Exploring Large All-Flash Storage System with Scientific Simulation
DOI: https://doi.org/10.1145/3538712.3538734
SSDBM 2022: 34th International Conference on Scientific and Statistical Database Management, Copenhagen, Denmark, July 2022
Solid state storage systems have been very effectively used in small devices; however, their effectiveness for large systems such as supercomputers is not yet proven. Recently, for the first time, a new supercomputer is being deployed with an all-flash storage as its main file system. In this work, we report our preliminary study of the I/O performance on this supercomputer named Perlmutter. We are able to achieve 1.4 TB/s with the default file configuration on the system. This default configuration outperforms dozens of other choices tested, though the current observed performance is still pretty far from the theoretical peak performance of 5 TB/s.
ACM Reference Format:
Junmin Gu, Greg Eisenhauer, Scott Klasky, Norbert Podhorszki, Ruonan Wang, and Kesheng Wu. 2022. Exploring Large All-Flash Storage System with Scientific Simulation. In 34th International Conference on Scientific and Statistical Database Management (SSDBM 2022), June 03–05, 2018, Copenhagen, Denmark. ACM, New York, NY, USA 4 Pages. https://doi.org/10.1145/3538712.3538734
1 INTRODUCTION
NAND flash memory is replacing the rotating disk as the data storage devices in many applications [15]. These solid state storage systems do not have any moving parts, therefore are heavily favored in mobile applications. At the device level, the flash storage generally has shorter access latency and higher throughput than the rotating disk [11]. These advantages of solid state storage over rotating disk has been well studied on a smaller scale [11, 15]. On larger systems including supercomputers and cloud computers, the use of flash memory for file storage is gradually gaining popularity as the cost comes down [10, 11]. In the recently installed supercomputer named Perlmutter, we saw the first all-flash primary storage system at petabyte scale. At this scale, a considerable amount of work is needed to coordinate the operations of the thousands of individual flash devices. This work is an attempt to understand the impact of such coordination on the I/O performance.
For users, the all-flash storage system on Perlmutter is accessed through a large parallel file system named Lustre [12]. This file system divides the user data onto multiple object storage targets (OST). Our work would primarily focus on measuring the I/O performance experienced by the application software, which is in a large part determined by effectiveness of the parallel file system in coordinating the I/O tasks over these OSTs. Users could affect these I/O operations by controlling (1) I/O patterns, (2) computing/networking resources, (3) file system parameters, and (4) I/O software parameters. In this short paper, we describe our preliminary attempts at exploring these four different classes of choices.
According to published studies, the flash memory devices support read operations more effectively than write operations [11, 15]. Therefore, in this study, we will focus on the write operations. In many scientific applications, the output files are created by libraries such as HDF5, NetCDF and ADIOS. This work focuses on one of the libraries, ADIOS1, because it requires relatively little tuning to achieve good write performance.
The scientific data is often represented as multi-dimensional arrays [5, 6, 17]. These arrays represent features defined on regular meshes for representing their problem domains. In this study, we choose an I/O pattern inspired by a plasma physics simulation code known as WarpX [5, 17]. This benchmark output data following the same schema as WarpX, except the output from each process has the same size, which avoids the load imbalance that typically reduces I/O performance. With this benchmark, we are able to achieve 1.4TB/s write performance using the default Lustre file system configuration. Additionally, this default configuration outperforms dozens of selected configurations tested, which suggests that the file system on Perlmutter is well-configured for the all-flash storage system.
2 STORAGE SYSTEM ON PERLMUTTER
The rapid growth of computing power in the last few decades has shifted the bulk of the execution time in high-performance computing from floating-point computations to data management tasks [7, 13]. This trend is causing the computer system designers to pay more attention to memory and storage sub-systems [14]. At the forefront of this storage revolution is the NAND flash memory [11, 15]. The largest installation of flash memory file system is currently located at National Energy Research Scientific Computing Center (NERSC) in a supercomputer named Perlmutter. NERSC serves a large variety of data intensive workloads from thousands of active users. The Perlmutter system is a Hewlett Packard Enterprise (HPE) Cray EX supercomputer, with a mixture of GPU-accelerated and CPU-only nodes [3]. When fully deployed, its projected performance is three to four times that of NERSC's current flagship system, Cori [2].
Flash drives are well known for lower latency and faster I/O operations compare to traditional hard disk [11, 15]. At the scale of Perlmutter, the flash devices are connected through an efficient storage-area network (SAN). It utilizes the latest version of InfiniBand switches to provide ample bandwidth for the storage-area network. This SAN also seamlessly interacts with the networking technology for the computer nodes, which is HPE Cray Slingshot in the dragonfly topology, to provide fast response time for the Lustre file system. This design is to take full advantage of the flash memory storage system to offer high I/O performance.
With 35 PB usable space, the main file system of Perlmutter has an all-flash version of HPE Cray ClusterStor E10002. It has an aggregate bandwidth of greater than 5 TB/s, and 4 million IOPS (4 KiB random). There are 16 metadata servers (MDS), 274 I/O servers called OSSs, and 3,792 dual-ported Non-volatile Memory (NVMe) Solid State Drives (SSD).3
This configuration delivered good performance at device level [12]. Using the obdfilter-survey, NERSC observed performance 92.6% of peak write and 99.9% of peak read out of the SSD. On top of this, using Slingshot and LNet, the LNet self test shows 84.8% of peak write performance out of 42 GB/s per OSS and 97% of peak read performance out of 48 GB/s per OSS. Note that the write speed is slower than read speed due to the write parity overhead and SSD specific features.
In this work, we focus on the whole system performance experienced by a user. The Lustre file system offers a number of user configurable parameters to tune the file system performance [1, 12]. Two of the more commonly used ones are known as stripe count and stripe size, where the stripe count is referring to the number of OSTs used for writing a file and the stripe size is the size of a stripe (in number of bytes) the Lustre system breaks a file into for distribution to the OSTs. In the past, Lustre files are configured with fixed choices for stripe counts and stripe sizes, say strip count of 1 and strip size of 1 MB. These default choices are set for some ”typical file sizes”, while other users have to carefully choose stripe counts and stripe sizes in order to achieve a reasonable fraction of the peak performance [8, 16]. This performance tuning could be time consuming.
On Perlmutter, the Lustre file system is configured with the progress file layout (PFL) that would dynamically choose the number of OSTs to distribute a file. Under PFL, the Lustre file system would use more OSTs as the file size grows. The current Perlmutter detault setting is to use 1 OST for files up to 1GB, 8 OSTs up to 10GB, 24 OSTs up to 100GB, and 72 OSTs for over 100 GB. For example, as one writes a 15 GB file, the first 1GB is written to 1 OST, and then 8 OSTs for next 9GB, and then to 24 OSTs for the last 5GB. One of the specific objective of this work is to study if this PFL provide a good general setting for our tests.
3 DATA I/O USING SYNTHETIC BENCHMARK
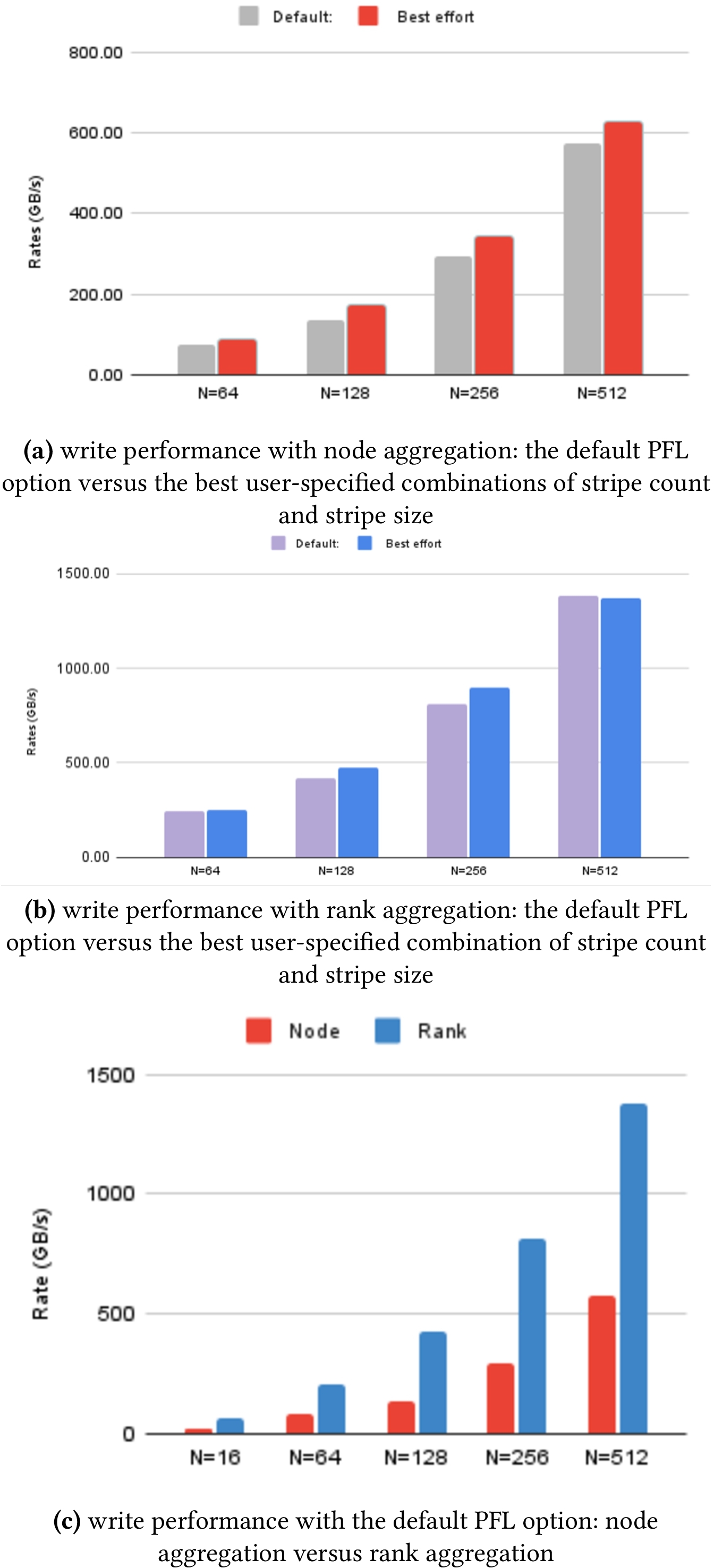
In this short paper, we explore I/O performance with a set of synthetic benchmarks developed with openPMD-api [9]. It outputs mesh data and particle data following the schema of WarpX [17]. The data is organized by timesteps where each timestep has 10 field and particle variables. In the following tests, each run of the benchmark writer produces 6 timesteps, all with 3D meshes.
Our I/O benchmark is configured to use ADIOS for I/O operations. Among the options available through ADIOS, our tests focus on two best performing file organization strategies known as node aggregation and rank aggression [4, 5]. In addition to these ADIOS parameters, the I/O performance is also affected by the Lustre file system parameters such as stripe size and stripe count. As users we are able to set a fixed value for stripe size and stripe count for each run of the I/O test, while the file system itself is able to dynamically select these parameters following the PFL scheme described in the last section. The PFL is the default choice on Perlmutter. In addition to this default choice, we also select nine different stripe count values and seven different stripe size values to explore 63 different combinations of these two file system parameters.
The main performance measurement we describe here is a weak scaling study with the WarpX benchmark writer. The writer employs 4 MPI ranks on each node using the ADIOS BP4 engine. Both rank aggregation and node aggregation are tested, along with the Lustre configurations described above. In our tests, each MPI rank writes about 7.5 GB. With rank aggregation, each ADIOS sub-file is about 7.5 GB in size; with node aggregation, each ADIOS sub-file writes the contents of 4 ranks, which is 30 GB.
Figure 1 shows a summary of the write performance from this weak-scaling study. This test primarily compares the default PFL option on Perlmutter against the best observed results from manually selected stripe count and stripe size (both would be fixed throughout a run of the benchmark). With either node aggregation (Figure 1(a)) or rank aggregation (Figure 1(b)), we see that the dynamic option PFL achieves very similar write rates as the best fixed-stripe-count-and-stripe-size option we could find. This observation confirms that the system operators have carefully selected the default configuration and the default PFL on Perlmutter is a good option for many applications.
With 512 nodes, the writer achieves about 1.4 TB/s, which is about 28% of the theoretical peak I/O bandwidth. We plan to further study the I/O performance to understand how to achieve a higher fraction of the peak performance, for example, by using more compute nodes or larger write operations.
From Figure 1(c), we see that ADIOS rank aggregation always performed better than the node aggregation option. Since the rank aggregation option generates four times as many Lustre files as the node aggregation strategy, the rank aggregation could spread out the write options onto more OSTs, especially if each of these ADIOS sub-files is written to a small number of OSTs (i.e., when the stripe count is small). However the file creation is a global operation on Lustre metadata servers, if many files are created at the same time, the Lustre metadata servers might become overwhelmed, leading to contention and delay. Since the all-flash storage system is able to support many more I/O operations per second than disk-based systems, the Lustre file system on Perlmutter is able to create many more files without experiencing the file-creation bottleneck. We plan to run much larger tests to probe the file system capability.
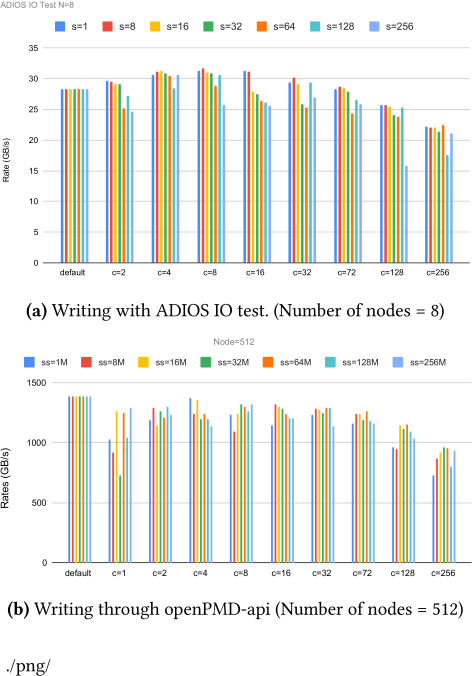
Next, we provide more details on how stripe count and stripe size impact the write performance. Figure 2 shows two sets of performance measurements with 8 nodes (in Figure 2(a)) and 512 nodes (in Figure 2(b)). The best-performing combination from Figure 2(b) is shown in the 512-node case of Figure 1(b) and 1(c). In this particular case, the stripe count c = 4 and the stripe size ss = 1MB. Figure 2(a) has the write performance from different I/O test, which shows the best performing stripe count is 4 and strip size is 2MB. The best performing stripe count behind Figure 1 are all modest values (around 4). With a given stripe count, the best performing stripe size varies from case to case as shown in Figure 2. We are not able to make a definitive observation from the current set of test. Additional study is required to better understand the impact of stripe size.
4 CONCLUSION AND FUTURE WORK
The effectiveness of an individual flash storage device is well established [11, 15]. Recently, an all-flash storage system with many thousands of flash devices has been deployed for a supercomputer known as Perlmutter [12]. Its peak I/O throughput is more than 5 TB/s. The basic question we seek to answer is how much of this peak performance is available to a typical user. We answer this question with a series of write tests to explore dozens of system parameter combinations. We observed that the default Lustre configuration known as PFL delivers at least near best write performance among all the Lustre configurations we have explored. Therefore, we believe the default file system configuration at Perlmutter is likely to be effective for most users.
Our tests also reveal a number of issues requiring further investigation. A notable observation is that the best write throughput we achieve is only about 28% of the peak performance. Are there bottlenecks in the parallel file system and I/O system that limit how much of the peak performance is available to a user? We are planning additional experiments to answer this questions.
As a practical matter, we are also interested in how to set the various system parameters to achieve the best I/O performance. The PFL strategy dynamically sets the Lustre stripe count, but the users are left on their own to determine the stripe size. Our tests so far do not suggest a simple strategy for determining the most effective stripe size.
There are also a number of shortcomings with the current set of tests conducted. The tests only involve synthetic benchmark write operations. Data-intensive scientific applications require extensive read operations, thus, we are interested in exploring the read performance of Perlmutter's all-flash storage system. Furthermore, we'd like to explore I/O performance of real scientific applications in addition to the benchmarks. Due to the current limitation, we are not able to conduct the large tests we planned at the time of this writing. In particular, we are planning to conduct large-scale tests with WarpX simulation and with the latest version of I/O software systems. We will schedule these tests after Perlmutter reaches its full capacity.
On a large storage system with many users, it is common for some of the OSTs assign for a particular application to be also serving other I/O operations, which might slow down the responses of these OSTs to our application. These slow OSTs could slow down the overall I/O operations. To avoid such slow-downs, we would like to try out the asynchronous capability of I/O systems. When feasible, we also plan to study the in situ option in the future because it is likely to become more important as the simulations grow in size.
ACKNOWLEDGMENTS
This research was supported in part by the Exascale Computing Project (17-SC-20-SC), a joint project of the U.S. Department of Energy's Office of Science and National Nuclear Security Administration, responsible for delivering a capable exascale ecosystem, including software, applications, and hardware technology, to support the nation's exascale computing imperative. This research used resources of the Oak Ridge Leadership Computing Facility, which is a DOE Office of Science User Facility supported under Contract DE-AC05-00OR22725 and of the National Energy Research Scientific Computing Center (NERSC), a U.S. Department of Energy Office of Science User Facility located at Lawrence Berkeley National Laboratory, operated under Contract No. DE-AC02-05CH11231.
REFERENCES
- Peter Braam. 2019. The Lustre storage architecture. Cluster File Systems, Inc. https://doi.org/10.48550/arXiv.1903.01955 arXiv preprint arXiv:1903.01955.
- NERSC documentation.2021. https://docs.nersc.gov/performance/io/lustre/.
- NERSC documentation. 2021. Nersc Systems Nersc file system Description. NERSC. https://docs.nersc.gov/systems/
- William F. Godoy, Norbert Podhorszki, Ruonan Wang, Chuck Atkins, Greg Eisenhauer, Junmin Gu, Philip Davis, Jong Choi, Kai Germaschewski, Kevin Huck, Axel Huebl, Mark Kim, James Kress, Tahsin Kurc, Qing Liu, Jeremy Logan, Kshitij Mehta, George Ostrouchov, Manish Parashar, Franz Poeschel, David Pugmire, Eric Suchyta, Keichi Takahashi, Nick Thompson, Seiji Tsutsumi, Lipeng Wan, Matthew Wolf, Kesheng Wu, and Scott Klasky. 2020. ADIOS2: The Adaptable Input Output System. A framework for high-performance data management. SoftwareX 12(2020), 100561. https://doi.org/10.1016/j.softx.2020.100561
- Junmin Gu, Philip Davis, Greg Eisenhauer, William Godoy, Axel Huebl, Scott Klasky, Manish Parashar, Norbert Podhorszki, Franz Poeschel, JeanLuc Vay, Lipeng Wan, Ruonan Wang, and Kesheng Wu. 2022. Organizing Large Data Sets for Efficient Analyses on HPC Systems. Journal of Physics: Conference Series 2224, 1 (2022), 012042. https://doi.org/10.1088/1742-6596/2224/1/012042
- Junmin Gu, Scott Klasky, Norbert Podhorszki, Ji Qiang, and Kesheng Wu. 2018. Querying large scientific data sets with adaptable IO system ADIOS. In Asian Conference on Supercomputing Frontiers. Springer, Springer, 51–69.
- T. Hey, S. Tansley, and K. Tolle (Eds.). 2009. The Fourth Paradigm: Data-Intensive Scientific Discovery. Microsoft. 287 pages.
- Sunggon Kim, Alex Sim, Kesheng Wu, Suren Byna, Yongseok Son, and Hyeonsang Eom. 2020. Towards HPC I/O performance prediction through large-scale log analysis. In Proceedings of the 29th International Symposium on High-Performance Parallel and Distributed Computing. ACM, 77–88. https://doi.org/10.1145/3369583.3392678
- Fabian Koller, Franz Poeschel, Junmin Gu, and Axel Huebl. 2021. openPMD-api: C++ & Python API for Scientific I/O with openPMD. OpenPMD. https://doi.org/10.14278/rodare.27 https://github.com/openPMD/openPMD-api.
- Donghun Koo, Jaehwan Lee, Jialin Liu, Eun-Kyu Byun, Jae-Hyuck Kwak, Glenn K. Lockwood, Soonwook Hwang, Katie Antypas, Kesheng Wu, and Hyeonsang Eom. 2021. An empirical study of I/O separation for burst buffers in HPC systems. J. Parallel and Distrib. Comput. 148 (2021), 96–108. https://doi.org/10.1016/j.jpdc.2020.10.007
- Adam Leventhal. 2008. Flash Storage Today: Can Flash Memory Become the Foundation for a New Tier in the Storage Hierarchy?Queue 6, 4 (jul 2008), 24––30. https://doi.org/10.1145/1413254.1413262
- Glenn K. Lockwood, Alberto Chiusole, and Nicholas J. Wright. 2021. New Challenges of Benchmarking All-Flash Storage for HPC. In 2021 IEEE/ACM Sixth International Parallel Data Systems Workshop (PDSW). IEEE, 1–8. https://doi.org/10.1109/PDSW54622.2021.00006
- Simone Ferlin Oliveira, Karl Furlinger, and Dieter Kranzlmuller. 2012. Trends in Computation, Communication and Storage and the Consequences for Data-intensive Science. In 2012 IEEE 14th International Conference on High Performance Computing and Communication. 572–579. https://doi.org/10.1109/HPCC.2012.83
- Wei Pan, Zhanhuai Li, Yansong Zhang, and Chuliang Weng. 2018. The new hardware development trend and the challenges in data management and analysis. Data Science and Engineering 3, 3 (2018), 263–276. https://doi.org/10.1007/s41019-018-0072-6
- H. Riggs, S. Tufail, I. Parvez, and A. Sarwat. 2020. Survey of Solid State Drives, Characteristics, Technology, and Applications. In 2020 SoutheastCon. IEEE, 1–6. https://doi.org/10.1109/SoutheastCon44009.2020.9249760
- Hanul Sung, Jiwoo Bang, Alexander Sim, Kesheng Wu, and Hyeonsang Eom. 2019. Understanding Parallel I/O Performance Trends Under Various HPC Configurations. In SNTA@HPDC 2019. ACM, 29–36. https://doi.org/10.1145/3322798.3329258
- J.-L. Vay, A. Huebl, A. Almgren, L. D. Amorim, J. Bell, L. Fedeli, L. Ge, K. Gott, D. P. Grote, M. Hogan, R. Jambunathan, R. Lehe, A. Myers, C. Ng, M. Rowan, O. Shapoval, M. Thevenet, H. Vincenti, E. Yang, N. Zaïm, W. Zhang, Y. Zhao, and E. Zoni. 2021. Modeling of a chain of three plasma accelerator stages with the WarpX electromagnetic PIC code on GPUs. Physics of Plasmas 28(2021), 023105. https://doi.org/10.1063/5.0028512
FOOTNOTE
1 https://github.com/ornladios/ADIOS.
2 https://www.hpe.com/psnow/doc/a00062172enw.html
3 https://docs.nersc.gov/filesystems/perlmutter-scratch/

This work is licensed under a Creative Commons Attribution International 4.0 License.
SSDBM 2022, July 06–08, 2022, Copenhagen, Denmark
© 2022 Copyright held by the owner/author(s).
ACM ISBN 978-1-4503-9667-7/22/07.
DOI: https://doi.org/10.1145/3538712.3538734