptions that include dates that are not mentioned themselves in the article text. We also noticed that disambiguation pages were recommended by the original model, and filtered out disambiguation pages client side, which is a change we plan to maintain. Other things such as capitalization of the first letter would also be a general fix that we could do because there is a clear heuristic we could use to implement it.
For languages where the model is not performing well enough to deploy, the most useful thing is adding more article descriptions in that language so that retraining of the model will have more data to go on. There isn't a set date or frequency at this point, however, for which the model will be retrained but we can work with the Research and Machine Learning team to get this prioritized as communities request it.
July 2023: Early Insights from 32 Days of Data Analysis: Grading Scores and Editing Patterns
We can not complete our data analysis until all entries have been graded so that we have an accurate grading score. However we do have early insights we can share. These insights are based on 32 days of data:
- 3968 Articles with Machine Edits were exposed to 375 editors.
- Note: Exposed does not mean selected.
- 2125 Machine edits were published by 256 editors
- Editors with 50+ edits completed three times the amount of edits per unique compared to editors with less than 50 edits
May 2023: Experiment Deactivated & Volunteers Evaluate Article Short Descriptions
The experiment has officially been deactivated and we are now in a period of edits being graded.
Volunteers across several language Wikis have begun to evaluate both human generated and machine assisted article short descriptions.
We express our sincere gratitude and appreciation to all the volunteers, and have added a dedicated section to honor their efforts on the project page. Thank you for your support!
We are still welcoming support from the following language Wikipedias for grading: Arabic, English, French, German, Italian, Japanese, Russian, Spanish, and Turkish languages.
If you are interested in joining us for this incredible project, please reach out to Amal Ramadan. We look forward to collaborating with passionate individuals like you!
April 2023: FAQ Page and Model Card
We released our experiment in the 25 mBART languages this month and it will run until mid-May. Prior to release we added a model card to our FAQ page to provide transparency into how the model works.
-
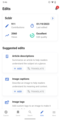 Suggested edits home
Suggested edits home -
 Suggested edits feed
Suggested edits feed -
 Suggested edits onboarding
Suggested edits onboarding -
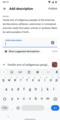 Active text field
Active text field -
 Dialog Box
Dialog Box -
 What happens after tapping suggestions
What happens after tapping suggestions -
 Manual text addition
Manual text addition -
 The preview
The preview -
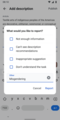 Tapping the report flag
Tapping the report flag -
 Confirmation
Confirmation -
 Gender bias support text
Gender bias support text











This is the onboarding process:
-
 Article Descriptions Onboarding
Article Descriptions Onboarding -
 Keep it short
Keep it short -
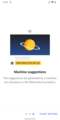 Machine Suggestions
Machine Suggestions -
 Tooltip
Tooltip




January 2023: Updated Designs
After determining that the suggestions could be embedded in the existing article descriptions task the Android team made updates to our design.
-
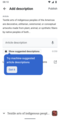 Tooltip to as onboarding of feature
Tooltip to as onboarding of feature -
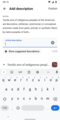 Once the tooltip is dismissed the keyboard becomes active
Once the tooltip is dismissed the keyboard becomes active -
 Dialog appears with suggestions when users tap "show suggested descriptions"
Dialog appears with suggestions when users tap "show suggested descriptions" -
 Tapping a suggestion populates text field and publish button becomes active
Tapping a suggestion populates text field and publish button becomes active




If a user reports a suggestion, they will see the same dialog as we proposed in our August 2022 update as the what will be seen if someone clicks Not Sure.
This new design does mean we will allow users to publish their edits, as they would be able to without the machine generated suggestions. However, our team will patrol the edits that are made through this experiment to ensure we do not overwhelm volunteer patrollers. Additionally, new users will not receive suggestions for Biographies of Living Persons.
November 2022: API Development
The Research team put the model on toolforge and tested the performance of the API. Initial insights found that it took 5-10 seconds to generate suggestions, which also varied depending on how many suggestions were being shown. Performance improved as the number of suggestions generated decreased. Ways of addressing this problem was by preloading some suggestions, restricting the number of suggestions shown when integrated into article descriptions, and altering user flows to ensure suggestions can be generated in the background.
August 2022: Initial Design Concepts and Guardrails for Bias
User story for Discovery
When I am using the Wikipedia Android app, am logged in, and discover a tooltip about a new edit feature, I want to be educated about the task, so I can consider trying it out. Open Question: When should this tooltip be seen in relation to other tooltips?
User story for education
When I want to try out the article descriptions feature, I want to be educated about the task, so my expectations are set correctly.


User story for adding descriptions
When I use the article descriptions feature, I want to see articles without a description, I want to be presented with two suitable descriptions and an option to add a description of my own, so I can select or add a description for multiple articles in a row.
-
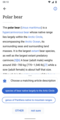 Concept for selecting a suggested article description
Concept for selecting a suggested article description -
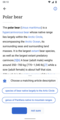 Design concept for a user deciding the description should be an alternative to what is listed
Design concept for a user deciding the description should be an alternative to what is listed -
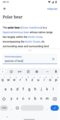 Design concept for a user editing a suggestion before hitting publish
Design concept for a user editing a suggestion before hitting publish -
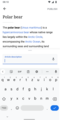 Design concept for what users see when pressing other
Design concept for what users see when pressing other -
 Screen displaying options for if a user says they are not sure what the correct article description should be
Screen displaying options for if a user says they are not sure what the correct article description should be





Guardrails for bias and harm
The team generated possible guardrails for bias and harm:
- Harm: problematic text recommendations
- Guardrail: blocklist of words never to use
- Guardrail: check for stereotypes – e.g., gendered language + occupations
- Harm: poor quality of recommendations
- Guardrail: minimum amount of information in article
- Guardrail: verify performance by knowledge gap
- Harm: recommendations only for some types of articles
- Guardrail: monitor edit distribution by topic
Gratitude and Appreciation for the Dedicated Volunteers of the Article Description Grading Project
We want to take a moment to express our deepest gratitude and heartfelt appreciation to each and every dedicated volunteer who has selflessly offered their time and unwavering support to the article description grading project. As the Apps Team at the Wikimedia Foundation, we are truly humbled by your invaluable contribution.
Your unwavering commitment to diligently patrol edits made during the experiment and wholeheartedly assign grades to them has played an irreplaceable role in helping us understand the impact of machine-generated article descriptions on the quality of edits. Your exceptional vigilance and unwavering dedication are the cornerstones of our collective efforts.
Your active participation in this project goes far beyond mere involvement; it represents a genuine and profound commitment to advancing the Wikimedia mission. Through your tireless efforts, our platforms continue to evolve and improve, creating an enhanced and enriching user experience for millions around the globe.
The boundless enthusiasm and unyielding passion you bring to the table truly inspire us. Together, we are forging a path toward a future where knowledge and accessibility know no bounds within the realm of our Wikipedia Android App.
Once again, we want to express our sincerest thanks for your extraordinary support and unwavering dedication. Your invaluable contributions are the lifeblood of this project and the broader Wikipedia community.
| VatBatCat | Umasoyee |
| Bernilein111 | Moha Elkotsh |
| Harouna674 | Anupamdutta73 |
| Barke11 | Shayi ngolu |
| Terio legal | Mndetatsin |
| Beheme | CptViraj |
And countless users who preferred to remain anonymous.